底层
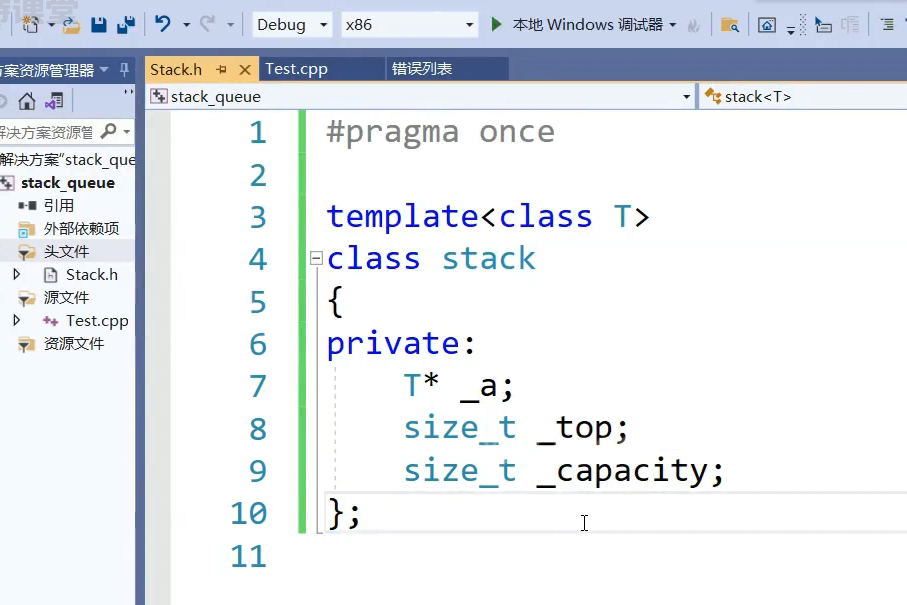
适配器模式:
栈只要支持一端插入删除就行,可以用vector list都可以,可以直接封装vector list 不用原生实现。

这样设计只能说是数组栈或者链式栈,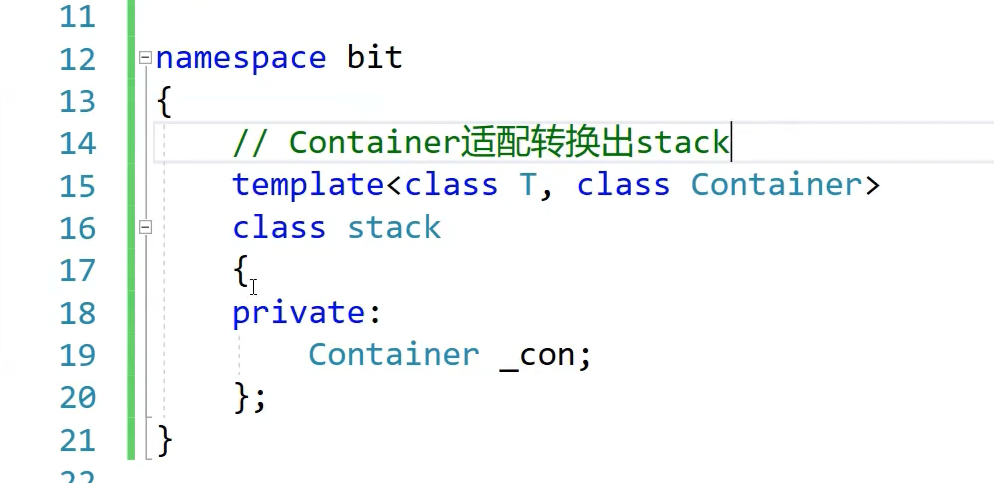
这样就是对container进行 适配转换,构造就不用写了,他是自定义类型,默认调用它的构造
cpp
#pragma once
#include<deque>
//
//template<class T>
//class stack
//{
//private:
// T* _a;
// size_t _top;
// size_t _capacity;
//};
#include<vector>
#include<list>
namespace bit
{
// Containerתstack
template<class T, class Container = deque<T>>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
const T& top() const
{
//return _con.func();
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
Container _con;
};
/*void func()
{
cout << "void func()" << endl;
}*/
}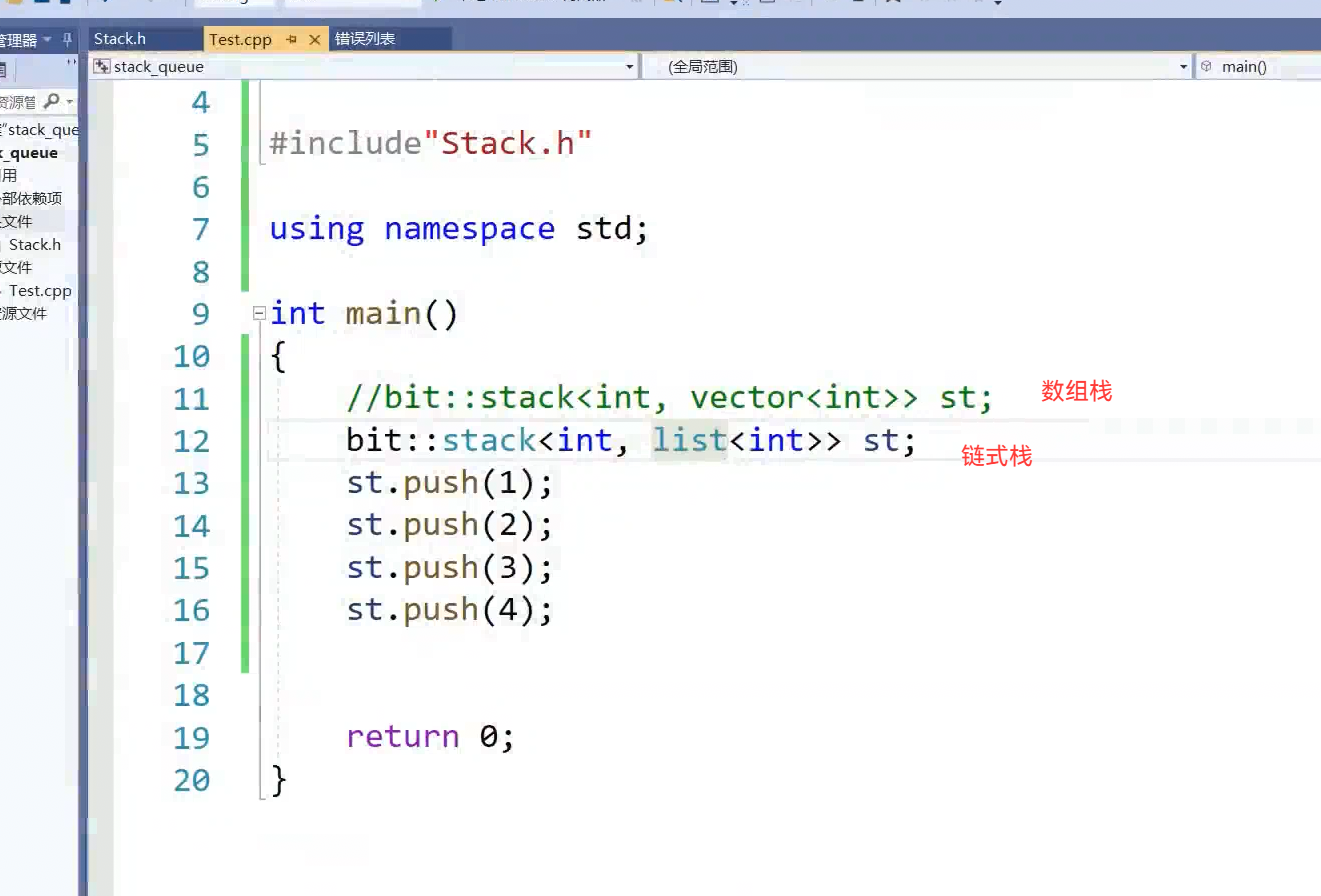
底层形态已发生巨大改变。传布同容器就行。
库里面并没有传第二个模版参数,
因为模版参数跟函数参数类似,函数参数传的是值,对象,模版参数传的是类型,这可以给缺省值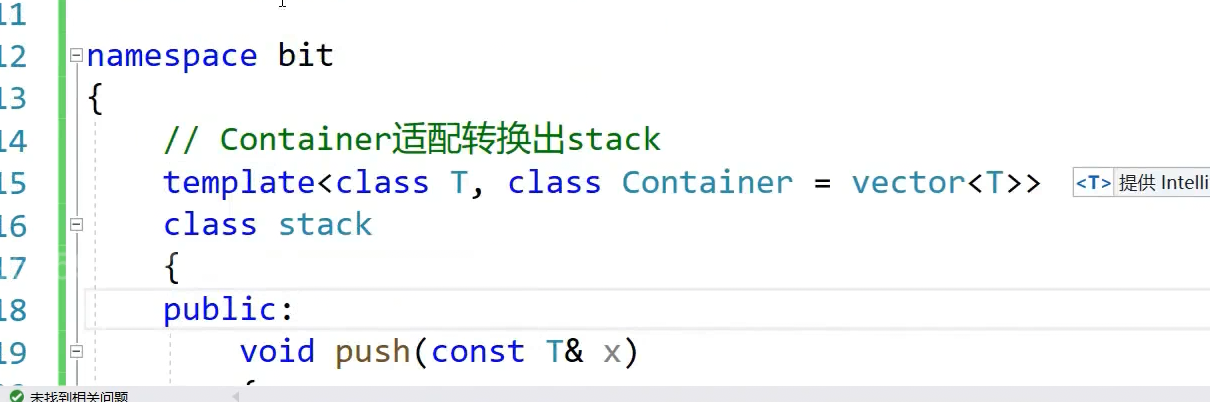
可以用vector默认适配,等会用dequeue..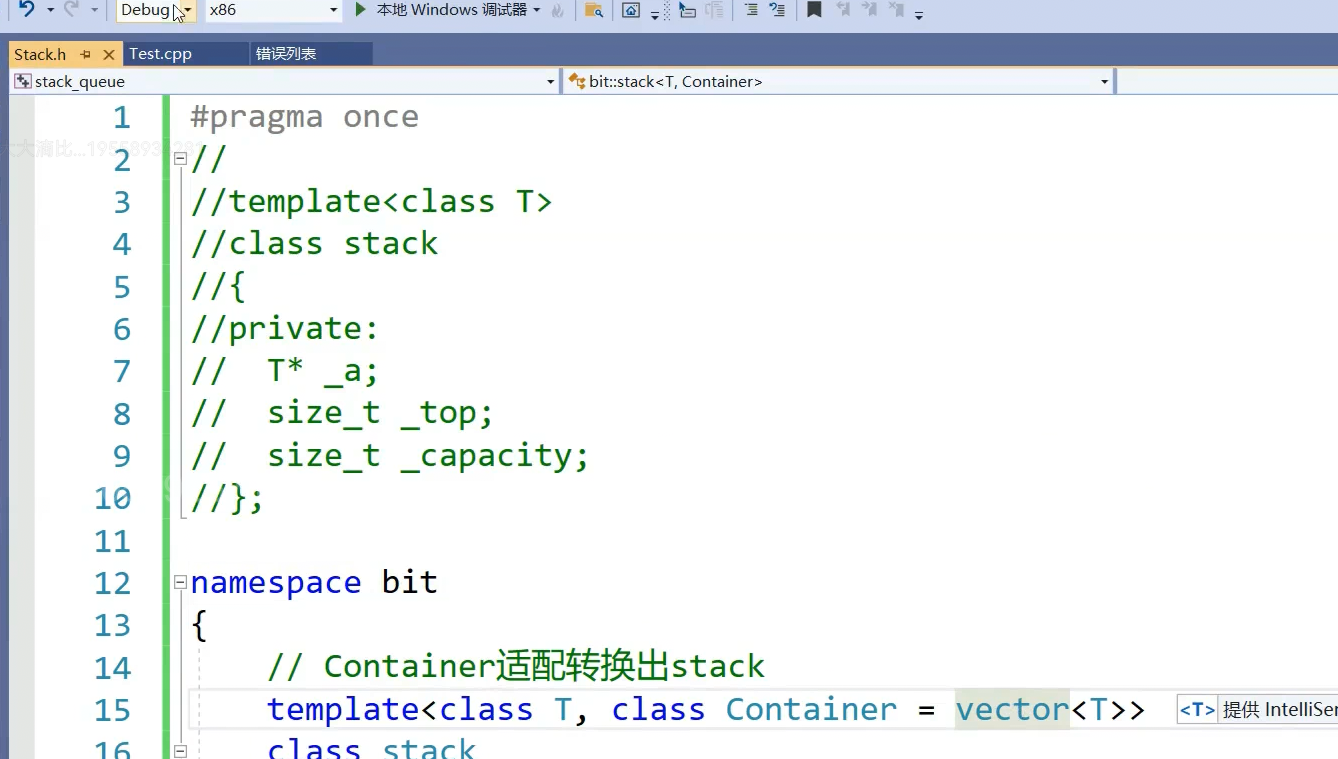
stack.h没有包头文件为什么能用,tect包了,编译器编译时候,预处理所有。h在。c或者。cpp展
开,,所以用vector可以过。
错误:
模版是在实例化之后才进行向上找。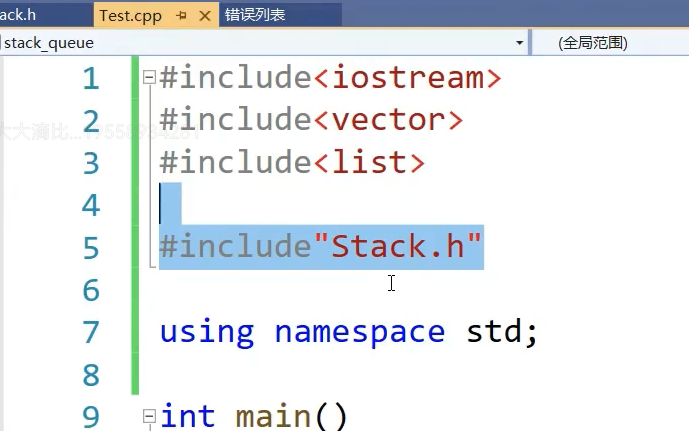
展开后往上找,找不到std,因为这不是模版这是普通函数
以后把。h放后面
 等主函数调用到了才报错,这叫按需实例化,模版实例化时候用到哪些函数实例化哪些,当不用pop就不实例化,细节不检查。
等主函数调用到了才报错,这叫按需实例化,模版实例化时候用到哪些函数实例化哪些,当不用pop就不实例化,细节不检查。
在写queue
queue要先进先出不能用vector,用list
cpp
#pragma once
#include<deque>
namespace bit
{
// ContainerÊÊÅäת>>>>³öqueue
template<class T, class Container = list<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
const T& front() const
{
return _con.front();
}
const T& back() const
{
return _con.back();
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
Container _con;
};
}
cpp
text.cpp
#include<vector>
#include<list>
#include<stack>
#include<queue>
#include<algorithm>
using namespace std;
#include"Stack.h"
#include"Queue.h"
#include"PriorityQueue.h"
int main()
{
//bit::stack<int, vector<int>> st;
//bit::stack<int, list<int>> st;
bit::stack<int, vector<int>> st;
// 类模板实例化时,按需实例化,使用哪些成员函数就实例化哪些,不会全实例化
st.push(1);
st.push(2);
st.push(3);
st.push(4);
cout << st.top() << endl;
st.pop();
//bit::queue<int, list<int>> q;
bit::queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
cout << q.front() << endl;
q.pop();
return 0;
}接下来看一下dequeue,把栈和队列第二个模版参数换成deque,虽然没包deque.h,但是没用缺省值,所以也不报错,也是按需实例化。
deque就是vector和list的缝合怪,vector只支持尾插尾删不支持头插头闪,list只支持各种插入删除不支持下标随机访问
list不支持下标随机访问就是很大问题,排序很慢访问大量数据
很互补。

如果头插,直接在前面开个buffer,指针指向这个buffer,尾插就在后面开个buffer让指针指向他,
也有扩容,但是扩容不需要拷贝全部数据,中控数组满了就要扩容,开一个更大中控数组,把数据拷贝下来,中控的指针数组需要扩容。
x是第几个buffer数组,y是这个数组第几个数据。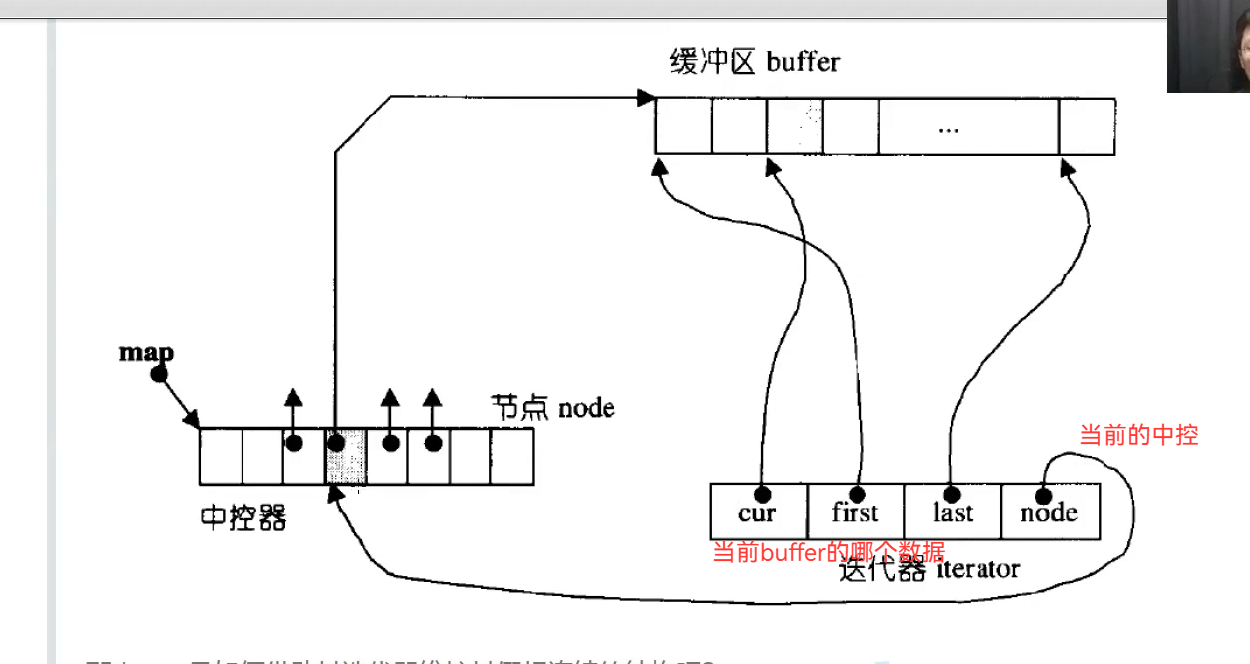
Node(二级指针)是当前指向那个buffer的中控,
主要靠迭代器管理,理解了迭代器就理解了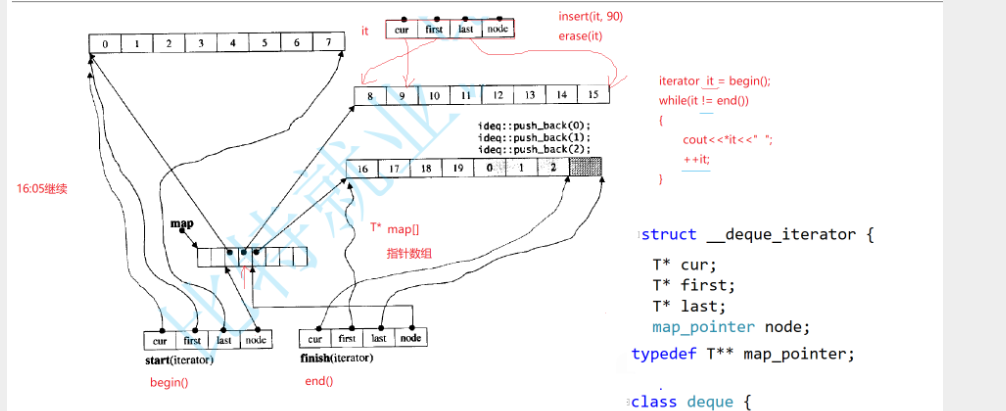
finish 的cur指向最后一个数据下一个位置,迭代器遍历是怎么走的
就算两个迭代器指向同一数组,我们用cur比较,不相等就不是==,start就是最开始的迭代器,
日常++迭代器就是++cur,buffer遍历结束,再找下一个buffer,Node+1就找到下一个位置数组了,解引用就是下一个buffer开始地址了,it是start拷贝给我的,把it里的start指向开始,last指向结束,cur指向第一个位置,Node指向下一个位置,迭代器就指向下一个位置了,*Node给first,buffer大小8,开始+8就是last,cur指向第一个数据位置,就可以开始访问了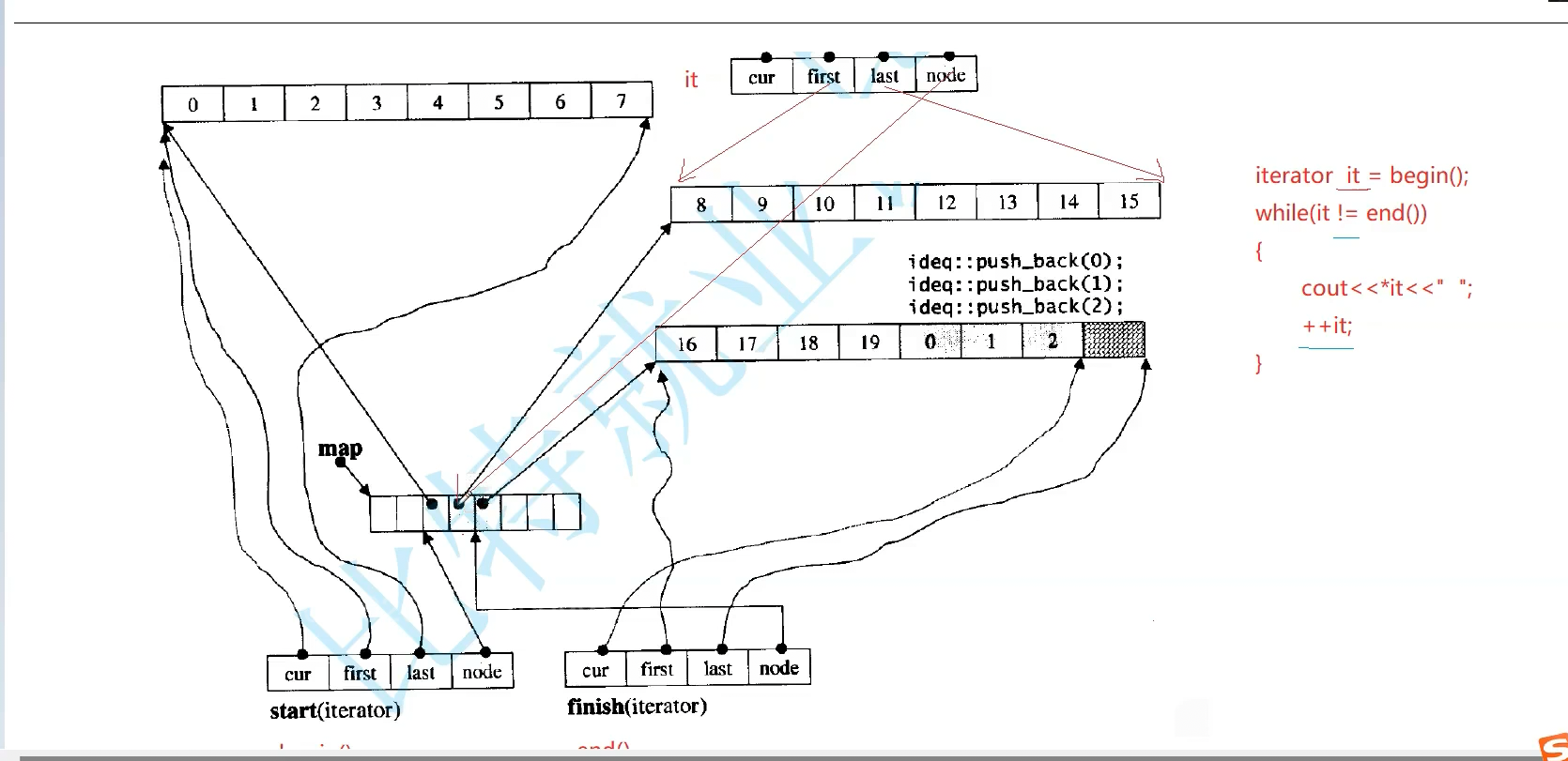
依次加到第三个buffer,最后和end相等了就结束了吗。
看源码,就是走马观花,dequeue这种不重要的了解就行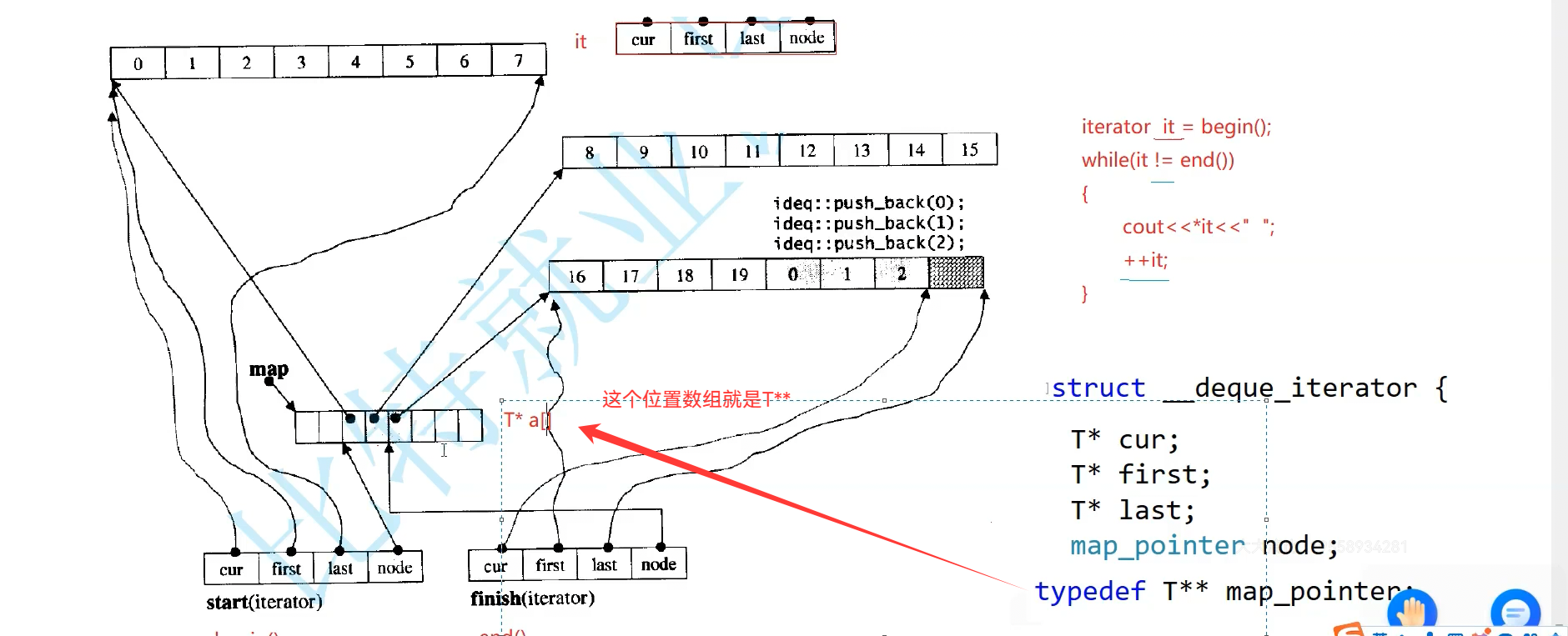
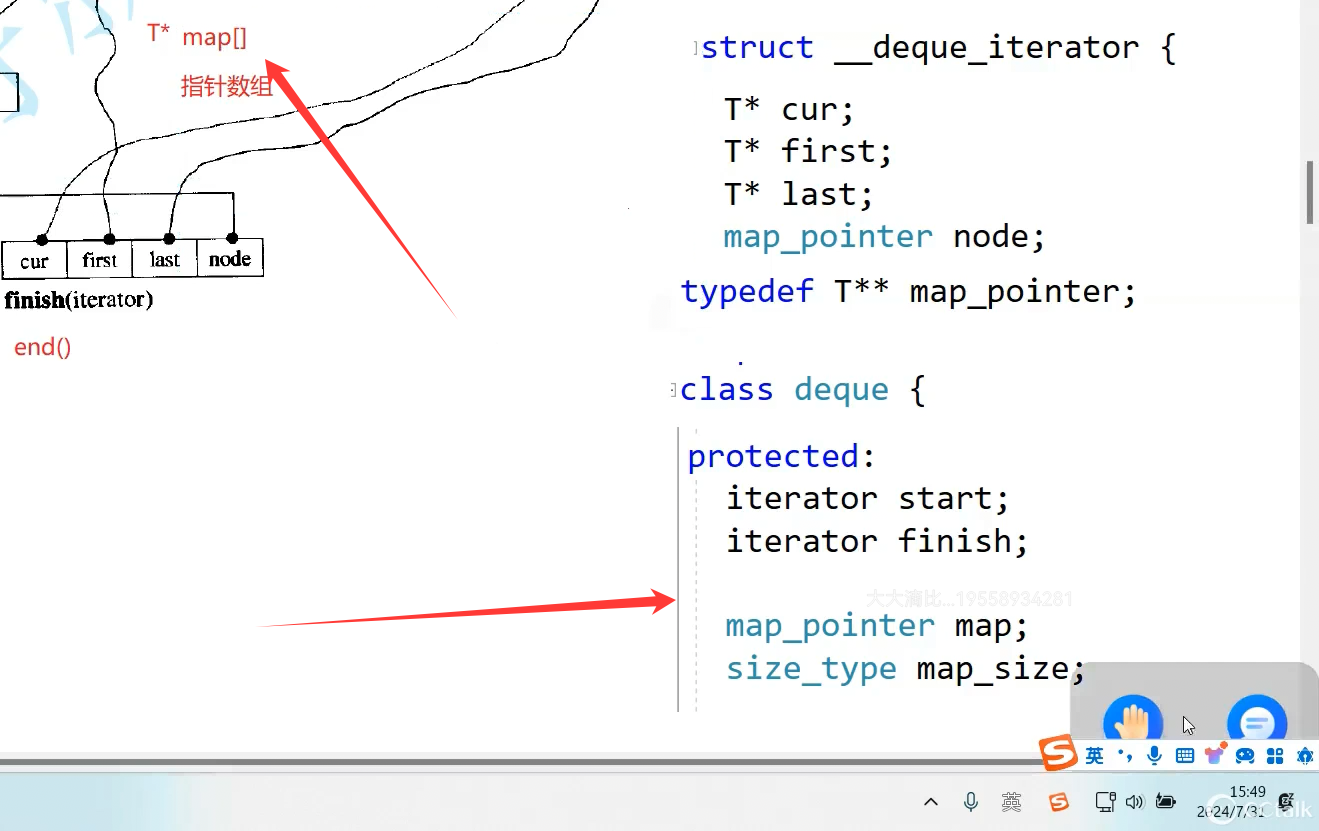
有一个指向这个数组的指针和大小,因为中控数组满了要扩容
再看一下operator++ 解引用就是解引用current
解引用就是解引用current
等于就比较current
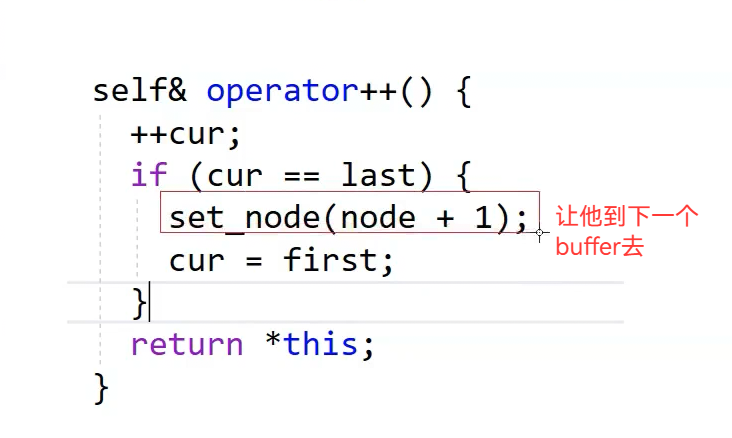
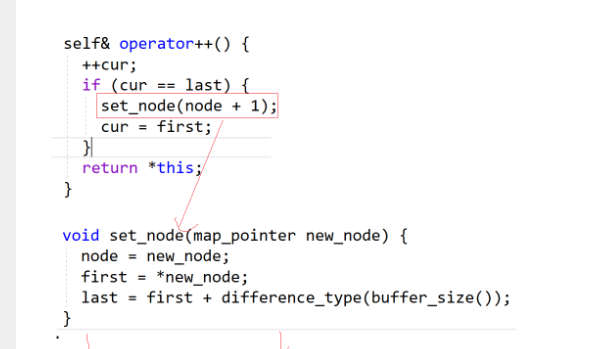
这就是迭代器++的逻辑
头插尾插怎么搞
如果cur!=last那直接cur处插入,然后cur++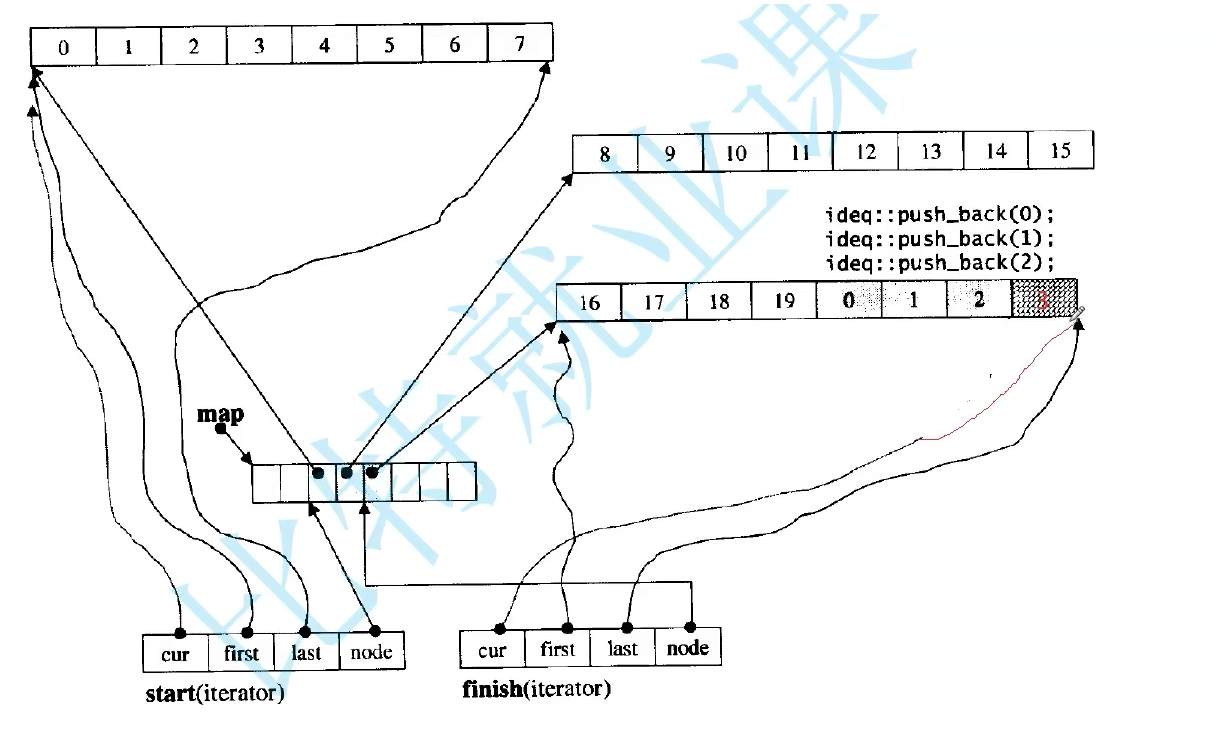
如果满了,cur=last,最后一个buffer也满了,那要新增加一个buffer,,先看中控数组满没满,中控数组满了要扩容,,finish的Node下一个位置指向新的buffer,然后调用stenode,然后firsst指向开始,last结束,然后Node指向刚刚Node下一个位置
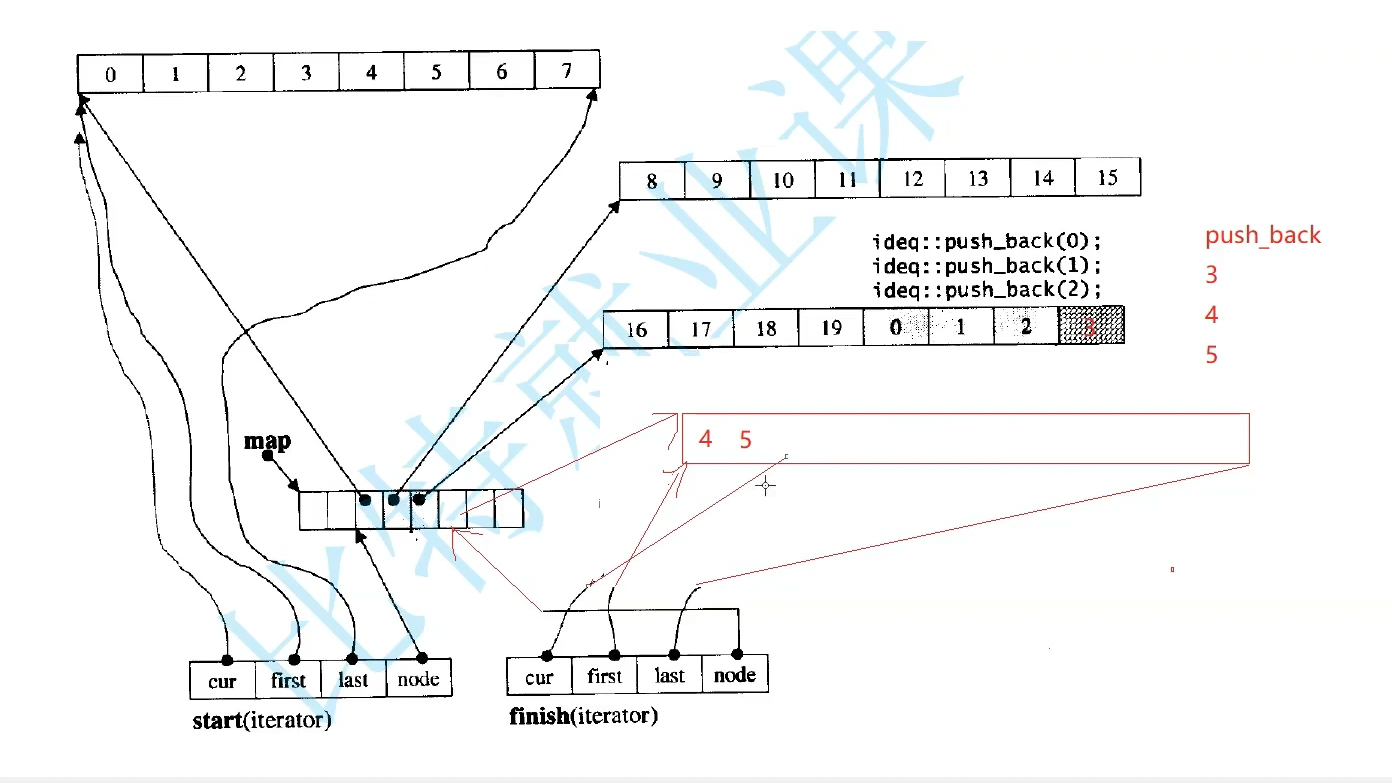
cur指向数据下一个位置,头插中控往左走。所以放中间。如果头插3,4,5,没法插,那就开一个新的buffer,让中控数组前一个位置指向这个buffer,自己的Node--,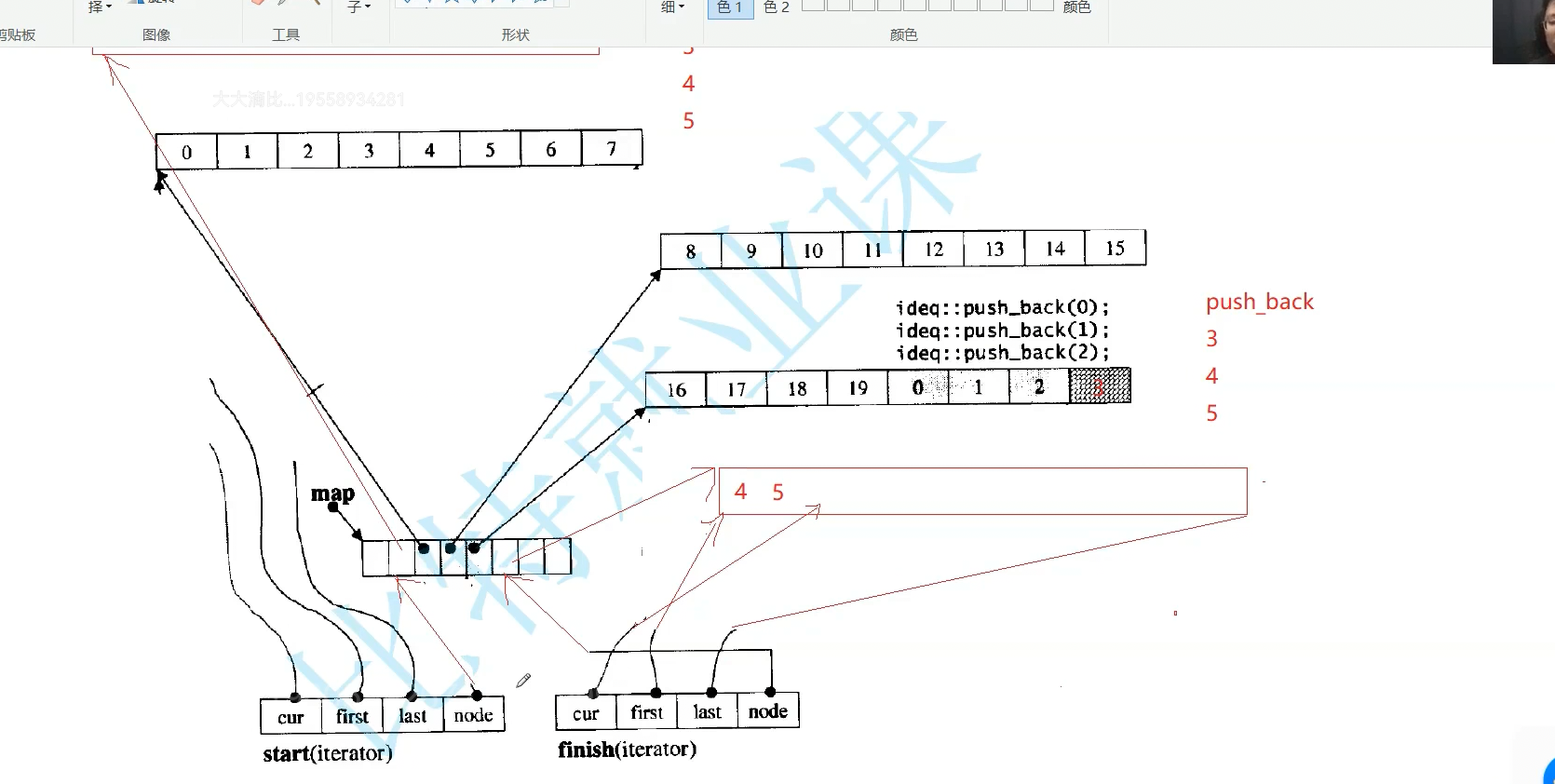
也就是头插尾插要动这个迭代器。插入3时候,first指向buffer开始,last结束,但是头插插在后面。finish指向最后一个数据下一个位置。start相当于begin,指向第一个数据,cur指向5本身
继续头插只要cur不等于first就继续往前走。结构很完美
【】:
依靠迭代器实现
迭代器依靠加所以重载+ 
+调用+=,跟日期类很像,不能直接除和取模,因为头插以后不能第一个buffer是满的,所以访问第i个数据首先看看在不在第一个buffer。如果在,就在第一个buffer访问,不在,就把第一个buffer减掉然后再算。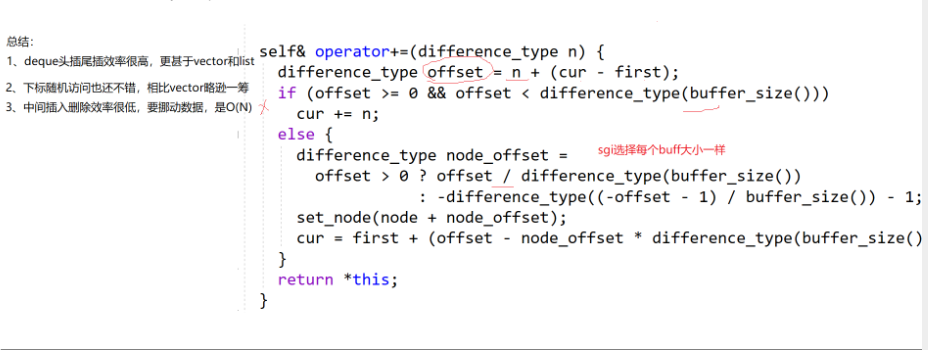
上面是算第几个buffer,下面是每个buffer大小偏移量。buffre第几个.
头插尾插效率更高,list扩容太频繁,vector,越到后面扩容越大,要拷贝要释放,buffer满了,新开buffer指针一改放就行,中控数组才开始扩容,只考指针,代价很低,头插尾插效率很高
插入时候,只把当前buffer扩容,删除把当前buffer缩小,会导致 每个buffer大小不一样,会导致【】效率下降,就不能\了,就得一个buffer一个buuffert的减,看看在第几个buffer,

库里是牺牲了insert和erase,,大于0选择\就是第几个buffer,每个buffer大小一样,不一样的话代价太大。
dequeue想替代vector或list,根本不行。但是有亮点,没有中间插入删除就好,所以栈和dequeue就很合理。
感受下面向对象的封装。适配器也是种封装,栈都实现好了,别管封装的底层,用就行。封装就是屏蔽底层细节,应该学一下别人的封装,高手就要看优秀的东西。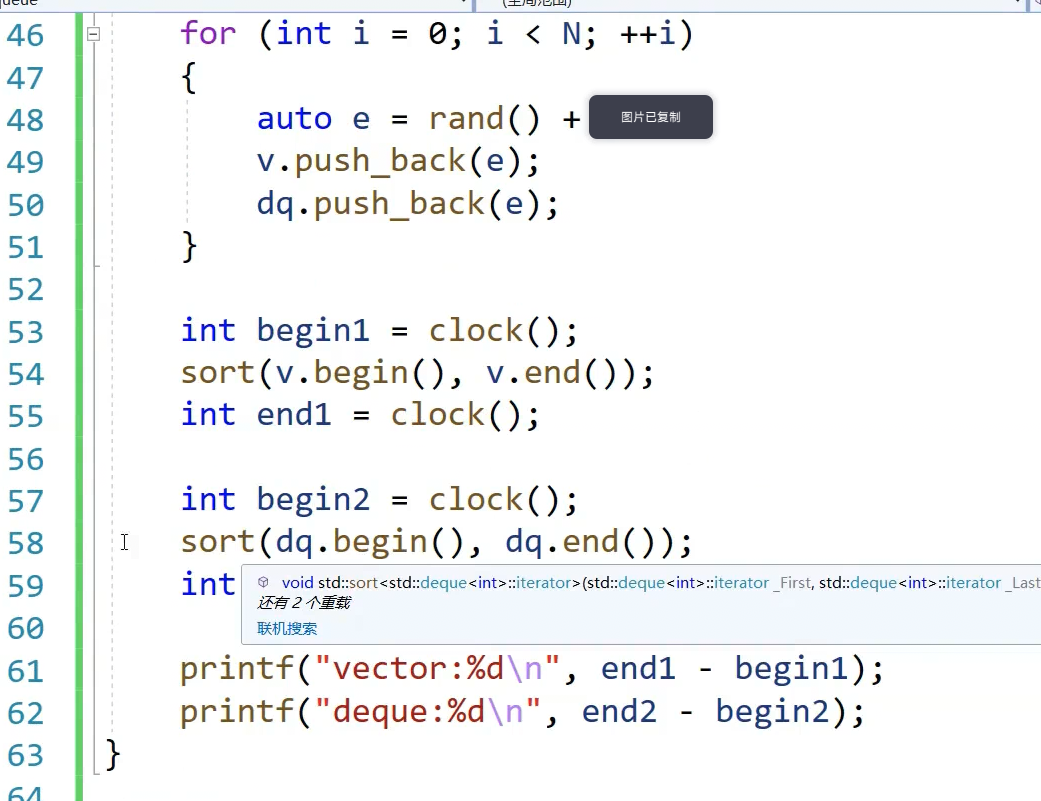
算法用同一个sort,dequeue很慢,【】很慢,