💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
@TOC
基于springboot的快递物流仓库管理系统介绍
本《基于SpringBoot的快递物流仓库管理系统》是一套专为模拟和管理现代快递物流仓储业务而设计的综合性信息管理平台,旨在通过信息化手段实现对快递包裹从揽收到运输完成全生命周期的精细化管控。系统采用当前业界主流且成熟的前后端分离架构进行开发,后端核心技术栈为Java语言结合轻量级、高效率的SpringBoot框架,整合了Spring、SpringMVC与MyBatis,实现了业务逻辑与数据访问的清晰分层;前端界面则基于Vue.js框架,并选用ElementUI组件库进行构建,打造了美观、响应式且用户体验友好的操作界面。整体系统基于B/S架构,通过IDEA或PyCharm作为开发工具,并选用稳定可靠的MySQL关系型数据库作为数据持久化存储方案。在功能层面,系统全面覆盖了快递物流的核心运营环节,构建了一个完整的业务闭环:首先,系统提供了完善的基础数据管理功能,包括对司机信息、快递员信息、客户信息、快递类型以及物流仓库等基础档案的统一维护;其次,核心业务流程模块精确追踪了包裹的每一个动态节点,从"快递揽件"的源头信息录入,到"快递入库"与"快递出库"的仓储作业管理,再到"快递运输"的过程监控,直至"运输完成"的状态确认,确保了物流信息流的完整与准确。此外,系统还特别设计了与人力成本相关的"司机津贴"和"快递员津贴"管理模块,实现了对运营成本的初步核算。最后,系统还配备了基础的"系统管理"与"个人中心"功能,保障了系统的安全与个性化使用,并通过"系统首页"为用户提供了关键业务数据的可视化概览,从而构成了一个功能完备、流程清晰、技术先进的计算机毕业设计项目。
基于springboot的快递物流仓库管理系统演示视频
基于springboot的快递物流仓库管理系统演示图片
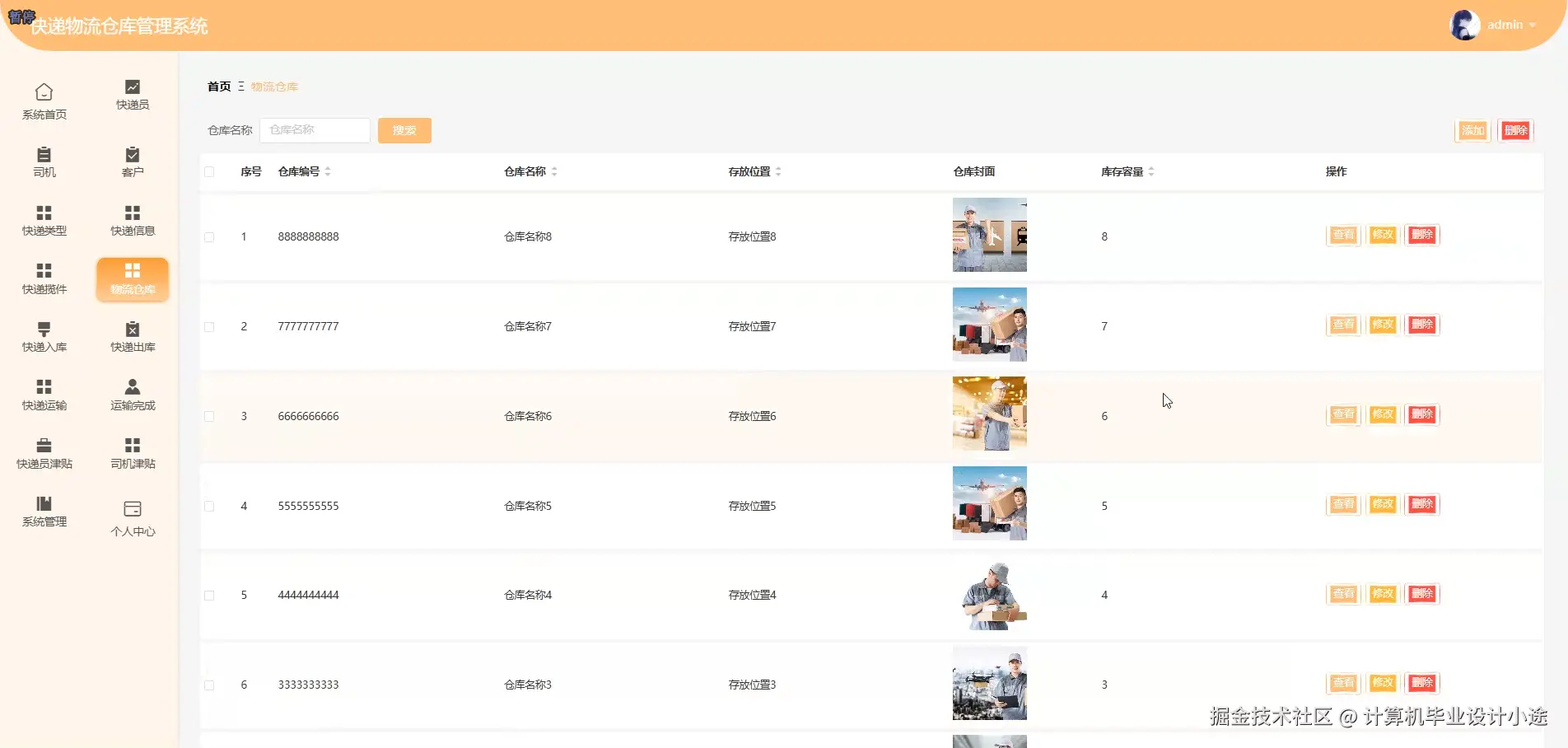

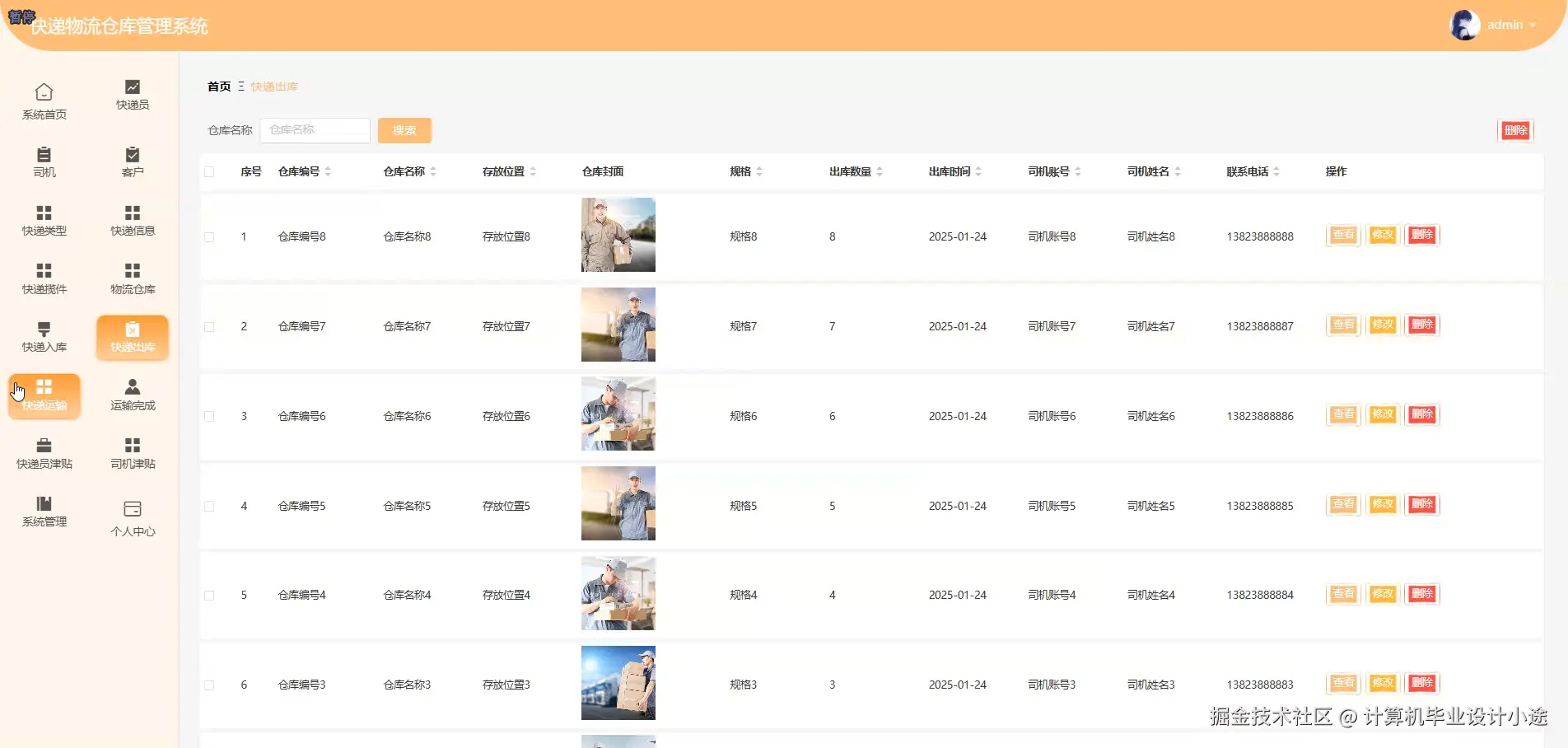
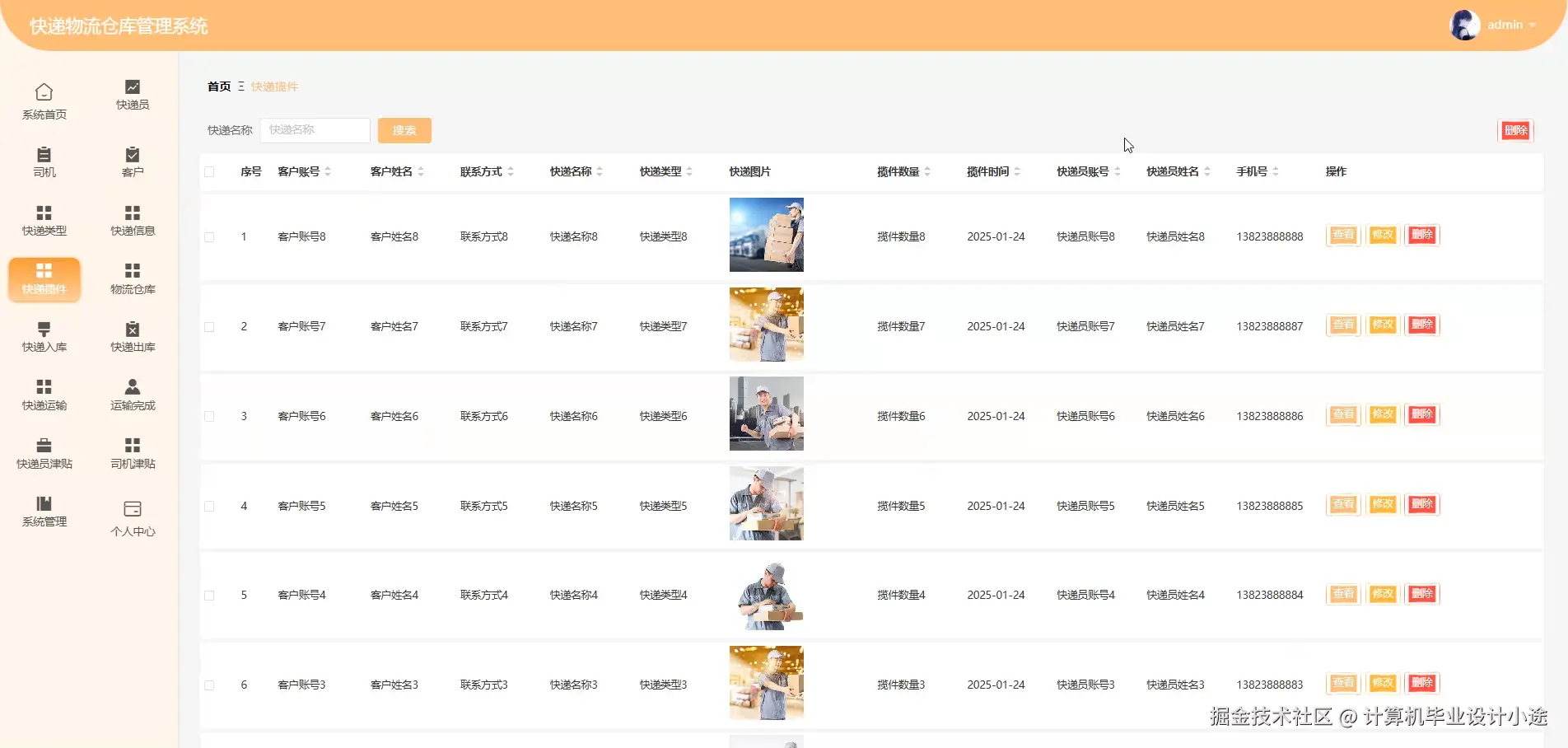
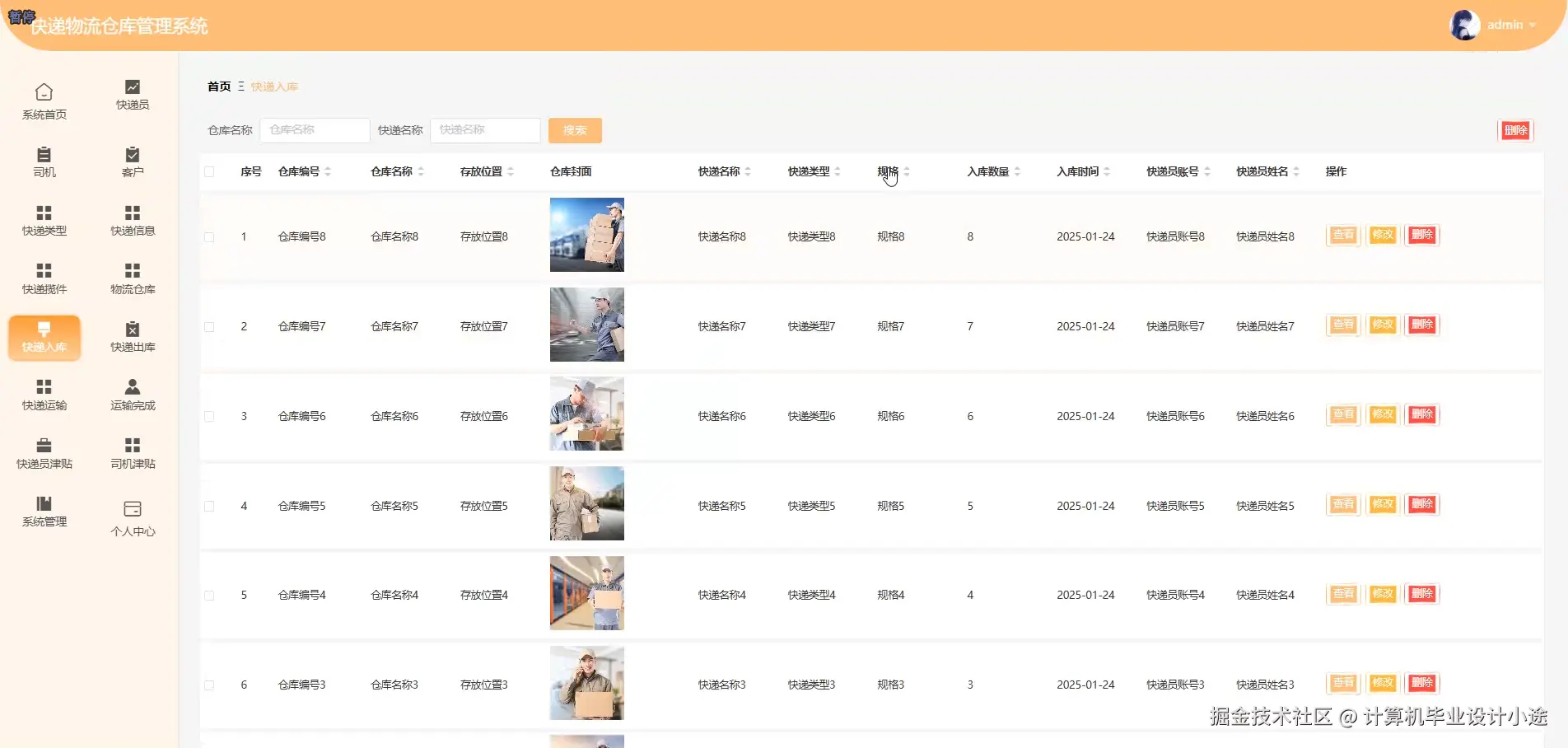
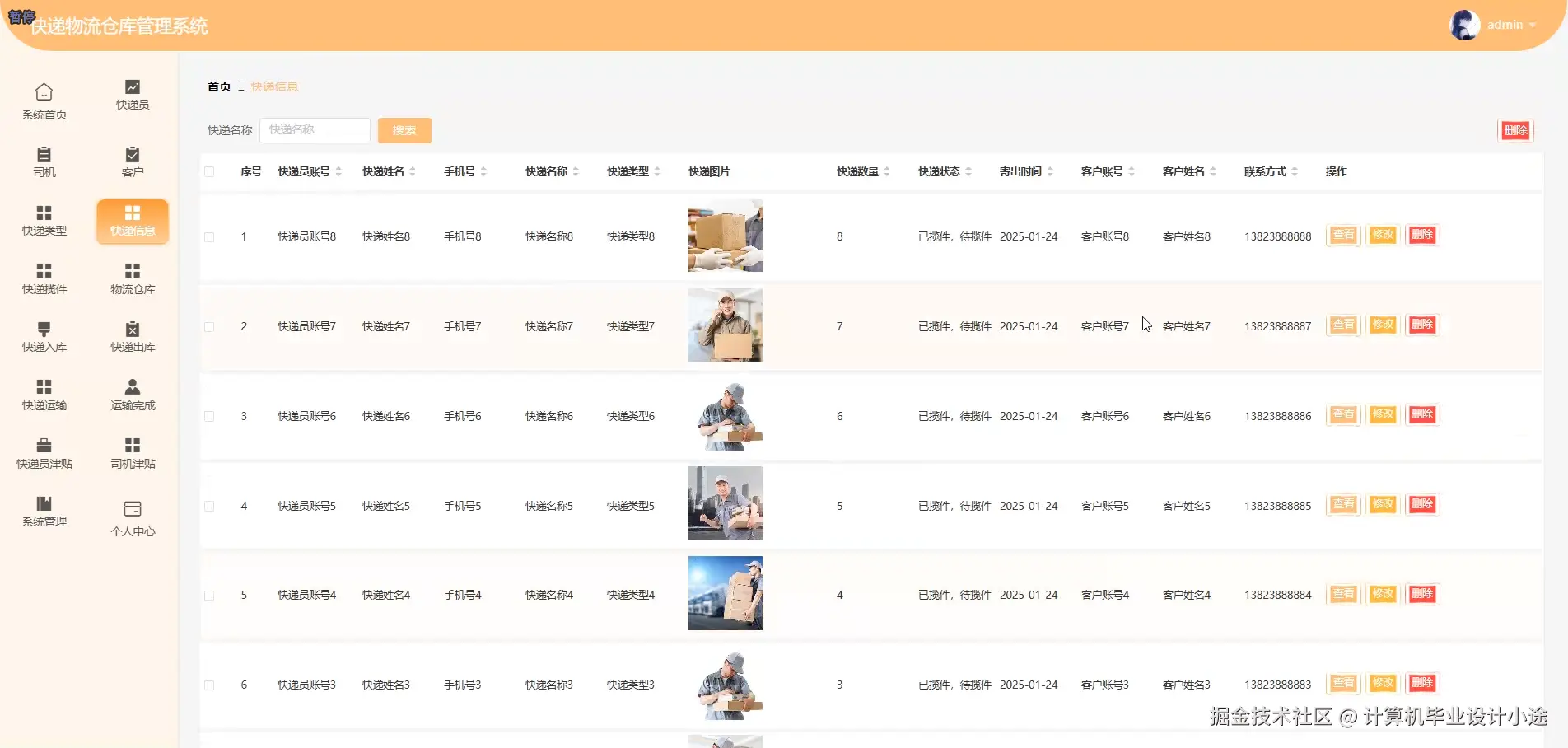
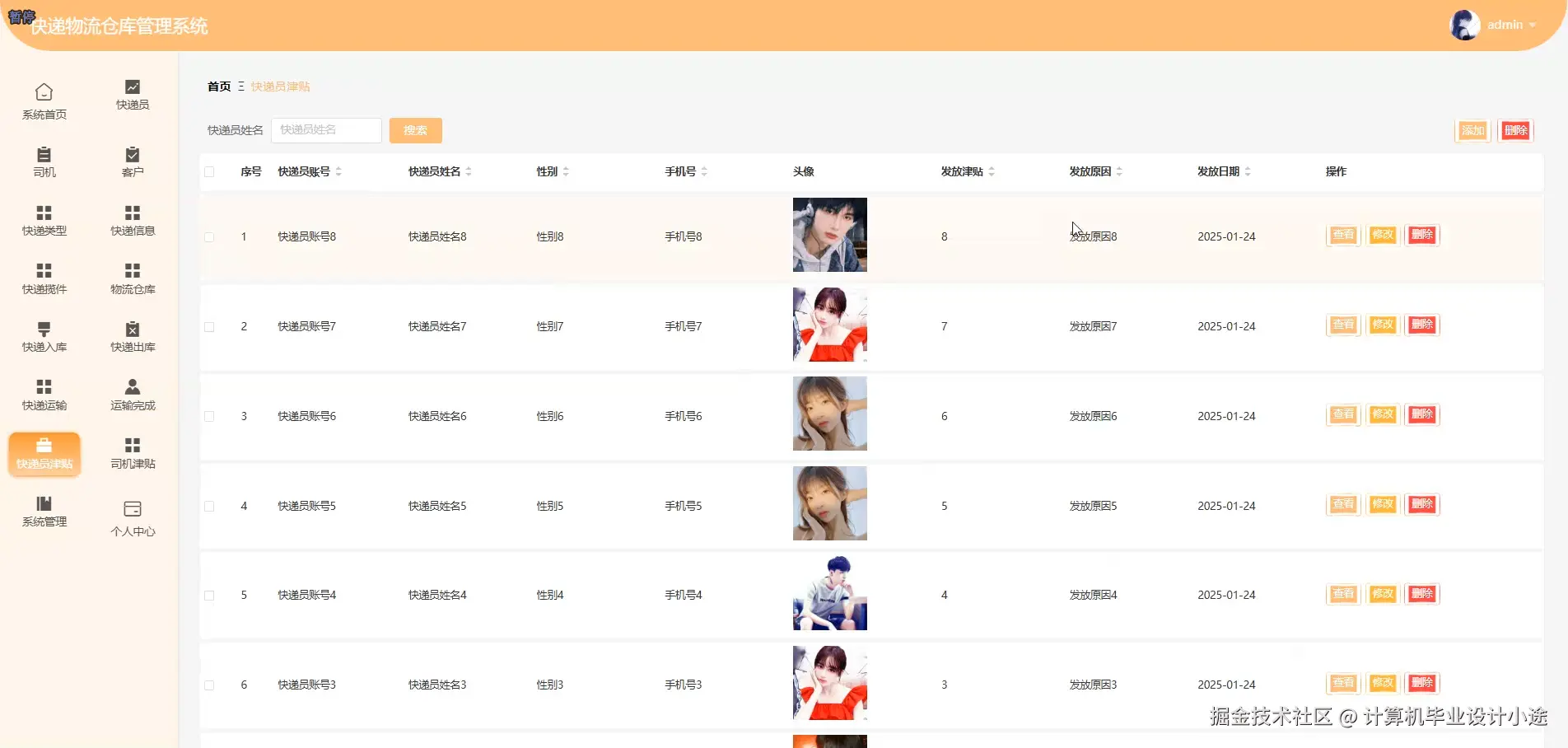
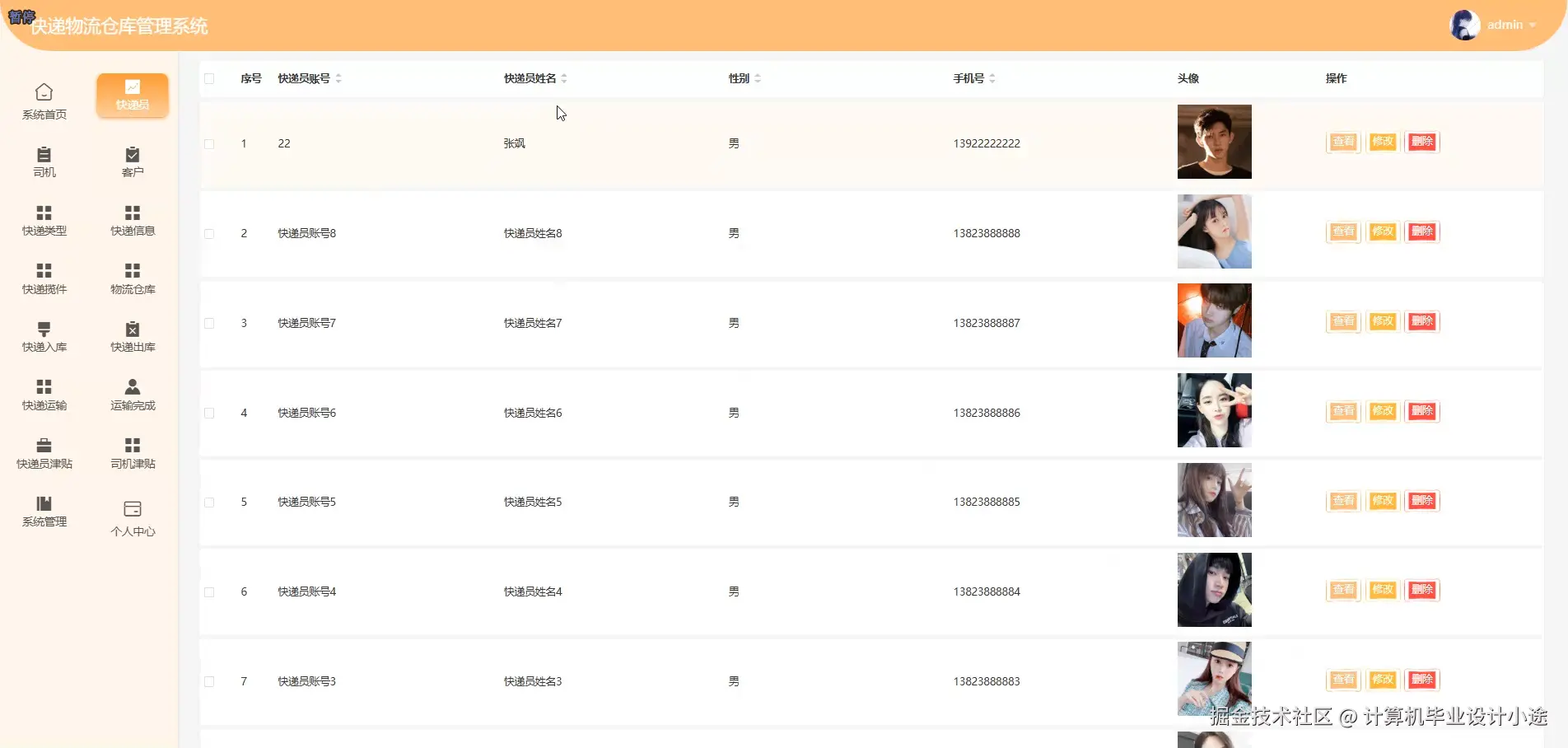

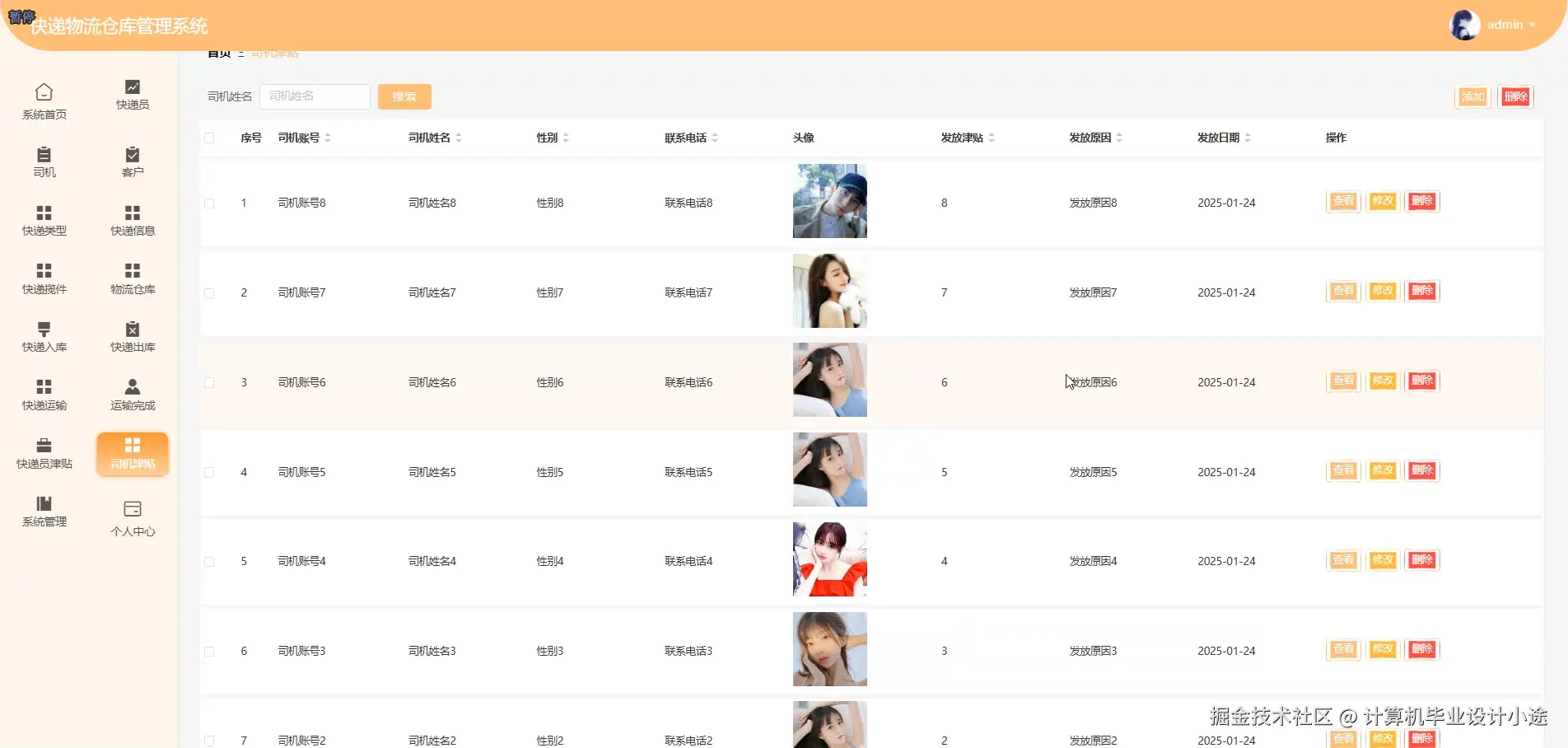
基于springboot的快递物流仓库管理系统代码展示
dart
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, count, avg, lit, round
# 初始化SparkSession,这是所有大数据处理的入口点
spark = SparkSession.builder.appName("StrokeAnalysisSystem").master("local[*]").getOrCreate()
# 模拟从HDFS或数据库加载数据到Spark DataFrame
# 实际项目中,这里会是 spark.read.csv("hdfs://...") 或 spark.read.jdbc(...)
schema = "id INT, gender STRING, age DOUBLE, hypertension INT, heart_disease INT, ever_married STRING, work_type STRING, Residence_type STRING, avg_glucose_level DOUBLE, bmi DOUBLE, smoking_status STRING, stroke INT"
# 此处使用模拟数据代替真实数据加载过程
mock_data = [(51676, "Male", 67.0, 0, 1, "Yes", "Private", "Urban", 228.69, 36.6, "formerly smoked", 1),
(31112, "Male", 80.0, 0, 1, "Yes", "Private", "Rural", 105.92, 32.5, "never smoked", 1),
(60182, "Female", 49.0, 0, 0, "Yes", "Private", "Urban", 171.23, 34.4, "smokes", 1),
(1665, "Female", 79.0, 1, 0, "Yes", "Self-employed", "Rural", 174.12, 24.0, "never smoked", 1),
(58202, "Male", 81.0, 1, 0, "Yes", "Private", "Urban", 186.21, 29.0, "formerly smoked", 1),
(7009, "Female", 50.0, 0, 0, "Yes", "Private", "Urban", 88.5, 27.5, "never smoked", 0),
(47649, "Female", 25.0, 0, 0, "No", "Private", "Rural", 92.5, 22.5, "smokes", 0),
(12175, "Male", 45.0, 0, 0, "Yes", "Govt_job", "Urban", 110.5, 33.5, "never smoked", 0)]
patient_df = spark.createDataFrame(mock_data, schema)
# ======================== 1. 高风险特征组合画像分析核心代码 ========================
def analyze_high_risk_profiles(df, risk_threshold=0.6):
"""
分析高风险特征组合,找出中风概率超过阈值的群体画像。
例如:分析同时患有高血压和心脏病的群体的中风风险。
"""
# 选择关键的二元特征进行组合分析:高血压、心脏病
# 使用 a.alias() 来避免列名冲突,并提高代码可读性
feature_combinations_df = df.groupBy("hypertension", "heart_disease", "smoking_status").agg(
count("*").alias("total_count"),
count(when(col("stroke") == 1, True)).alias("stroke_count")
)
# 计算每个特征组合下的中风风险概率
risk_analysis_df = feature_combinations_df.withColumn(
"stroke_risk_rate", round(col("stroke_count") / col("total_count"), 4)
)
# 筛选出总人数大于一定数量(例如1人以上,避免小样本偏差)且风险率高于设定阈值的组合
high_risk_profiles_df = risk_analysis_df.filter(
(col("total_count") > 1) & (col("stroke_risk_rate") >= risk_threshold)
).orderBy(col("stroke_risk_rate").desc())
# 为了方便前端Echarts等工具使用,将Spark DataFrame转换为JSON格式列表
high_risk_results = high_risk_profiles_df.toJSON().map(lambda j: eval(j)).collect()
# 构造最终返回给前端的数据结构
formatted_results = []
for row in high_risk_results:
profile_desc = f"高血压:{'是' if row['hypertension']==1 else '否'}, 心脏病:{'是' if row['heart_disease']==1 else '否'}, 吸烟:{row['smoking_status']}"
formatted_results.append({
"profile": profile_desc,
"totalCount": row["total_count"],
"strokeCount": row["stroke_count"],
"riskRate": row["stroke_risk_rate"]
})
return formatted_results
# ======================== 2. 多维度交叉与深度钻取分析核心代码 ========================
def analyze_multi_dimensional_cross(df, dimensions, filters=None):
"""
根据前端请求的维度列表进行动态的交叉分析,并支持过滤条件进行钻取。
例如:dimensions=["gender", "work_type"], filters={"Residence_type": "Urban"}
"""
# 应用钻取过滤条件
filtered_df = df
if filters:
for key, value in filters.items():
filtered_df = filtered_df.filter(col(key) == value)
# 检查传入的维度列表是否为空,如果为空则无法分组
if not dimensions:
return {"error": "维度列表不能为空"}
# 使用传入的维度列表进行动态分组聚合
cross_analysis_df = filtered_df.groupBy(*dimensions).agg(
count("*").alias("total_count"),
count(when(col("stroke") == 1, True)).alias("stroke_count")
)
# 增加中风占比列,用于前端图表展示
result_df = cross_analysis_df.withColumn(
"stroke_percentage", round((col("stroke_count") / col("total_count")) * 100, 2)
).orderBy(*dimensions)
# 将最终的分析结果转换为JSON格式,方便API返回
analysis_results_list = result_df.toJSON().map(lambda j: eval(j)).collect()
# 构造返回给前端的完整数据,包括维度信息和数据本身
final_response = {
"dimensions": dimensions,
"filtersApplied": filters if filters else "无",
"analysisData": analysis_results_list,
"totalRecordsAnalyzed": result_df.count()
}
return final_response
# ======================== 3. 中风核心风险因素关联分析核心代码 ========================
def analyze_risk_factor_correlation(df):
"""
分析核心健康指标(数值型变量)与是否中风的关联性。
通过对比中风患者与非中风患者在这些指标上的平均值差异来体现关联度。
"""
# 选择需要进行关联分析的核心数值型指标
numeric_factors = ["age", "avg_glucose_level", "bmi"]
# 构建聚合表达式列表,对每个指标计算平均值
agg_expressions = [avg(col(factor)).alias(f"avg_{factor}") for factor in numeric_factors]
# 按是否中风(stroke=0或1)进行分组,并应用上面的聚合表达式
correlation_df = df.groupBy("stroke").agg(*agg_expressions).orderBy("stroke")
# 清理列名,并对结果进行四舍五入,使其更适合展示
for factor in numeric_factors:
correlation_df = correlation_df.withColumn(
f"avg_{factor}", round(col(f"avg_{factor}"), 2)
)
# 将宽表(多列)转换为长表,这种格式更适合Echarts等图表库进行分组柱状图的渲染
# 例如:(factor, stroke_group, value) -> (age, 0, 55.2), (age, 1, 78.5)
unpivoted_results = []
collected_data = correlation_df.collect()
stroke_group_data = collected_data[1] if len(collected_data) > 1 and collected_data[1]['stroke'] == 1 else None
non_stroke_group_data = collected_data[0] if len(collected_data) > 0 and collected_data[0]['stroke'] == 0 else None
for factor in numeric_factors:
factor_data = {"factorName": factor, "strokeValue": 0, "nonStrokeValue": 0}
if stroke_group_data:
factor_data["strokeValue"] = stroke_group_data[f"avg_{factor}"]
if non_stroke_group_data:
factor_data["nonStrokeValue"] = non_stroke_group_data[f"avg_{factor}"]
unpivoted_results.append(factor_data)
# 返回最终处理好的、适合前端渲染的数据
return unpivoted_results
# 模拟调用这些函数并打印结果
print("--- 高风险特征组合画像分析结果 ---")
print(analyze_high_risk_profiles(patient_df, risk_threshold=0.5))
print("\n--- 多维度交叉与深度钻取分析结果 ---")
print(analyze_multi_dimensional_cross(patient_df, dimensions=["gender", "Residence_type"]))
print("\n--- 中风核心风险因素关联分析结果 ---")
print(analyze_risk_factor_correlation(patient_df))基于springboot的快递物流仓库管理系统文档展示

💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目