前言:本文使用 Spring-AI-Alibaba 1.0.0-M5.1 版本,Spring-AI-Alibaba 与 Spring AI 完全兼容,无需担心一致性;如您学过 Spring 拦截器 / AOP,了解第三方 API 调用的概念,即可无缝对接本文,没有理解压力;如果已经有一定基础可以直接移步目录中的第四部分,其剖析了 ChatClient 如何封装 ChatModel,以及怎么保证 Advisors 按 Order 升序执行。接下来进入正文。
Spring AI 也是大家老生常谈的新技术了,Advisor、ChatMemory,听着好像很牛;但实际上学起来一点也不难,这期笔者就从 Spring AI 的一段实际调用大模型的代码入手,带诸位完全吃透调用流程。
一、没有 Spring AI 前难道就不能调用 AI 吗?Spring AI 究竟做了什么?
首先要回答,没有 Spring AI 前当然可以调用 AI。但 Spring AI 的价值不是体现在支持 AI 调用上。光说比较抽象,我们可以先看看没有 Spring AI 前的 AI 调用方式。
下面是笔者在 2025 年 2 月时调用火山方舟平台 DeepSeek-R1 的代码,彼时 Spring AI 还未正式推出:
java
String apiKey = "aaa";
ArkService service = ArkService.builder().apiKey(apiKey).build();
List<ChatMessage> messages = new ArrayList<>();
ChatMessage userMessage = ChatMessage.builder()
.role(ChatMessageRole.USER)
.content("常见的十字花科植物有哪些?")
.build();
messages.add(userMessage);
ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder()
.model("ep-20250223163726-4vsvz")
.messages(messages)
.build();
service.createChatCompletion(chatCompletionRequest).getChoices().forEach(
choice -> {
System.out.println(choice.getMessage().getContent());
}
);
// shutdown service after all requests is finished
service.shutdownExecutor();这段代码的逻辑很简单,首先,依赖你在第三方平台创建的 API KEY 构建出一个调用的客户端 ArkService,然后将询问 AI 的问题包装成 ChatMessage 对象,最后构建请求,将消息发送给 AI 平台并等待响应。
这段代码虽然有点复杂,但也不是不能接受啊,为什么还需要 Spring AI 呢?
但是你有没有注意到,有些类的命名好像有点"难受"。ArkService 是啥玩意?还有ChatCompletionRequest,说不定还要查一下 Completion 是什么意思。而这两个类都是 com.volcengine.ark 包下的,也就是这是火山方舟平台独有的、只适配该平台 AI 调用的类,所以命名也是平台唯一的。这会带来什么问题呢?
火山方舟平台是字节旗下的,我们看看阿里的大模型怎么写 AI 调用。以下是阿里云百炼平台的官方示例代码:
java
Generation gen = new Generation();
Message systemMsg = Message.builder()
.role(Role.SYSTEM.getValue())
.content("You are a helpful assistant.")
.build();
Message userMsg = Message.builder()
.role(Role.USER.getValue())
.content("我是wyx,正在写 Spring AI 博客")
.build();
GenerationParam param = GenerationParam.builder()
.apiKey("")
.model("qwen-plus")
.messages(Arrays.asList(systemMsg, userMsg))
.resultFormat(GenerationParam.ResultFormat.MESSAGE)
.build();
return gen.call(param);发现问题了没?同样是调用 AI,阿里的代码和字节的代码,在类的命名,调用的写法上,完全驴唇不对马嘴!ChatMessage 变成了 Message,ArkService 变成了 Generation 。。。
那我现在用的是阿里的模型,如果有一天老板发现字节的模型更便宜,想切换一下模型,那就麻烦了------
++由于不同的平台对 SDK 中类、方法的命名约定互不相同,我们开发者不得不为每个模型都封装一套调用代码++;可能还涉及到重复套用业务逻辑,可复用性几乎为0;稍有不慎,代码框框堆成屎山。
于是,SpringAI 出手了。简单理解的话,它核心其实就做了两件事:
1.提供统一规范,使不同厂商的 AI 调用能复用同一套代码;
2.集成 Spring 生态,如依赖注入等,简化代码编写。
Spring 的规范就厉害了,本来阿里不想和字节统一命名,字节也不想和阿里统一命名,谁也不服谁。但由于 Spring "一手遮天"的用户基础,要想让 Spring 开发者无缝使用他们公司的模型,阿里和字节不得不抛弃爽命名的原则,转而遵守 Spring 的规范,也就是实现 Spring AI 的统一接口,自己编写一套符合 Spring 接口规范的 SDK 供开发者使用;
这样我们只需注入厂商提供给我们的 Spring Bean,就可以同一套代码无缝切换不同大模型调用了,爽爽爽!
而厂商提供给我们的、遵守了 Spring 命名规范(实现接口)的 SDK,还有另外的一个名字 ------ ChatModel。
我们来看下阿里提供的遵守 Spring AI 规范的 ChatModel SDK,怎么调用 AI:
java
@Component
public class SpringAIAlibabaInvoke {
@Resource
private ChatModel dashscopeChatModel;
public void callAI(){
String response = dashscopeChatModel.call("你好,通义千问");
System.out.println(response);
}
}private ChatModel dashscopeChatModel 这一行中,ChatModel 是 Spring AI 提供的规范(接口),dashscopeChatModel 是阿里提供的实现类的 bean 名称;如果要切换到字节的大模型,我们将 dashscopeChatModel 改为字节提供的实现类 bean 名称就可以。
可以看到,不仅类的命名统一为 ChatModel,而且由于依赖注入,逻辑都封装在实现类的 bean 里,调用代码也更简洁了!Spring AI 的优势已经体现出来。
二、ChatModel 接口核心 call 方法全面剖析
接下来,让我们追入源码,理解 ChatModel 的实质。
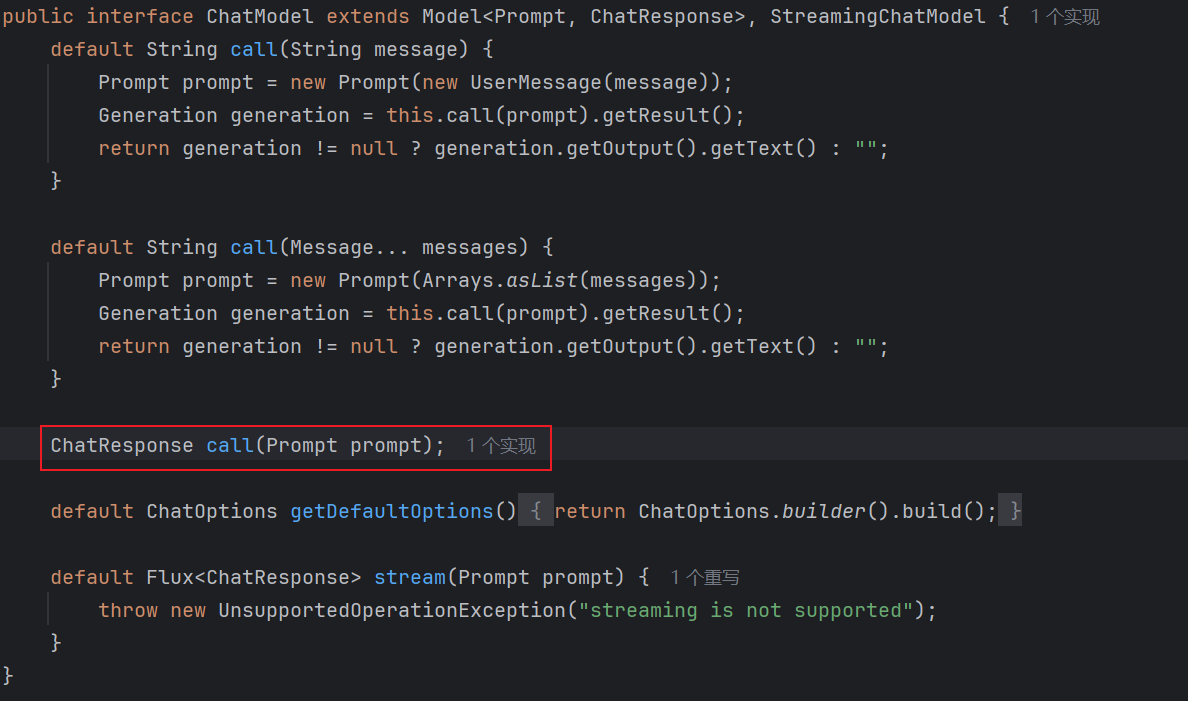
可以看到,ChatModel 就是一个接口!其中除了默认方法外,只定义了一个必须实现的抽象方法,也就是 call,构成了实质上的命名规范 ------ 厂商的 SDK 统一定义为 ChatModel 实现类,调用方法统一重写 call()。
再看默认方法 call(String message) 和 call(Message... messages),无一例外都是依赖了 call(Prompt prompt),我们只需关注 ChatResponse call(Prompt prompt) 这个抽象方法,就能理解整个 ChatModel 接口,从而掌握整个 AI 调用的基本流程。
那么我们接下来就来详细拆解 ChatResponse call(Prompt prompt) 的涉及的每一个类及其参数。
Prompt
首先,我们看下什么是 Prompt?通俗理解来说,Prompt 就是平时我们输入到对话框中并发送给 AI 的文本。细节上,Prompt 还包括对话的一些历史信息。我们可以看下 Spring AI 是怎么定义 Prompt 类的,就可以比较清晰地了解了。
我们追入 Prompt 类,以下为 Prompt 类的截断版本:
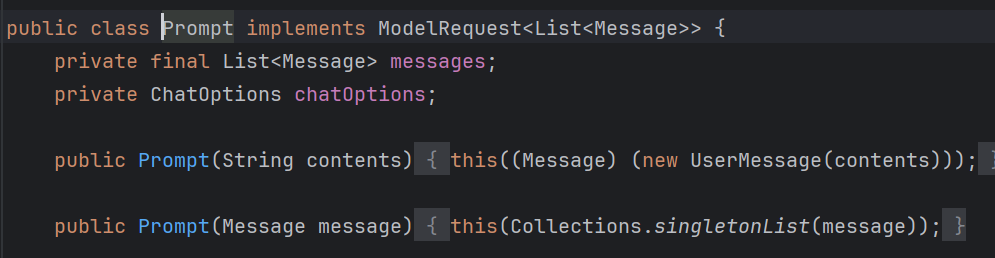
这下更简单了,这源码也没那么难看嘛!
Prompt 类核心就两个字段:List<Message> 和 ChatOptions。我们一步步来看:
List<Message>
Message 也是 Spring AI 定义的接口,代表一条消息;它的核心参数有三个:消息的内容、消息的类型、消息的元信息。我们举个例子:
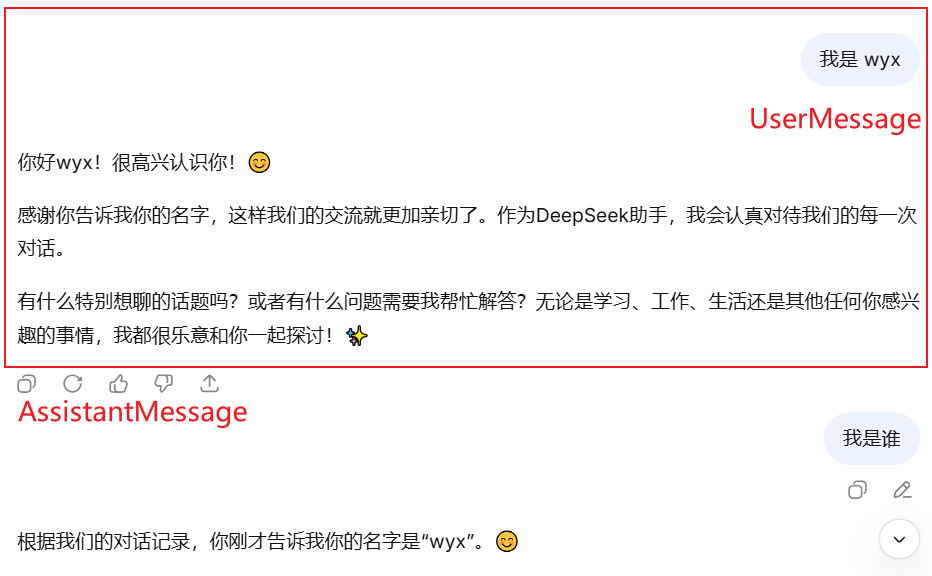
我们将 AI 大模型的一问一答称为一轮对话。拿上面对话中"我是 wyx"这段话举例,这就可以作为一个 Message ;
-
这条 Message 的消息内容是"我是 wyx",消息类型是 User(代表是用户的提问)。
-
而 AI 的回答也是一条 Message,消息内容是"你好wyx",消息类型是 AssistantMessage(代表是 AI 的回答)
这是消息内容和消息类型的概念。
至于消息的元信息,可以理解成我们给消息打上的标签,可以自定义与消息相关的属性,比如用户输入该消息的时间。
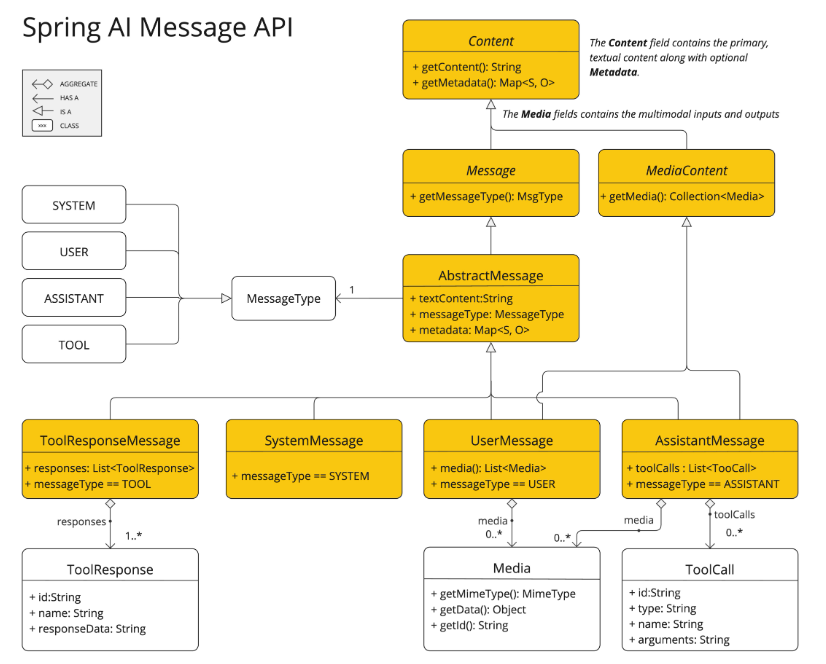
更详细点的话,Message 可以看 Spring AI 官方文档的这张图;我们先不用理解 ToolResponseMessage 是啥,只要知道有这四种消息类型就可以了:------ ToolResponseMessage、SystemMessage、UserMessage、AssistantMessage
说完了 Message,你会不会有疑问,为什么 Prompt 类要设计一个 List<Message> 字段呢?提问不是只需要向 AI 发一个 UserMessage 就可以了么?
这就涉及到一个很重要的概念:大语言模型是无状态的。
我们可以看下官方文档对无状态的定义:

简单来说,无状态就表示,我们调用 ChatModel.call() 的 API 时,对应平台的服务端并不会帮我们保存对话历史,他不记得我们之前问了他什么。
如果我们想关联多轮对话中的历史,比如让 AI 知道"我是wyx",就需要我们将此前的 UserMessage("我是wyx") 和 AssistantMessage("你好,wyx") 添加到当前的chatModel.call(Prompt promt)的 List<Message>中,这样 AI 才知道我们是谁。
这和我们平时在 AI 平台上问 AI 好像是不同的,会有点反直觉,但这也是我们理解 Prompt 构造的核心。
再来看看 Prompt 类的另一个字段 ChatOptions。
ChatOptions
同样是 SpringAI 定义的接口,截取了一部分如下;可以看出, ChatOption 主要就是对这次对话中 AI 响应的一些控制选项,比如模型类型 getModel,最大输出 token 数 getMaxTokens,以及模型的温度 Temperature 等。
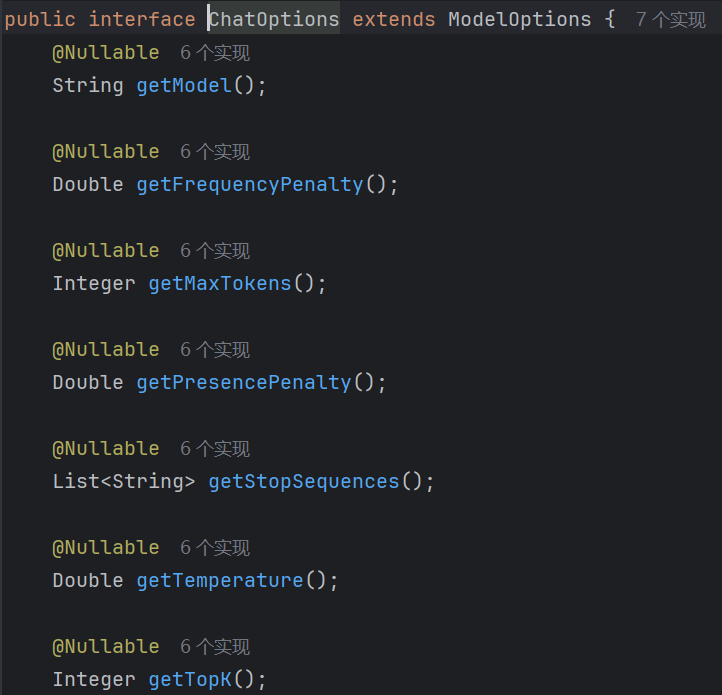
ChatOptions 的更多配置及解释就不一一列举了,具体可以看 SpringAIAlibaba 的中文文档,比去 Spring AI 官网翻译英文更友好:提示词工程模式 | Spring AI Alibaba
概括一下,Spring AI 对于 Prompt 的定义,就是由下面这些内容共同组成的 AI 调用输入:
1.本轮对话中提供给 AI 的所有消息,包括当前用户消息、历史用户消息、AI 的历史回复消息等,作为 List<Message>;
2.本轮对话对 AI 行为的设置,包括选用的模型、最大输出长度、温度,作为 ChatOptions。
ChatResponse
了解完 Prompt,别忘了完整的 API 是 ChatResponse call(Prompt prompt),我们还要看看什么是 ChatResponse。
老样子,我们追入源码:

可以看到,ChatResponse 是一个 class,核心就两个字段------ ChatResponseMetadata,即响应元信息;以及 List<Generation>;
我们依旧一步步剖析:
ChatResponseMetadata
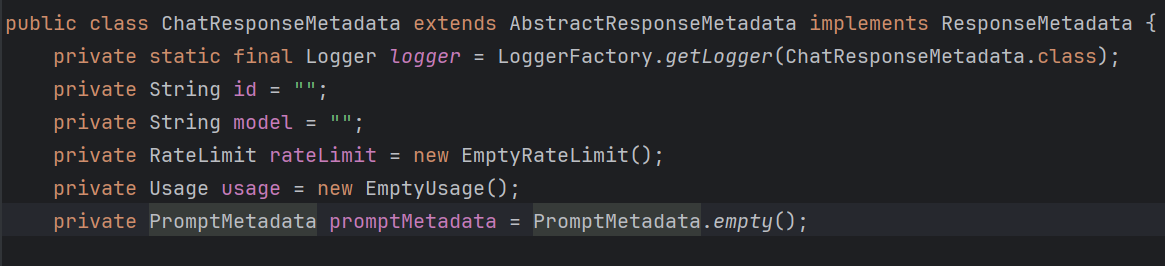
看着信息挺多的,我们可以实际调一轮 AI,然后打印这些数据看看情况,我贴一段自己写的代码如下,启动 SpringBoot 项目即可触发,大家也可以自行测试,所见即所得:
java
@Slf4j
@Component
public class SpringAIAlibabaInvoke implements CommandLineRunner {
@Resource
private ChatModel dashscopeChatModel;
@Override
public void run(String... args) throws Exception {
ChatResponse response = dashscopeChatModel.call(
new Prompt(
"你好,通义千问",
DashScopeChatOptions.builder()
.withTemperature(0.8)
.withModel("qwen-plus")
.build()
)
);
ChatResponseMetadata responseMetadata = response.getMetadata();
Usage usage = responseMetadata.getUsage();
RateLimit limit = responseMetadata.getRateLimit();
log.info("ChatResponseMetadata id = {}",responseMetadata.getId());
log.info("ChatResponseMetadata model = {}",responseMetadata.getModel());
log.info("ChatResponseMetadata Usage 如下:消耗 token {}; 其中,输入 token {}, 输出 token {}",
usage.getTotalTokens(), usage.getPromptTokens(), usage.getGenerationTokens());
log.info("ChatResponseMetadata RateLimit 如下:" +
"RequestsLimit {}, TokensLimit {}, RequestsRemaining {}, TokensRemaining {}",
limit.getRequestsLimit(), limit.getTokensLimit(),
limit.getRequestsRemaining(), limit.getTokensRemaining());
}
}测试下来,有的字段比如 model 和 RateLimit 就直接没有值;比较有用的就是 ChatResponse 类的 Usage 字段,其中记录了我们调用 AI 时输入和输出 token 的数量,可以对调用成本有个比较直接的观测:
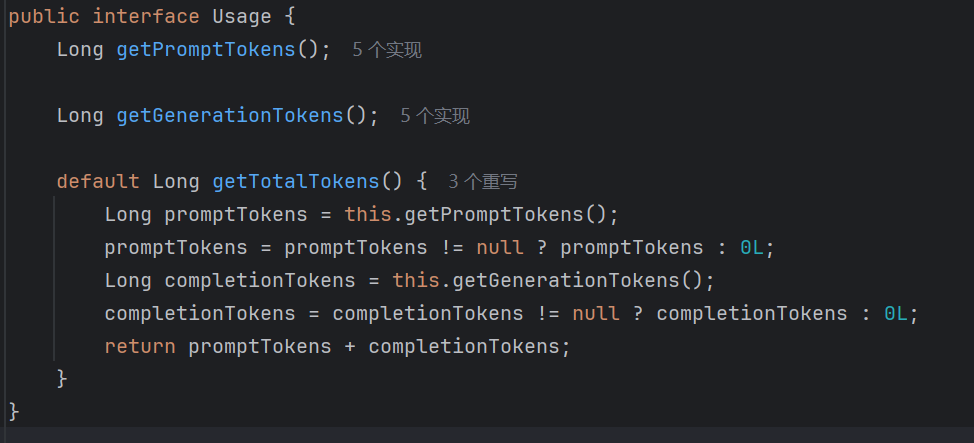
其中,PromptTokens 即输入消耗 token,GenerationTokens 即生成响应(输出)消耗 token。
List<Generation>
这个可能就有点不太好直观理解,一轮对话中,AI 的响应不就是一段文本么,哪来的一个 List?我们看看官方文档怎么说的:

大致意思是,调用一次 AI,有时我们可以配置让 AI 返回多个结果,每个结果就是一个 Generation,多个结果就是 List<Generation>;
但厂商的实际实现上可能不会支持返回多个 Generation;比如我们按照示例代码正常调一次阿里的大模型,返回的 List<Generation>大小就为1,也就是只有单个响应结果。
我们把 List<Generation> 当做 Spring AI 的一个可拓展的设计就可以,可能 OpenAI 会有一定支持,但平时我们就可以理解为单个 Generation。
我们再追入 Generation:

这就比较清晰了,首先是 AI 返回的内容作为 AssistantMessage,其次是单独针对这个 Generation 的元信息;但这个 ChatGenerationMetadata,试下来也没什么很大的用处,就不展开了。
概括一下,Spring AI 对于 ChatResponse 的定义,就是由下面这些内容共同组成的 AI 调用返回:
1.本轮对话中 AI 返回的结果,一般只有一个结果,也就是一条 AssistantMessage;
2.本轮对话 AI 响应的元信息,其中可以看到调用消耗的 token 等数据。
ChatResponse call (Prompt prompt)
总结一下吧:Spring AI 框架中,与 AI 交互的核心就是 ChatModel 接口的 ChatResponse call (Prompt prompt) 方法,它构成了事实上的 AI 调用规范,这就允许开发人员以最小的代码更改在不同模型之间切换。
其中,由于 AI 大模型调用的无状态特性,Prompt 封装了历史上下文以及当前上下文作为 List<Message>,还包括本次对话对 AI 属性的设置 ChatOptions;ChatResponse 封装了响应结果以及响应的元信息,用于可视化 token 的消耗数量。
是不是一目了然了呢?
三、ChatClient 与 ChatModel 的核心区别
深入理解了 ChatModel 接口,其实就可以调用任何一方大模型厂商的 SDK 了;但我们再看官方文档时,发现它还提供了另一个与 AI 交互的客户端 ChatClient,这不是多此一举么?
我们接下来就来讲讲,为什么需要 ChatClient,以及它和 ChatModel 的核心区别。
为什么需要 ChatClient?
其实核心就六个字:简化代码编写。
简单来说,ChatClient 就是一个功能更强大,能迅速集成一些额外功能的客户端,而 ChatModel 是一个更原生、更底层的客户端。++ChatClient 能做的事,其实我们手动编码封装 ChatModel 也能实现。++
但框架的意义,不就是功能复用、简化编码么?所以针对于一些可能会拓展的场景,一般都建议用 ChatClient;但这并不意味着 ChatModel 就白学了,之后讲 ChatClient 本质的时候会提到。我们先来看一段对比:
如果我们需要实现多轮对话记忆这个功能,如果用 ChatModel 实现,那么我们就必须要手动地维护 Prompt 对象的 List<Message>,在每次对话后都 add 一下这轮对话的 UserMessage 和 AssistantMessage;如果要做一个服务端,针对不同用户维护不同的对话记忆,还需要一个 Map<userId, List<Message>>,都需要手写(虽然也不难);
但如果我们用 ChatClient 实现,代码简化为如下所示:
java
@Slf4j
@Component
public class SpringAIAlibabaInvoke implements CommandLineRunner {
@Resource
private ChatModel dashscopeChatModel;
ChatMemory chatMemory = new InMemoryChatMemory();
@Override
public void run(String... args) throws Exception {
ChatClient chatClient = ChatClient.builder(dashscopeChatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
String conversationId = "001";
ChatResponse chatResponse = chatClient.prompt()
.user("我是wyx")
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.call()
.chatResponse();
chatResponse = chatClient.prompt()
.user("我是谁?")
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.call()
.chatResponse();
}
}虽然你可能暂时看不懂 chatClient.prompt 的链式调用是啥,但至少可以看出,已经不需要手动维护 List<Message>了。这就是 ChatClient 在迅速集成功能方面的优势。
与 ChatModel 的核心区别
我们来看下调用 AI 的这一段链式调用代码究竟做了什么:
java
ChatResponse chatResponse = chatClient.prompt()
.user("我是wyx")
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.call()
.chatResponse();首先,既然 chatClient 和 chatModel 调用的返回值都是 ChatResponse,也就是他们调用 AI 的返回值都是一样的;那我们就主要看在调用 AI 前,也就是 .call().chatResponse()代码之前,二者有何区别。
追入 ChatClient 的 prompt() 方法:

可以看到,返回的是一个 ChatClientRequestSpec 类型,我们追入 ChatClientRequestSpec,这是一个接口,我抛弃了一些弃用方法后如下所示:
java
public interface ChatClientRequestSpec {
Builder mutate();
ChatClientRequestSpec advisors(Consumer<AdvisorSpec> consumer);
ChatClientRequestSpec advisors(Advisor... advisors);
ChatClientRequestSpec advisors(List<Advisor> advisors);
ChatClientRequestSpec messages(Message... messages);
ChatClientRequestSpec messages(List<Message> messages);
<T extends ChatOptions> ChatClientRequestSpec options(T options);
ChatClientRequestSpec toolContext(Map<String, Object> toolContext);
ChatClientRequestSpec system(String text);
ChatClientRequestSpec system(Resource textResource, Charset charset);
ChatClientRequestSpec system(Resource text);
ChatClientRequestSpec system(Consumer<PromptSystemSpec> consumer);
ChatClientRequestSpec user(String text);
ChatClientRequestSpec user(Resource text, Charset charset);
ChatClientRequestSpec user(Resource text);
ChatClientRequestSpec user(Consumer<PromptUserSpec> consumer);
CallResponseSpec call();
StreamResponseSpec stream();
}可以看到,所谓 messages,system,user 这些方法,基本上就可以理解为,和 Prompt 构造 List<Message> 是一模一样的,就是将不同类型的 Message 以链式调用的形式塞到输入中;但不同的地方就在于 advisors。
由此,我们发现了两者的核心区别:ChatClient 支持 advisors 。
因此相比 ChatModel 能迅速集成一些通用功能,简化编码。
那 advisors 是啥呢?
Advisor 简介
这里官方文档对 Advisor 的概念解释很清晰,我们直接引用官方文档的话来回答,Advisor 是什么:

大家如果学过 Spring AOP 或 Spring 拦截器,就知道在实际调用方法前,我们可以通过拦截器或 AOP 对方法进行一些通用的功能增强;
Advisor 其实也是一样的思想,核心就是:
-
在调用 AI 前,对调用请求做一些额外处理后再调用 AI;
-
在 AI 响应后,对响应结果做一些额外处理。
那么我们就知道为什么 ChatClient 能够迅速集成类似多轮对话记忆的功能了。
++因为类似多轮对话记忆的功能,本质就是在 AI 调用前后做一些额外处理++;比如多轮对话记忆就是在调用 AI 后把这一轮对话加入 List<Message>,在下一次调用 AI 前把历史的 List<Message> 附带到本次的 Prompt 中。
也就是说,这些功能都可以视作 Advisor;因此这些功能都可以被 ChatClient 迅速集成。
我们接下来看下 Advisor 的源码,对他的功能的理解会更清晰:
java
package org.springframework.ai.chat.client.advisor.api;
public interface Advisor extends Ordered {
int DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER = -2147482648;
String getName();
}可以看到 Advisor 也是 SpringAI 提供的接口,但其中的方法就一个 getName;那我们看下 Advisor 的子类:

可以看到,有 CallAroundAdvisor 和 StreamAroundAdvisor 两个子接口,分别代表普通调用和流式调用(普通调用就是一次性输出,流式调用就是一点点输出)
而其中 AroundCall 方法命名就很亲切,Spring AOP 的 @Around 环绕通知不就是 around 吗!所以 aroundCall 的含义也很明确,实际上就是在调用 AI (call)的前后包了一层前置处理和后置处理。
我们看看官方提供的 Advisor 工作流程图:
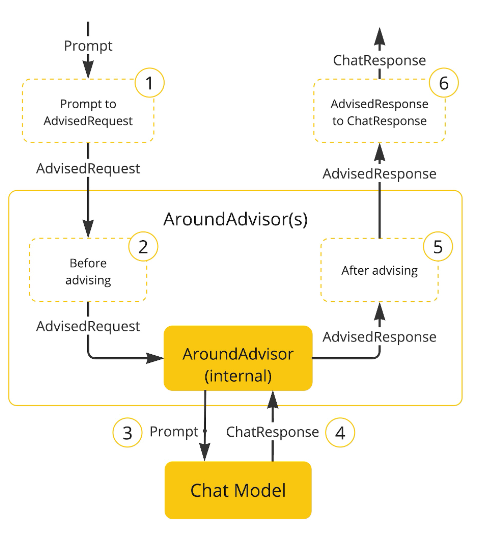
其中黄色方框圈起来的就是 Advisor 的工作,在 AI 调用请求 AdvisedRequest 前做一些处理,在 AI 调用响应 AdvisedResponse 后做一些处理。
ChatClient 的实质:对 ChatModel 的封装
其实,如果大家比较细心的话,从 ChatClient 的构造函数和上面的流程图中都可以看出端倪:
java
ChatClient chatClient = ChatClient.builder(dashscopeChatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();ChatClient 的构造依赖于 chatModel(这里是 dashscopeChatModel ),那么是否可以理解为,ChatClient 就是封装了 ChatModel 呢?
答案是肯定的。从 Advisor 工作流程图也能看出,在对 AI 调用请求进行前置处理后,步骤 3 会将 Prompt 传输给 ChatModel,最后步骤4中, ChatModel 返回 ChatResponse,然后进行 Advisor 后置处理。
一切都变的清晰起来。我总结一下:
ChatClient 和 ChatModel 的区别就是 ChatClient 支持 Advisor;
ChatClient 的实质就是封装 ChatModel 的 call 方法,并在 call 方法调用前后,用 Advisor 进行前置、后置处理,以达到迅速集成、功能增强的目的。
四、从源码入手,分析 ChatClient 如何封装 ChatModel,以及其如何支持 Advisor
虽然上面的流程图已经证明了 ChatClient 是对 ChatModel 的封装,但你可能不服气,说:"我不信,除非 show me the code"。
好,那我们就来 show the code。
java
ChatResponse chatResponse = chatClient.prompt()
.user("我是wyx")
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.call()
.chatResponse();我们就来看这段代码,最终是怎么调用的 ChatModel。
首先,我们在上文的分析中已经知道 chatClient.prompt 调用会返回一个 ChatClientRequestSpec 对象;

追入 ChatClientRequestSpec 类我们发现,这是 ChatClient 的一个内部类(或者说内部接口),简写为如下所示:
java
public interface ChatClient {
...
public interface ChatClientRequestSpec {
ChatClientRequestSpec advisors(Advisor... advisors);
ChatClientRequestSpec system(String text);
ChatClientRequestSpec user(String text);
CallResponseSpec call();
StreamResponseSpec stream();
}
...
}我们发现,chatClient.prompt() 后的所有链式调用,包括 .user(),.advisors(),全部都是基于 ChatClientRequestSpec 接口的方法,返回值也是 ChatClientRequestSpec,所以能支持链式;
直到最后调用 call() 的时候返回 CallResponseSpec,才算 ChatClientRequestSpec 链式调用的终止;那我们就看下 ChatClientRequestSpec 接口的实现类,就能明白这些链式调用都干了什么。
ChatClient 链式调用的核心:DefaultChatClientRequestSpec 及其构造器
下面是 实现类 DefaultChatClientRequestSpec 的源码,我做了大量省略,省略的部分打上了 ... ;
我们只关注最重要的一部分,就是 chatClient.prompt() 调用中,返回的是 new DefaultChatClientRequestSpec(),这个 DefaultChatClientRequestSpec 的构造器中有没有什么玄机。
java
public static class DefaultChatClientRequestSpec implements ChatClient.ChatClientRequestSpec {
...
private final ChatModel chatModel;
...
private final List<Advisor> advisors;
...
private final DefaultAroundAdvisorChain.Builder aroundAdvisorChainBuilder;
...
DefaultChatClientRequestSpec(DefaultChatClientRequestSpec ccr) {
this(ccr.chatModel, ccr.userText, ccr.userParams, ccr.systemText, ccr.systemParams, ccr.functionCallbacks, ccr.messages, ccr.functionNames, ccr.media, ccr.chatOptions, ccr.advisors, ccr.advisorParams, ccr.observationRegistry, ccr.customObservationConvention, ccr.toolContext);
}
public DefaultChatClientRequestSpec(final ChatModel chatModel, @Nullable String userText, Map<String, Object> userParams, @Nullable String systemText, Map<String, Object> systemParams, List<FunctionCallback> functionCallbacks, List<Message> messages, List<String> functionNames, List<Media> media, @Nullable ChatOptions chatOptions, List<Advisor> advisors, Map<String, Object> advisorParams, ObservationRegistry observationRegistry, @Nullable ChatClientObservationConvention customObservationConvention, Map<String, Object> toolContext) {
...
this.advisors = new ArrayList();
...
this.chatModel = chatModel;
...
this.advisors.add(new CallAroundAdvisor() {
public String getName() {
return CallAroundAdvisor.class.getSimpleName();
}
public int getOrder() {
return Integer.MAX_VALUE;
}
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
return new AdvisedResponse(chatModel.call(advisedRequest.toPrompt()), Collections.unmodifiableMap(advisedRequest.adviseContext()));
}
});
this.advisors.add(new StreamAroundAdvisor() {
public String getName() {
return StreamAroundAdvisor.class.getSimpleName();
}
public int getOrder() {
return Integer.MAX_VALUE;
}
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
return chatModel.stream(advisedRequest.toPrompt()).map((chatResponse) -> new AdvisedResponse(chatResponse, Collections.unmodifiableMap(advisedRequest.adviseContext()))).publishOn(Schedulers.boundedElastic());
}
});
this.aroundAdvisorChainBuilder = DefaultAroundAdvisorChain.builder(observationRegistry).pushAll(this.advisors);
}大家看我唯一完全保留的部分就能明白了------
ChatClient 封装 ChatModel 的核心,首先是基于 DefaultChatClientRequestSpec 进行链式调用,且在构造 DefaultChatClientRequestSpec 时,往 List<Advisor>,即 Advisor 调用链中,加入了两个 Advisor 的匿名实现类!


这两个实现类,一个是用于 chatModel 一次性返回AI 响应,一个是用于 chatModel 流式返回响应。拿 CallAroundAdvisor 的匿名实现类来说,可以看到,在 aroundCall 方法里,首先就调用 chatModel.call() !然后将返回值包装为 AdvisedResponse。
而且存在多个 Advisor 时,Advisor 的 getOrder 返回值决定了 Advisor 的执行顺序,order 值越大越靠后执行;而你可以看到,这两个 Advisor 匿名实现类的 Order 都是 Integer.MAX_VALUE;++也就是说,无论你向 ChatClient 调用添加多少个 Advisor,最后都是这两个匿名实现类最后执行!++
如果你选择一次性返回的 call 调用,就是 CallAroundAdvisor 的匿名实现类最后执行,StreamAroundAdvisor 没作用、不执行;如果你选择流式返回的 stream 调用,就反过来。
最后我们得出,ChatClient 实际上就是按 Order 大小顺序执行一个 List<Advisor>,并在必然最后执行的、上文提到的匿名 Advisor 中,调用 ChatModel.call!
我们再回看那个流程图,把 图中的 AroundAdvisor 看成最后执行的匿名实现类,一切都如此清晰。

ChatClient 链式调用为什么能按照 Advisor 的 order 升序执行?
作为补充,我们看看 Advisor 调用链如何构造,以及 ChatClient 链式调用为什么能按照 Advisor 的 order 升序执行。
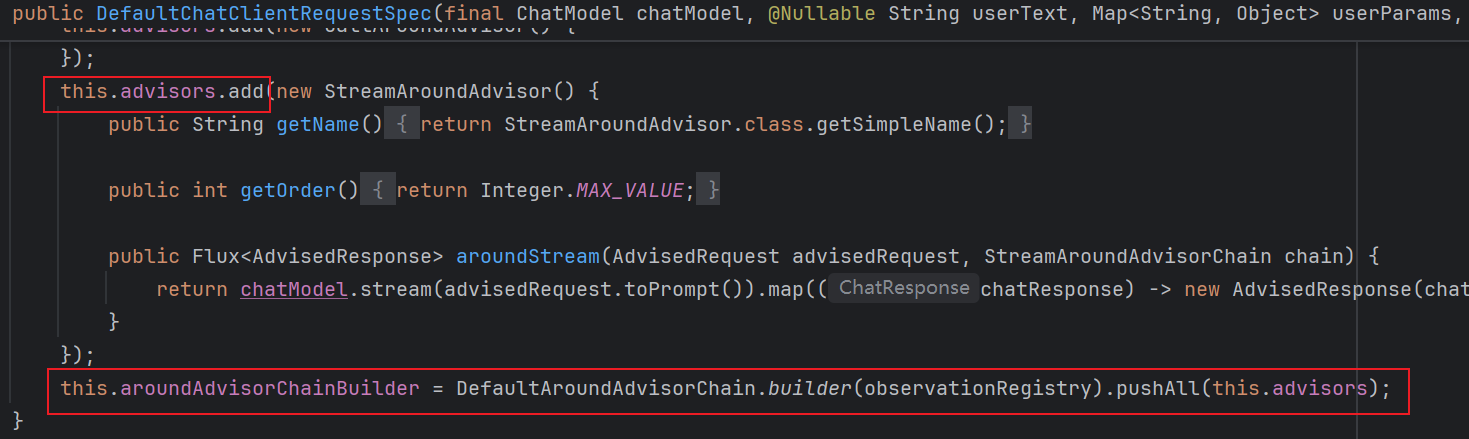
从上图可以看出,DefaultChatClientRequestSpec 构造器中的两个 Advisor 匿名实现类都被 add 到了 this.advisors(一个 List<Advisor>) 中,同时DefaultAroundAdvisorChain.builder(observationRegistry) 这段代码返回一个对象,我简写为 xxChain.Builder,然后这两个 Advisor 也被 pushAll 到了这个 xxChain.Builder 中
而 xxChain.Builder 的 pushAll 方法实际上是添加 Advisor 到一个 Deque<Advisor> 的队列,然后调用 this.reOrder(),按各个 Advisor 的 order 对它们进行重排序,确保 Deque 中的 Advisor 按 order 升序排列;
java
public class DefaultAroundAdvisorChain implements CallAroundAdvisorChain, StreamAroundAdvisorChain {
public static class Builder {
private final ObservationRegistry observationRegistry;
private final Deque<CallAroundAdvisor> callAroundAdvisors;
private final Deque<StreamAroundAdvisor> streamAroundAdvisors;
...
public Builder pushAll(List<? extends Advisor> advisors) {
Assert.notNull(advisors, "the advisors must be non-null");
if (!CollectionUtils.isEmpty(advisors)) {
List<CallAroundAdvisor> callAroundAdvisorList = advisors.stream().filter((a) -> a instanceof CallAroundAdvisor).map((a) -> (CallAroundAdvisor)a).toList();
if (!CollectionUtils.isEmpty(callAroundAdvisorList)) {
Deque var10001 = this.callAroundAdvisors;
Objects.requireNonNull(var10001);
// !!! 注意这行代码,将 advisor 添加到 builder 的 Deque 字段中
callAroundAdvisorList.forEach(var10001::push);
}
List<StreamAroundAdvisor> streamAroundAdvisorList = advisors.stream().filter((a) -> a instanceof StreamAroundAdvisor).map((a) -> (StreamAroundAdvisor)a).toList();
if (!CollectionUtils.isEmpty(streamAroundAdvisorList)) {
Deque var4 = this.streamAroundAdvisors;
Objects.requireNonNull(var4);
streamAroundAdvisorList.forEach(var4::push);
}
this.reOrder();
}
return this;
}
...
}
}而除了这两个 Advisor 匿名实现类,我们自己在 chatClient 链式调用中添加的 Advisor 也会被 pushAll 到上面说的 xxChain.Builder 的 Deque 中,并再次按 order 进行排序;
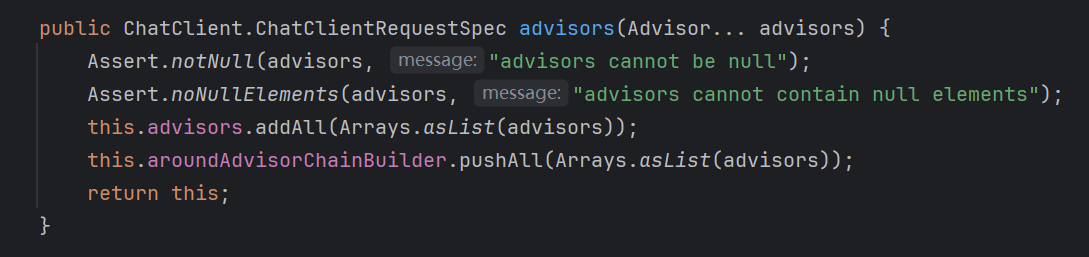
链式调用的最后,.chatResponse() 方法内部调用 doGetChatResponse(),最后实质是调用 xxChain.Builder.build().nextAroundCall();
其中,xxChain.Builder.build() 返回一个 DefaultAroundAdvisorChain 对象,我们称为 xxChain 对象;这个 xxChain 对象也有两个 Deque<Advisor> 字段,内容和 xxChain.Builer 的 Deque 完全相同;



也就是说,链式调用最后的 .chatResponse(), 实际上是调用 xxChain.Builder.build() 得到 xxChain 对象,再调用 xxChain 对象的 nextAroundCall 方法;
DefaultAroundAdvisorChain nextAroundCall 方法
我们关注这个 xxChain 的 nextAroundCall 方法,源码如下所示:
java
public class DefaultAroundAdvisorChain implements CallAroundAdvisorChain, StreamAroundAdvisorChain {
public AdvisedResponse nextAroundCall(AdvisedRequest advisedRequest) {
if (this.callAroundAdvisors.isEmpty()) {
throw new IllegalStateException("No AroundAdvisor available to execute");
} else {
CallAroundAdvisor advisor = (CallAroundAdvisor)this.callAroundAdvisors.pop();
AdvisorObservationContext observationContext = AdvisorObservationContext.builder().advisorName(advisor.getName()).advisorType(Type.AROUND).advisedRequest(advisedRequest).advisorRequestContext(advisedRequest.adviseContext()).order(advisor.getOrder()).build();
return (AdvisedResponse)AdvisorObservationDocumentation.AI_ADVISOR.observation((ObservationConvention)null, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext, this.observationRegistry).observe(() -> advisor.aroundCall(advisedRequest, this));
}
}
}在这个 nextAroundCall 方法中,关注 this.callAroundAdvisors.pop():
这就代表从 xxChain 的 Deque 中取出第一个 Advisor;而且,该方法在 return 的那一行调用了advisor.aroundCall(advisedRequest, this),实现了第一个 Advisor 的执行;
第一个 Advisor 的执行过程中,在 Advisor 前置处理完毕、后置处理之前会调用 chain.nextAroundCall,这对任何一个 Advisor 都是如此。我们拿 BaseAdvisor 举例;
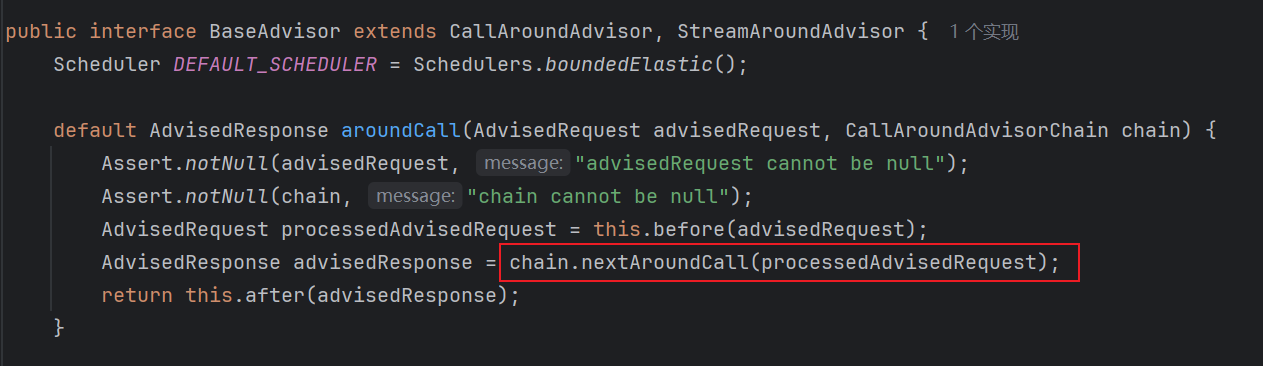
而 chain.nextAroundCall() 的调用,也就是回到上述的 xxChain.nextAroundCall() 方法,再 pop 出第二个 Advisor 并执行...
java
public class DefaultAroundAdvisorChain implements CallAroundAdvisorChain, StreamAroundAdvisorChain {
public AdvisedResponse nextAroundCall(AdvisedRequest advisedRequest) {
if (this.callAroundAdvisors.isEmpty()) {
throw new IllegalStateException("No AroundAdvisor available to execute");
} else {
CallAroundAdvisor advisor = (CallAroundAdvisor)this.callAroundAdvisors.pop();
AdvisorObservationContext observationContext = AdvisorObservationContext.builder().advisorName(advisor.getName()).advisorType(Type.AROUND).advisedRequest(advisedRequest).advisorRequestContext(advisedRequest.adviseContext()).order(advisor.getOrder()).build();
return (AdvisedResponse)AdvisorObservationDocumentation.AI_ADVISOR.observation((ObservationConvention)null, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext, this.observationRegistry).observe(() -> advisor.aroundCall(advisedRequest, this));
}
}
}由此递归到最后一个 Advisor,也就是上面提到的匿名实现类,然后调用 ChatModel。
总结
由此,ChatClient 调用全流程我们已经了然于胸,总结一下吧:
-
chatClient.prompt() 返回 DefaultChatClientRequestSpec,直到获取响应前,.prompt() 后的链式调用都基于这个类;
-
DefaultChatClientRequestSpec 有一个字段 xxChain.Builder,我们在链式调用 .advisor(Advisor myAdvisor) 时,会将 myAdvisor push 到这个 xxChain.Builder 中;同时,在创建 DefaultChatClientRequestSpec 时,也会 push 两个匿名 Advisor 到 xxChain.Builder 中;
-
xxChain.Builder 用一个 Deque 存储添加的 Advisor,且每次添加 Advisor 都会重新根据 Order 对他们排序,确保 Deque 中的 Advisor 始终按 order 升序排序;
-
链式调用的终结,即 .chatResponse() 方法,最终会递归执行 xxChain.nextAroundCall(),达到的效果是将 Deque 中的 Advisor 一个个执行,这也实质上达到了多个 Advisor 按 order 升序执行的效果;
-
最后一个 Advisor 就是第二步提到的匿名 Advisor,它的 order 为 Integer.MAX_VALUE ,确保其一定在最后执行;它的 aroundCall 方法就是封装 ChatModel 的调用;ChatClient 的 Advisor 链到此结束前半部分,开始后置处理。
-
后半部分实际上是递归的 return 过程,依次进行后置处理,最后拿到最终的 ChatResponse。
这次又码了不少字,希望对大家有所帮助!