一、前言
本文原创,著作权归WGrape所有,未经授权,严禁转载。
在AI搜索领域,随着技术的不断发展,已经出现多种实现方式。本文将带您快速了解并掌握四种常见的AI搜索实现方案,每种方案都具备独特优势,适用于不同的应用场景。接下来,我们将通过代码示例逐步解析各个实现方式。
二、基础工作
1、搜索引擎选择
用户可以根据需求自行选择购买谷歌、必应等搜索服务,或者使用第三方搜索服务,例如 SearchAPI。通过访问 SearchAPI 官方网站注册账号后,用户将获得一个 API Key,每个 Key 可免费调用 100 次,非常适合调研和初期测试。

2、创建基础web_search.py代码
我们首先创建一个 web_search.py 文件,作为共用代码。在该文件中定义 SearchAPI 服务的 KEY,同时设置模型的三个必备配置项:OPENAI_API_KEY、OPENAI_BASE_URL 和 OPENAI_MODEL。此外,还定义了两个自定义常量:OPENAI_MODEL_TYPE 和 MODEL_CONFIG,这两个常量将在后续使用第三方库创建模型时用到,暂时无需关注其具体作用。
最后,我们在文件中定义了 WebSearch 类及其相关工具,完整代码如下所示。
python
"""
@File: web_search.py
@Date: 2024/12/10 10:00
@Desc: 联网搜索工具
"""
from typing import Any
from langchain.tools import BaseTool
from langchain_community.utilities import BingSearchAPIWrapper, SearchApiAPIWrapper
SEARCHAPI_API_KEY = ""
OPENAI_API_KEY = ""
OPENAI_BASE_URL = "https://api.deepseek.com"
OPENAI_MODEL = "deepseek-chat"
OPENAI_MODEL_TYPE = "model_type_deepseek_chat"
MODEL_CONFIG = {
"api_base": OPENAI_BASE_URL,
"api_key": OPENAI_API_KEY,
"model": OPENAI_MODEL,
"model_type": OPENAI_MODEL_TYPE,
"max_tokens": 512,
"retry": 3,
}
class WebSearch:
"""
必应搜索类
"""
_engine: Any
ENGINE_TYPE_BING = "bing"
ENGINE_TYPE_GOOGLE = "google"
ENGINE_TYPE_SEARCHAPI = "searchapi"
def __init__(self, engine: str, engine_config: dict):
if engine == self.ENGINE_TYPE_BING:
self._engine = BingSearchAPIWrapper(
bing_subscription_key=engine_config["bing_subscription_key"],
bing_search_url=engine_config["bing_search_url"],
)
elif engine == self.ENGINE_TYPE_SEARCHAPI:
self._engine = SearchApiAPIWrapper(
engine="bing",
searchapi_api_key=engine_config["searchapi_api_key"],
)
def search(self, query: str, count: int = 5) -> list:
"""
开始搜索
:return:
"""
result: list = []
if isinstance(self._engine, BingSearchAPIWrapper):
search_list = self._engine.results(query=query, num_results=count)
for search_item in search_list:
result.append({
"title": search_item["title"],
"url": search_item["link"],
"icon": search_item["icon"],
"desc": search_item["snippet"],
})
elif isinstance(self._engine, SearchApiAPIWrapper):
search_result = self._engine.results(query=query, num_results=count)
for search_item in search_result["organic_results"]:
result.append({
"title": search_item["title"],
"url": search_item["link"],
"icon": search_item["favicon"],
"desc": search_item["snippet"],
})
return result
def search_web_tool(query: str, count: int = 5) -> str:
"""
联网搜索工具
:param query: 搜索内容
:param count: 搜索结果数量
"""
result = WebSearch(engine=WebSearch.ENGINE_TYPE_SEARCHAPI, engine_config={
"searchapi_api_key": SEARCHAPI_API_KEY,
}).search(query=query, count=count)
search_result_str = ""
for k, item in enumerate(result):
search_result_str += f"""[{k + 1}] 标题: {item["title"]} 链接: {item["url"]} 描述: {item["desc"]}\n"""
search_context = f"=> 搜索行为 | 搜索内容:{query} | 搜索结果如下所示\n{search_result_str}"
print(search_context)
return search_context
class SearchWebTool(BaseTool):
name = "search_web_tool" # 名字必须符合正则^[a-zA-Z0-9_-]+$
description = "联网搜索工具,通过网络搜索获取更详细更权威更实时的信息"
def _run(self, query: str) -> str:
return search_web_tool(query)
def _arun(self, query: str) -> str:
raise NotImplementedError("This tool does not support async")
WEBSEARCH_TOOL_DEFINITION = {
"type": "function",
"function": {
"name": "search_web_tool",
"description": "联网搜索工具,通过网络搜索获取更详细更权威更实时的信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "需要进行网络搜索的搜索词",
}
},
"required": ["query"],
"additionalProperties": False
},
}
}
# result = WebSearch(engine=WebSearch.ENGINE_TYPE_SEARCHAPI, engine_config={
# "searchapi_api_key": "",
# }).search("hello world", 5)
#
# print(result)三、实现AI搜索的几种方式
1、基于OpenAI Tool Calling实现
OpenAI 提供了 Tool Calling 功能(原称 Function Calling),允许开发者传入外部自定义函数来扩展大模型的能力。这项功能已经成为各大服务商大模型普遍遵循的规范,目前许多 Agent 的实现也基于此功能构建。借助 Tool Calling,开发者可以将定义的搜索工具集成到大模型中,使其在处理任务时具备搜索能力。
下面,我们新建一个aisearch_by_openai_tool_calling.py文件,我们写入如下代码。
python
"""
@File: aisearch_by_openai_tool_calling.py
@Date: 2024/12/10 10:00
@Desc: 基于OpenAI的tool-calling实现AI搜索
"""
import os
import sys
import json
from openai import OpenAI
from web_search import search_web_tool, OPENAI_API_KEY, OPENAI_BASE_URL, OPENAI_MODEL, WEBSEARCH_TOOL_DEFINITION
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 先调用模型并传递工具, 获取工具调用信息
messages = [
{"role": "system", "content": "你是一个智能助手,"},
{"role": "user", "content": "搜索北京今天的天气"},
]
model = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_BASE_URL)
llm_result = model.chat.completions.create(
model=OPENAI_MODEL,
messages=messages,
stream=False,
tools=[WEBSEARCH_TOOL_DEFINITION]
)
if hasattr(llm_result, "choices") and len(llm_result.choices) > 0 \
and hasattr(llm_result.choices[0], "message") \
and hasattr(llm_result.choices[0].message, "tool_calls") \
and type(llm_result.choices[0].message.tool_calls) == list \
and len(llm_result.choices[0].message.tool_calls) > 0:
tool_call = llm_result.choices[0].message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
function_result_str = ""
if function_name == "search_web_tool":
function_result_str = search_web_tool(**function_args) # 约定所有Tool都返回字符串
# 拼接调用结果
messages.extend([
{
"role": "assistant",
"tool_calls": [
{
"function": {
"arguments": tool_call.function.arguments,
"name": function_name
},
"id": tool_call.id,
"type": "function"
}
]
},
{"role": "tool", "tool_call_id": tool_call.id, "name": function_name, "content": function_result_str}
])
print(messages)
# 将工具调用结果传入上下文, 获取大模型的最终输出
llm_text_generator = model.chat.completions.create(
model=OPENAI_MODEL,
messages=messages,
stream=True,
)
for chunk in llm_text_generator:
# Get the current chunk content
if not hasattr(chunk, 'choices') or not chunk.choices or not chunk.choices[0].delta.content:
continue
chunk_text = chunk.choices[0].delta.content
print(chunk_text, end="", flush=True)执行结果如下图所示。

这种实现方式的优劣势如下:
- 优势:灵活易扩展,可根据需求轻松实现各种自定义功能。
- 劣势:基于原生实现,需要开发大量的基础逻辑,开发成本较高。
2、基于LangChain的Agent实现
LangChain 是一个专注于语言模型应用开发的框架,提供了功能强大的 Agent 模块。Agent 的核心能力在于根据用户输入动态选择合适的工具,并执行多步推理任务,从而实现复杂问题的解决。此外,LangChain 的生态系统还包括诸如 LangSmith 和 LangGraph 等工具,这些工具能够提供全面的 Agent 日志和执行信息的可视化功能,让开发者能够轻松追踪和优化 Agent 的行为。这些开箱即用的功能使 LangChain 成为开发语言模型应用的高效解决方案,非常方便实用。
下面,我们新建一个aisearch_by_langchain_agent.py文件,我们写入如下代码。
python
"""
@File: aisearch_by_langchain_agent.py
@Date: 2024/12/10 10:00
@Desc: 基于Langchain的Agent实现AI搜索
"""
import os
import sys
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor
from langchain.agents import create_tool_calling_agent
from langchain_core.prompts.chat import ChatPromptTemplate
from web_search import SearchWebTool, OPENAI_API_KEY, OPENAI_BASE_URL, OPENAI_MODEL
from langchain.prompts import HumanMessagePromptTemplate, SystemMessagePromptTemplate
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# 创建model模型
model = ChatOpenAI(
model=OPENAI_MODEL,
temperature=0.5,
timeout=None,
max_retries=3,
api_key=OPENAI_API_KEY, # 配置你的api_key
base_url=OPENAI_BASE_URL,
streaming=False,
)
system_message_prompt = SystemMessagePromptTemplate.from_template(template="# 角色\n你是一个智能助手")
human_message_prompt = HumanMessagePromptTemplate.from_template(template="# 用户问题\n{input}\n{agent_scratchpad}") # 必须使用agent_scratchpad这个变量
chat_prompt_template = ChatPromptTemplate.from_messages(messages=[
system_message_prompt, human_message_prompt,
])
# 创建工具
tools = [
SearchWebTool()
]
# 第一种使用方法[可以使用]
# agent = create_openai_tools_agent(llm=model, tools=tools, prompt=chat_prompt_template)
# executor = AgentExecutor(agent=agent, tools=tools)
# 第二种使用方法[可以使用]
agent = create_tool_calling_agent(llm=model, tools=tools, prompt=chat_prompt_template)
executor = AgentExecutor(agent=agent, tools=tools)
# 调用链
print("1: ", executor.invoke({"input": "搜索北京今天的天气"}))执行结果如下图所示。

这种实现方式的优劣势如下。
- 优势:开箱即用,不需要开发基础逻辑,生态完善。
- 劣势:扩展性不足、灵活性不足。
3、基于手动Workflow的实现
(1) Agent设计的劣势
在前两种实现方式种,主要讨论了基于 Agent 的实现方式。然而,在实际应用场景中,Agent通常不会将多个外部工具的调用集中到一个 Agent 中,而是采用"单功能单 Agent"的设计原则,通过多 Agent 协同的方式来完成复杂任务。然而,多 Agent 协同虽然灵活强大,但也伴随着一系列技术难题,例如通信、资源调度以及错误处理等问题。因此,在实际业务场景的落地实现中,基于实现复杂度考虑,同时为了确保大模型能够严格按照既定计划执行,通常会优先选择 Workflow 的方式。
(2) Workflow设计原理
Workflow 是一种完全自定义的流程实现方式,与 Agent 方法形成了鲜明对比,并且与 Agent 没有直接关联。其核心在于开发者自行控制和编排每一步的流程,强调对任务执行的完全可控。这种方式与 Agent 的自动感知、决策和执行逻辑截然相反。Agent 的优势在于动态选择工具并自动完成任务,而 Workflow 则要求开发者明确设计和串联流程逻辑,确保每个步骤都按照预定计划执行。
(3) 理解Workflow设计
为了更好地理解 Workflow 的概念,我们可以构想 AI 搜索的核心流程。首先,从用户输入开始,系统对用户的查询(Query)进行分析,包括意图识别、问题分类、错别字纠正等操作;接着,从分析结果中提取关键词,用于执行搜索以获取相关结果;最后,将搜索结果封装为上下文信息,传递给模型生成最终答案。
因此,在AI搜索中,Workflow 的核心思想是将这些关键步骤------意图分析、搜索执行、模型回答------拆解为独立的流程函数,并通过手动设计将它们串联起来,形成一个完整的搜索逻辑。开发者通过这种方式可以灵活掌控每一步的处理逻辑,实现高效且可控的 AI 搜索功能。
(4) 代码实现
下面,我们新建一个aisearch_by_manual_workflow.py文件,我们写入如下代码。
python
"""
@File: aisearch_by_manual_workflow.py
@Date: 2024/12/10 10:00
@Desc: 基于手动Workflow的AI搜索实现
"""
import os
import sys
from wpylib.util.x.xjson import parse_raise
from wpylib.pkg.langchain.model import Model
from wpylib.pkg.langchain.chain import create_chain
from web_search import search_web_tool, MODEL_CONFIG
from wpylib.pkg.langchain.prompt import create_chat_prompt_by_messages
from langchain_core.prompts.chat import SystemMessage, HumanMessage, HumanMessagePromptTemplate
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
model = Model(
model_type=MODEL_CONFIG["model_type"],
model_config=MODEL_CONFIG,
)
def analyze_query(query: str) -> list[str]:
"""
分析用户输入, 并返回分析后的Query列表
:param query: 用户输入的问题
:return: 返回分析处理后的query
"""
# (1) 意图分析
prompt = create_chat_prompt_by_messages(messages=[
SystemMessage(content="""
# 角色
你是一个意图分析器。
# 要求
请分析用户的意图,属于以下类别之一:
- method
- write
- summary
- none
# 返回格式
请以以下JSON格式返回:
{
"intention": "<类别>"
}
"""),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = create_chain(
model=model.get_raw_model(),
prompt=prompt,
)
llm_invoke = chain.invoke(input=query)
llm_result = parse_raise(llm_invoke["text"].replace("\n", ""))
intention = llm_result["intention"]
# 可以基于不同的意图, 自定义扩展后续的回答逻辑
# (2) Query改写
prompt = create_chat_prompt_by_messages(messages=[
SystemMessage(content="""
# 角色
你是一个查询改写器。
# 要求
请对此查询进行改写,包括但不限于错字更正、歧义消除等。
# 返回格式
请以以下JSON格式返回:
{
"rewritten_query": "<改写后的查询>"
}
"""),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = create_chain(
model=model.get_raw_model(),
prompt=prompt,
)
llm_invoke = chain.invoke(input=query)
llm_result = parse_raise(llm_invoke["text"].replace("\n", ""))
rewritten_query = llm_result["rewritten_query"]
# (3) Query扩写
prompt = create_chat_prompt_by_messages(messages=[
SystemMessage(content="""
# 角色
你是一个查询扩写器。
# 要求
请对此查询进行扩写,包括但不限于同义词扩写、相近概念扩写等。
# 返回格式
请以以下JSON格式返回:
{
"expanded_query": ["<扩写后的查询>"]
}
"""),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = create_chain(
model=model.get_raw_model(),
prompt=prompt,
)
llm_invoke = chain.invoke(input=rewritten_query)
llm_result = parse_raise(llm_invoke["text"].replace("\n", ""))
query_list = llm_result["expanded_query"][:3]
# 返回分析并处理后的Query列表
return query_list
def search_query(query_list: list[str]) -> str:
"""
执行搜索
:param query_list: 处理后的Query列表
:return: 返回搜索结果内容
"""
search_context = ""
for temp_query in query_list:
search_context += search_web_tool(query=temp_query) + "\n"
return search_context
def generate_answer(query: str, search_context: str) -> str:
"""
生成回答
:param query: 用户输入的问题
:param search_context: 搜索结果内容
:return: 返回模型回答内容
"""
# 调用模型回答
llm_text_generator = model.stream(
langchain_input=[
# System消息
SystemMessage(
content="# 角色\n你是一个智能助手 ## 要求\n请基于以下搜索结果,回答用户的问题。\n\n### 搜索结果\n" + search_context
),
# 加入当前用户提问
HumanMessage(query)
]
)
# 输出内容
llm_text = ""
for item in llm_text_generator:
llm_text += item.content
print(item.content, end="", flush=True)
return llm_text
def aisearch_workflow(query: str) -> str:
"""
开始执行AI搜索工作流
:param query: 用户输入的问题
"""
# [分析输入部分]分析用户输入
query_list = analyze_query(query=query)
# [执行动作部分]开始执行搜索
search_context = search_query(query_list=query_list)
# [生成答案部分]调用模型回答
llm_text = generate_answer(query=query, search_context=search_context)
return llm_text
user_ask = "搜索北京今天的天气"
answer = aisearch_workflow(query=user_ask)
print(f"\n\nAnswer: {answer}")执行结果如下图所示。
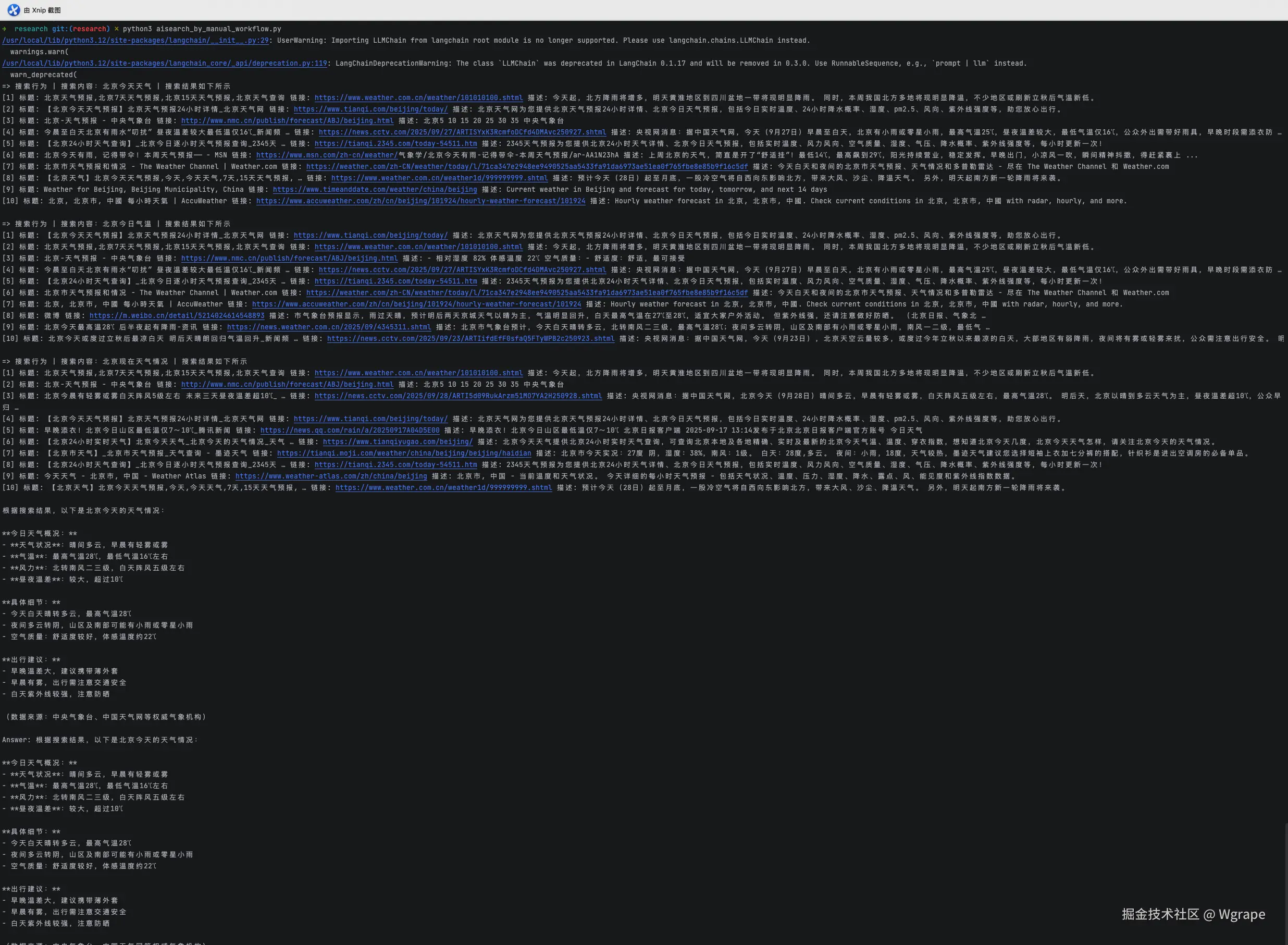
这种实现方式的优劣势如下。
- 优势:精准控制、稳定性高、灵活定制。
- 劣势:开发成本高、缺乏动态适应性。
4、基于自动Workflow的实现
(1) Workflow的劣势
在上述的 Workflow 实现中,我们虽然已经将 AI 搜索拆分为核心的分析流程函数、搜索流程函数和回答流程函数。然而,这种串联式的设计并不能解决所有问题。比如,有些用户的 Query 可能并不需要进行搜索,仅凭大模型的能力就可以直接生成答案。在这种情况下,上述 Workflow 的劣势就显现出来了,在这个串联的流程中,可能有些操作是不需要执行的。
(2) 优化Workflow方案
为了解决这一问题,同时提升系统的扩展性,我们需要设计一种更灵活的方案。这种设计可以从分析流程函数(即 analyze_query 函数)入手。目前 analyze_query 的最终输出是 Query,那么是否可以进一步扩展,让它直接生成后续需要执行的所有步骤?例如,是否需要进行搜索?是否需要直接输出结果?
基于这一思路,我们提出了一种基于自动 Workflow 的实现方式。首先,我们采用模块化开发的设计理念,将 AI 搜索的核心流程封装为独立的函数。然后,定义一个 Analyzer 分析器,负责对用户的 Query 进行意图分析等操作,并生成一个规划列表,即 analyze_plan_list。这个列表是一个由 Plan 类对象组成的数组,每个 Plan 对应一个具体的执行动作,例如搜索动作或输出动作。
(2) 自动Workflow的实现
为实现这些动作,我们进一步定义了动作类,例如 OutputAction 和 SearchWebAndOutputAction,分别对应直接输出和搜索后输出的行为。最后,我们设计了一个 WorkFlow 类,通过循环遍历 analyze_plan_list 列表,自动执行每个任务,从而实现灵活且高效的 AI 搜索。
这种基于自动 Workflow 的设计方式不仅解决了传统 Workflow 固定流程的弊端,还为未来的功能扩展提供了更多可能性。通过模块化和动态规划的结合,系统可以根据实际需求灵活调整执行步骤,大幅提升效率和适应性。
(3) 代码实现
下面,我们新建一个aisearch_by_auto_workflow.py文件,我们写入如下代码。
python
"""
@File: aisearch_by_auto_workflow.py
@Date: 2024/12/10 10:00
@Desc: 基于自动Workflow的AI搜索实现
"""
import os
import sys
from typing import Any
from wpylib.util.x.xjson import parse_raise
from wpylib.pkg.langchain.model import Model
from wpylib.pkg.langchain.chain import create_chain
from web_search import search_web_tool, MODEL_CONFIG
from wpylib.pkg.langchain.prompt import create_chat_prompt_by_messages
from langchain_core.prompts.chat import SystemMessage, HumanMessage, HumanMessagePromptTemplate
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
model = Model(
model_type=MODEL_CONFIG["model_type"],
model_config=MODEL_CONFIG,
)
class Plan:
"""
规划实体类: 分析器生成的结果封装
"""
_type: str
_desc: str
_query: str
_part: str
def __init__(self, type: str, desc: str, query: str, part: str):
"""
初始化实体
:param type: 动作类型
:param desc: 动作的描述
:param query: 查询词
:param part: 每一部分的输出标题
"""
self._type = type
self._desc = desc
self._query = query
self._part = part
def get_type(self) -> str:
"""
返回_type属性
:return:
"""
return self._type
def get_desc(self) -> str:
"""
返回_desc属性
:return:
"""
return self._desc
def get_query(self) -> str:
"""
返回_query属性
:return:
"""
return self._query
def get_part(self) -> str:
"""
返回_part属性
:return:
"""
return self._part
class Analyzer:
"""
分析器类: 对用户输入的分析
"""
_model: Any
def __init__(self):
# 完成动作类的初始化
self._model = model
def analyze(self, query: str) -> list[Plan]:
"""
开始分析
:param query: 用户输入的查询词
:return:
"""
prompt = create_chat_prompt_by_messages(messages=[
SystemMessage(content="""
# 角色
你是一个对用户提问做分析和深度意图挖掘,并动态给出规划的助手。
## 目标
对用户提问做分析和深度意图挖掘,并动态给出相应的规划。
## 可选择的意图
- method :比如 "如何零基础学习唱歌","如何学习大模型技术","如何自学高等数学"。
- write :比如 "帮我写个短篇小说","给我写篇关于大模型技术的博客","帮我写篇关于春天的自媒体文章"。
- summary :比如 "天空为什么是蓝色的","为什么大模型会出现幻觉"。
- none :无任务意图,比如 "你好啊","请问你是谁啊"。
## 可选择的动作
- 联网搜索并输出: {{"type": "search_web_and_output", "keyword": "the search keyword", "part": "which part does the output belong to"}}
- 仅输出: {{"type": "output", "part": "which part does the output belong to"}}
- 结束: {{"type": "end"}}
## 示例
### 教我零基础学习Python语言
{
"thought": "嗯,你向我询问学习Python编程语言。考虑到你零基础,可能从事非计算机领域。所以,我在回答前,我会先帮你联网搜索并解释编程语言和计算机领域的关系,接着我会联网搜索编程语言的作用。然后我开始正式回答你的问题,开始联网搜索并告诉你Python语言的基础知识和学习方法,再帮你联网搜索和推荐一些相关的学习课程,最后我自己给你一些Python语言的编程案例供你学习使用。",
"plan": [
{"type": "search_web_and_output", "keyword": "编程语言和计算机领域的关系", "part": "编程语言的背景"},
{"type": "search_web_and_output", "keyword": "编程语言的作用", "part": "编程语言的作用"},
{"type": "search_web_and_output", "keyword": "Python语言的基础知识", "part": "基础知识"},
{"type": "search_web_and_output", "keyword": "Python语言的学习方法", "part": "学习方法"},
{"type": "search_web_and_output", "keyword": "Python语学习课程推荐", "part": "课程推荐"},
{"type": "search_web_and_output", "keyword": "Python编程案例", "part": "编程案例"},
{"type": "output", "part": "总结"},
{"type": "end"}
],
"intention": "method"
}
## 要求
1. 如果提问意图为"method",必须按照有顺序、有逻辑条理的方式来解答。
2. 如果提问意图为"summary",则必须在正面回答问题的前提下,自行规划。
"""),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = create_chain(
model=self._model.get_raw_model(),
prompt=prompt,
)
llm_invoke = chain.invoke(input=query)
llm_result = parse_raise(llm_invoke["text"].replace("\n", ""))
print(llm_result)
# 返回结果
plan_list: list[Plan] = []
for item in llm_result["plan"]:
plan_list.append(Plan(
type=item["type"], desc=item.get("desc", ""), query=item.get("keyword", ""), part=item.get("part", "")
))
return plan_list
class OutputAction:
"""
动作类: 仅输出动作的实现
"""
_model: Any
def __init__(self):
# 完成动作类的初始化
self._model = model
def output(self, plan: Plan, search_context: str) -> str:
"""
开始输出
:param plan: 规划实体
:param search_context: 联网搜索结果
:return:
"""
llm_text_generator = self._model.stream(
langchain_input=[
# System消息
SystemMessage(
content="# 角色\n你是一个智能助手 ## 要求\n请基于以下搜索结果,回答用户的问题。\n\n### 搜索结果\n" + search_context
),
# 加入当前用户提问
HumanMessage(plan.get_query())
]
)
# 获取标题部分并打印
header = f"## {plan.get_part()}\n"
# print(header, end="", flush=True)
# 拼接内容并打印
llm_text = header
for item in llm_text_generator:
content = item.content
# print(content, end="", flush=True)
llm_text += content
# 打印换行符并添加到最终文本
footer = "\n"
# print(footer)
llm_text += footer
return llm_text
class SearchWebAndOutputAction:
"""
动作类: 联网搜索且输出动作的实现
"""
_output_action: OutputAction
def __init__(self):
self._output_action = OutputAction()
def search_web_and_output(self, plan: Plan, count: int = 5) -> (str, str):
"""
开始搜索
:param plan: 规划实体
:param count: 联网检索的数量
:return:
"""
search_context = search_web_tool(query=plan.get_query(), count=count)
output = self._output_action.output(plan=plan, search_context=search_context)
return search_context, output
class WorkFlow:
"""
工作流类: 执行分析器生成的规划
"""
_output_action: OutputAction
_search_web_and_output_action: SearchWebAndOutputAction
def __init__(self):
self._output_action = OutputAction()
self._search_web_and_output_action = SearchWebAndOutputAction()
def run(self, plan_list: list[Plan]) -> str:
"""
开始执行
:plan_list: 规划列表
:return:
"""
all_output = ""
all_search_context = ""
for plan in plan_list:
if plan.get_type() == "search_web_and_output":
search_context, output = self._search_web_and_output_action.search_web_and_output(
plan=plan, count=5
)
all_output += output + "\n"
all_search_context += search_context + "\n"
elif plan.get_type() == "output":
output = self._output_action.output(
plan=plan, search_context=all_search_context
)
all_output += output + "\n"
return all_output
# 用户输入
user_ask = "搜索北京今天的天气"
# 意图分析与规划
analyze_plan_list = Analyzer().analyze(query=user_ask)
# 执行工作流
answer = WorkFlow().run(plan_list=analyze_plan_list)
print(f"\n\nAnswer: {answer}")执行后,分析器的生成结果如下所示。可以看到,系统将这个Query分析为如下规划列表(动作列表)。
- 动作为search_web_and_output,搜索关键字为"北京今天天气",输出此部分答案(此部分标题)为"今日天气概况"
- 动作为search_web_and_output,搜索关键字为"北京今日温度湿度",输出此部分答案(此部分标题)为"温度湿度详情"
- 动作为search_web_and_output,搜索关键字为"北京今日穿衣建议",输出此部分答案(此部分标题)为"生活建议"

最后,输出的答案如下所示。

这种实现方式的优劣势如下。
- 优势:有效解决传统 Workflow 中全流程固定带来的扩展性差和难以适应变化的问题,提升系统的灵活性。
- 劣势:相比于简单的 Workflow,设计更复杂,开发和实现成本更高。
总结
本文从简单到复杂,逐步介绍了实现 AI 搜索的四种方法。每种方式都有其独特的优势与局限,开发者可以根据具体需求灵活选择,并在此基础上进行进一步的扩展与优化。