第一章:编译全流程和宏的深度解析
1.1 编译流程完整剖析
四阶段编译过程详解
在嵌入式开发中,理解编译全过程至关重要。让我们通过具体示例深入分析每个阶段:
预处理阶段实战分析
cpp
// example.c
#include <stdio.h>
#define MAX_SIZE 100
#define SQUARE(x) ((x) * (x))
int main() {
int size = MAX_SIZE;
int result = SQUARE(size + 1); // 注意这里的参数传递
printf("Result: %d\n", result);
return 0;
}预处理命令和结果分析:
bash
# 生成预处理文件
gcc -E example.c -o example.i
# 查看预处理结果的关键部分
cat example.i | grep -A 10 -B 5 "main"预处理阶段完成的核心工作:
-
头文件包含 :将
#include <stdio.h>替换为完整的头文件内容 -
宏展开 :
MAX_SIZE被替换为100,SQUARE(size + 1)被展开为((size + 1) * (size + 1)) -
条件编译处理 :处理
#if,#ifdef,#ifndef等指令 -
注释删除:所有注释被移除
关键陷阱 :宏展开时的运算符优先级问题。多加括号是关键。
cpp
// 危险的宏定义
#define SQUARE(x) x * x
int result = SQUARE(1 + 2); // 展开为 1 + 2 * 1 + 2 = 5,而不是期望的9
// 安全的宏定义
#define SQUARE(x) ((x) * (x)) // 正确展开为 ((1 + 2) * (1 + 2)) = 9编译阶段深度解析
编译阶段将预处理后的C代码转换为汇编代码,进行严格的语法和语义检查:
bash
# 生成汇编代码
gcc -S example.i -o example.s
# 查看生成的汇编代码
cat example.s编译阶段的关键检查:
-
类型检查和类型转换验证
-
函数声明与定义的一致性检查
-
变量作用域和生命周期分析
-
优化机会识别(常量传播、死代码消除等)
链接阶段的复杂场景
bash
# 错误信息:multiple definition of `variable_name'
# 原因:全局变量在多个文件中定义
# 解决方案:使用extern声明,确保变量只在一个地方定义常见链接错误及解决方案:
1.未定义引用错误
bash
# 错误信息:undefined reference to `function_name'
# 原因:函数声明存在但找不到实现
# 解决方案:确保所有声明的函数都有对应的实现文件被链接2.重复定义错误
bash
# 错误信息:multiple definition of `variable_name'
# 原因:全局变量在多个文件中定义
# 解决方案:使用extern声明,确保变量只在一个地方定义正确的多文件组织方式:
cpp
// header.h
#ifndef HEADER_H
#define HEADER_H
extern int global_var; // 声明而非定义
void function(void);
#endif
// source.c
#include "header.h"
int global_var = 0; // 实际定义
void function(void) { /* 实现 */ }1.2 宏的高级应用与陷阱规避
条件编译的工程级应用
Debug/Release模式智能切换:
cpp
// 智能调试宏系统
#ifdef DEBUG
#define DBG_PRINT(fmt, ...) \
do { \
fprintf(stderr, "[%s:%d] " fmt, __FILE__, __LINE__, ##__VA_ARGS__); \
} while(0)
#define DBG_ASSERT(cond) \
do { \
if (!(cond)) { \
fprintf(stderr, "Assertion failed: %s, at %s:%d\n", #cond, __FILE__, __LINE__); \
abort(); \
} \
} while(0)
#else
#define DBG_PRINT(fmt, ...) // 空宏,在Release版本中不产生任何代码
#define DBG_ASSERT(cond) // 空宏
#endif
// 使用示例
int sensitive_operation(int value) {
DBG_PRINT("Entering sensitive_operation with value %d\n", value);
DBG_ASSERT(value > 0);
int result = value * 2;
DBG_PRINT("Operation result: %d\n", result);
return result;
}平台特定代码的条件编译:
cpp
// 跨平台处理
#ifdef LINUX
#include <sys/time.h>
#define GET_CURRENT_TIME(tv) gettimeofday(&(tv), NULL)
#elif defined(WINDOWS)
#include <windows.h>
#define GET_CURRENT_TIME(tv) GetSystemTimeAsFileTime(&(tv))
#else
#error "Unsupported platform"
#endif宏函数的深度优化
安全的多语句宏编写模式 :使用do while语句最安全!
cpp
// 错误的宏定义:可能导致if-else匹配问题
#define SWAP_BAD(a, b) \
temp = a; \
a = b; \
b = temp
// 正确的多语句宏定义
#define SWAP_SAFE(type, a, b) \
do { \
type temp = (a); \
(a) = (b); \
(b) = temp; \
} while(0)
// 类型安全的交换宏
#define SWAP(type, a, b) \
do { \
type __swap_temp = (a); \
(a) = (b); \
(b) = __swap_temp; \
} while(0)
// 使用示例
int x = 10, y = 20;
SWAP(int, x, y); // 安全交换性能关键的宏优化:
cpp
// 用于嵌入式系统的位操作宏
#define BIT(n) (1UL << (n))
#define SET_BIT(reg, n) ((reg) |= BIT(n))
#define CLR_BIT(reg, n) ((reg) &= ~BIT(n))
#define TGL_BIT(reg, n) ((reg) ^= BIT(n))
#define CHK_BIT(reg, n) ((reg) & BIT(n))
// 硬件寄存器操作示例
#define GPIO_BASE 0x40020000
#define GPIO_MODER_OFFSET 0x00
#define GPIO_BSRR_OFFSET 0x18
#define GPIO_REG(offset) (*(volatile uint32_t*)(GPIO_BASE + (offset)))
// 设置GPIO引脚为输出模式
#define GPIO_SET_OUTPUT(pin) \
do { \
uint32_t moder = GPIO_REG(GPIO_MODER_OFFSET); \
moder &= ~(0x3UL << (2 * (pin))); /* 清除模式位 */ \
moder |= (0x1UL << (2 * (pin))); /* 设置为输出模式 */ \
GPIO_REG(GPIO_MODER_OFFSET) = moder; \
} while(0)高级宏技巧揭秘
字符串化运算符#的妙用:
cpp
// 自动生成调试信息
#define VARIABLE_TRACE(var) \
printf("Variable " #var " at address %p has value: ", &(var)); \
printf("%d\n", (var))
// 使用示例
int important_value = 42;
VARIABLE_TRACE(important_value);
// 输出: Variable important_value at address 0x7ffeeb4d4a4c has value: 42连接运算符##的高级应用:
cpp
// 自动生成函数族
#define DECLARE_GET_SET(type, name) \
type get_##name(void) { return name; } \
void set_##name(type value) { name = value; }
// 自动生成枚举和字符串映射
#define ENUM_CASE(name) case name: return #name;
#define DEFINE_ENUM(ename, ...) \
typedef enum { __VA_ARGS__ } ename; \
const char* ename##_to_string(ename value) { \
switch(value) { \
__VA_ARGS__ \
default: return "UNKNOWN"; \
} \
}
// 使用示例
DEFINE_ENUM(Color, RED, GREEN, BLUE)
// 生成:
// typedef enum { RED, GREEN, BLUE } Color;
// const char* Color_to_string(Color value) { ... }编译参数的高级用法
嵌入式开发中的编译优化:
bash
# 调试版本配置
gcc -g -O0 -DDEBUG -Wall -Wextra -Werror -o debug_app source.c
# 发布版本配置
gcc -O2 -DNDEBUG -fdata-sections -ffunction-sections -Wl,--gc-sections -o release_app source.c
# 特定处理器优化
gcc -mcpu=cortex-m4 -mthumb -mfpu=fpv4-sp-d16 -mfloat-abi=hard -o embedded_app source.c宏定义的命令行控制:
bash
# 动态定义多个宏
gcc -DARCH_ARM -DCPU_CORTEX_M4 -DDEBUG_LEVEL=3 -o app source.c
# 等价于在代码中写:
#define ARCH_ARM
#define CPU_CORTEX_M4
#define DEBUG_LEVEL 31.3 实战经验总结
宏使用的黄金法则
-
括号规则:每个参数和整个表达式都要用括号包围
-
多语句规则 :使用
do { ... } while(0)结构确保宏的语句完整性 -
副作用警惕:避免参数多次求值导致的副作用
-
调试友好:为调试版本和发布版本提供不同的宏实现
编译流程的工程实践
-
增量编译优化:合理组织头文件依赖,减少不必要的重新编译
-
错误处理策略:为每个编译阶段建立相应的错误检测和处理机制
-
内存布局控制:通过链接脚本精确控制嵌入式系统的内存分配
这一章的深度解析为后续理解C语言的高级特性奠定了坚实基础。在嵌入式开发中,对编译过程和宏机制的深刻理解,往往是写出高质量代码的关键。
第二章:关键字、运算符、逻辑运算深度解析
大体可分为数据类型关键字、修饰关键字、逻辑关键字。
2.1 数据类型关键字
sizeof关键字
sizeof是关键字、运算符,不是函数。在编译时,就已经计算完成结果了。
cpp
// sizeof是编译时运算符,不是函数
int array[100];
size_t size1 = sizeof(array); // 编译时计算为400
size_t size2 = sizeof(int[100]); // 同样为400,编译时已知
// 运行时数组大小无法通过sizeof获取
void process_array(int arr[]) {
// 这里sizeof(arr)返回指针大小,不是数组大小
printf("Size in function: %zu\n", sizeof(arr)); // 通常为4或8
}
// 编译时类型大小检查
_Static_assert(sizeof(int) == 4, "int must be 4 bytes");
_Static_assert(sizeof(char) == 1, "char must be 1 byte");char类型的特殊性质
声明和定义的区别:定义是实实在在地分配了内存,和声明没有。
内存访问的方式:标签访问和地址访问。
char = 'a' 等价于 char = 97。看你打印时是以%d还是%s输出
cpp
// char的符号性由编译器决定
char c1 = 200; // 可能是有符号的-56,或是无符号的200
// 明确的符号声明
signed char sc = -128; // 明确有符号
unsigned char uc = 255; // 明确无符号
// 字符与整数的等价性
char ch = 'A';
printf("As char: %c, as decimal: %d\n", ch, ch); // 输出: A, 65
// 嵌入式中的特殊应用:寄存器访问
volatile unsigned char* uart_data = (volatile unsigned char*)0x40000000;
*uart_data = 'X'; // 向UART发送字符int类型与CPU的适配性
int:最适合CPU的数据类型。
大小和编译器有关。
CPU拥有FPU单元的,适合进行浮点数的计算。
cpp
// int通常是机器字长,最适合CPU处理
printf("int size: %zu bytes\n", sizeof(int));
// 有FPU时的浮点运算优化
#ifdef __FPU_PRESENT
// 使用硬件浮点
float hardware_float_calc(float a, float b) {
return a * b + a / b; // 硬件加速
}
#else
// 软件模拟浮点(较慢)
float software_float_calc(float a, float b) {
// 软件模拟实现
return a * b + a / b;
}
#endifvoid
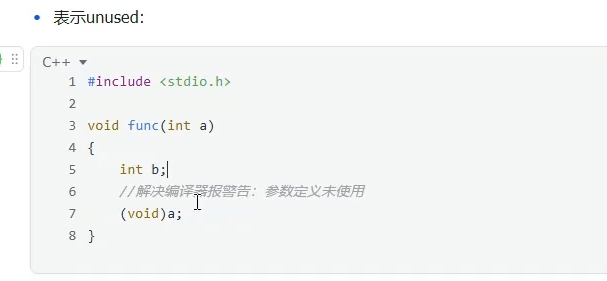
void常用做占位符,如:函数的返回值,参数。
void * :表示数据空间
void 也可表示unuesed
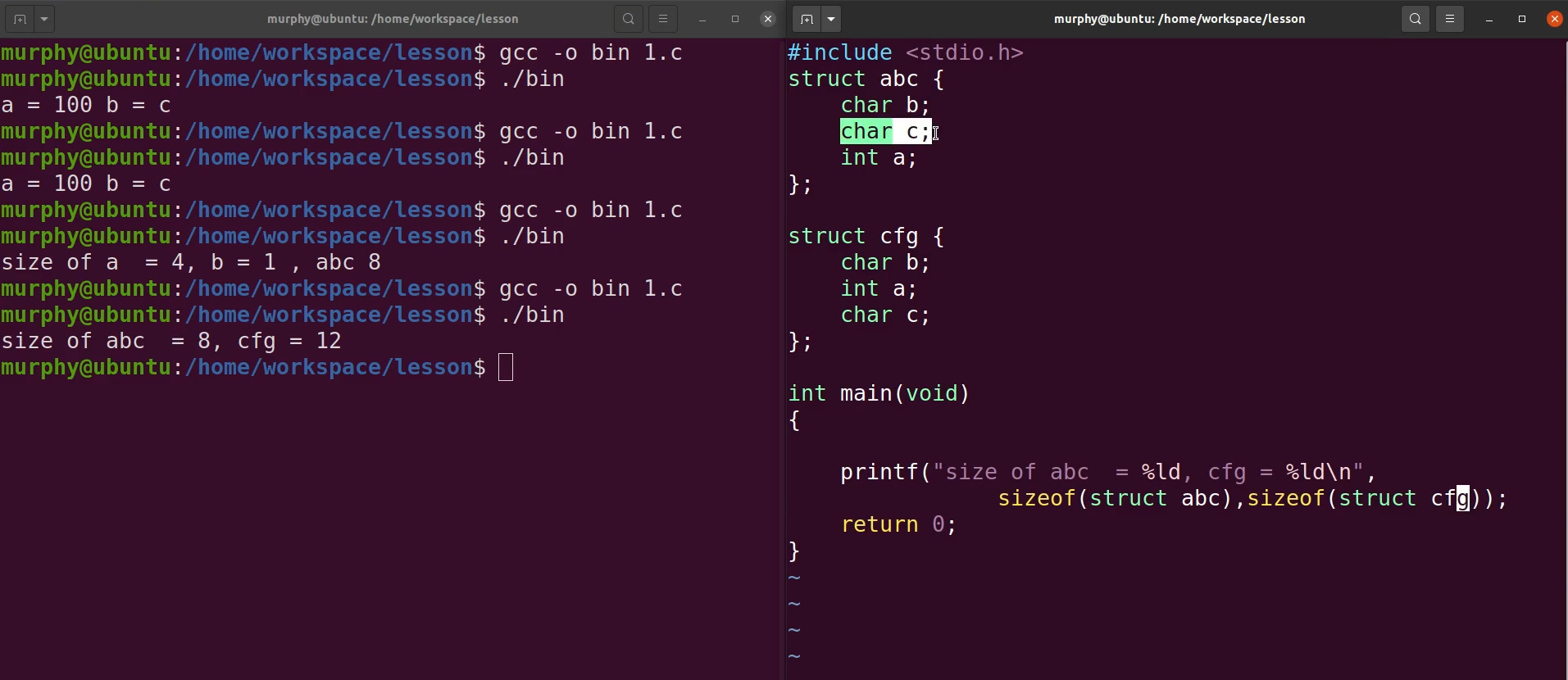
struct:结构体
字节对齐
示例代码
节约内存的方法:小的成员变量集中放在一起。
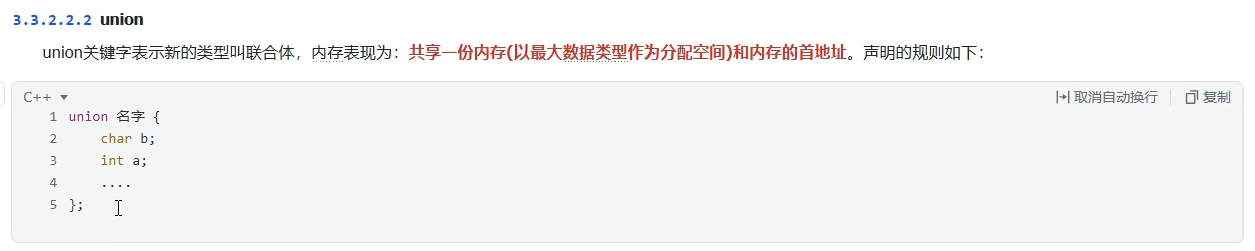
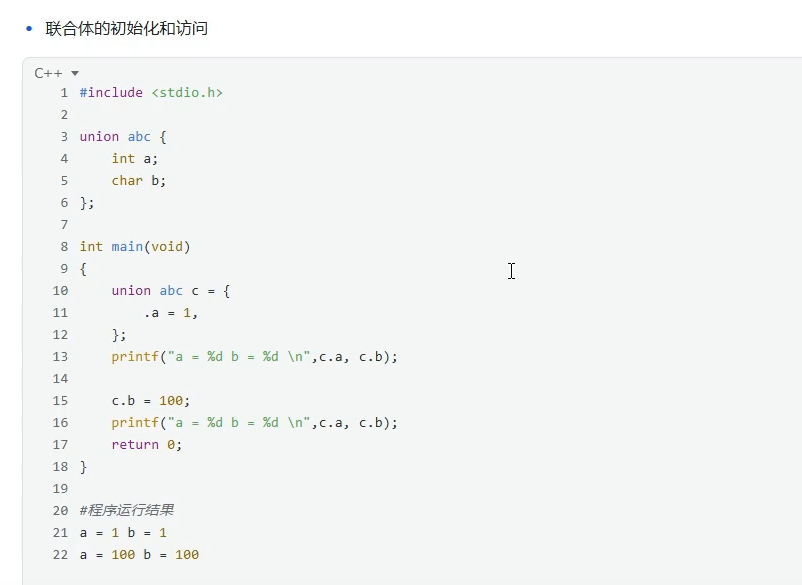
union:联合体
共用一块内存
补充:计算机的大小端。
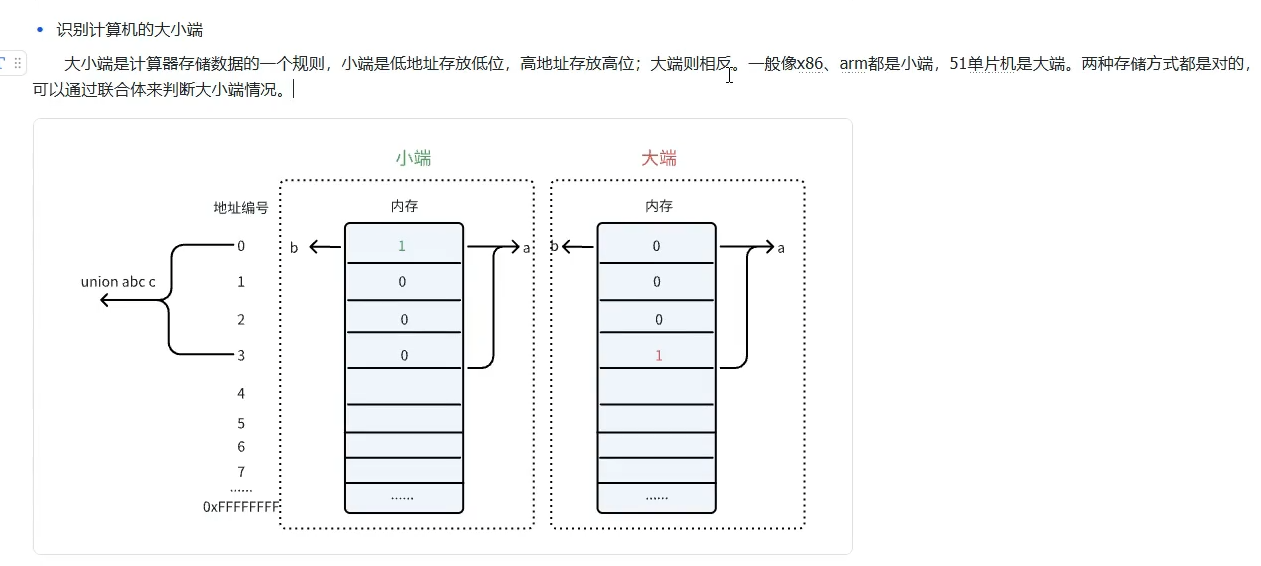
联合体的初始化和访问。
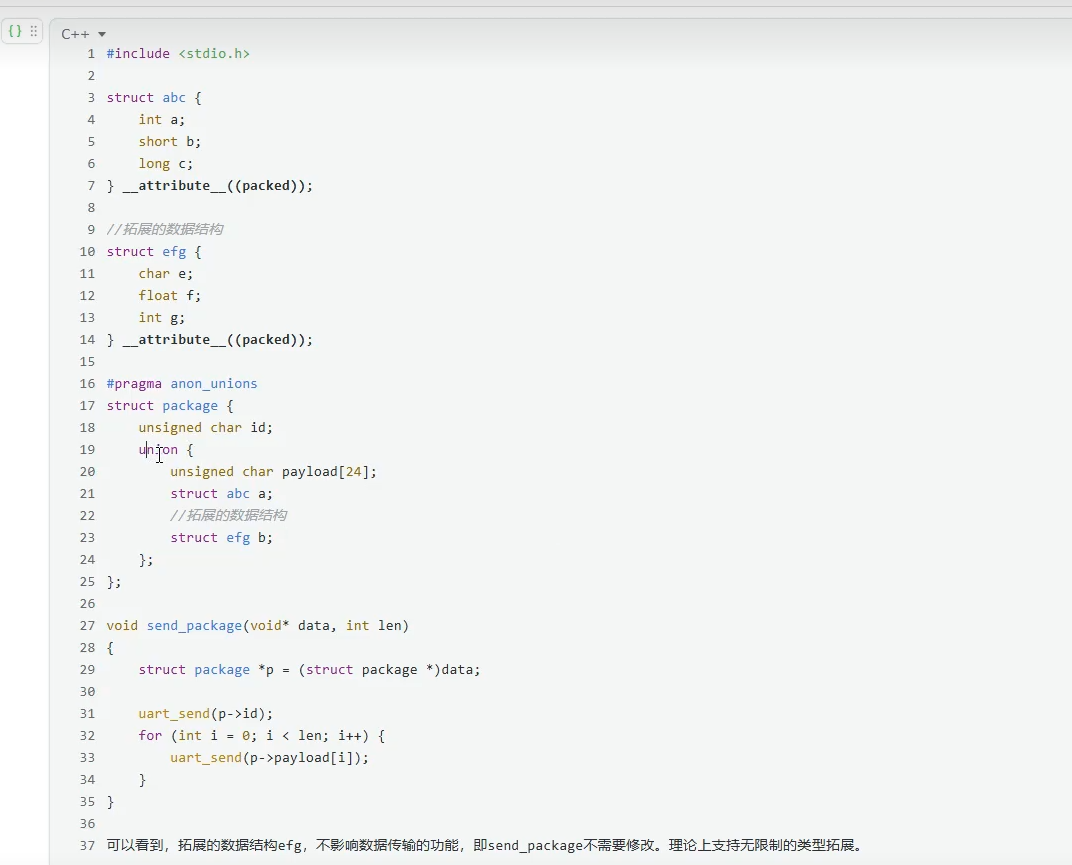
结构体和联合体的结合使用
attribute((packed)):取消内存对齐。
enum:枚举类型
里面的数值只能是整形常量。
初始化和访问

enum和宏

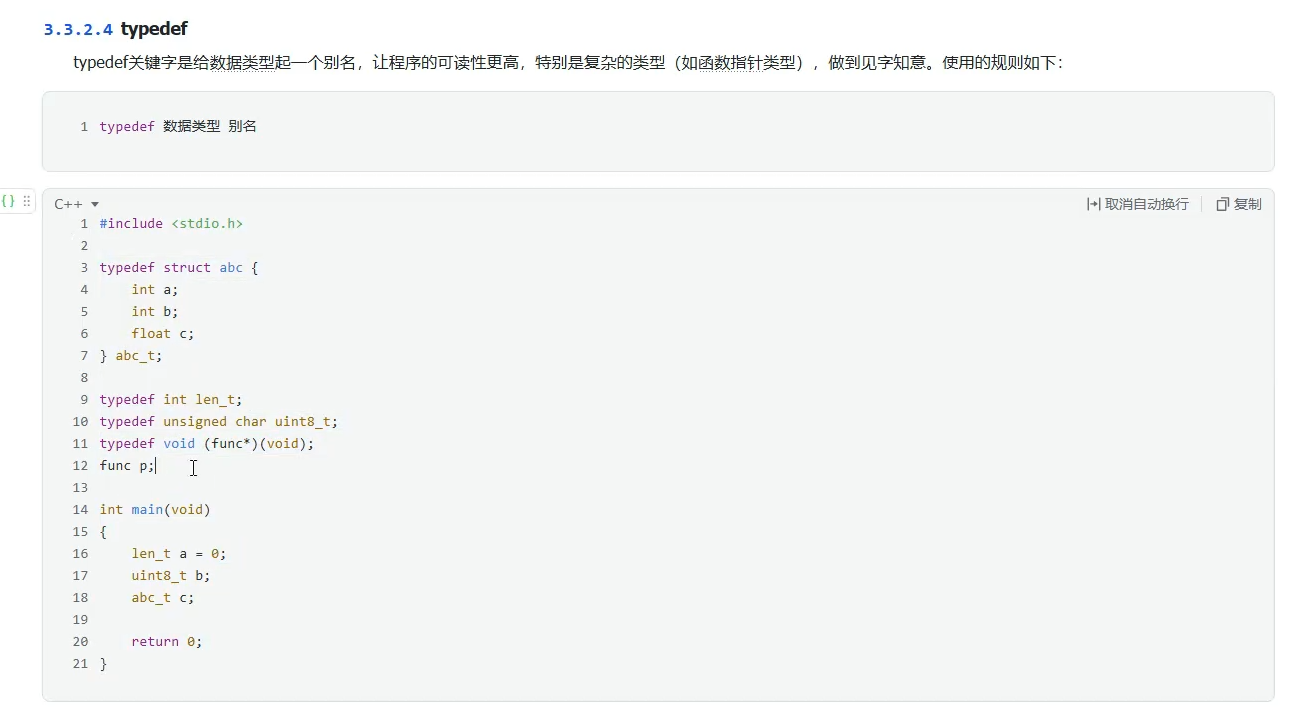
typedef:给数据类型起一个别名
typedef和define的区别
2.2 修饰关键字
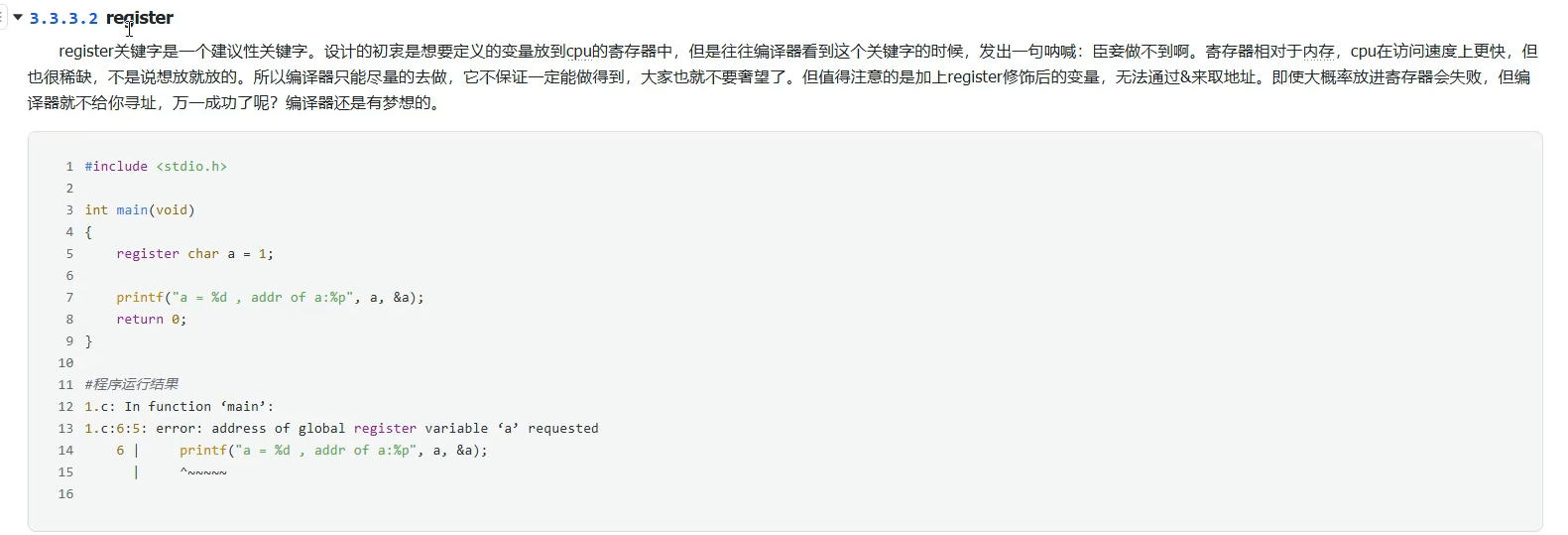
register
将定义的变量放到CPU的寄存器中,不一定成功。用register关键字修饰后,无法通过&来取地址。
static
延长生命周期、限定作用域。
extern
用来声明一个没有被static修饰的变量或者函数。
在架构设计中尽量不要用用extern,会导致代码的耦合度非常高且不可控。
extern "C" 用C++的编译器(g++)按照C的规则进行编译。
gcc -o libfunc.so 2.c -fPIC -shared
g++ -o bin 1.c -lfunc -L.
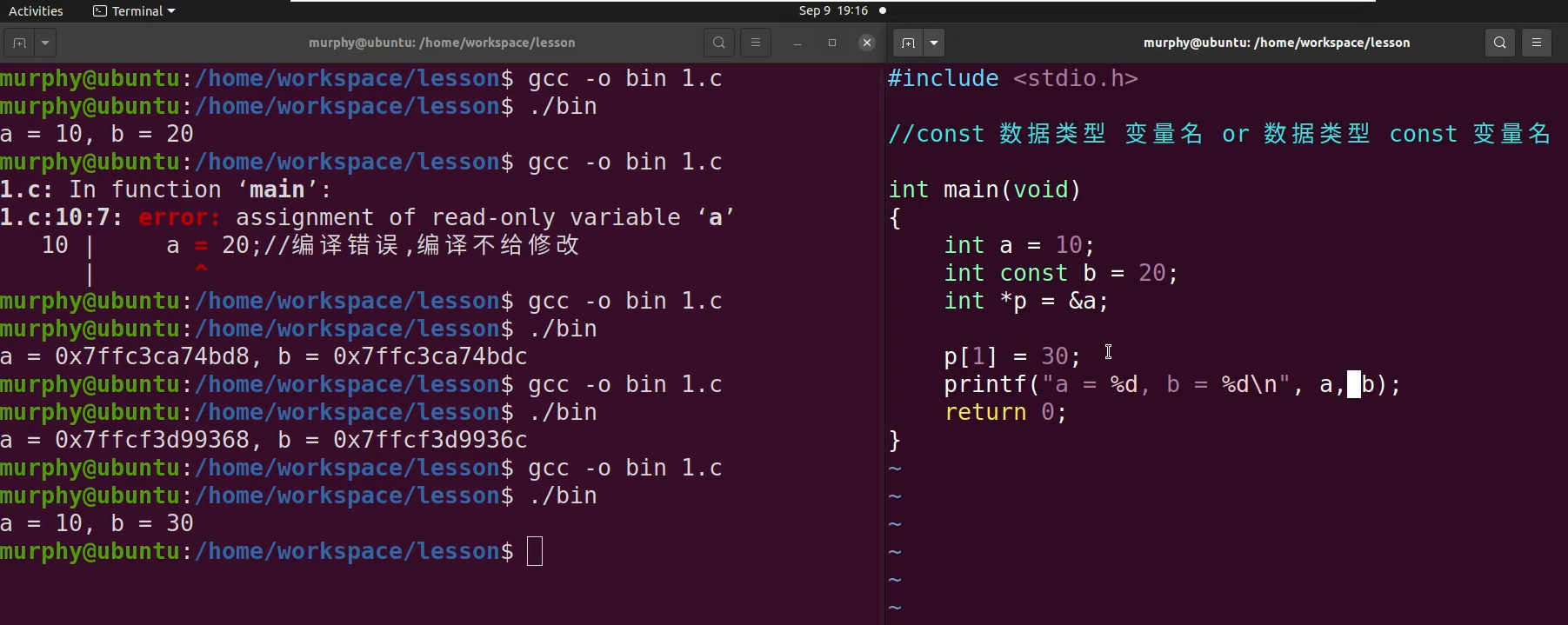
const
const修饰的变量不可以通过标签去修改,但是其实是可以通过指针的方式去间接修改的。
关于指针的一些补充知识
p = &a;
p0 等价于 *p
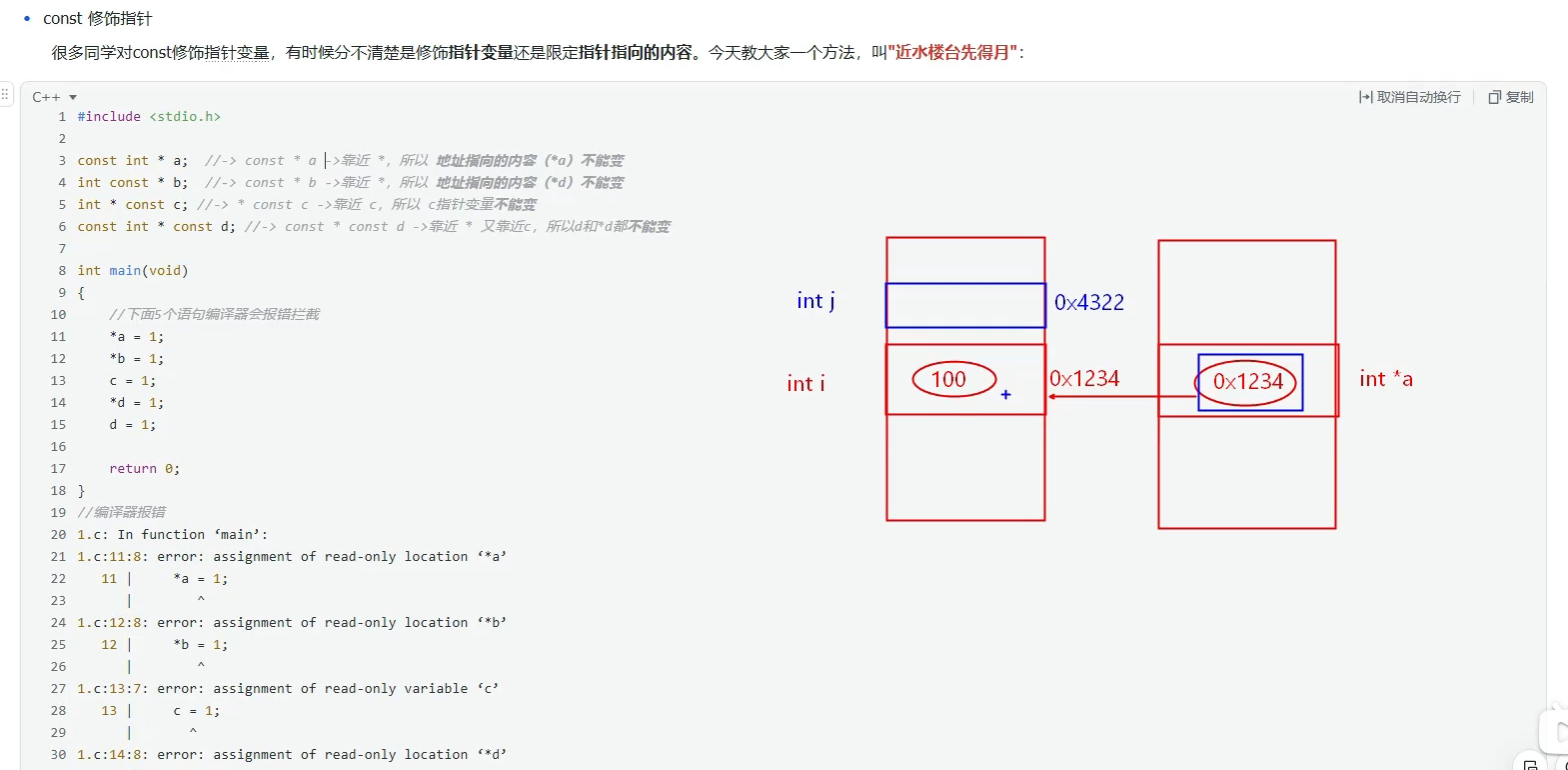
const修饰指针
先忽略掉数据类型。看const靠近*还是靠近变量。靠近谁,谁就不能变。靠近 *则内容不能变,靠近变量则指向不能变。
使用const可以提高运行效率
节约一条指令的时间。

const和和宏的区别

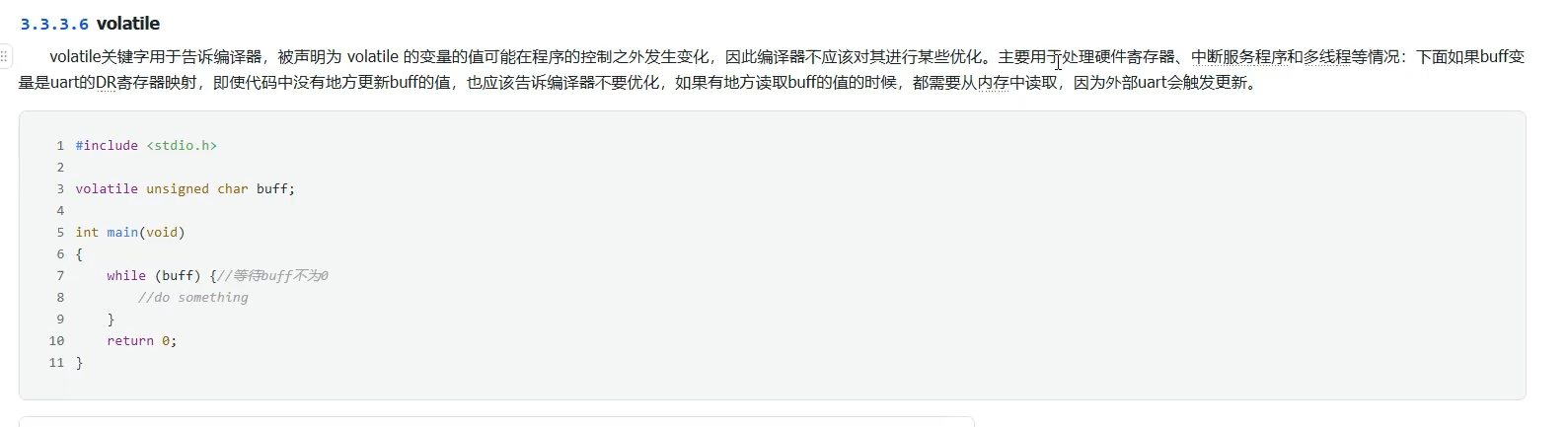
volatile
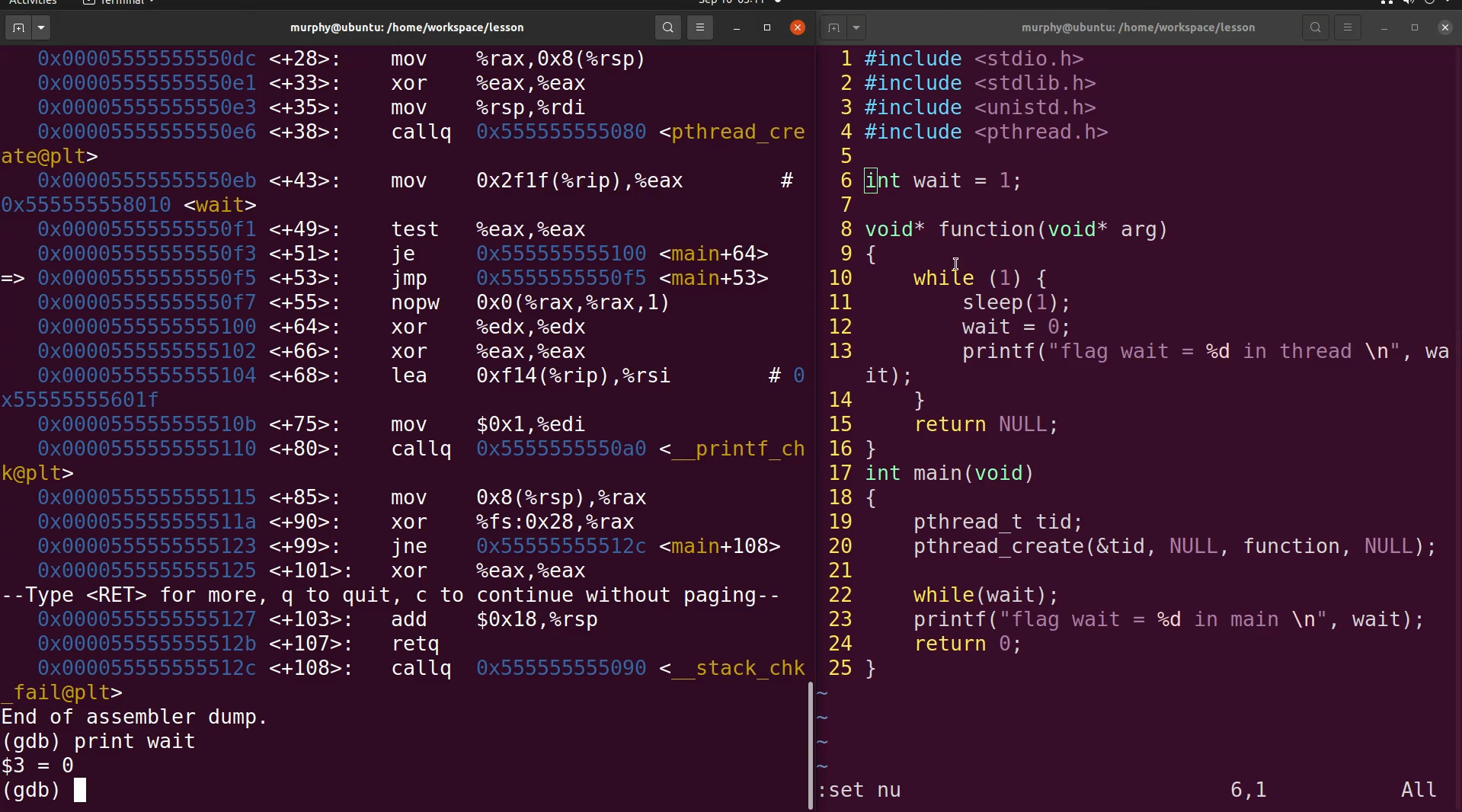
2.3 逻辑关键字
if判断中,写成2 == a,常数写在左边。
有时switch比多重if else更高效
2.4 运算符
乘除法效率低于加减法
模
模操作运算符:取余数。
应用场景:取余数;循环队列的索引更新;生成L,R区间的随机数;还可用作占位符。
位运算
左移一位,相当于是乘2;右移一位,相当于是除2。负数右移是不会变成0的,只会变成-1。正式右移是可以变成0的

有符号数的理解
计算机为了简化电路设计,统一使用 补码 来表示有符号整数。补码的定义如下:
正数的补码:就是它本身的二进制形式。例如:+1 的 8 位补码是 0000 0001。
负数的补码:将其对应正数的补码 全部位取反(0变1,1变0),然后加1。
%d打印十进制。%x打印十六进制,%o打印八进制。

特定位置一的宏

特定位清零的宏
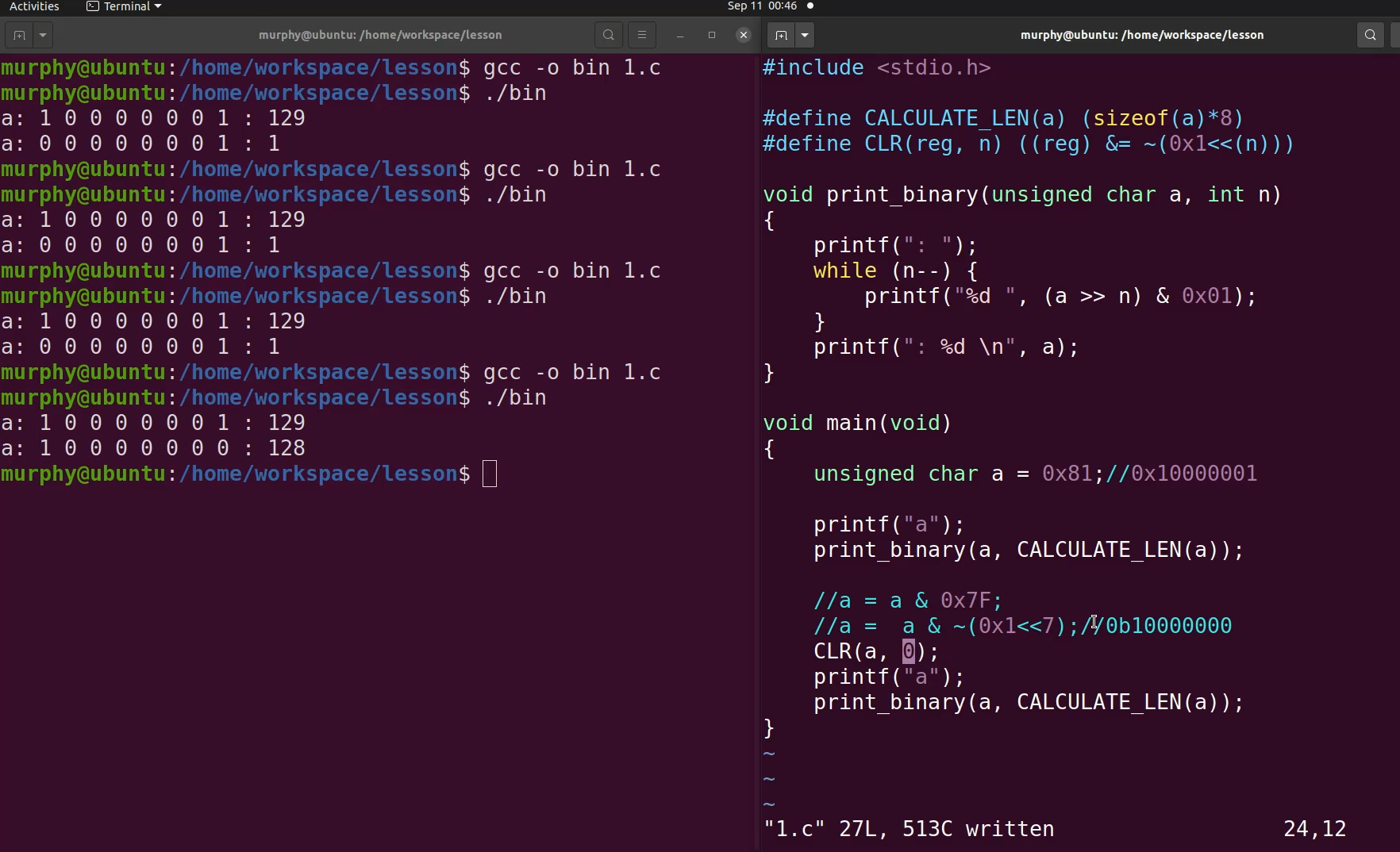
&清零,|置一。
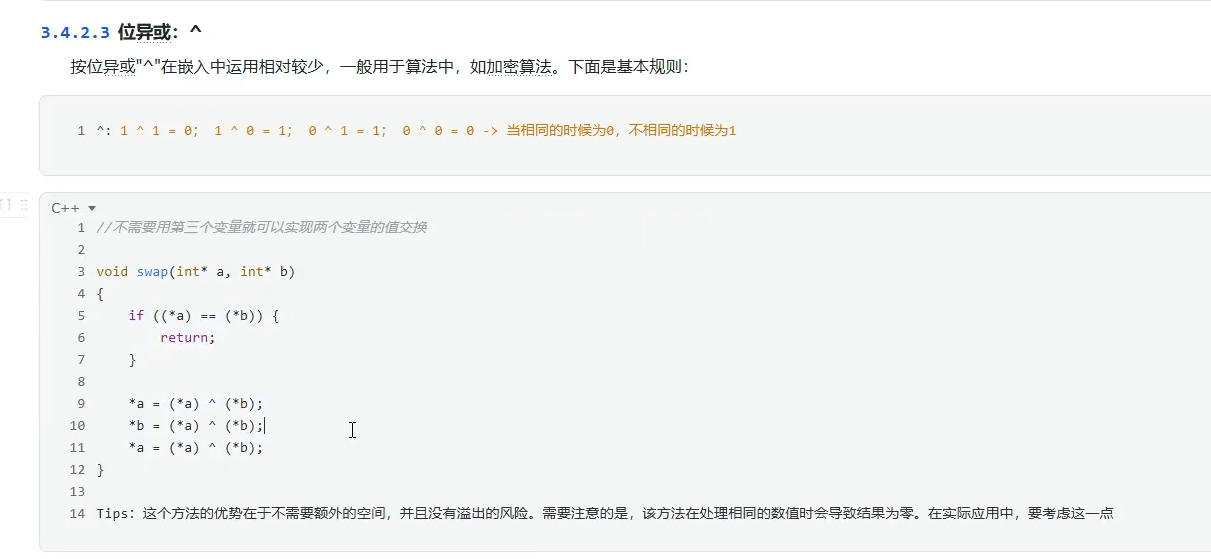
位异或的一个使用技巧(不需要第三个变量即可实现两个变量的值交换)
2.5 逻辑运算
条件或与:|| 和 &&

简单来说,就是编译器会偷懒。
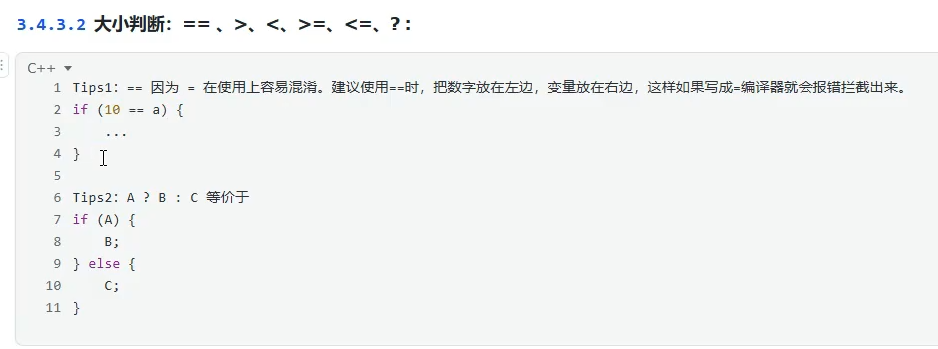
大小判断:==,>,<,>=,<=,?:
条件取反:!

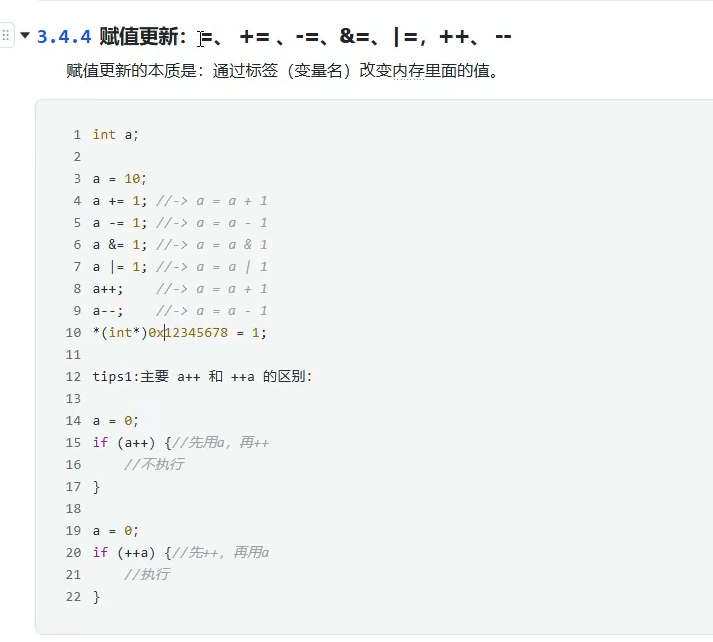
赋值更新
2.6 内存操作
函数访问:()

取值操作
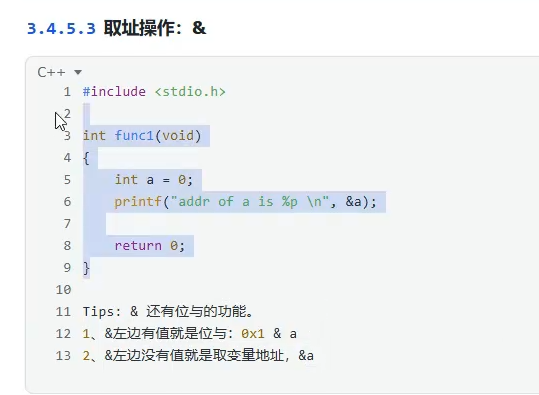
取址操作
用register修饰的变量无法进行取地址。
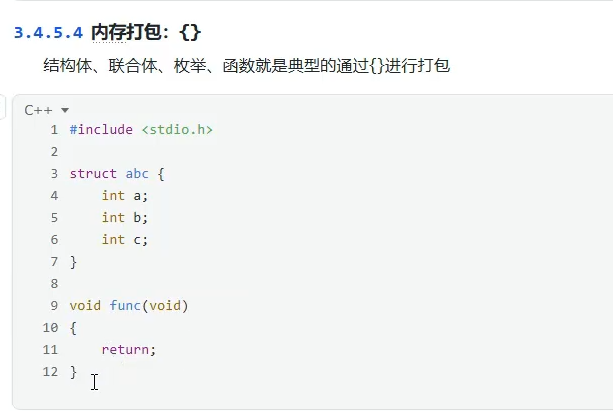
内存打包:{}
第三章:函数、面向对象与系统设计深度解析
3.1 函数三大属性:输入参数、返回值、函数名
函数名本质是一个地址标签,如果知道函数的地址,就可以直接()调用过去。
反汇编指令:objdump -d bin > bin.s
函数名的本质:地址标签
cpp
// 函数名就是内存地址的标签
void simple_function(int param) {
printf("Parameter: %d\n", param);
}
void demonstrate_function_essence(void) {
// 函数名就是指向函数代码的指针
printf("Function address: %p\n", simple_function);
// 通过函数指针调用
void (*func_ptr)(int) = simple_function;
printf("Pointer address: %p\n", func_ptr);
func_ptr(100); // 通过指针调用函数
// 直接地址调用(高级技巧,需要精确匹配)
// 注意:这需要知道确切的函数签名和调用约定
}
// 反汇编分析函数调用
// 使用:objdump -d program > disassembly.s
// 可以查看每个函数的机器码和内存布局3.2 函数参数传递的本质
传入和传递参数的本质其实是内存拷贝。
C语言中,传入参数时,目的地叫形参、源叫实参。
调用时,系统会把实参的值拷贝到形参的地址上。
3.3 值传递:对数据进行隔离和保护
函数返回的指针变化的话,要注意其合法性:可以通过malloc或者static修饰,让其不避免在栈空间分配
cpp
// 危险的返回:栈上局部变量的地址
int* dangerous_return(void) {
int local_var = 42;
return &local_var; // 错误:函数返回后局部变量失效
}
// 安全的返回方式1:静态变量
int* safe_return_static(void) {
static int persistent_var = 42; // 静态存储期
return &persistent_var; // 安全
}
// 安全的返回方式2:堆分配
int* safe_return_malloc(void) {
int* heap_var = malloc(sizeof(int));
if (heap_var) {
*heap_var = 42;
}
return heap_var; // 调用者需要负责free
}
// 安全的返回方式3:传入输出参数
int safe_return_output(int* output) {
if (output) {
*output = 42;
return 0; // 成功
}
return -1; // 失败
}3.4 栈帧布局与局部变量恢复技巧
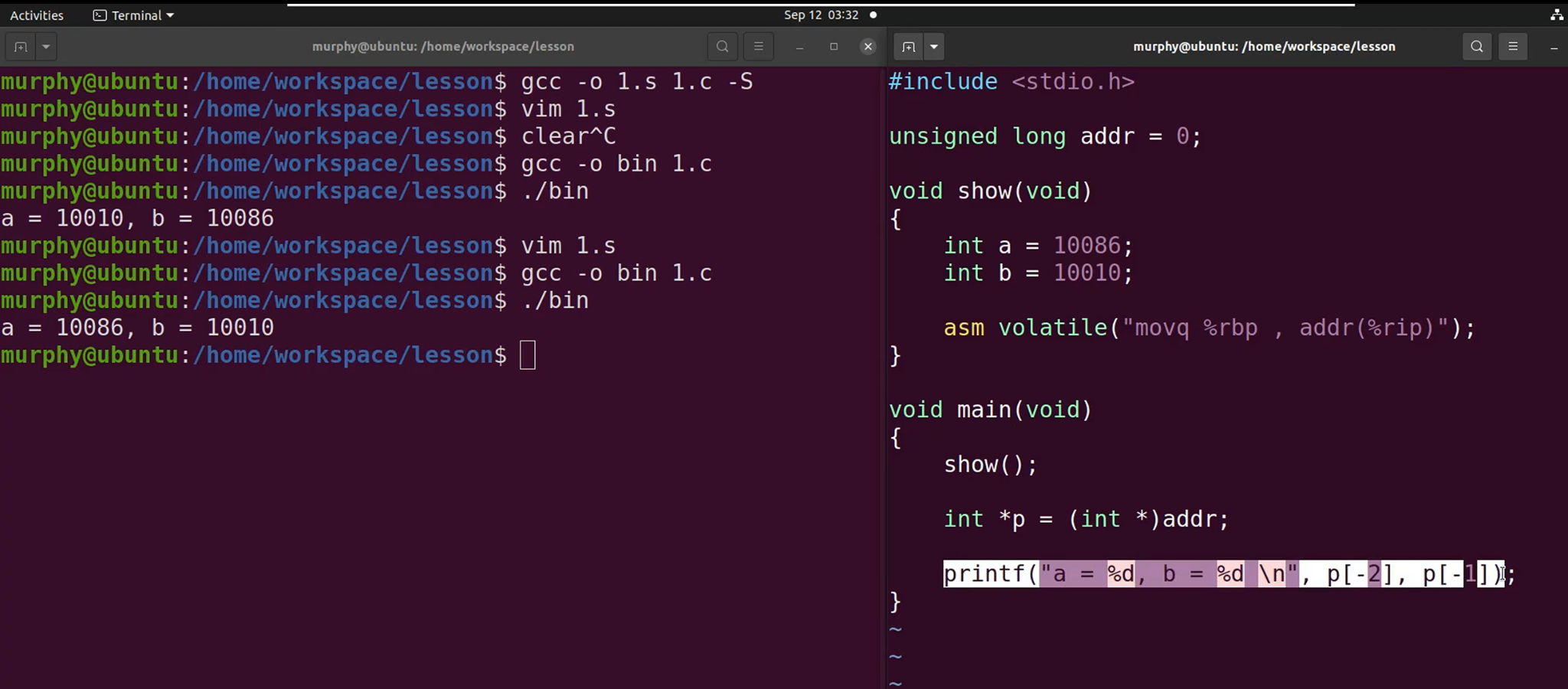
栈帧的详细布局分析
- 通过保持栈指针,对其进行+4或者+8,取出其地址上的值。
- 先定义的数据先入栈,地址,栈是高地址向低地址生长的,
- 假设先定义局部变量a,再定义局部变量b。则a先入栈,b后入栈,最后才是栈帧。
- 从按地址从小到大排序是:a, b, 栈帧sp。
3.5 地址传递:多返回值设计
地址传递:多返回值设计。约定俗成:返回0表示成功,返回非0表示失败。
字符空间与非字符空间的传递区别
如果是非字符空间,则需要给出传递空间的长度。

字符空间则不需要,因为字符空间的结束符是'\0'。所以默认情况下,传入字符空间可以不用给出传入空间的长度。

3.6 C语言实现面向对象的完整框架
C与继承
继承的定义:建立类之间的层次关系,使子类能自动拥有父类的特性和行为,实现代码复用。
实现方式:结构体嵌套
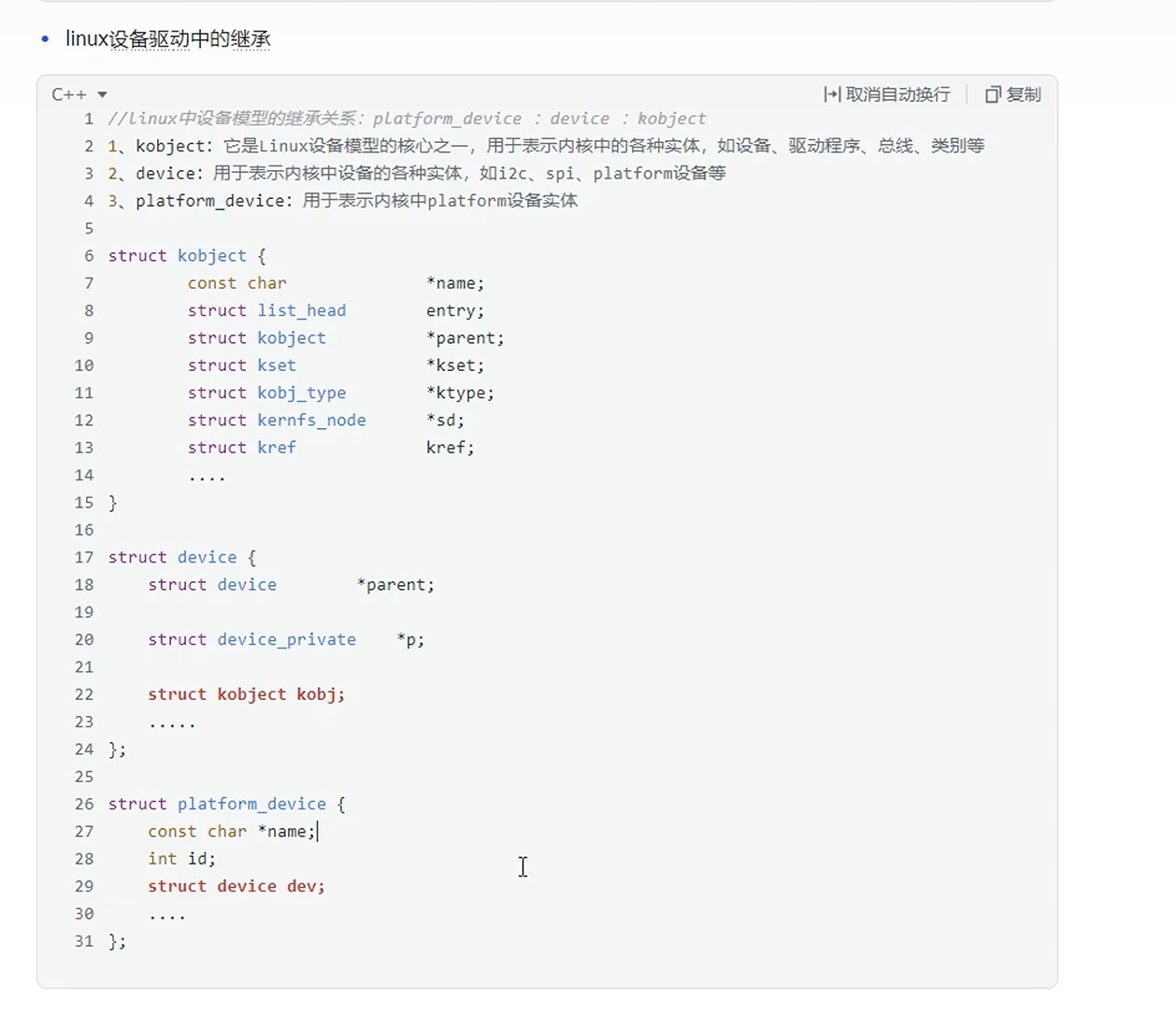
Linux设备驱动中的继承
RT-Thread就是MCU版的Linux
C与封装
封装的定义:隐藏对象的内部实现细节,仅对外提供受控的访问接口。
实现方法:结构体+函数指针+编程规范约束
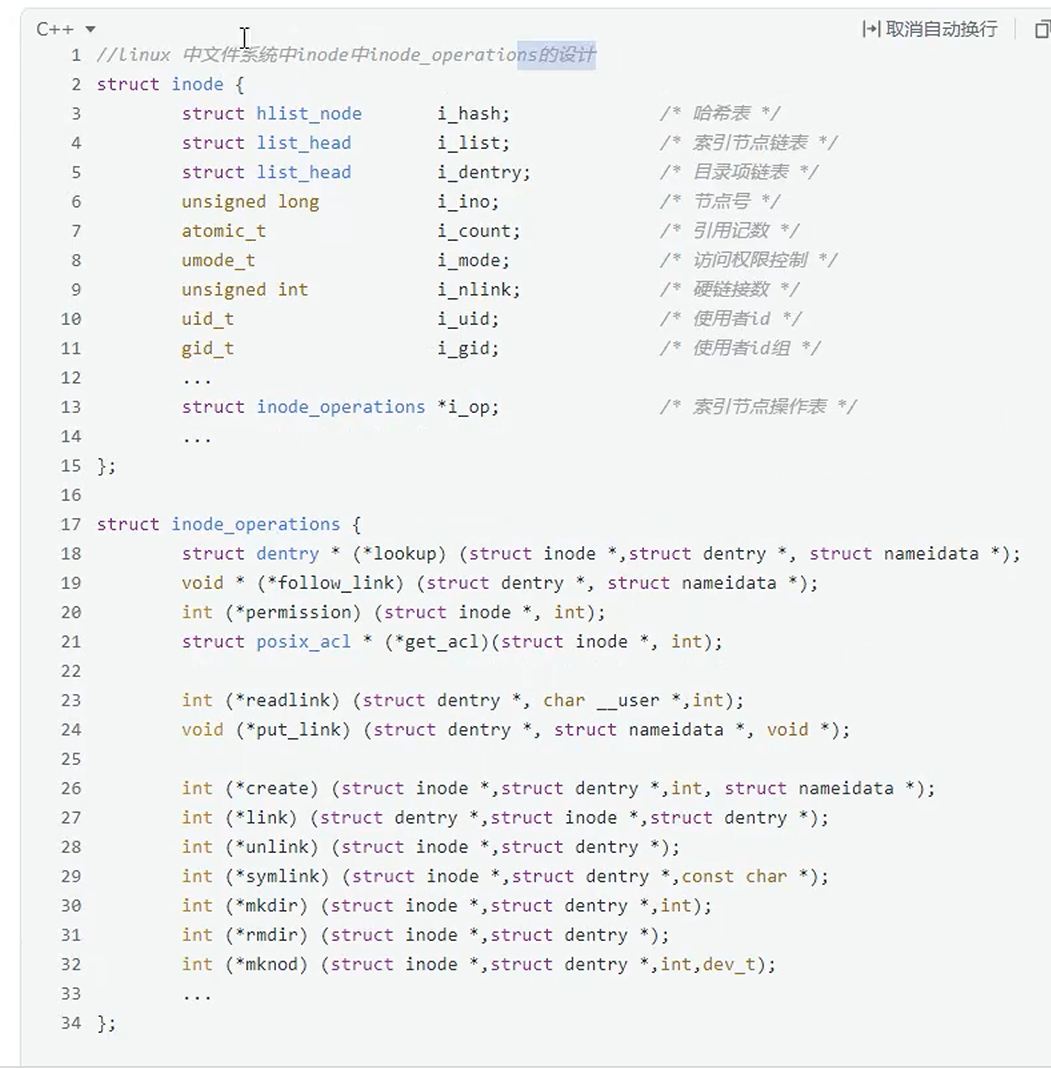
Linux中封装的应用
C与多态
多态的定义:同一操作作用于不同类的实例,各实例可以有不同的实现方式,从而产生不同的行为。
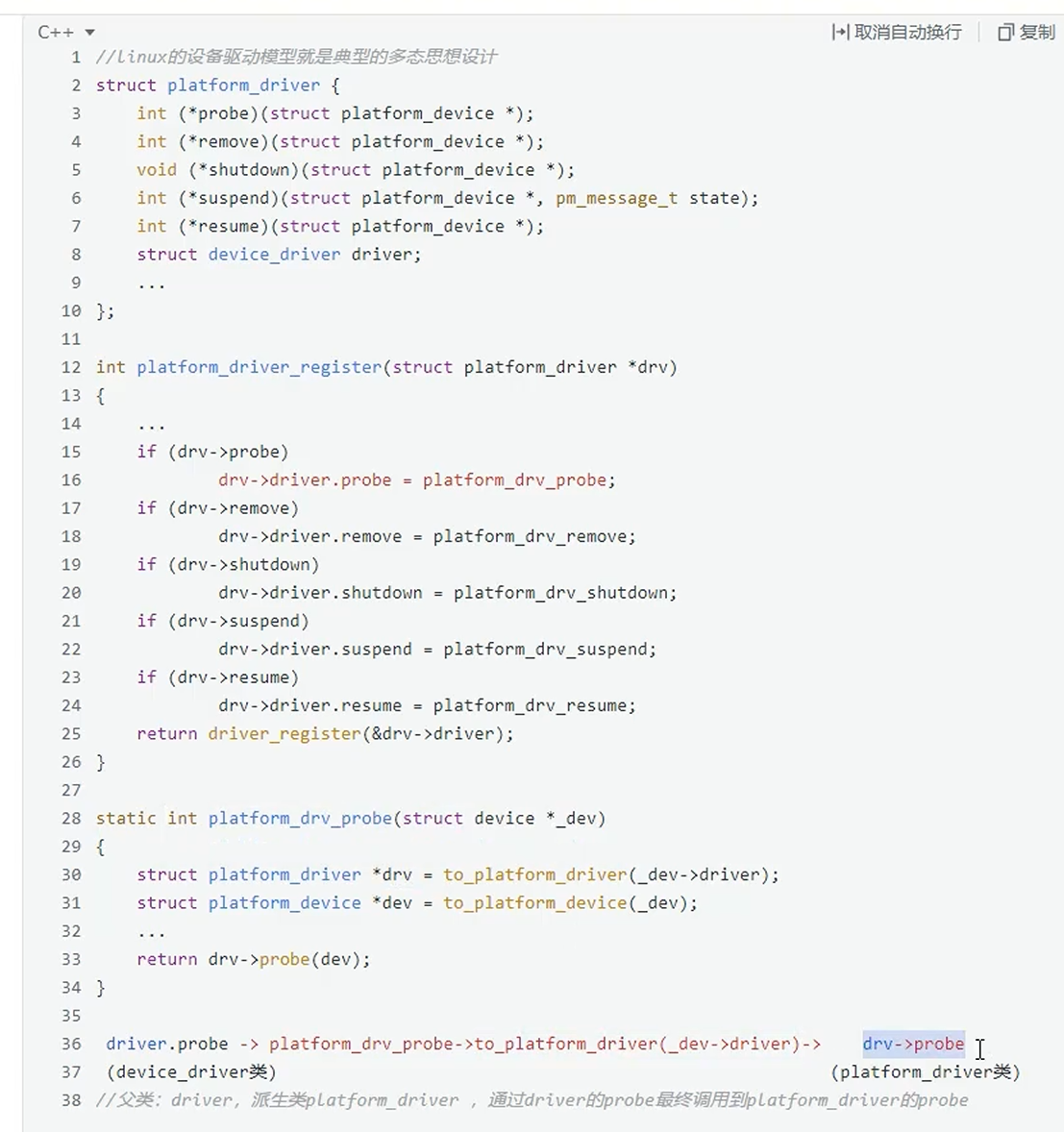
C++的多态实现是基于虚函数。C语言中的实现则是通过父类指针,调用到子类中的方法。
一个很关键的细节:被继承的父类结构体成员放在首位,这样父类结构体的地址和子类结构体的地址就是一样的。利用父类指针进行中转。
Linux驱动模型中的多态思想应用
C与重载
在同一作用域内(如一个类中),允许创建多个同名方法,只要它们的参数列表不同。
可变参数函数
回调函数 + void*
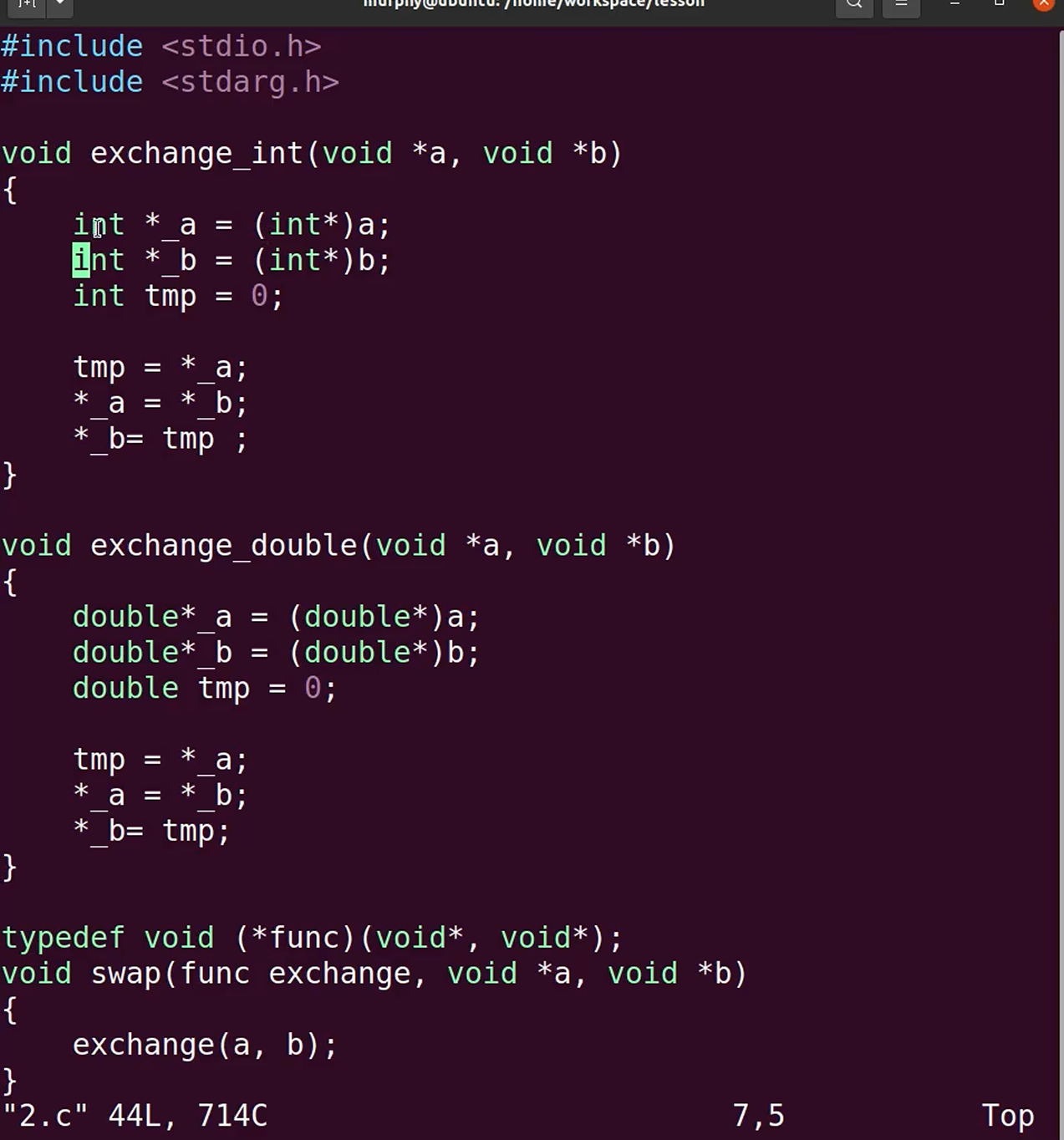
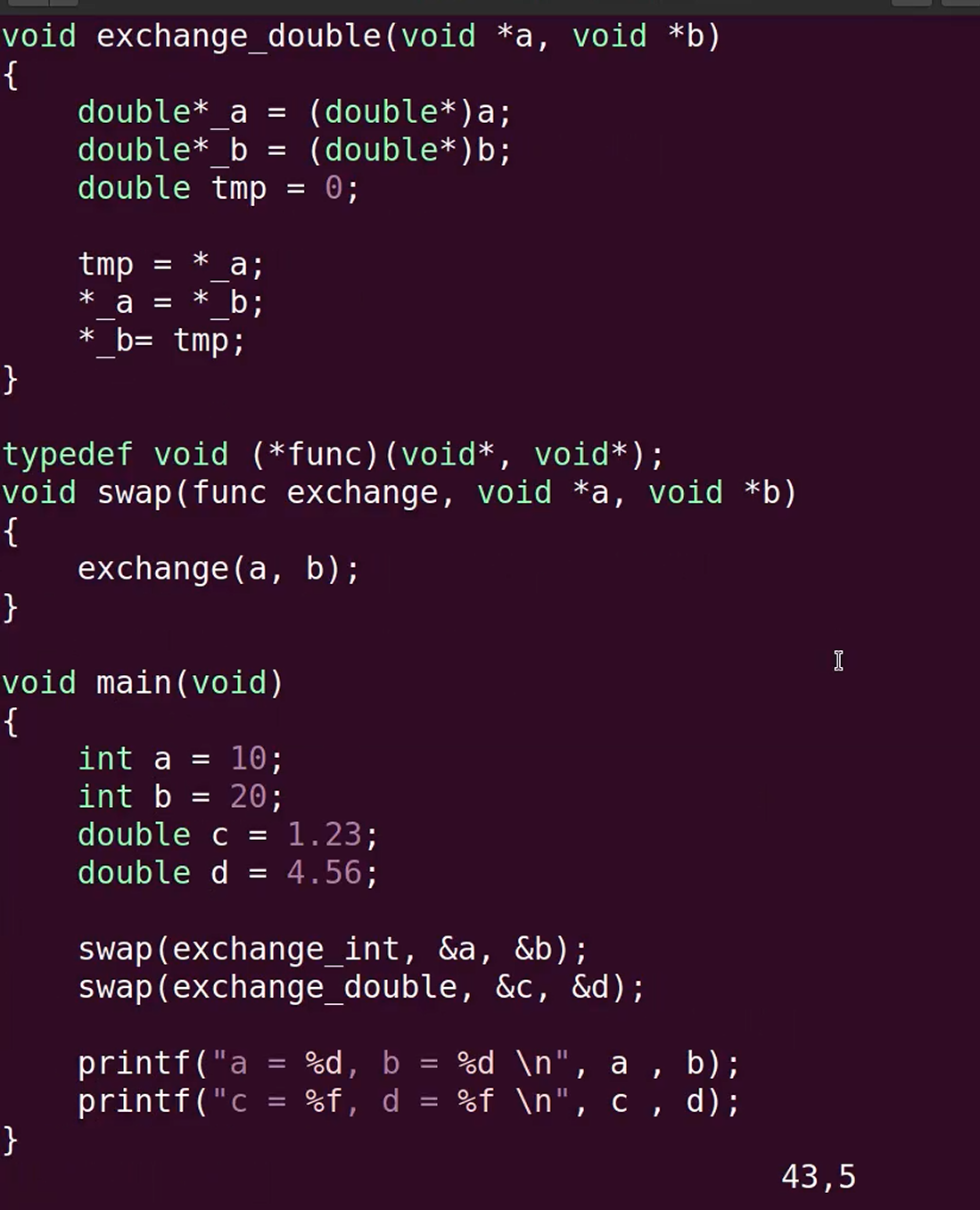
隐藏对象的内部实现细节,仅对外提供受控的访问接口。
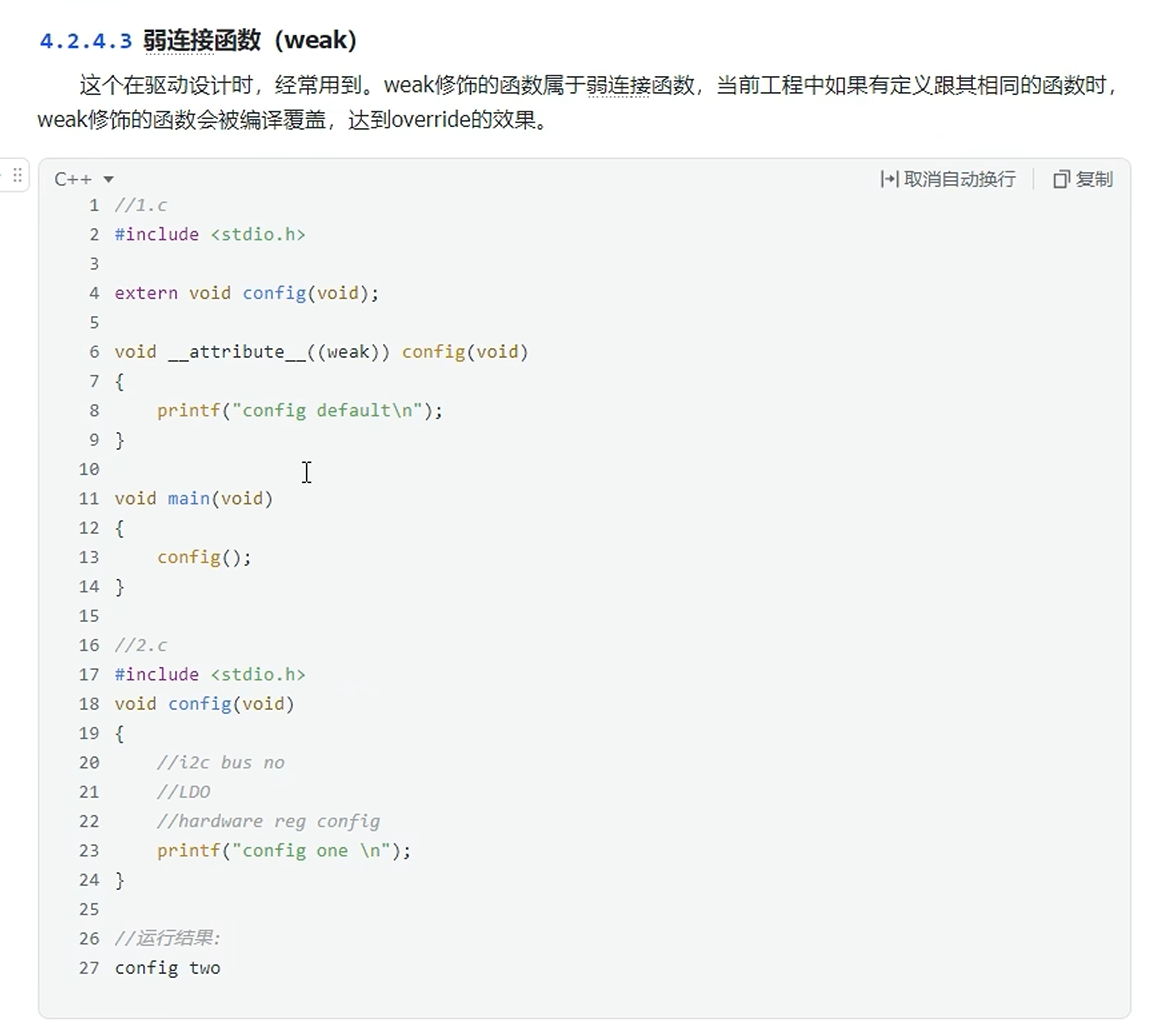
弱连接函数
用weak修饰。真正的函数实现由用户自己去实现。
Solid设计原则
从业务实际出发,不要为了设计而设计。

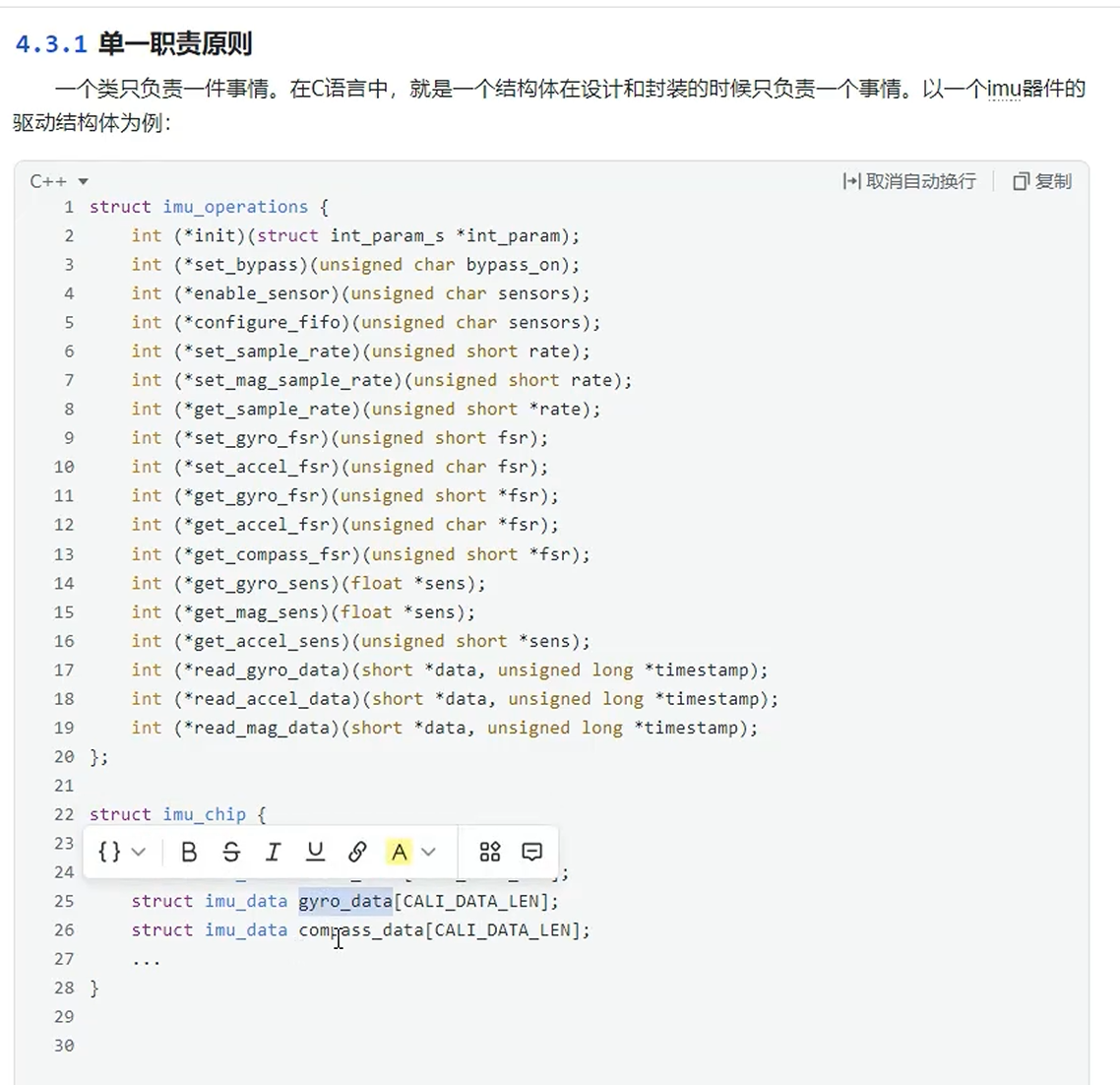
单一职责原则
开闭原则

里氏替换原则
核心思想是:子类必须能够替换它们的父类,而不会破坏程序的正确性。简单来说,如果一个程序使用的是父类对象,那么当把这个父类对象替换成它的任意子类对象时,程序的行为不应该发生变化
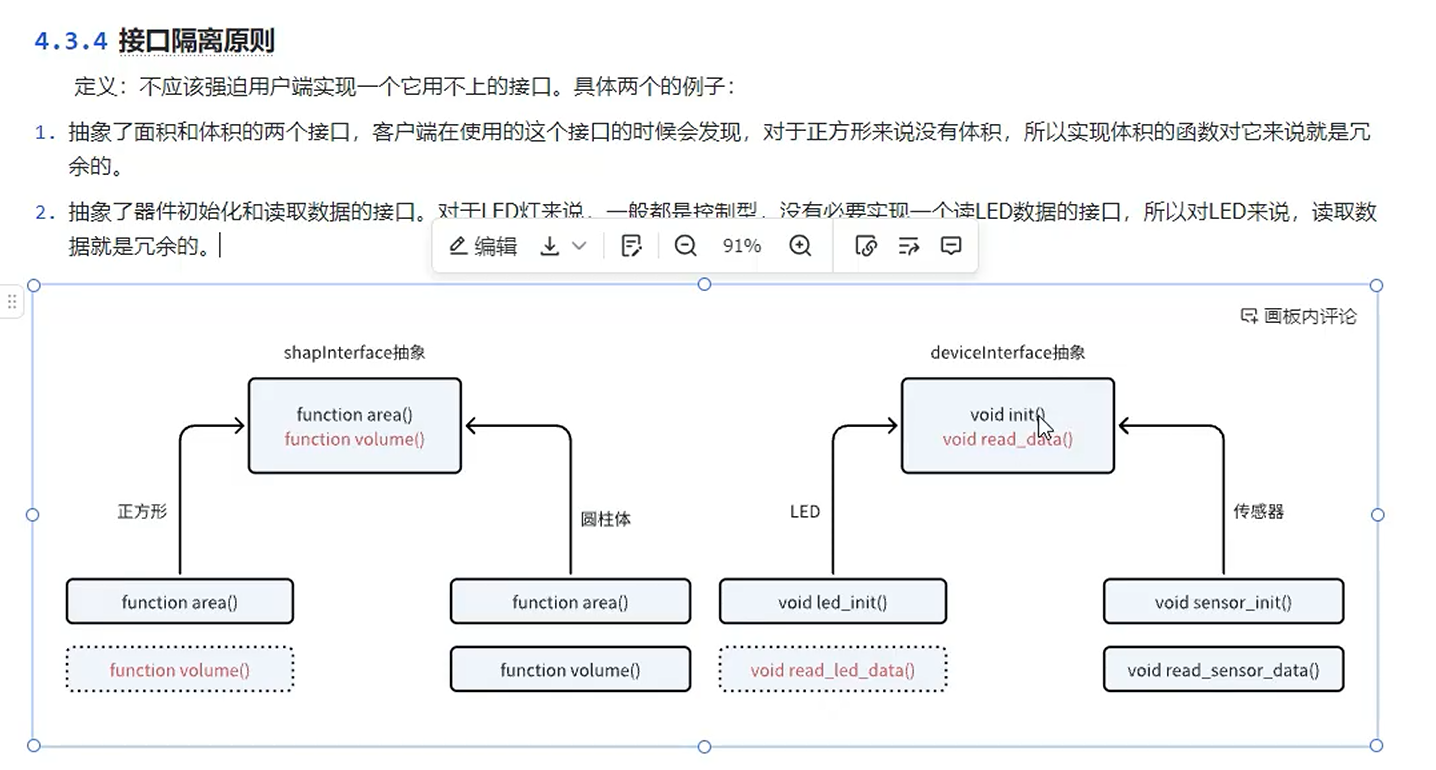
接口隔离原则
核心思想是客户端不应该被迫依赖它不需要的接口。简单说,就是不要制造"万能"的庞大接口,而应将其拆分成更小、更具体的专门接口,让类只知道自己需要的方法
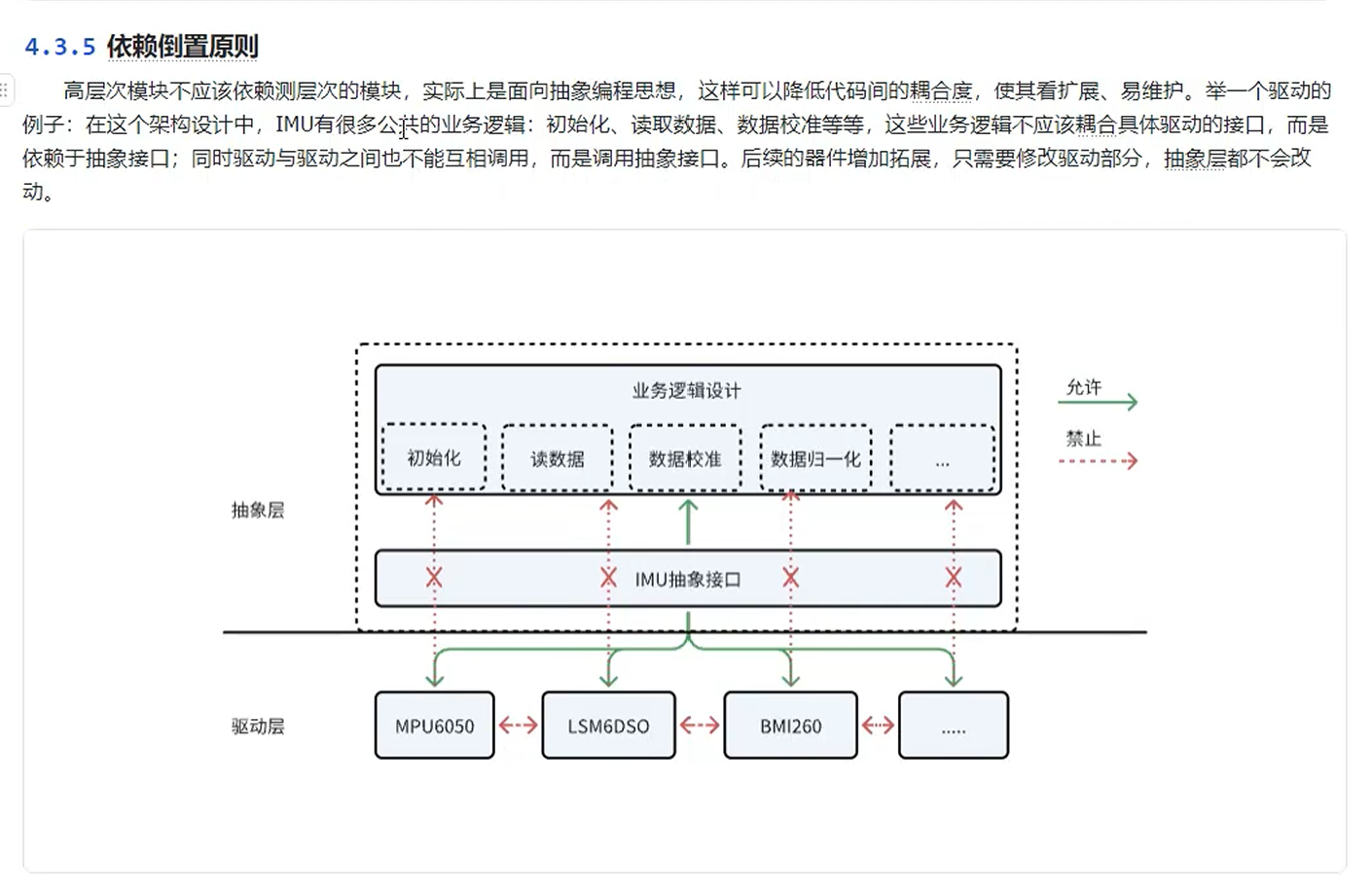
依赖倒置原则
核心是面向接口/抽象编程,通过依赖注入实现控制反转,最终达成解耦的目的。它常常与开闭原则(目标)和里氏替换原则(基础) 协同出现,是构建高质量、易扩展软件系统的关键手段
第四章:从内存空间的视角剖析
4.1 内存空间的分布
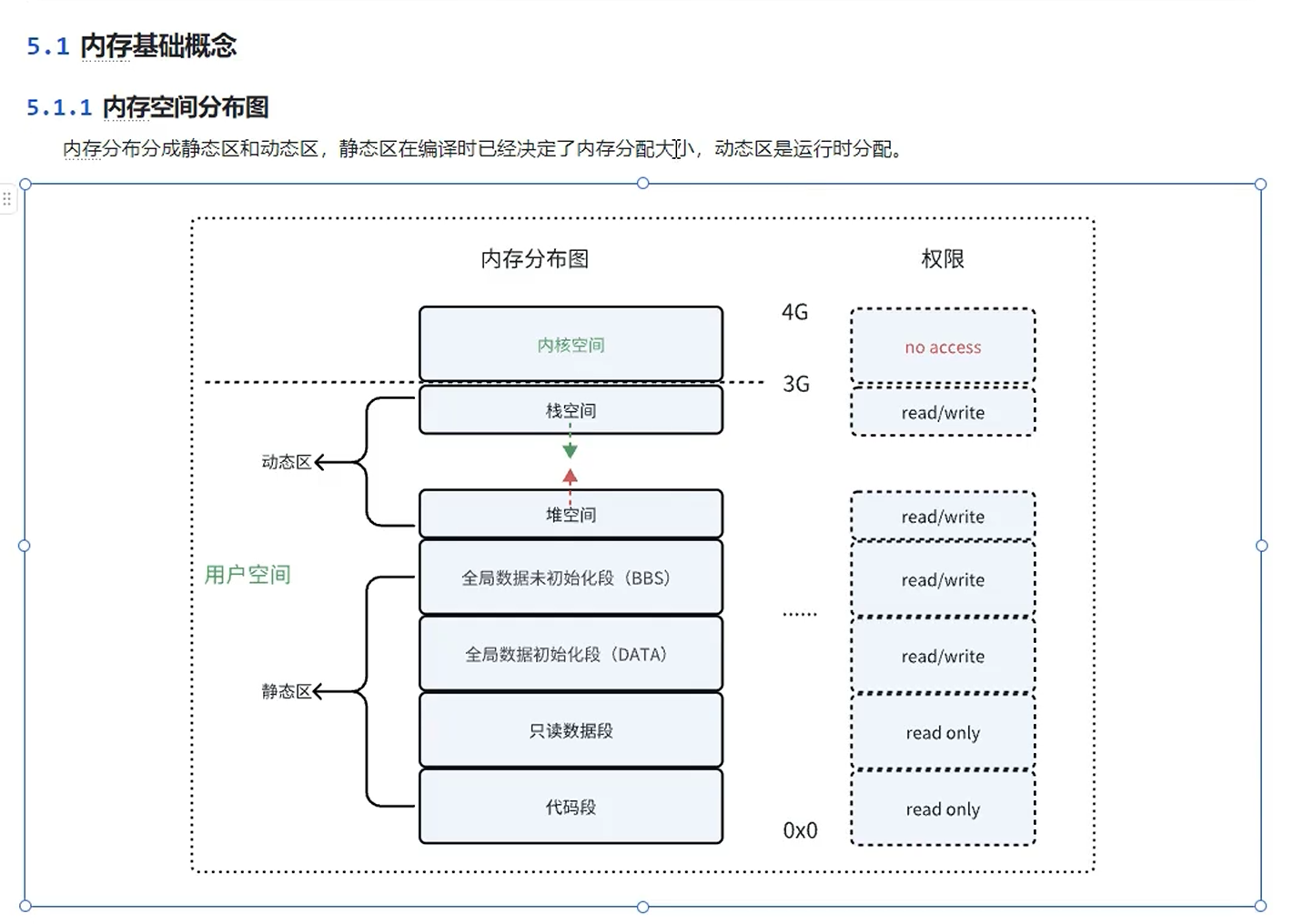
内存分布分为:静态存储区和动态存储区。
静态存储区就是:text段(代码段)、只读数据段、data段、BSS段。
动态存储区就是堆和栈。
生长方向:堆空间越用,地址越来越多,往上生长;栈空间越用,地址越来越小,往下生长。
地址依次递增:
代码段在最前面;只读数据段(字符常量,字符串常量等);全局初始化的变量;静态局部变量;全局未初始化的变量。
再细分:全局数据初始化段(data段),静态局部变量和未初始化的全局变量(BSS段)
4.2 内存的操作权限
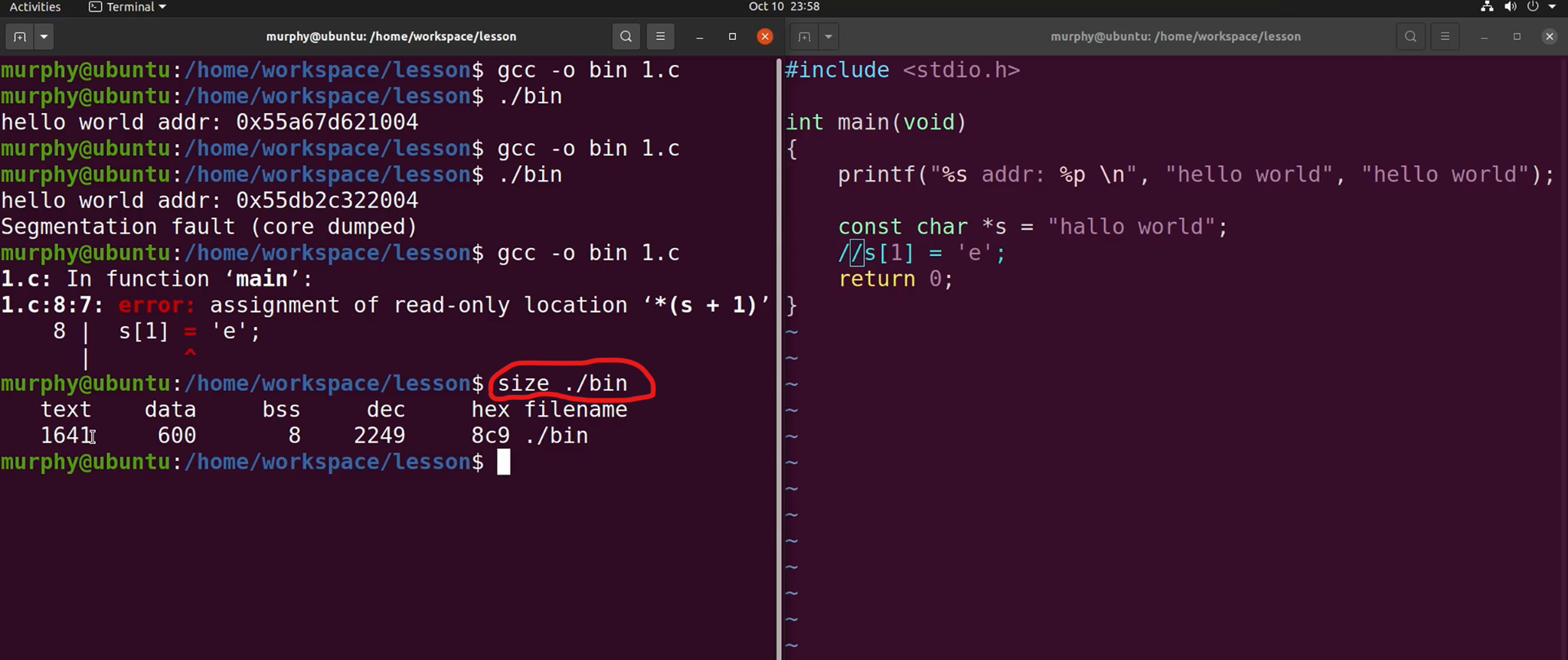
代码段
代码段只能读,不可以写,写的话则会触发Segmentation(core dumped)俗称"段错误"。

在整个程序运行当中,代码段都是合法有效的。
只读数据段
存放字符串常量,地址一般比代码段高一些。
权限:只能读,不能写。
图中的"hello world"其实相当于是地址。
注意:text段的大小包括了:代码段和只读数据段的大小。统计时放入text段进行计算。
全局数据段
全局数据段包含:data段+BSS段
都是可以可读可写的。
BSS段的地址,比data段要高。按顺序排列:data段;BSS段。
函数入参的顺序,都是从右到左。
堆空间
概念:由程序员进行分配和释放,可读可写。生命周期由程序员自己决定。
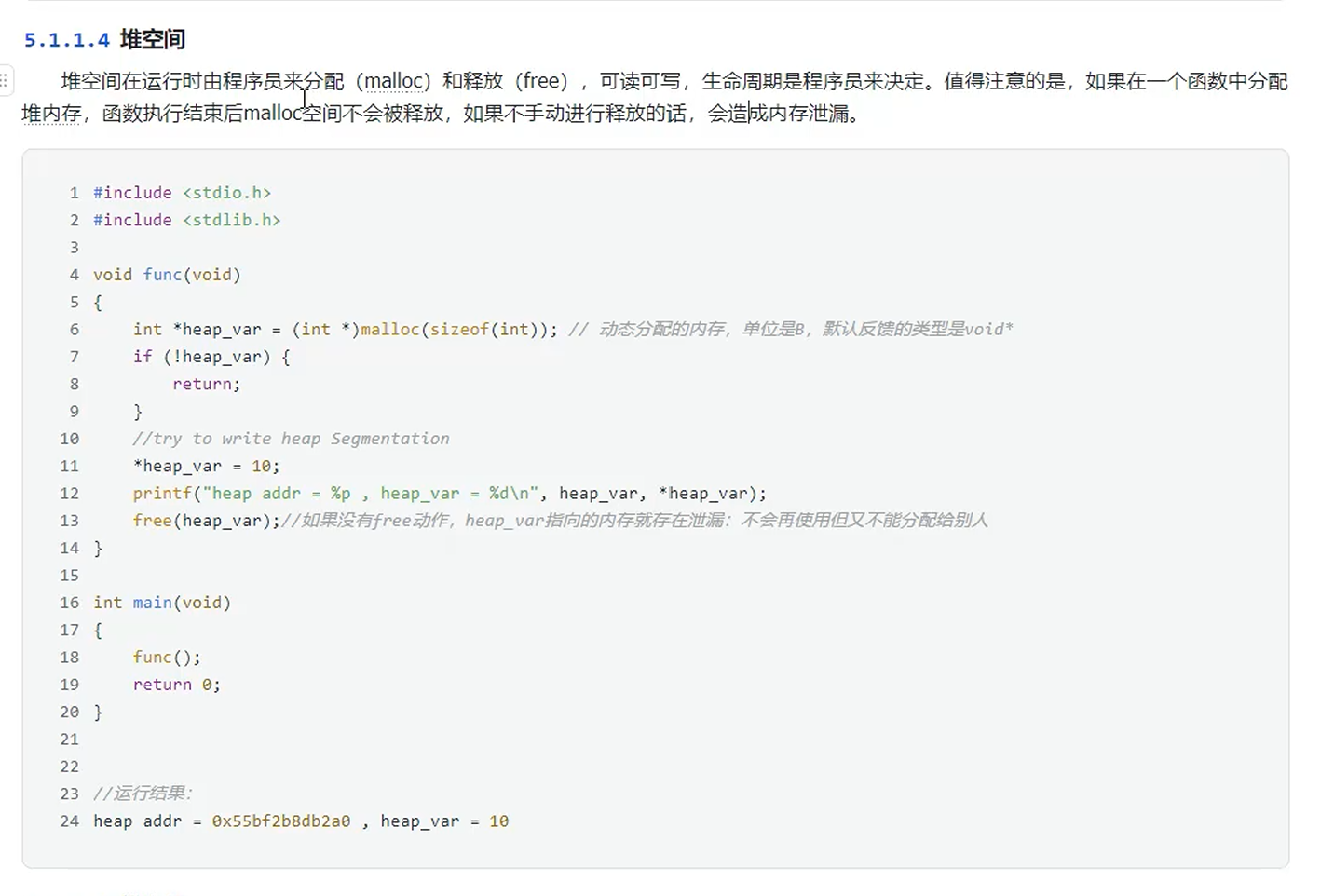
示例代码
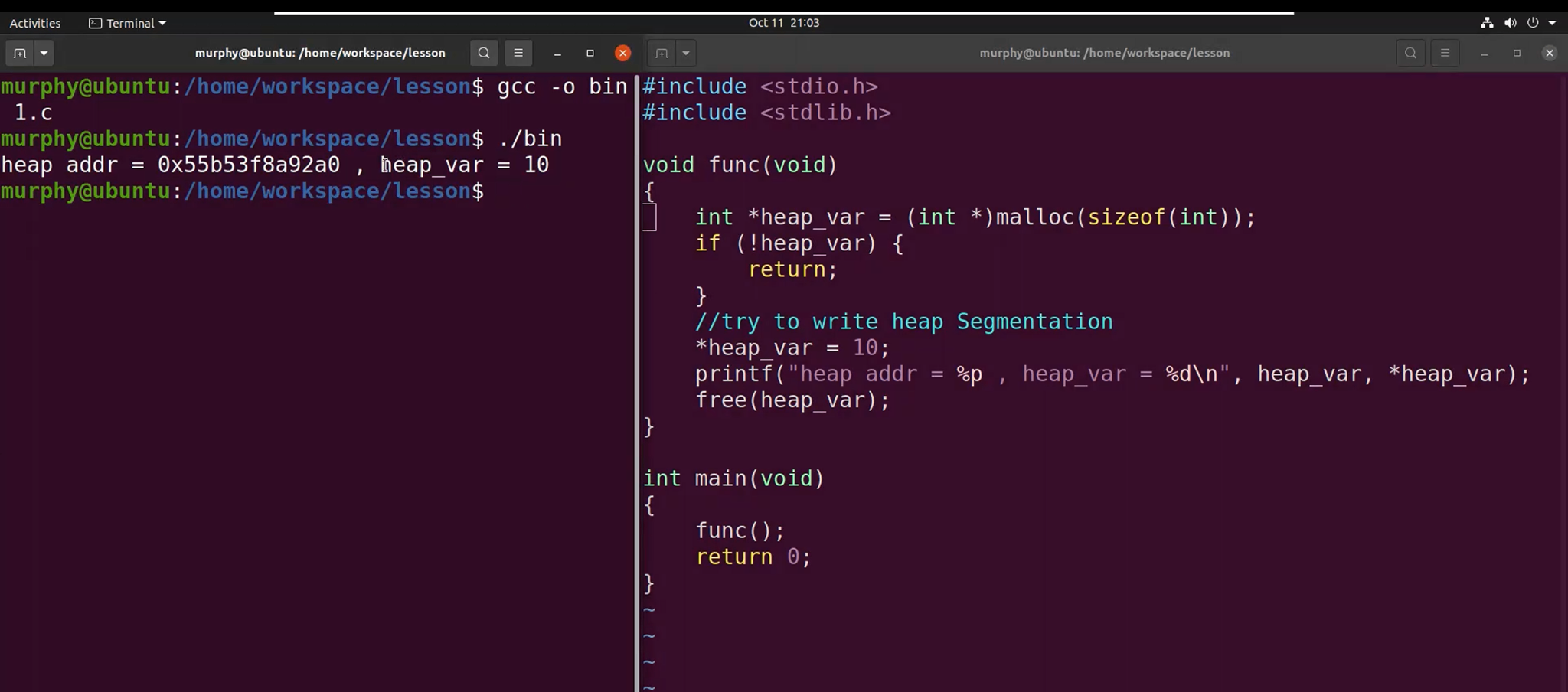
栈空间
概念:函数运行时上下文的分配空间,可读可写,但是生命周期仅维持到函数执行结束。

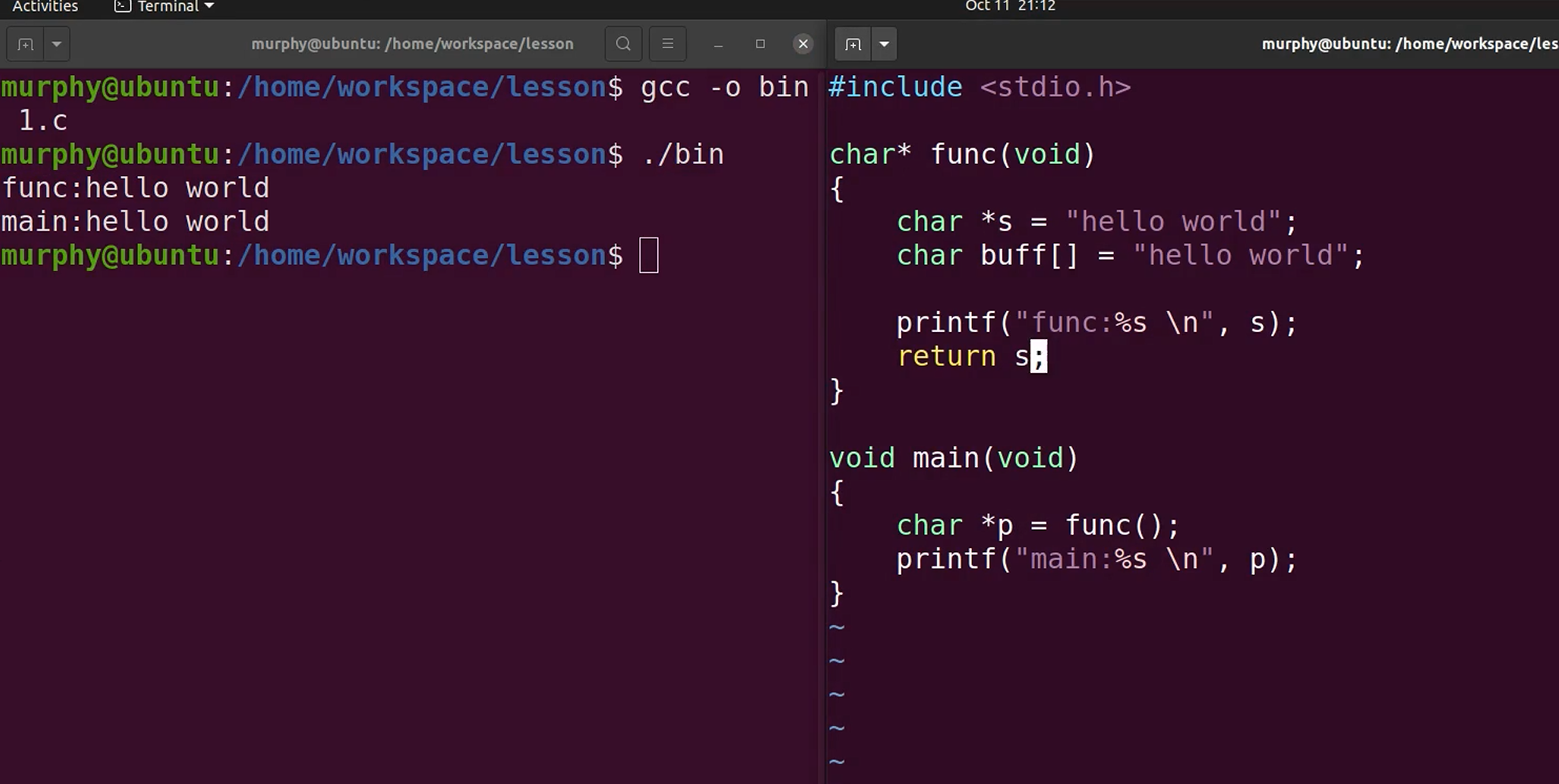
示例代码
char *s = "hello world"则是把只读数据段中的"hello world"的地址赋值给 s
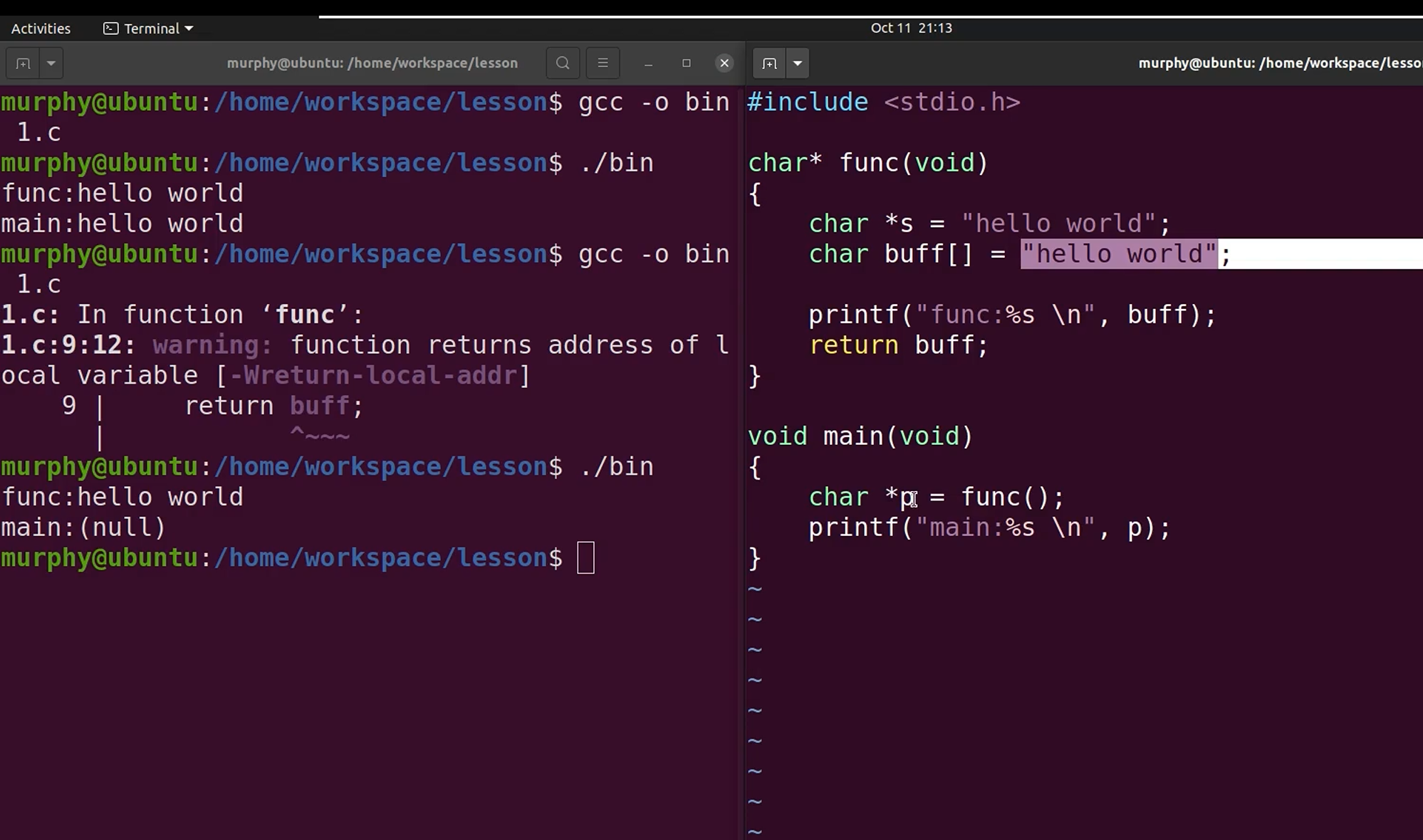
buff = "hello world"是把字符串重新拷贝一份到buff数组中。系统会分配sizeof("hello world")的栈空间
4.3 堆栈的生长方向
栈是向下生长的,堆是向上生长。
同一栈帧内的数据,不一定是向下生长的。但是栈的整体生长方向是向下生长。
4.4 内存溢出
栈溢出
常见的栈溢出情况分为两种:系统的栈空间被消耗完、单个栈被消耗完
系统的整个栈空间被消耗完:函数递归
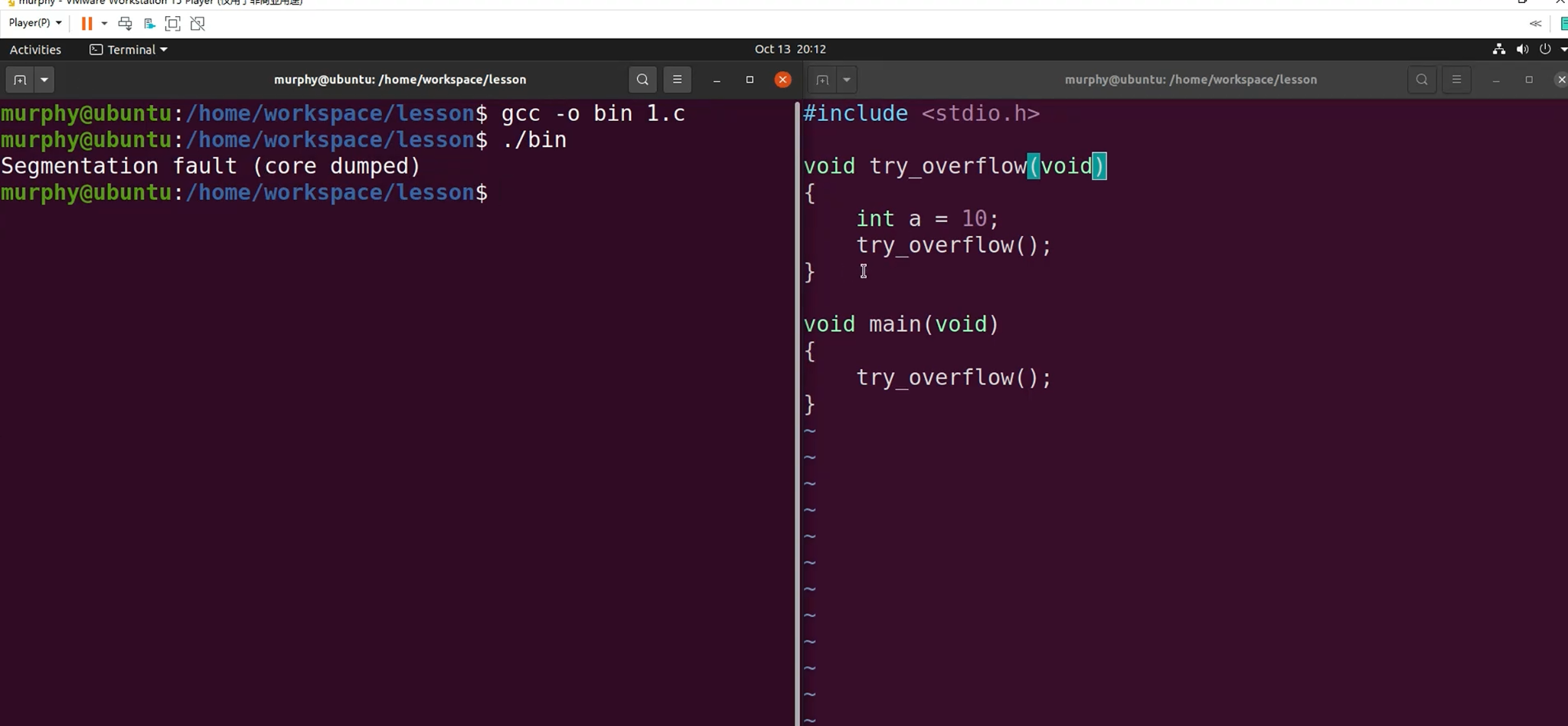
单个栈被消耗完
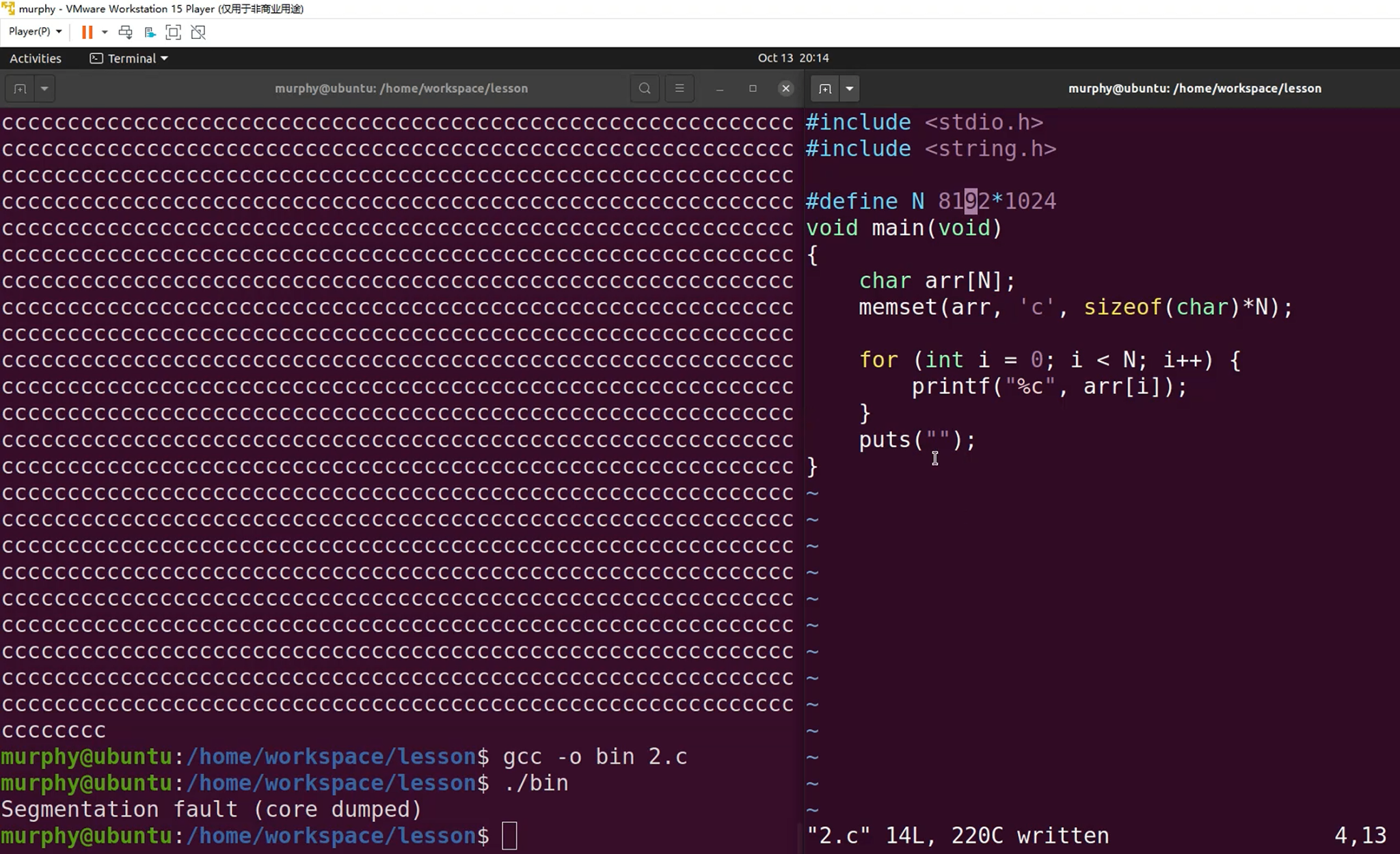
栈缓冲区溢出
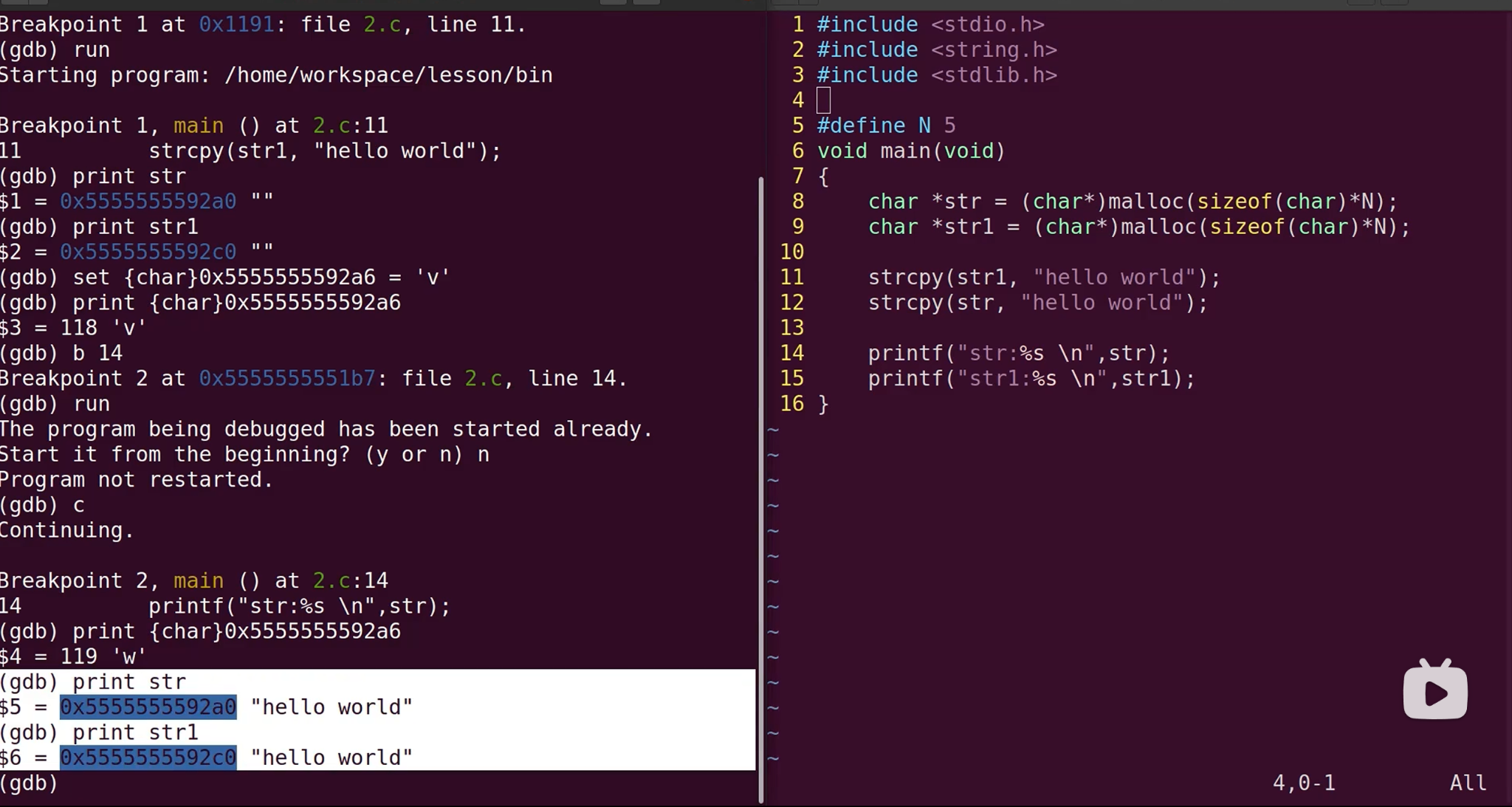
使用strcpy容易导致越界访问的问题。
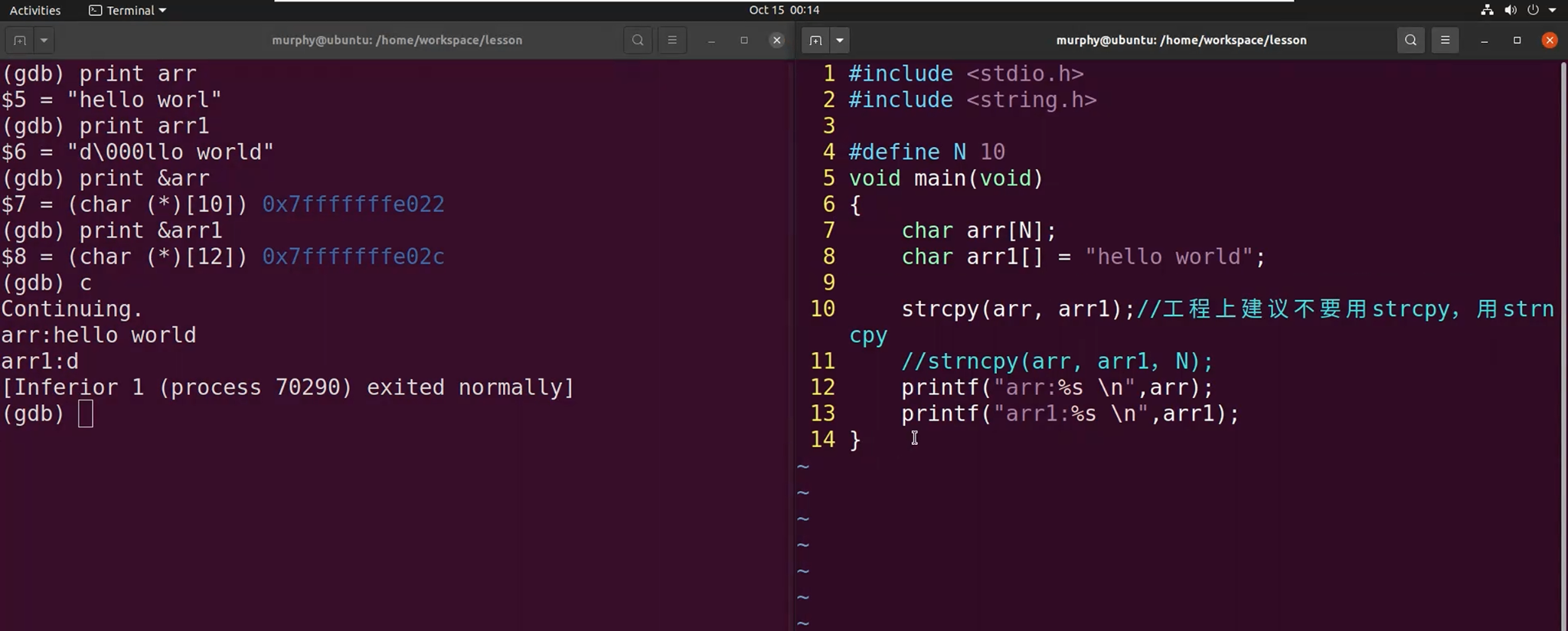
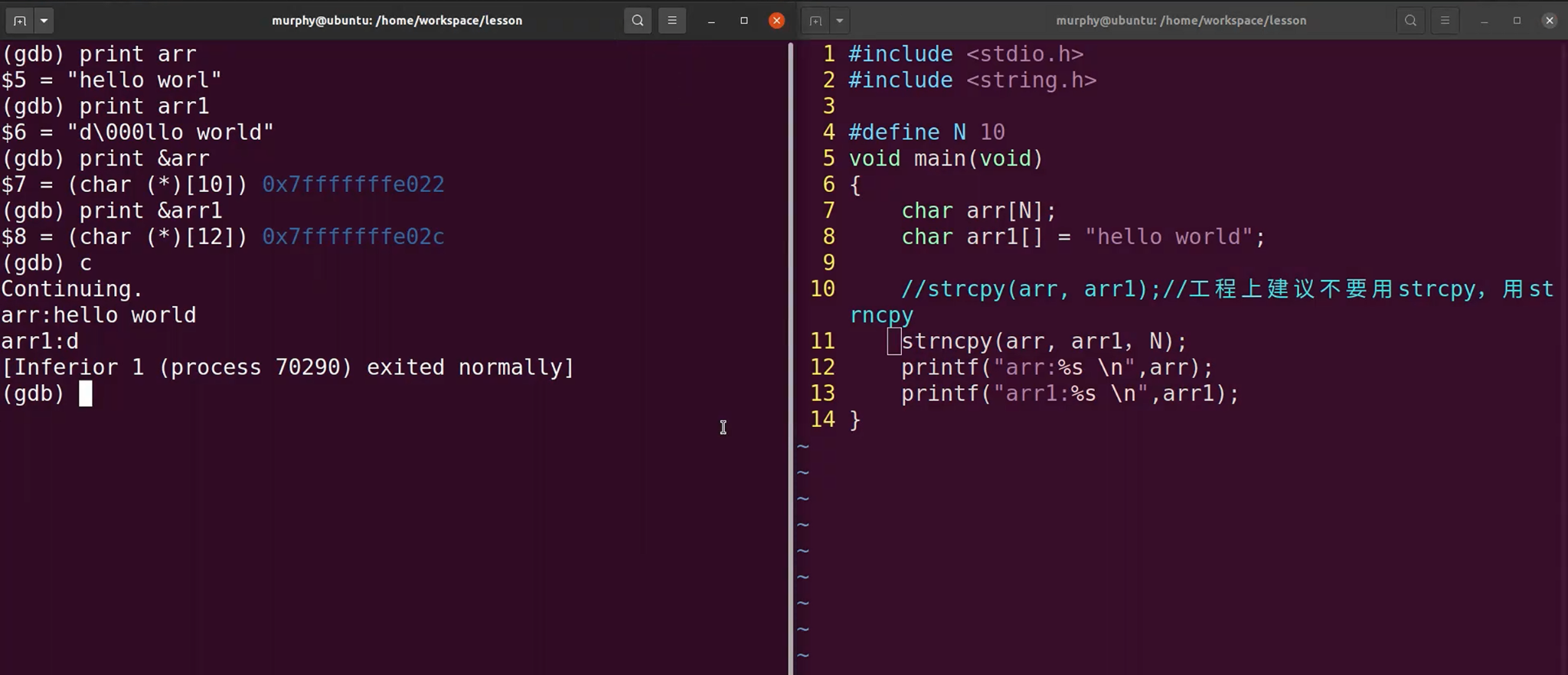
建议不要用strcpy,用strnpy会更安全一些。
printf %s,打印字符串的停止条件是检测到'\0'结束符。
堆缓冲区溢出
4.5 指针
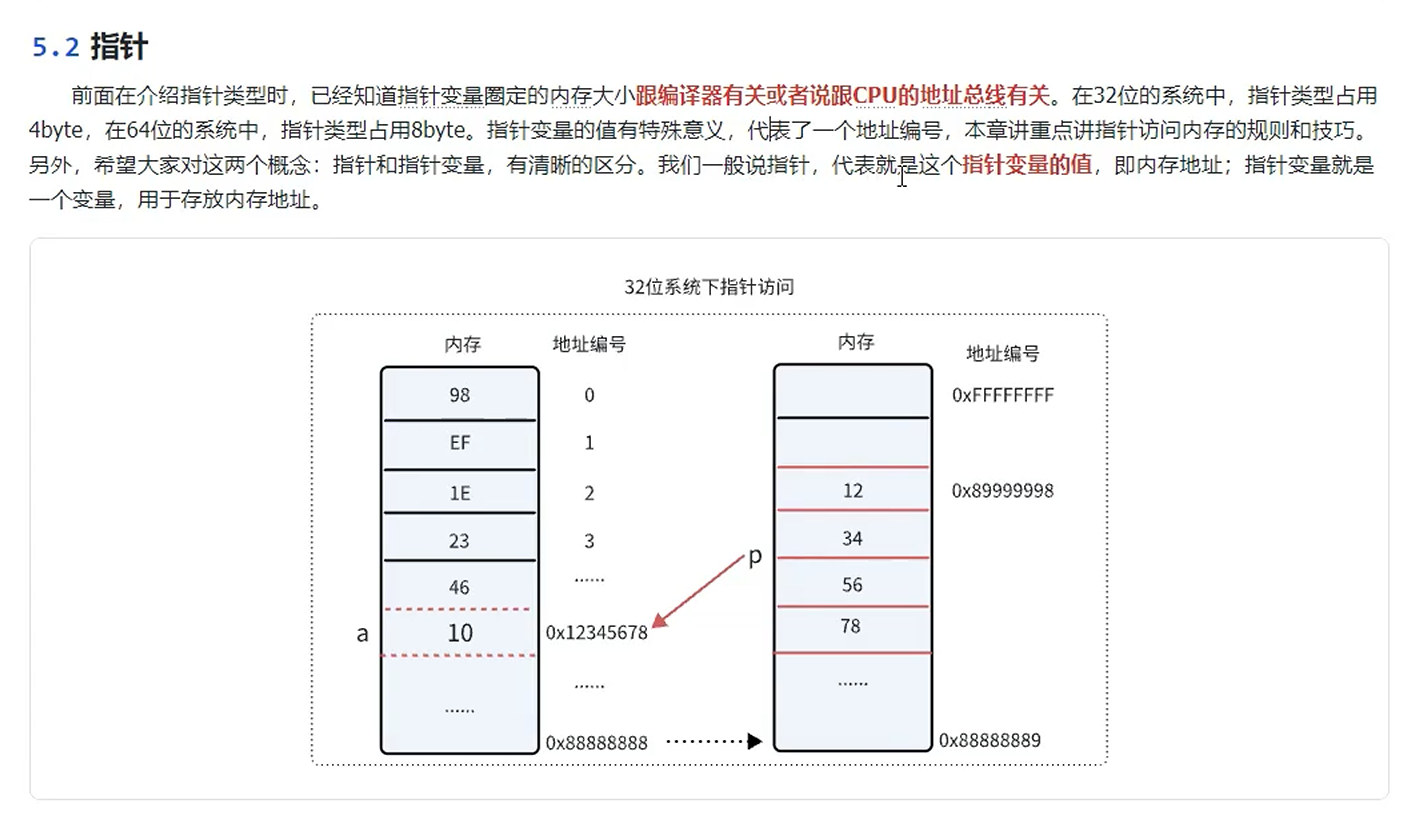
常见的易混概念
指针变量的大小和编译器有关或者说CPU的地址总线有关。
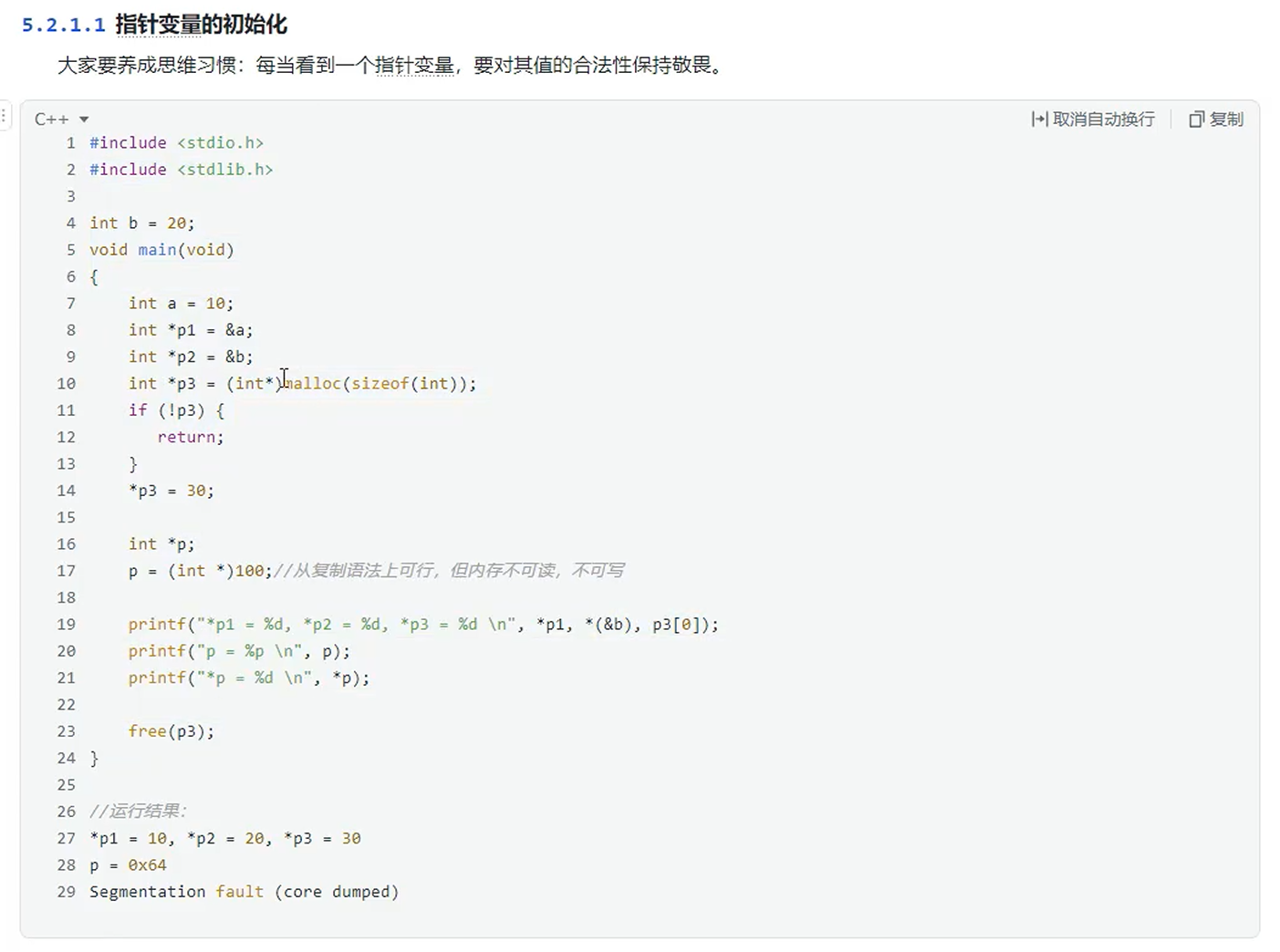
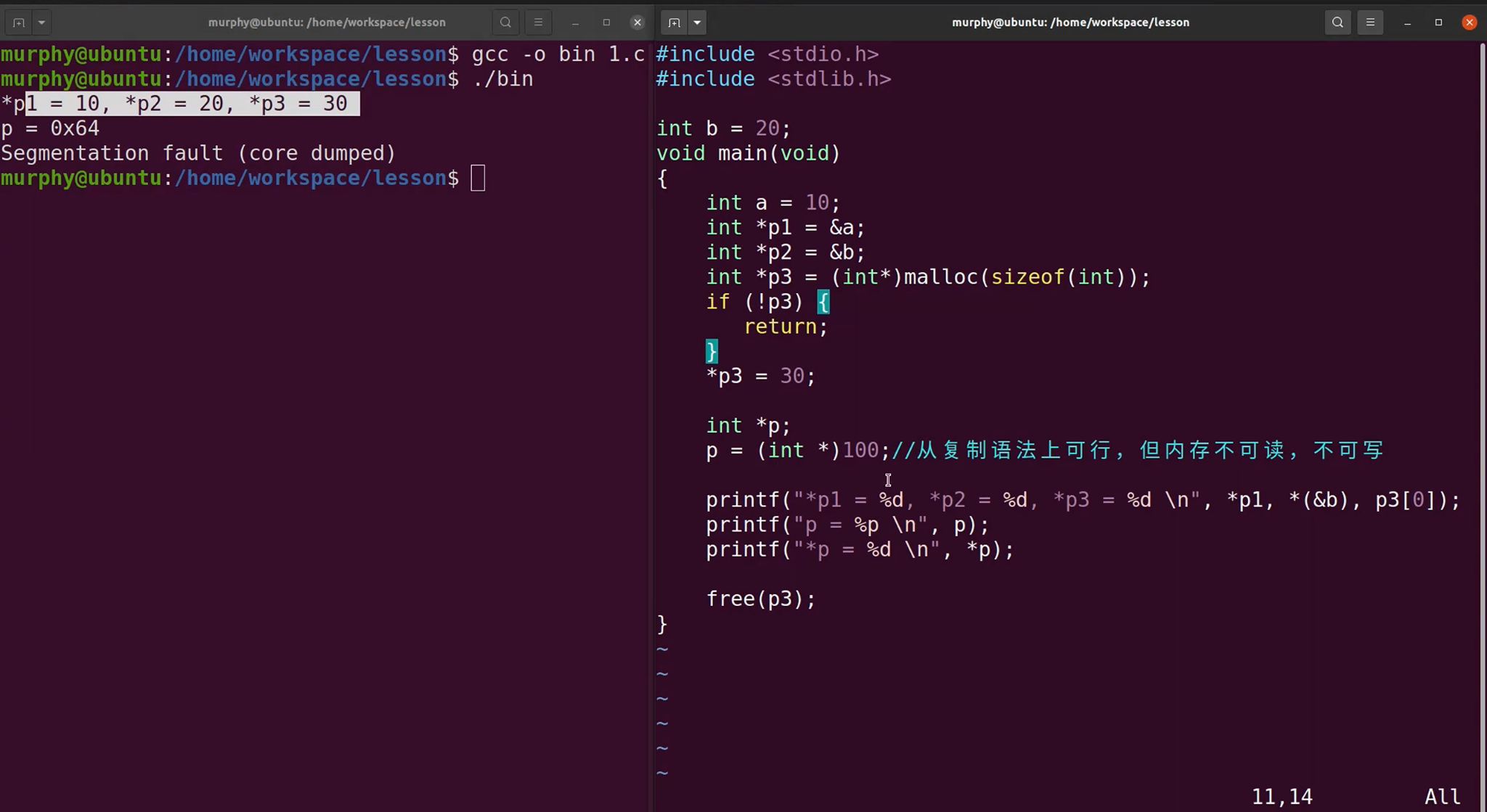
指针变量的初始化
建议养成一个习惯,看见指针就要留意它的合法性。
示例代码
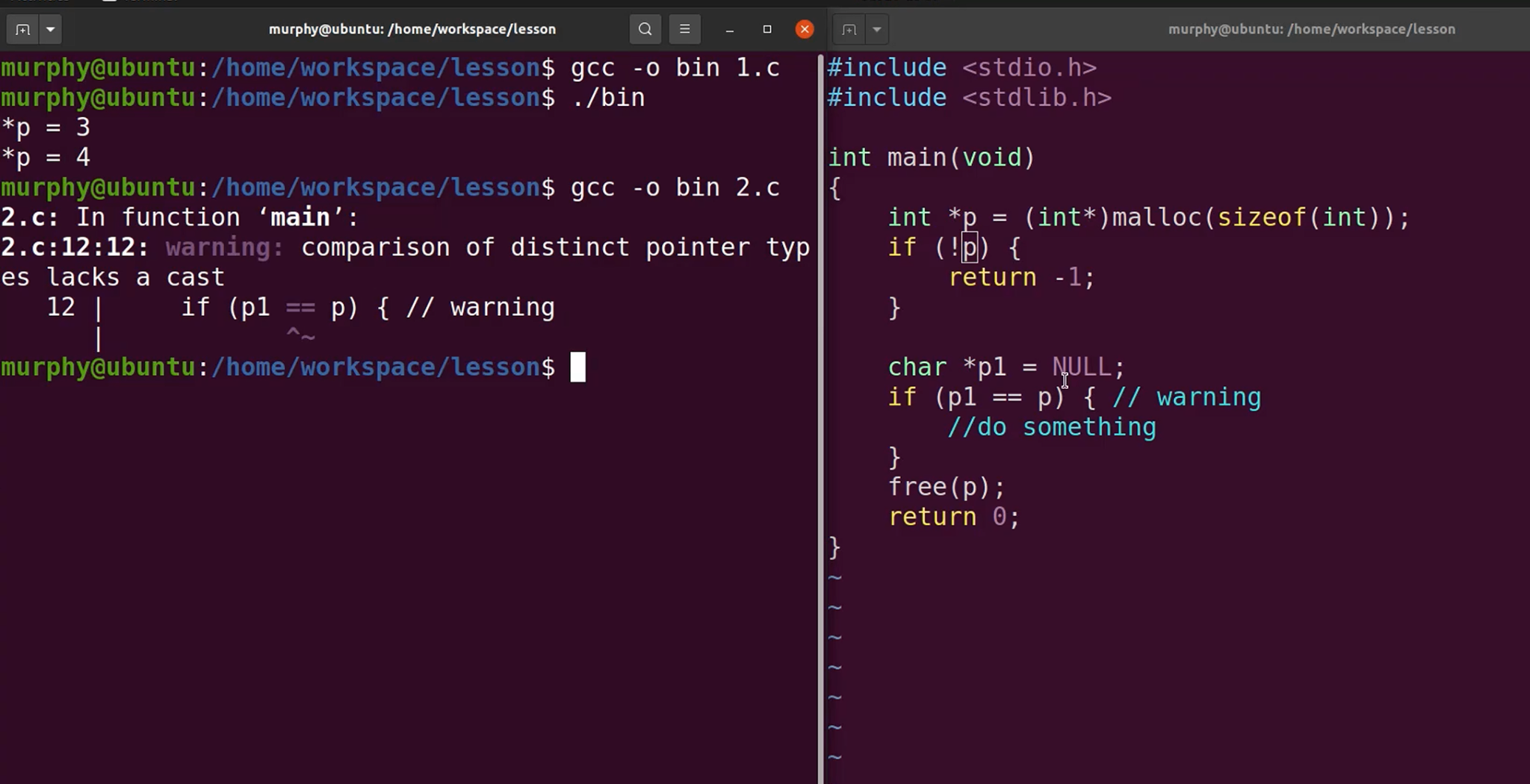
空指针和野指针
概念的区分

空指针:值为NULL的指针,NULL的值就是0。
野指针:指针指向了非法的地址。
malloc后一定要记得free,同时free完了之后也要记得把指针变量置为NULL。
指针访问内存
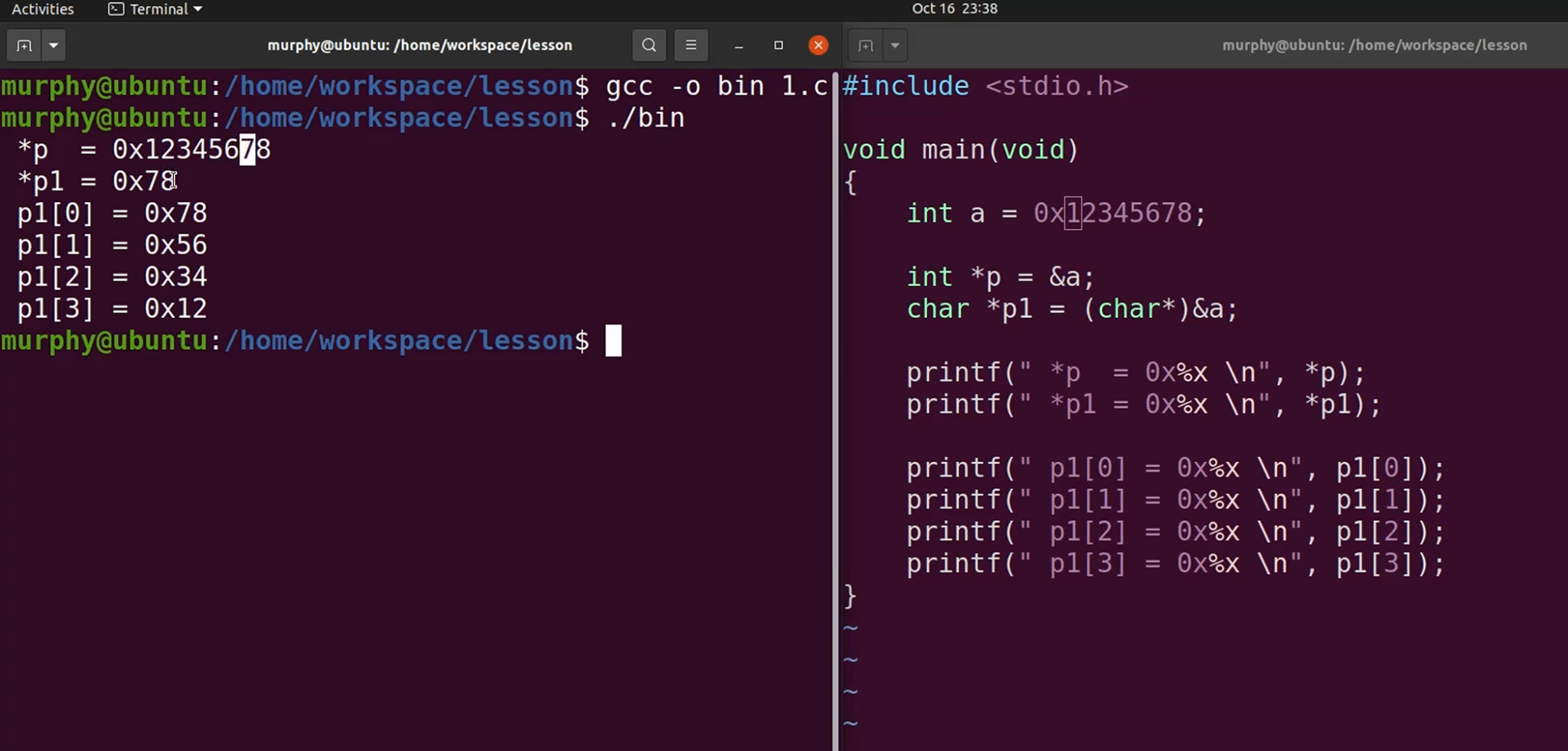
指针访问内存的规则
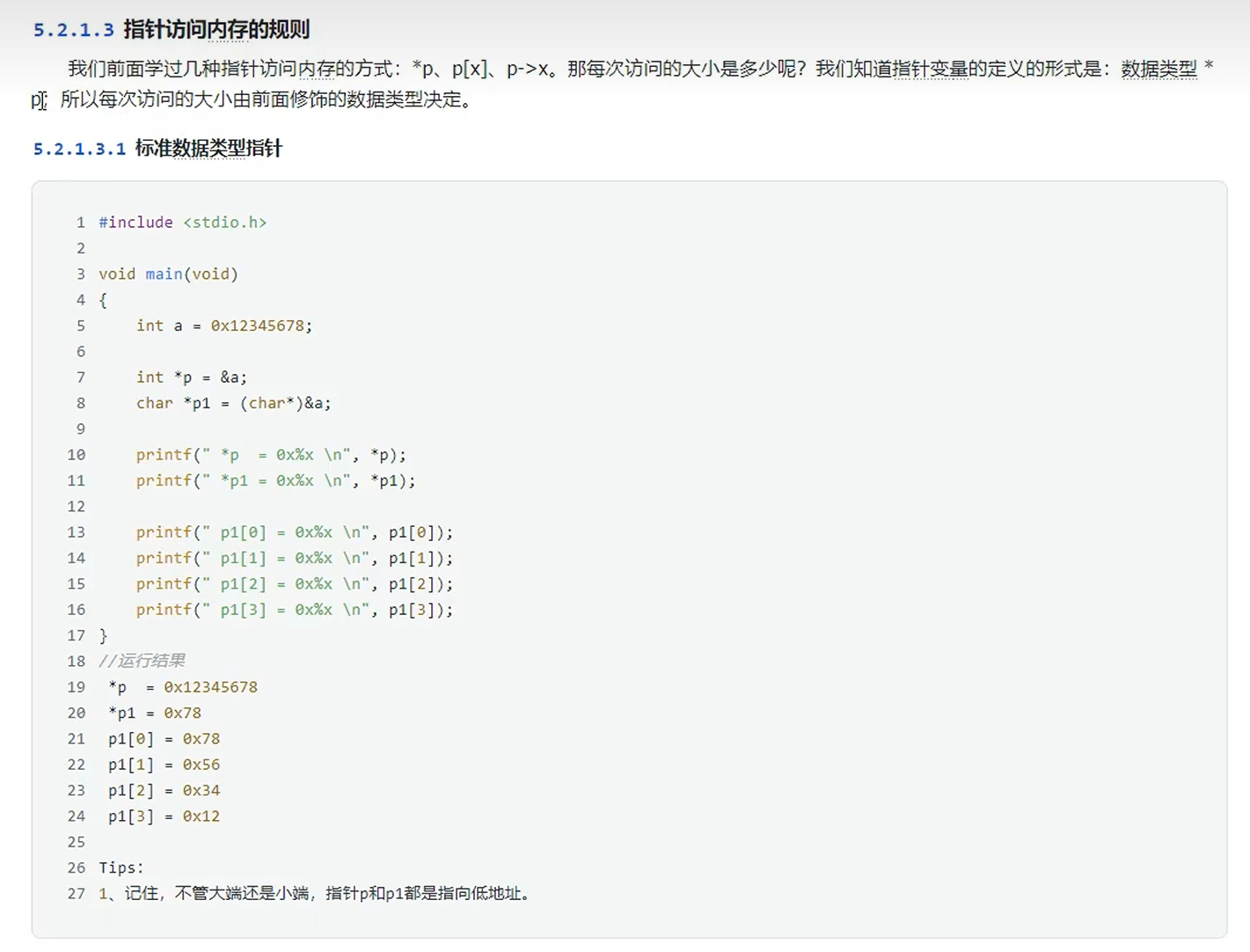
指针前面的数据类型,其实是定义了访问的地址大小,int * 则表示该指针要操作的是数据类型是int。
不管是大端还是小端,指向的地址都是小端。
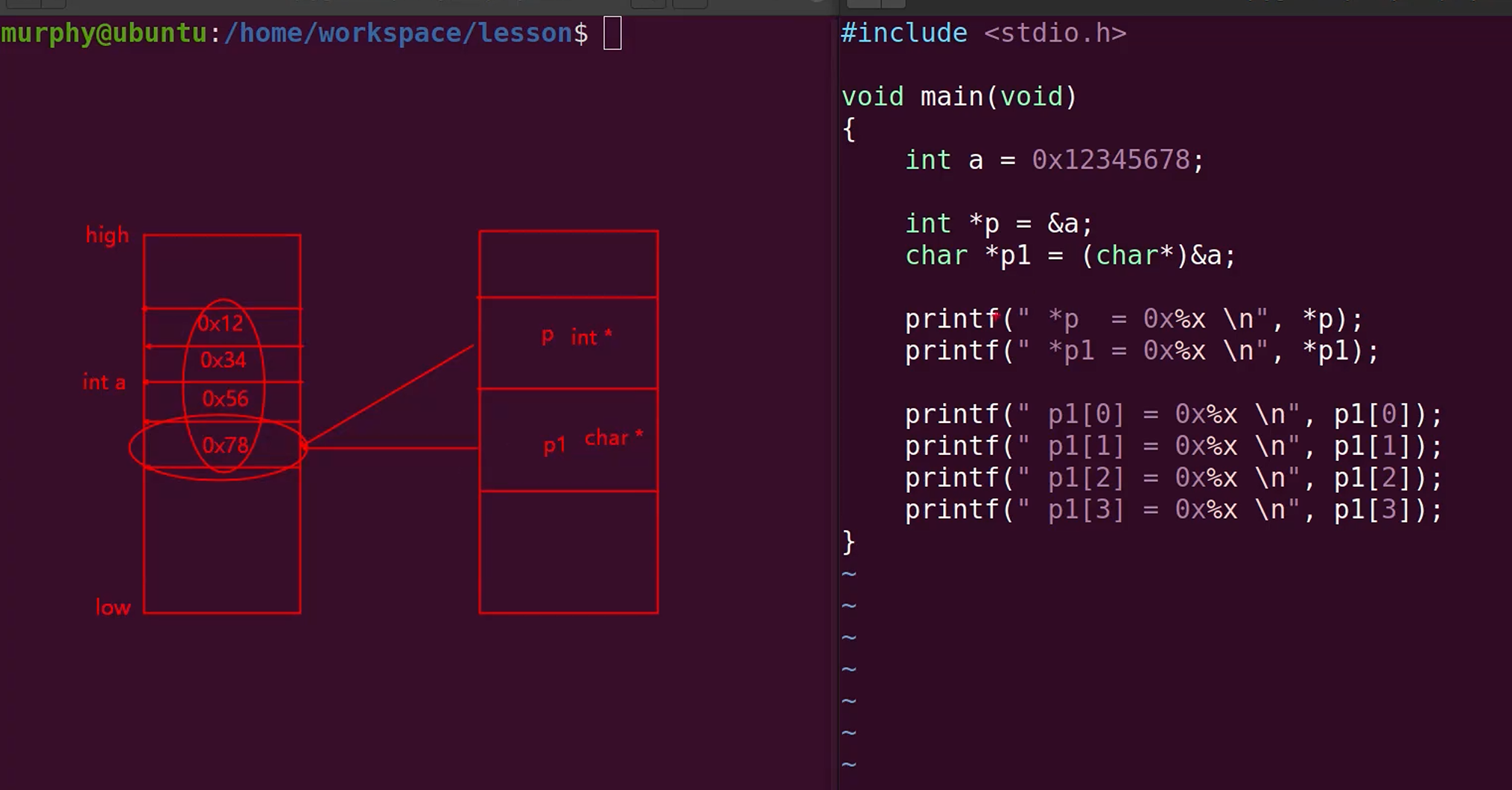
指针++,指针--,指针偏移的大小,是受前面的数据类型控制的。
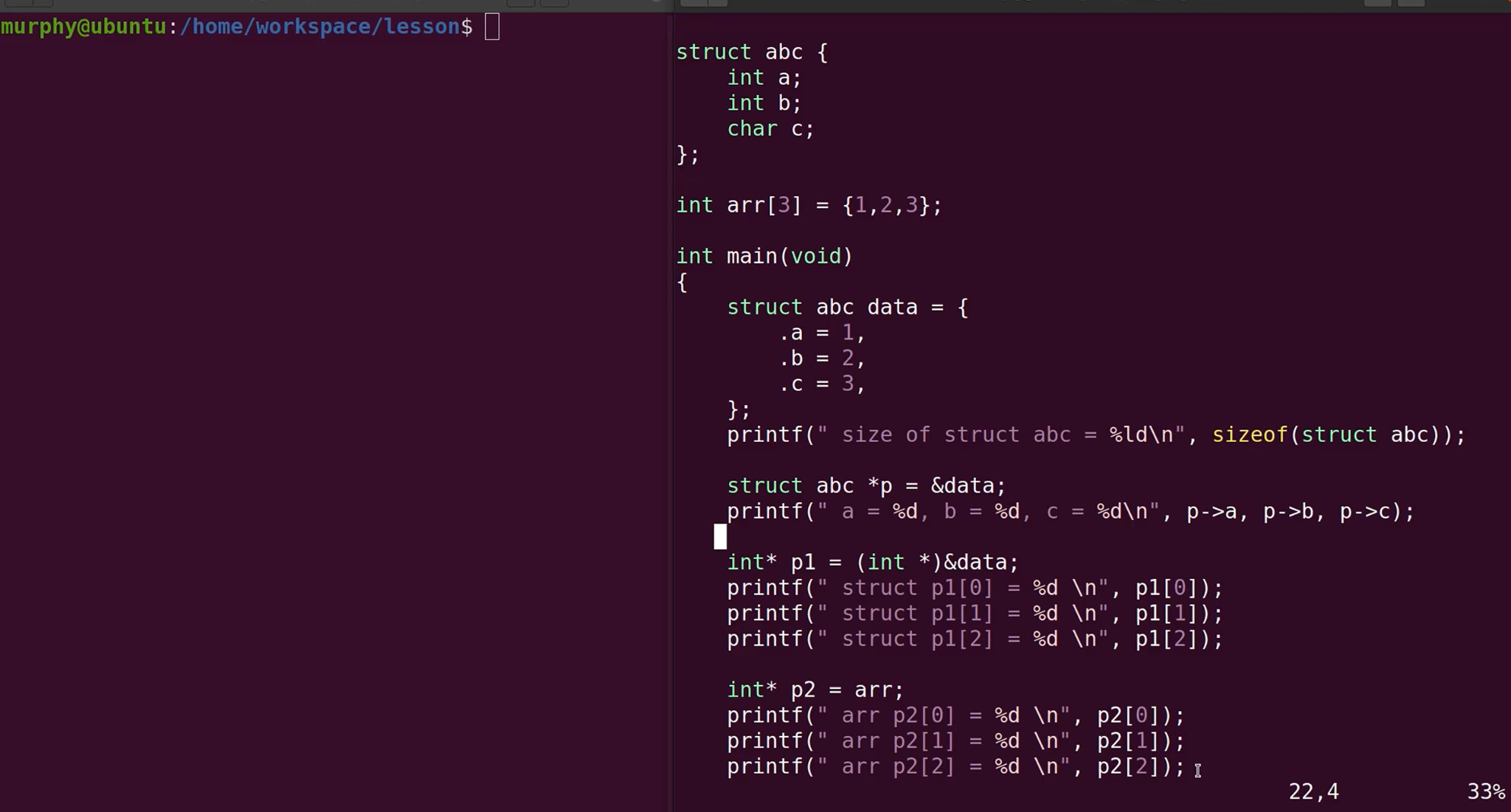
连续空间类型指针
数组,结构体本质其实是一段连续的内存空间。
示例代码
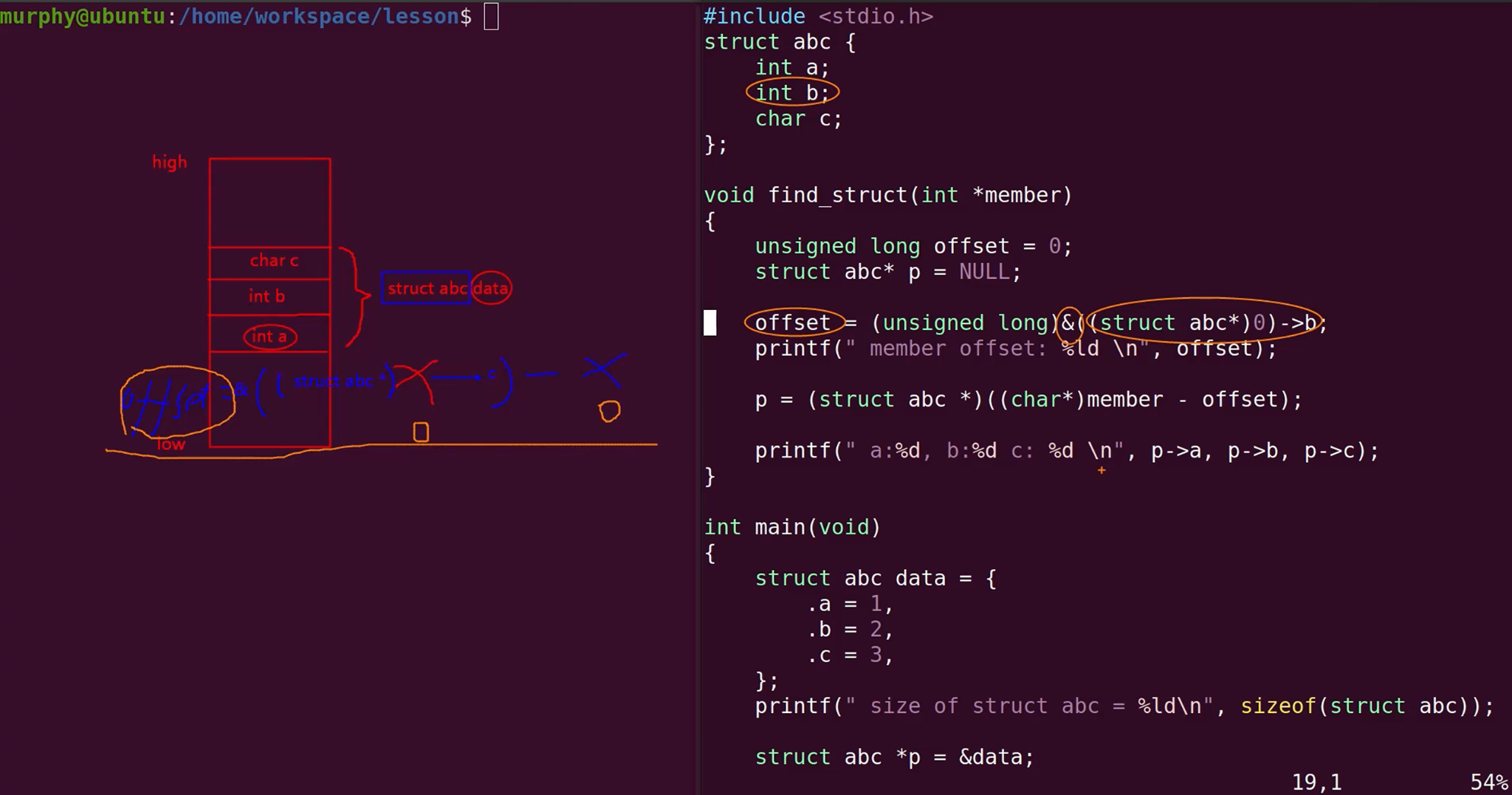
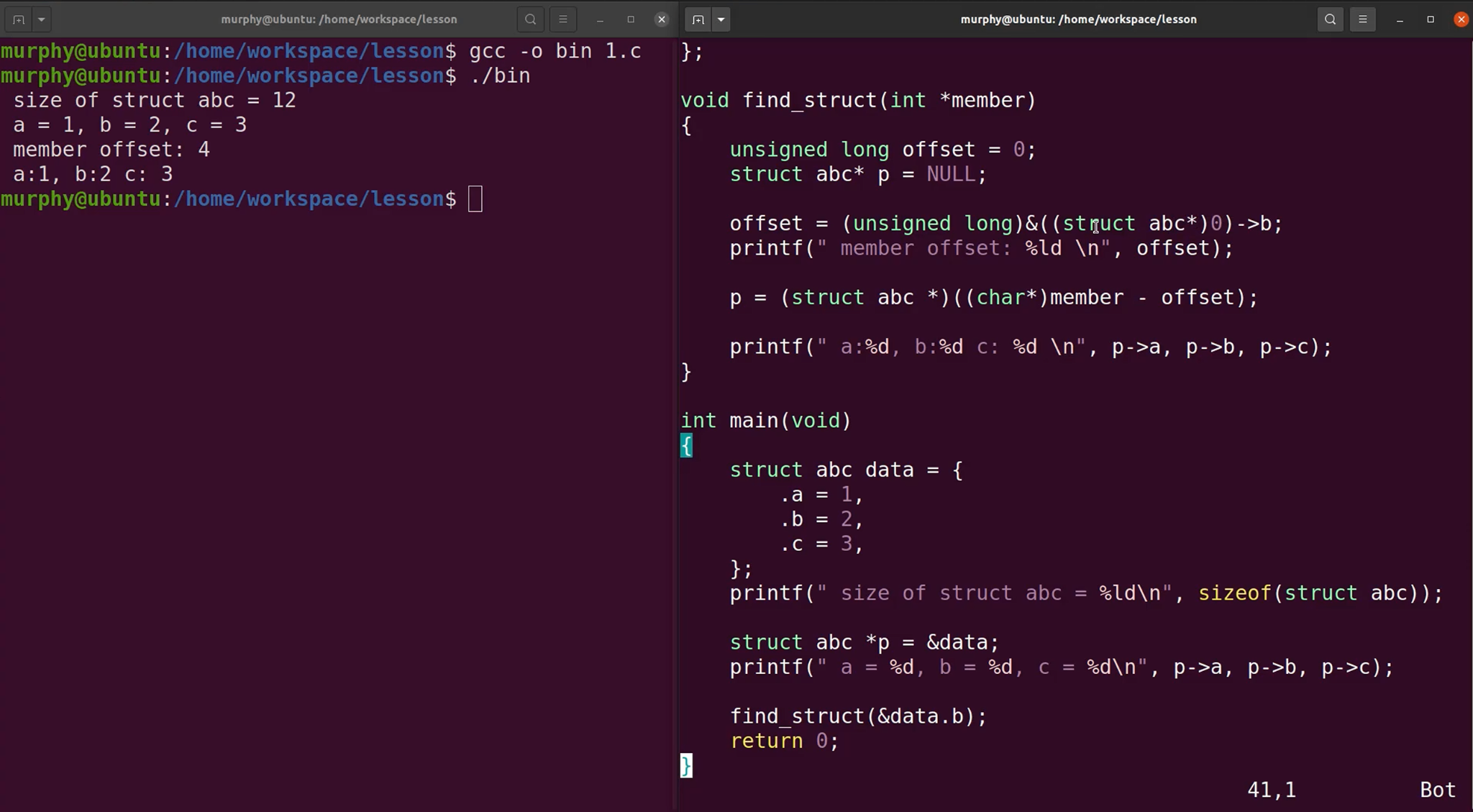
Linux第一宏container_of
知道结构体里面任意成员的地址,推出结构体的首地址。
那段计算offset的代码,在编译时就已经计算完成了。因此不会出现访问空指针的问题。
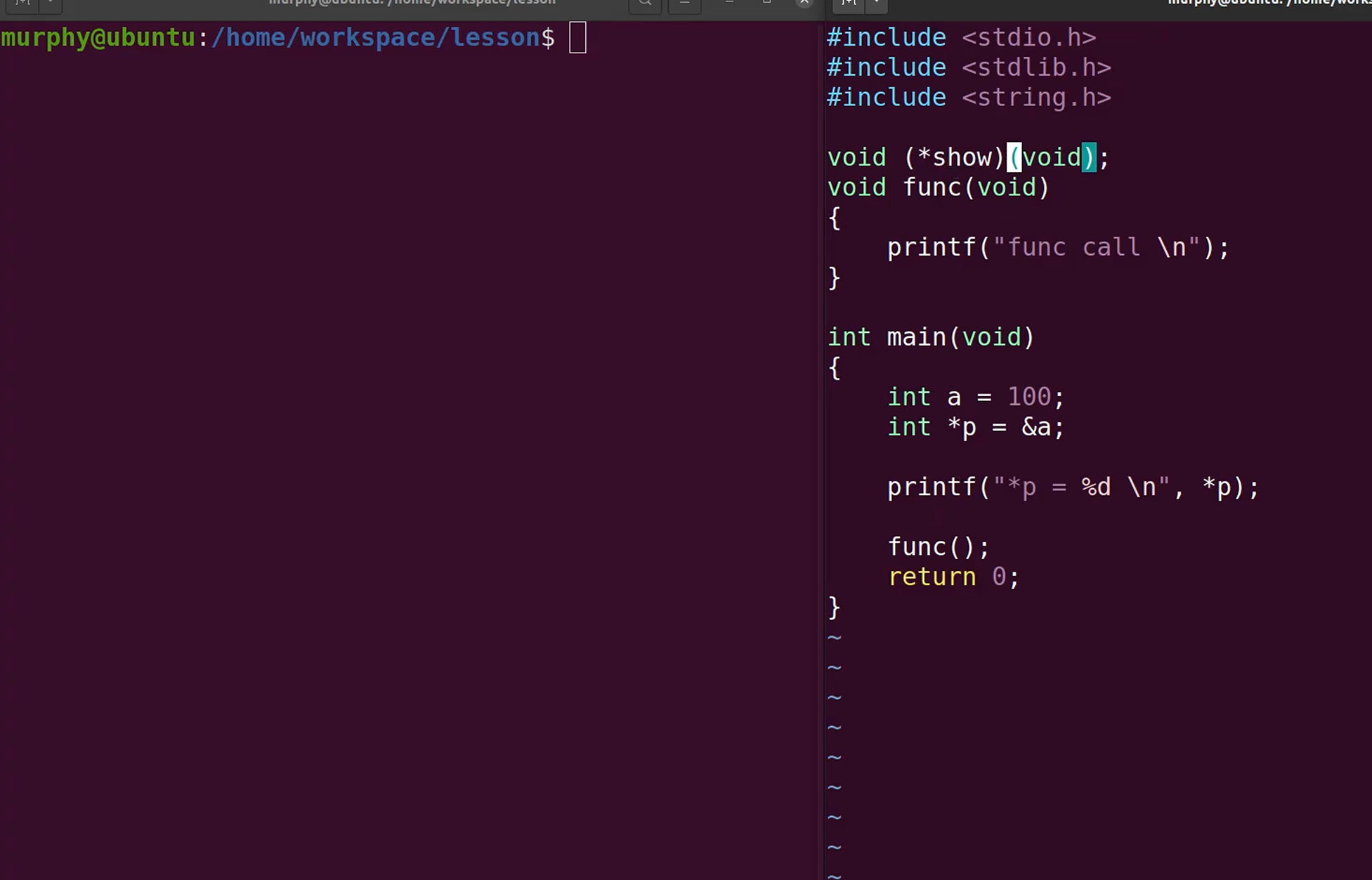
函数类型指针
函数指针介绍
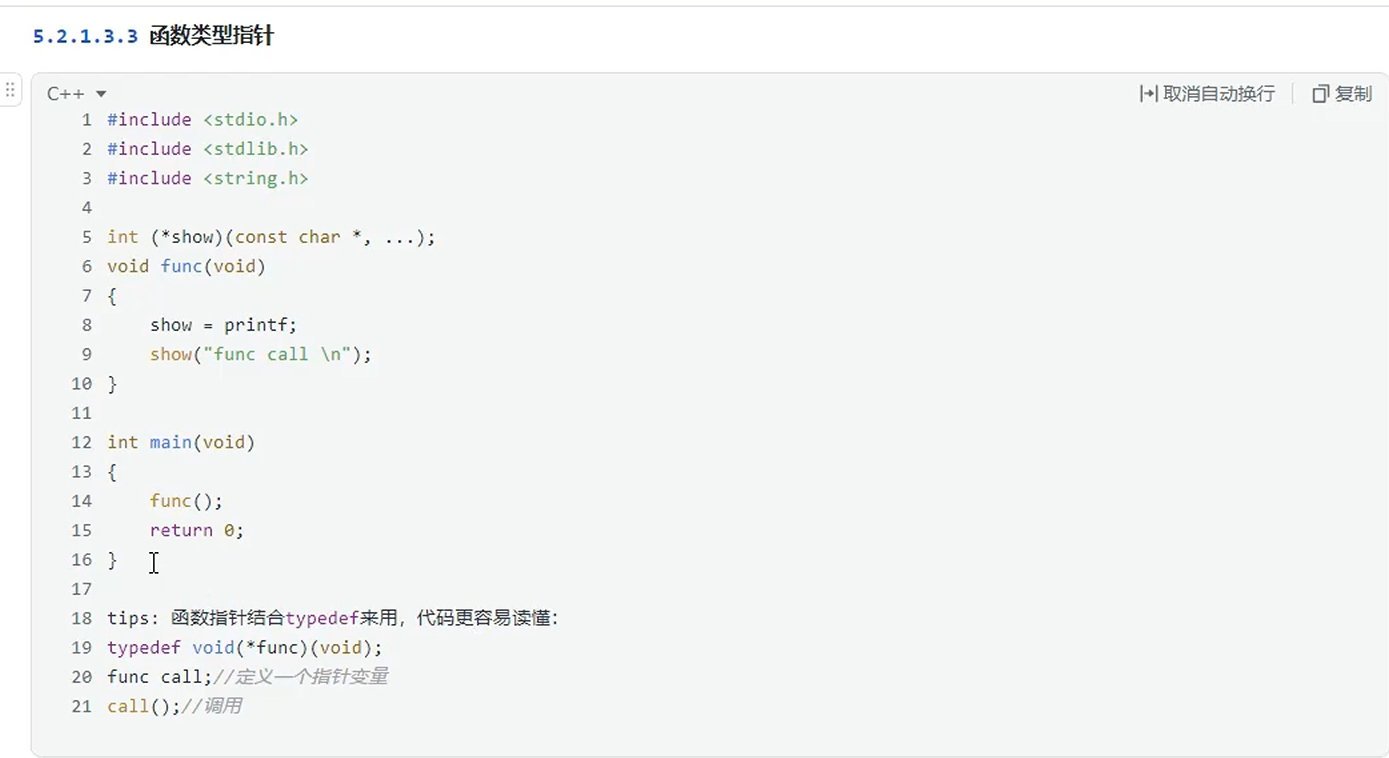
函数指针的格式:返回值 (*函数指针名字)(参数...)
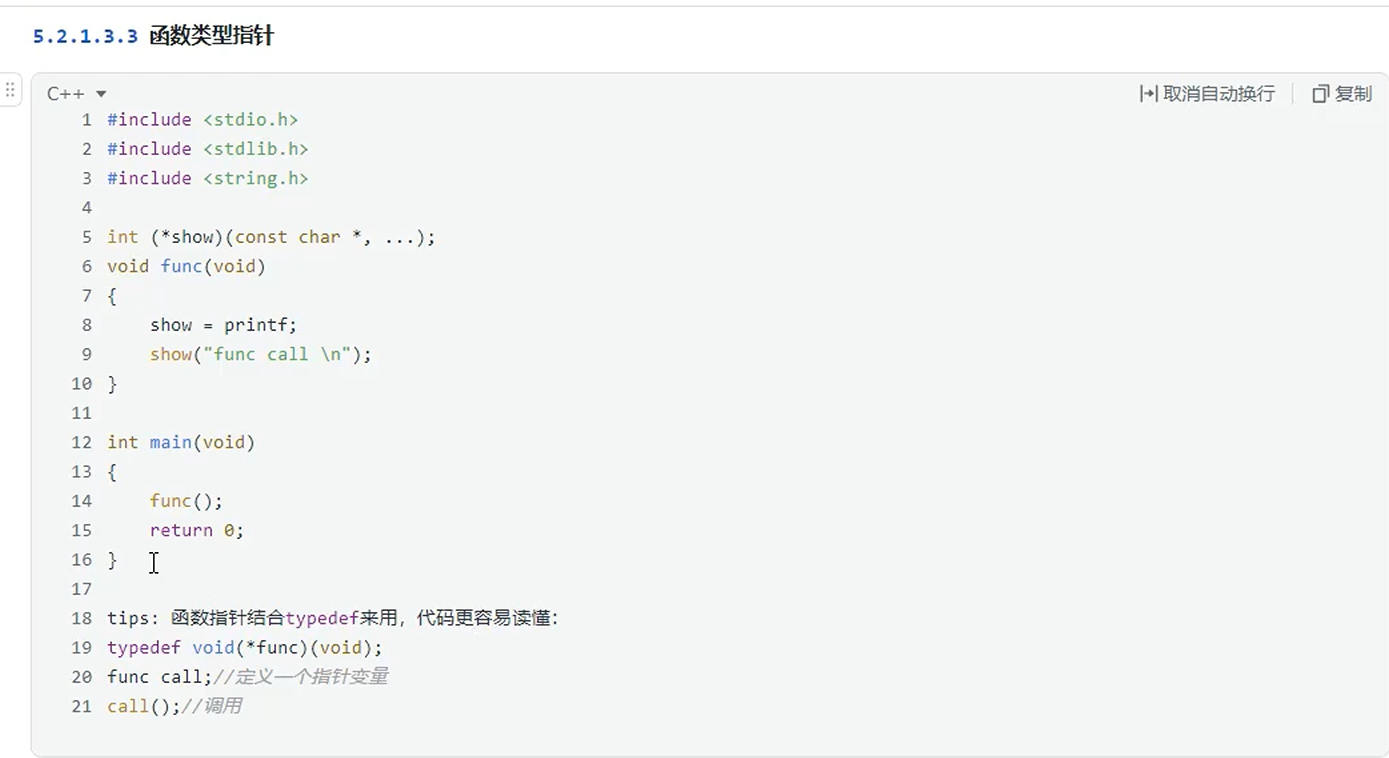
示例代码
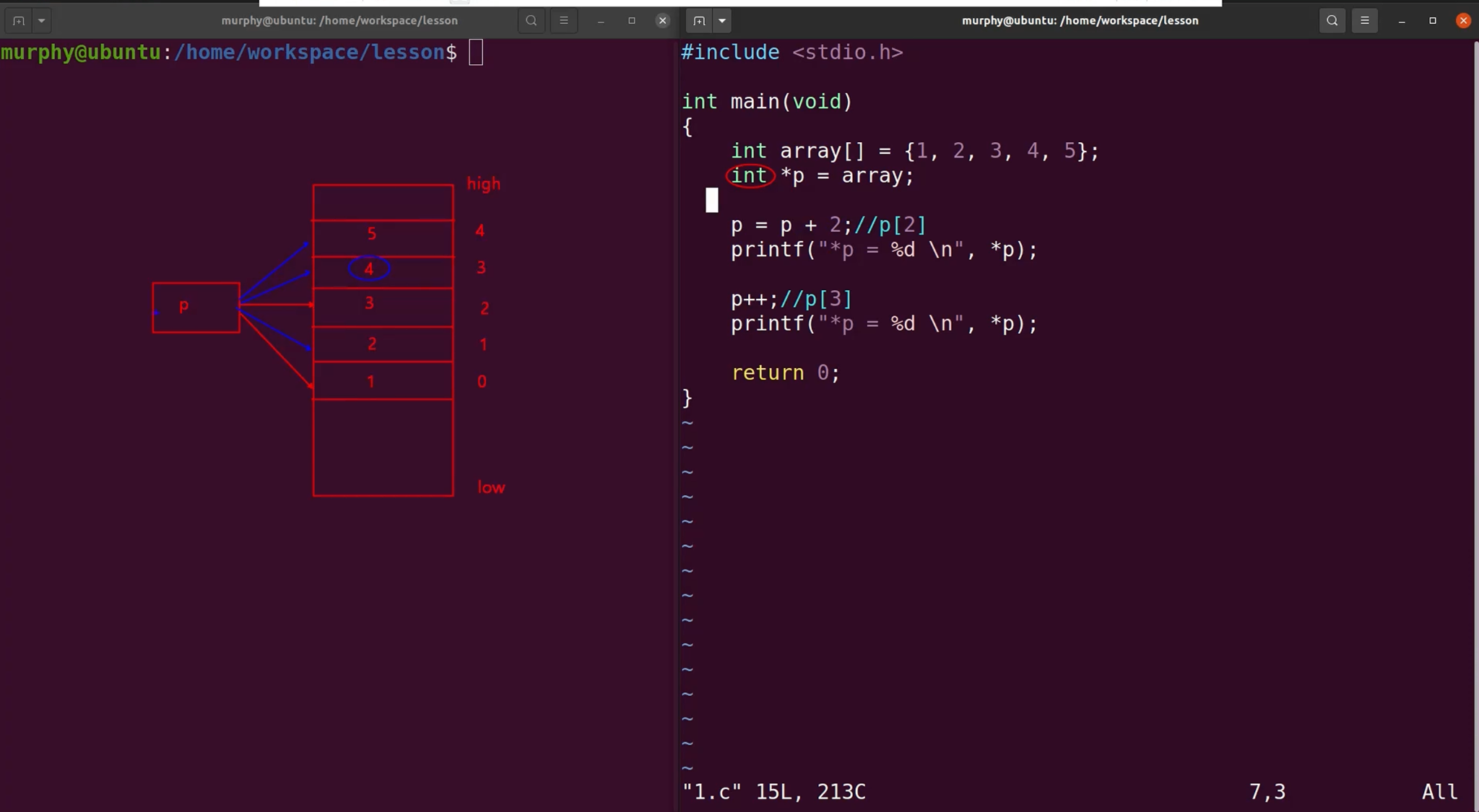
指针运算
算数运算
概念介绍
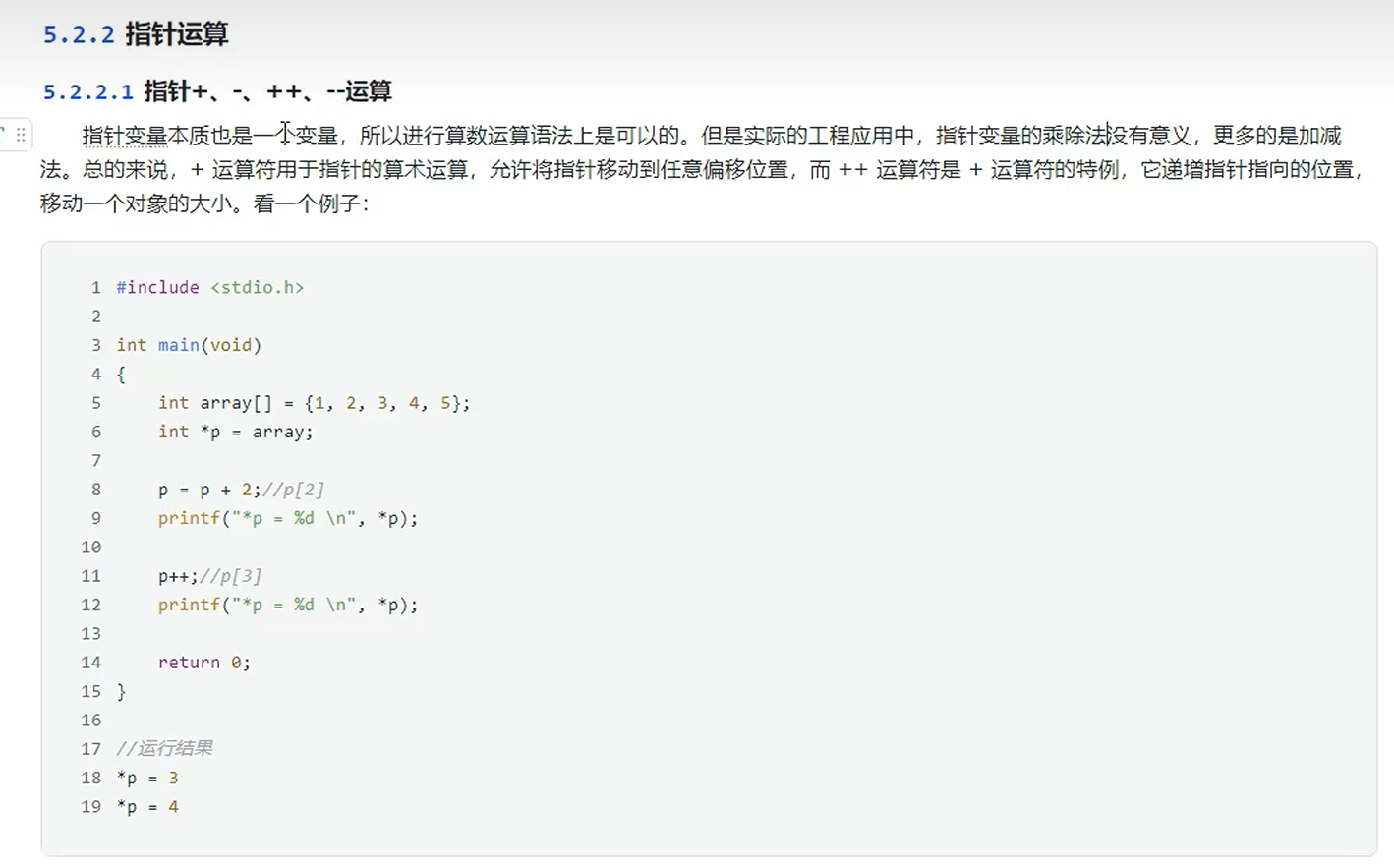
示例代码
逻辑运算
常用于判断指针的合法性
指针类型不同,管辖的范围不同。
示例代码
Linux内核里的应用

多级指针
概念
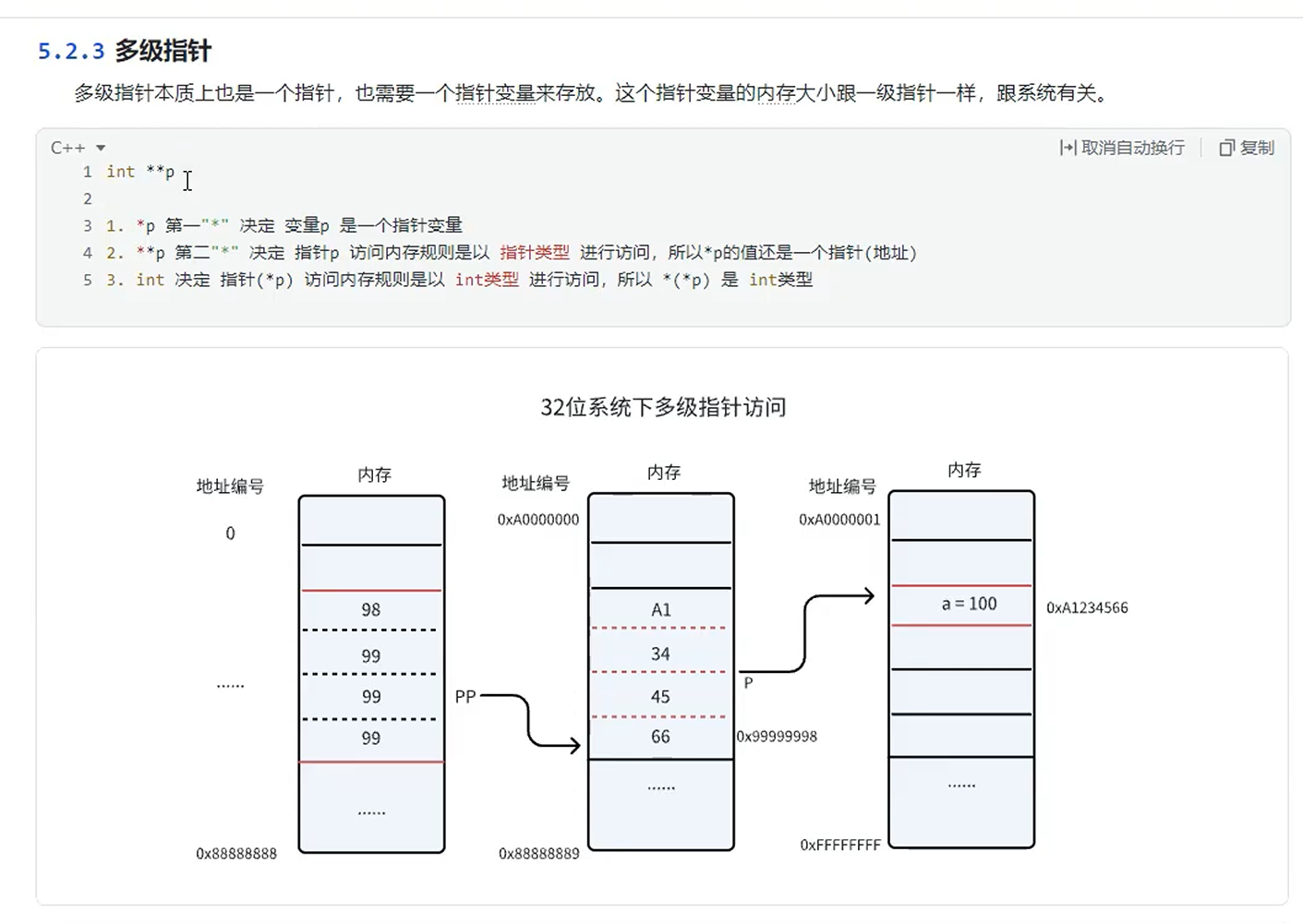
示例代码
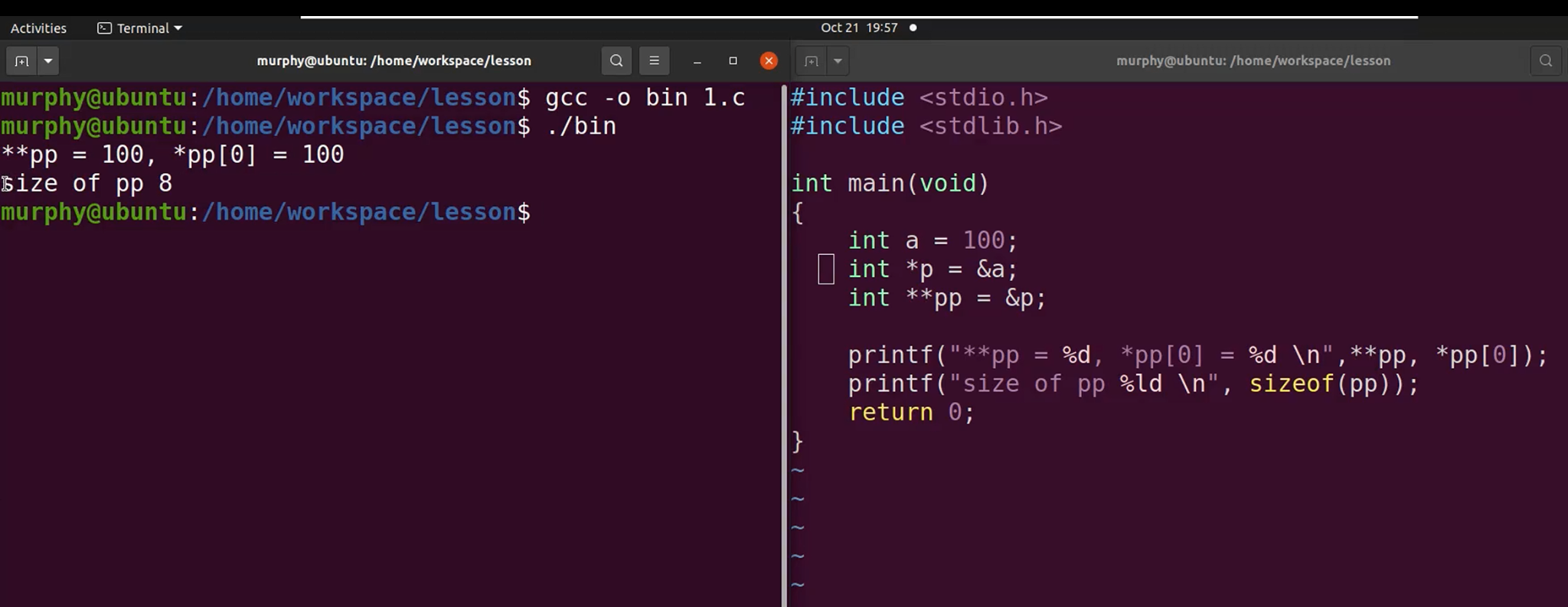
一般就用到二级指针就可以了。
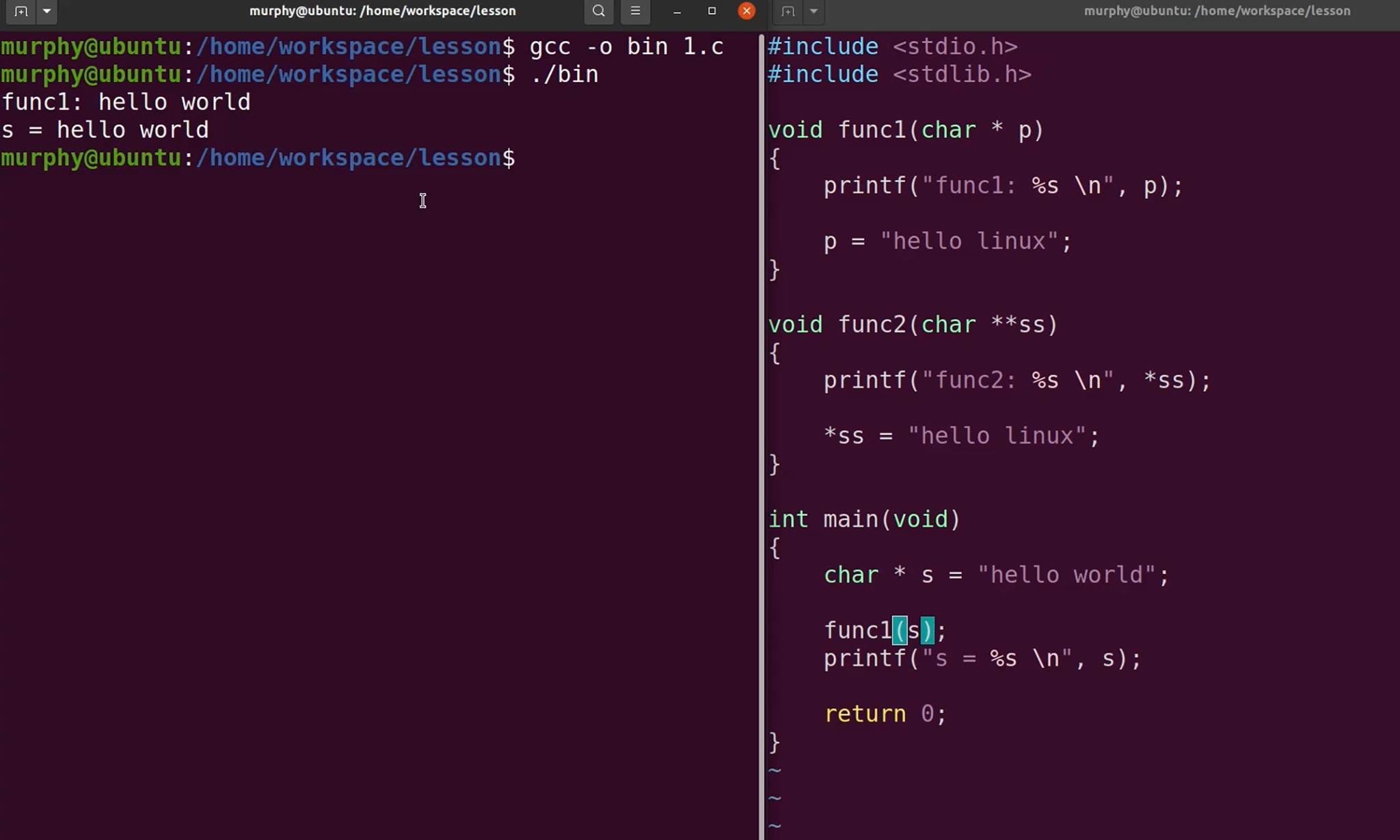
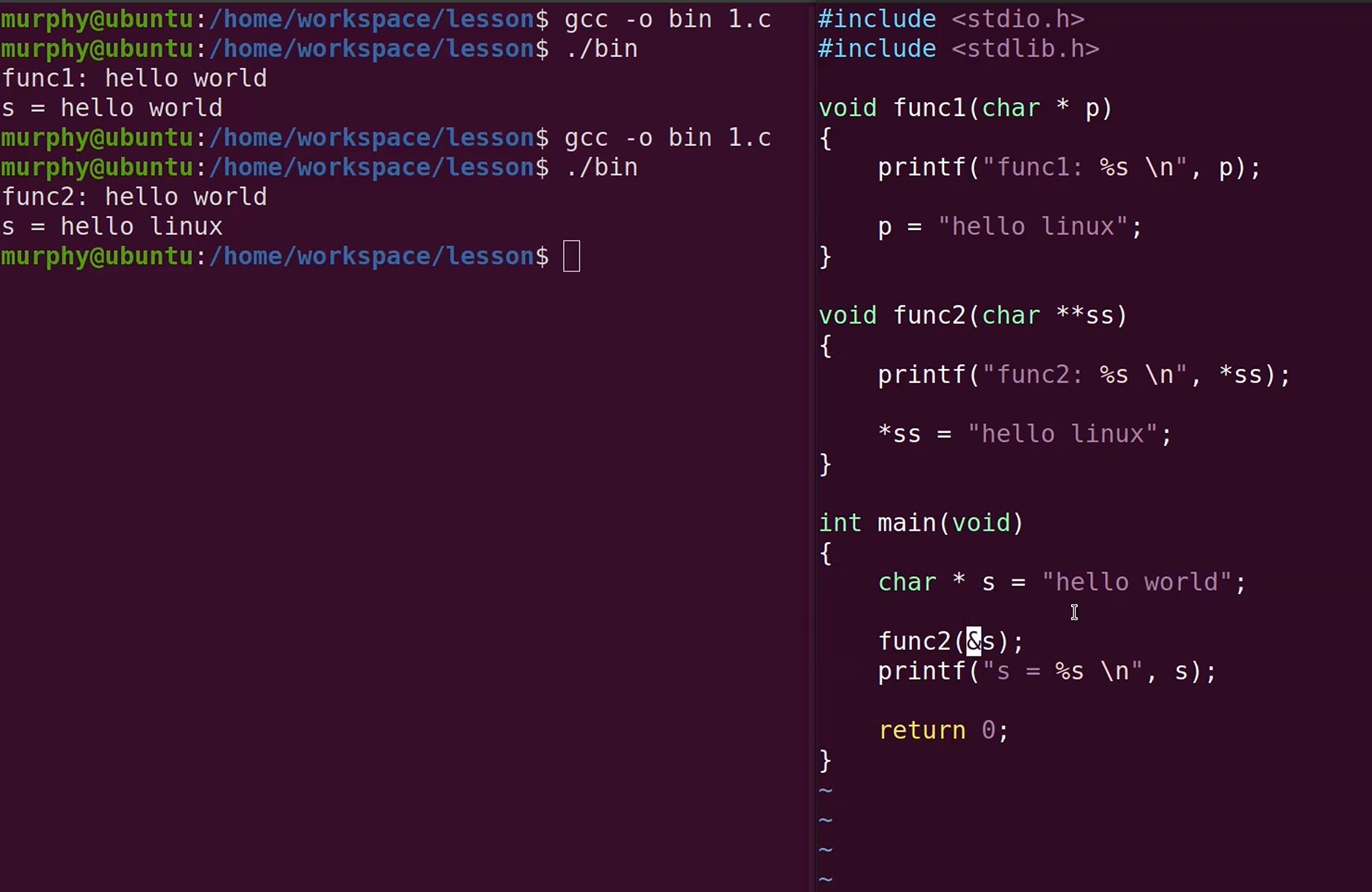
指针的地址传递
二级指针,可以改变一级指针的指向
示例代码
指针:无序变有序
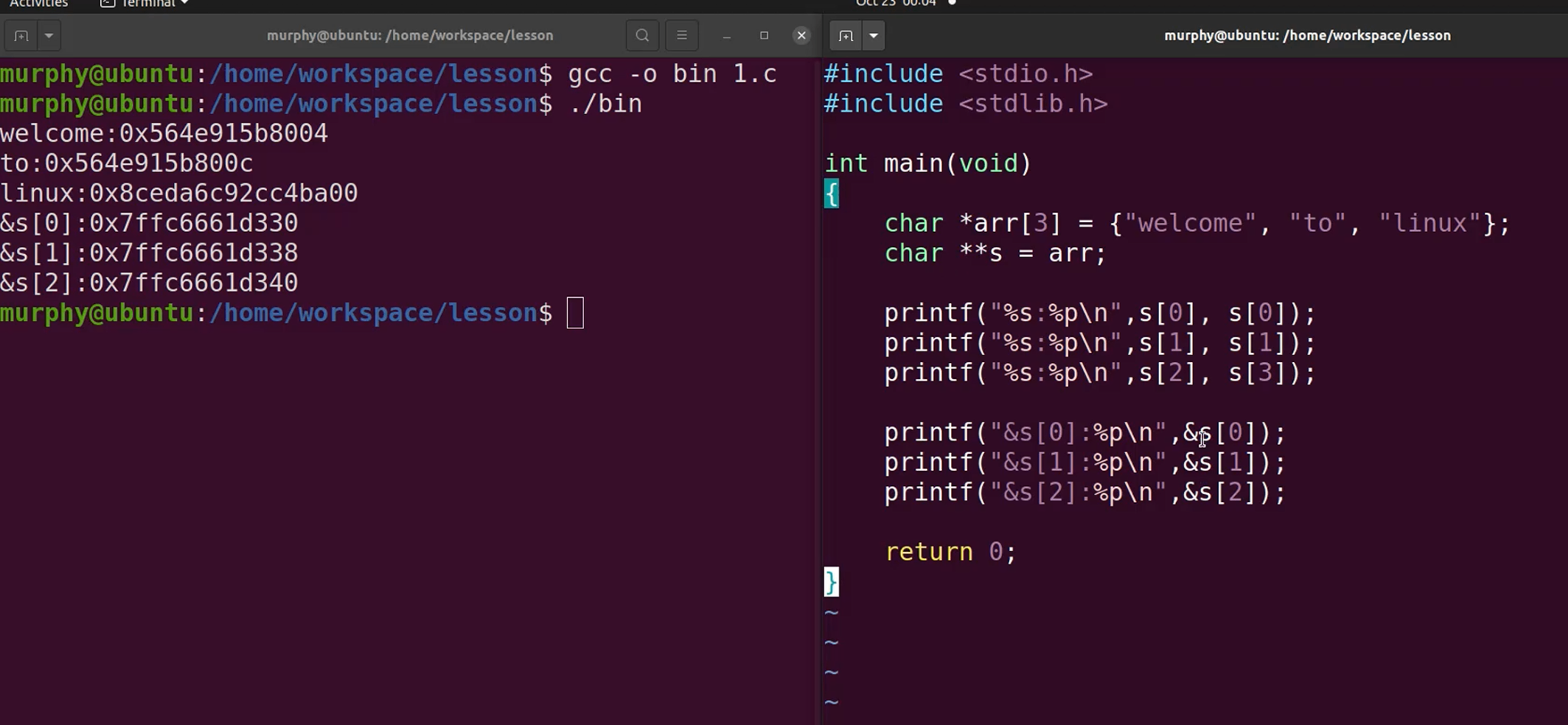
多级指针可用于物理无序映射到逻辑有序的数据结构设计
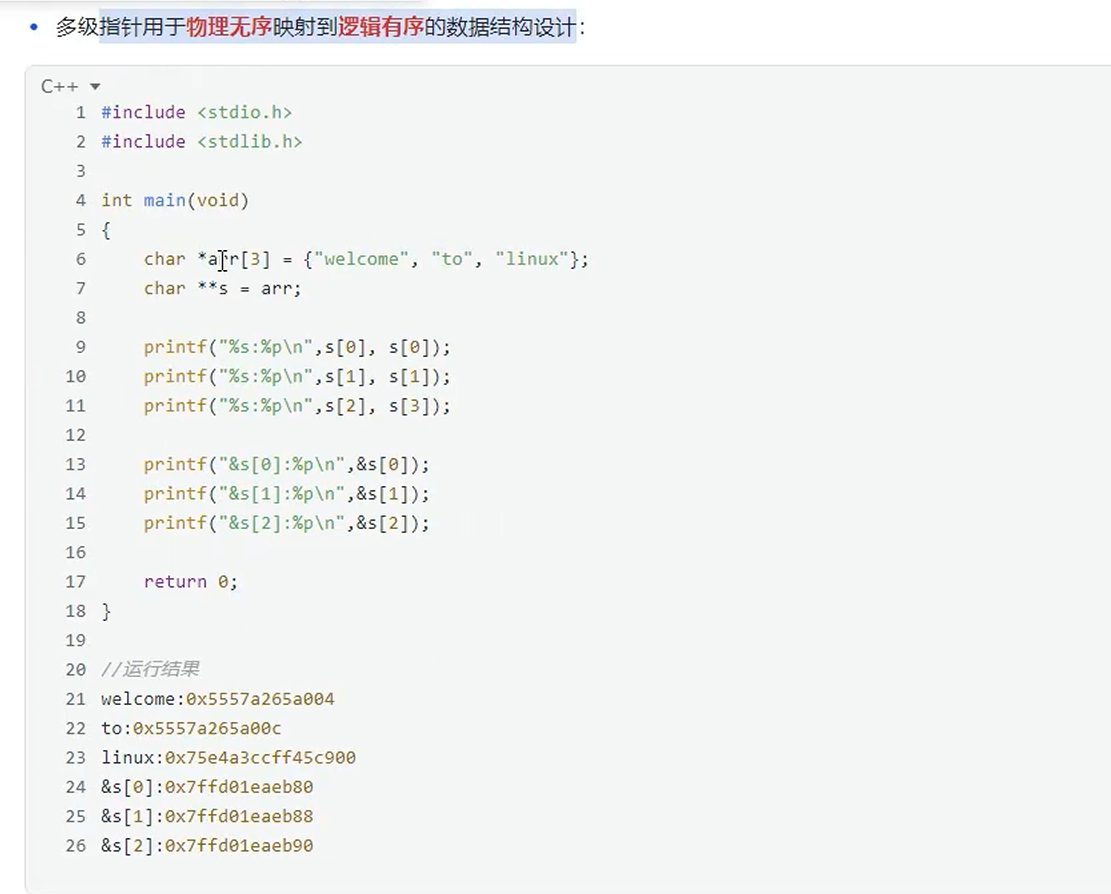
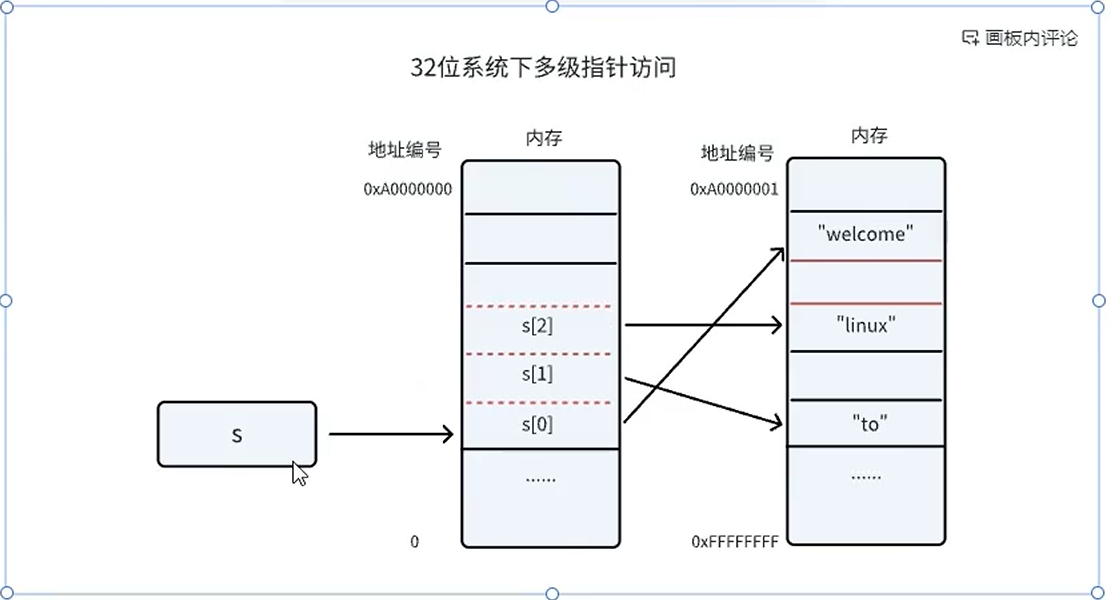
示例代码
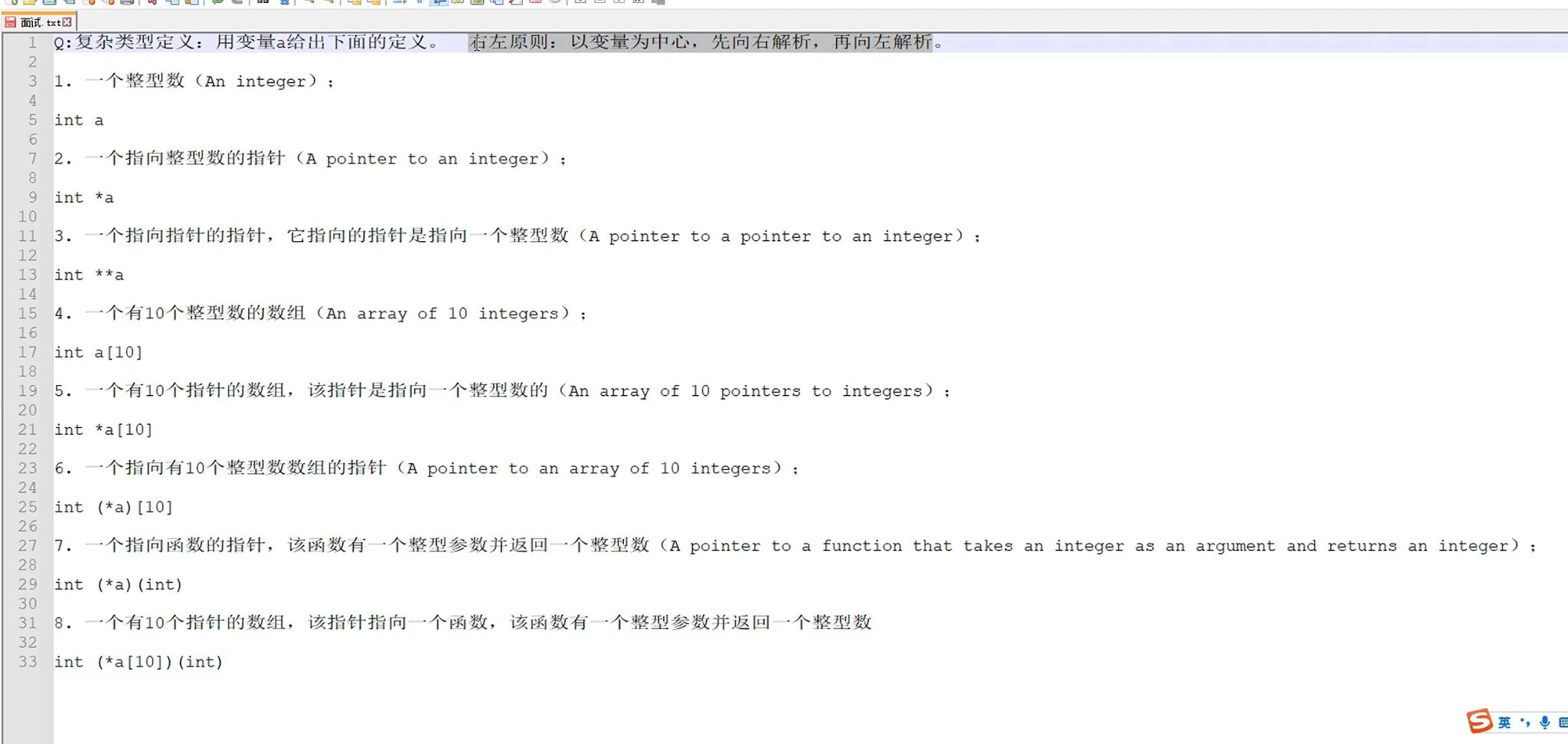
第五章:复杂类型的定义
右左原则:以变量为中心,先向右解析,再向左解析。