从0到1:用 Spring Boot 4 + Java 21 打造一个智能AI面试官平台
集成大模型、向量数据库与异步流处理,实现简历分析、模拟面试与知识库问答
大家好!今天想和大家分享一个我近期开发的、非常有趣的全栈项目------智能AI面试官平台。这个项目不仅整合了当前最热门的大语言模型(LLM)技术,还巧妙地运用了向量数据库(pgvector)和 Redis Stream 异步消息队列,旨在为求职者和HR提供一套完整的智能化面试辅助解决方案。
整个项目后端基于 Spring Boot 4.0 + Java 21 构建,前端采用 React 18 + TypeScript,技术栈前沿且实用。接下来,我将带大家深入剖析它的核心功能、架构设计以及关键技术选型。
一、项目简介与效果展示
核心目标是解决两个痛点:
- 对求职者:如何获得一份专业、客观的简历评估?如何进行高质量的模拟面试练习?
- 对HR/招聘方:如何高效地从海量简历中筛选出匹配的人才?
通过引入大模型,我们让机器扮演"面试官"的角色,实现了以下三大核心功能模块:
- 简历管理:上传PDF/DOCX等格式简历,系统自动解析内容并生成包含评分、优劣势分析和改进建议的详细报告。
- 模拟面试:基于你的简历内容,AI会生成个性化的面试问题,并在你回答后给出多维度的评分和反馈。
- 知识库问答:上传公司文档、技术手册等资料,构建专属知识库,AI可以基于这些知识进行精准问答。
先来看看最终的效果图,感受一下它的能力!
1. 简历分析效果
上传简历后,系统会立即返回,并在后台进行异步分析。分析完成后,你会得到一份结构清晰、洞察深刻的报告。
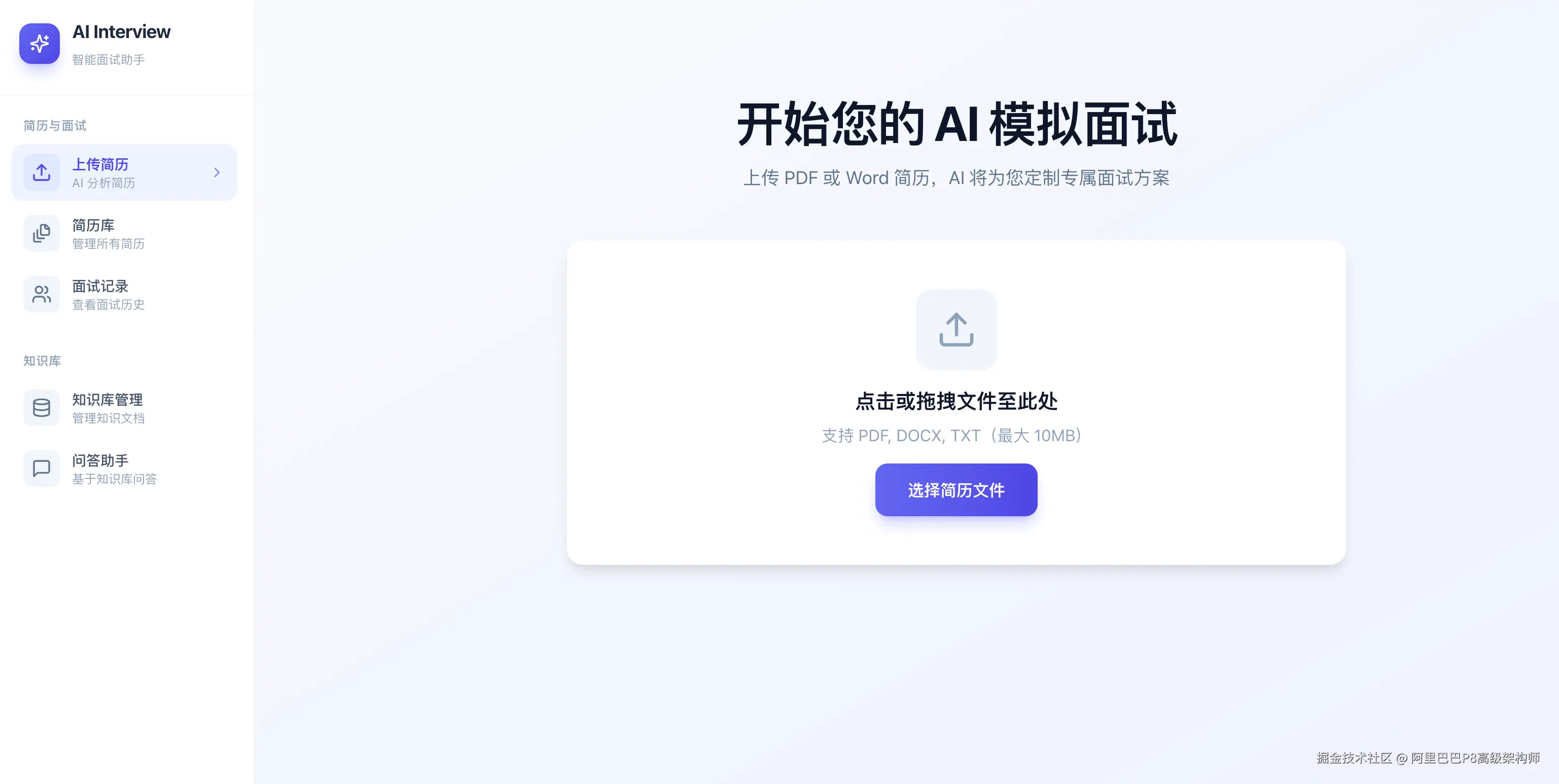
报告详情页不仅有文字分析,还包含了直观的雷达图,让你的能力画像一目了然。

2. 模拟面试体验
面试过程完全模拟真实场景,AI会根据你的简历提出针对性问题。回答结束后,系统会生成包含技术深度、沟通表达等维度的综合评估报告。
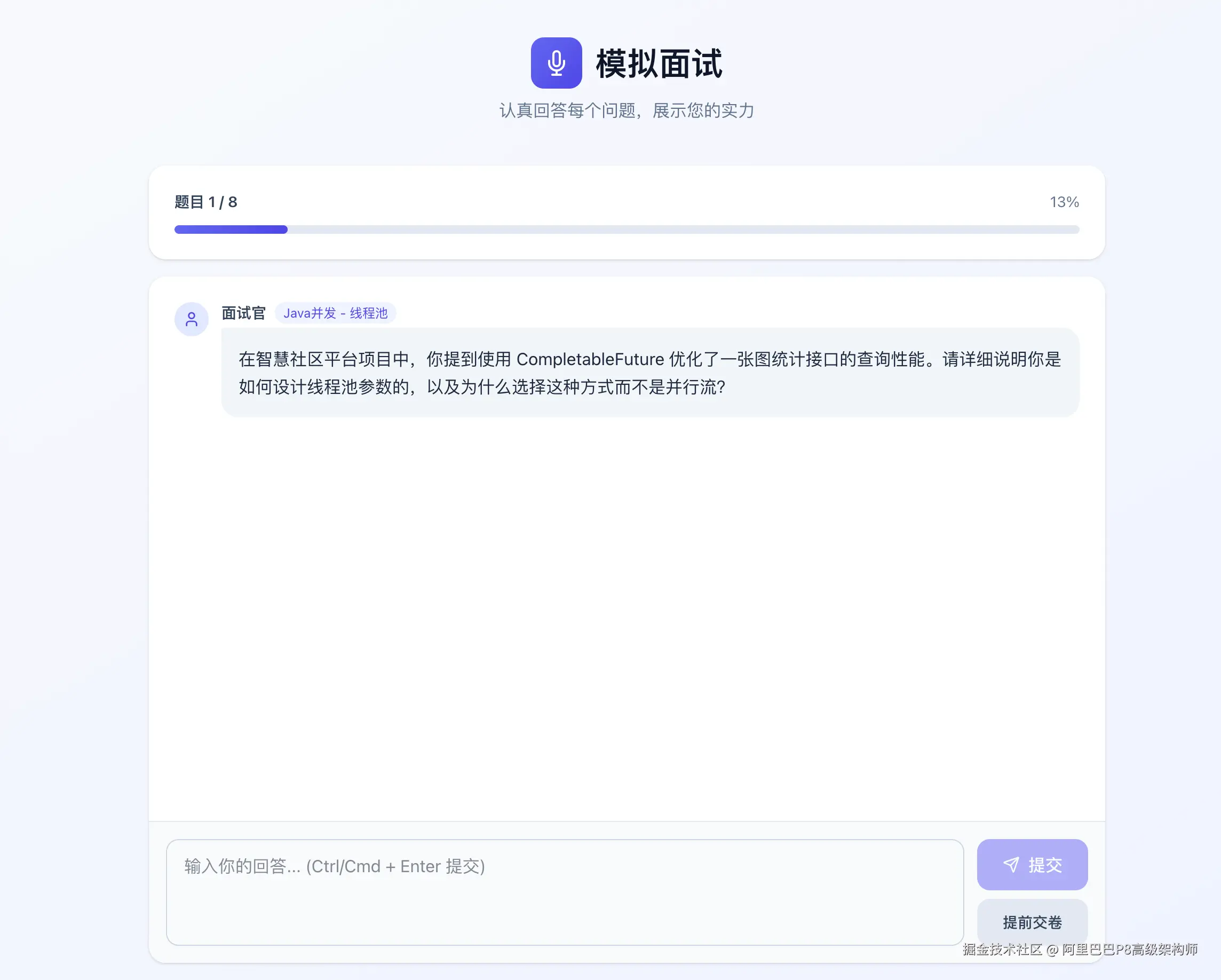

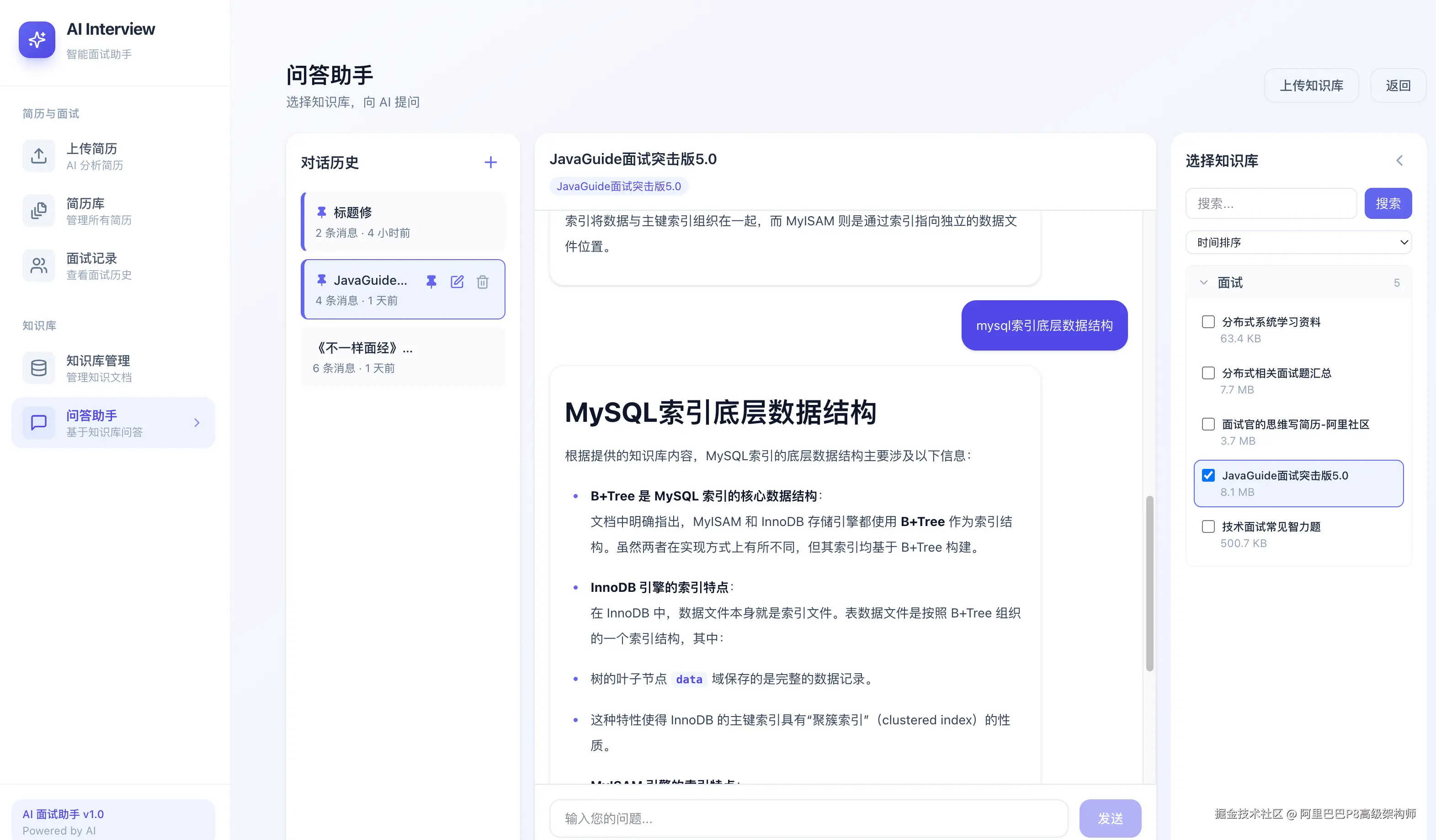
3. 知识库智能问答
你可以上传任何文档(如Java核心技术.pdf),系统会自动将其切片并向量化。之后,你就可以像使用ChatGPT一样,向它提问关于这份文档的任何问题,答案精准且附带原文出处。
二、核心架构与技术选型
项目的整体架构遵循了清晰的分层和模块化设计。
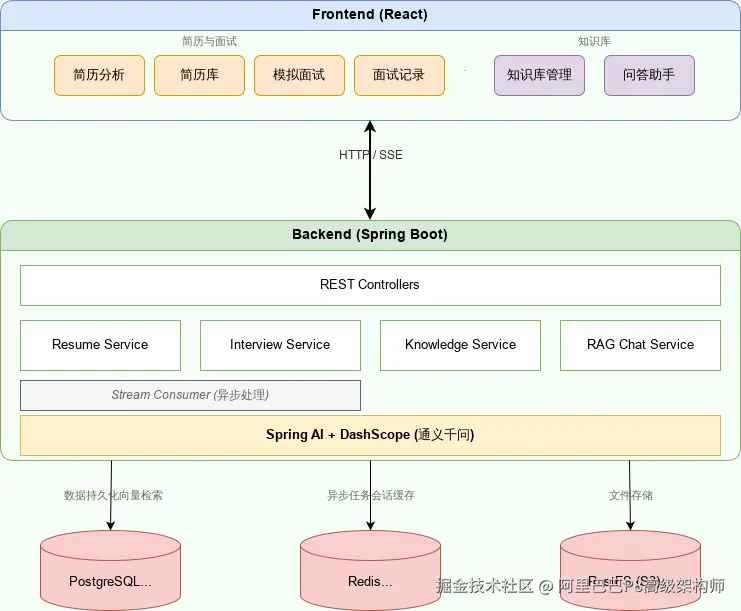
为什么选择这些技术?
在技术选型上,我坚持"够用、简洁、高效"的原则,避免过度设计。
- PostgreSQL + pgvector :传统的关系型数据存储业务信息(用户、简历、面试记录等),而
pgvector扩展则完美地解决了向量存储和相似度检索的问题。无需再引入一个独立的向量数据库(如 Milvus, Pinecone),大大简化了运维复杂度。 - Redis Stream:作为消息中间件,它承担了所有耗时任务的异步处理,比如简历分析和知识库向量化。相比 Kafka 或 RabbitMQ,Redis 在我的技术栈中已是标配,用 Stream 功能来解耦生产者和消费者,既轻量又高效。
- Spring AI 2.0 :这是 Spring 官方推出的 AI 集成框架,它提供了统一的抽象层。通过配置,我可以轻松地接入阿里云的 DashScope (Qwen) 大模型服务,无论是用于聊天(Chat)还是文本嵌入(Embedding),代码都变得非常简洁和标准化。
三、关键技术实现:异步任务处理
简历分析和知识库向量化都是典型的 I/O 密集型且耗时较长的任务。如果同步处理,用户体验会很差。因此,我设计了一套基于 Redis Stream 的异步处理流程。
流程如下:
css
[用户上传] → [保存文件元数据,状态=PENDING] → [发送任务到Stream] → [立即返回给前端]
↓
[Consumer监听Stream]
↓
[执行AI分析/向量化任务]
↓
[更新数据库状态]
↓
[前端轮询获取最新状态]核心代码片段:
1. 任务生产者 (VectorizeStreamProducer.java)
当用户上传知识库后,系统会调用此方法,将任务(kbId, content)发送到名为 kb_vectorize_stream 的 Redis Stream 中。
typescript
public void sendVectorizeTask(Long kbId, String content) {
Map<String, String> message = Map.of(
"kbId", kbId.toString(),
"content", content,
"retryCount", "0"
);
// 发送消息到 Redis Stream
redisService.streamAdd("kb_vectorize_stream", message);
}2. 任务消费者 (VectorizeStreamConsumer.java)
这是一个独立的后台线程,持续监听 Stream。一旦有新消息,就取出并执行 vectorService.vectorizeAndStore() 方法进行向量化,并更新知识库的状态(PROCESSING -> COMPLETED/FAILED)。
scss
private void consumeLoop() {
while (running.get()) {
// 从 Stream 读取消息
Map<StreamMessageId, Map<String, String>> messages =
redisService.streamReadGroup(...);
for (var entry : messages.entrySet()) {
processMessage(entry.getKey(), entry.getValue());
}
}
}
private void processMessage(StreamMessageId id, Map<String, String> data) {
try {
updateVectorStatus(kbId, VectorStatus.PROCESSING, null);
vectorService.vectorizeAndStore(kbId, content); // 核心向量化逻辑
updateVectorStatus(kbId, VectorStatus.COMPLETED, null);
ackMessage(id); // 确认消息已处理
} catch (Exception e) {
// 处理失败,支持重试机制
if (retryCount < MAX_RETRY) {
retryMessage(kbId, content, retryCount + 1);
} else {
updateVectorStatus(kbId, VectorStatus.FAILED, e.getMessage());
}
ackMessage(id); // 无论成功失败都要ACK,防止重复消费
}
}这套机制保证了系统的高响应性和可靠性,即使任务失败,也有自动重试机制兜底。
四、RAG(检索增强生成)的实现
知识库问答的核心是 RAG 技术。其流程是:用户提问 → 向量化问题 → 在pgvector中检索相似文档片段 → 将片段和问题一起交给大模型生成答案。
得益于 Spring AI 的 PgVectorStore,这一切的实现变得异常简单。
scss
// 1. 创建向量存储客户端
@Bean
public PgVectorStore vectorStore(JdbcTemplate jdbcTemplate, EmbeddingClient embeddingClient) {
return new PgVectorStore(jdbcTemplate, embeddingClient, ...);
}
// 2. 在Service中查询
public Flux<String> answerQuestionStream(List<Long> kbIds, String question) {
// a. 根据知识库ID构造检索过滤器
FilterExpression filter = ...;
// b. 使用向量存储进行相似性搜索
List<Document> documents = vectorStore.similaritySearch(
SearchRequest.query(question).withTopK(5).withFilterExpression(filter)
);
// c. 将检索到的文档和问题组装成Prompt
String prompt = buildRagPrompt(documents, question);
// d. 调用大模型进行流式(SSE)回答
return chatClient.stream(prompt);
}前端通过 Server-Sent Events (SSE) 接收流式响应,实现了打字机效果,用户体验极佳。
五、总结与展望
这个项目是一个很好的实践案例,它展示了如何将 LLM、向量数据库和现代 Web 开发技术结合起来,解决实际问题。整个项目代码结构清晰,技术选型务实,非常适合想要学习 AI 应用开发的朋友参考。
目前,项目还有一些待办事项(TODO),比如:
- 实现模拟面试的追问功能,让对话更自然。
- 将知识库与模拟面试打通,例如在面试中可以引用知识库中的内容。
- 进一步优化 PDF 报告的样式和内容。
如果你对这个项目感兴趣,欢迎访问 GitHub 仓库查看完整源码、详细的部署文档和更多技术细节!希望这篇文章能给你带来启发。