🍂 枫言枫语 :我是予枫,一名行走在 Java 后端与多模态 AI 交叉路口的研二学生。
"予一人以深耕,观万木之成枫。"
在这里,我记录从底层源码到算法前沿的每一次思考。希望能与你一起,在逻辑的丛林中寻找技术的微光。
这篇论文同样是关于多模态学习的前沿研究,发表于 AAAI 2025 。它提出了一种名为 DLF (Disentangled-Language-Focused)的框架,专门用于多模态情感分析(MSA)。
如果说上一篇 D2GNN侧重于解决对话中的"特征趋同"问题,那么这一篇 DLF 则侧重于解决多模态信息中的"冗余与冲突",并强调以语言模态为核心的特征增强 。
一、 核心动机:为什么要"偏爱"语言?
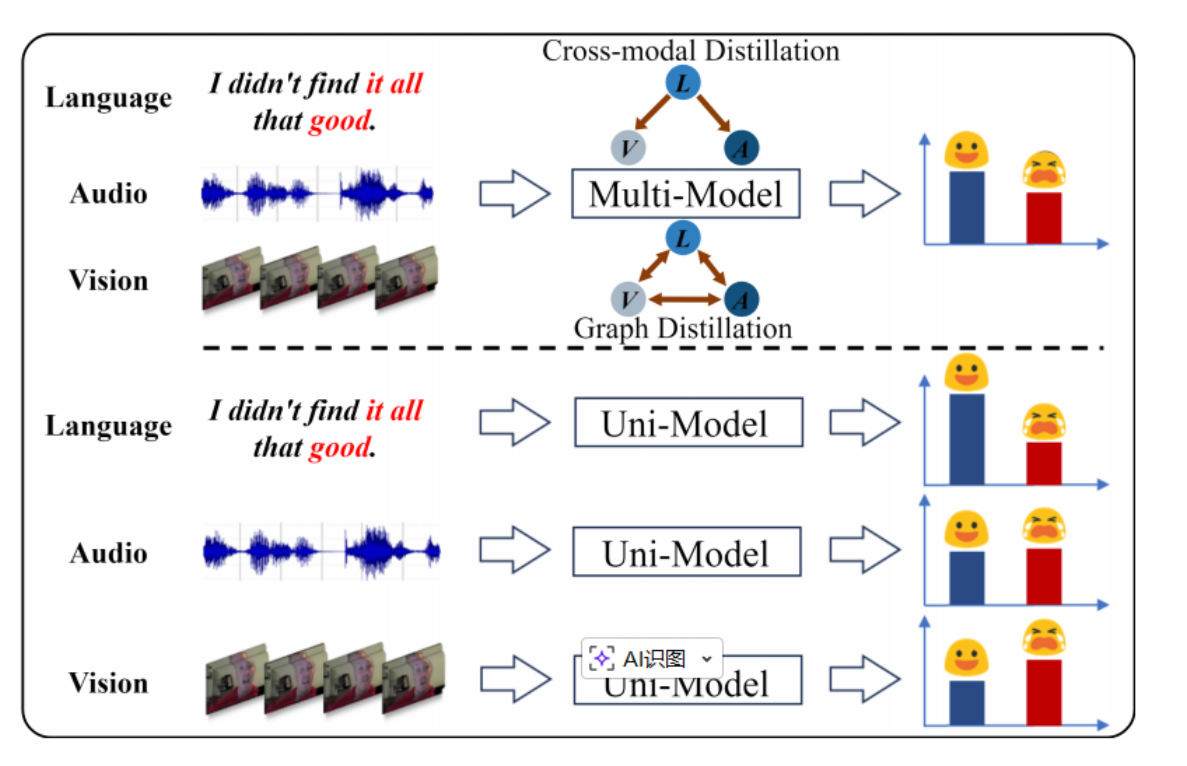
在多模态情感分析(MSA)中,通常包含语言(Language)、视觉(Vision)和音频(Audio)三种模态。
-
传统做法的弊端 :现有的模型(如跨模态蒸馏或图蒸馏)往往平等地对待所有模态,或者在所有模态对之间进行双向信息传递。作者认为这会引入大量的冗余和冲突信息。
-
DLF 的视角 :研究表明,语言在情感预测中占据主导地位(Dominant Modality)。因此,DLF 不再盲目桥接所有模态间的差异,而是战略性地增强主导模态(语言),通过吸引其他模态的互补信息来提升表现。
二、 DLF 三大核心组件
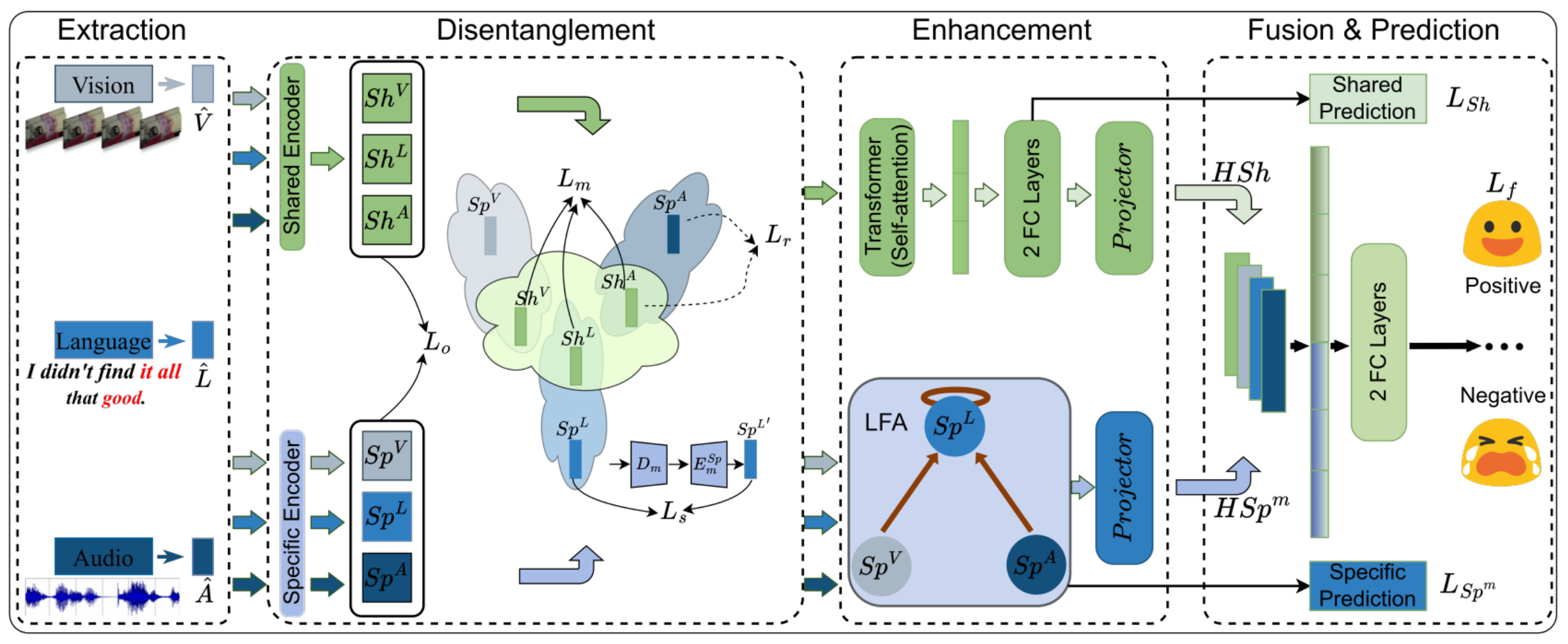
1. 特征解耦模块 (Feature Disentanglement Module, FDM)
为了减少干扰,DLF 首先将每个模态的特征分解为两个独立空间:
-
模态共享空间 (Modality-shared):捕获不同模态间的共同情感信息。
-
模态特有空间 (Modality-specific):保留每个模态独特的表达细节 。
-
四重几何约束:为了确保解耦彻底,作者引入了四种几何度量作为正则化项(重构损失、特有损失、三元组损失和正交损失),从欧几里得距离和余弦相似度两个维度优化特征空间。
2. 语言聚焦吸引子 (Language-Focused Attractor, LFA)
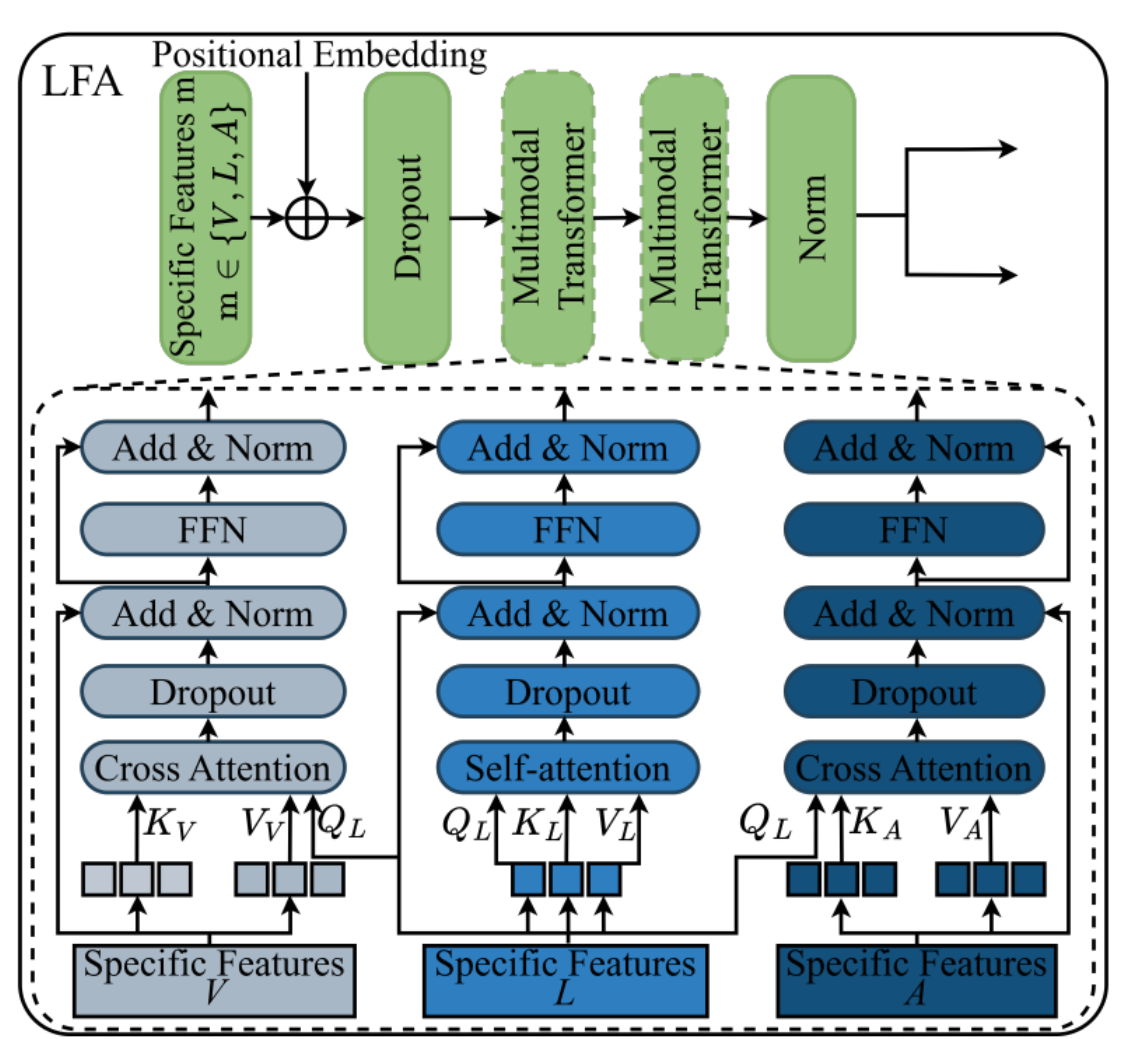
这是本论文最具创新性的设计。在解耦后的特有空间中,LFA 通过以语言为查询(Language-Query)的交叉注意力机制工作:
-
定向增强 :它构建了
视频→语言、音频→语言和语言→语言三条路径。 -
吸引互补信息:让语言模态像"吸引子"一样,精准地从视觉和音频中吸收有助于情感表达的补充特征,从而强化语言表征的判别力。
3. 分层预测机制 (Hierarchical Predictions)
为了进一步榨取特征价值,模型不仅仅在最后一步做预测,而是进行了分层处理:
-
同时考虑共享特征预测 、特有特征预测 和融合后的最终预测。
-
通过综合这三层损失函数,强迫模型在各个阶段都学习到对情感预测有用的表征。
三、 实验表现:全面超越 SOTA
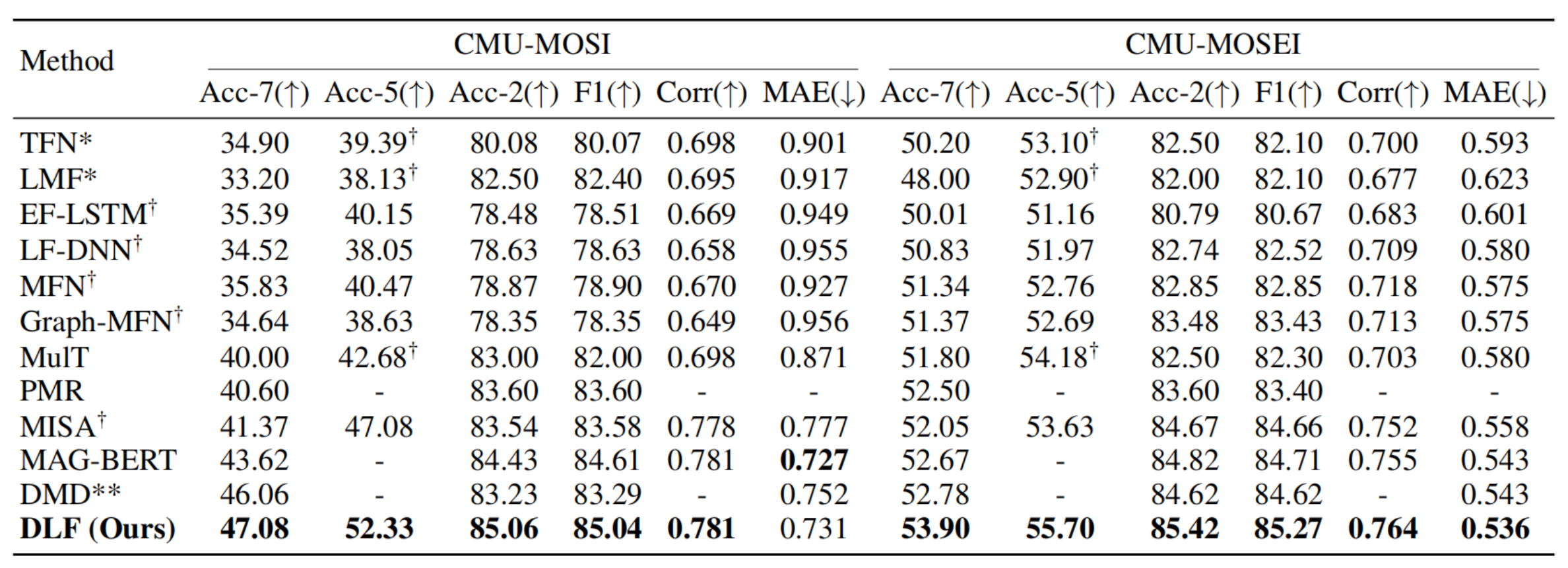
DLF 在 MSA 领域最权威的两个数据集 CMU-MOSI 和 CMU-MOSEI 上进行了验证:
-
超越经典:在与 MISA、MulT、DMD 等 11 种主流方法的对比中,DLF 在几乎所有指标(Acc-7, Acc-2, F1 Score 等)上都取得了最优结果。
-
消融分析:实验证明,移除 LFA(语言聚焦吸引子)会导致性能显著下降,证明了"以语言为核心"的增强策略远优于传统的对称式特征融合。
-
长尾分布思考:作者通过混淆矩阵发现,极度正面(HP)和极度负面(HN)的情感预测精度仍有提升空间,这可能受限于数据集样本分布不均(长尾问题),为未来研究指明了方向。
四、 总结:从"全模态对齐"到"主导模态增强"
DLF 的成功证明了在多模态任务中,"平等"并不一定是最好的策略。通过:
-
彻底解耦消除冗余;
-
定向吸引增强主导模态;
-
多级预测巩固特征。
DLF 为多模态情感分析提供了一套极其高效且逻辑严密的解决方案。
项目代码已开源 :https://github.com/pwang322/DLF
💡 予枫的对比小结
-
D2GNN :关注对话结构 ,解决 GNN 带来的节点同质化问题。
-
DLF :关注情感属性 ,解决模态间的信息冲突 ,强调语言的主导地位。
关于作者 : 💡 予枫 ,某高校在读研究生,专注于 Java 后端开发与多模态情感计算。💬 欢迎点赞、收藏、评论,你的反馈是我持续输出的最大动力!
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=9wrxwtlju1l
当前加入还有惊喜相送!