1.SCS 组件的出现的背景和作用
在分布式系统中,可能使用到的消息队列让人眼花缭乱,可能有使用(RabbitMq RroketMQ Kafka....),他们提供的客户端各不相同,使用的方式也让人眼花缭乱,此时就需要一个能够统一消息队列的客户端,通过更高级的抽象来实现更通用和更简单的集成不同的消息队列中间件,此时也就诞生了这个SCS 组件
2.SCS 集成srping Boot项目
我们在这个演示项目中所使用的Spring Boot版本为 2.7.18、SpringCloud Alibaba版本为 2021.0.6.0
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.6.0</version>
<type>pom</type>
<scope> import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.7.18</version>
<type>pom</type>
<scope> import</scope>
</dependency>
</dependencies>
</dependencyManagement>使用的SCS 组件版本为 3.2.10
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
<version>3.2.10</version>
</dependency>3.Yml 配置
scs 的使用难点主要就是在yml 的配置上,配置完成使用很方便
spring: cloud: function: definition: myTaskConsumer;ackConsumer #你注册的 Consumer 方法名 或者 Function 方法名 中间使用 ;分割 (生产者一般是动态发送消息 不需要注册) stream: binders: kafka-binder-1: # 绑定器名称 type: kafka # 消息队列的类型类型 environment: #绑定器环境配置 spring: kafka: bootstrap-servers: 172.22.134.135:9092 # kafka地址 可以设置多个 properties: security.protocol: PLAINTEXT # kafka协议 #rabbit-binde-1r: # type: rabbit # ... rabbitmq配置 # 全局生产者可靠性配置(推荐) binder: producer-properties: acks: all # 👈 生产者 ACK = all 所有副本同步完成才ack;ACK=1写入leader副本返回ack;ACK=0 生产者发送消息立马ack retries: 100 # 最大重试 当发送失败时(如网络抖动、Leader 切换),Producer 自动重试的最大次数。 retry.backoff.ms: 1000 #每次重试之间的等待时间(毫秒)。 enable-idempotence: true # 幂等生产者(防重复) bindings: myTaskConsumer-in-0: #命名规则 ${方法名}-${消费者:in/生产者:out}-${数字:不能与其他相同} destination: test-kraft # topic group: my-consumer-group #消费者组 binder: kafka-binder-1 # 绑定器 <--上面配置的绑定名称 consumer: # 消费者配置 autoStartup: true # 是否自动启动 concurrency: 1 #启动消费者实例数 (同属于一个消费者组) myTaskProducer-out-0: destination: test-kraft # topic binder: kafka-binder-1 # 绑定器 <--上面配置的绑定名称 producer: # 生产者配置 partitionCount: 1 # 应与目标 Topic 的实际分区数一致。 # - 若小于实际分区数:仅使用部分分区,浪费并行能力; # - 若大于实际分区数:发送时会因访问不存在的分区而失败! #使用消息头中的 headers的 partitionKey 作为 key进行分区 partition-key-expression: headers.partitionKey # 分区键(分区规则根据key进行hash落到分区 有助于落到指定分区顺序消费)
4.SpringCloud Stream 3.X新特性函数编程
4.1.编写 消费者
Mesage 的包别导错
import org.springframework.messaging.Message;
java
@Configuration
public class kafkaConsumer
{
@Bean
public Consumer<Message<String>> myTaskConsumer ()
{
System.out.println ("[初始化] myTaskConsumer Bean 已创建");
return message -> System.out.println ("[myTaskConsumer] 收到消息: " + message.getPayload ());
}
}4.2.编写动态生产者
java
@RestController
public class SendController
{
@Autowired
StreamBridge streamBridge;
@GetMapping ("/sendMyTaskProducer/{msg}")
public String send (@PathVariable ("msg") String msg)
{
//构建消息
Message<String> message = MessageBuilder.withPayload (msg)
.setHeader ("partitionKey", msg) // 添加分区键partitionKey 作为分区键
.build ();
//参数1为发送的通道名称(在yml中配置),参数2为消息
boolean myTaskProducer = streamBridge.send ("myTaskProducer-out-0", message);
System.out.println ("发送结果:" + myTaskProducer);
return "发送结果:" + myTaskProducer;
}
}5.进行测试
访问发送消息的接口,发送成功,并且消费者进行了消费
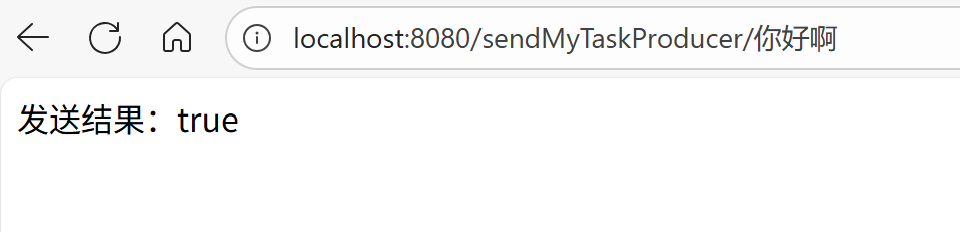
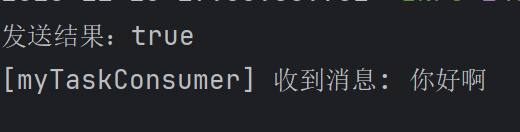
6.进行消费者手动ACK
消费者手动ACK 比自动ACK 要安全得多,默认scs 是实行自动ack,自动ack只要消息被投递到消费者,不论是否消费成功或者失败,都会被视为消费成功
6.1yml 配置
java
#========================================消费者ACK Kafka 专属配置========================================
#演示消费者ACK机制
ackConsumer-in-0: #命名规则 ${方法名}-${消费者:in/生产者:out}-${数字:不能与其他相同}
destination: topicOne # topic
group: ack-consumer-group #消费者组 (修改为独立的消费者组,避免与myTaskConsumer冲突)
binder: kafka-binder-1 # 绑定器 <--上面配置的绑定名称
consumer: # 消费者配置
autoStartup: true # 是否自动启动
concurrency: 1 #启动消费者实例数 (同属于一个消费者组)
ackProducer-out-0:
destination: topicOne # topic
binder: kafka-binder-1 # 绑定器 <--上面配置的绑定名称
producer: # 生产者配置
partitionCount: 1 # 应与目标 Topic 的实际分区数一致。
# - 若小于实际分区数:仅使用部分分区,浪费并行能力;
# - 若大于实际分区数:发送时会因访问不存在的分区而失败!
#使用消息头中的 headers的 partitionKey 作为 key进行分区
partition-key-expression: headers.partitionKey # 分区键(分区规则根据key进行hash落到分区 有助于落到指定分区顺序消费)
# Kafka 专属配置
kafka:
bindings:
ackConsumer-in-0: # 👈指定哪个消费者使用ACK
consumer:
ack-mode: MANUAL # 👈 关键!手动 ACK 模式
#RECORD 每条消息处理完自动提交 offset(默认) 简单场景
#BATCH 批量提交(一批 poll 的消息处理完后提交) 默认行为(等价于 auto-commit=true)
#TIME 定时提交 较少用
#COUNT 每 N 条提交一次 较少用
#MANUAL 手动调用 acknowledge() 才提交 ✅ 需要精确控制(推荐)
#MANUAL_IMMEDIATE 手动调用立即提交(不等批次) 高可靠性要求6.2编写消费者
java
@Bean
public Consumer<Message<String>> ackConsumer(){
System.out.println ("[初始化] ackConsumer Bean 已创建");
return message -> {
System.out.println ("[ackConsumer] ========== 开始处理消息 ==========");
System.out.println ("[ackConsumer] 消息内容: " + message.getPayload());
System.out.println ("[ackConsumer] 消息Headers: " + message.getHeaders());
//获取Acknowledgment
Acknowledgment ack = message.getHeaders ()
.get (KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (ack != null) {
//进行手动ack
ack.acknowledge ();
System.out.println ("[ackConsumer] ✅ 已手动确认消息");
} else {
System.out.println ("[ackConsumer] ⚠️ 警告: Acknowledgment为null,无法手动确认");
}
System.out.println ("[ackConsumer] ========== 消息处理完成 ==========\n");
};
}6.3编写生产者
java
@GetMapping ("/sendAckProducer/{msg}")
public String send2 (@PathVariable ("msg") String msg)
{
//构建消息
Message<String> message = MessageBuilder.withPayload (msg)
.setHeader ("partitionKey", msg) // 添加分区键partitionKey 作为分区键
.build ();
//参数1为发送的通道名称(在yml中配置),参数2为消息
boolean ackProducer = streamBridge.send ("ackProducer-out-0", message);
System.out.println ("发送结果:" + ackProducer);
return "发送结果:" + ackProducer;
}6.4测试结果
