缓存
本地缓存:一种将数据存储在应用程序本地内存中的技术,目的是减少对后端数据源(如数据库、远程服务)的访问次数,从而提高应用程序的性能和响应速度。本地缓存通常用于存储频繁访问且不经常变化的数据。
本地缓存的优势
- 提高性能:减少对后端数据源的访问次数,降低网络延迟,提高响应速度。
- 减轻后端压力:减少后端数据源的负载,提高系统的整体性能。
- 提高可用性:即使后端数据源不可用,缓存中的数据仍然可以提供服务。
本地缓存的局限性
- 数据一致性:缓存中的数据可能与后端数据源中的数据不一致,需要有效的缓存更新机制。
- 内存限制:本地缓存占用内存资源,需要合理管理缓存大小。
- 单点故障:本地缓存依赖于单个节点,如果节点故障,缓存中的数据会丢失
@EnableCaching:开启缓存注解功能,通常加在启动类上
@Cacheable:在方法执行前先查询缓存中是否有数据,如果有数据,则直接返回缓存数据,如果没有缓存数据,调用方法将方法返回值放到缓存中
@CachePut:将方法的返回值放到缓存
@CacheEvict:将一条或多条数据从缓存中删除
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>开启缓存功能
java
package com.itheima;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.cache.annotation.EnableCaching;
@SpringBootConfiguration
@EnableCaching // 开启缓存功能
public class SpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootApplication.class, args);
}
}使用缓存
java
package com.itheima.service.impl;
import com.itheima.domain.User;
import com.itheima.service.UserService;
import org.springframework.cache.annotation.Cacheable;
public class UserServiceImpl implements UserService {
@Override
// 开启缓存,将查询到的数据放到id为key的缓存中,value = "cacheSpace"是缓存的位置
@Cacheable(value = "cacheSpace", key = "#id")
public User getById(Integer id) {
return bookDao.selectById(id);
}
}
java
package com.itheima.service.impl;
import com.itheima.domain.User;
import com.itheima.service.UserService;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
public class UserServiceImpl implements UserService {
@Override
// 开启缓存,将查询到的数据放到id为key的缓存中,value = "cacheSpace"是缓存的位置(有读取的功能)
@Cacheable(value = "cacheSpace", key = "#id")
@CachePut(value = "cacheSpace", key = "#id") // 向缓存中放入缓存中
public User setById(Integer id) {
return User.selectById(id);
}
public User getById(Integer id) {
return User.selectById(id);
}
//查看缓存中是否有id为键的内容,如果有返回查到的内容,没有返回null
@Cacheable(value = "cacheSpace", key = "#id")
public String get(Integer id) {
return null;
}
}缓存穿透
缓存穿透是指客户端请求数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
理解:当一个缓存和数据库中都不存在的数据请求多次被提交,这些请求查缓存失败都会进行查数据库。
解决方法:
- 缓存空对象,将不存在的请求缓存成一个null
优点:实现简单,维护方便
缺点:
可能造成短期的不一致
会产生额外的内存消耗 - 布隆过滤
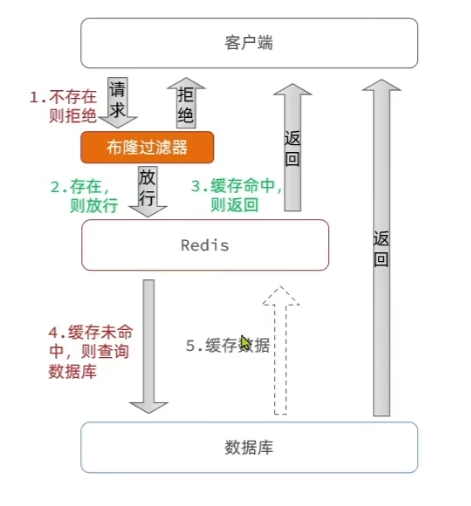
优点:内存占用较少,没有多余key
缺点:
实现复杂
存在误判的可能
缓存雪崩
缓存雪崩:在同一时段大量的缓存key同时失效,或者redis服务当即,导致大量请求到达数据库带来巨大压力
解决方法:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿问题(热点key问题):一个被高并发访问并缓存重建业务交复杂的key突然失效,无数的请求访问会在瞬间给数据库带来巨大的冲击
问题:在缓存失效后,很多用户访问缓存失败,查询数据库,并进行缓存重建(只需一个用户进行缓存重建即可)
解决方案:
- 互斥锁
- 逻辑过期
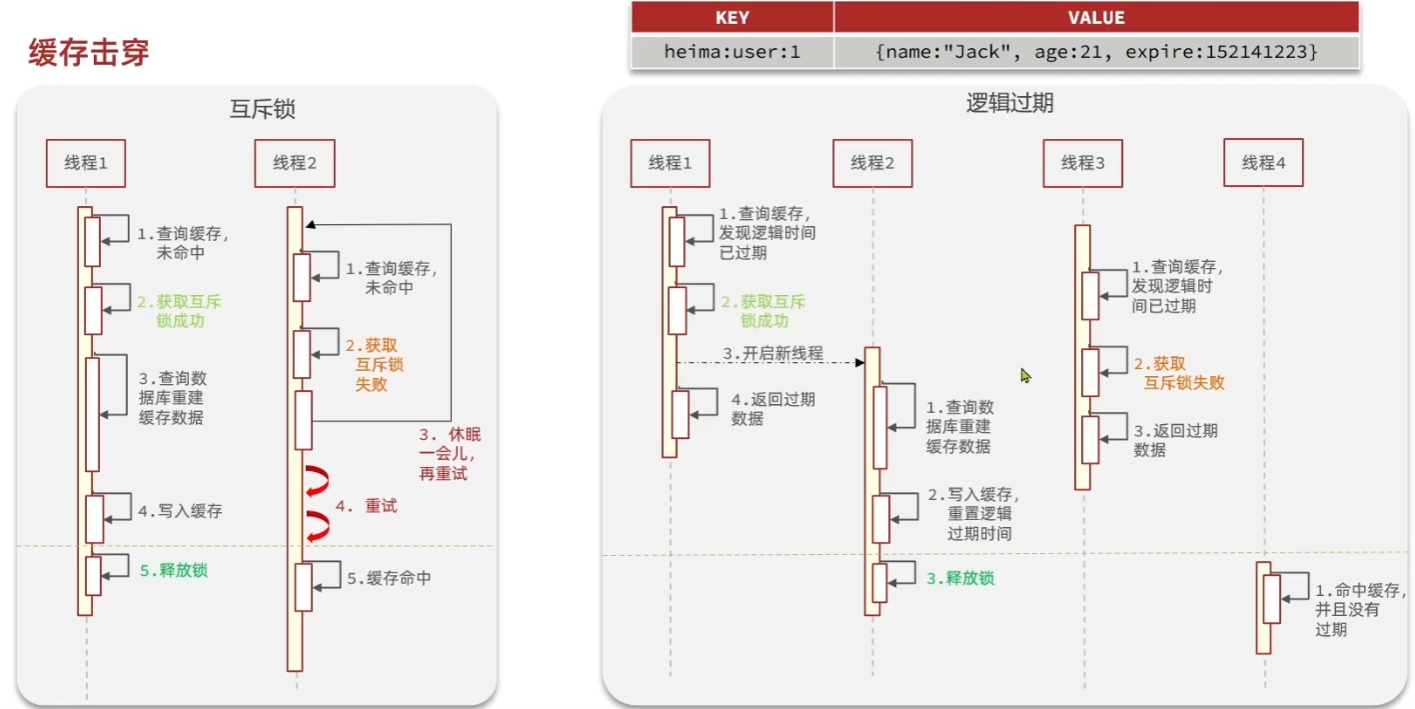
互斥锁:
优点:
- 没有额外的内存消耗
- 保证一致性
- 实现简单
缺点:
- 线程需要等待,性能受影响
- 可能出现死锁
逻辑过期:将线程设置成永远有效,但是设置一个逻辑上的有效期,如果缓存过期了,则先用原来已经过期的缓存用着
优点:线程无需等待,性能较好
缺点:
- 不保证一致性
- 有额外内存消耗
- 实现复杂
互斥锁解决缓存击穿问题
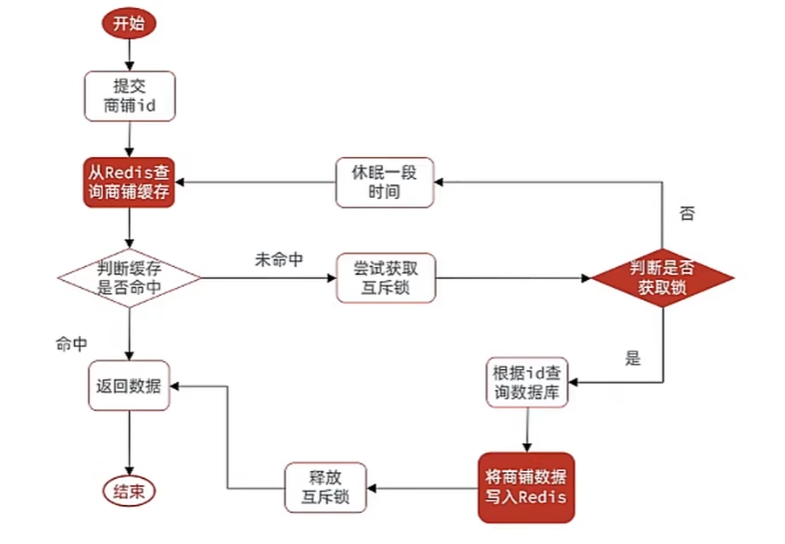
可以通过redis中使用setnx来实现互斥锁
setnx可以对一个变量进行赋值,且只能进行赋值操作和删除操作,上锁就对这个值赋值,释放互斥锁只需要删除这个键值对
setnx进行获取锁
java
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return Boolean.TRUE.equals(flag);
}释放锁
java
private void unlock(String key) {
stringRedisTemplate.delete(key);
}逻辑过期解决缓存击穿问题
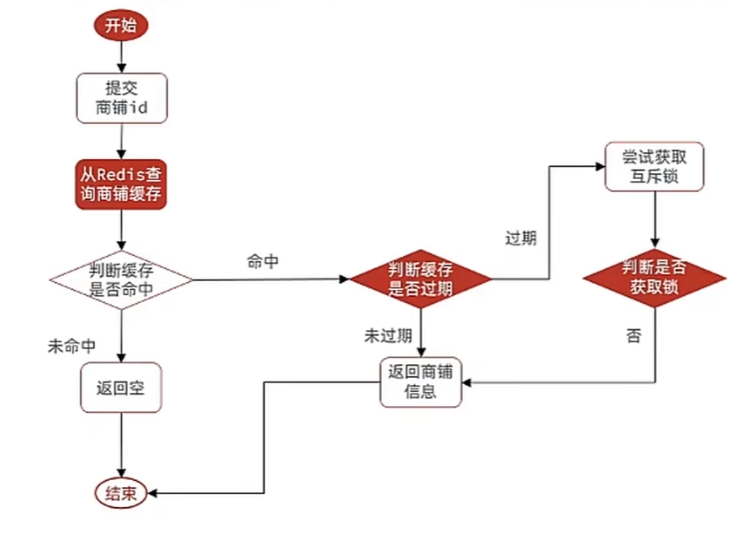
缓存更新策略
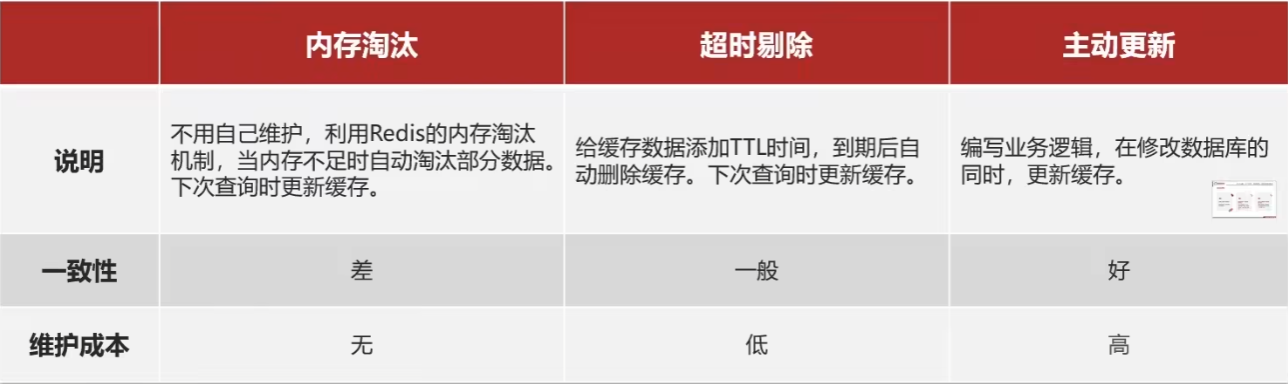
低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存
高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存
好的,图中的内容是关于操作缓存和数据库时需要考虑的三个主要问题:
操作缓存和数据库时有三个问题需要考虑:
-
删除缓存还是更新缓存?
更新缓存: 每次更新数据库都更新缓存,无效写操作较多。
删除缓存: 更新数据库时让缓存失效,查询时再更新缓存。(更优)
-
如何保证缓存与数据库的操作的同时成功或失败?
单体系统: 将缓存与数据库操作放在一个事务。
分布式系统: 利用TCC等分布式事务方案。
-
先操作缓存还是先操作数据库?
先删除缓存,再操作数据库。
先操作数据库,再删除缓存。(更优)