插值
什么是插值
为什么要进行插值
插值大概都有啥方法
插值是覆盖掉原来的数值还是加入新的数值?
图像放大是图像处理中的一个特别基础的操作。在几乎每一个图片相关的项目中,从传统图像处理到深度学习,都有应用。从图片发出到朋友收到图片,查看图片,都会数次地改变图像地尺寸,从而用到这个算法
插值指的是利用已知的点来猜未知的点,图像领域插值常用在修改图像尺寸的过程,由旧的图像矩阵中的点计算新图像矩阵中的点并插入,不同的计算过程就是不同的插值算法
下图是自己实现双线性插值的效果:

常用的插值算法:
最近邻法:计算速度最快,但是效果最差
双线性插值 bilinear interpolation:双线性插值是用原图像中4(2*2)个点计算新图像中1个点,效果略差于双三次插值,速度比双三次插值快,在很多框架中属于默认算法
双三次插值 bicubic interpolation 双三次插值是用原图像中的16(4*4)个点计算新图像中1个点,效果好但是计算代价大
最近邻法:
最近邻法实际上是不需要计算新图像矩阵中的点的数值的,直接找到原图像中对应的点,将数值赋值给新图像矩阵中的点,根据对应关系找到原图像中的对应的坐标,这个坐标可能不是整数,这时候找最近的点进行插值
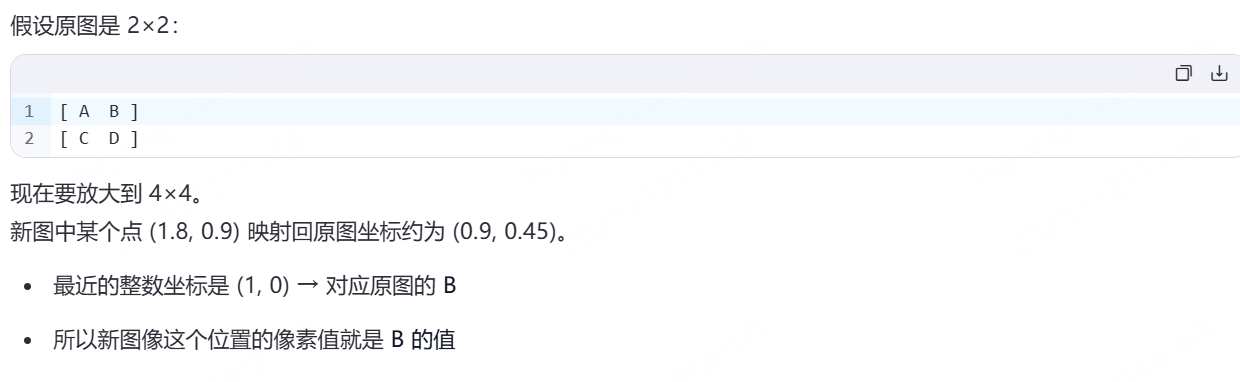
别管这个截图中的新图中的某个点了,肯定是整数,但是在原图中,要根据变换的方式去映射,映射到的位置可能是小数
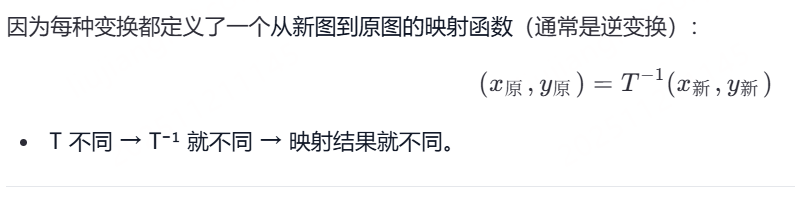
变换方式决定映射关系,映射关系决定原图采样位置 所以既然这样的话哦我就不去举例子计算对应关系了
双线性插值就不是找最近的那个点,而是找最近的四个点
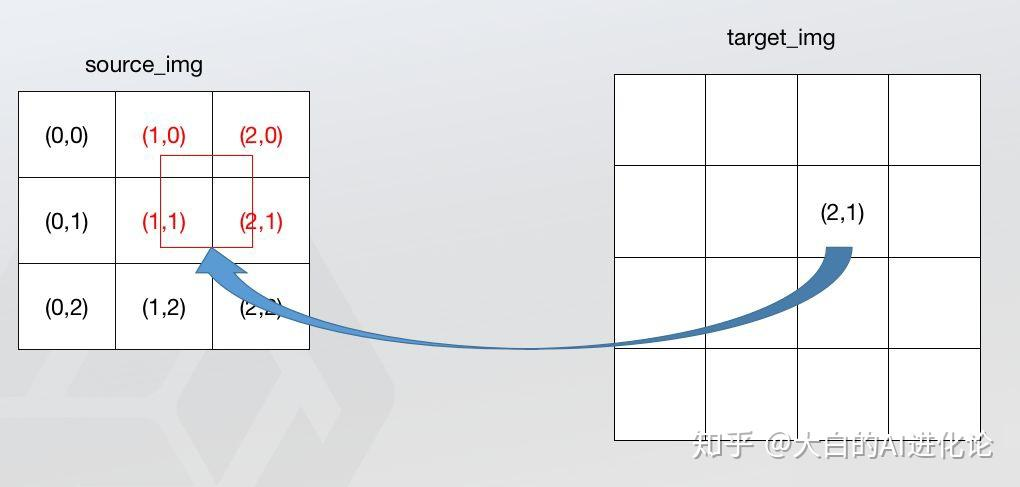
针对于单线性插值,已知p1和 p2 计算x1 x2区间内某一位置x在直线上的y值,直接求一条直线公式 
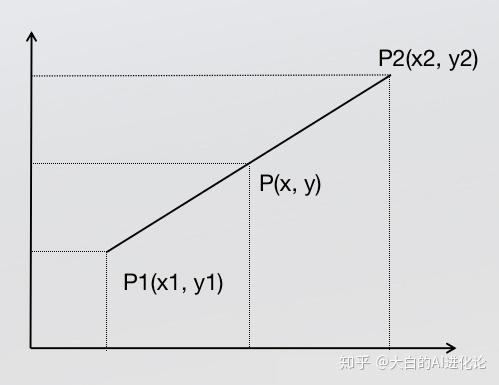
这个直线公式也是双线性插值所需要的唯一的基础公式
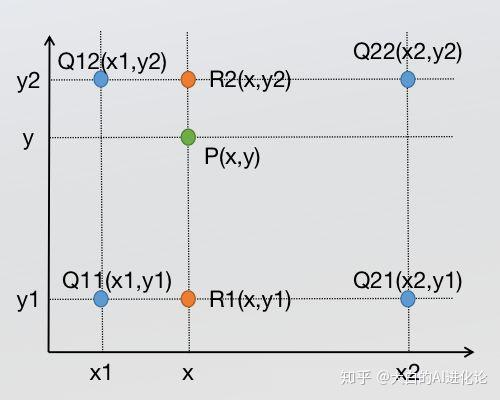
双线性插值就是进行三次单线性插值,先在x方向上求出2次单线性插值,获得R1 R2,再在y方向计算一次单线性插值得出P 简单简单
遇到的问题
无论选哪个角做原点,总有一侧边界"占便宜"(更容易保留原始值),另一侧"吃亏"(被插值模糊或拉伸)。这是坐标系定义带来的系统性不对称。
注意计算的是像素值,不是坐标
对于上面那个图,有这样的关系
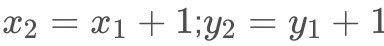
就相当于这样理解,这距离为1中的像素值差距是多少,每个部分像素值是多少,进行这样的累加,比如下面这个题目

横着看距离为1差距为20,那么0.4就是8 所以R1是38 同理r2是78 那么y方向来说距离为1差距是40 那么0.6就是24 所以最后的像素值是62 就是这样的算的 很简单 确定邻点 然后计算 但是这样就会导致上面所说的遇到的问题
然后解决方案就是:几何中心点重合对应公式,这个不管了
现在opencv就很牛背了,自带坐标映射 边界处理和高效插值计算 不管了简单知道啥意思就行