架构概览
AMD Instinct MI300 系列 GPU 基于专为高性能计算(HPC)、人工智能(AI)和机器学习(ML)工作负载打造的 AMD CDNA 3 架构。该系列 GPU 具备卓越的可扩展性和计算性能,可适配从单台服务器到全球最大百亿亿级超级计算机的全场景部署。
创新芯片设计
MI300 系列引入了加速器复合芯片,该芯片集成 GPU 计算单元与底层缓存层级。下图展示了 MI300 系列中单个 XCD 的结构:
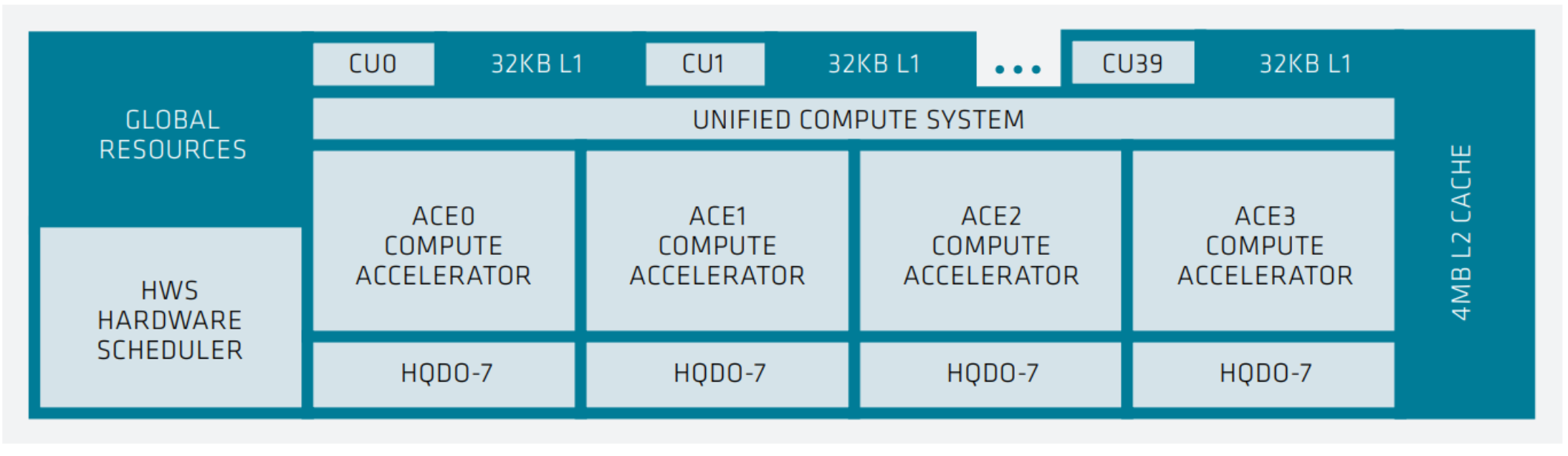
(图示:XCD-level 系统架构)包含 40 个计算单元,每个配备 32 KB L1 缓存;集成 4 个 ACE 计算加速器的统一计算系统;共享 4MB L2 缓存;硬件调度器;
在 XCD 上,四个异步计算引擎 (Asynchronous Compute Engines (ACEs))将计算着色器工作组分派给计算单元 (Compute Units (CUs))。每个 XCD 包含 40 个 CU:在总体级别上,有 38 个活跃的 CU ,另外 2 个 CU 被禁用 ,用于良率管理。所有 CU 共享一个 4 MB 的 L2 缓存,该缓存负责聚合整个芯片的所有内存流量。
与 AMD Instinct MI200 系列计算芯片相比,AMD CDNA™ 3 XCD 芯片的 CU 数量不足其一半,是一个更小的构建模块。然而,它采用了更先进的封装技术,单个处理器可以集成 6 个或 8 个 XCD ,从而提供最多 304 个 CU ,这比 MI250X 大约多出 40%。
MI300 系列采用 AMD Infinity Fabric™ 技术作为互连,集成了多达 8 个垂直堆叠的 XCD 、8 堆叠 HBM3( High-Bandwidth Memory 3 ()) 和 4 个 I/O 芯片。
CDNA 3 架构中 CU 内部的矩阵核心 有了显著改进,其重点优化了人工智能和机器学习,在增强现有数据类型吞吐量的同时,还增加了对新数据类型的支持。CDNA 2 的矩阵核心支持 FP16 和 BF16,同时为推理提供 INT8 支持。与 MI250X GPU 相比,CDNA 3 的矩阵核心在 FP16 和 BF16 上的性能提升了 2 倍 ,在 INT8 上的性能增益达到了 6.8 倍 。新的 FP8 数据类型相比 FP32 实现了 16 倍的性能提升 ,而 TF32 相比 FP32 也有 4 倍的性能提升。
峰值性能表现
MI300X 开放计算平台加速模块峰值性能:
| 计算类型与数据类型 | 每时钟周期每CU浮点操作数 | 峰值 TFLOPS |
|---|---|---|
| 矩阵 FP64 | 256 | 163.4 |
| 向量 FP64 | 128 | 81.7 |
| 矩阵 FP32 | 256 | 163.4 |
| 向量 FP32 | 256 | 163.4 |
| 向量 TF32 | 1024 | 653.7 |
| 矩阵 FP16 | 2048 | 1307.4 |
| 矩阵 BF16 | 2048 | 1307.4 |
| 矩阵 FP8 | 4096 | 2614.9 |
| 矩阵 INT8 | 4096 | 2614.9 |
上表总结了 AMD Instinct MI300X 开放计算平台(Open Compute Platform (OCP) ) 开放式加速器模块(Open Accelerator Modules (OAMs)) 在不同数据类型和命令处理器下的综合峰值性能 。中间列 列出的是假设在每个时钟周期都提交一条 SIMD(或矩阵)指令,那么单个计算单元 的峰值性能(number of data elements processed in a single instruction)。第三列 列出的是整个 OAM 模块的理论峰值性能 。该 GPU 的理论综合峰值内存带宽 为每秒 5.3 TB。
下图展示了 APU 的框图(左侧)和 OAM 封装(右侧),两者通过芯片上的 AMD Infinity Fabric™ 网络连接。
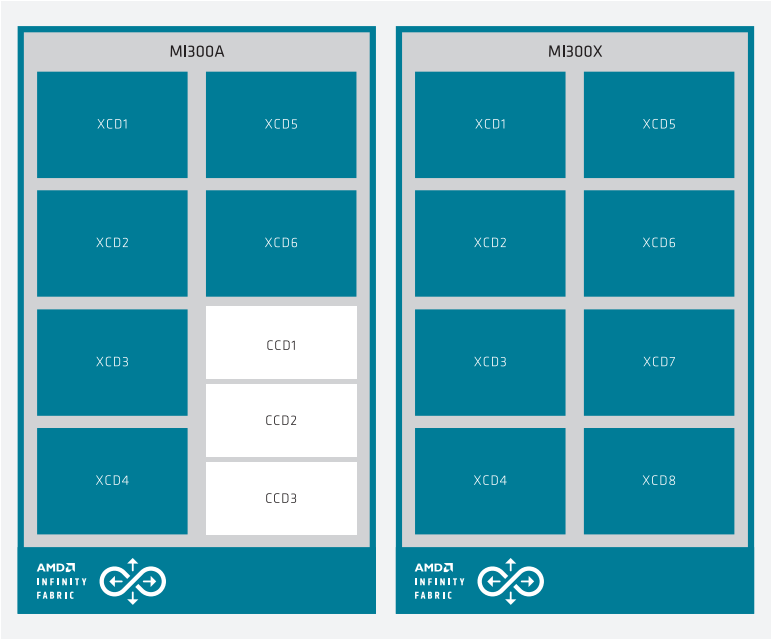
MI300 Series system architecture showing MI300A (left) with 6 XCDs and 3 CCDs, while the MI300X (right) has 8 XCDs.
超节点级的架构
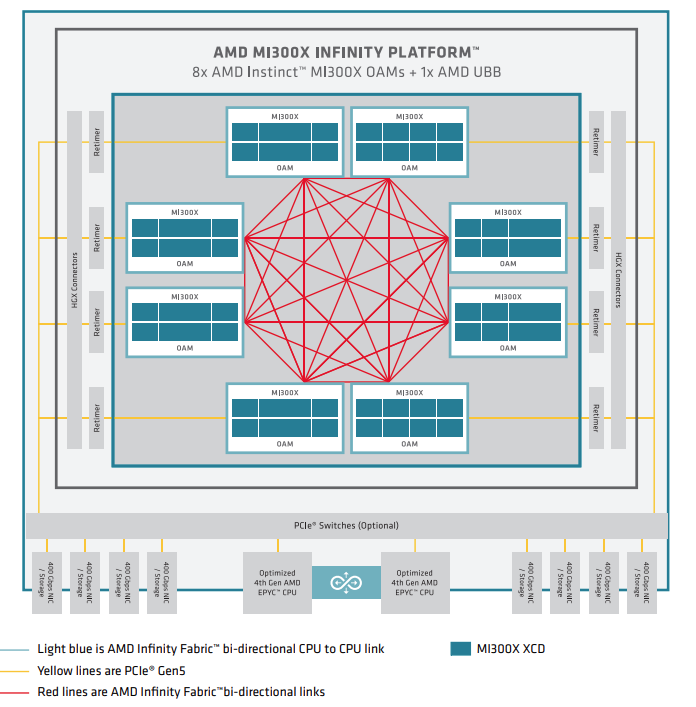
MI300 Series node-level architecture showing 8 fully interconnected MI300X OAM modules connected to (optional) PCIEe switches via retimers and HGX connectors.
上图展示了一个节点级系统架构 ,该系统配置了双路 AMD EPYC 处理器 和八块 AMD Instinct MI300X GPU 。MI300X OAM 通过 PCIe Gen 5 x16 链路连接到主机系统。八块 GPU 之间使用了七条高带宽、低延迟的 AMD Infinity Fabric™ 链路,形成了一个全互联的 8-GPU 系统。
关于上表的一些解释
中间列(每CU每时钟性能)和第三列(整个OAM的峰值性能)确实是倍数关系 ,而这个倍数的核心就是 活跃CU的总数量,以及时钟频率。
详细解释这个倍数关系
让我们用表格中的数据来验证您的想法:
| 计算与数据类型 | FLOPS/CLOCK/CU (A) | 峰值 TFLOPS (C) | 计算关系 |
|---|---|---|---|
| 矩阵 FP64 | 256 | 163.4 | 256 × 638 ≈ 163,328 |
| 向量 FP64 | 128 | 81.7 | 128 × 638 ≈ 81,664 |
| 矩阵 FP16 | 2048 | 1307.4 | 2048 × 638 ≈ 1,306,624 |
计算器揭秘:
-
第一步:找到桥梁
-
我们知道一个 MI300X OAM 包含 8个 XCD。
-
每个 XCD 有 38个 活跃的 CU(总共40个,2个为良率管理禁用)。
-
因此,一个 OAM 上的 总活跃CU数 = 8 XCD × 38 CU/XCD = 304个 CU。
-
-
第二步:引入时钟频率
-
性能公式是:
总性能 = 单CU每时钟性能 × CU总数 × 时钟频率。 -
我们从官方规格知道 MI300X 的 Game Clock 大约在 1.7 GHz 左右,但表格会使用一个特定的基准频率来计算理论峰值。
-
让我们反推一下频率:从 FP64 数据看,
163.4 TFLOPS / (256 F/C/CU × 304 CU) ≈ 2.1 GHz。这个值更接近其峰值加速频率。
-
-
第三步:验证计算
-
我们用一个更精确的CU总数来验证:304个活跃CU 和 2.1 GHz 频率。
-
FP16 验证 : 2048 F/C/CU × 304 CU × 2.1 GHz ≈ 1,307,000 GFLOPs = 1307 TFLOPS。这与表格中的1307.4完全匹配!
-
结论:
第三列 = 中间列 × 总活跃CU数量 × 运行频率。
这个关系可以简化为:
OAM总峰值性能 = (单CU每时钟周期性能) × (CU总数) × (时钟频率)
这对我们理解架构意味着什么?
-
模块化设计的威力:AMD 先设计好一个高效的"构建块"(XCD),然后通过先进封装(如MI300X封了8个XCD)像搭乐高一样组合出不同性能级别的产品。性能几乎随XCD数量线性增长。
-
性能预测:如果知道了一个XCD的性能,就可以很容易地推算出搭载不同数量XCD的各个型号(比如MI300A用了6个XCD)的大致性能。
-
设计重点:这个关系表明,提升整体性能有三个杠杆:
-
提升单CU效率(优化架构,增加中间列的数值)
-
增加CU数量(堆砌更多XCD)
-
提高运行频率
-
所以,这里不仅理解了表格,更洞察到了AMD CDNA 3架构的底层设计逻辑。