在AI的浪潮中,多模态大模型正成为突破单模态限制的关键方向。Flamingo作为视觉语言模型(VLM)的代表,以"视觉-文本交错输入+自由文本输出"的独特设计,实现了多模态语义的深度融合与流畅生成。本文将从架构、训练、推理到创新价值,全方位解析这一技术杰作。
一、架构解析:多模态信息的"交响乐团"
Flamingo的架构是一场视觉与文本的"交响协作",每个模块都承担着独特的"声部"角色。
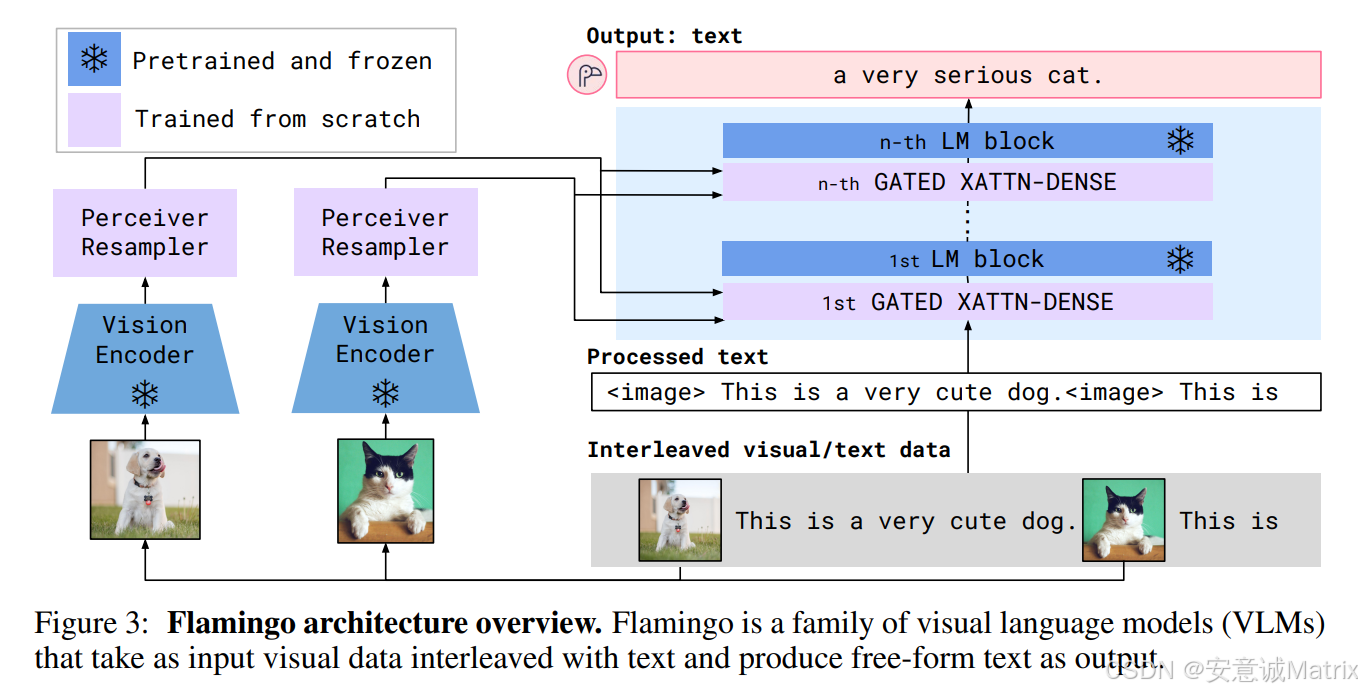
1. 输入:视觉-文本的交错序列
Flamingo的输入是视觉数据与文本数据的交错组合 ,形式为<image>标记与自然语言文本的交替序列。例如:
"<image> 这是一只在草地上奔跑的狗。<image> 它的毛色很特别......"
这种设计让模型能自然地处理"先看图像、再读文本、再看图像、再生成文本"的多模态交互场景。
2. 输出:自由形式的文本生成
输出是自由文本(free-form text) ,可完成图像描述、视觉问答、多模态对话等任务。比如输入猫咪图像和上下文后,模型能生成"a very serious cat."这类精准且流畅的描述,也能回答"这只猫是什么品种?"这类视觉问题。
二、训练:"冻结预训练+从头训新模块"的混合策略
Flamingo的训练策略堪称"站在巨人肩膀上创新",既保留单模态预训练的知识沉淀,又针对性地学习多模态融合能力。
1. 预训练并冻结的"基石模块"
- 视觉编码器(Vision Encoder):基于CLIP等预训练视觉模型,在海量图像数据上学习了鲁棒的视觉特征提取能力。训练时冻结参数,避免破坏已有视觉知识。
- 语言模型(LM)基础块:基于GPT类预训练语言模型,在大规模文本数据上掌握了文本理解与生成的核心能力。训练时同样冻结,保留其文本领域的"语言直觉"。
2. 从头训练的"多模态桥接模块"
- Perceiver Resampler:负责"翻译"视觉特征,将视觉编码器输出的高维特征重采样为固定长度、适配语言模型的格式,成为视觉与文本的"翻译官"。
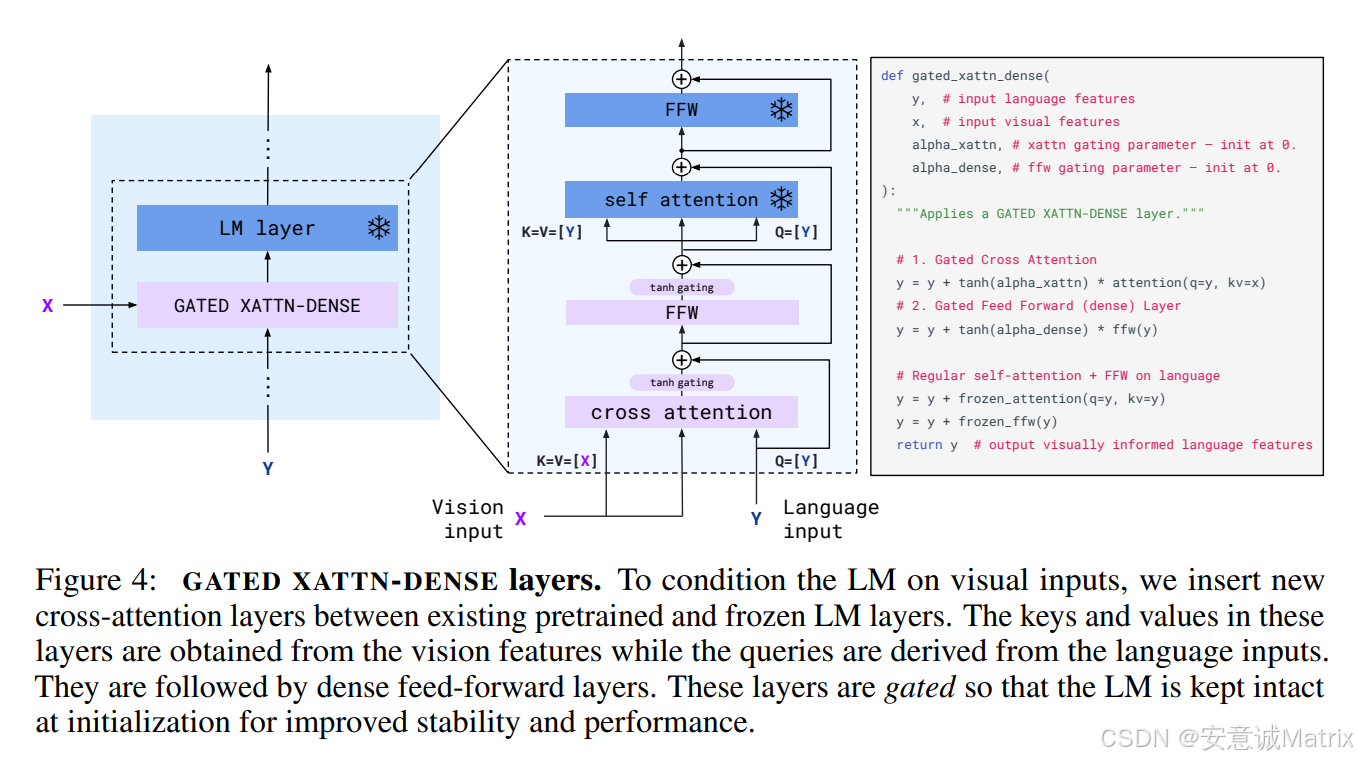
- GATED XATTN-DENSE(门控交叉注意力-密集层):在语言模型的每一层中插入,通过"门控机制"动态控制视觉信息的融入程度,实现视觉与文本特征的渐进式交叉融合。
3. 训练流程:多模态对齐的优化
以交错的视觉-文本序列 为训练数据,通过自回归生成任务 (如根据输入生成后续文本)优化模型。损失函数采用交叉熵,仅更新Perceiver Resampler和GATED XATTN-DENSE的参数,让模型专注学习"视觉-文本"的语义关联。
三、推理:多模态信息的"链式融合与生成"
推理时,Flamingo遵循"特征提取→模态桥接→渐进融合→文本生成"的流程:
- 视觉特征提取 :视觉编码器对输入图像提取特征,经
Perceiver Resampler处理为适配格式。 - 多模态序列输入:交错的视觉特征(处理后)与文本序列一同输入语言模型。
- 渐进式多模态融合 :语言模型每一层通过
GATED XATTN-DENSE,逐层将视觉特征与文本特征交叉融合。 - 自回归文本生成:基于融合后的多模态特征,模型逐词生成文本输出,完成多模态推理任务。
四、技术创新:为何Flamingo如此独特?
- 交错输入的天然适配 :以
<image>与文本交错的形式,天然模拟人类"看-读-想-写"的多模态交互习惯。 - 混合训练的效率与效果平衡:冻结预训练模块节省算力,仅训练桥接模块聚焦多模态融合,兼顾效率与效果。
- 门控交叉注意力的精细控制:通过"门控"灵活调节视觉信息的融入程度,既避免视觉噪声干扰,又保证关键视觉信息的有效传递。
五、应用场景:从感知到创作的多模态能力
Flamingo可应用于:
- 图像描述(Image Captioning):生成精准且富有细节的图像描述。
- 视觉问答(VQA):结合图像和问题,生成自然语言回答。
- 多模态对话:支持"图像+文本"的多轮交互,如智能助手理解用户的视觉+文本指令。
- 创意生成:基于图像触发文本创作(如故事、诗歌),拓展多模态创作边界。
总结
Flamingo以"交错多模态输入-自由文本输出"的设计,"预训练冻结+新模块训练"的策略,以及"门控交叉注意力"的精细融合机制,为多模态大模型的发展提供了极具启发性的范式。它不仅是技术的创新,更是"视觉与文本交响"的生动实践,未来在人机交互、内容创作、智能助手等领域将释放巨大潜力。