
1.理解训练和推理
学习AI 模型是需要理解"训练"和推理的,它们不仅是人工智能(尤其是机器学习和深度学习)中最基础、最核心的两个概念,更是贯穿整个AI系统生命周期的骨架性知识。
1.1生活类比理解
你把AI想象成一个小孩子,你在教它识别水果:
- 训练阶段:你拿出很多苹果和香蕉的照片,每张都告诉他:"这是苹果""这是香蕉"。孩子反复看、反复记,慢慢总结出规律------红红圆圆的是苹果,黄黄弯弯的是香蕉。
- 推理阶段 :有一天你给他一张新照片(他从没见过),问他:"这是什么?"他根据之前学到的经验,自信地说:"是苹果!"------这就是他在"推理"。
✅ 核心区别:
训练 = 学习知识 (需要老师、大量例子)
推理 = 运用知识(独立判断新问题)
1.2机器视角理解
AI 模型其实是一个数学函数,比如:
python
output = f(input; θ)其中 θ(theta)代表模型内部的参数(比如神经网络中的权重)。
- 训练的目标 :找到一组最好的
θ,让这个函数在已知数据上预测得尽可能准。- 方法:不断试错 → 算误差 → 调整
θ→ 再试......直到误差最小。
- 方法:不断试错 → 算误差 → 调整
- 推理的过程 :把训练好的
θ固定下来,输入新数据,直接算出结果。- 不再调整
θ,只做一次计算。
- 不再调整
1.3技术流程理解
- 🔧 训练(Training)详细流程:
- 准备数据:收集并标注大量样本(如 100 万张带标签的图片)
- 定义模型结构:选择神经网络类型(CNN、Transformer 等)。
- 前向传播:输入数据 → 模型计算 → 得到预测值。
- 计算损失:用损失函数(如交叉熵)衡量预测与真实标签的差距。
- 反向传播:利用链式法则计算每个参数对损失的"责任"(梯度)。
- 参数更新:用优化器(如 Adam)按梯度方向微调参数 θ。
- 重复迭代:遍历整个数据集多次(称为"epoch"),直到模型收敛。
💡 这个过程通常在 GPU 集群上跑几天甚至几周。
- 🚀 推理(Inference)详细流程:
- 加载训练好的模型:包含固定的参数 θ。
- 输入新数据:比如用户上传的一张照片。
- 前向计算:数据流经模型各层,输出预测结果(如"猫,置信度 92%")。
⏱️ 推理通常只需几十毫秒,可在手机、服务器甚至智能摄像头中实时运行。
一句话:训练是"创造智能"的过程,推理是"释放智能"的时刻。
没有高质量的训练,推理就是无源之水;没有高效的推理,训练成果就无法落地应用。二者相辅相成,共同构成 AI 系统的核心生命周期。
2.使用代码进行推理(或者预测)
这里使用VSCode IDE 工具,因为前面环境部署的时候,YOLOv8 的源码在 Ubuntu机器上。所以给VSCode 安装 Remote插件,使用插件打开 YOLOv8 源码代码项目:
在根目录下创建一个文件: mypredict.py
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 我想用yolov8n.pt模型进行预测
model.predict(
# 我要预测 ultralytics/assets 文件夹下所有的图片,就是你要预测的目标
source="ultralytics/assets",
# 下面两个参数是对预测提一些额外的要求
save=True, # 保存预测结果
show=True, # 是否立刻显示结果
)项目根目录下并没有这个文件 yolov8n.pt , 脚本运行后会自动下载这个文件到根目录
打开终端,切换虚拟环境,然后执行这个脚本:
shell
conda activate yolov8 # 这个环境上个章节已经建好了
cd ~/yolo/ultralytics-8.3.229输出:

- 因为本地没有模型文件,所以它到 geithub上去下载了
ultralytics/assets目录下有两个图片文件,就是我们要预测的文件
从运行的结果看,图1预测(或者叫识别,或者叫推理),图片大小事 648*480有4个人,1辆车,一个标有 stop 的标志,耗时 17.1 毫秒
图二:284*640,两个人,1个领带,耗时 17.4毫秒


可以尝试自己找一些图片或者视频或者摄像头进行预测。只需要将 source参数更改一下,可以是一个文件夹,可以是一个单个文件。
如果是摄像头,将值改为 0 即可。但是使用摄像头的话,不会释放内存,到了一个极限,程序会终止释放内存。最后我会用一个脚本来解决这个问题。
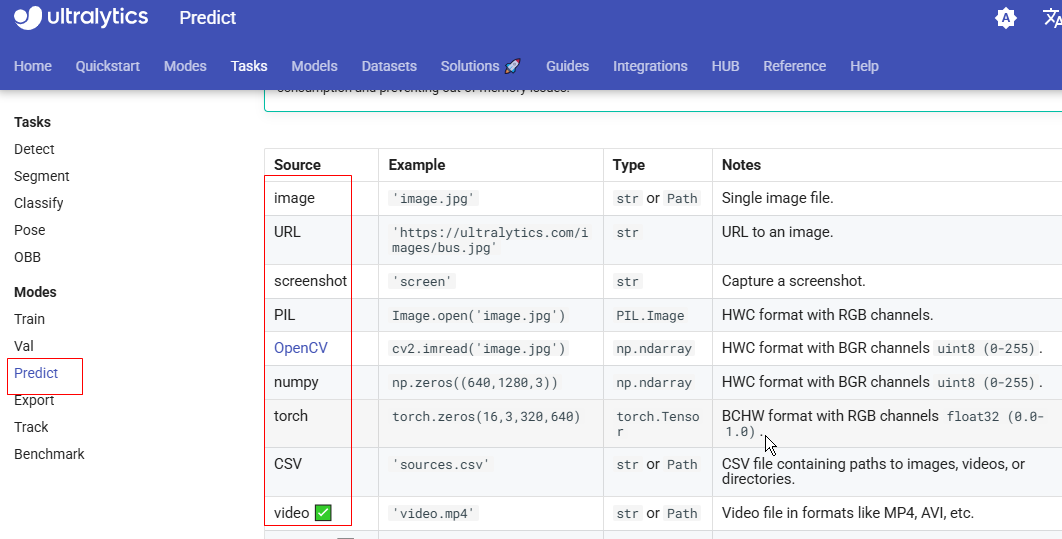
3.预测目标
官方文档中给出了所有可预测的目标:https://docs.ultralytics.com/modes/predict/#inference-sources
4.模型
上面代码中,使用的的是 yolov8n.pt这个模型,对模型的初步认识:
- 模型的任务类型。
yolo支持5中类型: 目标检测(yolo11n.pt),旋转目标检测(yolo11n.pt),姿态估计(yolo11n-pose.pt),实例分割(yolo11n-seg.pt),图像分类(yolo11n-cls.pt)
可以使用代码来检测你加载的模型的任务类型:
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
print(model.task) # 输出 detect- 模型可预测的类型:
yolo11n模型可以预测80中类型的目标.
你可以打开摄像头,然后将物品放入摄像头实现内,它就会预测出来是啥。也可以使用代码来输出可以预测的类型
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
print(model.names) # 输出 {0: "person", 1:"bicycle", 2:"car" ...}- 模型的大小
yolo11n.pt 中的n是
nano很小的意思yolo11s.pt 中的n是
small小yolo11m.pt 中的n是
medium中yolo11l.pt 中的n是
large大yolo11x.pt 中的n是
extra-large超大
到这里 https://github.com/ultralytics/assets/releases 可以下载各种尺寸的模型,这里是官方提供的模型仓库:
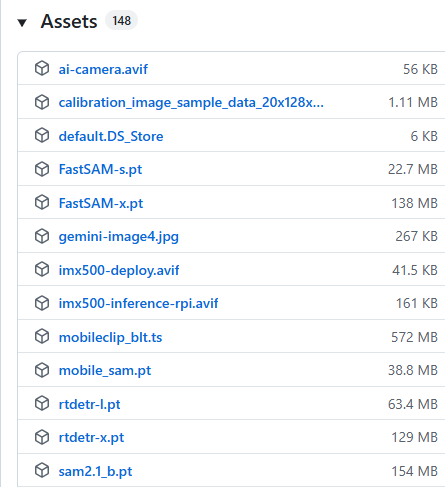
将他们下载到源码目录,加载后可以使用代码来输出它的参数:
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
# 参数会很多
print(sum(p.numel() for p in model.parameters()))参数越多,推理越准确,同时耗费的推理和训练的时间就越长。
下图中看到 v8 和 v11 支持所有5中类型
5.预测选项
前面代码进行预测的时候:
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt') # 我想用yolov8n.pt模型进行预测
model.predict(
# 我要预测 ultralytics/assets 文件夹下所有的图片,就是你要预测的目标
source="ultralytics/assets",
# 下面两个参数是对预测提一些额外的要求
save=True, # 保存预测结果
show=True, # 是否立刻显示结果
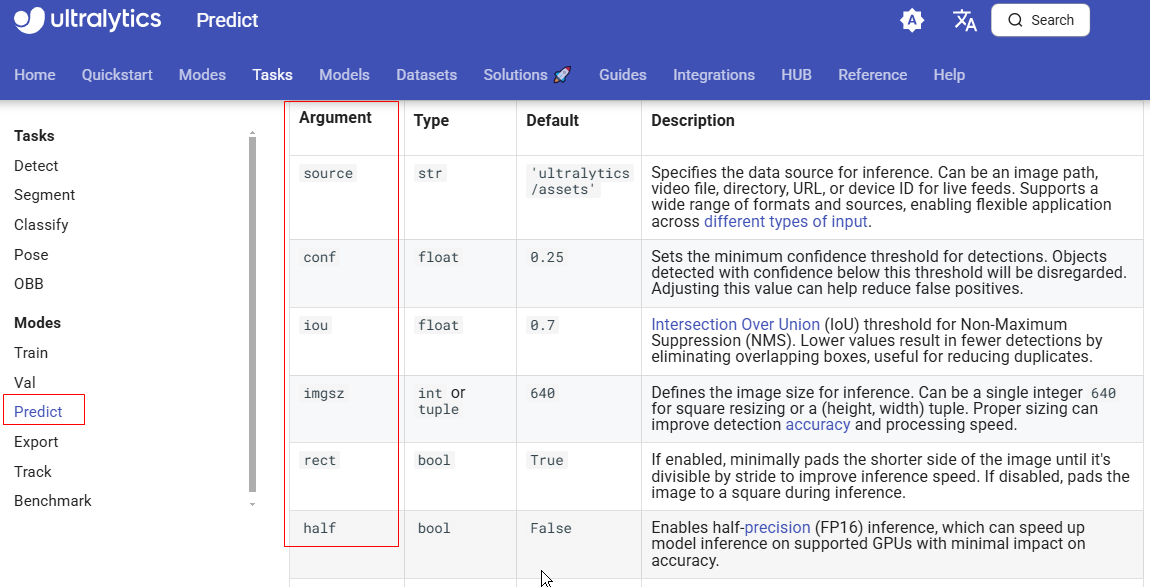
)predict中还有很多选项,官方文档可以查阅:
https://docs.ultralytics.com/modes/predict/#inference-arguments
6.解决摄像头内存问题
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt') #
model.predict(
# 我要预测 ultralytics/assets 文件夹下所有的图片,就是你要预测的目标
source=0,
stream=True,
)
for result in results:
plotted = result.plot()
cv2.imshow('yolo inference', plotted)
if cv2.waitKey(1) == ord('q'):
break