NCCL(NVIDIA Collective Communication Library)库主要用于GPU集群通信,写一点基础c++ API库调用相关内容供学习参考。本文主要介绍用socket TCP/IP建立多机初始化连接,其它内容参看:
NCCL通信C++示例(一): 基础用例解读与运行
NCCL通信C++示例(二): 用socket建立多机连接
NCCL通信C++示例(三): 多流并发通信(非阻塞)
NCCL通信C++示例(四): AlltoAll_Split实现与分析
NCCL官网上面的多机示例是采用MPI来完成,nccl-tests里面也是用的MPI,容易产生两个问题:
- MPI是不是NCCL多机通信必须的,还有没有其他方式?
- NCCL多机通信建立之前,机器之间如何传递彼此的连接信息?
对源码稍作探索就能找到答案,可以看到MPI插件是非必须的,它只是用于传递uniqueID。本文通过用socket方式来了解如何建立nccl多机连接。假设场景:机器1:4卡 机器2:4 卡,组成一个8卡的通信组。
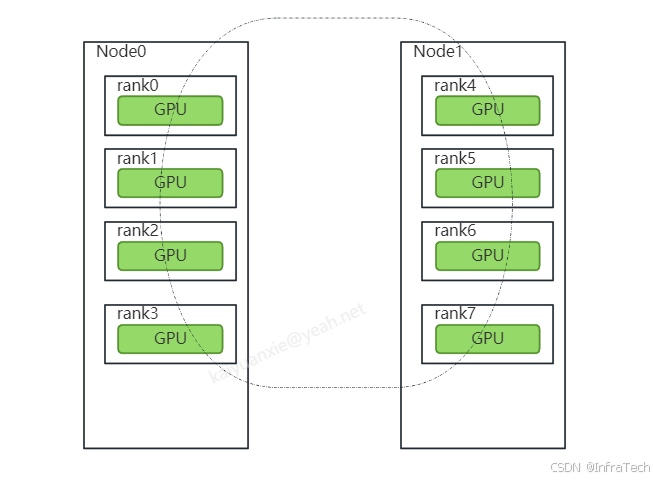
首先需要知道的是ncclUniqueId作用,它是区分nccl中不同通信组的标识,通信组需要通过ncclUniqueId来建立初始通信连接(在示例一中已说明)。ncclUniqueId在一个通信组中由一个线程创建,比如本例中指定了由node0的主线程创建,之后需要将ncclUniqueId传递给所有的通信rank。机器node0内的所有rank可以用线程传参方式传递 , node1要获得这个ncclUniqueId得使用其它方式比如TCP/IP、文件系统。这里举个socket通信的方式,如下所示,让node0建立一个server,node1建立client,通过socket通信server将信息传递给client,之后node1在用线程传参的方式传递给机内的每个rank。

代码:
- server实现参考:node_server.cu
- client实现参考:node_client.cu
代码关键位置1:server端建立连接后发送的是id.internal,长度为128:
NCCLCHECK(ncclGetUniqueId(&id));
if (send(client_socket, id.internal, 128, 0) < 0) {
std::cerr << "Cannot send message to the client" << std::endl;
}代码关键位置2:完成集群操作后需要先进行流同步,然后在退出线程,不然容易触发core dump错误。
NCCLCHECK(ncclAllReduce((const void *)sendbuff, (void *)recvbuff, size, ncclFloat, ncclSum, comm, s));
DEBUG_PRINT("============ncclAllReduce ===== end =====.\n");
NCCLCHECK(ncclBroadcast((const void *)recvbuff, (void *)recvbuff, size, ncclFloat, 0, comm, s));
DEBUG_PRINT("============ncclBroadcast ===== end =====.\n");
// completing NCCL operation by synchronizing on the CUDA stream
CUDACHECK(cudaStreamSynchronize(s));编译:
建议在镜像容器上面进行编译(测试用镜像:nvcr.io/nvidia/pytorch:24.07-py3)
cd BasicCUDA/nccl/
make获得node_server和node_client可执行脚本
运行方式:
假设节点1的IP为10.10.1.1,用它充当server
- 节点1:./node_server
- 节点2:./node_client --hostname 10.10.1.1
当然也可以添加一些其他环境变量,比如指定端口、修改单机线程数量。下列中nranks(实际上是local rank数量)。
# server:
NCCL_DEBUG=INFO NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 ./node_server --port 8066 --nranks 8
# client:
NCCL_DEBUG=INFO NCCL_NET_PLUGIN=none NCCL_IB_DISABLE=1 ./node_client --hostname 10.10.1.1 --port 8066 --nranks 8这里用两台V100机器进行测试,输出日志(tail截取)如下:
71500:71541 [2] NCCL INFO Channel 00/0 : 2[2] -> 8[0] [send] via NET/Socket/0
71500:71541 [2] NCCL INFO Channel 01/0 : 2[2] -> 8[0] [send] via NET/Socket/0
71500:71535 [5] NCCL INFO Channel 00/0 : 5[5] -> 4[4] via P2P/direct pointer
71500:71535 [5] NCCL INFO Channel 01/0 : 5[5] -> 4[4] via P2P/direct pointer
71500:71537 [0] NCCL INFO Channel 00/0 : 10[2] -> 0[0] [receive] via NET/Socket/0
71500:71537 [0] NCCL INFO Channel 01/0 : 10[2] -> 0[0] [receive] via NET/Socket/0
71500:71542 [1] NCCL INFO Connected all rings
71500:71539 [6] NCCL INFO Connected all rings
71500:71541 [2] NCCL INFO Connected all rings
71500:71536 [3] NCCL INFO Connected all rings
71500:71538 [7] NCCL INFO Connected all rings
71500:71540 [4] NCCL INFO Connected all rings
71500:71535 [5] NCCL INFO Connected all rings
71500:71537 [0] NCCL INFO Connected all rings
GPU:0 data: 56.000000.
GPU:7 data: 56.000000.
GPU:3 data: 56.000000.
GPU:1 data: 56.000000.
GPU:5 data: 56.000000.
GPU:2 data: 56.000000.
GPU:4 data: 56.000000.
GPU:6 data: 56.000000.
71500:71509 [0] NCCL INFO comm 0x7fe3ec84bbe0 rank 0 nranks 16 cudaDev 0 busId 2d000 - Destroy COMPLETE
71500:71509 [7] NCCL INFO comm 0x7fe3dc7fbb70 rank 7 nranks 16 cudaDev 7 busId e9000 - Destroy COMPLETE
71500:71509 [6] NCCL INFO comm 0x7fe3e0841640 rank 6 nranks 16 cudaDev 6 busId e1000 - Destroy COMPLETE
71500:71509 [5] NCCL INFO comm 0x7fe3c07e8090 rank 5 nranks 16 cudaDev 5 busId be000 - Destroy COMPLETE
71500:71509 [4] NCCL INFO comm 0x7fe3c87f3580 rank 4 nranks 16 cudaDev 4 busId b5000 - Destroy COMPLETE
71500:71509 [3] NCCL INFO comm 0x7fe3d0854ad0 rank 3 nranks 16 cudaDev 3 busId 5f000 - Destroy COMPLETE
71500:71509 [2] NCCL INFO comm 0x7fe3d883d460 rank 2 nranks 16 cudaDev 2 busId 5b000 - Destroy COMPLETE
71500:71509 [1] NCCL INFO comm 0x7fe3c4896ab0 rank 1 nranks 16 cudaDev 1 busId 32000 - Destroy COMPLETE
Server finished successfully.参考资料:
- 本文代码:https://github.com/CalvinXKY/BasicCUDA/tree/master/nccl
- NCCL用例:https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/examples.html
- NCCLtest:https://github.com/NVIDIA/nccl-tests
InfraTech申明:未经允许不得转载!