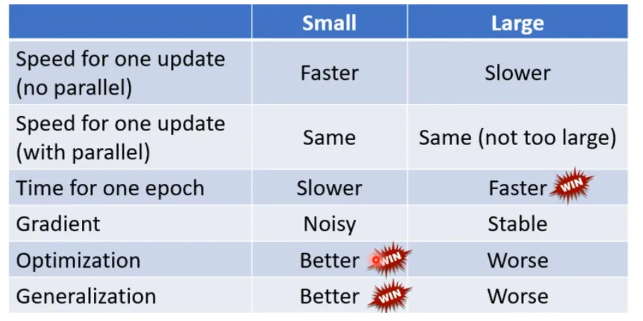
作业流程
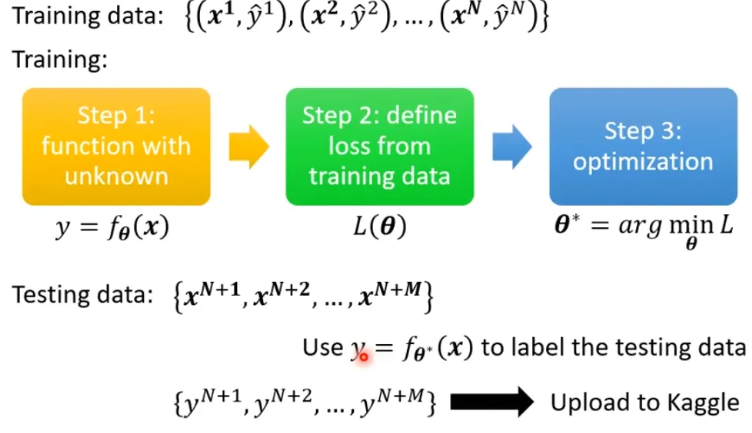
General Guide
- model bias:增加模型的flexibility,比如激活函数、更多层数等
- model bias 还是 optimization ?
- comparison
- Start from shallower network (or other models), which are easier to optimize
- If deeper networks do not obtain smaller loss on training data, then there is optimization issue.
- Overfitting:flexibility太大,training data不够多导致的
- more training data:
- data augmentation 数据增强,对现有数据进行各种变换来生成更多数据,要合理变换
- less flexibility , constrained model:
- Less parameters:less神经元、less层数
- sharing parameters:CNN
- Less features
- Early stopping
- Regularization
- Dropout
- more training data:
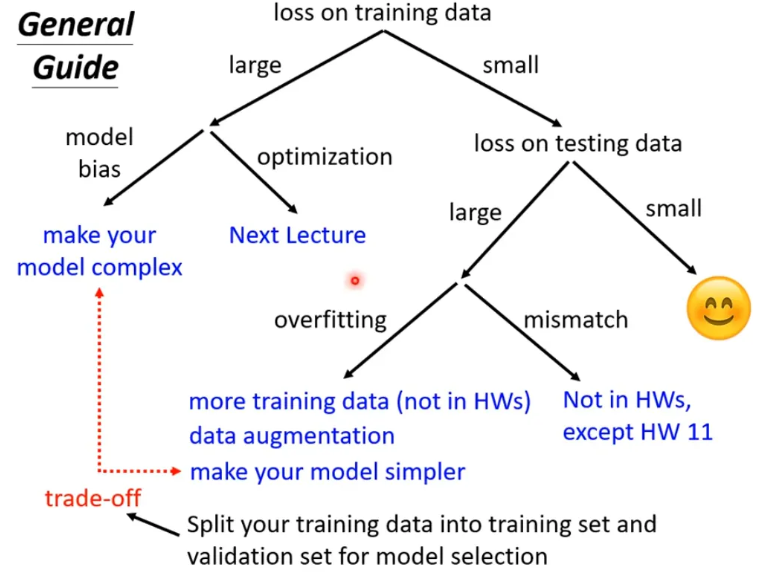
Bias-Complexity Trade-off
- benchmark corpora:基准测试语料库
- how to select the best one?
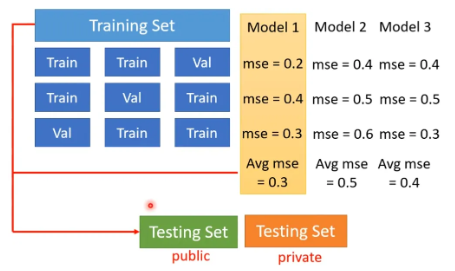
- 不建议的做法:直接比较model 在 public testing set的分数来选择。WHY?类比猴子敲出莎士比亚,如果test很多遍,即使是很废模型,还是有可能拿到好分数
- testing set分public和private:public one 可以看成是训练时会用的,private one可以理解为实际放出来给大众用的,在public testing set上表现好可能是用了某些手段导致在此过拟合,但是在private testing set的表现不好
- 建议的做法:cross validation,用validation set 来选model,少看public testing set的结果
- n-fold cross validation
Mismatch
- training and testing data have different distribution

critical point:local minima、saddle point
- gradient为0的点统称critical point:比如local minima、saddle point
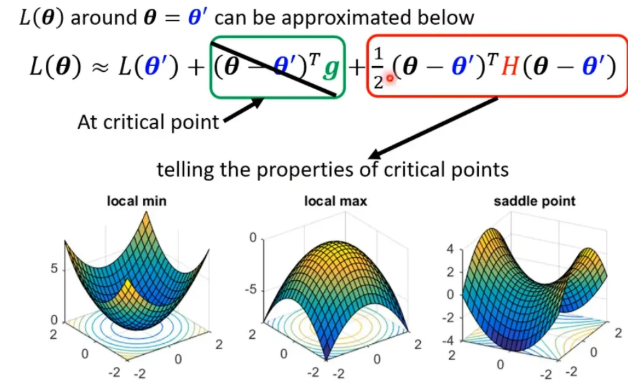
- 判断critical point的类型:Hessian
-
大概原理:Tayler Series Approximation 可以近似Loss函数某点附近的样子,critical point处绿色项为0,只剩红色项,只需判断H矩阵的特征值
-
- saddle point:可以沿着负特征值的特征向量去更新参数

- local minima:When you have lots of parameters, perhaps local minima is rare
可能在高维空间只是个saddle point - 经验上看,其实local minima其实不常见,多数是saddle point
Batch
-
shuffle after each epoch
-
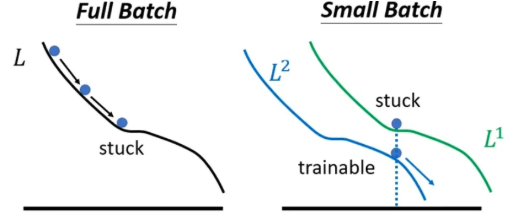
Why batch? 如果不用batch,那就是整个training set一起训练,相当于batch size = training set size,即极端情况的large batch
-
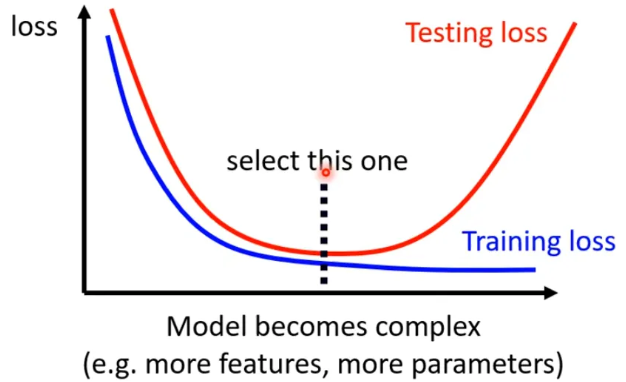
Small Batch v.s. Large Batch
- large batch:Long time for cool down, but powerful(稳定)
- small batch:Short time for cool down, but powerful but noisy
-
时间上,large batch 跑完一个epoch的时间反而短,因为GPU并行运算的能力
-
但noisy反而会有利于training
-
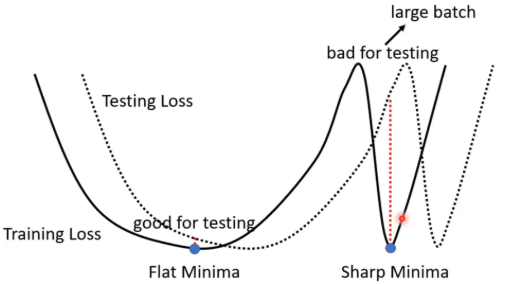
而且 Small batch is better on testing data,大的batch size会让我们倾向于走到峡谷里面
-
-
总结:Batch size is a hyperparameter you have to decide