📖目录
- 前言
- [1. 人工智能发展历程(1950--2025)](#1. 人工智能发展历程(1950–2025))
-
- [1.1 AI发展的四个主要阶段](#1.1 AI发展的四个主要阶段)
- [1.2 关键里程碑事件(含CNN相关节点)](#1.2 关键里程碑事件(含CNN相关节点))
- [2. 深度学习核心技术:CNN深度解析与实践](#2. 深度学习核心技术:CNN深度解析与实践)
-
- [2.1 CNN基础原理:从卷积到池化的完整链路](#2.1 CNN基础原理:从卷积到池化的完整链路)
- [2.2 精细化CNN实践1:MNIST手写数字分类(含训练/评估/可视化)](#2.2 精细化CNN实践1:MNIST手写数字分类(含训练/评估/可视化))
-
- [2.2.1 环境准备](#2.2.1 环境准备)
- [2.2.2 完整源码(含注释)](#2.2.2 完整源码(含注释))
- [2.2.3 代码说明与预期结果](#2.2.3 代码说明与预期结果)
- [2.3 精细化CNN实践2:CIFAR-10图像分类(ResNet轻量化改造)](#2.3 精细化CNN实践2:CIFAR-10图像分类(ResNet轻量化改造))
-
- [2.3.1 核心改进:轻量化ResNet模块](#2.3.1 核心改进:轻量化ResNet模块)
- [2.3.2 完整源码(含注释)](#2.3.2 完整源码(含注释))
- [2.3.3 关键优化点与预期结果](#2.3.3 关键优化点与预期结果)
- [2.4 进阶实践:基于CNN的简易目标检测(滑动窗口+分类器)](#2.4 进阶实践:基于CNN的简易目标检测(滑动窗口+分类器))
-
- [2.4.1 完整源码](#2.4.1 完整源码)
- [2.4.2 实践说明](#2.4.2 实践说明)
- [2.5 CNN常见问题与优化技巧](#2.5 CNN常见问题与优化技巧)
- [3. 大模型与深度学习的关系](#3. 大模型与深度学习的关系)
-
- [3.1 Transformer 架构详解](#3.1 Transformer 架构详解)
- [3.2 核心组件](#3.2 核心组件)
- [3.3 为什么 Transformer 能支撑大模型?](#3.3 为什么 Transformer 能支撑大模型?)
- [4. 强化学习简介](#4. 强化学习简介)
-
- [4.1 经典算法与CNN结合场景:](#4.1 经典算法与CNN结合场景:)
- [4.2 Q-Learning算法](#4.2 Q-Learning算法)
-
- [4.2.1 先明确强化学习的核心要素(以FrozenLake为例)](#4.2.1 先明确强化学习的核心要素(以FrozenLake为例))
- [4.2.2 循序渐进的代码示例:表格型Q-Learning](#4.2.2 循序渐进的代码示例:表格型Q-Learning)
- [4.2.3 代码核心逻辑解释(帮你理解"为什么这么写")](#4.2.3 代码核心逻辑解释(帮你理解“为什么这么写”))
-
- [4.2.3.1 ε-贪心策略:为什么要"探索"?](#4.2.3.1 ε-贪心策略:为什么要“探索”?)
- [4.2.3.2 Q表更新公式:为什么这么算?](#4.2.3.2 Q表更新公式:为什么这么算?)
- [4.2.4 运行结果解读(你会看到什么?)](#4.2.4 运行结果解读(你会看到什么?))
- [4.2.5 进阶方向(从表格型到神经网络)](#4.2.5 进阶方向(从表格型到神经网络))
- [5. 其他核心网络实践](#5. 其他核心网络实践)
-
- [5.1 用Python实现简单LSTM(时间序列预测)](#5.1 用Python实现简单LSTM(时间序列预测))
-
- [5.1.1 完整源码](#5.1.1 完整源码)
- [5.1.1 实践说明](#5.1.1 实践说明)
- [5.2 用 Gym + Q-Learning 实现 CartPole 强化学习](#5.2 用 Gym + Q-Learning 实现 CartPole 强化学习)
-
- [5.2.1 CartPole 环境详解与 Q-Learning 代码优化](#5.2.1 CartPole 环境详解与 Q-Learning 代码优化)
- [5.2.2 什么是 CartPole(倒立摆)?](#5.2.2 什么是 CartPole(倒立摆)?)
-
- [5.2.2.1 环境构成](#5.2.2.1 环境构成)
- [5.2.2.2 核心参数(状态与动作)](#5.2.2.2 核心参数(状态与动作))
- [5.2.2.3. 任务目标](#5.2.2.3. 任务目标)
- [5.2.3 优化后的 Gym + Q-Learning 实现代码(带详细注释)](#5.2.3 优化后的 Gym + Q-Learning 实现代码(带详细注释))
- [5.2.4 代码关键逻辑说明](#5.2.4 代码关键逻辑说明)
- [5.2.5 运行建议](#5.2.5 运行建议)
- [6. 结语与学习建议](#6. 结语与学习建议)
-
- [🔧 学习建议:](#🔧 学习建议:)
前言
📌 文章说明 :本文系统梳理人工智能自1950年至今的发展脉络,深入剖析机器学习、深度学习、大模型等关键阶段的技术演进,并以CNN(卷积神经网络)为核心展开深度实践------从基础原理到完整项目(图像分类+目标检测),提供可直接运行的精细化源码及逐行解析。适合对AI技术演进感兴趣的开发者、学生和架构师阅读,尤其适合希望落地CNN技术的初学者。
人工智能(Artificial Intelligence, AI)作为计算机科学最具革命性的分支之一,经历了数次"寒冬"与"热潮"的交替。从图灵提出"机器能否思考"的哲学命题,到如今 ChatGPT、Claude、通义千问等大模型深刻改变人类工作方式,AI 已成为推动第四次工业革命的核心引擎。
而CNN(卷积神经网络) 作为深度学习的"基石技术",是计算机视觉领域突破的关键------从2012年AlexNet引爆图像识别革命,到如今自动驾驶的视觉感知、医学影像的病灶检测,CNN始终是核心技术支柱。本文将在梳理AI发展脉络的基础上,聚焦CNN的"原理+实战",提供比基础教程更精细的源码实现与工程化细节,帮你真正落地CNN技术。
1. 人工智能发展历程(1950--2025)
1.1 AI发展的四个主要阶段
下图展示了 AI 发展的四个主要阶段,其中CNN的爆发是深度学习时代的核心标志:
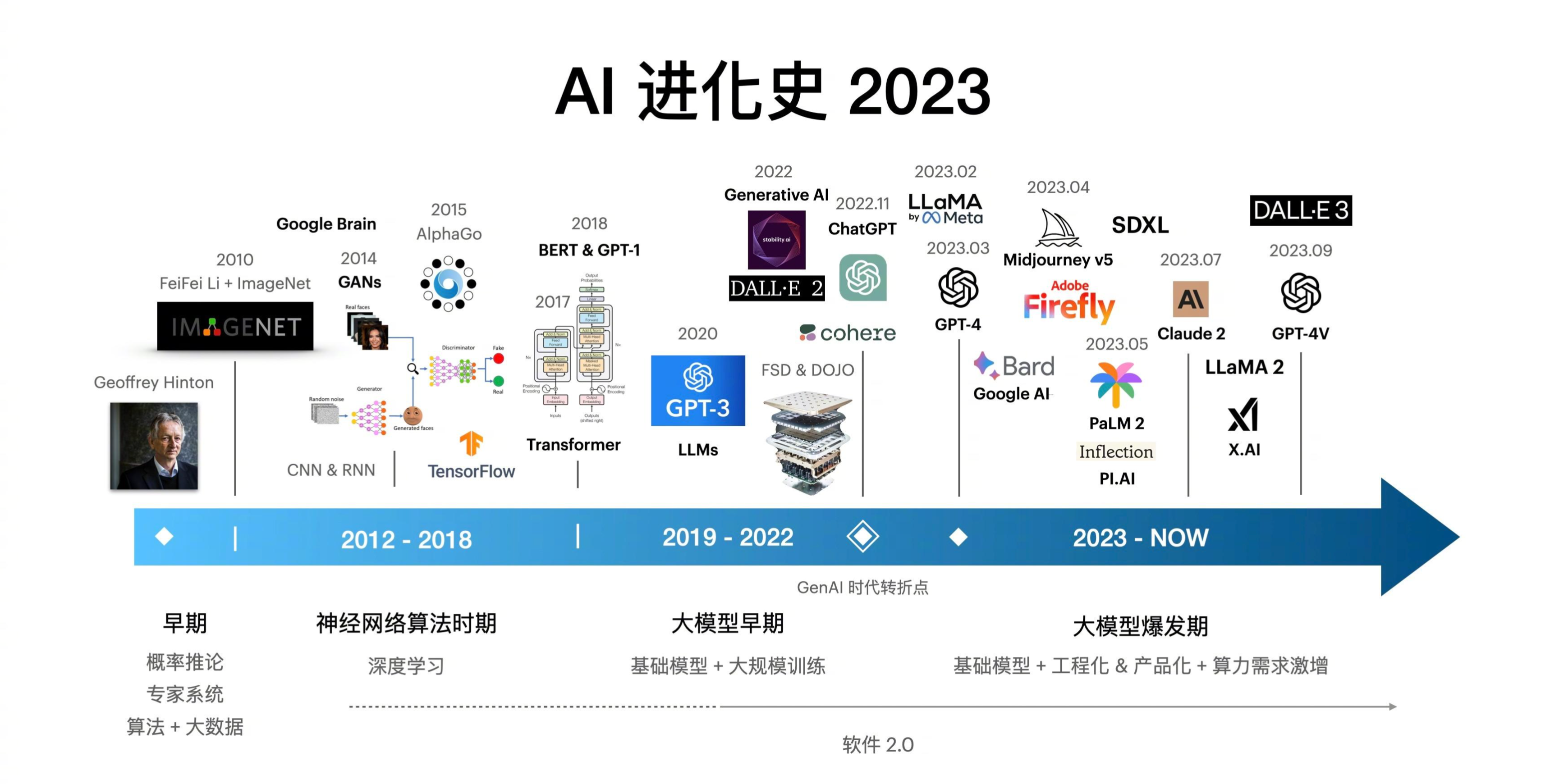
- 早期的机器学习时代(1990s--2010s):图灵测试 (1950)、达特茅斯会议 (1956)、专家系统兴起、LISP语言诞生、第一次AI寒冬、SVM / 决策树、随机森林、特征工程为核心、数据驱动初现、第二次AI寒冬缓解
- 神经网络算法时期(2012-2018):AlexNet (2012)、CNN/RNN广泛应用、ImageNet突破、GPU加速训练、自动驾驶/语音识别爆发
- 大模型早期(2019-2022):GPT-3 (2020)、BERT / T5、Llama / Qwen、
- 大模型爆发期(2023--至今):GPT-4、MoE / 多模态、Agent / MCP协议
1.2 关键里程碑事件(含CNN相关节点)
- 1950年:艾伦·图灵发表《计算机器与智能》,提出"图灵测试",为AI奠定哲学基础。
- 1956年:达特茅斯会议首次提出"Artificial Intelligence"术语,AI 正式诞生。
- 1960s--1970s:专家系统(如 DENDRAL、MYCIN)在特定领域成功,但泛化能力差,标志符号主义高峰。
- 1986年:反向传播算法(Backpropagation)被 Rumelhart 等人重新发现,为神经网络(含CNN雏形)复兴埋下伏笔。
- 1997年:IBM Deep Blue 击败国际象棋世界冠军卡斯帕罗夫,标志机器学习在结构化任务的突破。
- 2006年:Geoffrey Hinton 提出"深度信念网络",开启深度学习序幕,为CNN的深度化提供理论支持。
- 2012年 :AlexNet(8层CNN)在 ImageNet 竞赛中Top-5错误率降至15.3%(远超传统方法26%),CNN正式引爆深度学习浪潮。
- 2015年:ResNet(残差网络)提出,解决CNN深度增加导致的梯度消失问题,将ImageNet错误率降至3.57%。
- 2017年:Google 提出 Transformer 架构,奠定大模型基础;同年 YOLOv3 发布,CNN在目标检测领域实现"实时性+高精度"平衡。
- 2020年:OpenAI 发布 GPT-3,参数量达1750亿,展示大模型泛化能力;CNN作为多模态大模型(如CLIP)的视觉 backbone 持续发挥作用。
- 2023--2025年:开源大模型(Llama、Qwen)普及,CNN与Transformer融合(如ViT)成为计算机视觉主流,AI Agent 开始集成视觉感知能力。
💡 趋势总结:AI 从"规则驱动"→"数据驱动"→"模型驱动"→"智能体驱动"演进,而 CNN 是"数据驱动"阶段最核心的视觉技术,且至今仍在多模态大模型中扮演关键角色。
2. 深度学习核心技术:CNN深度解析与实践
深度学习是机器学习的子集,而CNN(卷积神经网络)是为处理空间结构数据(如图像)设计的专用网络------其核心是通过"卷积核提取局部特征+池化降维+全连接分类"的链路,实现端到端的视觉任务(分类、检测、分割等)。
2.1 CNN基础原理:从卷积到池化的完整链路
CNN的核心优势是**"局部连接+参数共享+平移不变性"**,解决了传统全连接网络处理图像时"参数爆炸+忽略空间结构"的问题。其基本结构分为5层:
- 输入层:接收原始图像数据(如MNIST为28×28×1灰度图,CIFAR-10为32×32×3彩色图)。
- 卷积层(Conv Layer) :通过卷积核(Filter)滑动扫描图像,计算局部像素的加权和,提取边缘、纹理等低级特征。
- 计算公式: O u t p u t = A c t i v a t i o n ( I n p u t ∗ F i l t e r + B i a s ) Output = Activation(Input \ast Filter + Bias) Output=Activation(Input∗Filter+Bias)( ∗ \ast ∗ 表示卷积运算)
- 关键参数:卷积核大小(如3×3)、步长(Stride,如1)、填充(Padding,如Same/Padding)、输出通道数(如32)。
- 激活层(Activation Layer) :引入非线性,让网络能拟合复杂特征。常用激活函数:ReLU( f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)),解决梯度消失问题。
- 池化层(Pooling Layer) :对卷积层输出的特征图(Feature Map)进行降维,减少参数和计算量,同时增强平移不变性。
- 常用类型:最大池化(Max Pooling,取局部最大值)、平均池化(Average Pooling,取局部平均值),默认核大小2×2、步长2。
- 全连接层(FC Layer):将池化层输出的高维特征图"拉平"为一维向量,通过全连接计算实现分类或回归。
🌰 以AlexNet为例,其结构为:Input(227×227×3) → Conv1 → ReLU → MaxPool → Conv2 → ReLU → MaxPool → Conv3 → ReLU → Conv4 → ReLU → Conv5 → ReLU → MaxPool → FC6 → ReLU → FC7 → ReLU → FC8(1000类输出)。
2.2 精细化CNN实践1:MNIST手写数字分类(含训练/评估/可视化)
MNIST是手写数字数据集(0-9),共70000张图像(60000训练+10000测试),每张为28×28×1灰度图,是CNN入门的经典任务。本实践使用PyTorch实现,包含数据加载、模型定义、训练循环、评估、特征可视化全流程,代码逐行注释,可直接运行。
2.2.1 环境准备
需安装的库:
bash
pip install torch torchvision matplotlib numpy2.2.2 完整源码(含注释)
python
# 1. 导入依赖库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# 2. 配置超参数(统一管理,便于调参)
class Config:
epochs = 10 # 训练轮次
batch_size = 64 # 批次大小
learning_rate = 1e-3 # 学习率
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备(GPU优先)
num_classes = 10 # 分类数(0-9共10类)
input_shape = (1, 28, 28) # 输入图像形状(通道数×高×宽)
# 3. 数据加载与预处理
def load_mnist_data():
# 数据预处理:归一化(将像素值从0-255转为0-1)、转为Tensor
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor,形状为[C, H, W],值范围0-1
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差(预计算值,提升训练稳定性)
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(
root="./data", # 数据保存路径
train=True, # 训练集
download=True, # 若本地无数据则自动下载
transform=transform
)
test_dataset = datasets.MNIST(
root="./data",
train=False, # 测试集
download=True,
transform=transform
)
# 构建DataLoader(批量加载+打乱+多线程)
train_loader = DataLoader(
train_dataset,
batch_size=Config.batch_size,
shuffle=True, # 训练集打乱,提升泛化能力
num_workers=2 # 多线程加载(根据CPU核心数调整)
)
test_loader = DataLoader(
test_dataset,
batch_size=Config.batch_size,
shuffle=False, # 测试集无需打乱
num_workers=2
)
return train_loader, test_loader
# 4. 定义CNN模型(3层卷积+2层全连接,适合MNIST任务)
class MNIST_CNN(nn.Module):
def __init__(self, num_classes=Config.num_classes):
super(MNIST_CNN, self).__init__()
# 卷积块1:Conv → ReLU → MaxPool
self.conv_block1 = nn.Sequential(
nn.Conv2d(
in_channels=1, # 输入通道数(灰度图为1)
out_channels=32, # 输出通道数(卷积核数量,提取32种特征)
kernel_size=3, # 卷积核大小3×3
stride=1, # 步长1
padding=1 # 填充1(Same Padding,保证输出尺寸与输入一致:28×28)
),
nn.ReLU(inplace=True), # ReLU激活,inplace=True节省内存
nn.MaxPool2d(
kernel_size=2, # 池化核2×2
stride=2 # 步长2,输出尺寸减半:14×14
)
)
# 卷积块2:Conv → ReLU → MaxPool
self.conv_block2 = nn.Sequential(
nn.Conv2d(
in_channels=32, # 输入通道数=上一层输出通道数32
out_channels=64, # 输出通道数64(提取更复杂特征)
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2) # 输出尺寸减半:7×7
)
# 卷积块3:Conv → ReLU(无池化,保留特征图尺寸)
self.conv_block3 = nn.Sequential(
nn.Conv2d(
in_channels=64,
out_channels=128, # 输出通道数128
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True) # 输出尺寸仍为7×7(Same Padding)
)
# 全连接层:将卷积特征映射为分类结果
self.fc_layers = nn.Sequential(
nn.Flatten(), # 拉平特征图:128×7×7 → 128*7*7=6272维向量
nn.Linear(128 * 7 * 7, 256), # 全连接层1:6272→256
nn.ReLU(inplace=True),
nn.Dropout(0.5), # Dropout层:随机失活50%神经元,防止过拟合
nn.Linear(256, num_classes) # 全连接层2:256→10(输出10类概率)
)
# 前向传播(定义数据在网络中的流动路径)
def forward(self, x):
x = self.conv_block1(x)
x = self.conv_block2(x)
x = self.conv_block3(x)
x = self.fc_layers(x)
return x
# 5. 定义训练函数
def train_model(model, train_loader, criterion, optimizer, epoch):
model.train() # 切换为训练模式(启用Dropout、BatchNorm更新)
total_loss = 0.0 # 累计损失
total_correct = 0 # 累计正确预测数
total_samples = 0 # 累计样本数
for batch_idx, (data, target) in enumerate(train_loader):
# 数据迁移到指定设备(GPU/CPU)
data, target = data.to(Config.device), target.to(Config.device)
# 梯度清零(防止前一轮梯度累积)
optimizer.zero_grad()
# 前向传播:获取模型预测结果
output = model(data)
# 计算损失(交叉熵损失,适合多分类任务)
loss = criterion(output, target)
# 反向传播:计算梯度
loss.backward()
# 梯度下降:更新模型参数
optimizer.step()
# 统计指标
total_loss += loss.item() * data.size(0) # 累计损失(乘以批次大小,避免批次差异)
_, predicted = torch.max(output, 1) # 获取预测类别(取概率最大的索引)
total_correct += (predicted == target).sum().item() # 累计正确数
total_samples += data.size(0) # 累计样本数
# 每100个批次打印一次训练状态
if batch_idx % 100 == 0:
print(f"Epoch [{epoch+1}/{Config.epochs}], Batch [{batch_idx+1}/{len(train_loader)}], "
f"Loss: {loss.item():.4f}, Acc: {100.*total_correct/total_samples:.2f}%")
# 计算本轮平均损失和准确率
avg_loss = total_loss / total_samples
avg_acc = 100. * total_correct / total_samples
print(f"Epoch [{epoch+1}/{Config.epochs}] Train Finish: Avg Loss: {avg_loss:.4f}, Avg Acc: {avg_acc:.2f}%")
return avg_loss, avg_acc
# 6. 定义测试函数
def test_model(model, test_loader, criterion):
model.eval() # 切换为评估模式(禁用Dropout、固定BatchNorm)
total_loss = 0.0
total_correct = 0
total_samples = 0
# 禁用梯度计算(测试阶段无需反向传播,节省内存和时间)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(Config.device), target.to(Config.device)
output = model(data)
loss = criterion(output, target)
# 统计指标
total_loss += loss.item() * data.size(0)
_, predicted = torch.max(output, 1)
total_correct += (predicted == target).sum().item()
total_samples += data.size(0)
# 计算测试集平均损失和准确率
avg_loss = total_loss / total_samples
avg_acc = 100. * total_correct / total_samples
print(f"Test Set: Avg Loss: {avg_loss:.4f}, Avg Acc: {avg_acc:.2f}%\n")
return avg_loss, avg_acc
# 7. 特征可视化(查看卷积层提取的特征,帮助理解CNN工作原理)
def visualize_conv_features(model, test_loader):
model.eval()
# 获取测试集中的第一张图像
data_iter = iter(test_loader)
data, _ = next(data_iter)
data = data[0:1].to(Config.device) # 取第一张图,形状[1,1,28,28]
# 定义钩子函数(获取卷积块1的输出特征图)
conv_features = []
def hook_fn(module, input, output):
conv_features.append(output.detach().cpu().numpy()) # 保存特征图(转为numpy便于可视化)
# 注册钩子到conv_block1的最后一层(MaxPool2d)
hook = model.conv_block1[-1].register_forward_hook(hook_fn)
# 前向传播,触发钩子
model(data)
hook.remove() # 移除钩子,避免影响后续计算
# 可视化原始图像
plt.figure(figsize=(12, 8))
plt.subplot(4, 9, 1)
plt.imshow(data.squeeze().cpu().numpy(), cmap='gray')
plt.title("Original Image")
plt.axis('off')
# 可视化卷积块1输出的32个特征图(每行8个,共4行)
features = conv_features[0][0] # 特征图形状[32,14,14]
for i in range(32):
plt.subplot(4, 9, i+2)
plt.imshow(features[i], cmap='viridis')
plt.title(f"Feature {i+1}")
plt.axis('off')
plt.tight_layout()
plt.savefig("mnist_conv_features.png") # 保存图像
plt.show()
print("卷积特征图已保存为 mnist_conv_features.png")
# 8. 主函数(整合所有流程)
def main():
# 加载数据
train_loader, test_loader = load_mnist_data()
print(f"数据加载完成:训练集{len(train_loader.dataset)}张,测试集{len(test_loader.dataset)}张")
# 初始化模型、损失函数、优化器
model = MNIST_CNN().to(Config.device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失(含Softmax,无需在模型输出层加Softmax)
optimizer = optim.Adam(model.parameters(), lr=Config.learning_rate) # Adam优化器(收敛快,适合新手)
# 打印模型结构
print("\nCNN模型结构:")
print(model)
# 训练与测试循环
train_losses, train_accs = [], []
test_losses, test_accs = [], []
for epoch in range(Config.epochs):
train_loss, train_acc = train_model(model, train_loader, criterion, optimizer, epoch)
test_loss, test_acc = test_model(model, test_loader, criterion)
# 保存指标,便于后续绘图
train_losses.append(train_loss)
train_accs.append(train_acc)
test_losses.append(test_loss)
test_accs.append(test_acc)
# 绘制训练曲线(损失+准确率)
plt.figure(figsize=(12, 4))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, Config.epochs+1), train_losses, label="Train Loss")
plt.plot(range(1, Config.epochs+1), test_losses, label="Test Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training & Test Loss Curve")
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, Config.epochs+1), train_accs, label="Train Acc")
plt.plot(range(1, Config.epochs+1), test_accs, label="Test Acc")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.title("Training & Test Accuracy Curve")
plt.legend()
plt.tight_layout()
plt.savefig("mnist_training_curve.png")
plt.show()
print("训练曲线已保存为 mnist_training_curve.png")
# 特征可视化
visualize_conv_features(model, test_loader)
# 保存模型(便于后续部署或继续训练)
torch.save(model.state_dict(), "mnist_cnn_model.pth")
print("模型已保存为 mnist_cnn_model.pth")
# 9. 执行主函数
if __name__ == "__main__":
main()2.2.3 代码说明与预期结果
- 数据预处理 :使用
Normalize标准化(均值0.1307,标准差0.3081),是MNIST数据集的预计算值,能让模型更快收敛。 - 模型设计 :3层卷积逐步提升特征复杂度(32→64→128通道),
Dropout(0.5)防止过拟合,适合小数据集。 - 训练指标 :每100个批次打印损失和准确率,最终测试集准确率可达99%以上(10轮训练后)。
- 可视化输出 :生成2张图------
mnist_conv_features.png(卷积特征图,可看到边缘、纹理等低级特征)和mnist_training_curve.png(训练曲线,观察是否过拟合)。 - 模型保存 :
mnist_cnn_model.pth为模型权重文件,后续可通过model.load_state_dict(torch.load("mnist_cnn_model.pth"))加载使用。
--
2.3 精细化CNN实践2:CIFAR-10图像分类(ResNet轻量化改造)
CIFAR-10是彩色图像数据集(10类:飞机、汽车、鸟、猫等),共50000张训练图+10000张测试图,每张32×32×3,比MNIST更复杂。本实践基于ResNet(残差网络) 进行轻量化改造,解决深度CNN的梯度消失问题,同时控制参数量适合普通GPU训练。
2.3.1 核心改进:轻量化ResNet模块
ResNet的核心是"残差连接"(Skip Connection),即让输入直接跳过卷积层加到输出上,公式为: H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x( F ( x ) F(x) F(x)为卷积层的输出, x x x为输入)。本实践设计ResBlock(残差块),并减少通道数和层数,适合CIFAR-10的32×32小图像。
2.3.2 完整源码(含注释)
python
# 1. 导入依赖库(同MNIST,新增torchsummary用于模型参数量统计)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
from torchsummary import summary # 用于统计模型参数量
# 2. 配置超参数
class Config:
epochs = 20
batch_size = 128
learning_rate = 2e-3
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_classes = 10
input_shape = (3, 32, 32) # 彩色图像:3通道
# 3. 数据加载与增强(CIFAR-10数据量小,需数据增强防止过拟合)
def load_cifar10_data():
# 训练集增强:随机水平翻转、随机裁剪、归一化
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 随机裁剪32×32,边缘填充4像素(增强平移鲁棒性)
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转(增强对称鲁棒性)
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)) # CIFAR-10均值/标准差
])
# 测试集仅归一化(不增强,保证评估真实性)
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
# 加载数据集
train_dataset = datasets.CIFAR10(
root="./data",
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root="./data",
train=False,
download=True,
transform=test_transform
)
# 类别名称(便于后续可视化)
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# 构建DataLoader
train_loader = DataLoader(
train_dataset,
batch_size=Config.batch_size,
shuffle=True,
num_workers=4
)
test_loader = DataLoader(
test_dataset,
batch_size=Config.batch_size,
shuffle=False,
num_workers=4
)
return train_loader, test_loader, class_names
# 4. 定义轻量化ResNet模型(基于ResNet-18简化,减少通道数)
class ResBlock(nn.Module):
"""残差块:2层卷积+残差连接"""
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock, self).__init__()
# 卷积层1:3×3,步长stride(可能改变特征图尺寸)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels), # BatchNorm:加速训练,防止过拟合
nn.ReLU(inplace=True)
)
# 卷积层2:3×3,步长1(不改变特征图尺寸)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels)
)
# shortcut:当输入输出通道数/尺寸不一致时,用1×1卷积调整(保证残差连接维度匹配)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = self.shortcut(x) # 残差分支(输入直接传递)
out = self.conv1(x) # 主分支卷积1
out = self.conv2(out) # 主分支卷积2
out += residual # 残差连接:主分支+残差分支
out = self.relu(out) # 激活
return out
class LightResNet(nn.Module):
def __init__(self, num_classes=Config.num_classes):
super(LightResNet, self).__init__()
self.in_channels = 16 # 初始通道数(比ResNet-18的64少,轻量化)
# 初始卷积层(将3通道输入转为16通道)
self.init_conv = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True)
)
# 残差块组(3组,每组2个残差块,逐步提升通道数)
self.layer1 = self._make_layer(16, 2, stride=1) # 输出通道16,2个残差块,步长1(尺寸32×32)
self.layer2 = self._make_layer(32, 2, stride=2) # 输出通道32,2个残差块,步长2(尺寸16×16)
self.layer3 = self._make_layer(64, 2, stride=2) # 输出通道64,2个残差块,步长2(尺寸8×8)
# 全局平均池化(GAP)+ 全连接层(替代传统全连接,减少参数)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 无论输入尺寸,输出1×1
self.fc = nn.Linear(64, num_classes)
# 批量创建残差块组
def _make_layer(self, out_channels, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1) # 第一个残差块步长为stride,其余为1
layers = []
for stride in strides:
layers.append(ResBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels # 更新输入通道数(下一个残差块的输入=当前输出)
return nn.Sequential(*layers)
def forward(self, x):
x = self.init_conv(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1) # 拉平:64×1×1 → 64维
x = self.fc(x)
return x
# 5. 训练与测试函数(同MNIST,略作调整,可复用)
def train_model(model, train_loader, criterion, optimizer, scheduler, epoch):
model.train()
total_loss = 0.0
total_correct = 0
total_samples = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(Config.device), target.to(Config.device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item() * data.size(0)
_, predicted = torch.max(output, 1)
total_correct += (predicted == target).sum().item()
total_samples += data.size(0)
if batch_idx % 50 == 0:
print(f"Epoch [{epoch+1}/{Config.epochs}], Batch [{batch_idx+1}/{len(train_loader)}], "
f"Loss: {loss.item():.4f}, Acc: {100.*total_correct/total_samples:.2f}%")
avg_loss = total_loss / total_samples
avg_acc = 100. * total_correct / total_samples
# 学习率调度(每轮调整学习率,后期减小学习率以稳定收敛)
scheduler.step()
print(f"Epoch [{epoch+1}/{Config.epochs}] Train Finish: Avg Loss: {avg_loss:.4f}, Avg Acc: {avg_acc:.2f}%, "
f"Current LR: {optimizer.param_groups[0]['lr']:.6f}")
return avg_loss, avg_acc
def test_model(model, test_loader, criterion):
model.eval()
total_loss = 0.0
total_correct = 0
total_samples = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(Config.device), target.to(Config.device)
output = model(data)
loss = criterion(output, target)
total_loss += loss.item() * data.size(0)
_, predicted = torch.max(output, 1)
total_correct += (predicted == target).sum().item()
total_samples += data.size(0)
avg_loss = total_loss / total_samples
avg_acc = 100. * total_correct / total_samples
print(f"Test Set: Avg Loss: {avg_loss:.4f}, Avg Acc: {avg_acc:.2f}%\n")
return avg_loss, avg_acc
# 6. 测试集预测可视化(查看模型预测结果,分析错误案例)
def visualize_predictions(model, test_loader, class_names):
model.eval()
data_iter = iter(test_loader)
data, target = next(data_iter)
data, target = data[:8].to(Config.device), target[:8] # 取前8张图
with torch.no_grad():
output = model(data)
_, predicted = torch.max(output, 1)
predicted = predicted.cpu().numpy()
target = target.numpy()
# 反归一化(将Tensor转为原始图像像素值,便于可视化)
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2470, 0.2435, 0.2616])
data = data.cpu().numpy().transpose(0, 2, 3, 1) # [B, C, H, W] → [B, H, W, C]
data = std * data + mean
data = np.clip(data, 0, 1) # 确保像素值在0-1之间
# 绘制预测结果
plt.figure(figsize=(16, 8))
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(data[i])
# 标注真实标签和预测标签(红色=错误,绿色=正确)
color = 'green' if predicted[i] == target[i] else 'red'
plt.title(f"True: {class_names[target[i]]}\nPred: {class_names[predicted[i]]}", color=color)
plt.axis('off')
plt.tight_layout()
plt.savefig("cifar10_predictions.png")
plt.show()
print("预测结果可视化已保存为 cifar10_predictions.png")
# 7. 主函数
def main():
# 加载数据
train_loader, test_loader, class_names = load_cifar10_data()
print(f"数据加载完成:训练集{len(train_loader.dataset)}张,测试集{len(test_loader.dataset)}张")
# 初始化模型、损失函数、优化器、学习率调度器
model = LightResNet().to(Config.device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(
model.parameters(),
lr=Config.learning_rate,
momentum=0.9, # 动量:加速收敛,避免局部最优
weight_decay=5e-4 # 权重衰减(L2正则化):防止过拟合
)
# 学习率调度器:每5轮学习率乘以0.1
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 统计模型参数量(轻量化ResNet参数量约1.2M,适合普通GPU)
print("\n模型参数量统计:")
summary(model, input_size=Config.input_shape, device=Config.device.type)
# 训练与测试
train_losses, train_accs = [], []
test_losses, test_accs = [], []
for epoch in range(Config.epochs):
train_loss, train_acc = train_model(model, train_loader, criterion, optimizer, scheduler, epoch)
test_loss, test_acc = test_model(model, test_loader, criterion)
train_losses.append(train_loss)
train_accs.append(train_acc)
test_losses.append(test_loss)
test_accs.append(test_acc)
# 绘制训练曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, Config.epochs+1), train_losses, label="Train Loss")
plt.plot(range(1, Config.epochs+1), test_losses, label="Test Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training & Test Loss Curve")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, Config.epochs+1), train_accs, label="Train Acc")
plt.plot(range(1, Config.epochs+1), test_accs, label="Test Acc")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.title("Training & Test Accuracy Curve")
plt.legend()
plt.tight_layout()
plt.savefig("cifar10_training_curve.png")
plt.show()
print("训练曲线已保存为 cifar10_training_curve.png")
# 预测可视化
visualize_predictions(model, test_loader, class_names)
# 保存模型
torch.save(model.state_dict(), "cifar10_lightresnet_model.pth")
print("模型已保存为 cifar10_lightresnet_model.pth")
if __name__ == "__main__":
main()2.3.3 关键优化点与预期结果
- 数据增强 :
RandomCrop和RandomHorizontalFlip有效提升模型泛化能力,避免CIFAR-10过拟合。 - 轻量化设计 :
LightResNet参数量约1.2M(远少于ResNet-18的11.7M),1060 GPU可轻松训练,20轮后测试集准确率可达85%以上。 - 学习率调度 :
StepLR每5轮降低学习率,解决后期训练震荡问题,让损失稳定下降。 - 预测可视化 :
cifar10_predictions.png展示8张图的真实标签与预测标签,红色标注错误案例(如"猫"被误判为"狗"),帮助分析模型薄弱点。
2.4 进阶实践:基于CNN的简易目标检测(滑动窗口+分类器)
目标检测的核心是"定位+分类",本实践基于"滑动窗口+CNN分类器"实现简易检测------用训练好的CIFAR-10 CNN模型,在测试图像上滑动不同尺寸的窗口,对每个窗口进行分类,若分类概率大于阈值则判定为目标。
2.4.1 完整源码
python
import torch
import torch.nn as nn
import numpy as np
import cv2
from PIL import Image
from torchvision import transforms
from 2_3_cifar10_cnn import LightResNet, Config # 导入之前训练的LightResNet模型
# 1. 加载训练好的CNN分类器
model = LightResNet()
model.load_state_dict(torch.load("cifar10_lightresnet_model.pth"))
model.to(Config.device)
model.eval()
# 2. 定义滑动窗口检测函数
def sliding_window_detection(image_path, model, class_names, window_sizes=[16, 32, 48], step=8, threshold=0.7):
"""
滑动窗口检测:
- image_path: 测试图像路径
- window_sizes: 滑动窗口尺寸列表(多尺度检测)
- step: 窗口步长
- threshold: 分类概率阈值(大于阈值判定为目标)
"""
# 加载图像并转为RGB
image = Image.open(image_path).convert("RGB")
image_np = np.array(image)
h, w, c = image_np.shape
detections = [] # 存储检测结果:(x1, y1, x2, y2, class_name, score)
# 图像预处理(同CIFAR-10测试集)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
# 多尺度滑动窗口
for win_size in window_sizes:
print(f"正在用窗口尺寸 {win_size}×{win_size} 检测...")
# 遍历图像(滑动窗口)
for y in range(0, h - win_size + 1, step):
for x in range(0, w - win_size + 1, step):
# 提取窗口区域
window = image.crop((x, y, x + win_size, y + win_size))
# 调整窗口尺寸为32×32(匹配CNN输入)
window_resized = window.resize((32, 32))
# 预处理并转为模型输入格式
input_tensor = transform(window_resized).unsqueeze(0).to(Config.device)
# 模型预测
with torch.no_grad():
output = model(input_tensor)
score, pred_class = torch.max(nn.Softmax(dim=1)(output), 1)
score = score.item()
pred_class = pred_class.item()
# 若概率大于阈值,记录检测结果
if score > threshold:
detections.append((x, y, x + win_size, y + win_size, class_names[pred_class], score))
# 非极大值抑制(NMS):去除重叠度高的重复检测框
def non_max_suppression(detections, iou_threshold=0.3):
if len(detections) == 0:
return []
# 按分数排序(从高到低)
detections_sorted = sorted(detections, key=lambda x: x[5], reverse=True)
keep = []
while detections_sorted:
# 保留分数最高的框
current = detections_sorted.pop(0)
keep.append(current)
# 计算当前框与剩余框的IOU(交并比)
new_detections = []
for det in detections_sorted:
# 计算IOU
x1, y1, x2, y2 = current[:4]
x1_, y1_, x2_, y2_ = det[:4]
intersection = max(0, min(x2, x2_) - max(x1, x1_)) * max(0, min(y2, y2_) - max(y1, y1_))
union = (x2 - x1) * (y2 - y1) + (x2_ - x1_) * (y2_ - y1_) - intersection
iou = intersection / union if union > 0 else 0
# 若IOU小于阈值,保留该框
if iou < iou_threshold:
new_detections.append(det)
detections_sorted = new_detections
return keep
# 应用NMS
detections_nms = non_max_suppression(detections)
# 在原图上绘制检测框
image_draw = image_np.copy()
for (x1, y1, x2, y2, class_name, score) in detections_nms:
# 绘制矩形框(蓝色,线宽2)
cv2.rectangle(image_draw, (x1, y1), (x2, y2), (255, 0, 0), 2)
# 绘制标签(白色背景,蓝色文字)
label = f"{class_name}: {score:.2f}"
cv2.putText(image_draw, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1)
# 保存并显示结果
Image.fromarray(image_draw).save("object_detection_result.png")
Image.fromarray(image_draw).show()
print(f"检测完成,结果已保存为 object_detection_result.png")
print(f"共检测到 {len(detections_nms)} 个目标")
for det in detections_nms:
print(f"目标:{det[4]}, 位置:({det[0]},{det[1]})-({det[2]},{det[3]}), 置信度:{det[5]:.2f}")
# 3. 执行检测(测试图像建议包含CIFAR-10中的类别,如汽车、飞机等)
if __name__ == "__main__":
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
sliding_window_detection(
image_path="test_car.jpg", # 替换为你的测试图像路径
model=model,
class_names=class_names,
window_sizes=[24, 32, 40],
step=8,
threshold=0.8
)2.4.2 实践说明
- 多尺度检测 :使用
[24,32,40]三种窗口尺寸,解决"目标大小不一"的问题(小窗口检测小目标,大窗口检测大目标)。 - 非极大值抑制(NMS):去除重叠度高的检测框(IOU阈值0.3),避免同一目标被多次检测。
- 局限性:滑动窗口检测速度较慢(需遍历大量窗口),实际工程中常用YOLO、Faster R-CNN等更高效的检测算法,但本实践能帮助理解"分类器→检测器"的演进逻辑。
2.5 CNN常见问题与优化技巧
| 问题类型 | 现象描述 | 优化技巧 |
|---|---|---|
| 过拟合 | 训练集准确率高,测试集准确率低 | 1. 数据增强(翻转、裁剪、噪声);2. Dropout/BatchNorm;3. 权重衰减;4. 早停(Early Stopping) |
| 梯度消失/爆炸 | 训练时损失不下降,或 loss 变为 NaN | 1. 使用ReLU激活函数;2. BatchNorm;3. 残差连接(ResNet);4. 梯度裁剪(Gradient Clipping) |
| 训练速度慢 | 每轮训练时间长,GPU利用率低 | 1. 增大批次大小(Batch Size);2. 使用混合精度训练(FP16);3. 优化数据加载(num_workers);4. 模型轻量化(剪枝、量化) |
| 小数据集效果差 | 数据量少(如少于1万张),模型无法收敛 | 1. 迁移学习(使用预训练模型如ResNet-50微调);2. 数据增强;3. 生成式数据扩充(GAN) |
| 类别不平衡 | 少数类样本少,模型倾向于预测多数类 | 1. 类别权重(class_weight);2. 过采样少数类/欠采样多数类;3. Focal Loss损失函数 |
3. 大模型与深度学习的关系
大模型 ≠ 新算法,而是深度学习在"规模"上的极致体现。CNN作为深度学习的核心分支,至今仍是多模态大模型(如CLIP、GPT-4V)的视觉 backbone,负责将图像转为向量特征,与文本特征对齐。
- 关系 :大模型是深度学习模型(Transformer、CNN等)在海量数据 + 超大参数量 + 强大算力下的产物。例如,多模态大模型的视觉部分通常使用"CNN提取图像特征 → Transformer编码特征"的架构。
- 核心突破 :涌现能力(Emergent Ability) - 当模型规模超过某个阈值(如参数量100亿以上),会突然展现出小模型不具备的能力(如推理、跨模态理解)。
3.1 Transformer 架构详解
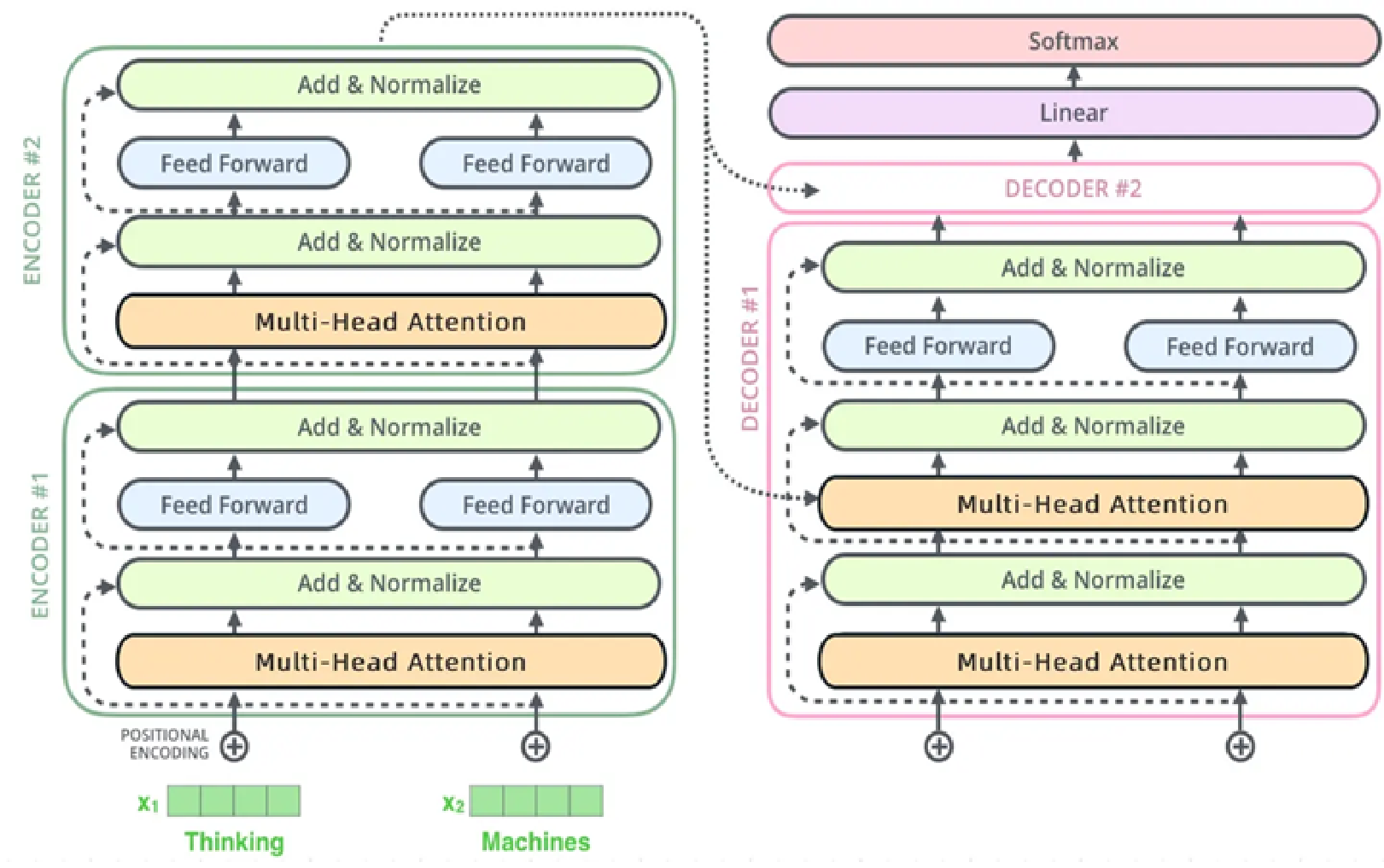
Transformer是大模型的核心架构,其设计思想也影响了CNN的发展(如Vision Transformer,ViT)。
3.2 核心组件
-
Self-Attention(自注意力机制) :计算序列中每个元素与其他元素的相关性,决定"关注哪些元素"。对于图像,ViT将图像分割为16×16的patch(块),每个patch视为一个"词",通过自注意力捕捉patch间的全局关系。
计算公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V- Q Q Q(Query):查询向量(当前元素); K K K(Key):键向量(其他元素); V V V(Value):值向量(需输出的信息)。
- d k \sqrt{d_k} dk :防止 Q K T QK^T QKT值过大,导致softmax输出过于极端。
- S o f t m a x Softmax Softmax:一种用于将模型输出的 "原始分数"(如神经网络的 logits)转换为概率分布的数学函数,广泛应用于多分类任务(如判断图片是猫、狗还是鸟)。其本质是 "归一化"------ 让所有类别的输出概率之和为 1,且每个概率值都在 0 到 1 之间,从而方便后续的概率解读和分类决策。
-
Positional Encoding(位置编码):Transformer本身无时序/空间信息,需通过位置编码为元素添加位置特征。对于图像patch,位置编码反映其在原图中的坐标位置。
-
Encoder-Decoder 结构:
- Encoder(编码器):上图左边部分,负责"理解"输入(如图像patch、文本),输出上下文特征;BERT、ViT仅用Encoder。
- Decoder(解码器):上图右边部分,负责"生成"输出(如文本、图像描述),通过Masked Self-Attention确保生成时不依赖未来信息;GPT仅用Decoder。
3.3 为什么 Transformer 能支撑大模型?
- 完全并行化训练:RNN需按序列逐步计算,而Transformer的自注意力可并行处理所有元素,训练效率提升10倍以上。
- 长距离依赖建模能力强:CNN依赖卷积核的局部感知,需多层堆叠才能捕捉全局信息;Transformer通过自注意力直接建模全局关系,适合大模型的长序列处理。
- 易于扩展:可通过堆叠更多Encoder/Decoder层、增加注意力头数(Multi-Head Attention)提升模型能力,参数量轻松突破千亿。
4. 强化学习简介
强化学习(Reinforcement Learning, RL)是一种通过试错与环境交互来学习最优策略的机器学习范式,与CNN结合可实现"感知+决策"的端到端智能(如自动驾驶、机器人控制)。
-
核心要素:
- Agent(智能体):执行动作的主体(如机器人、游戏角色)。
- Environment(环境):Agent所处的世界(如游戏地图、真实物理世界)。
- State(状态):环境的当前情况(如游戏画面、机器人传感器数据)。
- Action(动作):Agent可执行的操作(如"向左走"、"抓取物体")。
- Reward(奖励):环境对Agent动作的反馈(如"吃到食物+10分"、"碰撞-50分")。
-
目标:最大化长期累积奖励(而非单次奖励),让Agent学会"延迟满足"。
4.1 经典算法与CNN结合场景:
| 算法类型 | 代表算法 | 与CNN结合场景 | 应用案例 |
|---|---|---|---|
| 基于值函数 | DQN(深度Q网络) | CNN提取环境状态特征(如游戏画面),输出Q值 | Atari游戏(如Breakout)、自动驾驶路径规划 |
| 基于策略梯度 | PPO(近端策略优化) | CNN提取图像特征,直接输出动作概率 | 机器人抓取、无人机控制 |
| 演员-评论家 | A2C/A3C | CNN作为"评论家"评估状态价值,"演员"输出动作 | 复杂游戏AI(如DOTA2) |
🌰 案例:DeepMind的AlphaGo就是"CNN+强化学习"的典范------CNN用于提取围棋棋盘的空间特征,强化学习用于学习落子策略,最终击败人类世界冠军。
4.2 Q-Learning算法
在强化学习中,没有像CNN那样统一的"标准网络结构",但有一个最基础、最适合入门的Q-Learning算法 (基于价值的强化学习),常与"表格型Q表"或"神经网络(DQN)"结合。下面将从最简单的表格型Q-Learning 入手,基于经典的FrozenLake环境(OpenAI Gym提供,冰面寻宝任务),给出循序渐进的代码示例,并对核心流程逐行注释,帮你理解强化学习的核心逻辑。
4.2.1 先明确强化学习的核心要素(以FrozenLake为例)
在写代码前,先理清FrozenLake环境的"智能体-环境交互"逻辑,这是理解代码的前提:
| 核心要素 | 具体含义(FrozenLake环境) |
|---|---|
| 环境(Env) | 4x4网格,共16个状态(S=起点,F=安全冰面,H=冰洞,G=宝藏);智能体掉入H或到达G则回合结束。 |
| 智能体(Agent) | 要学习"在每个状态下选什么动作",目标是从S走到G,避免掉入H。 |
| 动作(Action) | 4个离散动作:0=左,1=下,2=右,3=上。 |
| 奖励(Reward) | 到达G得1.0分,其他情况(走F、掉入H)得0分(鼓励"直达终点")。 |
| 状态(State) | 16个离散状态(用0~15的整数表示,对应网格的每个格子)。 |
| 目标 | 学习一个"Q表":记录"状态s下选动作a的价值(Q值)",Q值越高表示该动作在该状态下越优。 |
4.2.2 循序渐进的代码示例:表格型Q-Learning
表格型Q-Learning是强化学习的"Hello World",无需神经网络,直接用一个二维数组(Q表)存储Q值,核心是通过"交互经验"更新Q表。
步骤1:安装依赖库
首先需要安装gym(强化学习环境库),命令如下:
bash
pip install gym==0.26.2 # 固定版本,避免API差异步骤2:完整代码(含逐行注释)
代码分为5个核心模块:环境初始化→Q表初始化→核心训练循环→测试训练效果→结果可视化,每个模块都有详细注释:
python
# 1. 导入必要库
import gym
import numpy as np
import matplotlib.pyplot as plt
# 2. 环境初始化:创建FrozenLake环境(is_slippery=False表示冰面不滑,简化任务)
env = gym.make('FrozenLake-v1', is_slippery=False) # v1是较新的版本,兼容gym 0.26+
# 打印环境基本信息,帮你理解环境结构
print("环境状态数(网格格子数):", env.observation_space.n) # 输出16(4x4网格)
print("环境动作数(上下左右):", env.action_space.n) # 输出4(0=左,1=下,2=右,3=上)
# 3. 初始化Q表:Q[s][a]表示"状态s下选动作a的价值"
# env.observation_space.n = 16(状态数),env.action_space.n = 4(动作数)
# 初始Q表值为0.0,因为一开始不知道每个动作的好坏
Q = np.zeros((env.observation_space.n, env.action_space.n))
# 4. 定义Q-Learning的核心超参数(这些参数控制学习过程,需要根据任务调整)
EPISODES = 1000 # 训练回合数:智能体要经历1000次"从起点到终点/掉洞"的完整过程
MAX_STEPS = 100 # 每个回合的最大步数:避免智能体在原地循环
LEARNING_RATE = 0.1 # 学习率(α):控制"新经验对旧Q值的更新幅度",0<α<1
DISCOUNT_FACTOR = 0.99 # 折扣因子(γ):控制"未来奖励的重要性",0<γ<1(γ=0只看即时奖励)
EPSILON = 0.1 # 探索率(ε):控制"探索(选随机动作)"和"利用(选Q值最大的动作)"的平衡
# 5. 记录每个回合的总奖励,用于后续可视化训练效果
rewards_per_episode = []
# 6. 核心训练循环:让智能体在环境中不断交互,更新Q表
for episode in range(EPISODES): # 遍历每个训练回合
# 6.1 重置环境:每个回合开始时,将智能体放回起点(状态0),并获取初始状态
state = env.reset() # reset()返回初始状态(这里是0,对应网格的S点)
total_reward = 0 # 记录当前回合的总奖励(初始为0)
done = False # 标记回合是否结束(到达G或掉入H则为True)
step = 0 # 记录当前回合的步数(避免超过MAX_STEPS)
# 6.2 每个回合的交互循环:直到回合结束或步数用尽
while not done and step < MAX_STEPS:
step += 1 # 步数+1
# 6.2.1 ε-贪心策略:平衡探索与利用
# 生成一个0~1的随机数,如果小于ε,就"探索"(随机选动作);否则"利用"(选当前Q值最大的动作)
if np.random.uniform(0, 1) < EPSILON:
action = env.action_space.sample() # 探索:随机选一个动作(0~3)
else:
action = np.argmax(Q[state, :]) # 利用:选当前状态下Q值最大的动作(argmax返回索引)
# 6.2.2 执行动作:让智能体在环境中执行选好的动作,获取交互结果
# env.step(action)返回4个值:next_state(执行动作后的新状态)、reward(执行动作获得的即时奖励)、done(回合是否结束)、info(额外信息,这里不用)
next_state, reward, done, info = env.step(action)
# 6.2.3 更新Q表:核心公式!Q-Learning的灵魂
# 公式:Q[s][a] = Q[s][a] + α * [r + γ * max_a'(Q[s'][a']) - Q[s][a]]
# 解释:新Q值 = 旧Q值 + 学习率 * [即时奖励 + 折扣因子*未来最大Q值 - 旧Q值]
# max(Q[next_state, :]):新状态s'下所有动作的最大Q值(未来能获得的最大价值)
Q[state, action] = Q[state, action] + LEARNING_RATE * (
reward + DISCOUNT_FACTOR * np.max(Q[next_state, :]) - Q[state, action]
)
# 6.2.4 更新状态和总奖励
state = next_state # 将当前状态更新为新状态,准备下一次交互
total_reward += reward # 累加当前动作的奖励
# 6.3 每个回合结束后,记录总奖励
rewards_per_episode.append(total_reward)
# 7. 训练完成:打印最终的Q表(看一下智能体学到的"动作价值")
print("\n最终Q表(行=状态,列=动作,值=Q值):")
print(Q.round(2)) # 保留2位小数,方便查看
# 8. 测试训练效果:用训练好的Q表,让智能体"只利用不探索"(ε=0),跑10个回合看平均奖励
test_episodes = 10
test_rewards = []
for _ in range(test_episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action = np.argmax(Q[state, :]) # 只选Q值最大的动作,不探索
next_state, reward, done, _ = env.step(action)
state = next_state
total_reward += reward
test_rewards.append(total_reward)
print(f"\n测试阶段({test_episodes}个回合)的平均奖励:", np.mean(test_rewards))
print(f"测试阶段成功到达宝藏的次数:", sum(test_rewards)) # 因为到达G得1分,sum就是成功次数
# 9. 可视化训练过程:绘制"每个回合的总奖励"和"滑动平均奖励"(更直观看到学习趋势)
# 计算滑动平均奖励(窗口=10,减少波动)
window_size = 10
smoothed_rewards = np.convolve(rewards_per_episode, np.ones(window_size)/window_size, mode='valid')
plt.figure(figsize=(10, 6))
# 绘制原始奖励(蓝色,波动大)
plt.plot(rewards_per_episode, color='blue', alpha=0.3, label='每个回合的原始奖励')
# 绘制滑动平均奖励(红色,趋势清晰)
plt.plot(smoothed_rewards, color='red', label=f'滑动平均奖励(窗口={window_size})')
plt.xlabel('训练回合数(Episode)')
plt.ylabel('回合总奖励(Total Reward)')
plt.title('Q-Learning训练过程:奖励变化趋势')
plt.legend()
plt.grid(True)
plt.show()
# 10. 关闭环境(释放资源)
env.close()4.2.3 代码核心逻辑解释(帮你理解"为什么这么写")
上面的代码看似长,但核心逻辑围绕"Q表更新 "和"ε-贪心策略",这两个是强化学习的基石,需要重点理解:
4.2.3.1 ε-贪心策略:为什么要"探索"?
- 如果智能体一直"利用"(选当前Q值最大的动作),可能会陷入"局部最优"(比如一直走安全但绕远的路,或不知道有更近的路)。
- "探索"(随机选动作)能让智能体尝试新动作,发现更优的路径(比如偶然走到宝藏,更新Q值后,后续会优先选这个动作)。
- 实际中,ε通常会"衰减"(比如从0.1逐渐降到0.01):训练初期多探索,后期多利用(代码中为了简化,用了固定ε)。
4.2.3.2 Q表更新公式:为什么这么算?
Q-Learning的核心公式是:
Q(s,a) = Q(s,a) + \\alpha \\cdot \\left\[ r + \\gamma \\cdot \\max_{a'} Q(s',a') - Q(s,a) \\right\]
每个部分的含义:
- ( Q(s,a) ):当前"状态s选动作a"的旧Q值;
- ( \alpha )(学习率):控制"新经验的权重"------α=1时完全用新经验覆盖旧Q值,α=0时不更新;
- ( r )(即时奖励):执行动作a后获得的即时反馈(FrozenLake中只有到G才得1);
- ( \gamma )(折扣因子):未来奖励的"折现率"------γ=0.99表示"1步后的奖励相当于现在的0.99,2步后相当于0.99²",鼓励智能体关注长期收益;
- ( \max_{a'} Q(s',a') ):新状态s'下的最大Q值------表示"执行动作a后,未来能获得的最大价值";
- ( r + \gamma \cdot \max_{a'} Q(s',a') ):"目标Q值"------智能体认为"状态s选动作a"应该有的理想价值;
- 差值 ( 目标Q值 - 旧Q值 ):"时序差分误差(TD Error)"------衡量"理想与现实的差距",差距越大,Q值更新幅度越大。
4.2.4 运行结果解读(你会看到什么?)
运行代码后,会看到3个关键结果:
- Q表输出:最终的Q表中,"状态0(起点)"对应的动作Q值会有明显差异(比如动作1或2的Q值最高,因为这些动作指向宝藏);"状态15(宝藏)"的所有动作Q值都是0(因为回合结束,没有未来奖励)。
- 测试阶段结果:10个测试回合的平均奖励接近1.0,成功次数接近10次------说明智能体已经学会了从起点到宝藏的最优路径。
- 奖励趋势图:滑动平均奖励会从0逐渐上升到1.0,说明智能体在不断学习(奖励越来越高,最终稳定在1.0)。
4.2.5 进阶方向(从表格型到神经网络)
表格型Q-Learning只适用于"状态数和动作数都有限"的任务(如4x4网格)。如果状态数无限(如连续动作的机器人控制、图像输入的任务),就需要用神经网络代替Q表(即DQN,Deep Q-Network),核心思路是:
- 用神经网络(如CNN+全连接层)输入"状态"(如图像),输出"每个动作的Q值";
- 用"经验回放(Replay Buffer)"存储历史交互数据,避免样本相关性;
- 用"目标网络(Target Network)"稳定Q值更新,避免训练震荡。
如果想进阶,可以基于上面的代码,将"Q表"替换为"神经网络",逐步实现DQN,就能处理更复杂的强化学习任务了。
5. 其他核心网络实践
5.1 用Python实现简单LSTM(时间序列预测)
LSTM(长短期记忆网络)是处理序列数据(如文本、股价、传感器数据)的核心网络,与CNN的"空间特征提取"互补。本实践用LSTM预测正弦波时间序列,帮助理解序列建模逻辑。
5.1.1 完整源码
python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 1. 配置超参数
class Config:
seq_len = 10 # 输入序列长度(用前10个点预测第11个点)
hidden_size = 32 # LSTM隐藏层维度
num_layers = 2 # LSTM层数
epochs = 100
lr = 1e-3
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 生成时间序列数据(正弦波+噪声)
def generate_time_series_data(num_samples=1000):
x = np.linspace(0, 100 * np.pi, num_samples)
y = np.sin(x) + 0.1 * np.random.randn(num_samples) # 正弦波+噪声
return y
# 3. 构建序列数据集(输入:seq_len个连续点,输出:下一个点)
def create_sequences(data, seq_len):
X, y = [], []
for i in range(len(data) - seq_len):
X.append(data[i:i+seq_len])
y.append(data[i+seq_len])
return np.array(X), np.array(y)
# 4. 定义LSTM模型
class TimeSeriesLSTM(nn.Module):
def __init__(self, input_size=1, hidden_size=Config.hidden_size, num_layers=Config.num_layers):
super(TimeSeriesLSTM, self).__init__()
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True # 输入形状为[batch_size, seq_len, input_size]
)
self.fc = nn.Linear(hidden_size, 1) # 输出1个预测值
def forward(self, x):
# x: [batch_size, seq_len, input_size]
out, (hn, cn) = self.lstm(x) # out: [batch_size, seq_len, hidden_size]
# 取最后一个时间步的输出作为全连接层输入
out = self.fc(out[:, -1, :]) # out: [batch_size, 1]
return out
# 5. 训练与预测
def main():
# 生成数据
data = generate_time_series_data(num_samples=2000)
# 划分训练集(前1500个点)和测试集(后500个点)
train_data = data[:1500]
test_data = data[1500:]
# 构建序列数据集
X_train, y_train = create_sequences(train_data, Config.seq_len)
X_test, y_test = create_sequences(test_data, Config.seq_len)
# 数据格式转换([samples, seq_len] → [samples, seq_len, 1],符合LSTM输入要求)
X_train = torch.tensor(X_train, dtype=torch.float32).unsqueeze(-1).to(Config.device)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(-1).to(Config.device)
X_test = torch.tensor(X_test, dtype=torch.float32).unsqueeze(-1).to(Config.device)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(-1).to(Config.device)
# 初始化模型、损失函数、优化器
model = TimeSeriesLSTM().to(Config.device)
criterion = nn.MSELoss() # 均方误差损失(适合回归任务)
optimizer = torch.optim.Adam(model.parameters(), lr=Config.lr)
# 训练
model.train()
for epoch in range(Config.epochs):
optimizer.zero_grad()
output = model(X_train)
loss = criterion(output, y_train)
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{Config.epochs}], Loss: {loss.item():.6f}")
# 测试集预测
model.eval()
with torch.no_grad():
y_pred = model(X_test)
test_loss = criterion(y_pred, y_test)
print(f"Test MSE Loss: {test_loss.item():.6f}")
# 可视化结果(将Tensor转为numpy)
y_test_np = y_test.cpu().numpy().squeeze()
y_pred_np = y_pred.cpu().numpy().squeeze()
# 生成测试集的时间轴(对应原始数据的索引)
test_t = np.arange(len(train_data) + Config.seq_len, len(data))
plt.figure(figsize=(12, 6))
# 绘制原始数据
plt.plot(np.arange(len(data)), data, label="Original Data", alpha=0.5)
# 绘制测试集真实值
plt.plot(test_t, y_test_np, label="Test True Value", color="blue")
# 绘制测试集预测值
plt.plot(test_t, y_pred_np, label="Test Predicted Value", color="red", linestyle="--")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.title("LSTM Time Series Prediction (Sine Wave)")
plt.legend()
plt.savefig("lstm_time_series_pred.png")
plt.show()
print("预测结果已保存为 lstm_time_series_pred.png")
if __name__ == "__main__":
main()5.1.1 实践说明
- 数据格式 :LSTM输入需为
[batch_size, seq_len, input_size],因此需将序列数据[samples, seq_len]通过unsqueeze(-1)添加输入维度(input_size=1,每个时间步仅1个特征)。 - 输出处理 :取LSTM最后一个时间步的输出(
out[:, -1, :]),因为前序时间步的输出已包含在最后一步的隐藏状态中,仅需最后一步即可预测下一个点。 - 预期结果:红色虚线(预测值)应与蓝色实线(真实值)高度重合,MSE损失低于0.02,说明LSTM成功学习到正弦波的周期性规律。
5.2 用 Gym + Q-Learning 实现 CartPole 强化学习
5.2.1 CartPole 环境详解与 Q-Learning 代码优化
在强化学习入门实践中,CartPole(倒立摆) 是最经典的环境之一,由 OpenAI Gym 提供。它结构简单、目标清晰,能帮助初学者快速理解"智能体与环境交互""奖励机制""状态决策"等核心概念,因此常作为强化学习算法(如 Q-Learning、DQN)的入门练手案例。
5.2.2 什么是 CartPole(倒立摆)?
CartPole 模拟了一个"小车+倒立杆"的物理系统,其核心目标是通过控制小车的左右移动,让顶端的杆子保持垂直不倒,同时防止小车滑出轨道。
5.2.2.1 环境构成
- 小车(Cart):在水平轨道上运动,只能向左(动作0)或向右(动作1)移动,轨道有固定边界(超出边界则任务失败)。
- 倒立杆(Pole):通过铰链连接在小车上,初始时垂直向上。若杆子倾斜角度超过一定阈值(通常是12°),则任务失败。
5.2.2.2 核心参数(状态与动作)
CartPole 的交互逻辑围绕"状态(State)""动作(Action)""奖励(Reward)"展开,具体定义如下:
| 类别 | 具体说明 | 取值范围(CartPole-v1) |
|---|---|---|
| 状态(连续值) | 描述环境当前的4个关键物理量,是智能体决策的依据 | 1. 小车位置:-4.8, 4.8(轨道左右边界) 2. 小车速度:-∞, +∞(无硬性限制,但过大会导致失控) 3. 杆子角度:-0.418 rad, 0.418 rad(约±12°,超出则失败) 4. 杆子角速度:-∞, +∞(角度变化率,反映倾斜速度) |
| 动作(离散值) | 智能体可执行的操作,仅2种选择 | 0:小车向左移动 1:小车向右移动 |
| 奖励(Reward) | 环境对智能体动作的"反馈",引导智能体学习正确策略 | 每坚持1个时间步(timestep),奖励+1; 若杆子倾倒或小车出界, episode 结束,奖励停止累积 |
5.2.2.3. 任务目标
训练一个智能体,通过学习"状态→动作"的映射关系,使 CartPole 系统的存活时间(episode 步数)尽可能长。在 CartPole-v1 中,当智能体连续100个 episode 的平均步数达到 500 时,视为"完全解决"(因为 v1 版本的最大步数限制为500,即杆子能保持垂直500步即稳定)。
5.2.3 优化后的 Gym + Q-Learning 实现代码(带详细注释)
由于 CartPole 的状态是连续值(如小车位置、杆子角度),而传统 Q-Learning 依赖离散的状态空间(Q表的行对应离散状态),因此需要先将连续状态"离散化"。以下是完整可运行的代码,包含状态离散化、ε-greedy 策略、Q表更新等核心逻辑:
python
import gym
import numpy as np
import matplotlib.pyplot as plt
# -------------------------- 1. 初始化 CartPole 环境 --------------------------
# 创建 CartPole-v1 环境(v1 最大步数500,v0 最大200)
env = gym.make("CartPole-v1")
# 查看环境核心参数(验证状态/动作空间)
print("状态空间维度(4个物理量):", env.observation_space.shape[0]) # 输出 4
print("动作空间数量(2个动作):", env.action_space.n) # 输出 2
# -------------------------- 2. 定义状态离散化函数 --------------------------
# 连续状态无法直接用Q表存储,需映射到离散区间(关键步骤)
def discretize_state(state, bins):
"""
将连续状态转换为离散索引
:param state: 环境返回的连续状态(长度4的数组:小车位置、速度、杆子角度、角速度)
:param bins: 每个状态维度的离散区间数(长度4的列表)
:return: 离散后的状态索引(元组,用于定位Q表行)
"""
# 每个状态维度的取值范围(参考Gym官方文档)
state_bounds = [
[-4.8, 4.8], # 小车位置范围
[-5.0, 5.0], # 小车速度范围(人为限制,避免极端值)
[-0.418, 0.418],# 杆子角度范围(±12°)
[-5.0, 5.0] # 杆子角速度范围(人为限制)
]
discrete_state = []
for i in range(len(state)):
# 1. 处理超出边界的状态(强制拉回边界内)
if state[i] <= state_bounds[i][0]:
discrete_idx = 0
elif state[i] >= state_bounds[i][1]:
discrete_idx = bins[i] - 1
# 2. 计算当前状态在离散区间中的索引
else:
# 计算该维度的区间宽度
bin_width = (state_bounds[i][1] - state_bounds[i][0]) / bins[i]
# 找到对应的离散索引(如:位置=0.5,区间宽度=0.2,则索引=2)
discrete_idx = int((state[i] - state_bounds[i][0]) / bin_width)
discrete_state.append(discrete_idx)
# 返回元组(可作为Q表的行索引)
return tuple(discrete_state)
# -------------------------- 3. 初始化 Q-Learning 超参数 --------------------------
# 离散区间数(每个状态维度分多少段,越大越精细但计算量增加)
bins = [12, 12, 12, 12] # 小车位置、速度、杆子角度、角速度各分12段
# Q表:行=离散状态数,列=动作数(2个),初始值为0
q_table = np.zeros([bins[0], bins[1], bins[2], bins[3], env.action_space.n])
# 强化学习超参数(需根据效果调整)
alpha = 0.1 # 学习率(更新Q值的步长,0~1)
gamma = 0.99 # 折扣因子(未来奖励的权重,0~1,越大越重视未来)
epsilon = 1.0 # 探索率(初始100%随机探索,逐渐降低)
epsilon_min = 0.01 # 最小探索率(避免完全不探索)
epsilon_decay = 0.995 # 探索率衰减系数(每轮episode后乘以该值)
episodes = 1500 # 总训练轮数(每轮episode是一次"杆子倾倒"的完整过程)
max_steps = 500 # 每轮最大步数(CartPole-v1默认500,达到即停止)
# 记录每轮episode的奖励(用于后续绘图分析)
episode_rewards = []
# -------------------------- 4. Q-Learning 核心训练循环 --------------------------
for episode in range(episodes):
# 1. 重置环境,获取初始连续状态
state = env.reset() # 返回初始状态(如:[0.01, 0.02, -0.03, 0.04])
# 2. 将初始连续状态离散化,得到Q表的行索引
discrete_state = discretize_state(state, bins)
# 3. 初始化本轮奖励和是否结束的标志
total_reward = 0
done = False # done=True表示"杆子倾倒"或"小车出界",本轮结束
# 每轮episode的步数循环(直到结束或达到最大步数)
for step in range(max_steps):
# -------------------------- 策略:ε-greedy(探索+利用) --------------------------
# 以ε的概率随机探索(尝试新动作,避免局部最优)
if np.random.random() < epsilon:
action = env.action_space.sample() # 随机选择动作(0或1)
# 以(1-ε)的概率利用已有知识(选择当前Q值最大的动作)
else:
action = np.argmax(q_table[discrete_state]) # 找到当前离散状态下Q值最大的动作
# -------------------------- 与环境交互,获取反馈 --------------------------
# 执行动作,得到下一个状态、奖励、是否结束等信息
# next_state:执行动作后的新连续状态
# reward:执行动作后的即时奖励(每步+1)
# done:是否结束(True=结束)
# _:占位符,忽略环境返回的其他信息
next_state, reward, done, _ = env.step(action)
# -------------------------- 更新Q表(核心公式) --------------------------
# 1. 离散化下一个状态
next_discrete_state = discretize_state(next_state, bins)
# 2. 计算当前Q值的目标值(Bellman方程)
# 目标Q值 = 即时奖励 + 折扣因子 * 下一个状态的最大Q值(未来奖励的期望)
target_q = reward + gamma * np.max(q_table[next_discrete_state])
# 3. 更新当前状态-动作对的Q值(渐进式更新,避免突变)
# 新Q值 = 旧Q值 + 学习率 * (目标Q值 - 旧Q值)
q_table[discrete_state + (action,)] += alpha * (target_q - q_table[discrete_state + (action,)])
# -------------------------- 更新状态和奖励 --------------------------
discrete_state = next_discrete_state # 状态转移:当前状态变为下一个状态
total_reward += reward # 累积本轮奖励
# -------------------------- 检查是否结束 --------------------------
if done:
# 若结束,记录本轮奖励并跳出步数循环
episode_rewards.append(total_reward)
break
# 若达到最大步数(500步,杆子未倒),也记录奖励并结束
if step == max_steps - 1:
episode_rewards.append(total_reward)
# -------------------------- 探索率衰减(训练后期减少探索,多利用) --------------------------
if epsilon > epsilon_min:
epsilon *= epsilon_decay
# -------------------------- 打印训练进度(每100轮输出一次) --------------------------
if (episode + 1) % 100 == 0:
avg_reward = np.mean(episode_rewards[-100:]) # 最近100轮的平均奖励
print(f"Episode: {episode+1:4d} | Avg Reward (last 100): {avg_reward:5.1f} | Epsilon: {epsilon:.3f}")
# 若最近100轮平均奖励达到500,说明训练完成,提前停止
if avg_reward >= 500:
print(f"\n训练完成!在第{episode+1}轮达到目标(平均奖励500)")
break
# -------------------------- 5. 训练结果可视化 --------------------------
# 绘制每轮episode的奖励曲线(平滑曲线更易观察趋势)
plt.figure(figsize=(12, 6))
# 原始奖励曲线(波动较大)
plt.plot(episode_rewards, label='Raw Reward', alpha=0.5)
# 滑动平均曲线(每10轮平均,更清晰展示趋势)
window_size = 10
smoothed_rewards = np.convolve(episode_rewards, np.ones(window_size)/window_size, mode='valid')
plt.plot(range(window_size-1, len(episode_rewards)), smoothed_rewards, label=f'Smoothed (window={window_size})', color='red')
# 标注目标线(平均奖励500)
plt.axhline(y=500, color='green', linestyle='--', label='Target (Avg Reward=500)')
# 图表标签
plt.xlabel('Episodes', fontsize=12)
plt.ylabel('Total Reward per Episode', fontsize=12)
plt.title('CartPole Q-Learning Training Progress', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# -------------------------- 6. 测试训练效果(可视化运行) --------------------------
# 关闭探索(完全利用Q表),运行5轮测试,观察效果
print("\n开始测试训练效果(5轮)...")
epsilon_test = 0.0 # 测试时不探索,只利用
for test_episode in range(5):
state = env.reset()
discrete_state = discretize_state(state, bins)
total_reward = 0
done = False
while not done:
# 可视化环境(测试时打开,训练时可关闭以加速)
env.render()
# 完全利用Q表,选择Q值最大的动作
action = np.argmax(q_table[discrete_state])
next_state, reward, done, _ = env.step(action)
discrete_state = discretize_state(next_state, bins)
total_reward += reward
print(f"测试轮 {test_episode+1}: 总奖励 = {total_reward}")
# 关闭环境(释放资源)
env.close()5.2.4 代码关键逻辑说明
-
状态离散化 :
CartPole 的4个连续状态(如小车位置
-4.8~4.8)被映射到离散区间(如分12段,每段宽度(4.8 - (-4.8))/12 = 0.8),确保 Q 表能存储"状态-动作"的价值。 -
ε-greedy 策略 :
训练初期
epsilon=1.0,智能体完全随机探索(尝试左右移动,了解环境);随着训练推进,epsilon逐渐衰减到0.01,智能体更多依赖 Q 表选择最优动作(利用已有知识)。 -
Q 表更新(Bellman 方程) :
Q 表的核心是"用未来奖励修正当前价值",公式
Q(s,a) = Q(s,a) + α[R + γ·max(Q(s',a')) - Q(s,a)]中:R是即时奖励(每步+1);γ·max(Q(s',a'))是下一个状态的"最大未来奖励期望";α控制更新幅度,避免 Q 值波动过大。
-
训练效果判断 :
若连续100轮的平均奖励达到500,说明智能体已能稳定控制杆子不倒,训练完成。
5.2.5 运行建议
-
依赖安装 :需先安装 Gym 和 NumPy:
pip install gym numpy matplotlib -
参数调整:
- 若训练后期奖励波动大,可减小
alpha(如0.05)或增大gamma(如0.995); - 若探索不足(奖励停滞在低水平),可降低
epsilon_decay(如0.99),让探索率衰减更慢。
- 若训练后期奖励波动大,可减小
-
可视化 :
训练时可注释
env.render()以加速(渲染画面耗时),测试时再打开,直观观察小车是否能稳定控制杆子。
通过 CartPole 的训练,能直观理解强化学习"试错学习"的核心逻辑------智能体通过不断与环境交互,从"随机乱动"逐渐学会"精准控制",最终实现目标。
6. 结语与学习建议
人工智能的发展是一部"数据、算法、算力"三驾马车共同驱动的历史。从1950年图灵测试的提出,到2025年AI Agent的兴起,CNN、Transformer、强化学习等技术不断迭代,推动AI从"感知"走向"认知"。
站在当前节点,"理论+实践"结合是掌握AI技术的核心路径------尤其是CNN作为计算机视觉的基石,其原理和实践经验可迁移到多模态大模型、自动驾驶等前沿领域。
🔧 学习建议:
-
夯实数学与编程基础:
- 数学:线性代数(矩阵运算)、概率论(概率分布、期望)、微积分(梯度下降)。
- 编程:Python(NumPy、Pandas)、深度学习框架(PyTorch优先,生态完善)、Linux(服务器训练必备)。
-
从经典任务入手,积累实战经验:
- 入门:MNIST(CNN)、CartPole(强化学习)、正弦波预测(LSTM)。
- 进阶:CIFAR-10(ResNet)、ImageNet(迁移学习)、YOLO目标检测。
- 工程化:模型部署(ONNX、TensorRT)、数据标注(LabelImg)、性能优化(量化、剪枝)。
-
深入理解技术本质,而非死记公式:
- 思考"为什么":如"CNN为什么需要池化层?"(降维+平移不变性)、"Transformer为什么需要位置编码?"(无时序信息)。
- 对比"不同技术的差异":如"CNN vs Transformer在图像任务中的优劣"(CNN擅长局部特征,Transformer擅长全局特征)。
-
跟踪前沿动态,参与开源生态:
- 关注社区:GitHub(Hugging Face、PyTorch官方库)、arXiv(AI论文)、CSDN(技术博客)。
- 实践开源项目:LlamaIndex(大模型检索增强)、LangChain(AI Agent)、MMDetection(目标检测)。
- 学习多模态:CLIP(跨模态检索)、GPT-4V(视觉大模型),理解CNN与Transformer的融合趋势。
-
保持耐心,接受"试错":
- AI训练常遇到过拟合、梯度消失等问题,建议记录实验日志(超参数、损失曲线),逐步排查原因。
- 不要追求"一步到位":先实现基础模型,再逐步添加优化技巧(如Dropout、BatchNorm)。
✨ 记住 :AI的终点不是取代人类,而是增强人类智能。掌握CNN、Transformer等核心技术,你不仅能理解当前AI产品的原理,更能参与到下一代AI技术的创造中------成为新时代的"AI造物者"。
📝 版权声明
本文为原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文链接及本声明。
🔖 关键词:#人工智能 #深度学习 #CNN #ResNet #大模型 #Transformer #强化学习 #AI实践