1. 什么是连接池
现如今在做程序开发的时候,尤其是涉及到数据库的时候,都会用连接池来管理数据库连接。其中Java里面有比较出名Druid,以Go语言里面的Gorm框架也会自带连接池管理。数据库连接池,其实就是存储数据库连接的池子,本质是一种资源复用技术
2. 为什么要使用连接池
使用连接池的核心目的是提升应用程序的性能和效率。建立和关闭数据库连接的过程通常是非常消耗资源的,尤其是在高并发环境或频繁访问数据库的场景中,这开销会对应用性能造成显著的负面影响
通过连接池,应用程序可以重复利用已有的数据库连接,减少了每次连接建立和销毁的开销,从而加快系统的响应速度和提高了系统的吞吐能力。同时,连接池还能对连接数量进行有效管理,防止因连接过多而导致数据库过载或性能下降的问题,从而保证系统运行的稳定性和资源的合理利用
3. 连接池常见参数
| 参数 | 含义 |
|---|---|
| max-active | 最大连接数(默认8) |
| max-wait | 获取连接时的最大等待时间 |
| min-evictable-idle-time-millis | 连接保持空闲而不被释放的最小时间 |
| min-idle | 最小连接池数量 |
| initial-size | 连接池初始化时建立物理连接的个数 |
| time-between-eviction-runs-millis | 配置间隔多久才进行一次检测,Destroy线程会检测连接,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接 |
4. 连接池爆满排查路径
连接池的使用虽然可以带来很大程度上性能的话优化,但是在使用MySQL数据库时,尤其是在高并发的场景下,数据库连接数过多会导致连接池耗尽,进而影响应用程序的正常运行。所以对于数据库连接池爆满问题的排查,也相当重要,在排查这类问题的时候可以按照下图的总体思路来进行
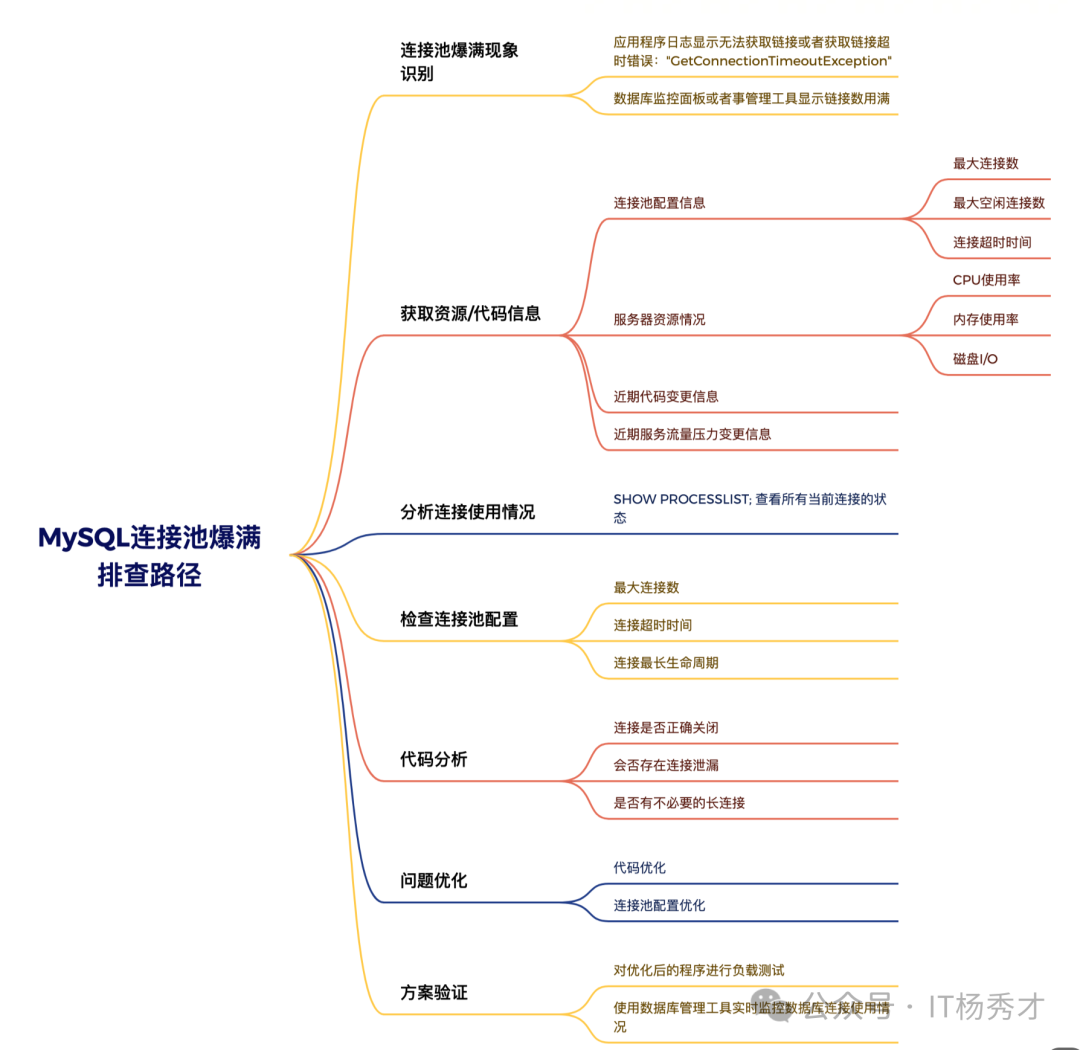
5. 案例分析
5.1 数据模拟
现有一张用户表t_user,要对这张表的数据做一些查询操作,表结构如下:
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键自增',
`name` varchar(32) NOT NULL DEFAULT '' COMMENT '姓名',
`create_time` varchar(32) NOT NULL DEFAULT '' COMMENT '创建日期,yyyy-MM-dd HH:mm:ss',
`age` int(4) NOT NULL DEFAULT 0 COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARSET = utf8;插入两条记录
insert into t_user (name,age,create_time) values ("zhangsan",18,"2024-11-20 12:07:46");
insert into t_user (name,age,create_time) values ("zlisi",20,"2024-11-20 12:07:46");结果如下:

5.2 工程模拟
假设现在有一个spring boot的web工程connPoolDemo,提供了两个查询接口,分别是根据ID查询用户全体信息以及根据ID查询用户的姓名。spring boot工程使用的连接池是Druid,工程配置application.yml如下:
server:
port: 8080
spring:
application:
name: @artifactId@
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:8086/camps?serverTimezone=GMT%2B8&characterEncoding=utf8&&allowMultiQueries=true&useSSL=false
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
druid:
web-stat-filter:
# 是否启用StatFilter默认值true
enabled: true
# 添加过滤规则
url-pattern: /*
# 忽略过滤的格式
exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico
stat-view-servlet:
# 是否启用StatViewServlet默认值true
enabled: true
# 访问路径为/druid时,跳转到StatViewServlet
url-pattern: /druid/*
# 是否能够重置数据
reset-enable: false
# 需要账号密码才能访问控制台,默认为root
login-username: druid
login-password: druid
# IP白名单
allow: 127.0.0.1
# IP黑名单(共同存在时,deny优先于allow)
min-idle: 1 # 最小连接数
max-active: 2 # 最大连接数(默认8)
max-wait: 1000 # 获取连接时的最大等待时间
min-evictable-idle-time-millis: 300000 # 一个连接在池中最小生存的时间,单位是毫秒
time-between-eviction-runs-millis: 60000 # 多久才进行一次检测需要关闭的空闲连接,单位是毫秒
connect-timeout: 10000 # 默认是10s
socket-timeout: 1100000 # 默认是10s
mybatis:
mapper-locations: classpath:mapper/*.xml
#开启驼峰命名
configuration:
map-underscore-to-camel-case: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl注意需要把上述配置中的这两个配置connect-timeout和socket-timeout配置大一些,因为jdbc会根据这两个配置来进行发包测试,默认是10s,如果超过10s,连接没有响应,就会强行断开连接。后面会模拟一个长连接占用的情况来占满连接池,所以这里需要把这两个参数设置的大一些。另外为了方便测试,我们把最大连接数配置小一点,上述yml文件中最大连接数max-active配置为2
5.3 模拟长连接占用
connPoolDemo对外提供两个接口,工程的controller代码如下:
package com.camps.connpooldemo.controller;
import com.camps.connpooldemo.model.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.camps.connpooldemo.service.impl.ConnPoolServiceImpl;
@RestController
public class ConnPoolController {
// 示例:使用 HikariCP 作为连接池
@Autowired
private ConnPoolServiceImpl connPoolServiceImpl;
@GetMapping("/getUser")
public User getUser(@RequestParam("id") Long userID) {
return connPoolServiceImpl.getUser(userID);
}
@GetMapping("/getName")
public String getName(@RequestParam("id") Long userID) {
return connPoolServiceImpl.getName(userID);
}
}都是提供get请求,一个是通过ID获取用户全量信息,一个是通ID获取用户名。再来看对应的mapper代码
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camps.connpooldemo.mapper.UserMapper">
<resultMap id="userMap" type="com.camps.connpooldemo.model.User">
<result column="id" property="id"/>
<result column="name" property="name"/>
<result column="age" property="age"/>
<result column="sleep_time" property="sleepTime"/>
<result column="create_time" property="createTime"/>
</resultMap>
<sql id="Vo_Column_List">
`id`,
`name`,
`age`,
`sleep_time`,
`create_time`
</sql>
<select id="getUser" resultType="com.camps.connpooldemo.model.User" resultMap="userMap">
select * from t_user where id = #{id} limit 1;
</select>
<select id="getName" resultType="com.camps.connpooldemo.model.User" resultMap="userMap">
select sleep(60) as sleep_time,name from t_user where id = #{id} limit 1;
</select>
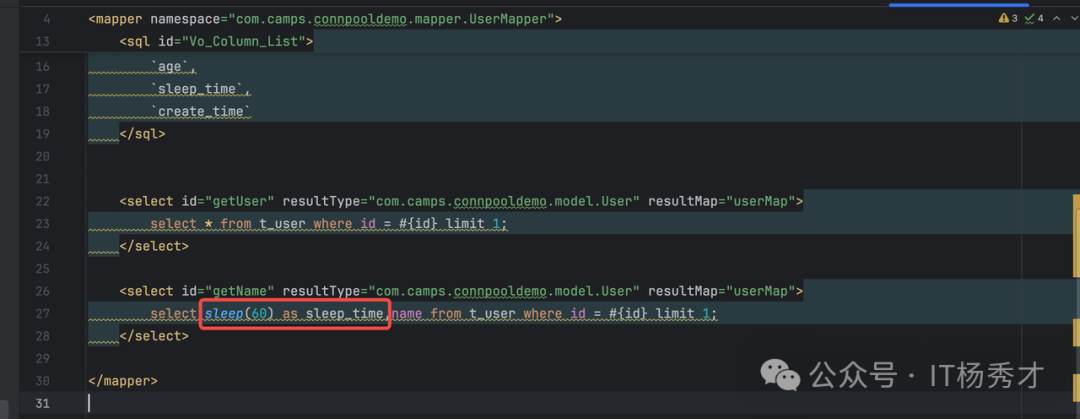
</mapper>注意在mapper.xml中,根据用户ID来获取用户名的sql,select sleep(60),name from t_user where id = #{id} limit 1;在这条sql又一个sleep(60),让这次查询延迟60s执行。用这个延迟执行来模拟后台的一些长连接占用情况,以致连接被长期占用,短时间内无法释放
5.4 请求测试
- 启动服务,服务启动成功,控制台如下:
由于我们使用的是Druid,并且在application.yml文件中配置了Druid的可视化信息,所以我们可以通过页面的形式来查看我们的连接情况,访问如下地址登陆:http://localhost:8080/druid/login.html,先登录
登陆的用户名和密码就是我们在上述application.yml文件中配置的druid的用户名和密码

登陆之后点击上面的数据源页签可以看到数据源的地址,连接等信息,这里我们重点关注连接信息
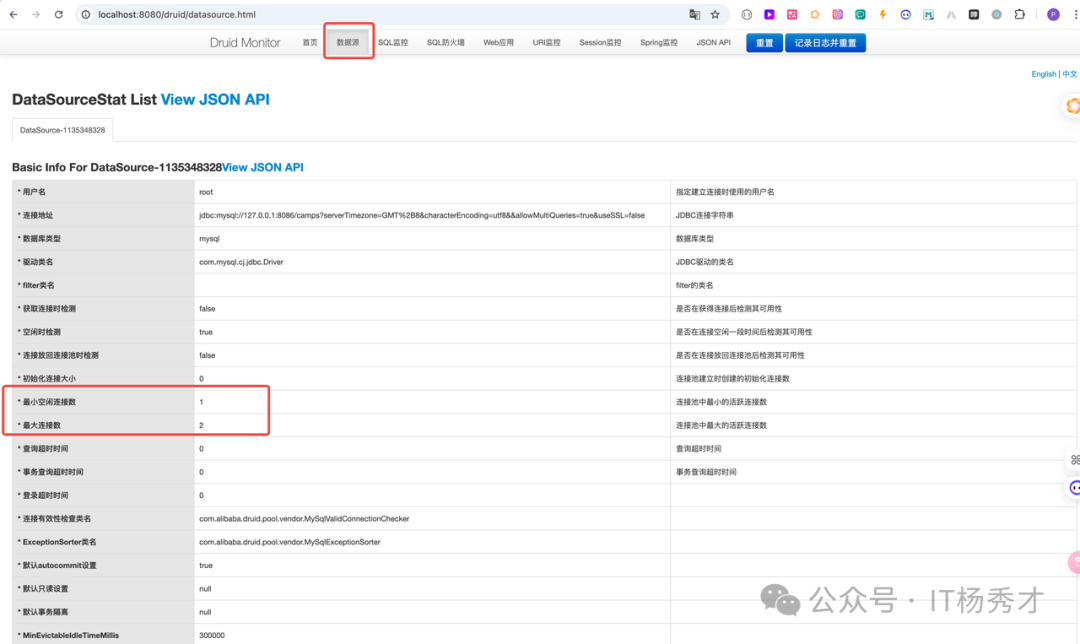
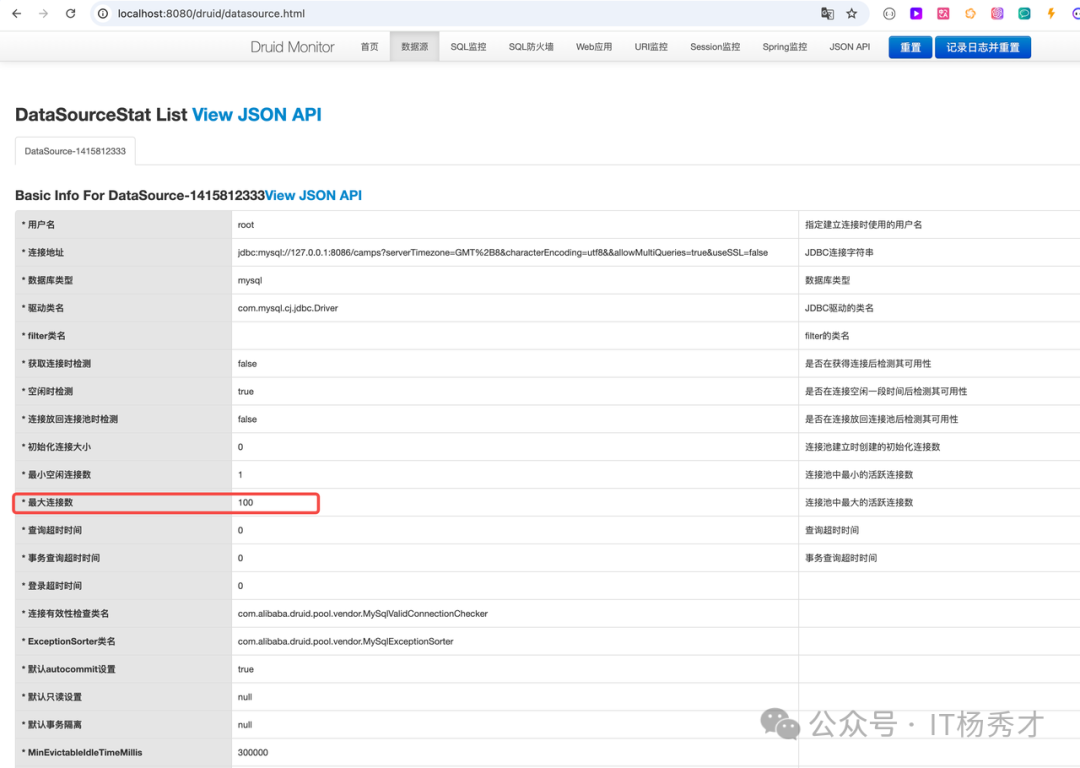
可以看到最大连接数以及最小空闲连接数跟我们在application.yml配置的都是一样的
- 模拟请求
在浏览器开两个页签同时访问http://localhost:8080/getName?id=1这个地址,即发起两次获取用户名的请求

可以看到这两个页面都处于等待转圈等待的情况,因为获取姓名这个请求在后台在Mysql执行查询的时候需要延迟60s在执行,会处于等待状态
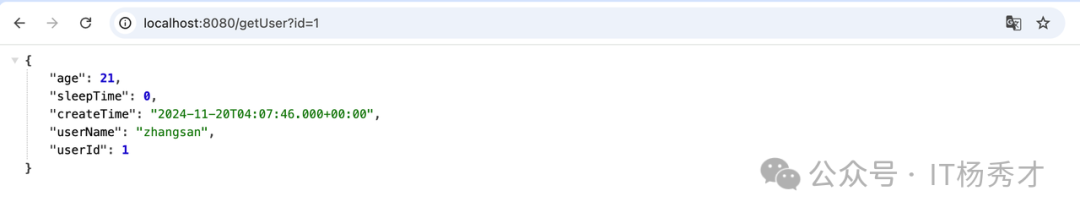
同时浏览器打开第三个页签发起获取用户信息的请求:http://localhost:8080/getUser?id=1,可以看到页面直接报错

等待60s之后,前两个请求用户名的请求此时返回了数据zhangsan,如下图所示:

5.5 连接池爆满现象识别
看后台程序,控制台报错如下:
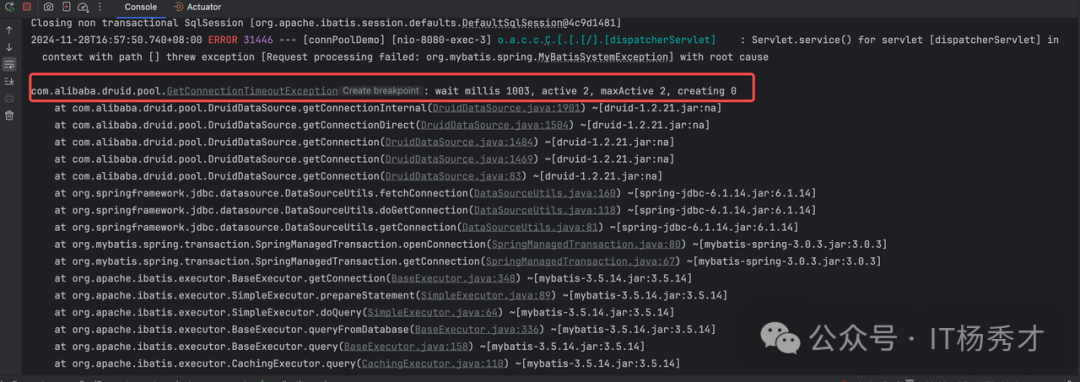
获取连接池超时,可以初步断定问题为连接池满了,获取不到连接所致
5.6 根因分析
进一步分析sql情况,查看当前数据库连接的session情况,数据库执行以命令:
show processlist;
可以看到当前两条连接,都是执行的查询操作,并且分别执行了45s和41s都是属于慢查询,再结合前面启动服务时我们在页面观测到的当前服务配置的最大连接数是2,所以这两个慢查询就将连接池里的连接用完了,并且短时间内不会释放,所以在第三个请求查询用户全量信息的发起的时候,会获取不到连接,报了获取连接超时错误
5.7 方案优化
从上面的分析我们就知道了报错的根本原因就是连接池连接耗尽导致的。而且连接池的最大连接数配置的是2,很小,这样优化起来就很好做了,我们增大连接池的连接配置,重启服务再次测试,现连接调整为100,配置完重启可以看到线上显示druid的连接池最大连接已经是100了
接下来,再次重复上面的测试,在两个页签中发起获取用户名的请求:http://localhost:8080/getName?id=1,在第三个页签中发起获取用户全量信息的请求:http://localhost:8080/getUser?id=1。此时可以看到前两个页面跟上次测试结果一样,依旧是在等待
而第三个页面马上返回了用户信息,结果如下:
过一分钟后前两个页面也会收到返回信息:zhagnsan,跟上次测试一样。虽然这里通过调大数据库连接池的配置参数,使问题得到了初步的解决。这里可以进一步分析,通过前面执行show processlist;查看数据库连接信息的时候,我们发现两条sql长时间占用连接,导致连接不能有效释放,使得连接池被占满,导致第三个请求才一直获取不到连接而报错,所以这里的这两条sql也是需要优化的,具体分析show processlist的结果,初步看后面的sql语句

再去代码中确认,看下获取用户名请求对应的db曾操作,查看mapper.xml
在select语句执行有个sleep(60)的操作,所以这里很明显会慢,导致延迟60s后才会执行查询操作。所以把这个地方去掉就可以了。这里只是个demo,为了展示连接池如何优化来做的,到具体的业务场景下,这里的慢sql分析还需要借助explain分析工具来进行分析。再去代码中确认,看下获取用户名请求对应的db曾操作,查看mapper.xml
确实在查询的时候,有一个sleep的操作,去掉这个sleep(60)后,mapper.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camps.connpooldemo.mapper.UserMapper">
<resultMap id="userMap" type="com.camps.connpooldemo.model.User">
<result column="id" property="id"/>
<result column="name" property="name"/>
<result column="age" property="age"/>
<result column="sleep_time" property="sleepTime"/>
<result column="create_time" property="createTime"/>
</resultMap>
<sql id="Vo_Column_List">
`id`,
`name`,
`age`,
`sleep_time`,
`create_time`
</sql>
<select id="getUser" resultType="com.camps.connpooldemo.model.User" resultMap="userMap">
select * from t_user where id = #{id} limit 1;
</select>
<select id="getName" resultType="com.camps.connpooldemo.model.User" resultMap="userMap">
select name from t_user where id = #{id} limit 1;
</select>
</mapper>重启服务再次进行测试,前两个页面发起请求后可以立刻获得返回数据zhangsan,第三个页发起请求也可以马上获得用户的全量信息
6. 小结
数据库连接池是现在后端开发中必然会使用的一项池化技术,主要是通过对数据库的连接进行管理和复用,以此来减少频繁的连接创建,从而减少不必要的性能消耗。但是随着并发量的提高,连接池在使用上也很容易出现一些问题,最常见的就是连接耗尽,导致请求获取不到连接而报错。所以掌握好数据库连接池问题的排查是非常有必要的,同时我们还应当做好数据库的一些性能监控,这样对于连接的使用情况就能比较清晰的观测到,这样在要出现问题的时候就会发出告警,从而可以进行及时干预,避免出现线上问题