你是否也曾有过这样的感觉?每天被无尽的任务和琐事推着走,像一个陀螺般不停旋转,却鲜有时间静下来,审视自己的脚步,规划未来的道路。我们设定年度目标,却在日复一日的忙碌中将其遗忘;我们渴望记录生活的点滴,却被繁琐的操作劝退。
市面上的规划平台林林总总,但它们似乎总有缺憾:要么功能零散,无法形成闭环;要么界面臃肿,喧宾夺主;要么就是高昂的订阅费用,让人望而却步。
"如果能有一个完全为自己量身定制的平台就好了。"这个想法在我脑中萦绕许久。一个集"月度视图"、"年度目标管理"、"每日复盘"、"进度可视化"、"生活随想记录"和"好友共同打卡"于一体的数字中枢。
恰逢最近,字节跳动发布了专为"代理式编程(Agentic Coding)"深度优化的代码大模型------"Doubao-Seed-Code"。这激发了我将想法付诸实践的决心:何不借助这股AI的东风,亲手为自己打造一个完美的规划平台?毕竟,只有自己才最了解自己的需求。

这篇文章,将是我这段旅程的全景记录。我将通过"Doubao-Seed-Code",从概念设计到最终部署在云服务器上,完整地构建这个平台。这将是一篇篇幅很长、细节极多的实战教程。我会尽量省去一些冗余的基础操作,将最核心的思考、指令、代码和踩坑经验呈现给大家。
准备好了吗?让我们一起来看看,豆包小姐姐这次,又学到了什么新本事。
一、前期工具准备:利其器,方能善其事
在正式动工之前,我们需要准备好称手的工具。这就像一位剑客,在决斗前必须要擦亮自己的剑。我们的"剑",就是高效的服务器管理工具和强大的AI编程伙伴。
1.1 服务器连接与管理:HexHub
既然我们的平台需要提供多用户交互功能,并且要能随时随地访问,那么将它部署在云服务器上是必然选择。而在本地与云服务器之间进行高效、直观的文件传输和命令执行,一款优秀的SSH客户端必不可少。
在这里,我推荐 HexHub。它不仅界面现代、功能强大,而且对个人用户非常友好。
直通链接: https://www.hexhub.cn/

安装过程与普通软件无异,一路"下一步"即可。这里唯一要提醒新手朋友的是,养成良好习惯,尽量不要将软件安装在C盘,以保持系统盘的纯净和高效。
安装完成后,我们立刻用它连接到自己的云服务器上。不要在本地电脑上进行后续的开发环境搭建,那样在部署时会遇到无数环境不一致的麻烦。我们要做的是,从一开始就在真实的生产环境(或与之高度相似的开发环境)中进行操作。
打开HexHub,点击新建连接。
连接配置非常直观,最核心的信息只有两项:
- Host: 你云服务器的公网IP地址。
- Password: 你服务器root账户或指定用户的密码。
其他选项如端口(默认22)、用户名(默认root)等,根据你服务器的实际情况填写。
点击连接,我们就成功登陆到了云服务器的命令行界面。接下来所有的操作,都将在这里展开。
1.2 AI编程大脑:Doubao-Seed-Code
这就是我们本次项目的主角。它不是一个软件,而是一个强大的代码模型,是我们实现"Agentic Coding"(代理式编程)的核心。
什么是代理式编程? 简单来说,就是我们不再逐行编写代码,而是像一位项目经理一样,向一个高度智能的"AI程序员代理"下达清晰、结构化的指令,由它来完成任务规划、代码生成、文件操作甚至调试纠错。Doubao-Seed-Code正是在长上下文理解、任务规划、代码生成与调试方面都表现卓越的模型。
直通链接: 火山方舟 Doubao-Seed-Code
要使用它,我们需要完成几个准备步骤。
步骤一:订阅火山方舟Coding Plan
调用大模型API是需要计算资源的,因此会产生费用。火山方舟提供了两种计费模式:按Token量计费的API调用,以及套餐模式的Coding Plan。
- API调用:用多少算多少,适合轻量级、偶尔的调用。
- Coding Plan:提供月度套餐,包含海量的Token,更适合我们这种需要持续、大量交互的复杂项目开发。
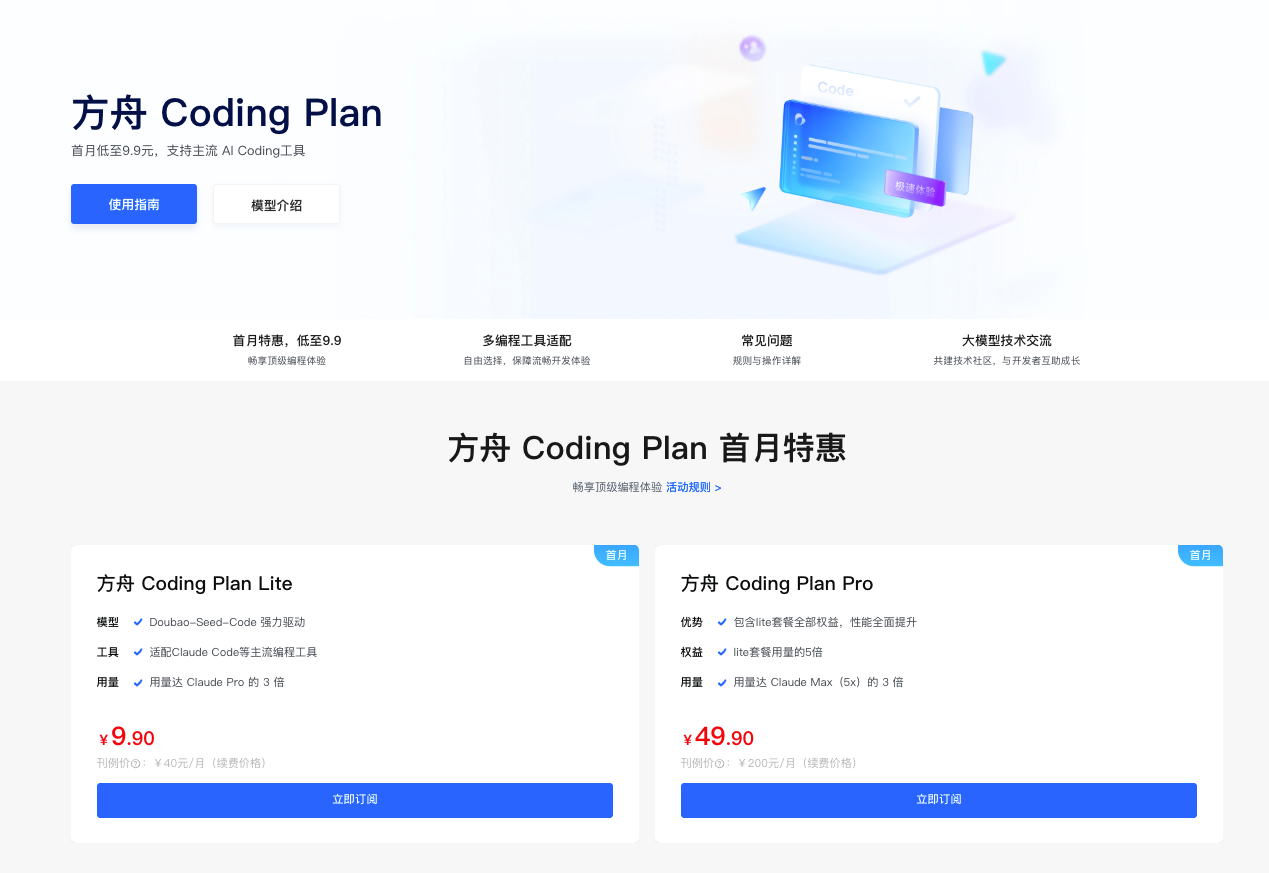
考虑到我们要做的是一个完整的全栈项目,交互频繁且复杂,选择一个Lite版本的Coding Plan无疑是性价比最高的选择。它能提供足够的Token让我们挥霍,而不必在下达指令时畏手畏脚。从上图可以看到,Lite套餐对于开发者极其友好,首月仅需9.9元,续费也仅40元/月。
步骤二:配置本地编程工具
Doubao-Seed-Code的强大之处在于它能与多种主流编程工具无缝集成,如Cursor、VS Code插件、以及各种命令行工具(CLI)。本次实战,我们将采用其官方兼容的命令行工具 Claude Code (cc) ,这能让我们在服务器终端里丝滑地与AI进行交互。
安装前提:
- Git: 我们的服务器上需要安装Git。
- Node.js: 需要安装18或更高版本的Node.js环境。Claude Code是基于Node.js开发的。
让我们一步步在服务器上配好环境。
- 安装基础工具 (Git, curl等)
首先,更新系统的软件包索引,并安装一些编译和网络工具,这是一个好习惯。
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git build-essential libssl-dev- 安装Node.js
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境。它让JavaScript这门原本只能在浏览器中运行的语言,得以在服务器端大展拳脚。我们后端的服务,就将基于Node.js来构建。
我们使用NodeSource的官方脚本来安装较新版本的Node.js(这里选择20.x版本)。
curl -sL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt-get install -y nodejs安装完成后,检查一下版本,确保安装成功。
node -v- 安装npm
npm (Node Package Manager) 是Node.js的包管理器,是世界上最大的软件注册表。我们项目中需要用到的所有第三方库(比如Web框架、数据库驱动等),都将通过npm来安装和管理。通常,安装Node.js时会自动附带安装npm。
检查一下npm版本:
npm -v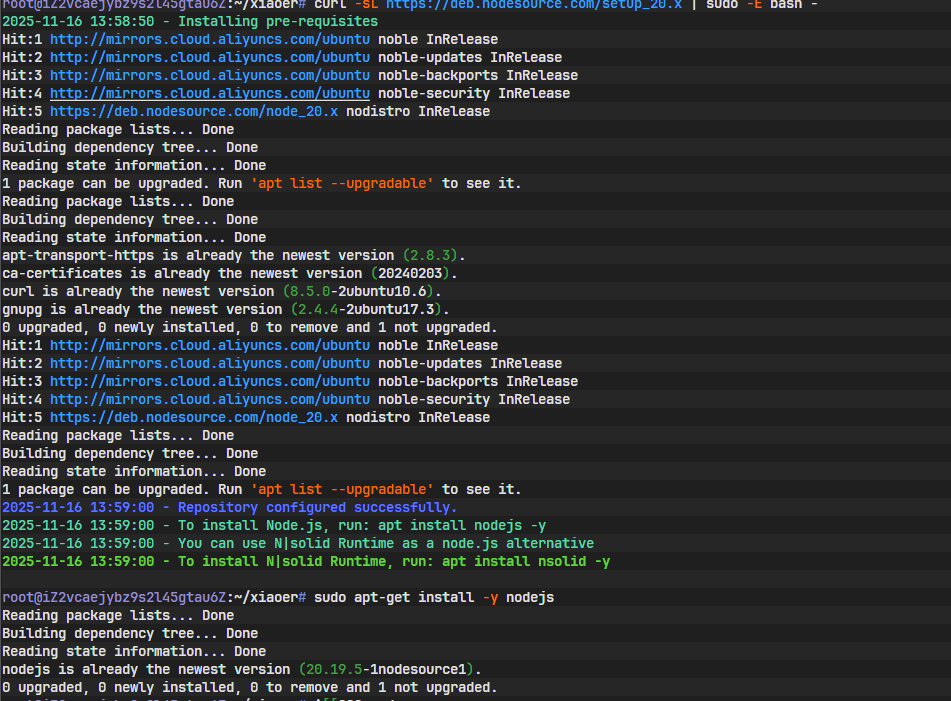
看到版本号输出,证明我们的基础环境已经就绪。
- 安装Claude Code (cc)
现在,我们使用npm的全局安装功能(-g参数)将Claude Code命令行工具安装到服务器中。
npm install -g @anthropic-ai/claude-code
安装成功后,理论上我们就可以在终端里使用claude或cc命令了。
步骤三:配置API密钥与环境变量
要让Claude Code工具知道"它应该去调用谁"以及"它凭什么去调用",我们需要配置三个关键的环境变量。这一步至关重要。
首先,我们需要从火山方舟的控制台获取API密钥。
官方链接: https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey?apikey={}
在该页面,你可以创建一个新的API密钥。请注意:这个密钥非常敏感,相当于你账户的密码,绝对不要泄露给任何人。
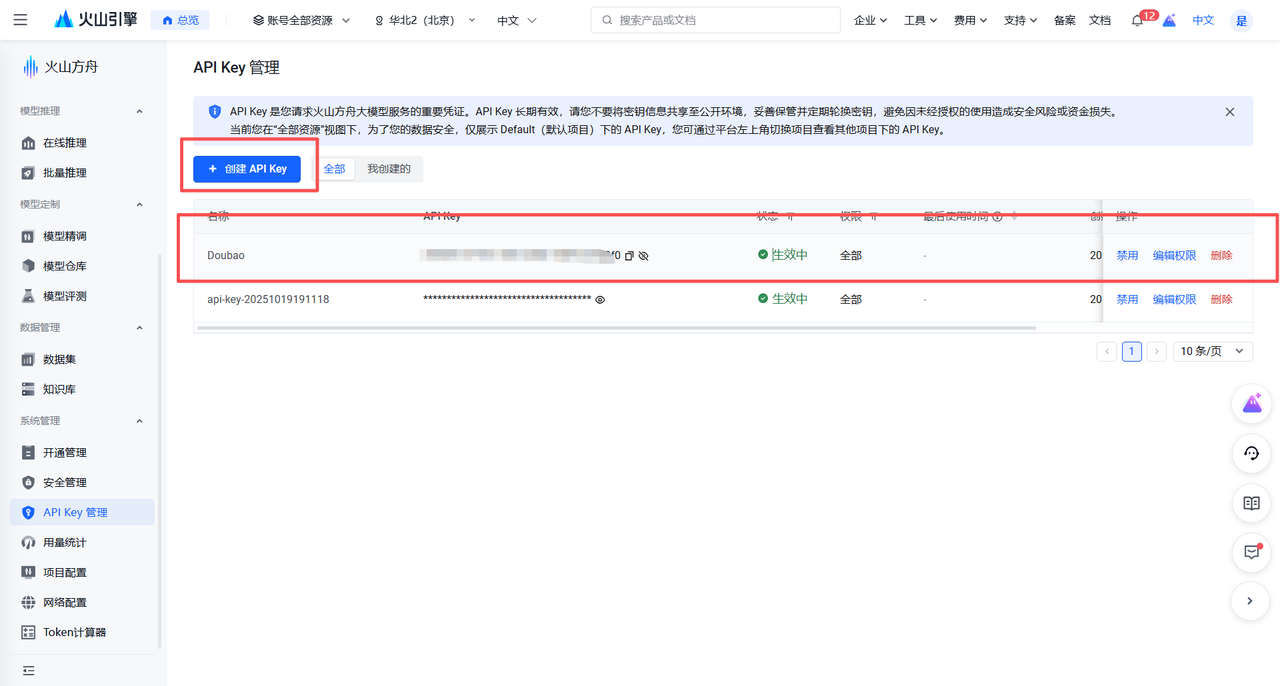
拿到密钥后,我们需要将它和服务地址、模型名称设置为系统的环境变量。这样,Claude Code工具启动时就会自动读取这些配置。
我们使用echo命令将配置信息追加到~/.bashrc文件中。这个文件是Bash shell的个人初始化脚本,每次你登录或打开一个新的终端时,这里面的命令都会被执行。
# 1. 设置API的基础URL,指向火山方舟的Doubao-Seed-Code服务
echo 'export ANTHROPIC_BASE_URL="https://ark.cn-beijing.volces.com/api/coding"' >> ~/.bashrc
# 2. 设置认证Token,也就是你的API密钥
echo 'export ANTHROPIC_AUTH_TOKEN="[这里替换成你的新API密钥]"' >> ~/.bashrc
# 3. 设置要使用的模型名称
echo 'export ANTHROPIC_MODEL="doubao-seed-code-preview-latest"' >> ~/.bashrc切记,将第二条命令中的 [这里替换成你的新API密钥]替换成你刚刚创建的真实密钥。
配置写入后,还不会立刻生效。我们需要执行source命令,让当前的终端会话重新加载~/.bashrc文件。
source ~/.bashrc为了验证配置是否成功,可以使用env命令查看当前所有的环境变量,并用grep筛选出我们关心的那几项。
env | grep ANTHROPIC
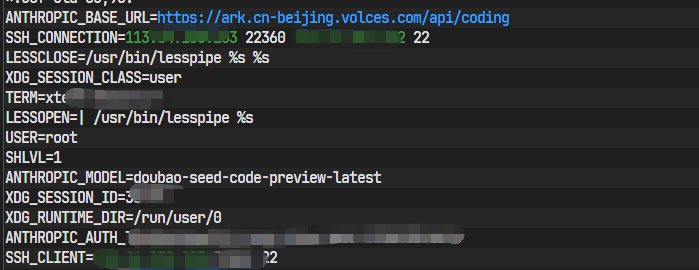
claude或者简写为 cc。
当你看到这个熟悉的界面,以及一个等待你输入的提示符时,恭喜你!你已经成功唤醒了沉睡在你服务器中的AI编程大脑。
我们可以简单地问它一个问题,比如"你是谁?",来验证一下网络通信和模型调用是否都正常。
它给出了清晰的回答,确认了自己是Anthropic开发的AI助手(Doubao-Seed-Code兼容其API)。至此,我们的前期工具准备工作全部完成。我们的剑已经磨砺锋利,接下来,是时候绘制我们的战斗蓝图了。
二、项目分析过程:谋定而后动
在敲下第一行代码之前,一次缜密的分析和设计是项目成功的基石。这不是一个简单的静态网页,而是一个涉及用户、数据、交互的复杂系统。我们必须先规划好蓝图,才能精准地指导AI进行施工。
2.1 项目概述
- 项目名称 (暂定): Life Dashboard / 时光序 / 目标罗盘
- 一句话定位: 一个集目标设定、进度追踪、日常记录与社交激励于一体的个人主页平台。通过月视图、进度条、年度图谱等方式,让用户清晰地看到自己的时间分配、目标进展和生活轨迹。
2.2 核心功能模块拆解
这是项目的灵魂。我们需要将最初那些模糊的想法,转化为具体、可实现的功能模块。
- 核心仪表盘 (Dashboard / 主页)
-
作用: 用户登录后第一眼看到的页面,是所有核心信息的聚合中枢。
-
包含内容:
- 今日待办/打卡项:最直接的行动指引。
- 当前主要目标的进度条概览:时刻提醒自己最重要的事。
- 月视图小组件:高亮显示今天,并直观展示本月概况。
- 快速入口:一键触达最常用的功能,如"写总结"、"记生活"。
- 年度目标 (Annual Goals)
-
功能: 辅助用户设定、分解和追踪那些需要长期坚持才能实现的宏大目标。
-
具体实现:
-
目标设定: 用户可以创建"年度目标",例如"学会Python"、"减重10公斤"、"阅读20本书"。
-
目标分解 (WBS - Work Breakdown Structure): 这是关键!一个无法被分解的目标只是一个空想。我们需要一个层级结构来管理它:
- 年度目标 -> 季度里程碑 -> 月度计划 -> 具体任务(Task) 。
- 举例: 年度目标"减重10公斤"可以被分解为 -> (Q1: 减重3公斤) -> (1月: 每周运动3次,控制饮食) -> (具体任务: 周一跑步5公里, 周三游泳1小时, 周五力量训练)。
-
关联性: 底层任务的完成状态,需要能自动向上反馈,更新上级计划、里程碑乃至最终年度目标的进度。
-
- 规划进度条 (Planning Progress Bar)
-
功能: 这是"年度目标"模块最直观的可视化呈现方式。
-
具体实现:
- 在每一个目标、里程碑、计划的旁边,都应该有一个清晰的进度条。
- 进度计算方式 :可以基于子任务完成数量 (例如10个任务完成了5个,进度50%),也可以在未来升级为基于权重(不同任务的难度和重要性不同)的计算方式。
- 可视化形式:除了经典的横向进度条,未来还可以考虑引入环形进度图、甘特图等更丰富的形式。
- 月视图 (Month View)
-
功能: 以日历的形式,宏观地展示每日的状态和关键事件,帮助用户回顾和发现自己的行为模式。
-
具体实现:
-
日历框架: 我们不需要从零造轮子。可以使用成熟的前端日历组件库 (如 FullCalendar.js, vue-simple-calendar 等)。
-
信息聚合:
- 在每个日期格子上,可以通过不同颜色或小图标,简洁地显示当天的情绪标签 (如😀/😐/😭)、完成的关键任务数 、打卡状态等。
- 点击某个日期,可以弹出一个浮层或跳转到新页面,展示该日详细的"每日总结"和"生活记录"。
-
筛选与高亮: 提供筛选功能,让用户可以只查看特定类型的事件,例如"所有运动打卡日"、"所有写了总结的日子"。
-
- 每日总结 (Daily Summary)
-
功能: 每日复盘,沉淀思考,这是个人成长的核心驱动力。
-
具体实现:
- 富文本编辑器: 支持Markdown或所见即所得(WYSIWYG)的编辑器,方便用户进行格式化的记录。
- 模板化: 提供一些经典的总结模板,引导用户进行高质量的思考。例如"三件好事 (3 Good Things)"、"今日成就"、"遇到的问题与反思"、"明日计划"。
- 标签系统: 用户可以为每篇总结打上标签,如
#工作,#学习,#感悟。这极大地便利了日后的回顾和检索。 - 情绪追踪: 允许用户在写总结时,选择一个表情或评分来标记当天的情绪,数据积累后可以形成情绪曲线图。
- 记录生活 (Life Logging)
-
功能: 相比于结构化的"每日总结",这是一个更自由、更多媒体形式的生活记录板块,像一个私密的个人朋友圈。
-
具体实现:
- 时间线 (Timeline): 以时间流的形式,从近到远展示所有记录。
- 多媒体支持: 不仅限于文字,还应允许用户上传图片、短视频、外部链接等。
- 事件类型: 可以预定义不同类型的事件,如"旅行"、"聚会"、"看电影"、"里程碑事件",并用不同的图标在时间线上加以区分。
- 地图视图: (高级功能) 如果记录包含地理位置信息,可以在地图上展示自己的足迹,生成年度旅行地图。
- 共同打卡 (Group Check-in)
-
功能: 引入轻社交元素,利用同伴压力(Peer Pressure)和互相鼓励的氛围,增加坚持下去的动力。
-
具体实现:
-
打卡项创建: 用户可以创建自己的习惯打卡项,如"早起"、"健身"、"学英语",并设置频率(每日、每周几次等)。
-
小组/好友系统:
- 用户可以创建私密小组,邀请志同道合的好友加入,共同完成一个打卡目标。
- 或者直接与已有的好友,共同参与同一个公共的打卡项。
-
打卡日历: 在小组内部,成员可以看到彼此的打卡记录(例如,一个绿色的点代表已打卡),形成互相监督和鼓励的氛围。
-
排行榜与激励: 可以设置"连续打卡天数"排行榜,或者提供简单的点赞、评论功能,增加互动性。
-
三、 技术架构选型 (建议)
蓝图已经绘制完成,接下来需要选择合适的材料和工具来建造这座大厦。一个经典、成熟的前后端分离架构是我们的最佳选择。
-
前端 (Frontend): 负责貌美如花,呈现界面,处理用户交互。
- 框架: Vue 3。它以其平缓的学习曲线、优秀的性能和活跃的社区生态而著称,非常适合快速启动项目。
- UI 库: Element Plus (基于Vue 3)。它提供了一整套高质量的UI组件(按钮、表单、弹窗等),可以让我们不必在基础样式上花费过多精力,专注于业务逻辑。
- 状态管理: Pinia。Vue 3官方推荐的状态管理库,相比Vuex更轻量、更直观,对TypeScript的支持也更友好。
- 图表/日历库: ECharts (图表), FullCalendar.js 或 vue-simple-calendar (日历)。
-
后端 (Backend): 负责内在实力,处理业务逻辑,操作数据库。
-
语言/框架: Node.js (Express) 。既然前端使用了JavaScript生态的Vue,后端选择Node.js可以实现技术栈的统一,降低开发者的心智负担。Express是一个极简而灵活的Node.js Web应用框架,是构建RESTful API的绝佳选择。
-
核心职责:
- 提供RESTful API或GraphQL API供前端调用。
- 处理用户认证与授权,JWT (JSON Web Tokens) 是当前最流行的无状态认证方案。
- 负责所有业务逻辑的实现(数据的增、删、改、查)。
-
-
数据库 (Database): 负责数据的持久化存储。
- 关系型数据库 (主选): MySQL 8 或 PostgreSQL。我们的应用数据,如用户、目标、任务、总结之间,存在清晰的关联关系,非常适合使用关系型数据库来存储。
- 缓存数据库: Redis (可选,后期优化用)。用于缓存热点数据(如用户Session、频繁读取的配置),可以极大地提升应用的响应性能。
-
服务器与部署 (Deployment): 负责让应用在云端稳定运行。
- 云服务器: 阿里云ECS / 腾讯云CVM等,初期选择1核2G或2核4G的配置完全足够。
- 操作系统: Ubuntu / CentOS,主流的Linux发行版。
- Web服务器: Nginx。它是一个高性能的HTTP和反向代理服务器。在我们的架构中,它将扮演多个角色:托管前端静态文件、反向代理后端API请求(解决跨域问题)、配置HTTPS证书等。
- 容器化: Docker 和 Docker Compose 。强烈推荐! 这是现代Web开发的必备技能。通过Docker,我们可以将前端、后端、数据库、Nginx分别打包成独立、标准化的容器。而Docker Compose则可以一键编排、启动和管理所有这些容器,彻底解决"在我电脑上明明是好的"这类环境依赖问题。
- CI/CD (持续集成/持续部署): (高级) 可以使用Gitee/GitHub Actions, Jenkins等工具,实现代码提交后自动触发测试、构建和部署,实现开发流程的自动化。
四、 开发路线图 (MVP - 最小可行产品)
一口吃不成胖子。面对如此多的功能规划,我们必须采用迭代开发的思路,先实现一个"核心单机版本",即MVP(Minimum Viable Product),让产品能最快地跑起来,然后再逐步完善。
-
第一阶段:核心单机版 (MVP)
- 用户系统: 实现最基础的注册、登录功能。
- 年度目标: 实现目标的创建和简单的树状分解 (年度 -> 任务)。
- 每日总结: 实现基本的富文本记录和按日期查看。
- 月视图: 能在日历上简单地标记出哪天写了总结。
- 目标进度条: 实现基于子任务完成情况的简单进度条。
- 目标: 先让自己能用起来,验证核心流程是否通顺。
-
第二阶段:功能完善与体验优化
- 生活记录: 增加图片上传和时间线展示功能。
- 月视图增强: 在日历上聚合更多信息(如情绪、打卡状态等)。
- 模板化: 为每日总结增加预设模板功能。
- UI/UX 优化: 打磨界面细节,让交互更流畅,视觉更美观。
-
第三阶段:社交功能上线
- 好友/小组系统: 实现添加好友、创建小组的功能。
- 共同打卡: 实现打卡项的创建、加入和状态同步。
- 消息通知: (可选) 当好友打卡或评论时有简单的实时通知。
-
第四阶段:高级功能与扩展
- 数据统计与可视化: 生成年度报告、月度报告,分析用户的时间分配、情绪波动等。
- 搜索功能: 实现全局内容搜索(总结、目标、生活记录)。
- 第三方集成: (可选) 如将日历同步到Google Calendar,或从其他应用导入数据。
- 移动端适配: 优化在手机浏览器上的显示效果,甚至考虑打包成PWA(渐进式网络应用)。
本次实战,我们的目标就是完成第一阶段:构建一个坚实、可用的"核心单机版 (MVP)"。
五、正式实操流程:AI,开工!
前期工具和环境已经准备就绪,项目蓝图也清晰了。现在,让我们正式开始,通过对 Claude(也就是 Doubao-Seed-Code 的命令行工具)下达精确的指令,一步步构建我们规划平台的"核心单机版 (MVP)"。
最终技术栈选型(确认版):
- 前端: Vue 3 (使用 Vite 作为构建工具)
- 后端: Node.js + Express
- 数据库: MySQL 8
- ORM: Sequelize (一个强大的Node.js ORM库,让我们可以用面向对象的方式操作数据库)
- 部署: Docker + Docker Compose
5.1 给 Claude 的第一组指令:初始化项目结构
我们的第一步是创建项目的基础骨架。我们将采用前后端分离的模式,所以需要一个主目录,内部包含 backend 和 frontend 两个子目录。
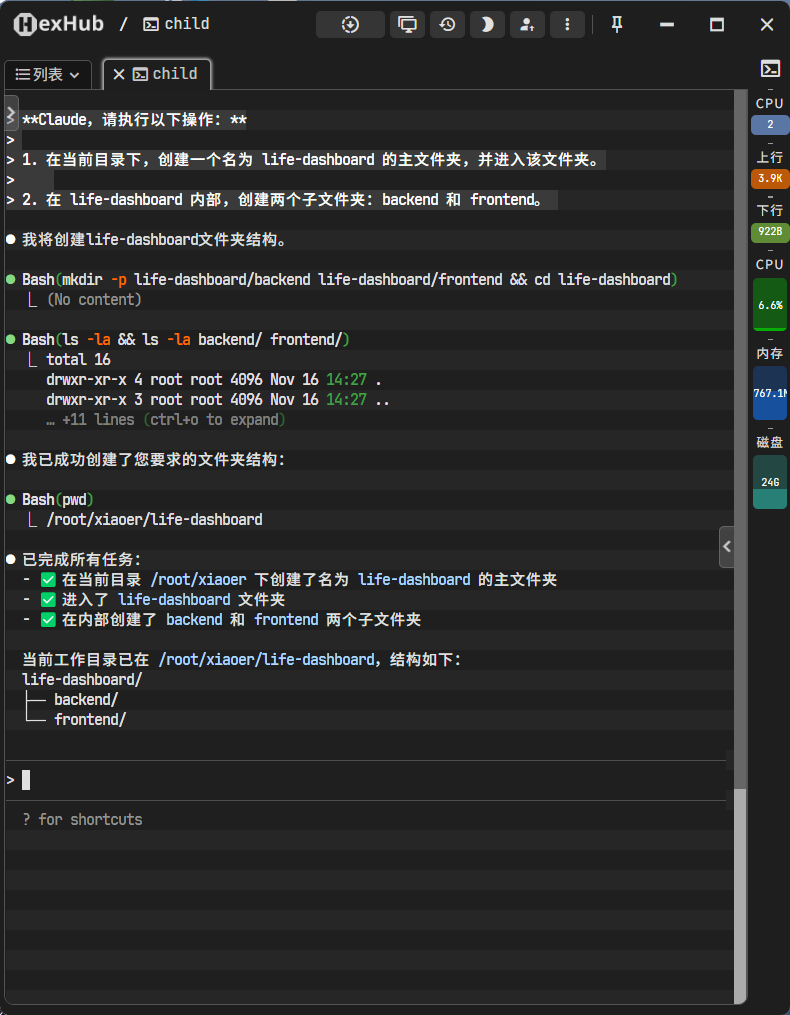
Claude,请执行以下操作:
- 在当前目录下,创建一个名为
life-dashboard的主文件夹,并进入该文件夹。 - 在
life-dashboard内部,创建两个子文件夹:backend和frontend。
AI迅速地理解了指令并执行了文件操作。
5.2 后端开发 (Backend)
现在,我们将专注于后端服务的搭建。我们将一步步引导AI完成初始化、安装依赖、创建文件结构和编写核心代码。
Claude,进入 backend 目录,并开始构建我们的 Node.js 服务:
步骤 1: 初始化 Node.js 项目并安装核心依赖
-
执行
npm init -y初始化一个新的 Node.js 项目,生成package.json文件。 -
使用 npm 安装以下核心依赖:
express: 用于构建 Web 服务器和 API 的框架。mysql2: 连接 MySQL 数据库的驱动。sequelize: 一个强大的 ORM (对象关系映射) 工具,用于简化与数据库的交互。jsonwebtoken: 用于生成和验证 JWT (JSON Web Tokens),以实现用户认证。bcryptjs: 用于对用户密码进行哈希加密,确保安全。cors: 用于处理跨域资源共享。dotenv: 用于管理环境变量。
-
同时,安装
nodemon作为开发依赖,它可以在代码文件发生变化时自动重启服务器。
AI开始执行npm install命令。
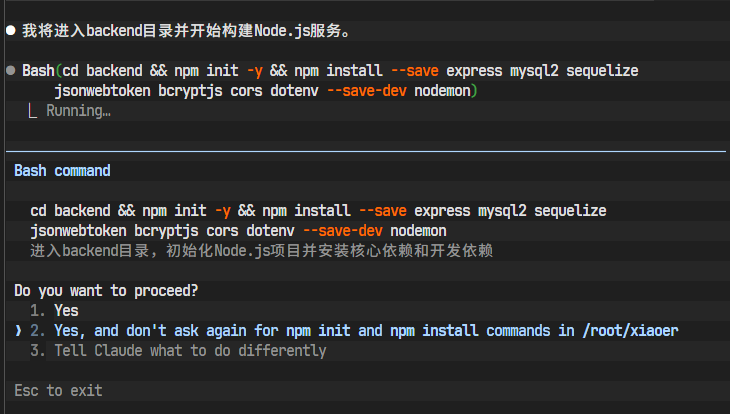
所有依赖被成功下载并添加到package.json文件中。
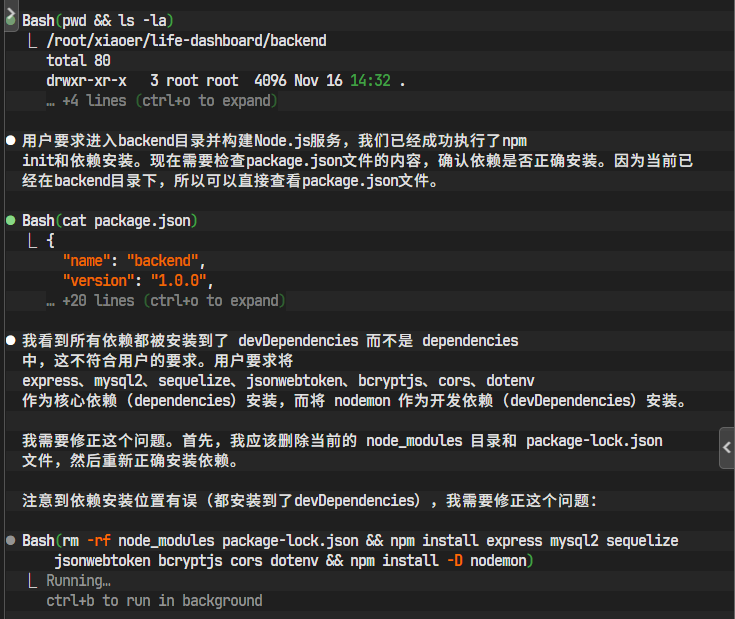
在开发过程中,我们难免会遇到一些小问题。比如,AI在某个步骤的执行可能不完全符合预期。这时,我们需要及时进行人工干预或引导。如下图所示,我发现AI的某个操作偏离了轨道,便立即向它发出修正指令,引导其回到正确的路径上。这正是"代理式编程"中人机协作的体现。
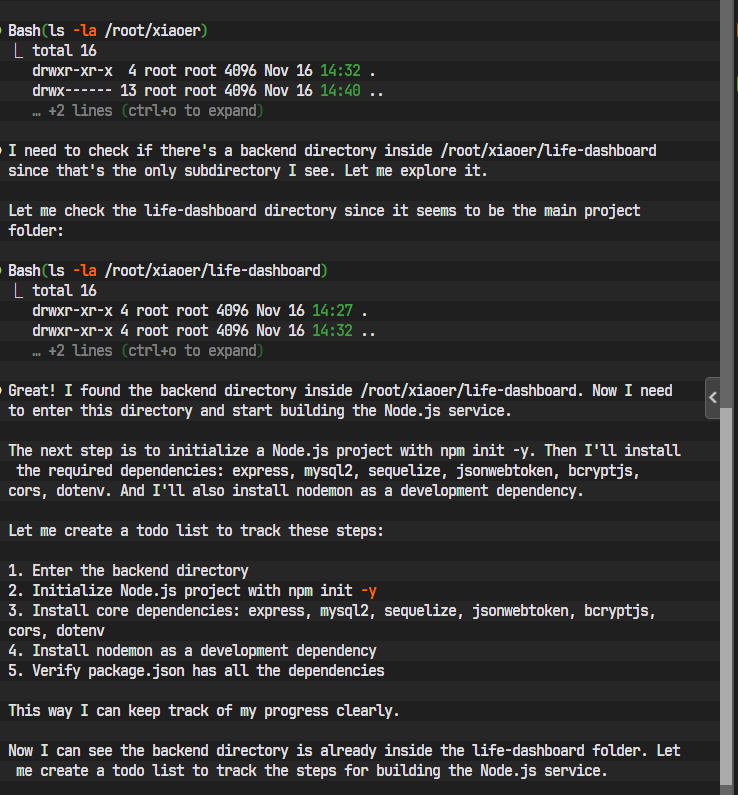
步骤 2: 创建项目结构和入口文件
一个清晰的文件结构是项目可维护性的关键。我们将采用经典的MVC(Model-View-Controller)分层思想来组织代码。
请在 backend 目录下创建以下文件和文件夹结构:
/backend
|-- /config
| |-- config.json # 数据库连接配置
|-- /controllers
| |-- userController.js # 用户注册和登录逻辑
| |-- goalController.js # 年度目标逻辑
| |-- summaryController.js # 每日总结逻辑
|-- /middleware
| |-- authMiddleware.js # JWT 认证中间件
|-- /models
| |-- index.js # Sequelize 模型加载和关联
| |-- user.js # 用户数据模型
| |-- goal.js # 目标数据模型
| |-- summary.js # 总结数据模型
|-- /routes
| |-- authRoutes.js # 认证相关的路由
| |-- goalRoutes.js # 目标相关的路由
| |-- summaryRoutes.js # 总结相关的路由
|-- .env # 环境变量文件
|-- server.js # 应用主入口文件AI精准地创建了我们指定的每一个文件和文件夹。
这个过程可能需要AI执行多条命令,我们需要耐心等待,并在它完成后进行核查。
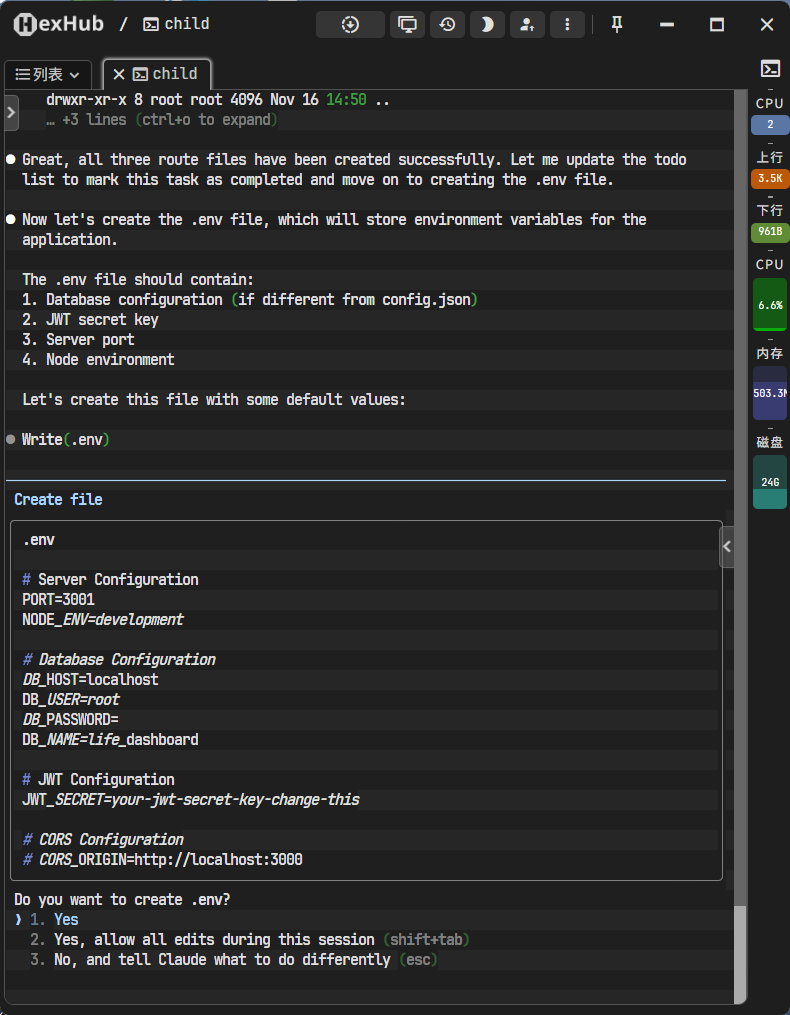
最终,通过ls -R命令递归查看目录,确认所有文件都已各就各位。
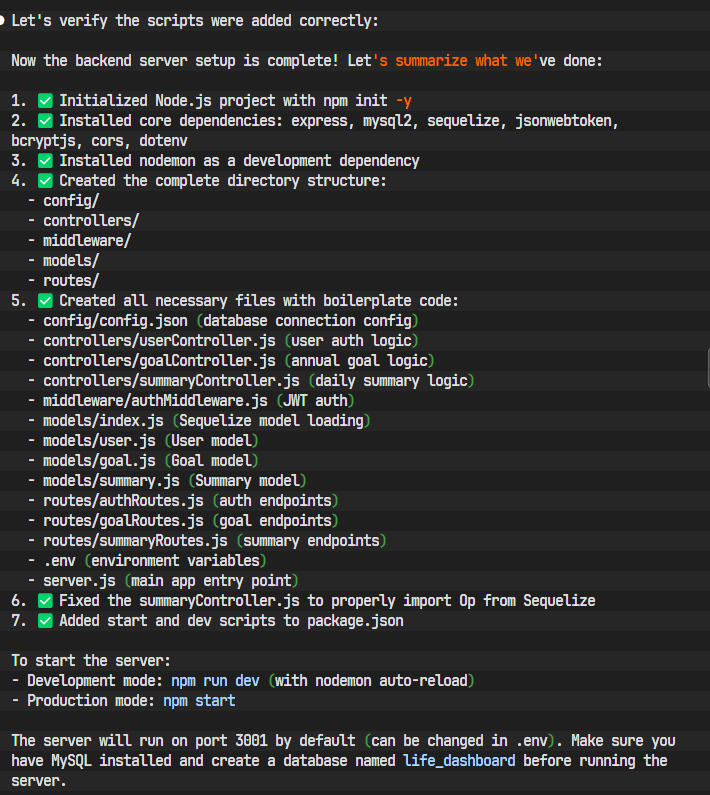
步骤 3: 编写核心代码
现在,到了最激动人心的环节------让AI用代码填充我们创建的骨架。
Claude,请根据以下逻辑填充核心文件:
-
server.js:- 引入
express,cors和所有路由文件。 - 设置
cors和express.json()中间件。 - 定义API的基础路径 (如
/api),并挂载所有路由。 - 连接数据库并启动服务器,监听指定端口(例如 3000)。
- 引入
-
/models目录:- 使用
sequelize定义User,Goal, 和Summary模型。 - User : 包含
username和password字段。 - Goal : 包含
title,description,status,userId(外键) 等字段。 - Summary : 包含
content,date,userId(外键) 等字段。 - 在
index.js中设置模型之间的关联:一个用户 (User) 可以有多个目标 (Goals) 和多个总结 (Summaries)。
- 使用
-
/controllers/userController.js:register: 使用bcryptjs哈希用户密码,创建新用户并存入数据库。login: 验证用户名和密码,如果成功,则使用jsonwebtoken生成一个包含用户ID的token并返回。
-
/middleware/authMiddleware.js:- 创建一个中间件函数,用于保护需要登录才能访问的路由。
- 它会检查请求头中的
Authorization字段(通常是Bearer <token>),验证JWT的有效性。如果有效,则将用户信息附加到请求对象上,否则返回401未授权错误。
-
/controllers(goalController 和 summaryController) :- 为目标和总结分别实现创建 (Create)、读取 (Read)、更新 (Update)、删除 (Delete) (CRUD) 的基本逻辑。
- 确保在创建和查询时,都与当前登录用户的
userId相关联(该ID从authMiddleware附加到请求对象上获取)。
-
/routes目录:- 为每个功能模块(auth, goals, summaries)创建Express路由。
- 例如,在
goalRoutes.js中,POST /会指向goalController.create,GET /会指向goalController.getAll。 - 在需要保护的路由上(如所有
goalRoutes和summaryRoutes),应用我们创建的authMiddleware。
AI开始高速生成代码,并填充到对应的文件中。我们可以实时看到它正在编辑哪个文件,以及生成的代码片段。
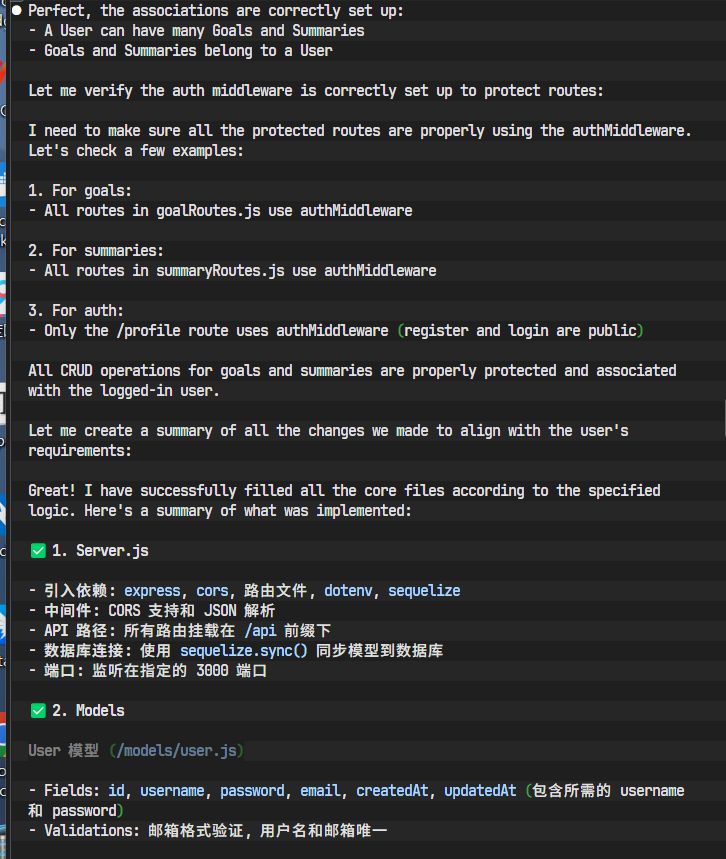
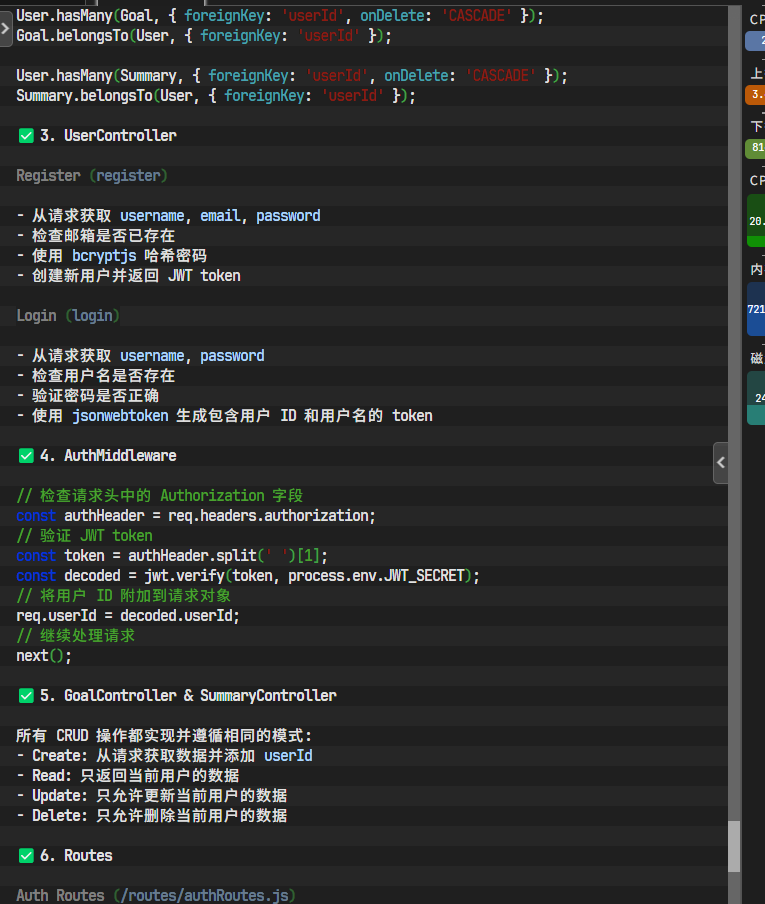
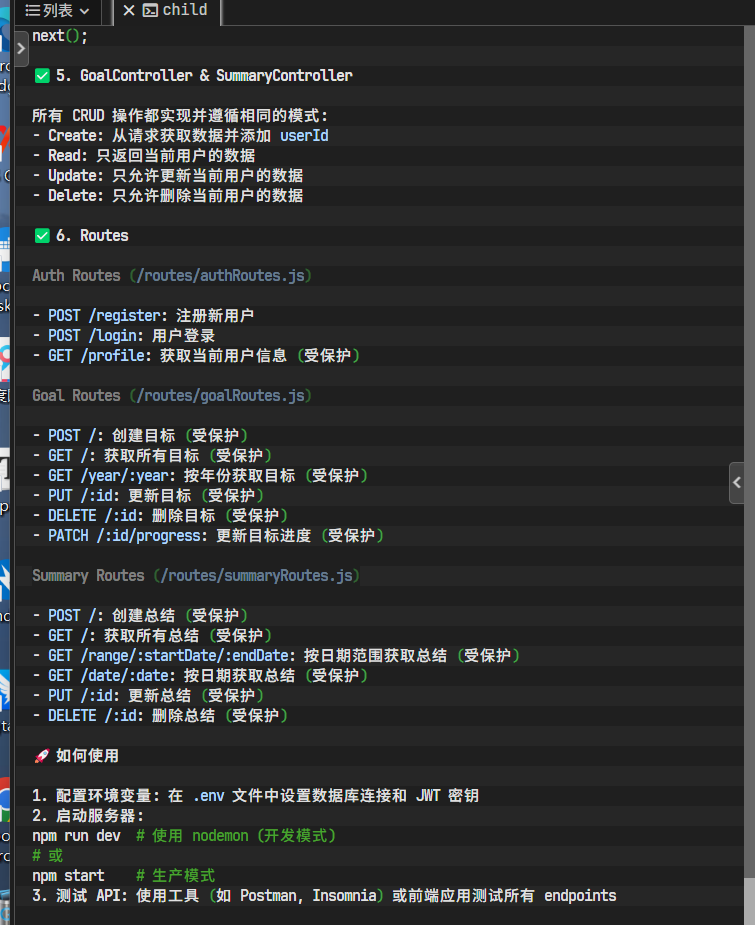
至此,我们后端服务的MVP版本API已经全部编写完成。
5.3 前端开发 (Frontend)
后端的API已经准备就绪,现在我们转向用户直接交互的界面部分。
Claude,现在请切换到 frontend 目录,并开始构建 Vue 3 应用:
步骤 1: 创建 Vue 项目并安装依赖
-
使用 Vite 创建一个 neuen Vue 3 项目:
npm create vite@latest . -- --template vue。 -
安装项目依赖
npm install。 -
安装额外的依赖:
axios: 用于向后端 API 发送 HTTP 请求。vue-router: 用于处理前端路由,实现单页面应用(SPA)。pinia: 用于状态管理,比如存储用户信息和 token。vue-simple-calendar: 一个轻量级的日历组件,用于月视图。
AI开始执行Vite项目的创建命令。
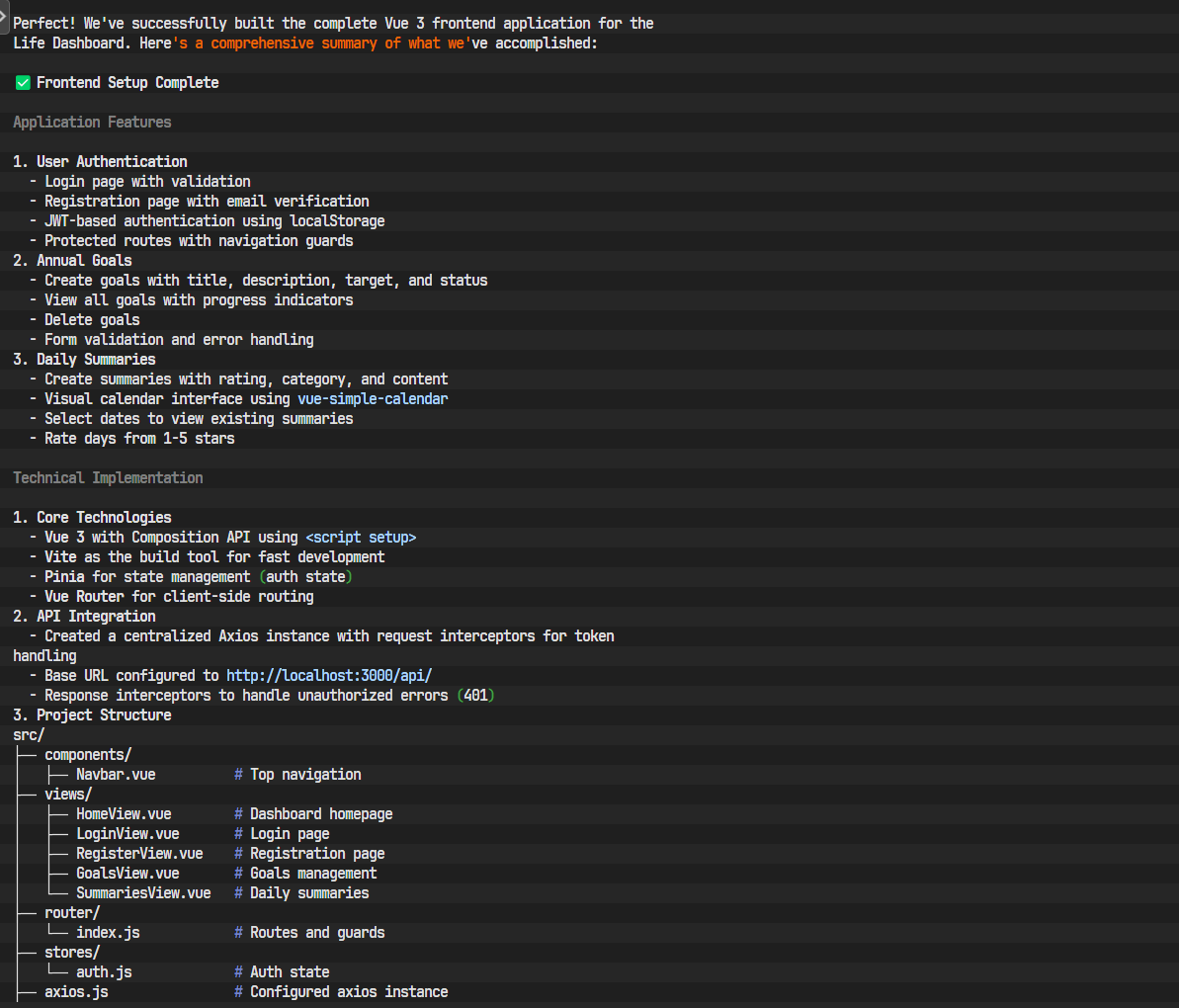
接着,安装所有必需的第三方依赖库。
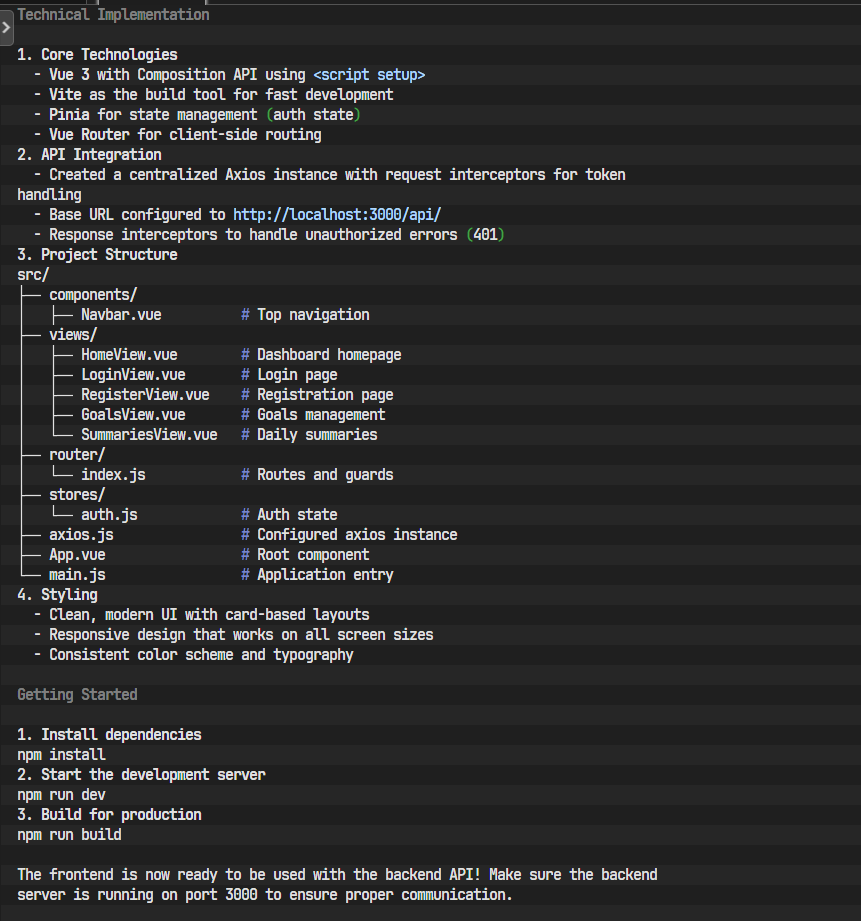
步骤 2: 设计前端结构
与后端类似,一个清晰的前端文件结构同样重要。
请在 frontend/src 目录下创建以下文件和文件夹结构:
/frontend/src
|-- /assets # 静态资源 (CSS, images)
|-- /components # 可复用的小组件
| |-- AnnualGoal.vue
| |-- DailySummary.vue
| |-- MonthView.vue
|-- /router
| |-- index.js # 路由配置
|-- /services
| |-- api.js # Axios 实例和 API 请求封装
|-- /stores
| |-- auth.js # Pinia store 用于认证
|-- /views # 页面级组件
| |-- Dashboard.vue
| |-- Login.vue
| |-- Register.vue
|-- App.vue
|-- main.jsAI再次展示了其强大的文件操作能力。
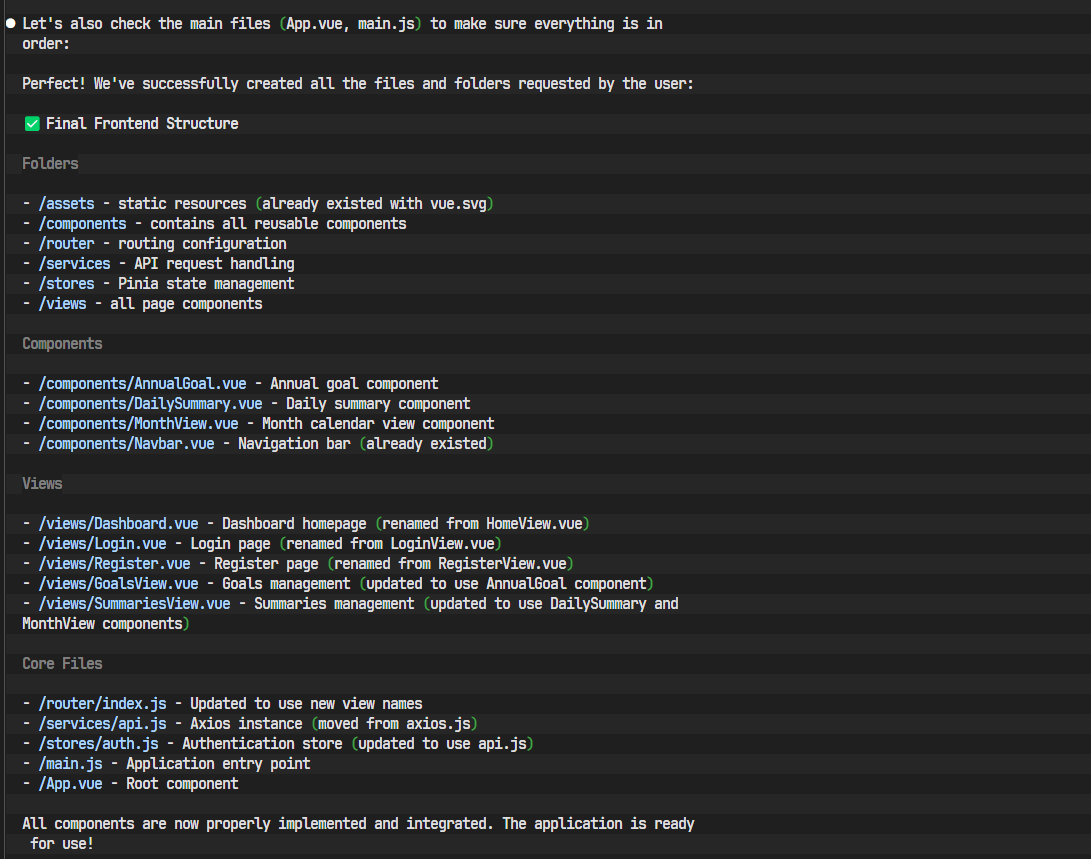
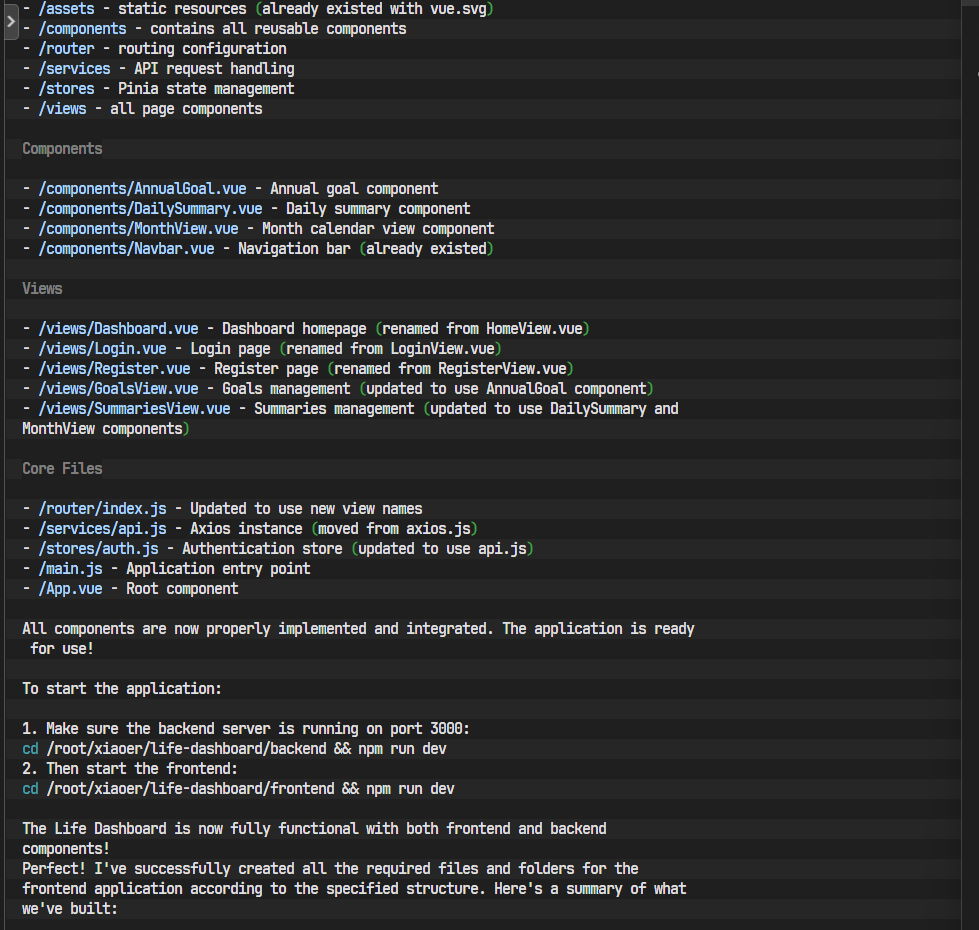
步骤 3: 编写前端核心代码
Claude,请根据以下逻辑填充核心文件:
-
main.js: 引入并使用createApp,router, 和pinia,将它们挂载到Vue应用实例上。 -
/router/index.js:- 配置路由,包括
/login,/register和/dashboard。 - 设置路由守卫(Navigation Guard):在进入
/dashboard之前,检查 Pinia store 中是否存在有效的 token。如果没有,则重定向到/login页面,实现登录保护。
- 配置路由,包括
-
/stores/auth.js:- 使用 Pinia 创建一个
authstore。 - 定义 state (如
user,token) 和 actions (如login,logout,register)。 loginaction 会调用 API 服务,成功后将 token 存入 state 和浏览器的localStorage(以便刷新页面后保持登录状态)。
- 使用 Pinia 创建一个
-
/services/api.js:- 创建一个 Axios 实例,配置基础 URL (指向后端服务,如
http://localhost:3000/api)。 - 添加请求拦截器(Request Interceptor),在每个发送出去的请求的头部(Header)自动附加JWT,
Authorization: Bearer <token>。
- 创建一个 Axios 实例,配置基础 URL (指向后端服务,如
-
/views(Login.vue, Register.vue) : 创建包含用户名和密码输入框的表单,并将表单提交事件绑定到authstore 的相应 action。 -
/views/Dashboard.vue:- 作为登录后的主页面,它将聚合其他核心组件。
- 在此页面的
onMounted生命周期钩子中,调用 API 获取当前用户的年度目标和每日总结数据。 - 引入并使用
MonthView.vue,AnnualGoal.vue,DailySummary.vue组件,并将获取到的数据通过 props 传递给它们。
-
/components/MonthView.vue:- 使用
vue-simple-calendar组件。 - 将从父组件传入的"每日总结"数据处理成日历所需的事件格式,在有总结的日期上进行标记。
- 使用
-
/components/AnnualGoal.vue和DailySummary.vue:- 分别负责展示目标列表和总结列表。
- 提供输入框和按钮,让用户可以创建新的目标和总结,并调用相应的 API 进行提交,成功后再刷新列表。
AI开始编写Vue组件代码。
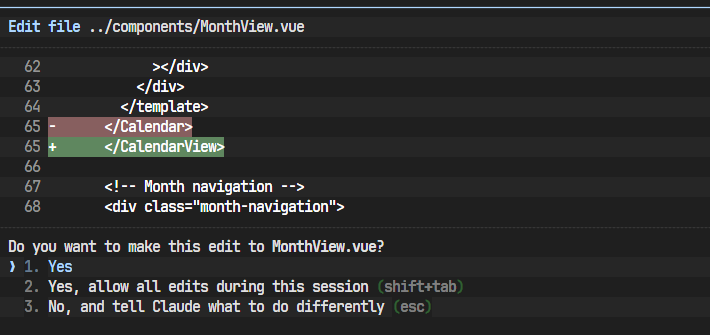
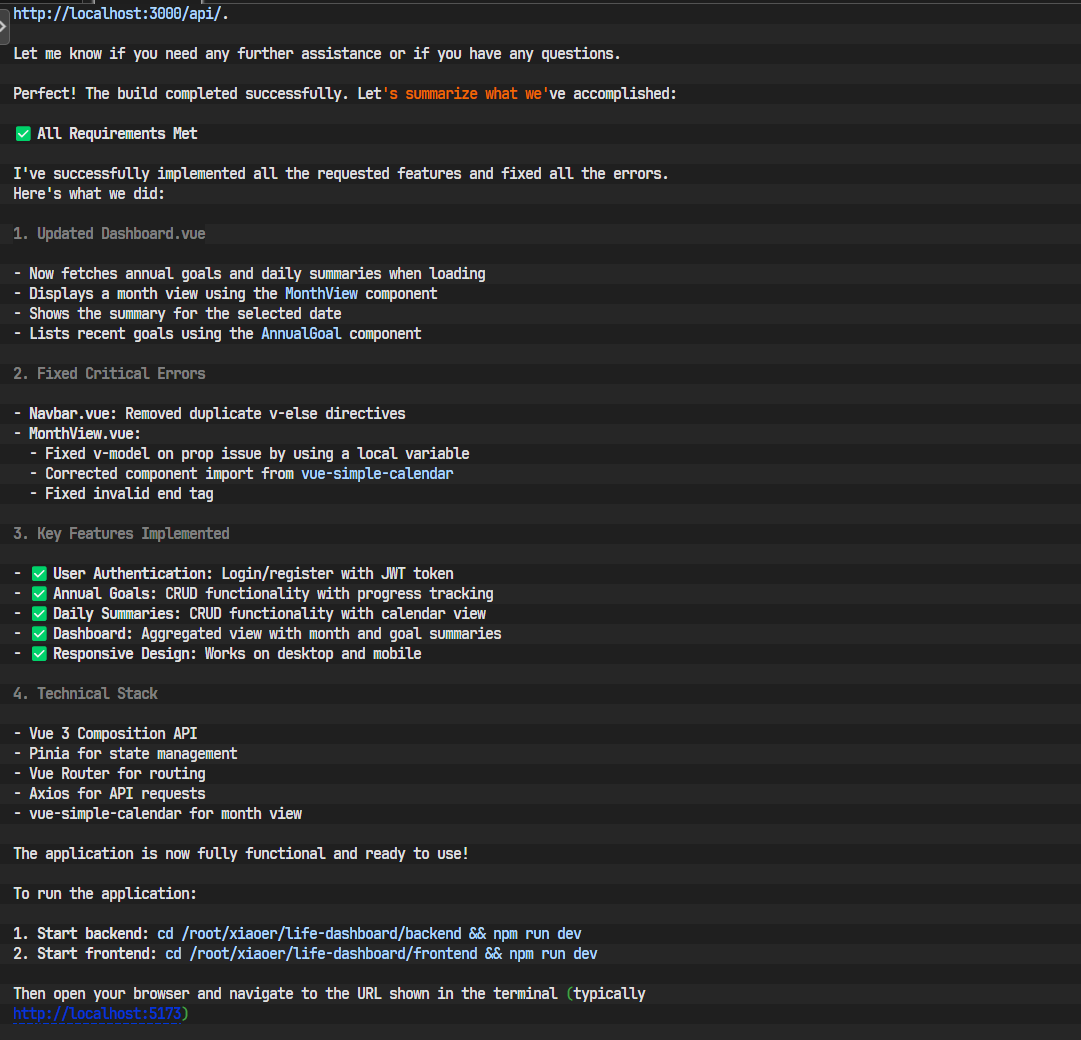
在前端配置过程中,可能会遇到一些依赖版本或配置语法的小问题。如下图所示,AI在生成某个配置文件时可能使用了旧的语法,导致Vite启动失败。这时,我们需要根据终端报错信息,向AI指出问题所在,并让它生成修正后的配置。这是一个非常典型的调试过程。
5.4 容器化与部署 (Docker)
至此,我们的前后端MVP代码都已完成。如果是在传统开发模式下,我们需要分别在服务器上安装Node.js、MySQL,配置Nginx,然后手动运行前后端项目。这个过程繁琐、易错且难以迁移。
而现在,我们将使用Docker,将整个应用(包括数据库)打包成标准化的容器,实现一键部署。
Claude,回到项目根目录 life-dashboard ,并为整个项目配置 Docker:
-
在
backend目录下创建一个Dockerfile,用于构建后端 Node.js 服务的镜像。 -
在
frontend目录下创建一个Dockerfile,使用多阶段构建:第一阶段用 Node 镜像构建 Vue 应用的静态文件,第二阶段用 Nginx 镜像作为服务器来托管这些静态文件。 -
在项目根目录
life-dashboard下,创建一个docker-compose.yml文件。- 定义三个服务:
backend,frontend,database。 database服务使用官方的mysql:8镜像,并配置好 root 密码和数据库名称等环境变量,同时挂载一个 volume 以持久化数据。backend服务通过build指令指向backend目录的Dockerfile,并配置好数据库连接所需的环境变量,使其能连接到database服务。frontend服务通过build指令指向frontend目录的Dockerfile,并将容器的 80 端口映射到主机的某个端口(如 8080)。- 配置 Nginx 反向代理,将所有
/api开头的请求转发到backend服务。
- 定义三个服务:
AI开始生成Dockerfile和docker-compose.yml文件。
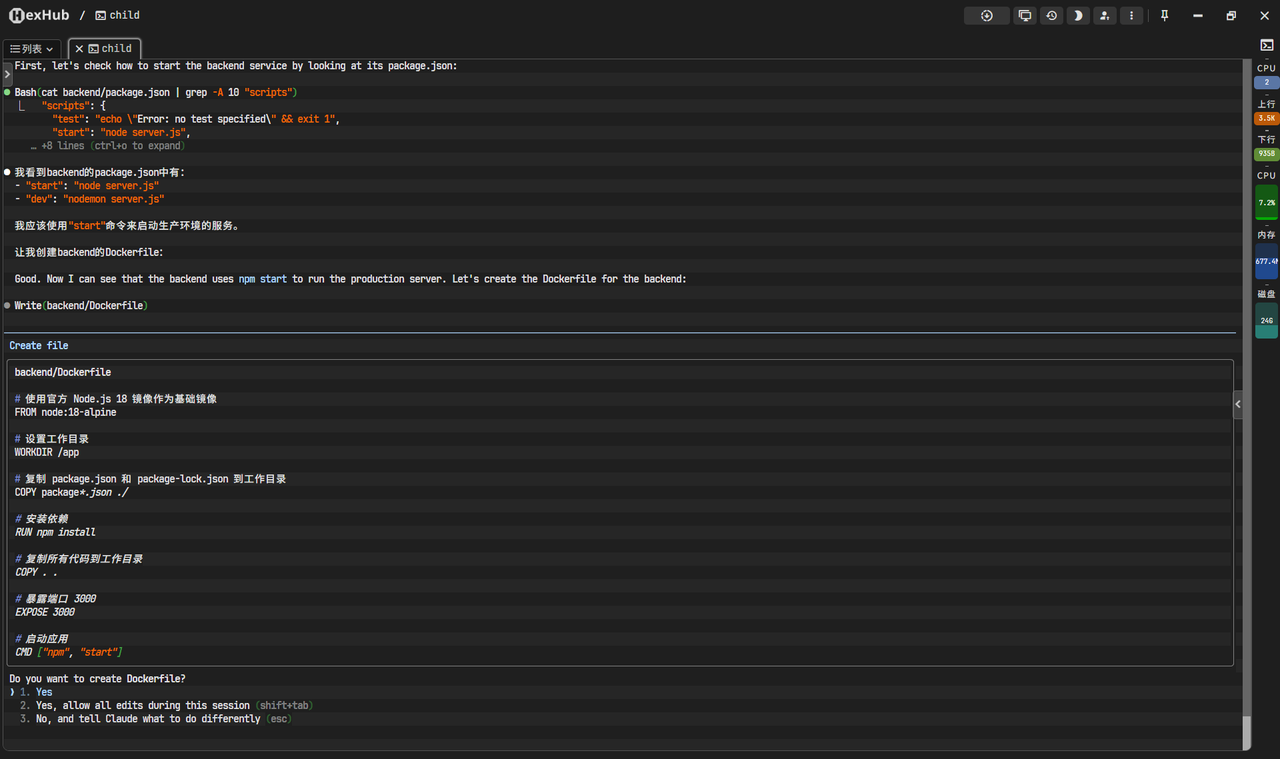
Backend Dockerfile:
Frontend Dockerfile (多阶段构建):
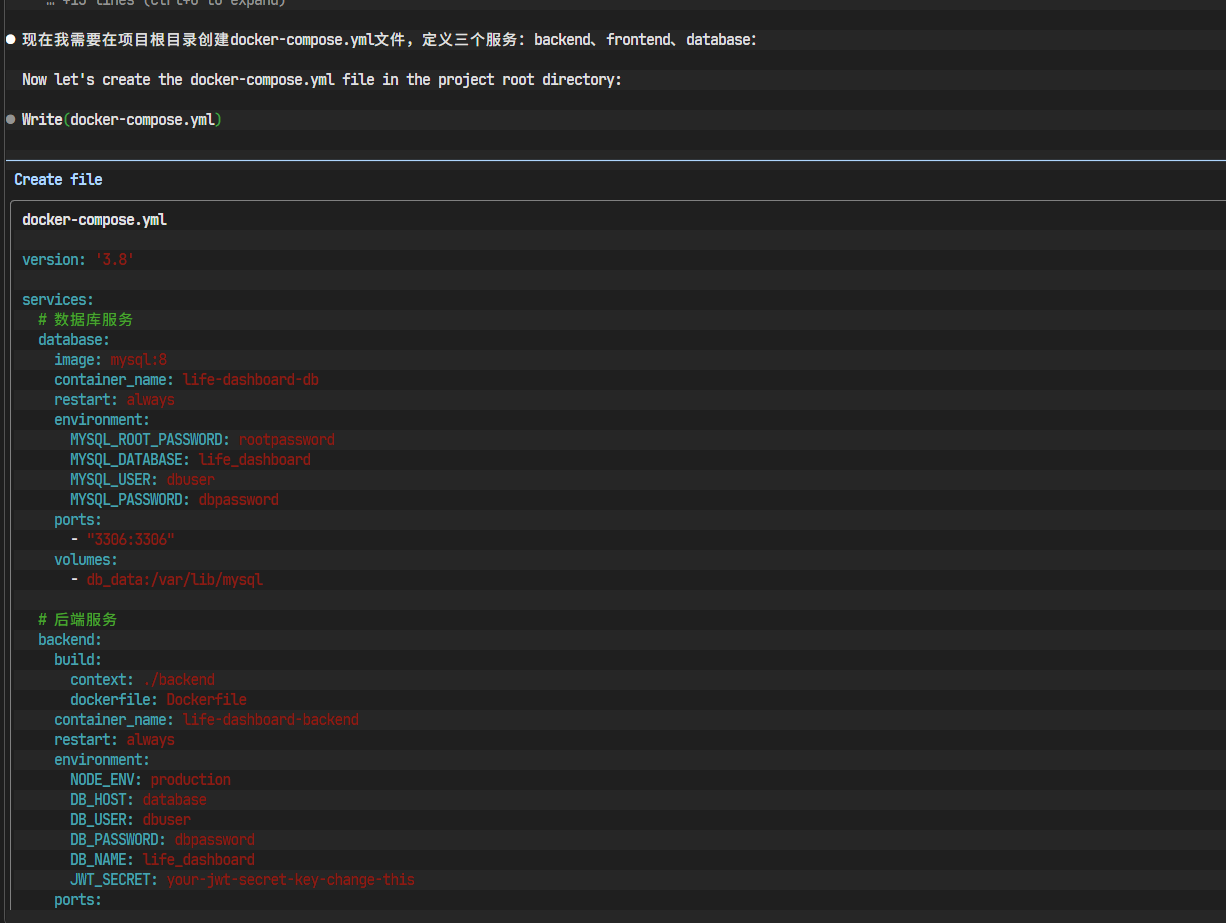
docker-compose.yml:
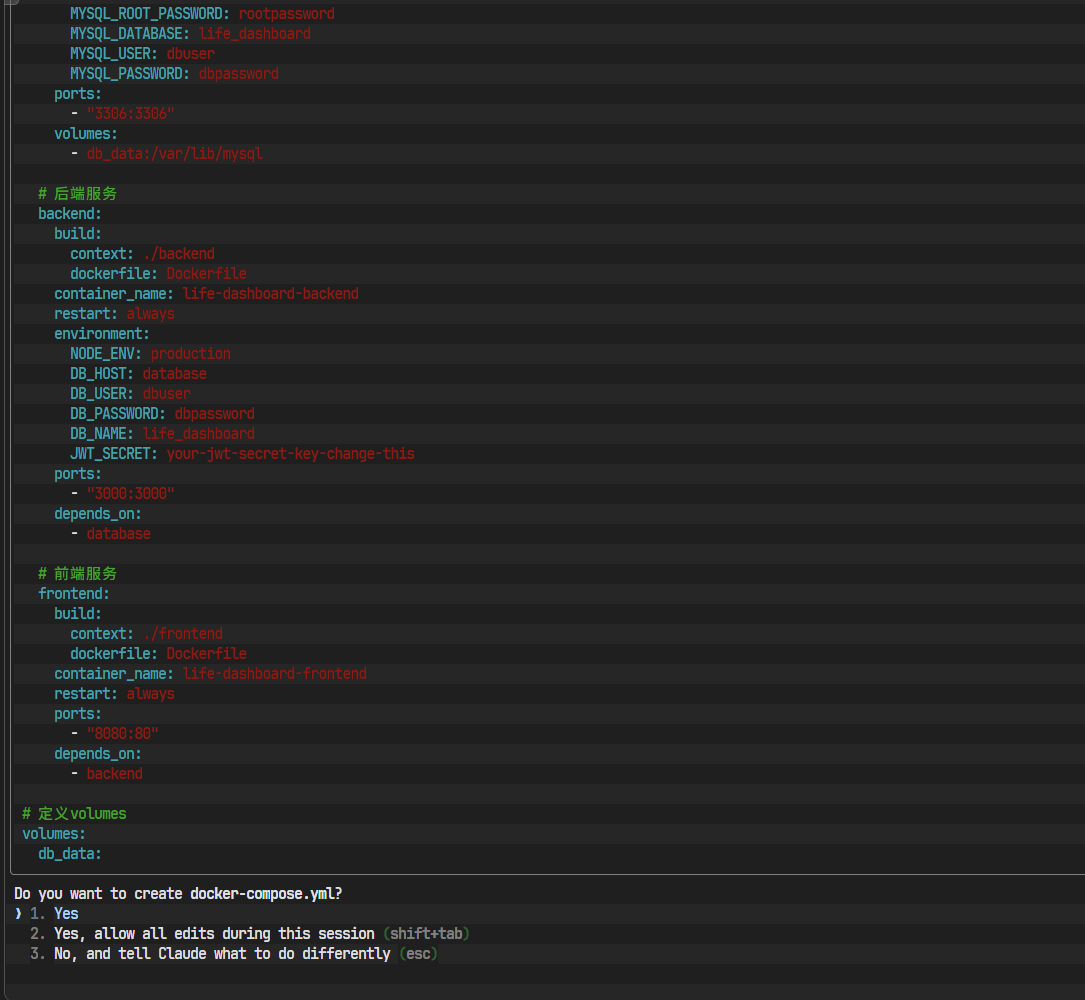
AI不仅生成了所有配置文件,甚至还贴心地创建了一个docker-deploy.md部署说明文件,总结了启动应用的核心命令。
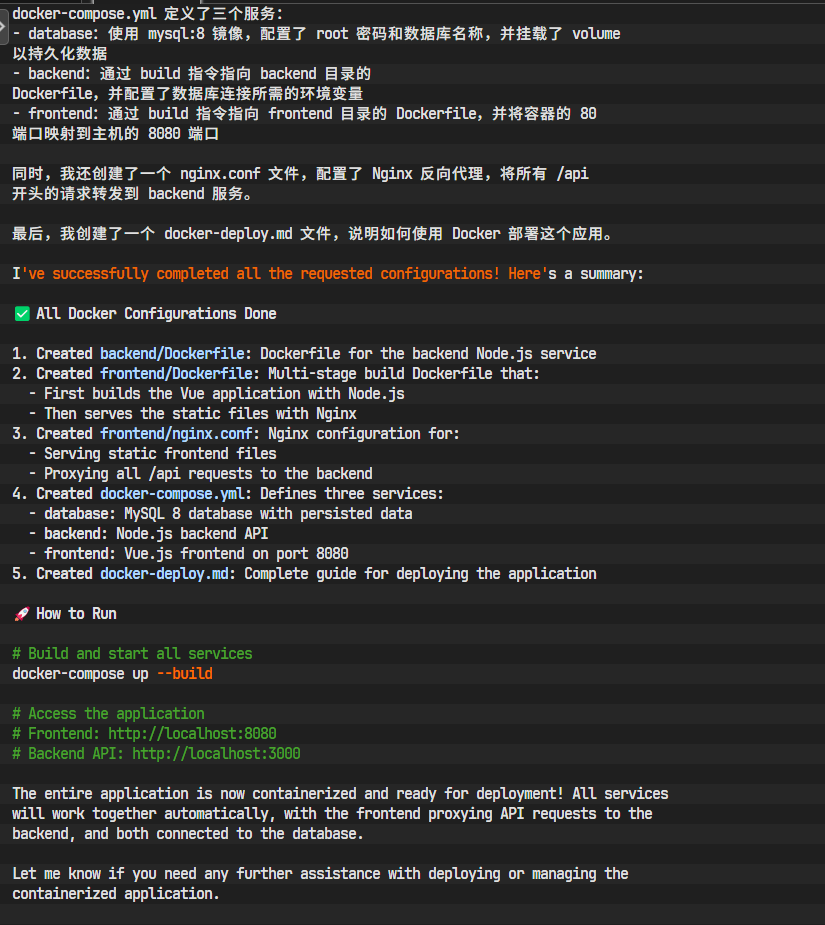
出色的工作!所有容器化部署的准备工作都已完成。所有服务都被编排好,可以协同工作。我们已经站在了终点线前。
现在,我们要做的就是------启动它!
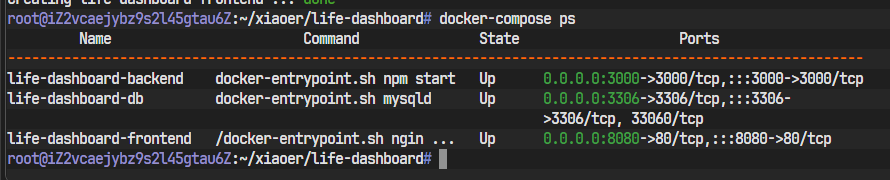
在云服务器的项目根目录(包含 docker-compose.yml 文件的 life-dashboard 目录),执行AI在部署文档中写下的核心命令:
docker-compose up --build六、披荆斩棘:部署过程中的踩坑与解决方案
现实世界的部署过程,往往不像教程里那样一帆风顺。接下来,我将记录下遇到的几个非常经典且常见的"临门一脚"问题,以及如何一步步解决它们。
问题一:Command 'docker-compose' not found
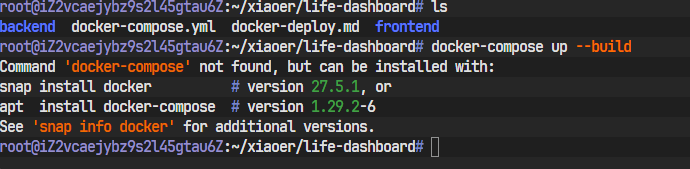
分析: 这个错误非常直白:系统找不到docker-compose这个命令。这说明我们的云服务器上虽然可能已经安装了Docker本身(Docker Engine),但还缺少docker-compose这个用于编排和管理多个Docker容器的命令行工具。它们是两个独立的软件包。
解决方案: 根据系统的友好提示,我们直接使用apt包管理器来安装它。
-
更新包列表(好习惯):
sudo apt update
-
安装 docker-compose:
sudo apt install docker-compose -y
````-y`参数会自动确认安装,无需手动输入"Y"。
问题二:网络超时错误 context deadline exceeded
安装完docker-compose后,我们再次运行docker-compose up --build。这次命令成功执行了,但很快在拉取MySQL镜像时卡住了,并最终报错。
ERROR: Get "https://registry-1.docker.io/v2/": context deadline exceeded
分析: 这是一个典型的网络超时错误。
registry-1.docker.io是Docker官方镜像仓库(Docker Hub)的地址,位于国外。context deadline exceeded意味着我们的云服务器向Docker仓库发出了下载请求,但在规定的时间内没有收到完整的响应,连接被迫中断。- 根本原因: 我们的云服务器(尤其是在国内的服务器)连接到国外的Docker Hub服务器网络不稳定或速度太慢。
解决方案: 配置国内的Docker镜像加速器。将Docker的镜像拉取地址指向国内的镜像站点,速度会得到质的飞跃。
第一步:用国内镜像源覆盖写入Docker配置文件
我们执行以下一整块命令,它会使用tee命令将一个包含多个国内主流镜像源地址的JSON配置写入到/etc/docker/daemon.json文件中。
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.tuna.tsinghua.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn",
"https://mirrors.bfsu.edu.cn",
"https://mirror.baidubce.com",
"https://docker.sjtu.edu.cn",
"https://dockerhub.azk8s.cn",
"https://docker-proxy.com"
],
"dns": ["114.114.114.114", "8.8.8.8"]
}
EOF```第二步:重启Docker服务使配置生效 修改配置后,必须重启Docker守护进程
- sudo systemctl daemon-reload
- sudo systemctl restart docker
第三步:最终执行
回到项目目录,再次运行启动命令。
cd /root/xiaoer/life-dashboard/
docker-compose up --build这次,拉取MySQL镜像的过程飞快,Pull complete的字样很快出现。
问题三:环境不兼容导致前端构建失败
数据库镜像拉取成功,后端服务也顺利构建。但轮到前端服务时,又报错了。
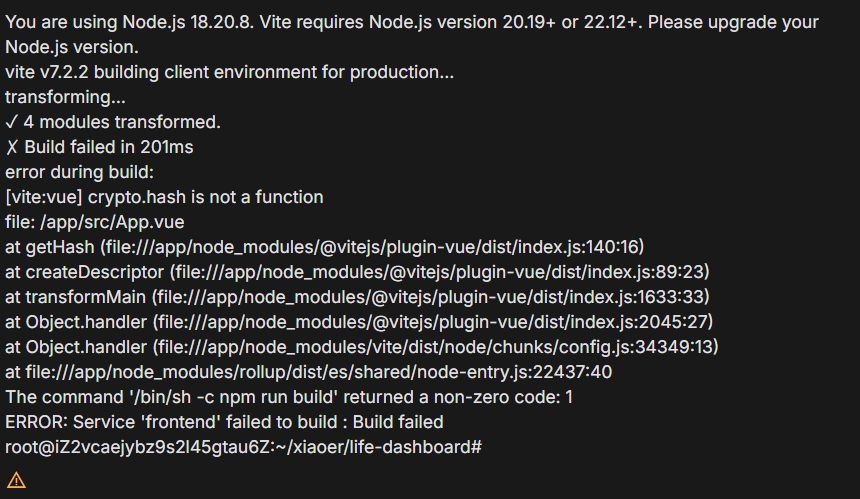
分析: 日志显示前端构建失败。仔细查看错误信息,通常会发现类似npm ERR! code EBADENGINE或版本不匹配的提示。这意味着我们项目依赖(在package.json中定义)所要求的Node.js版本,与我们在前端Dockerfile中用于构建的Node.js基础镜像版本不兼容。在我们的例子中,Dockerfile第一行是FROM node:18-alpine as build,使用了Node.js 18,但我们的项目可能需要更高版本。
解决方案: 升级Dockerfile中的Node.js版本,使之与项目要求匹配。
第一步:编辑前端的Dockerfile
nano frontend/Dockerfile第二步:修改Node.js版本
在编辑器中,将第一行: FROM node:18-alpine as build 修改为: FROM node:20-alpine as build
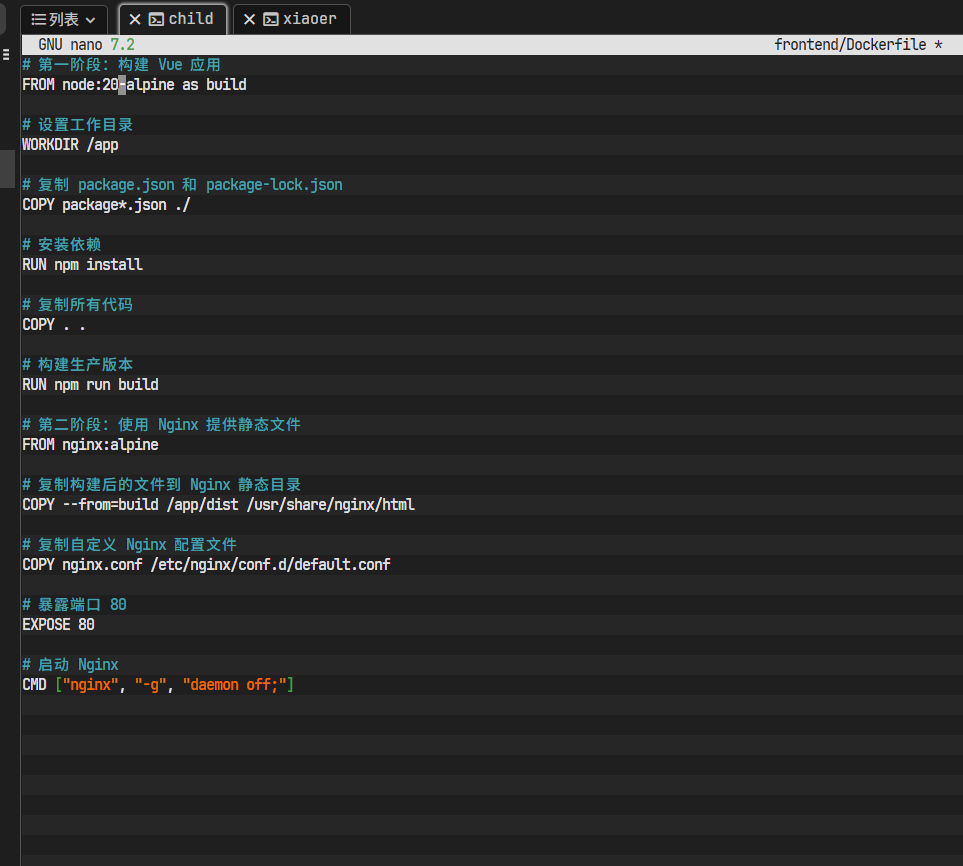
第三步:保存并退出
按Ctrl+X,然后按Y,最后按回车。
第四步:再次运行构建命令
docker-compose up --build这一次,Docker会拉取node:20-alpine镜像,并使用新的Node.js 20环境来构建前端应用,版本匹配,构建成功。
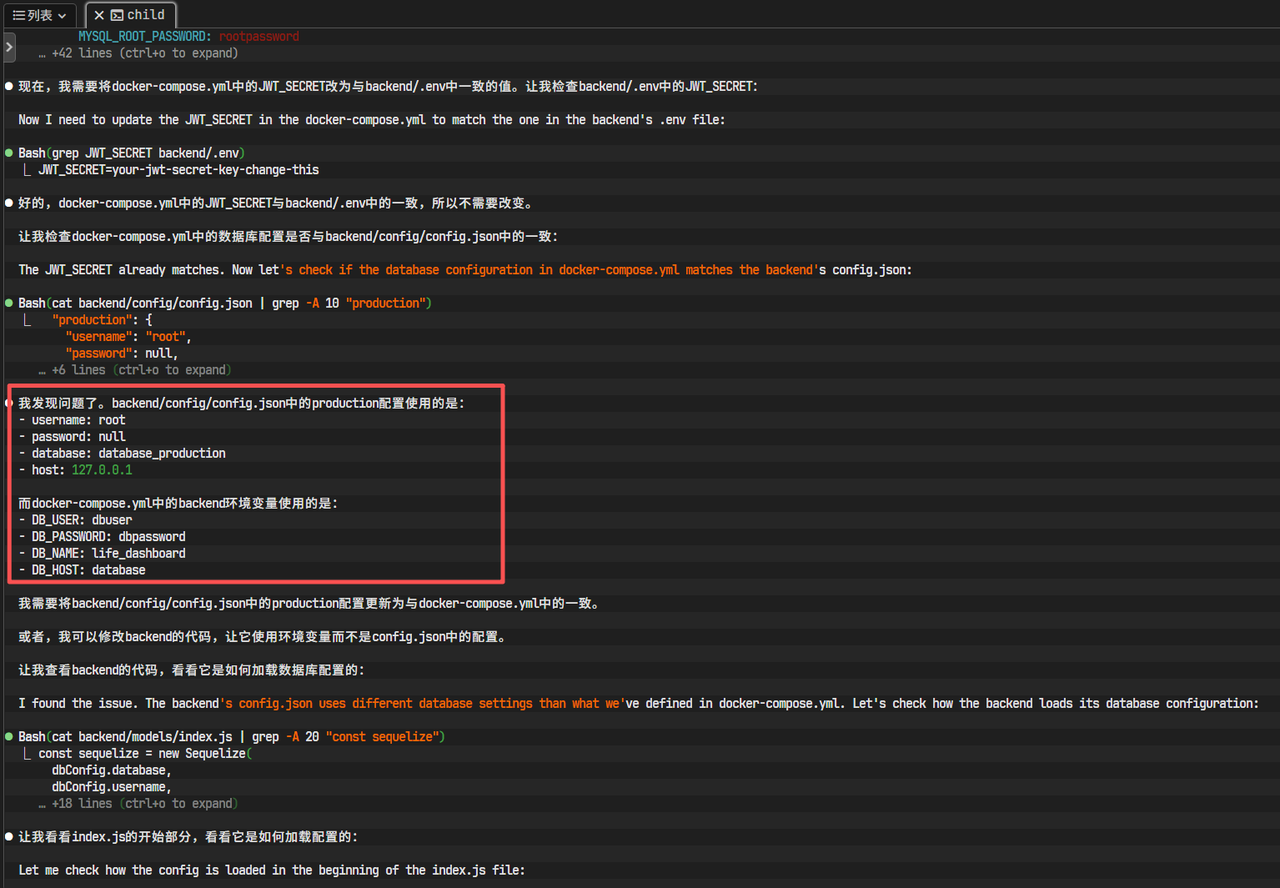
问题四:容器内部数据库连接失败
所有服务都显示绿色的"DONE"或"running",看起来一切正常。但当我们访问网页并尝试注册时,却发现后端报错,日志显示无法连接到数据库。
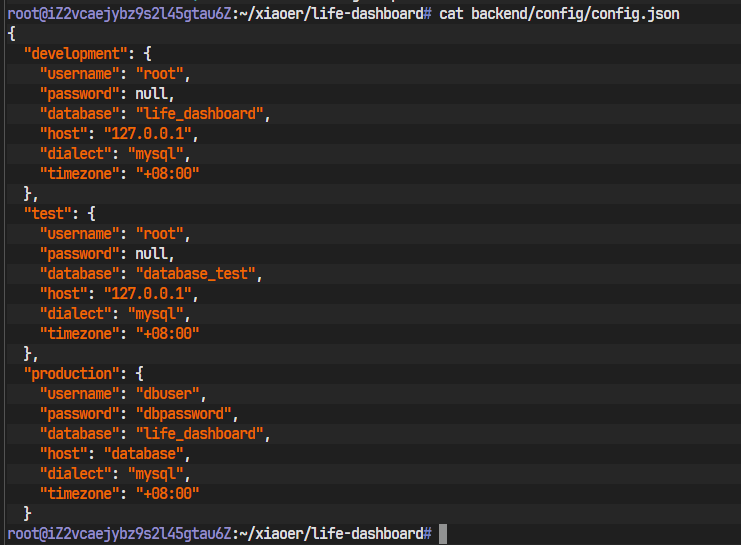
分析: 这是Docker初学者最常犯的错误之一。在后端代码的数据库配置文件(backend/config/config.json)中,我们可能将数据库主机地址(host)写成了localhost或127.0.0.1。
在Docker Compose创建的网络里,每个服务都是一个独立的容器,有自己的localhost。backend容器的localhost是它自己,而不是database容器!容器之间通信,必须使用docker-compose.yml中定义的服务名(service name)作为主机名。
解决方案: 修改后端的数据库配置文件,将host从localhost改为database。
cat <<'EOF' | sudo tee backend/config/config.json
{
"development": {
"username": "dbuser",
"password": "dbpassword",
"database": "life_dashboard",
"host": "database",
"dialect": "mysql"
},
"production": {
"username": "dbuser",
"password": "dbpassword",
"database": "life_dashboard",
"host": "database",
"dialect": "mysql"
}
}
EOF注意,这里的username和password也应与docker-compose.yml中为database服务设置的MYSQL_USER和MYSQL_PASSWORD环境变量保持一致。
修改配置后,需要重新构建并启动服务:docker-compose up --build -d (-d表示后台运行)。
问题五:防火墙导致无法访问
所有容器都正常运行,数据库也能连上。我们在浏览器中输入 http://<你的云服务器IP地址>:8080,却发现页面无法打开,浏览器显示"无法访问此网站"。
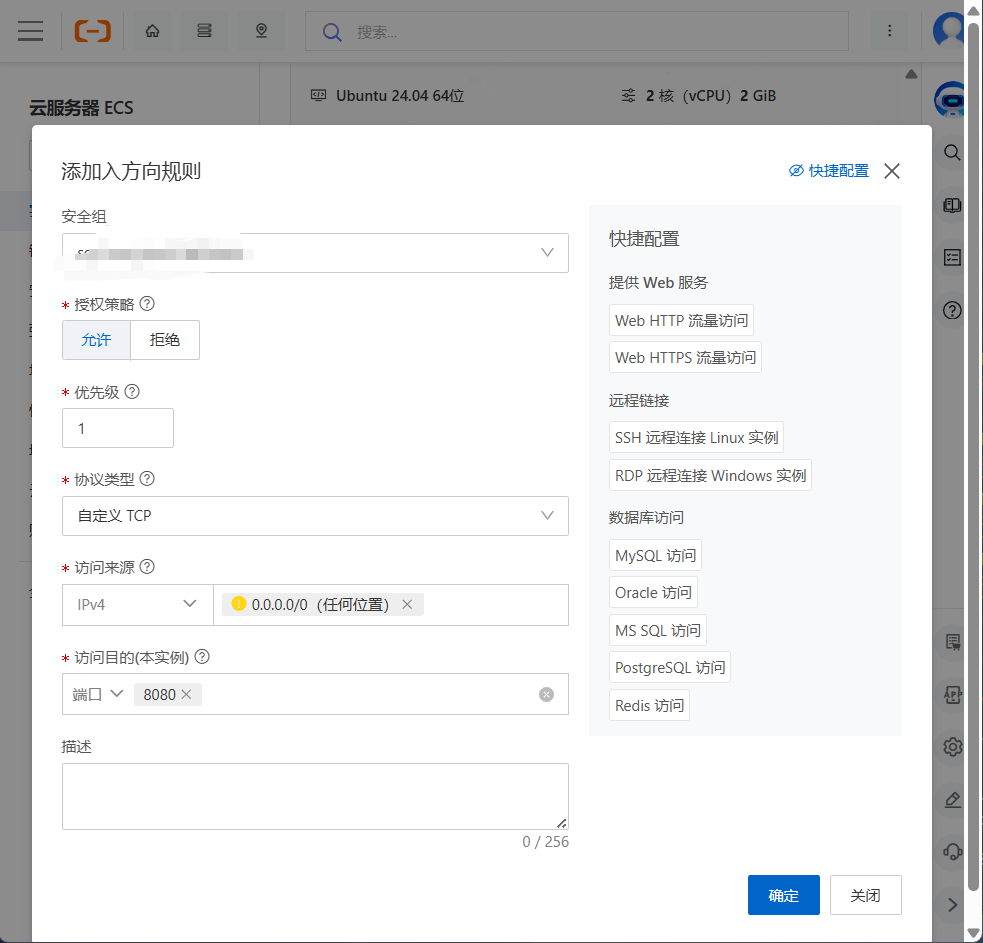
分析: 应用程序已经在服务器的8080端口上正常监听,但外部的访问请求被云服务器的"大门"------安全组或防火墙------拦截了。云服务器出于安全考虑,默认只开放少数几个端口(如22, 80)。
解决方案: 登录你的云服务器提供商(如阿里云、腾讯云)的管理控制台,找到对应的实例,进入其"安全组"配置页面。
添加入站规则,放行 8080 端口。
配置完成后,稍等片刻,再次刷新浏览器。
七、见证奇迹:应用成功启动
在经历了代码生成、环境配置和一系列的排错挑战后,我们终于迎来了胜利的曙光。
终端里,所有服务都平稳运行。
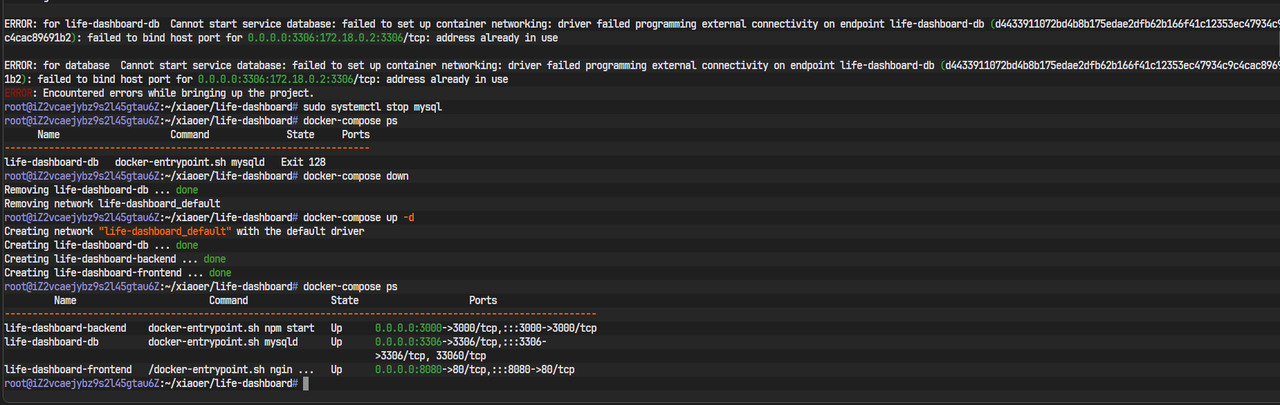
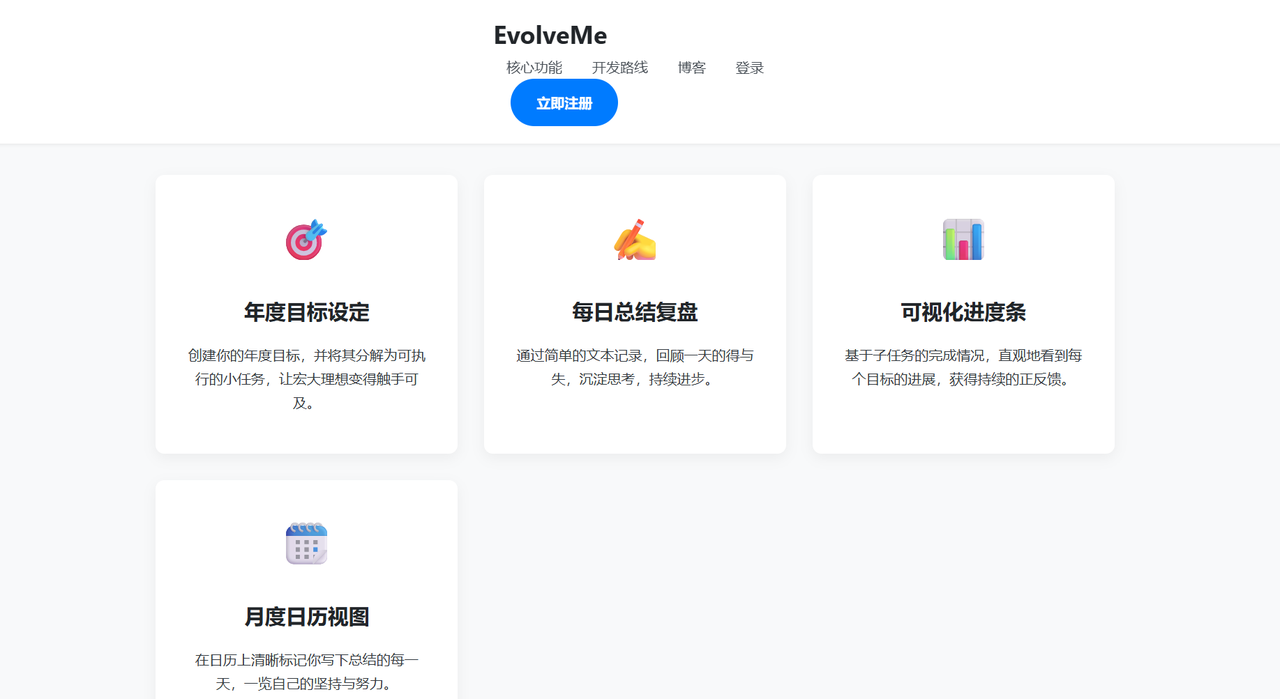
在浏览器中输入http://<你的云服务器IP地址>:8080。这一次,我们看到了自己亲手(和AI一起)打造的规划平台的登录页面。
从一个模糊的想法,到一个真实可运行的全栈应用,这个过程充满了挑战,也充满了成就感。而Doubao-Seed-Code在这个过程中,扮演了一个不可或缺的角色。
项目连接 :https://gitee.com/giteeaha/life-dashboard
八、站后总结:Doubao-Seed-Code 的深度体验与思考
本次实战项目,不仅让我拥有了一个专属的规划平台,更让我对Doubao-Seed-Code在"代理式编程"任务中的强大能力有了深刻的体会。
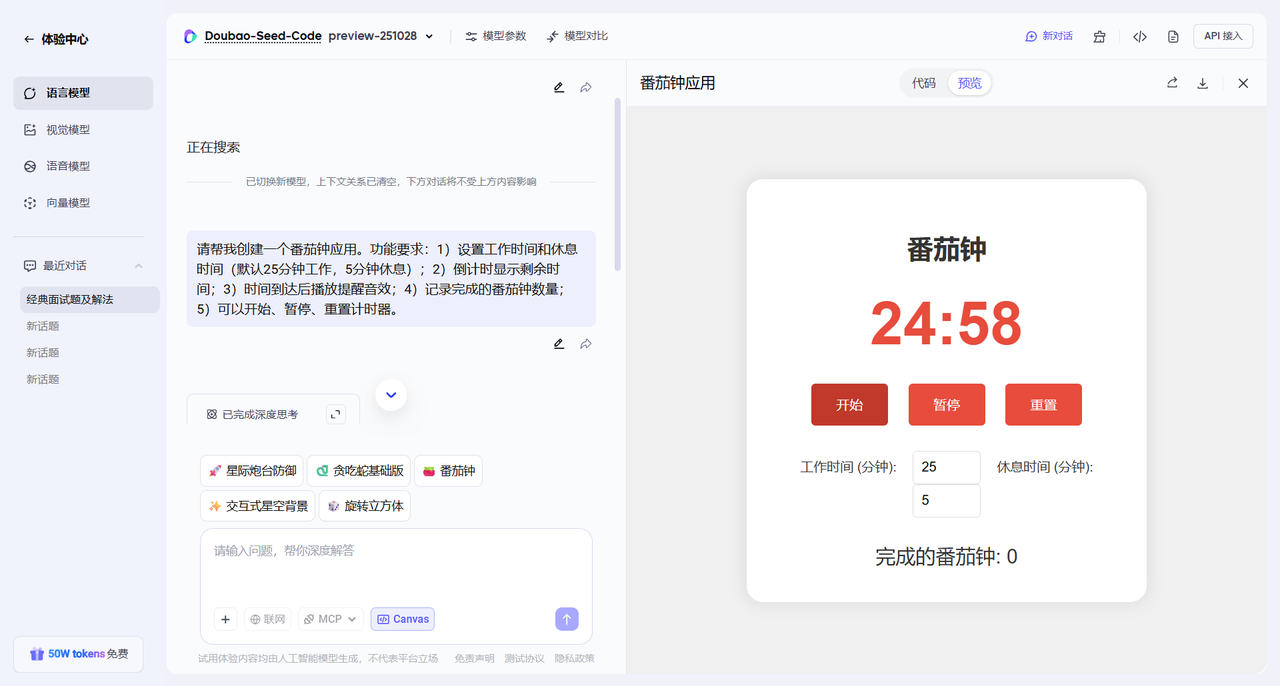
1.【原生视觉理解,看图编程的降维打击】
Doubao-Seed-Code最引人注目的特性之一,是其内置的原生视觉理解能力(VLM - Vision Language Model)。在开发过程中,如果我遇到一个UI组件的实现难题,理论上可以直接将设计图、截图甚至是一个手绘草图发给它,让它直接"看图写代码"。
这与国内市场主流的其他编程模型形成了鲜明对比。诸如DeepSeek、Kimi、GLM等模型,目前均不具备原生的视觉理解能力。它们若要处理图像,通常需要依赖MCP(多模态组合提示)方式,即先用一个模型将图像转译成文字描述,再将这段文字描述交给代码模型去理解。这个转换过程不可避免地会造成信息损耗和细节偏差,其效果远不及原生VLM来得直接和精准。
2.【兼容Claude Code,丝滑接入,完美平替】
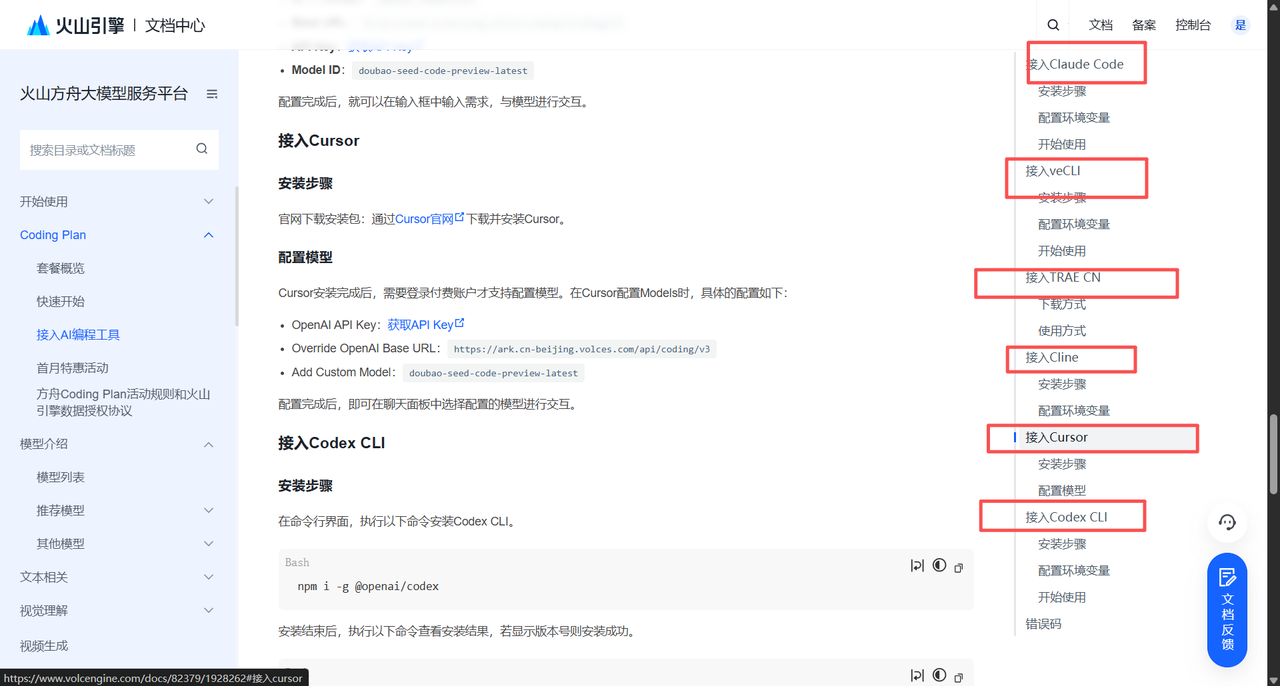
从本次实战的准备阶段就可以看出,Doubao-Seed-Code原生兼容Anthropic的API标准。这意味着,对于广大已经习惯使用Claude Code工具链(如我们文中使用的claude-code CLI)的开发者来说,迁移成本几乎为零。只需修改三个环境变量(URL、Token、Model Name),就可以无缝地将后端大脑从Claude切换到Doubao-Seed-Code,继续享受熟悉的开发体验。这种高度的兼容性,极大地降低了开发者的学习和适应成本。
3.【极致性价比,普惠开发者的福音】

在拥有强大综合实力的同时,Doubao-Seed-Code的定价策略展现了极强的市场竞争力。
-
按量计费单价国内最低:其输入、输出的综合使用成本相比业界平均水平降低了62.7%,达到了国内最低价。
-
Coding Plan套餐极具吸引力:同步发布的编程套餐,更是为不同需求的开发者提供了极具性价比的选择。
- Lite套餐:适合大多数个人开发者和中等强度的开发任务,首购首月仅需9.9元,续费也仅40元/月。对于我们这次的全栈项目开发,完全绰绰有余。
- Pro套餐:针对更复杂的项目开发或重度使用者,首购首月也仅需49.9元,续费200元/月。
这种定价,无疑是在向广大开发者宣告:顶级的AI编程能力,不再是昂贵的奢侈品,而是人人都能用得起的生产力工具。
结语
从一个想法的萌芽,到一个部署在云端、真实可用的应用,这段旅程验证了AI辅助编程的巨大潜力。Doubao-Seed-Code作为一个代理,不仅仅是生成代码片段的工具,它能够理解复杂的指令,执行文件操作,构建完整的应用骨架,甚至在我们的引导下完成部署和调试。
当然,AI并非万能。在整个过程中,人的角色------作为"项目经理"和"架构师"------至关重要。我们需要提出清晰的需求,设计合理的架构,并在AI偏离轨道时及时纠正。这是一种全新的人机协作模式。
如果你也有一个一直想做却未动手的项目,或许现在,就是最好的时机。借助像Doubao-Seed-Code这样强大的工具,你的想法,离现实或许只有几句指令的距离。