个人博客地址
|----------------------------------------|
| 个人博客: 花开富贵 |
文章目录
- 个人博客地址
-
- [1 一致性](#1 一致性)
- [2 再谈隔离性](#2 再谈隔离性)
-
- [2.1 MVCC - 多版本并发控制](#2.1 MVCC - 多版本并发控制)
-
- [2.1.1 三个记录隐藏字段](#2.1.1 三个记录隐藏字段)
- [2.1.2 undo log](#2.1.2 undo log)
- [2.1.3 当前读与快照读](#2.1.3 当前读与快照读)
- [2.1.4 Read View - 读视图](#2.1.4 Read View - 读视图)
- [2.1.5 MVCC](#2.1.5 MVCC)
- [2.2 RR 与 RC 的本质区别](#2.2 RR 与 RC 的本质区别)
1 一致性
在前文中提到了事务的几个隔离级别,并且讲述了事务的原子性 , 隔离性 , 持久性;
事务除了这三个性质以外还有一个性质:
- 一致性
事务执行的结果必须使数据库从一个一致性 状态变换到另一个一致性 状态,当数据库中只包含已经提交的事务的结果时,该数据库处于一种一致性状态;
在前文中,我们提到,所谓的事务实际上是一条或者一组DML语句的合集操作,说明事务一定会有若干条DML语句,而若是该事务执行中断后已经操作的DML语句被提交到实际的数据库中进行存储化,那么将会出现中间态,即不能保证其一致性 , 因此实际在事务的执行过程当中,当数据库发生异常时,将会自动执行ROLLBACK进行回滚操作以保证其一致性 , 可以看到这里的一致性 是由原子性来保证的;
但除了原子性 以外,我们可以举一反三,实际上事务的一致性是由其他的三个属性共同维护的,即:
-
"事务中的隔离性由事务的原子性,一致性,永久性" 共同保证
原子性相关的我们已经在上文进行了讨论;
隔离性 通过隔离级别 保证,而若是没有隔离级别 , 将出现脏读 , 不可重复读 与幻读 的问题,这种问题在多个事务共同对一个数据库进行操作时将无法保证其一致性;
关于永久性 , 当事务完成后需要通过
COMMIT进行操作,将对应的操作永久写进数据库并撤销undo缓存 (后面谈), 同时在COMMIT操作后将无法进行ROLLBACK操作,这也使得了多个事务在对一张表并行操作时,不会因为若干个事务的ROLLBACK操作而影响数据库中的内容从而保持一致性;
2 再谈隔离性
在前文中,我们讨论了隔离性 的相关内容,主要围绕着不同级别的隔离级别进行讨论,且讨论了不同级别将可能发生的问题;
首先我们再次谈到,实际上MySQL的核心部分是其服务端,即mysqld, 其作为一个服务端,那么一定会同时连接多个客户端,因此也将会在某个时刻同时遇到多个事务的并发操作;
隔离性 主要是为了防止数据库在进行并发时出现数据问题因此才设计出的,主要通过不同的隔离级别这种调节器来预防可能发生的问题;
通常情况下,在MYSQL中,遇到的并发场景无非就只有三种:
-
"读 - 读"
若干个事务对同一个表内数据进行查询操作;
-
"读 - 写"
若干个事务操作同一张表,但其中有些事务在进行查询操作,有些事务在进行写 (如插入,更新,删除) 操作;
-
"写 - 写"
若干个事务操作同一张表,所有事务都在进行写 (如插入,更新,删除) 操作;
而大部分的并发情况通常都为读写并发;
2.1 MVCC - 多版本并发控制
MVCC多版本并发控制是一种用来解决读写冲突的无锁并发控制;
通常情况下,使用Create语句来创建一张表,其表内的字段通常是我们指定的,如:
sql
CREATE TABLE IF NOT EXISTS CREATE TABLE students(
id int,
name varchar(20)
);在这个建表语句中,我们只创建了两个column, 即id与name, 但其实不然,MySQL在创建表时将会为我们添加三个隐藏字段;
其次在MySQL中,我们所使用的ROLLBACK操作通常是将过去版本的数据覆盖到回对应条目中,这与MySQL中的特殊机制undo_log有关;
最后是在上一篇文章中,我们提到关于REPEATABLE READ隔离级别中存在一种快照读的方式;
上述的这些内容都与MVCC多版本并发控制有关,我们将这些内容总结为几点:
- 三个隐藏字段
- undo 日志
- Read View
2.1.1 三个记录隐藏字段
在 花开富贵 的个人博客 - 『 MySQL 』索引中,我们提到了一个重要的索引被称为 "聚簇索引" , 在MySQL - Innodb中,必须存在聚簇索引,若是数据库中不存在用户主动设置的聚簇索引 , 那么Innodb将会在表中自行创建一个隐藏的DB_ROW_ID作为聚簇索引, 这个是其中一个隐藏字段,但并不止只有这一个隐藏字段,如标题所言,一共有三个隐藏字段,分别为:
DB_TRX_IDDB_ROLL_PTRDB_ROW_ID
在源码的 mysql/mysql-server/storage/innobase/dict/dict0dict.cc文件中dict_table_add_system_columns方法内可以看到对应的字段的添加;
cpp
void dict_table_add_system_columns(dict_table_t *table, mem_heap_t *heap) {
// ...
// 添加 DB_ROW_ID 列
dict_mem_table_add_col(table, heap, "DB_ROW_ID", DATA_SYS,
DATA_ROW_ID | DATA_NOT_NULL, DATA_ROW_ID_LEN, false,
phy_pos, v_added, v_dropped);
// 添加 DB_TRX_ID 列
dict_mem_table_add_col(table, heap, "DB_TRX_ID", DATA_SYS,
DATA_TRX_ID | DATA_NOT_NULL, DATA_TRX_ID_LEN, false,
phy_pos, v_added, v_dropped);
// 添加 DB_ROLL_PTR 列
if (!table->is_intrinsic()) {
dict_mem_table_add_col(table, heap, "DB_ROLL_PTR", DATA_SYS,
DATA_ROLL_PTR | DATA_NOT_NULL, DATA_ROLL_PTR_LEN,
false, phy_pos, v_added, v_dropped);
}
}在MySQL中,通常调用dict_mem_table_add_col()方法来增加列,通常情况下,无论是建表时创建的列还是通过ALTER TABLE ADD ...方法所添加的列都通过该函数来进行创建;
而在创建一个新表时,需要调用dict_table_add_system_columns()方法来为表增加对应的系统隐藏列;
-
DB_ROW_ID该字段在表中的大小通常为
6byte;在上文中,我们提到,这个隐藏字段本质是通过代替表中的聚簇索引 所存在,没有显式定义聚簇索引 时,这个字段将存在并且成为聚簇索引 列,构建对应的
B+Tree;当然,该列并不是必须存在的列,只有当没有显式定义聚簇索引时才会存在该列;
-
DB_TRX_ID该字段在表中的大小通常为
6byte;该字段用来记录对应的事务 ID;
我们知道,
mysqld作为服务端,必然会存在多个客户端连接,并且通过多个事务对同一份数据并发进行操作;当系统内部存在大量相同的数据,那么这些数据将会被进行管理,管理方式我们通常用六个字来进行统称 ------ "先描述 后组织" , 先将大量相同的数据以类
class或结构体struct的方式进行描述,而后再通过一组特定的数据结构对这些对象进行管理;除此之外,在管理时为了更好的方便操作这些数据,我们需要使用对应的字段来对每一个数据进行命名从而保证其在内部的唯一性,因此事务具备这样的属性,同样的我们需要用对应的
ID来确保一个事务在一定范围有该事务的唯一性 (mysqld的全局,一个mysqld的所有数据库统一分配同一块索引,因此不会因为表的不同而重新增长);因此在表中,我们需要有一个字段来记录是哪个事务操作 (增 / 删 / 改) 了这条数据;
除此之外,事务
ID的分配是根据事务所到来的顺序进行分配,而不是根据事务结束的顺序进行分配,也不可能根据事务结束的顺序进行分配,因为事务有长事务与短事务之分,我们无法看到一个事务谁先结束,对应的mysqld更不知道在没有事务结束时哪个事务先结束,因此无法根据事务的结束顺序进行分配事务ID; -
DB_ROLL_PTR该字段在表中的大小通常为
7byte;这一列通常作为一个指针 , 默认是
nullptr, 但其有数据时,通常是指向该列的上一个版本记录的内存位置;这里可能需要卖一个关子 orz
但首先我们需要简单的知道一点:
- 当事务在进行时,所进行的插入
INSERT/ 删除DELETE/ 更新UPDATE操作都将会被存储在一个名为undo_log的日志中,以便于后期进行ROLLBACK操作,这些日志将包含对应的值,以及操作信息,以便于后期进行ROLLBACK操作时方便滚回;
而这些被存储在
undo_log的内容可以看作该条数据之前的版本记录,而该指针所指向的位置则为上个版本的记录; - 当事务在进行时,所进行的插入
这几个字段的顺序通常是固定不变的 (DB_TRX_ID, DB_ROLL_PTR, DB_ROW_ID);
通过这几个字段我们就可以了解实际一张表的全貌 (以上文给出的表结构为例):
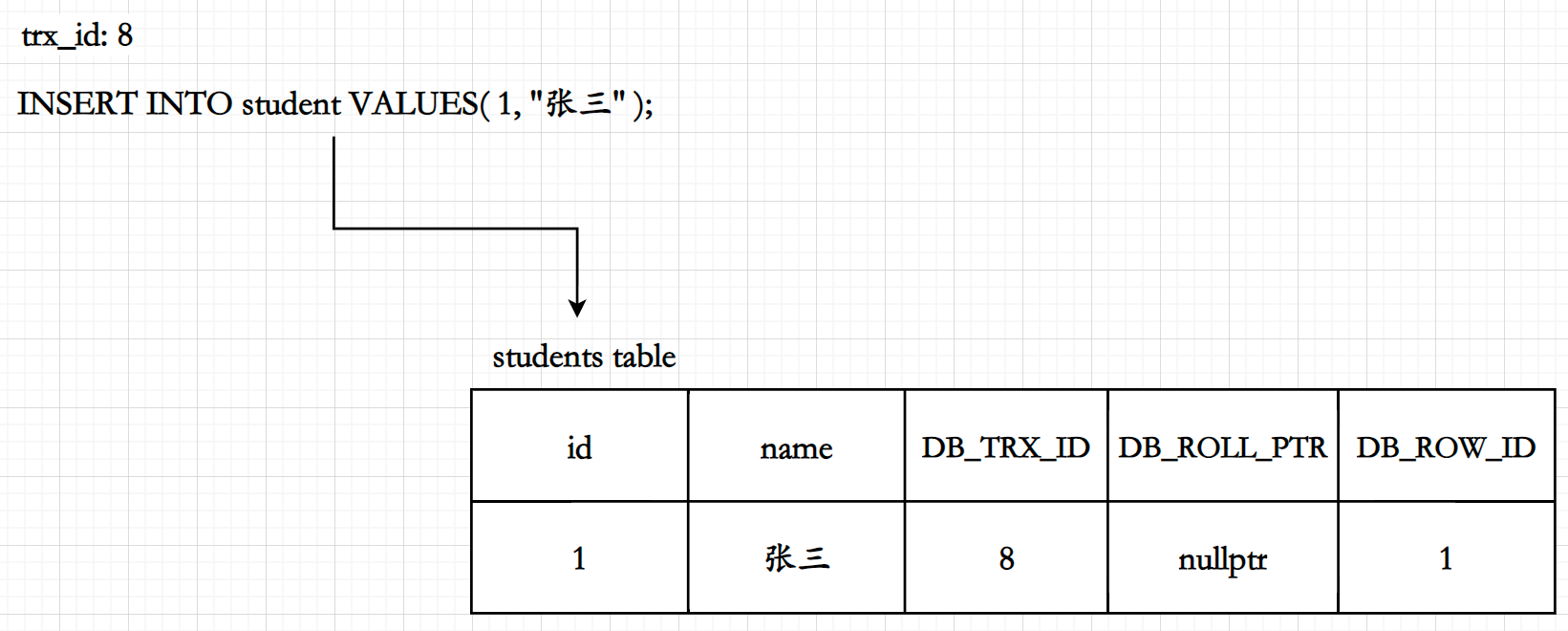
在这张图中,操作该记录的事务ID为8, 是插入数据,因此是最早的版本,其db_roll_ptr指针为nullptr, 其次在该表中并没有显示定义聚簇索引 , 因此将会定义一个DB_ROW_ID作为聚簇索引;
2.1.2 undo log
在上文中,我们在2.1.1中提到了DB_ROLL_PTR与undo日志的关系;
在这里我们可以先做结论,"undo log是应用层由MySQL维护的一段内存空间 ", 同时是MySQL中的一段缓冲区;
其存储着每一条版本记录,为MVCC 多版本控制与未来可能出现的ROLLBACK操作作准备;
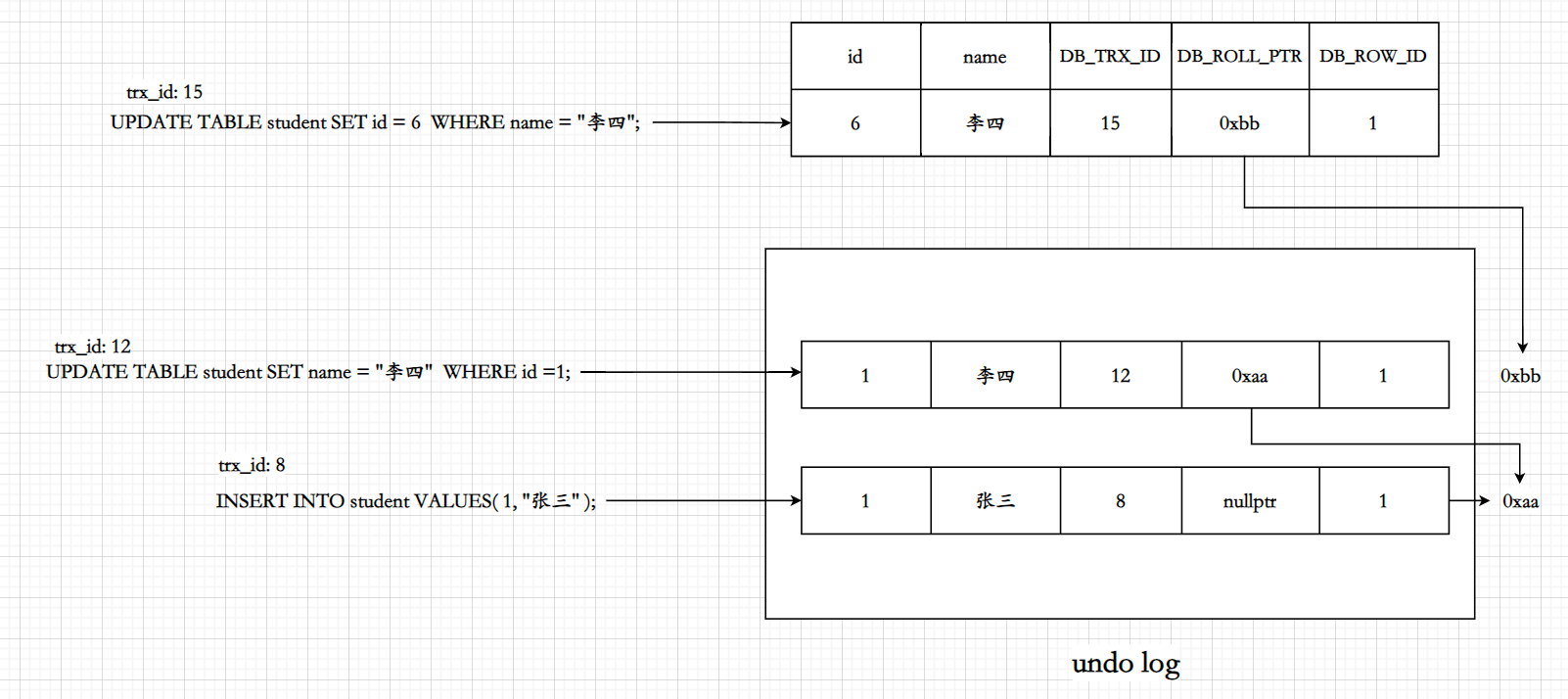
我将单条undo记录的核心结构与undo整体的核心结构的源码进行了整理:
-
单条
undo记录cpp/** undo log记录格式(单字节代码): 1 type_cmpl ... 信息位, 完成信息, 表ID, 事务ID, 回滚指针, ... */ /** 事务undo log页面头偏移 */ /** @{ */ /** TRX_UNDO_INSERT 或 TRX_UNDO_UPDATE */ constexpr uint32_t TRX_UNDO_PAGE_TYPE = 0; /** 最新事务undo log记录在该页开始的字节偏移(更新undo log的第一页可能包含多个undo log) */ constexpr uint32_t TRX_UNDO_PAGE_START = 2; /** 该页第一个空闲字节的字节偏移 */ constexpr uint32_t TRX_UNDO_PAGE_FREE = 4; /** undo log页链的文件列表节点 */ constexpr uint32_t TRX_UNDO_PAGE_NODE = 6; /*-------------------------------------------------------------*/ /** 事务undo log页面头大小(字节) */ constexpr uint32_t TRX_UNDO_PAGE_HDR_SIZE = 6 + FLST_NODE_SIZE; /** @} */ /** 只包含一个页的更新undo段可以重用, 如果其已用字节最多为此限制; 我们必须至少为一个新undo log头留空间 */ #define TRX_UNDO_PAGE_REUSE_LIMIT (3 * UNIV_PAGE_SIZE / 4) -
undo log整体核心结构cppstruct trx_undo_t { ulint id; /*!< undo log槽号(在回滚段内) */ ulint type; /*!< TRX_UNDO_INSERT 或 TRX_UNDO_UPDATE */ ulint state; /*!< 对应undo log段的状态 */ bool del_marks; /*!< 仅在更新undo log相关: 如果事务可能因行删除或索引字段更新而删除标记记录, 则为true, 因为需要purge; 如果事务更新外部存储字段也为true */ trx_id_t trx_id; /*!< 分配给undo log的事务ID */ XID xid; /*!< X/Open XA事务标识 */ ulint flag; /*!< 当前事务XID和GTID的标志. 持久化在undo头的TRX_UNDO_FLAGS标志中 */ Gtid_storage m_gtid_storage{Gtid_storage::NONE}; bool dict_operation; /*!< 如果是字典操作事务则为true */ trx_rseg_t *rseg; /*!< undo log所属的rseg */ space_id_t space; /*!< undo log所在的空间ID */ page_size_t page_size; page_no_t hdr_page_no; /*!< undo log头页的页号 */ ulint hdr_offset; /*!< 页上undo log头的偏移 */ page_no_t last_page_no; /*!< undo log最后一页的页号; 回滚期间可能与top_page_no不同 */ ulint size; /*!< 当前大小(页数) */ ulint empty; /*!< 如果undo log记录栈当前为空则为true */ page_no_t top_page_no; /*!< 最新undo log记录拼接的页号; 回滚期间是从中选择最新undo记录的页 */ ulint top_offset; /*!< 最新undo记录的偏移, 即undo log视为栈时的栈顶元素 */ undo_no_t top_undo_no; /*!< 最新记录的undo号 */ buf_block_t *guess_block; /*!< 猜测top页可能所在的缓冲块 */ UT_LIST_NODE_T(trx_undo_t) undo_list; /*!< 回滚段中的undo log对象链入列表 */ };
从两段代码来看,我们似乎没有看到单条undo记录的结构体描述,我们需要对上文中,单条undo记录的描述进行更改;
实际上也是如此,在MySQL中,单条undo记录通过undo的偏移操作 + 页的概念进行描述,并不是固定的结构体,本质因为操作类型之多且单条记录的数据也是弹性大小,无法使用单一的struct进行描述,上文我们只是对其结构进行抽象,实际底层要复杂的多;
这些单条的undo记录将成为快照的数据源;
MVCC 多版本控制将根据当前事务的ROLLBACKptr来决定能看到哪一条数据,从而产生所谓的 "快照" ;
在这里我们讨论了
undolog与事务的关系,但是实际上,事务的处理方式和undolog的处理方式是解耦的;从上面我们可以看到,单条
undolog作为版本中的一环本质是undolog的一部分;而当一个事务
commit了之后,他将可能成为undolog多个版本中的其中一环;虽然我们知道,在上文的代码块中,对应的单条
undolog将会被purge清理,但这本质上并与事务无关,只和Innodb给予undolog的大小限制有关,undolog只需要为事务提供快照 功能与让事务能够在一定范围内进行ROLLBACK即可;
2.1.3 当前读与快照读
在事务中有两种读取数据的方式,我们称之为当前读 与快照读;
针对当前读 与快照读 我们主要根据动词 "读" 之前的修饰词进行区分,那么何为当前读 何为快照读;
-
当前读
当前读旨在读取最新的数据, 但当前读并不仅仅只针对读操作,这里的读本质上也只是一个抽象动作;
只要是针对当前最新数据的操作,无论是增删改查,我们都统称为当前的数据,而不是历史版本数据,因为历史版本数据决不能被更改;
因此我们在进行当前读时,为了确保数据不出现脏读 /幻读 以及不可重复读 等问题,我们通常需要为数据增加读写锁, 避免读取数据的事务因为其他的事务当前读的修改操作导致读取到错误的数据;
-
快照读
快照读通常是一种读取历史版本 的功能,其将读取
undo log中其应该看到对应范围的历史版本数据,以保证其在查询中能够游刃有余;针对快照读而言,我们只对其进行
select操作才称之为快照读;
2.1.4 Read View - 读视图
2.1.3中我们解释了快照读 和当前读的区别;
本质上快照读 是读取undo log中历史版本的数据,那么这里的快照的数据源到底属于哪些版本的数据?
在花开富贵 的个人博客 - MySQL 事务 (一)中,我们提到了一个事务应该看到其应该看到的范围,而这些能看到的范围就是undo log给予事务能看到的范围;
Read View 抽象来说就是一个活跃事务在进行快照读 时所产生的视图,当事务执行快照读 的那一刻,就会针对事务生成数据库当前的一个快照;
不同的事务将会存在不同的ReadView, 老生常谈,"mysqld 是服务,意味着一定会有若干客户端使用若干个事务进行并发访问操作,这意味着系统内将存在大量的结构相同的数据,那么必然要对这些数据进行管理" , 因此对应管理的方式即为 "先描述 后组织" ;
因此本质上ReadView是一个类,用来描述一个事务在进行快照读的可见性判断;
cpp
class ReadView {
/**
# 这个类的行为与 std::vector 类似
# 但不能简单地把代码中的 std::vector 直接替换成它
#它是专门为 ReadView 这个特定用途实现的
*/
// ...
/** 读取操作不应看到事务ID >= 此值的任何事务。换言之,这是"高水位标记"。*/
trx_id_t m_low_limit_id; // 高水位
/** 读操作应能看到所有严格小于(<)此值的 trx(事务)ID。换句话说,这是"低水位线"。 */
trx_id_t m_up_limit_id; // 低水位
/** 创建事务的事务ID,如果是free views则设置为TRX_ID_MAX */
trx_id_t m_creator_trx_id; // 创建该ReadView的事务ID
/** 此快照拍摄时处于活跃状态的读写事务集合 */
ids_t m_ids; // 该视图被创建时的活跃事务ID列表
/** 配合purge,标识该视图不需要小于m_low_limit_no的UNDO LOG,
* 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/
trx_id_t m_low_limit_no;
/* 标记视图是否被关闭 */
bool m_closed;
// ...
};代码段源自mysql-server/storage/innobase/include/read0types.h at 8.0 · mysql/mysql-server;
可以看到实际上我们主要关注的是几个成员:
-
m_ids该视图被创建时的活跃事务 ID列表;
-
m_up_limit_id记录
m_ids中最小的事务 ID; -
m_low_limit_id与
m_up_limit_id相反,该成员记录ReadView生成时系统尚未分配的下一个事务 ID , 即当前m_ids中最大的事务ID + 1; -
m_creator_trx_id创建该
ReadView的事务 ID;
在前文中,我们说过,"一个事务只能看到他应该看到的范围" , 但实际不然,一个事务他能读到undolog中已有的每一个版本的事务ID, 这样意味着,我们可以通过这些事务ID间接的看到undolog中已有的所有版本,因此这句话只是一个现象,但这个现象是如何产生的;
- 那么针对当前事务的快照读, 其是否应该读取到当前版本的记录?
这个答案实际上与ReadView的成员有关;
首先作为一个事务,其一定能读取自己所做的操作,因此能在进行快照读时,自己所更改的版本是一定能看到的;
其次,事务能看到过往的已经commit的记录,其次,事务在开启时,一定会有其他的快照正在同时操作,这些其他事务被MySQL维护在了m_ids中,为了保证隔离性 , 当前事务无法读取m_ids内的事务记录;
因此,当前事务在进行快照读 时,其能看到的范围为[m_up_limit_id, m_low_limit_id)并且其不能看到创建ReadView时的m_ids中的事务记录;
对应的逻辑类似于:
cpp
if (id < m_up_limit_id || id == m_creator_trx_id) → 可见
else if (id >= m_low_limit_id) → 不可见
else if (m_ids.empty()) → 可见
else → !binary_search(m_ids, id) ? 可见 : 不可见因此可以划分为:
m_ids中活跃事务的修改 → 不可见 (隔离性)- 快照之后新开启事务的修改 →
id≥m_low_limit_id→ 不可见 (隔离性) - 快照之前已提交 + 自己修改 + 快照后提交的 → 可见 (一致性)
在 MySQL源码 (8.0分支) 中的 "mysql-server/storage/innobase /include /read0types.h"中,对应判断事务ID是否可见的函数为 changes_visible():
cpp
[[nodiscard]] bool changes_visible(trx_id_t id,
const table_name_t &name) const {
// 断言:事务ID必须大于0(0是无效值,源码中用0表示"无事务")
ut_ad(id > 0);
// 规则1:事务ID < 低水位(m_up_limit_id)
// → 说明该版本在当前ReadView创建之前就已经提交,一定可见
// 或:该版本正是当前事务自己产生的(id == m_creator_trx_id)
// → 自己改的数据在快照读中必须对自己可见(写后读一致性)
if (id < m_up_limit_id || id == m_creator_trx_id) {
return true;
}
// 对处于"灰色区间"(低水位 ≤ id < 高水位)的版本,需要额外检查事务ID是否合理
// 防止出现已purge掉但仍被引用的非法旧版本
check_trx_id_sanity(id, name);
// 规则2:事务ID ≥ 高水位(m_low_limit_id)
// → 说明该版本是在当前ReadView创建之后才产生的新事务产生的,一定不可见
if (id >= m_low_limit_id) {
return false;
}
// 规则3:如果当前ReadView创建时系统中没有其他活跃的读写事务
// → 灰色区间内的所有版本都是在ReadView创建后提交的,可以全部看见
if (m_ids.empty()) {
return true;
}
// 规则4:灰色区间 + 在m_ids(活跃事务列表)中
// → 说明该版本属于一个在ReadView创建时仍未提交的事务
// → 为了保证可重复读隔离性,必须对当前事务不可见
// → 因此只有"不在m_ids中"的才可见(即后来提交的)
const ids_t::value_type *p = m_ids.data();
return !std::binary_search(p, p + m_ids.size(), id);
}2.1.5 MVCC
实际上,MVCC 的多版本控制通过上述的隐藏字段 , undolog以及ReadView共同组成;
-
隐藏字段
隐藏字段中的事务 ID 用于记录每个事务的
ID, 为事务在ReadView查看范围提供基础;roll_ptr用于将这些undolog进行联系; -
undolog
用于记录对应事务操作的各个版本 , 为MVCC接下来查看版本提供基础;
-
ReadView
直接根据隐藏字段 和
undolog为事务提供快照;
从而实现多版本控制;
ps: 这里真的写累了 orz
2.2 RR 与 RC 的本质区别
RR和RC的本质区别是,其生成ReadView 的时机以及其ReadView的生命周期不同;
针对RR隔离级别,其ReadView 将在第一次SELECT快照读 时生成,且自此其快照将自始至终伴随着他的生命周期;
而针对RC而言,其生成ReadView 的时机为,每次进行快照读 SELECT时都将会创建一次ReadView;