目录
[3.Linux 正则表达式分类](#3.Linux 正则表达式分类)
[二.grep ------ 条件查找](#二.grep —— 条件查找)
[三.基础正则 vs 扩展正则](#三.基础正则 vs 扩展正则)
[1.cut ------ 按列或字符截取](#1.cut —— 按列或字符截取)
[2.sort ------ 排序(默认按行首字符升序)](#2.sort —— 排序(默认按行首字符升序))
[3.uniq ------ 去除 连续 重复行](#3.uniq —— 去除 连续 重复行)
[4.tr ------ 字符替换 / 删除 / 压缩重复](#4.tr —— 字符替换 / 删除 / 压缩重复)
前言:
上次和读者们分享了有关函数和数组的相关语句及基本运用,今天带大家了解一下有关正则表达式以及一些有用的命令小工具。
一.正则表达式
1.定义
正则表达式( Regular Expression, regex/regexp/RE )是一种用来描述字符串模式的规则。
功能:检索、替换、过滤符合特定规则的字符串。
2.用途
系统日志筛选(如定位 " 登录失败 "" 服务启动失败 " )
配置文件解析
文本查找替换
脚本编程中的条件匹配
3.Linux****正则表达式分类
3.1.BRE (基础正则表达式)
传统语法,功能有限
量词 {} 需要转义 \{n,m\}
- , ? , () 需要转义
常用工具: grep 、 sed
3.2.ERE (扩展正则表达式)
功能更强大,语法简洁
- , ? , () , {} , | 等无需转义
常用工具: egrep ( grep - E ) 、 awk
4.正则表达式组成
4.1.普通字符
字母、数字、标点符号等本身。
4.2.元字符
. 匹配任意单个字符
匹配任意单个字符(除 \r\n ),就是 " 通配符 " ,你想匹配啥都行一个字符
\] 匹配字符集 \[a - z\] \[0 - 9\] \[A - Z
匹配 list 列表中的一个字符 例: goolad , abc 、 a-z 、 a-z0-9
\^list 匹配非集合中的字符
匹配任意不在 list 列表中的一个字符 例: \^a-z 、 \^0-9 、 \^A-Z0-9
^ 行首
$ 行尾
\ 转义符
4.3.重复次数
* 0 次或多次
匹配前面子表达式 0 次或者多次 例: goo*d 、 go.*d goo*d goooooood
\+ 至少 1 次
匹配其前面的字符出现最少 1 次 , 即 : 肯定有且 >=1 次
\{n\} 恰好 n 次
匹配前面的子表达式 n 次,例 :go\{2\}d 、 'O-9\{2\}' 匹配两位数字
\{m,n\} m 到 n 次
匹配前面的子表达式 n 到 m 次,例 : go\{2,3\)d 、 '0-9\{2,3\}' 匹配两位到三位数字
\{n,\} 至少 n 次
匹配前面的子表达式不少于 n 次,例 : go\{2,\}d 、 ' 0-9\{2,\}' 匹配两位及两位以上数字
扩展:
egrep 、 awk 使用 {n} 、 {n, } 、 {n, m} 匹配时 "{}" 前不用加 "\"
egrep -E -n 'wo{2}d' test.txt //-E 用于显示文件中符合条件的字符
egrep -E -n 'wo{2,3}d' test.txt

举例:
- 作用:重复一个或者一个以上的前一个字符
示例:执行 "egrep -n 'wo+d' test.txt" 命令,即可查询 "wood" "woood" "woooooood" 等字符串

? 作用:零个或者一个的前一个字符
示例:执行 "egrep -n 'bes?t' test.txt" 命令,即可查询 "bet""best" 这两个字符串
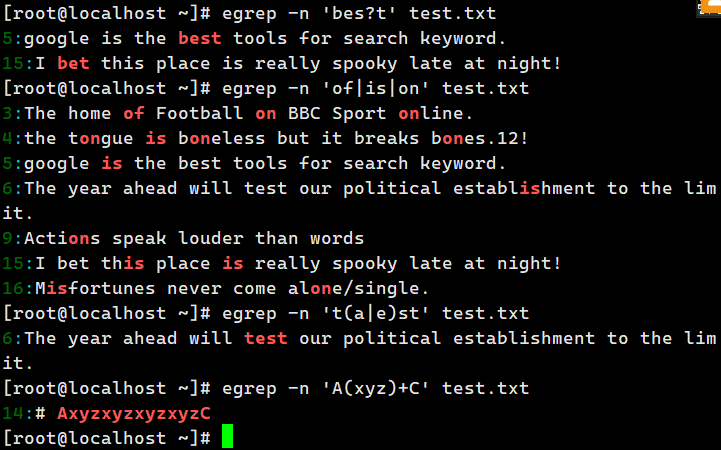
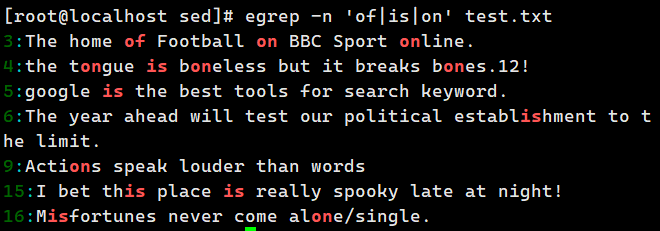
| 作用:使用或者( or )的方式找出多个字符
示例:执行 "egrep -n 'of|is|on' test.txt" 命令即可查询 "of" 或者 "if" 或者 "on" 字符串
() 作用:查找 " 组 " 字符串
示例: "egrep -n 't(a|e)st' test.txt" 。 "tast" 与 "test" 因为这两个单词的 "t" 与 "st" 是重复的,
所以将 "a" 与 "e"
列于 "()" 符号当中,并以 "|" 分隔,即可查询 "tast" 或者 "test" 字符串

()+ 作用:辨别多个重复的组
示例: "egrep -n 'A(xyz)+C' test.txt" 。该命令是查询开头的 "A" 结尾是 "C" ,中间有一个以上
的 "xyz" 字符串的意思

**二.grep ------**条件查找
- E :启用扩展正则
- c :统计匹配行数
- i :忽略大小写
- o :只输出匹配内容
- v :反向匹配(不包含的行)
- n :显示行号
-- color=auto :高亮匹配
grep -c root /etc/passwd # 统计 root 出现的行数
grep -i "the" web.sh # 不区分大小写匹配
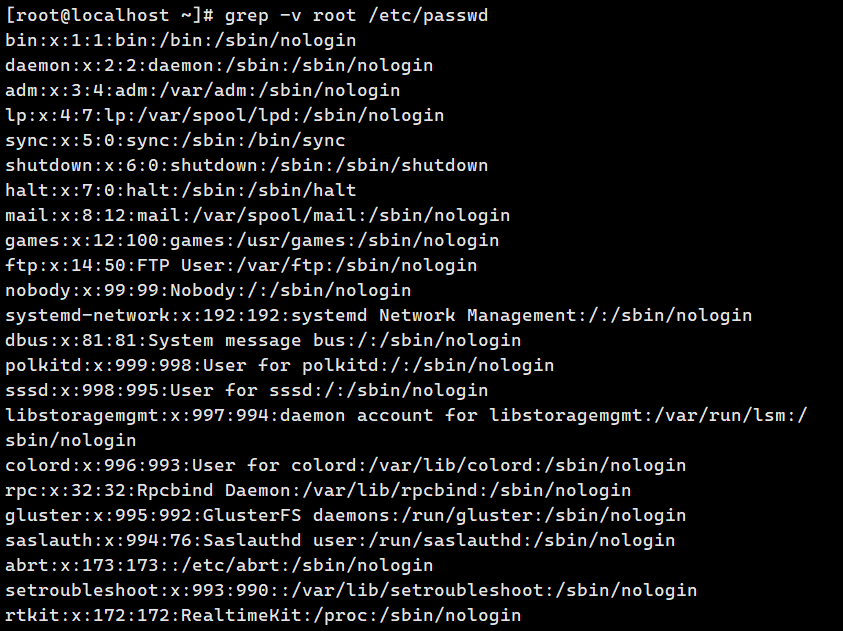
grep -v root /etc/passwd # 输出不包含 root 的行
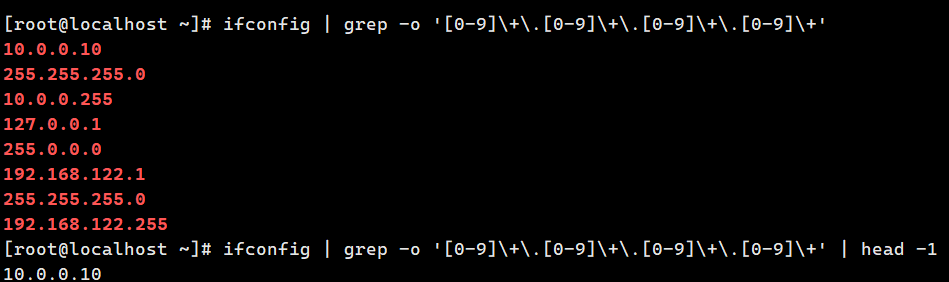
grep -o '0-9\+\.0-9\+\.0-9\+\.0-9\+' ifconfig.out | head -1 # 提取 IP 地址
ifconfig | grep -o '0-9\+\.0-9\+\.0-9\+\.0-9\+' | head -1 # 提取 IP 地址


三.基础正则vs扩展正则
BRE 常见元字符
^ 行首
$ 行尾
. 任意单字符
list 匹配字符集
\^list 反向匹配
* 0 或多次
\{n\} 精确次数
\{n,\} 至少 n 次
\{n,m\} n~m 次
ERE 新增功能
- 一个或多个
? 0 或 1 次
| 或者( OR )
() 分组
()+ 匹配重复的组
四.元字符操作案例
1.查找特定字符
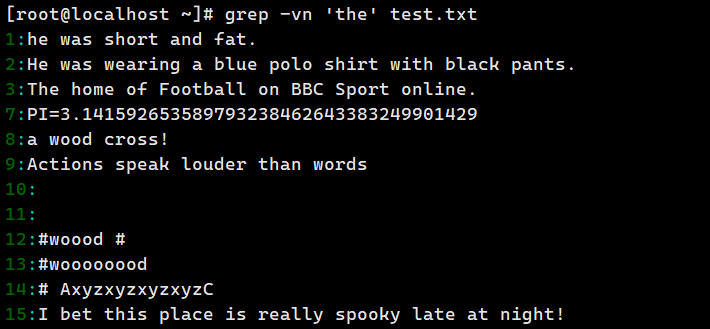
grep -n 'the' test.txt # 查找 the
grep -vn 'the' test.txt # 反向匹配

2.中括号集合
grep -n 'shiort' test.txt # shirt 或 short
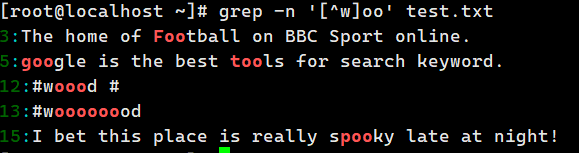
grep -n '\^woo' test.txt # 前面不是 w 的 oo

3.定位符
grep -n '^the' test.txt # 行首是 the
grep -n '\.' test.txt # 行尾是 .
grep -n '\^' test.txt # 空行



4.点与星
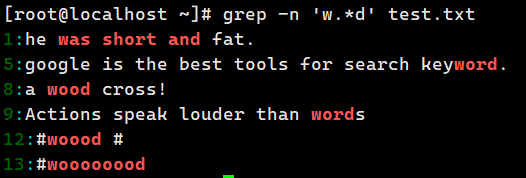
grep -n 'w..d' test.txt # w 开头 d 结尾,中间两个字符
grep -n 'woo*d' test.txt # w 开头 d 结尾,中间 o 可有可无
grep -n 'w.*d' test.txt # w 开头 d 结尾,中间任意字符
执行以下命令即可查询任意数字所在行。
grep -n '0-90-9*' test.txt


五.命令小工具
1.**cut ------**按列或字符截取
- b :按字节截取
- c :按字符截取(中文推荐用 - c )
- d :指定分隔符(默认 TAB )
- f :指定字段(需配合 - d )
cut -d ':' -f1 /etc/passwd # 截取第 1 列(用户名)
cut -d ':' -f3 /etc/passwd # 截取第 3 列( UID )
cut -d ':' -f1 ,3 /etc/passwd # 截取第 1 和 3 列
cut -c 2 name.txt # 截取第 2 个字符
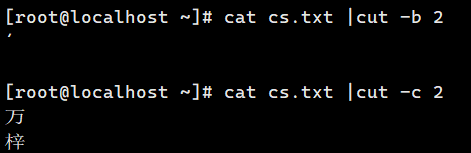
who | cut -b 3
who | cut -c 3
cat name | cut -b 2
cat name | cut -c 2 # 中文字符截取

2.**sort ------**排序(默认按行首字符升序)
- t :指定分隔符
- k :指定排序字段
- n :按数值排序(默认是字典序)
- r :降序
- u :去重(等价于 uniq )
- o :输出到文件
sort passwd.txt # 按第一列升序
sort -n -t : -k3 passwd.txt # 以冒号分隔,按第 3 列数值升序
sort -nr -t : -k3 passwd.txt # 第 3 列数值降序
sort -u passwd.txt # 去重
sort -nr -t : -k3 passwd.txt -o out.txt # 排序结果保存
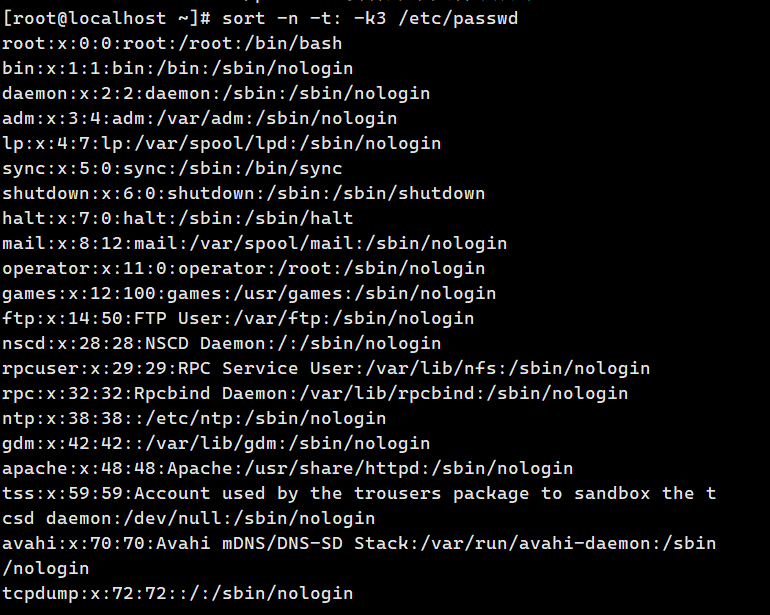
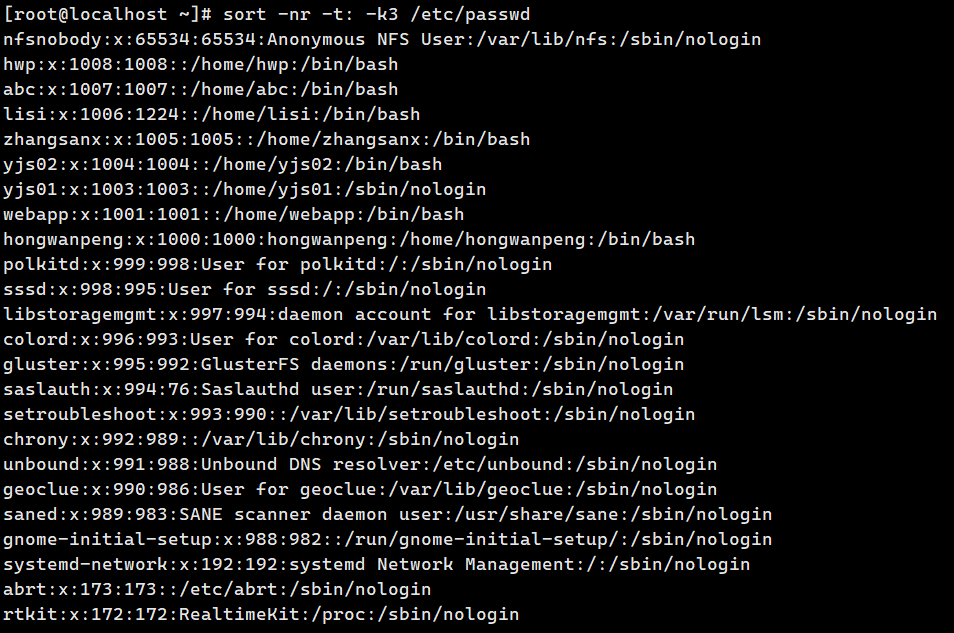
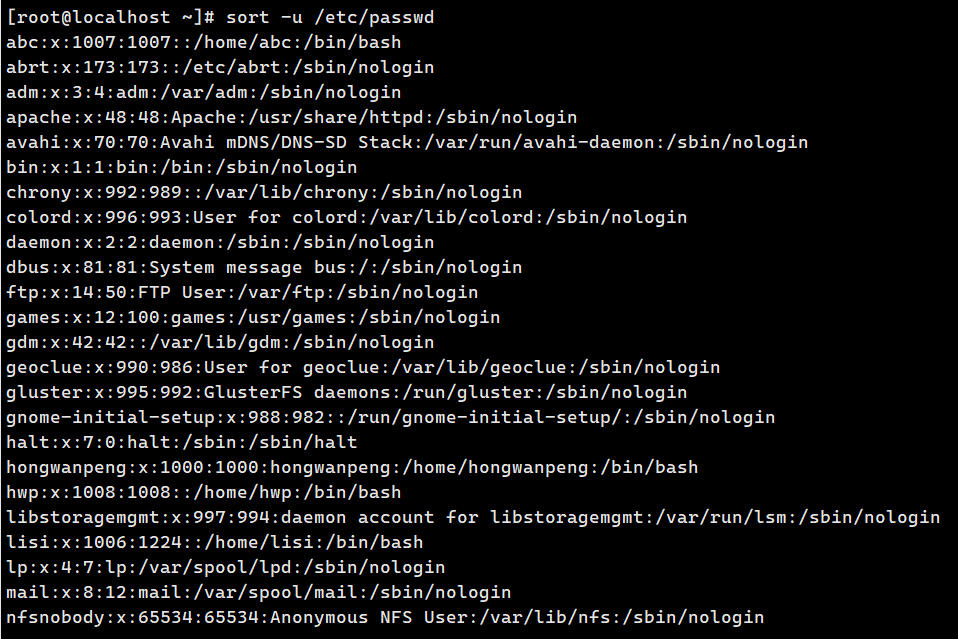
**3.uniq ------**去除 连续 重复行
注意: 只能去掉相邻的重复行 ,所以通常先 sort 再 uniq 。
常用选项
- c :对重复的行进行计数
- d :只显示重复行
- u :只显示唯一行
查看登录用户
who | awk '{print 1}' \| uniq  查看登陆过系统的用户 last \| awk '{print 1}' | sort | uniq | grep -v "^$" | grep -v wtmp

4.**tr ------字符替换/删除/**压缩重复
主要用于 单个字符处理 ,不适合字段级别。
常用选项
- d :删除字符
- s :压缩重复字符,只保留一个
tr 'a-z' 'A-Z' < fruit.txt # 小写转大写
或 cat fruit.txt | tr 'a-z' 'A-Z'
cat fruit | tr 'apple' 'APPLE' # 替换是一一对应的字母的替换
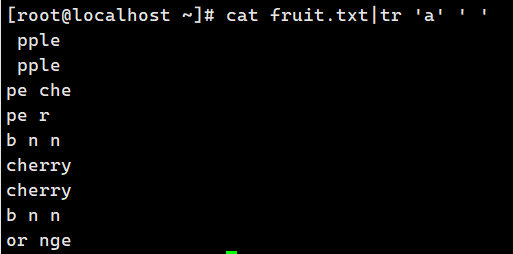
cat fruit | tr 'a' ' ' # 把替换的字符用单引号引起来,包括特殊字
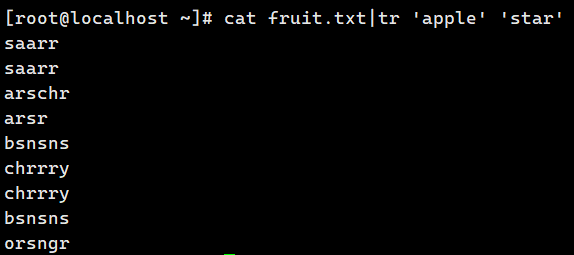
cat fruit | tr 'apple' 'star' #a 替换成 s , p 替换成 a , le 替换成 r
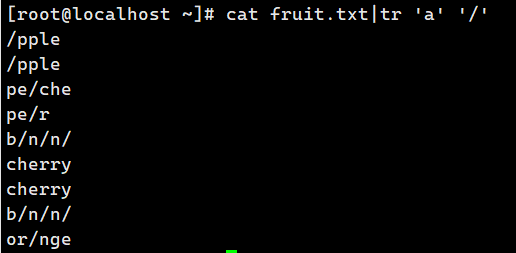
tr 'a' '/' < fruit.txt # 替换 a -> / 多个字符替换成一个
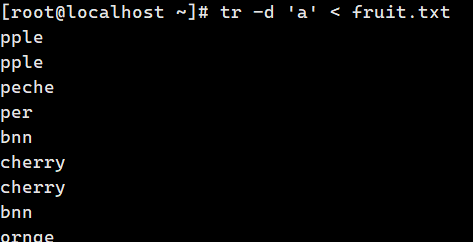
tr -d 'a' < fruit.txt # 删除所有 a
tr -d '\n' < fruit.txt # 删除换行符
tr -s 'p' < fruit.txt # 连续 p 压缩成一个

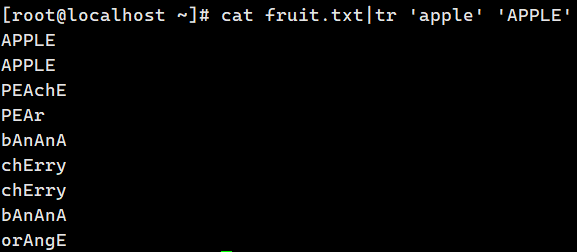

总结:
今天主要相对详细的讲解了下有关正则表达式以及一些有用的命令小工具,希望对读者们有所帮助!