一、Llama.cpp框架简介

llama.cpp是由Georgi Gerganov创建的轻量级推理引擎,它是基于C/C++语言编码实现的LLM框架,支持大模型的训练和推理,专注于在本地硬件环境(比如个人电脑、树莓派等)上高效运行LLM模型。
llama.cpp框架目前支持的大模型有LLaMA系列、Qwen系列、Gemma系列、LLaVA系列等。
llama.cpp框架支持运行在CPU、GPU、 嵌入式等设备上,对消费级硬件和资源受限的边缘计算设备支持较好。
由于llama.cpp的实现代码以C/C++为主,因此它也具备跨平台兼容性(支持Windows、Linux、macOS等平台),并支持Python编码调用,比如llama-cpp-python第三方库。
Georgi Gerganov本人是AI开源社区知名的开发者,专注于高性能机器学习框架的C/C++编程实现,在Georgi Gerganov创建llama.cpp项目之前,此前已经开发出了以极简主义和高性能而闻名的whisper.cpp框架和专为机器学习优化的张量计算库ggml。
2023年初,Meta公司发布了LLaMA模型,但原版LLaMA模型的推理运行需要消耗大量计算资源,且依赖Pytorch和GPU算力,此时Georgi Gerganov开始意识到他可以将LLaMA模型移植到基于C语言开发的ggml张量库中,并实现基于CPU处理器本地运行大模型的推理和训练过程,由此导致业界闻名的llama.cpp框架的诞生。
llama.cpp的应用场景:
边缘人工智能:在计算能力有限的设备(例如智能手机、物联网设备)上部署 LLaMA 或类似 GPT 的模型。
模型研究:研究人员可以快速迭代量化模型,而无需担心资源密集型硬件设置。
离线推理:将人工智能服务部署在本地离线环境,不与云服务器交互,用来确保数据隐私和商业机密。
二、关于GGUF模型文件
llama.cpp框架不能直接使用PyTorch或TensorFlow生成的原始模型文件,它主要使用的文件格式是GGUF(GGML Unified Format),用于存储LLM大模型的权重和配置。
llama.cpp早期采用的是GGML文件格式, 后来改为使用GGUF文件格式。
在GGML/GGUF出现之前,最早期的机器学习模型文件格式主要侧重于存储未量化的模型,并确保不同的AI框架和硬件平台之间的兼容性。
最早期的机器学习模型文件格式有".pb"文件格式(应用于TensorFlow框架),".pt"或".pth"文件格式(应用于PyTorch框架),虽然这些格式适用于较小的AI模型,但它们有很大的局限性,比如:
1.不支持量化,这些模型存储了全精度(32位浮点)权重,导致模型文件过大。
2.内存使用率高,由于模型未压缩,它们需要大量内存来存储和推理,在消费级硬件上部署时占用了过高的内存。
引入GGML文件格式(通用GPT模型语言)是为了满足LLaMA等大型LLM模型的量化和压缩需求。GGML允许以较低精度的格式存储模型权重,例如8位整型(INT8)或4位整型(INT4),从而大大减少了模型的大小和内存占用。
GGUF是在GGML格式的基础上做的优化,GGUF包含了更多的元数据,并且设计上更易于扩展和使用,GGUF格式将权重、分词器和元数据等集成到一个高效的二进制文件中,该二进制文件加载速度快,可跨平台工作。

GGUF格式的核心特性:
硬件兼容性强:支持在消费级硬件(例如CPU)上运行LLM模型,无需昂贵的GPU配置。
内存占用低:通过量化显著减少内存占用,使大模型更易于部署。
支持自定义量化:通过选择量化级别来微调模型的性能和精度之间的平衡。
模型可扩展性强:GGUF能够存储和运行巨大规模的LLM模型(例如LLaMA 2),而不会遇到GGML格式下的可扩展性问题。
易于部署:GGUF可以部署在云服务器、边缘设备和移动端设备上,即使在算力较低的硬件设备上也能高效完成推理过程。
丰富的元数据信息:GGUF能够存储LLM模型的更广泛的元数据信息,这些元数据包括模型的层级结构、配置参数和量化级别等。

GGUF模型文件的获取和转换
开发者可以使用llama.cpp提供的convert.py脚本,将原始的PyTorch模型转换为GGUF格式,命令示例:
cpp
python convert.py path/to/model --outtype gguf --outfile model.ggufllama.cpp中加载GGUF文件的代码实现:
cpp
struct gguf_context * gguf_init_from_file(const char * fname, struct gguf_init_params params) {
FILE * file = ggml_fopen(fname, "rb");
if (!file) {
GGML_LOG_ERROR("%s: failed to open GGUF file '%s'\n", __func__, fname);
return nullptr;
}
struct gguf_context * result = gguf_init_from_file_impl(file, params);
fclose(file);
return result;
}
cpp
struct gguf_context {
uint32_t version = GGUF_VERSION;
std::vector<struct gguf_kv> kv;
std::vector<struct gguf_tensor_info> info;
size_t alignment = GGUF_DEFAULT_ALIGNMENT;
// offset of `data` from beginning of file
size_t offset = 0;
// size of `data` in bytes
size_t size = 0;
void * data = nullptr;
};用户可以从Hugging Face Hub下载预转换的GGUF模型:
三、LLM模型的量化
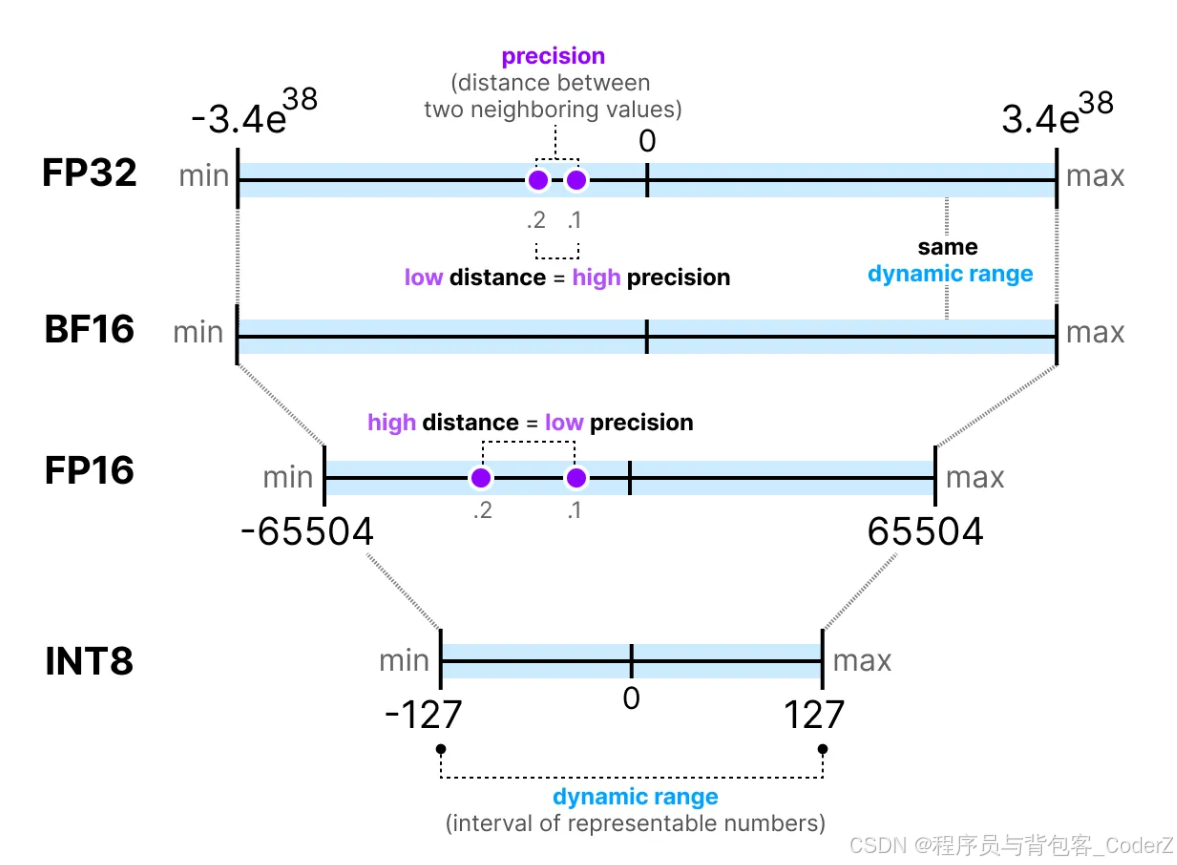
**量化(Quantization)**就是通过使用较低精度的整型格式来压缩LLM模型文件的大小,比如将LLM模型参数(比如权重、偏差等)的精度从32位浮点型(FP32)等较高精度格式降低到8位整型(INT8)或4位整型(INT4)等较低精度的过程,这大大减少了模型的存储大小和推理计算时的内存负载。
量化技术的目的就是在适当降低模型的精度后,达到既没有显著降低模型的效果,又能大幅度优化模型的内存占用。
量化技术对于在内存资源有限的边缘硬件设备上部署LLM模型至关重要。
1.量化的分类
(1).按量化等级分类:
Q8级别量化:
8位量化 (INT8),保留了LLM模型更多的原始精度,但模型文件较大,且内存占用仍然很高,适合应用在对话生成等通用场景。
Q4级别量化:
4位量化 (INT4),最节省内存的量化方案,可显著提高内存和推理速度,但会降低模型的精度,适合应用在关键字提取、语义搜索等专用场景。
(2).按量化方法分类:
简单量化:
简单量化统一降低所有参数的精度。
K均值量化:
K均值量化是通过划分聚类的方式来实现量化。

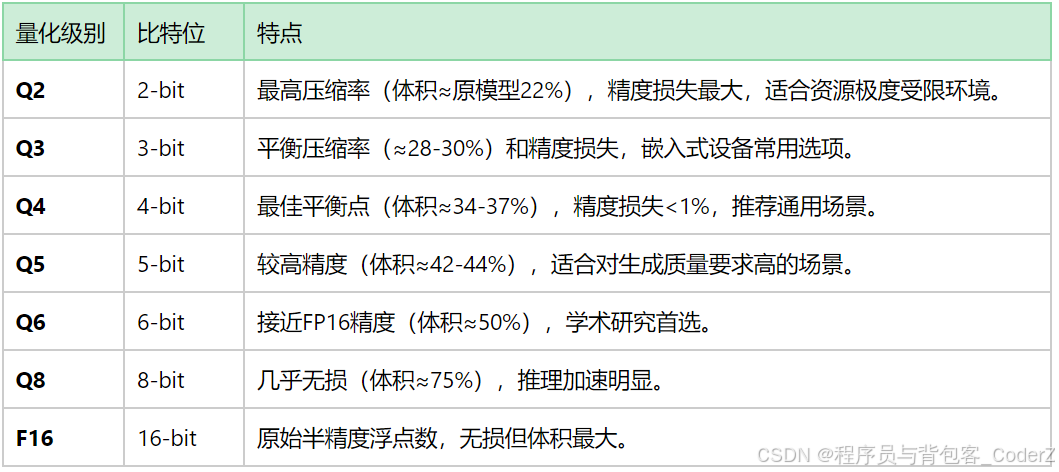
llama.cpp支持多种量化级别,常用的级别如下:
Q8_0: 8位整型量化,文件较大,质量接近FP16,但运行速度较快。
Q5_K_M, Q5_K_S: 5位K均值量化,平衡了模型文件大小、运行速度和精度,折衷方案。
Q4_K_M, Q4_K_S: 5位K均值量化,模型文件更小,内存占用更低,但精度有所下降,Q4_K_M是许多用户首选的入门级别,因为它能在消费级硬件上较好地运行。
Q2_K: 2位K均值量化,文件最小,运行速度最快,但精度损失较大。
量化的应用举例:
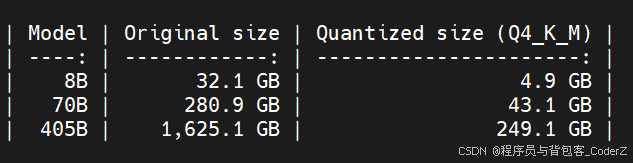
基于LLaMA-7B模型测试发现,Q4_K_M级别相比FP16级别,模型体积减小了63%,推理速度提升了2.5倍,但LLaMA-7B模型的精度损失仅0.8%。
llama.cpp量化级别中的"Q#_K_M"的含义:
*Q:代表量化。
*#:表示量化过程中使用的位数。
*K:表示在量化中使用 k 均值聚类。
*M:表示量化后的模型大小。S=小,M=中,L=大。

2.量化命令实战
用户可以通过llama.cpp的quantize工具进行模型的量化。
参考示例:llama.cpp/tools/quantize
cpp
./llama-quantize ./models/ggml-vocab-deepseek-llm.gguf Q4_K_M量化过程打印:
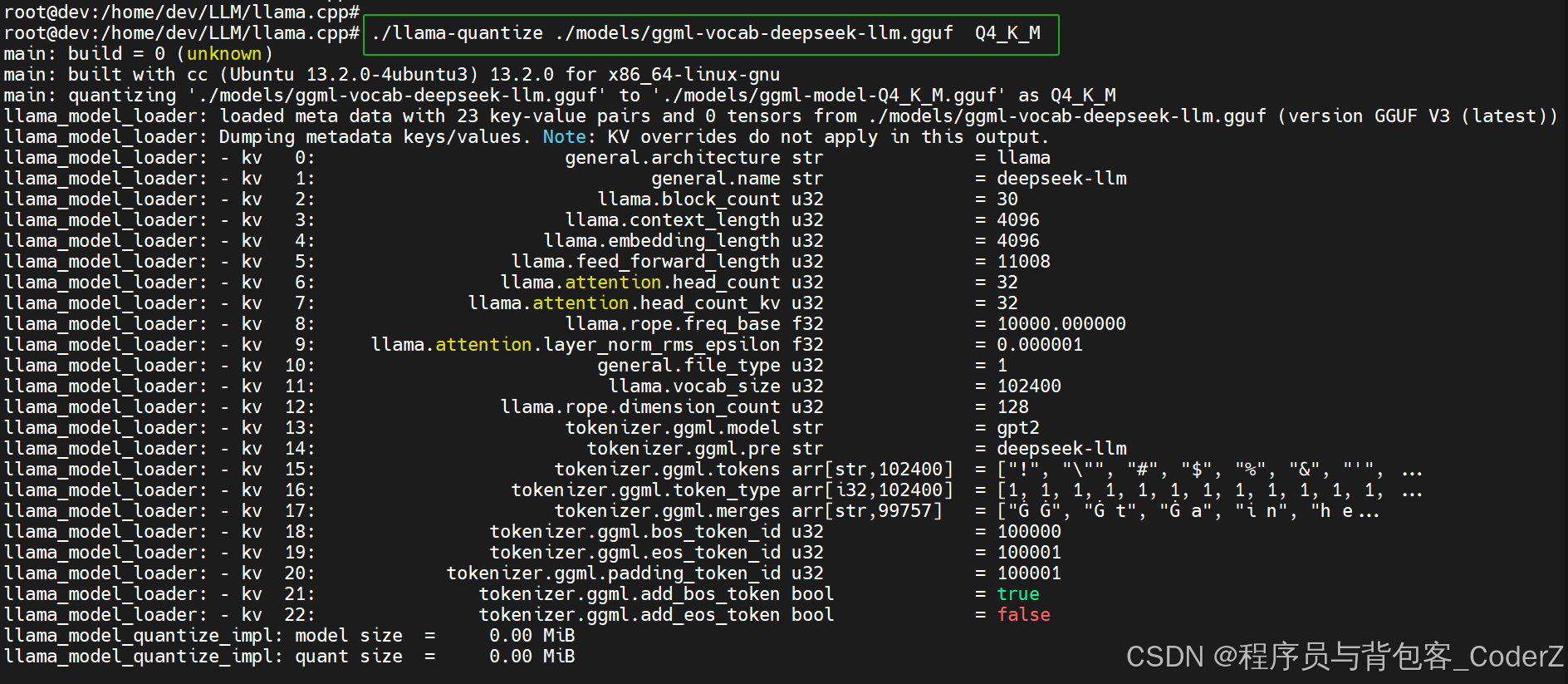
四、llama.cpp命令行
llama.cpp的核心命令行工具包括模型推理工具(main) 和量化工具(quantize),main是llama.cpp的核心命令行工具,用于加载GGUF模型并执行推理任务。基本语法为:
cpp
./main [选项] -m <模型路径>常用命令行参数如下:
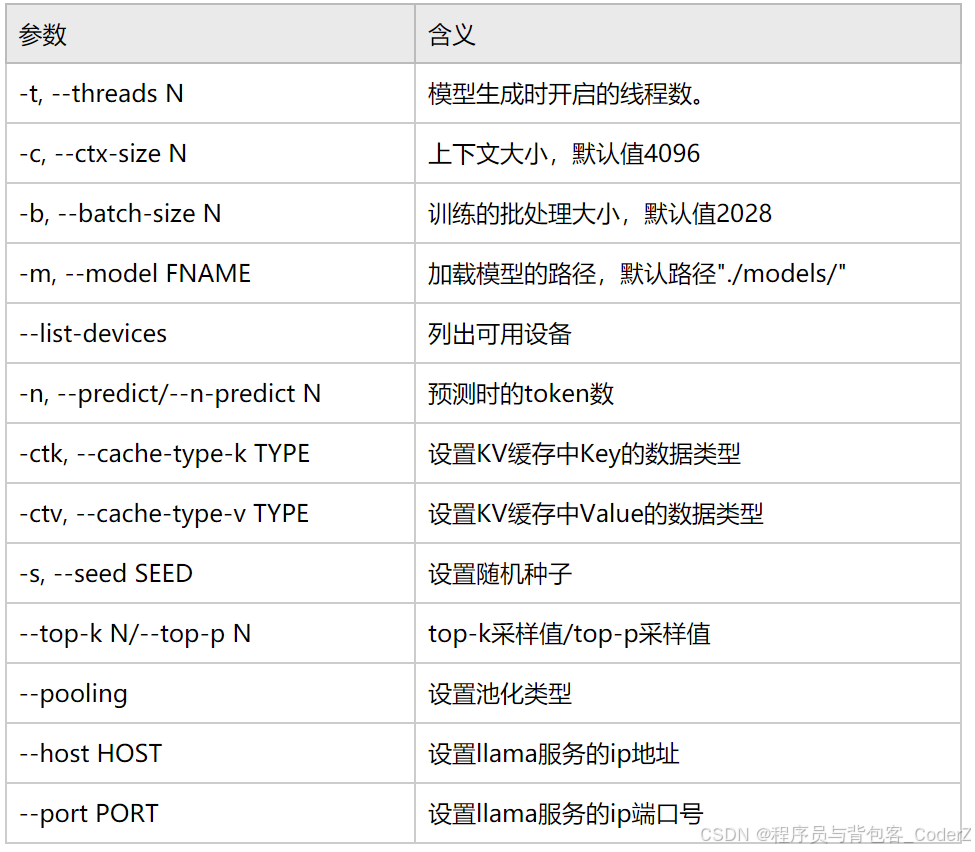
全量的命令行参数参考官方文档: https://github.com/ggml-org/llama.cpp/blob/master/tools/server/README.md
五、llama.cpp本地部署实战
step.01:从github仓库下载llama.cpp项目源码
cpp
git clone https://github.com/ggml-org/llama.cppstep.02:编译llama.cpp项目源码
cpp
cmake -B build
cmake --build build --config Release
step.03:安装HuggingFace_Hub Python环境,推荐使用env虚拟环境安装。
cpp
python3 -m venv .env
source .env/bin/activate
pip install huggingface_hub
安装完成以后可以使用"hf"命令进行验证:
step.04:从HuggingFace_Hub下载大模型到本地,以阿里的Qwen大模型为例。
cpp
https://huggingface.co/Qwen/Qwen3-0.6B-GGUF/
step.05:使用llama.cpp加载Qwen3大模型,并生成Restful服务。
bash
./llama-server -m /home/dev/LLM/llama.cpp/models/Qwen3-0.6B-Q8_0.gguf --host 0.0.0.0 --port 8080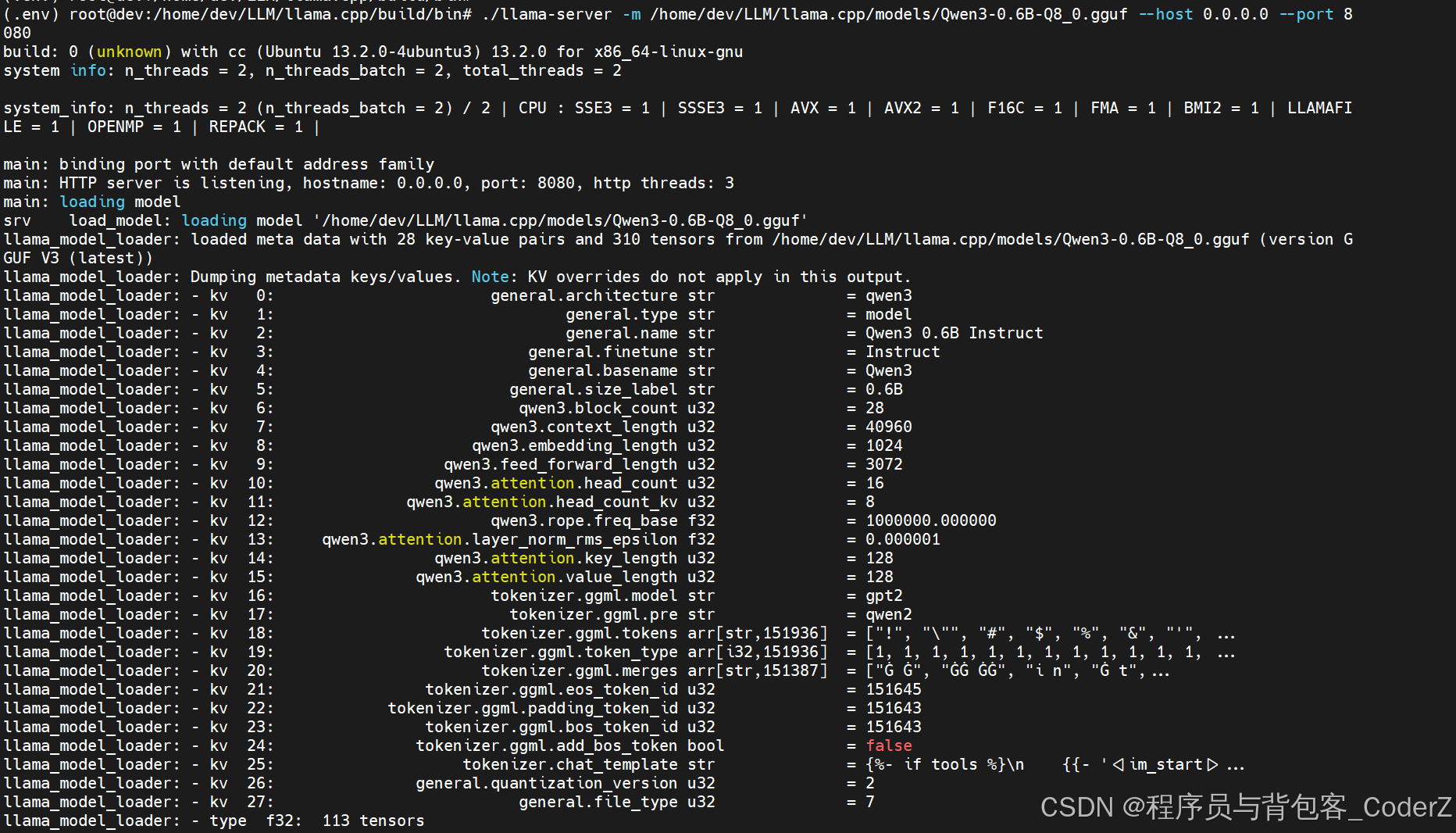
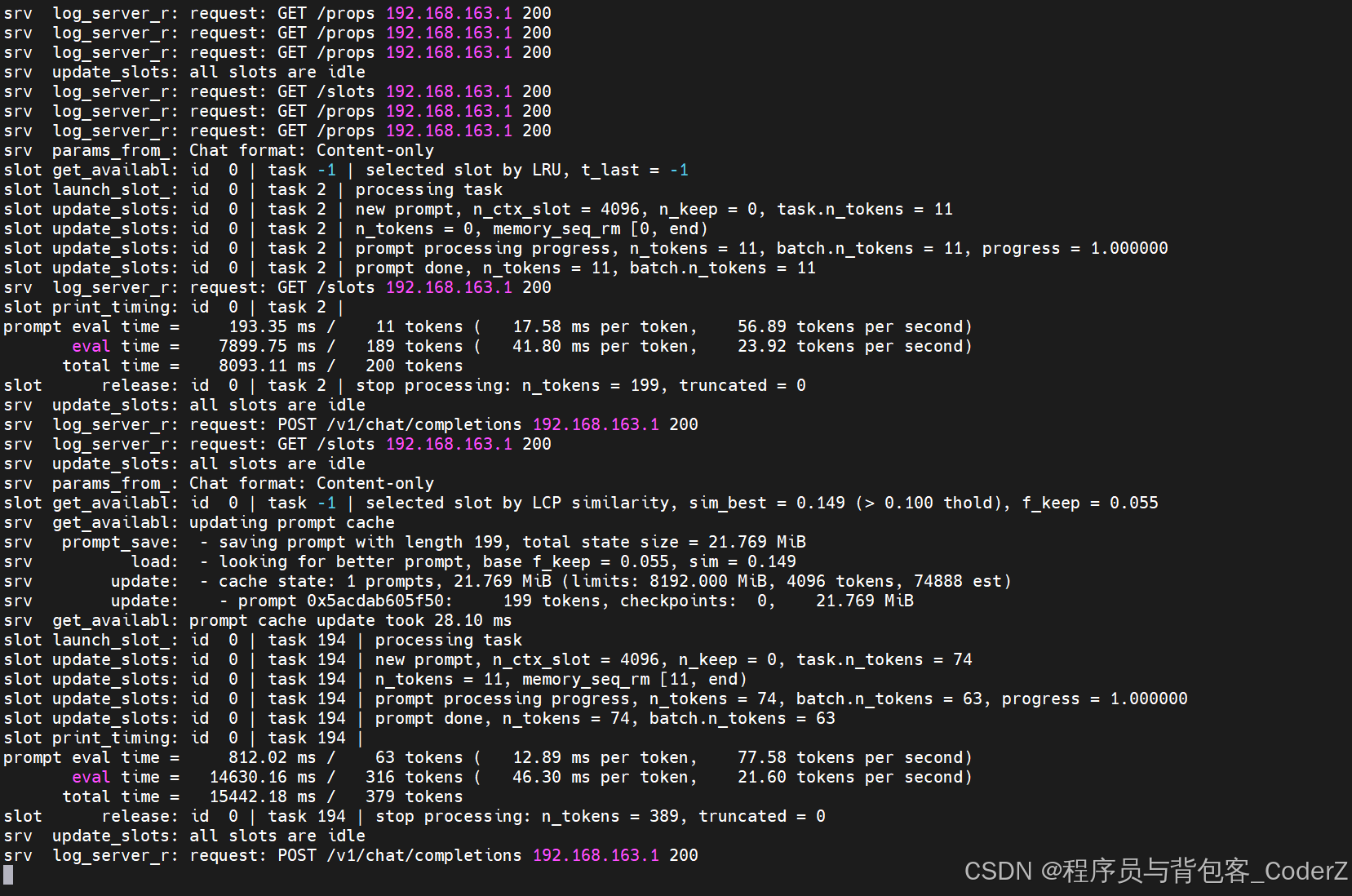
Restful服务的后台日志打印:
访问LLM对应的Restful服务:
cpp
http://127.0.0.1:8080/
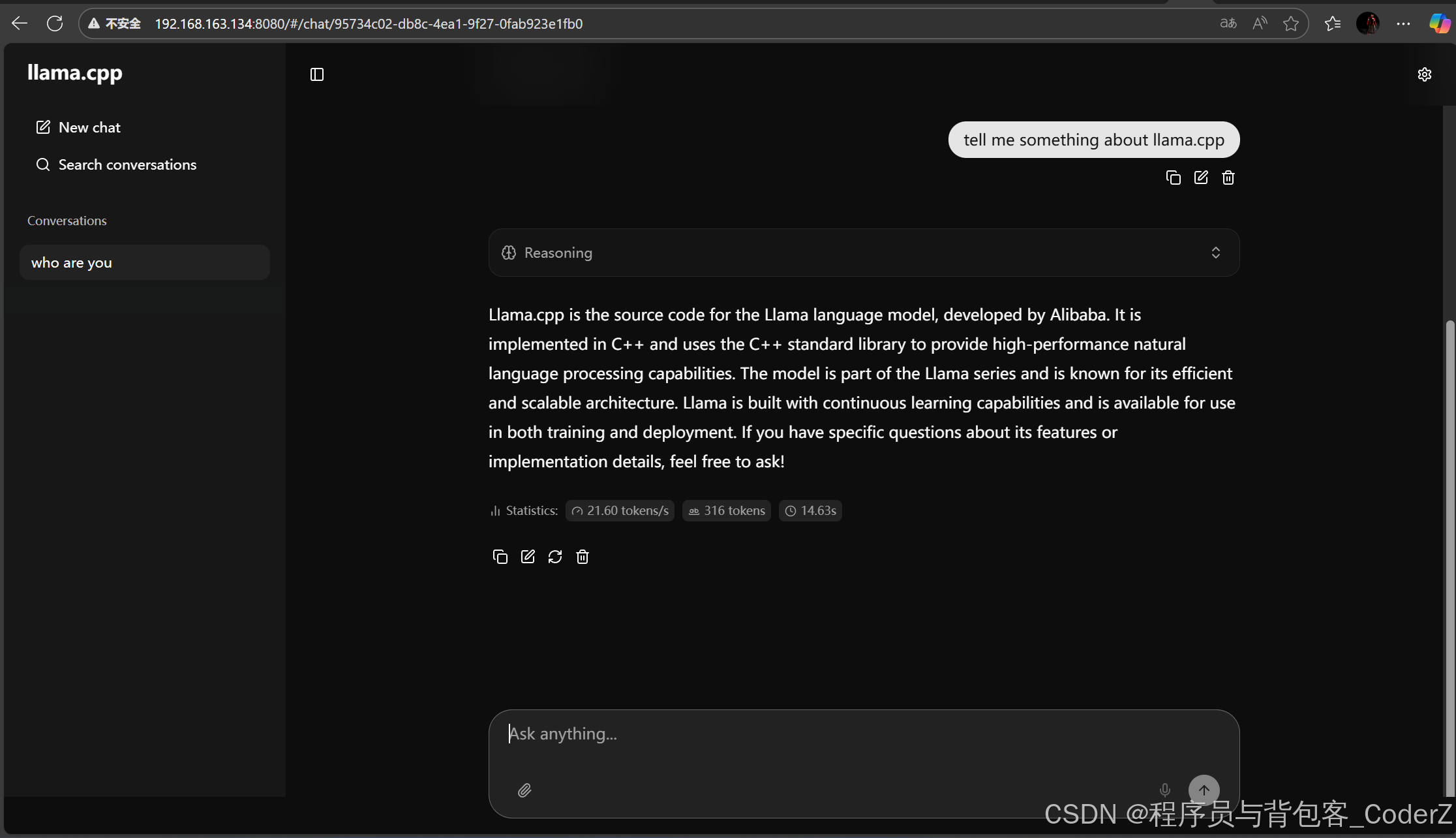
也可以不生成Restful服务,直接用llama.cpp命令行与模型进行聊天:
bash
./llama-cli -m /home/dev/LLM/llama.cpp/models/Qwen3-0.6B-Q8_0.gguf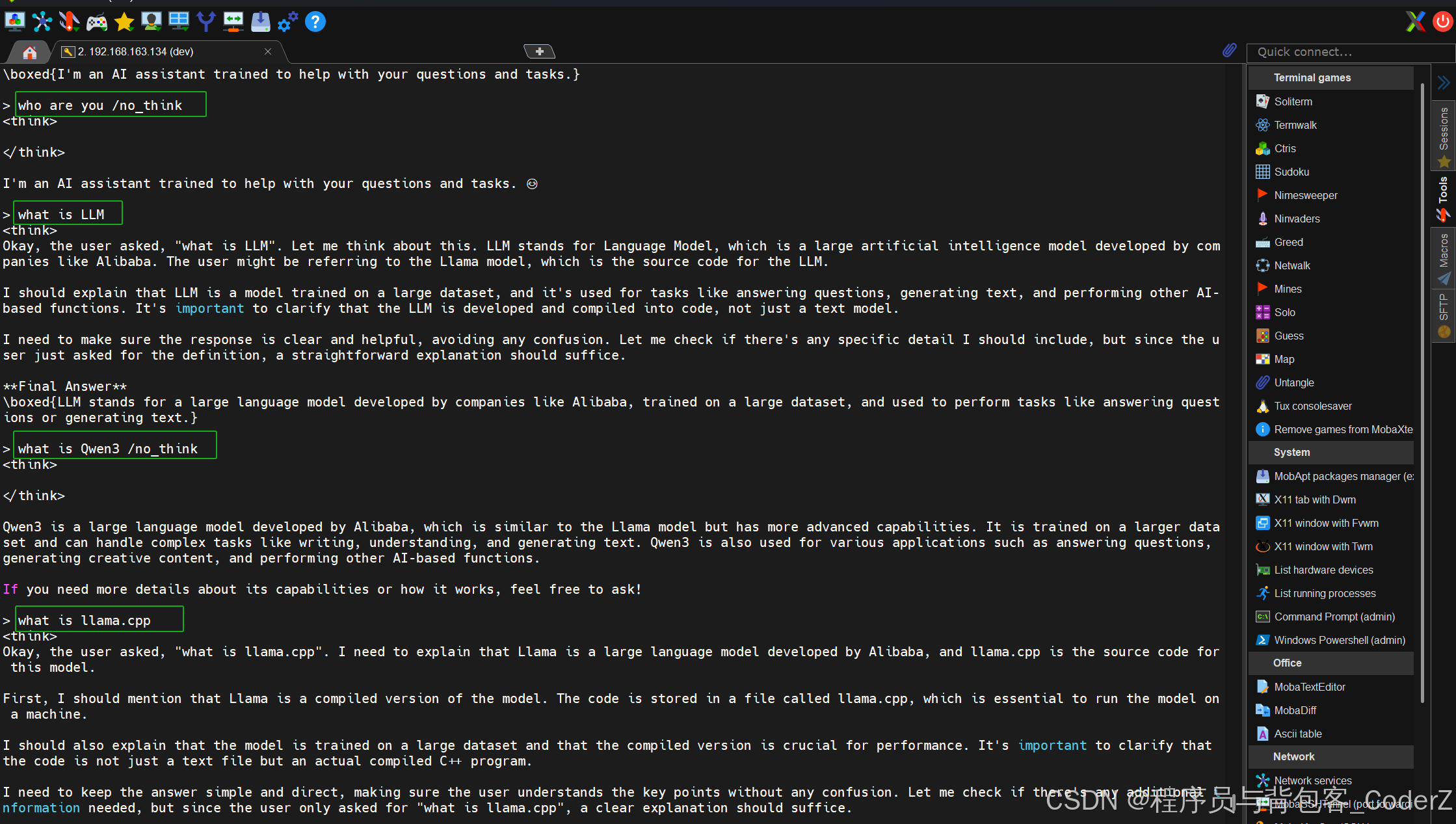
六、llama.cpp Python编码实战
Python编码之前,需要先安装依赖库"llama-cpp-python":
bash
pip install llama-cpp-pythonDemo1:
python
from llama_cpp import Llama
# Load the model
llm = Llama(
model_path="/home/dev/LLM/llama.cpp/models/Qwen3-0.6B-Q8_0.gguf",
n_ctx=512,
n_threads=4
)
# Provide a prompt
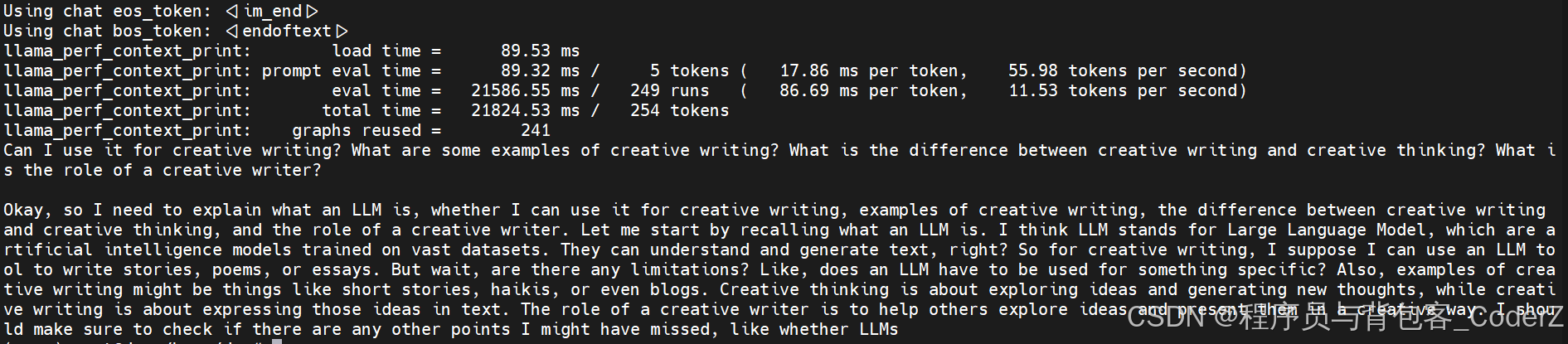
prompt = "What is LLM?"
# Generate the response
output = llm(prompt, max_tokens=250)
# Print the response
print(output["choices"][0]["text"].strip())运行结果:
七、llama.cpp C++编码实战
Demo2:
cpp
#include "arg.h"
#include "common.h"
#include "log.h"
#include "llama.h"
#include <algorithm>
#include <cstdio>
#include <string>
#include <vector>
int main(int argc, char ** argv) {
common_params params;
params.model.path = "/home/dev/LLM/llama.cpp/models/Qwen3-0.6B-Q8_0.gguf";
params.prompt = "What is LLM?";
params.n_predict = 128;
common_init();
// number of parallel batches
int n_parallel = params.n_parallel;
// total length of the sequences including the prompt
int n_predict = params.n_predict;
// init LLM
llama_backend_init();
llama_numa_init(params.numa);
// initialize the model
llama_model_params model_params = common_model_params_to_llama(params);
llama_model *model = llama_model_load_from_file(params.model.path.c_str(), model_params);
if (model == NULL) {
LOG_ERR("%s: error: unable to load model\n" , __func__);
return 1;
}
const llama_vocab * vocab = llama_model_get_vocab(model);
// tokenize the prompt
std::vector<llama_token> tokens_list;
tokens_list = common_tokenize(vocab, params.prompt, true);
const int n_kv_req = tokens_list.size() + (n_predict - tokens_list.size())*n_parallel;
// initialize the context
llama_context_params ctx_params = common_context_params_to_llama(params);
ctx_params.n_ctx = n_kv_req;
ctx_params.n_batch = std::max(n_predict, n_parallel);
llama_context * ctx = llama_init_from_model(model, ctx_params);
auto sparams = llama_sampler_chain_default_params();
sparams.no_perf = false;
llama_sampler * smpl = llama_sampler_chain_init(sparams);
llama_sampler_chain_add(smpl,
llama_sampler_init_top_k(params.sampling.top_k));
llama_sampler_chain_add(smpl,
llama_sampler_init_top_p(params.sampling.top_p, params.sampling.min_keep));
llama_sampler_chain_add(smpl,
llama_sampler_init_temp (params.sampling.temp));
llama_sampler_chain_add(smpl,
llama_sampler_init_dist (params.sampling.seed));
if (ctx == NULL) {
LOG_ERR("%s: error: failed to create the llama_context\n" , __func__);
return 1;
}
const int n_ctx = llama_n_ctx(ctx);
LOG_INF("\n%s: n_predict = %d, \
n_ctx = %d, \
n_batch = %u, \
n_parallel = %d, \
n_kv_req = %d\n",
__func__, n_predict, n_ctx, ctx_params.n_batch, n_parallel, n_kv_req);
// make sure the KV cache is big enough to hold all the prompt and generated tokens
if (n_kv_req > n_ctx) {
LOG_ERR("the required KV cache size is not big enough\n");
return 1;
}
// print the prompt token-by-token
LOG("\n");
for (auto id : tokens_list) {
LOG("%s", common_token_to_piece(ctx, id).c_str());
}
// create a llama_batch
// we use this object to submit token data for decoding
llama_batch batch = llama_batch_init(std::max(tokens_list.size(),
(size_t) n_parallel),
0, n_parallel);
std::vector<llama_seq_id> seq_ids(n_parallel, 0);
for (int32_t i = 0; i < n_parallel; ++i) {
seq_ids[i] = i;
}
// evaluate the initial prompt
for (size_t i = 0; i < tokens_list.size(); ++i) {
common_batch_add(batch, tokens_list[i], i, seq_ids, false);
}
GGML_ASSERT(batch.n_tokens == (int) tokens_list.size());
if (llama_model_has_encoder(model)) {
if (llama_encode(ctx, batch)) {
LOG_ERR("%s : failed to eval\n", __func__);
return 1;
}
llama_token decoder_start_token_id = llama_model_decoder_start_token(model);
if (decoder_start_token_id == LLAMA_TOKEN_NULL) {
decoder_start_token_id = llama_vocab_bos(vocab);
}
common_batch_clear(batch);
common_batch_add(batch, decoder_start_token_id, 0, seq_ids, false);
}
// llama_decode will output logits only for the last token of the prompt
batch.logits[batch.n_tokens - 1] = true;
if (llama_decode(ctx, batch) != 0) {
LOG_ERR("%s: llama_decode() failed\n", __func__);
return 1;
}
if (n_parallel > 1) {
LOG("\n\n%s: generating %d sequences ...\n", __func__, n_parallel);
}
// main loop
// we will store the parallel decoded sequences in this vector
std::vector<std::string> streams(n_parallel);
std::vector<int32_t> i_batch(n_parallel, batch.n_tokens - 1);
int n_cur = batch.n_tokens;
int n_decode = 0;
const auto t_main_start = ggml_time_us();
while (n_cur <= n_predict) {
// prepare the next batch
common_batch_clear(batch);
// sample the next token for each parallel sequence / stream
for (int32_t i = 0; i < n_parallel; ++i) {
if (i_batch[i] < 0) {
// the stream has already finished
continue;
}
const llama_token new_token_id = llama_sampler_sample(smpl, ctx, i_batch[i]);
if (llama_vocab_is_eog(vocab, new_token_id) || n_cur == n_predict) {
i_batch[i] = -1;
LOG("\n");
if (n_parallel > 1) {
LOG_INF("%s: stream %d finished at n_cur = %d", __func__, i, n_cur);
}
continue;
}
// if there is only one stream, we print immediately to stdout
if (n_parallel == 1) {
LOG("%s", common_token_to_piece(ctx, new_token_id).c_str());
}
streams[i] += common_token_to_piece(ctx, new_token_id);
i_batch[i] = batch.n_tokens;
common_batch_add(batch, new_token_id, n_cur, { i }, true);
n_decode += 1;
}
if (batch.n_tokens == 0) {
break;
}
n_cur += 1;
if (llama_decode(ctx, batch)) {
LOG_ERR("%s : failed to eval, return code %d\n", __func__, 1);
return 1;
}
}
if (n_parallel > 1) {
LOG("\n");
for (int32_t i = 0; i < n_parallel; ++i) {
LOG("sequence %d:\n\n%s%s\n\n", i, params.prompt.c_str(), streams[i].c_str());
}
}
const auto t_main_end = ggml_time_us();
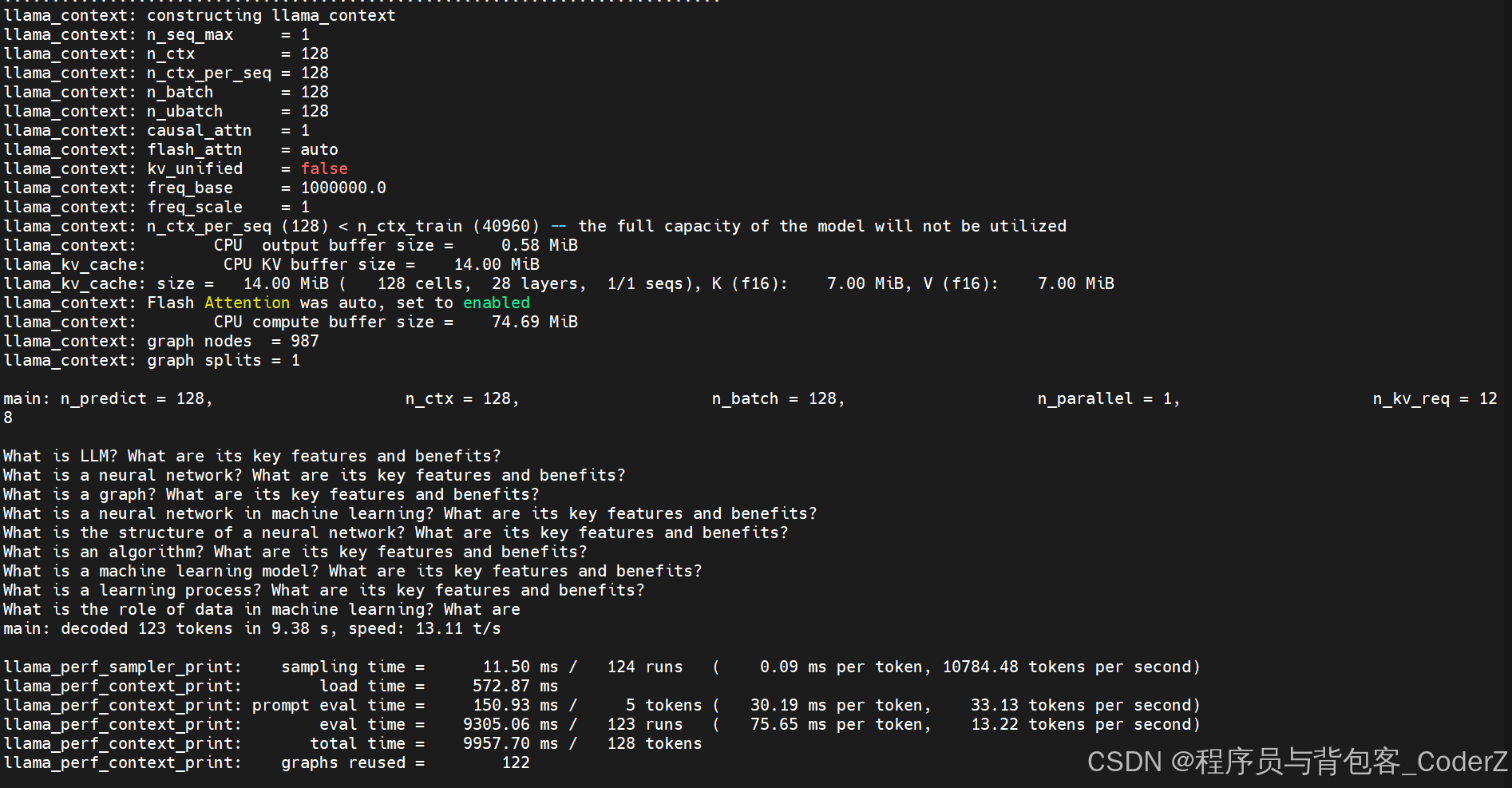
LOG_INF("%s: decoded %d tokens in %.2f s, speed: %.2f t/s\n",
__func__, n_decode, (t_main_end - t_main_start) / 1000000.0f,
n_decode / ((t_main_end - t_main_start) / 1000000.0f));
LOG("\n");
llama_perf_sampler_print(smpl);
llama_perf_context_print(ctx);
fprintf(stderr, "\n");
llama_batch_free(batch);
llama_sampler_free(smpl);
llama_free(ctx);
llama_model_free(model);
llama_backend_free();
return 0;
}运行结果:
参考阅读:
https://medium.com/@vimalkansal/understanding-the-gguf-format-a-comprehensive-guide-67de48848256
https://qwen.readthedocs.io/zh-cn/latest/run_locally/llama.cpp.html
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization