目录
[3、深度学习(DL, Deep Learning)](#3、深度学习(DL, Deep Learning))
一、概念
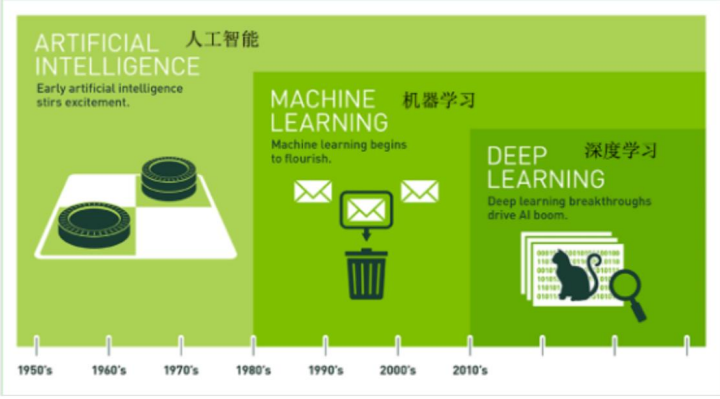
1、人工智能
Artificial Intelligence
人工智能(AI)是一门研究智能行为计算主体的合成与分析的学科。
人工智能(AI)旨在通过计算机模拟并辅助(或:替代)人类大脑的功能。
2、机器学习
一门让计算机无需被明确编程,就能自主获得学习能力的研究领域。
3、深度学习(DL, Deep Learning)
也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物
三者关系:机器学习是实现人工智能的一种途径 ,深度学习是机器学习的一种方法
二、机器学习
1、基于规则的学习
程序员根据经验利用手工的if-else方式进行预测
2、基于模型的学习
有很多问题无法明确的写下规则,此时我们无法使用规则学习的方式来解决这一类问题,比如:图像和语音 识别和自然语言处理,从数据中自动学出规律
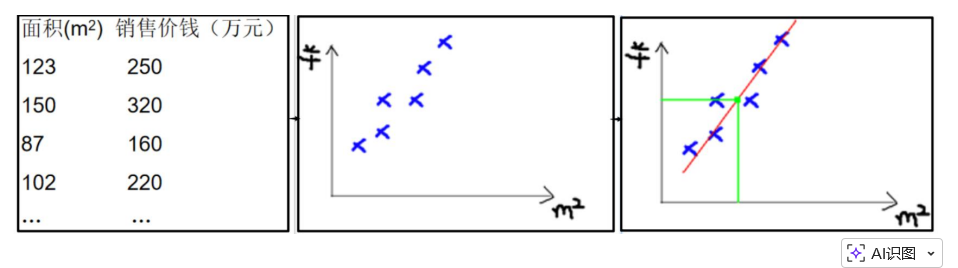
比如:房价预测
直线记成y = ax + b 就是模型,其中 a、b 就是我们要训练的模型参数,得到一个最佳的a和b,然后就可以用方程预测房价了。
3、样本与数据集
想要模型学习,必须要有收集的原始数据
样本(sample) :一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录
特征(feature) :一列数据一个特征,有时也被称为属性
标签/目标(label/target) :模型要预测的那一列数据
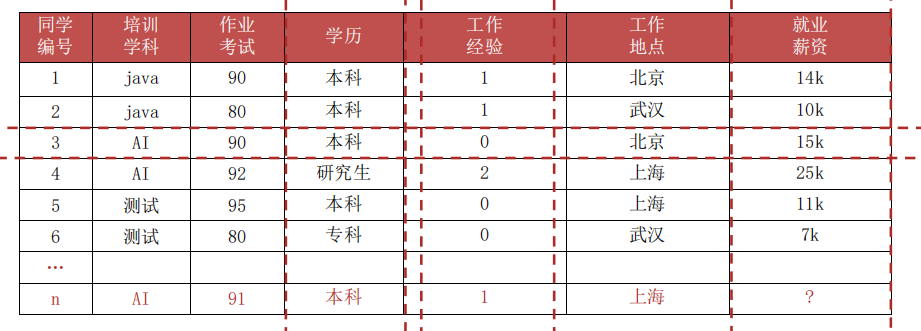
比如薪资表:
我们想用学科、考试成绩、学历、工作经验、工作地点作为条件x,预测就业薪资y。
首先需要收集已有的数据,一条条数据就是样本,学科、考试成绩、学历、工作经验、工作地点等条件就是特征,薪资就是要预测的目标
数据集可划分两部分:训练集、测试集 比例:8 : 2,7 : 3
训练集(training set) :用来训练模型(model)的数据集
测试集(testing set):用来测试模型的数据集
x_train 训练集中的x,x_test 测试集中 的x
y_train 训练集中的y,y_test 测试集中的y
4、有监督学习与无监督学习
有监督学习:有特征有标签,比如上面的薪资的例子
定义:输入数据是由输入特征值和目标值所组成,即输入的训练数据有标签的
数据集:需要标注数据的标签/目标值
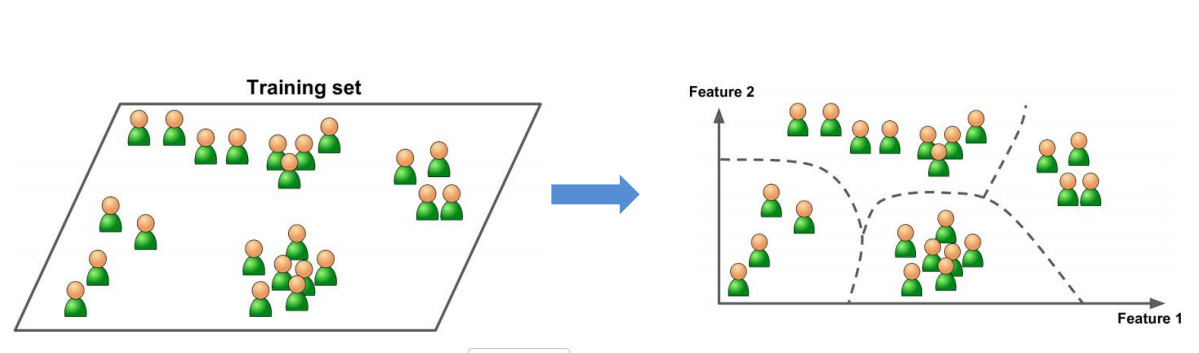
无监督学习:无特征无标签,用于在不知道规律的数据中发掘出有用的信息
定义:输入数据没有被标记,即样本数据类别未知,没有标签, 根据样本间的相似性,对样本集聚类,以发现事物内部结构及相互关系。
比如下面的例子,通过机器学习,自己发掘规律
5、有监督的分类问题与回归问题
分类问题,目标值(标签值)是不连续的,有二分类,多分类等。比如我们把薪资水平分为三类,0:低水平,1:中水平,2:高水平:0,1,2之间只是代表类别,通过预测得到的结果落在0,1,2之内,不会出现新的值。
回归问题:还是以薪资为例,我们不进行分类,而是记录每个人的薪资金额,通过预测他们的薪资,会得到一个具体的值,这个值是连续的。
6、机器学习建模流程
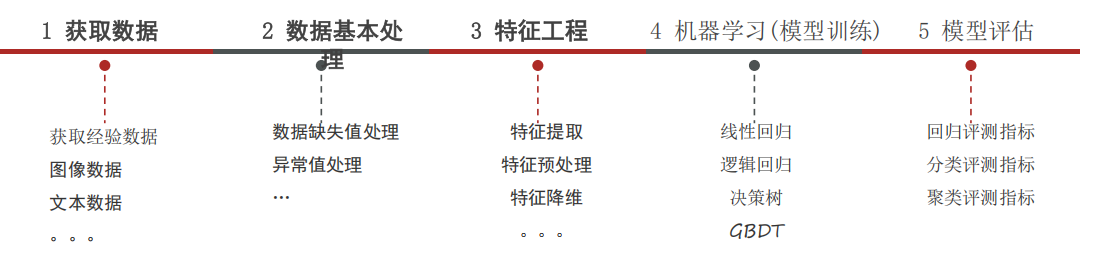 获取数据:搜集与完成机器学习任务相关的数据集
获取数据:搜集与完成机器学习任务相关的数据集
数据基本处理**:**数据集中异常值,缺失值的处理等
特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果
机器学习(模型训练):选择合适的算法对模型进行训练
根据不同的任务来选中不同的算法;有监督学习,无监督学习,半监督学 习,强化学习
模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
7、模型表现效果
拟合:用来表示模型对样本分布点的模拟情况
欠拟合:模型在训练集上表现很差、在测试集表现也很差,是欠拟合
过拟合:模型在训练集上表现很好、在测试集表现很差,是过拟合

原因:
欠拟合产生的原因:模型过于简单
过拟合产的原因:模型太过于复杂、数据不纯、训练数据太少