文章:Enhancing Vision Transformers for Object Detection via Context-Aware Token Selection and Packing
代码:暂无
单位:暂无
初始评分:6664
🧠 一、问题背景|Why ViT still struggles on Object Detection?
Vision Transformers(ViT)已经在图像分类上表现优异, 但在 **Object Detection(目标检测)**任务中仍存在明显挑战:
| 问题 | 原因 |
|---|---|
| 🧩 Token冗余 | ViT会处理大量不相关区域,注意力低效 |
| 🚫 上下文缺失 | 关键目标可能被错误聚合或压缩 |
| 📉 计算开销大 | Token数量与图片分辨率成正比,限制实际部署 |
| 🔍 无法区分核心区域 | 没有"该关注哪些token"的能力 |
因此,如何让 ViT 更有效聚焦重要目标和上下文, 成为提升目标检测性能的关键突破口。

🚀 二、方法创新|Context-Aware Token Selection & Packing
论文提出了一套专为检测任务设计的增强策略:
核心思想 : 👉 不是处理所有 token,而是选对 token + 合理打包(packing), 👉 让模型把计算资源放在真正"有意义的区域"。
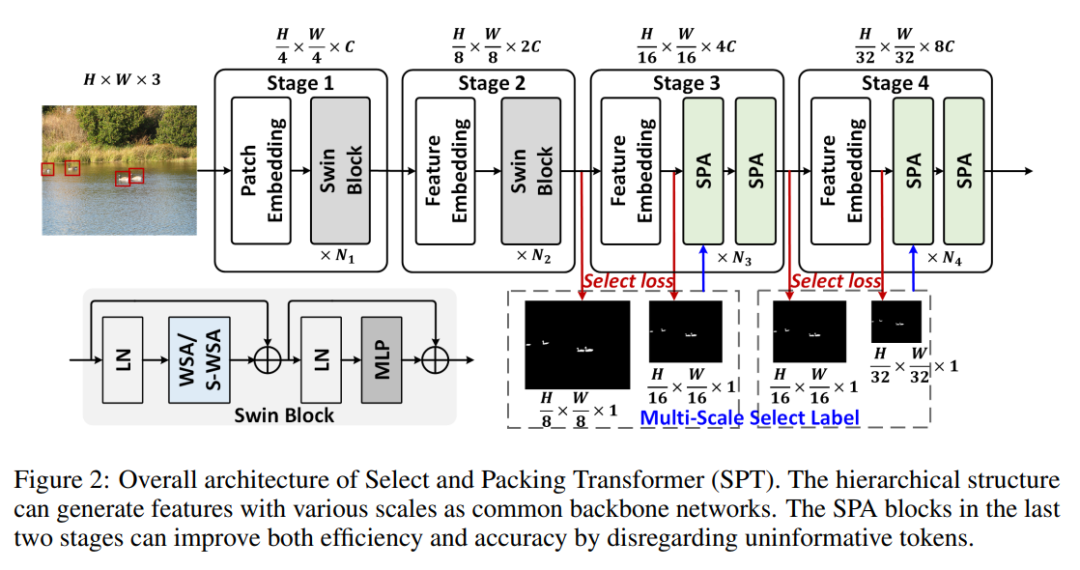
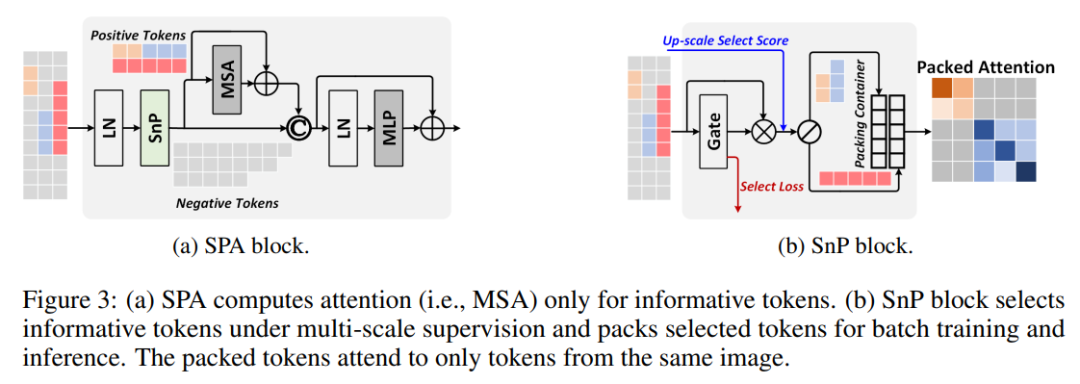
🔍 1️⃣ Token Importance Scoring
-
对每个 token 计算 context-aware score(基于 attention + spatial relevance)
-
选出最具语义贡献的 token
-
弃掉背景/无效区域,提高效率
💡 与传统 token pruning 最大不同➡️ 不是简单"剪枝",而是"理解语义后有选择地保留"。
📦 2️⃣ Token Packing Strategy
选中的重要 token 会被空间重组(Packing) , 形成一种紧凑表征,减少 patch 之间的空洞信息。
效果: ✔ Token 数减少 → 推理更快 ✔ 上下文更清晰 → 检测更准确 ✔ 可接入任意 ViT Backbone(Swin / DeiT / ViT-B)
🔄 3️⃣ End-to-End Integration
这个模块 **可插拔(Plug-and-Play)**可以直接嵌入到主流检测框架中:
| 检测框架 | 兼容性 |
|---|---|
| DETR | ✔ 直接集成 |
| Deformable DETR | ✔ 支持 |
| Cascade Mask R-CNN | ✔ 不需修改 backbone |
| Faster R-CNN | ✔ 可迁移 |
📊 三、实验结果|Object Detection 全面提升
在 COCO 数据集测试中:
| Backbone | Baseline (AP) | +本方法 | 提升 |
|---|---|---|---|
| Swin-T | 38.2 | 41.1 | +2.9 |
| DeiT-S | 36.4 | 39.0 | +2.6 |
| ViT-B | 39.7 | 42.3 | +2.6 |
🔥 **在小目标检测任务上提升最明显(AP⁽small⁾ +4.2)**说明 token selection + packing 更适合 dense detection 场景。
⚖️ 四、优势与局限
🟢 优势
✔ 保留上下文信息,非盲目剪枝
✔ 可插拔结构,适配多种 ViT 检测框架
✔ 显著降低 token 数量,推理更快
✔ 对小目标与复杂背景效果尤佳
🔴 局限
✘ token score 计算引入少量额外开销
✘ 仍依赖标准 attention,未来可加入 frequency/geometry bias
✘ 未扩展到视频检测 / 3D 检测
🧭 一句话总结
这篇论文不是改变 ViT,而是教它**"该看哪里、如何看"** ------ 让目标检测从粗暴卷积,进入 上下文驱动的智能选择时代。