MyISAM和InnoDB的区别
- 事务能力(这是最根本的区别!)
- InnoDB:支持事务(ACID),就像银行转账,要么全部成功,要么全部失败,保证数据安全
- MyISAM:不支持事务,就像手写账本,"写错一笔就全盘皆输"
- 锁机制(并发性能的关键)
- InnoDB:行级锁,只锁你要操作的行,别人还能同时操作其他行
- MyISAM:表级锁,你一写,整张表都锁住,别人只能干等
- 外键支持
- InnoDB:支持外键,能自动保证关联表数据一致
- MyISAM:不支持外键,需要靠程序员自己写逻辑
- 读写性能
- InnoDB:读写都均衡,适合高并发场景
- MyISAM:读快写慢,写操作会锁整张表,适合"读多写少"的场景
- 故障恢复
- InnoDB:有完善的崩溃恢复机制,不怕突然断电
- MyISAM:断电后可能要手动修复,就像突然断电的Excel文档
- 存储方式
- InnoDB :数据和索引一起存,用
.ibd文件 - MyISAM :数据、索引、表结构分开存,分别是
.MYD、.MYI、.frm
- InnoDB :数据和索引一起存,用
- 适用场景
- InnoDB:适合高并发读写、需要事务和外键的场景,例如:电商、银行系统。写入性能更稳定(行锁减少锁冲突)。
- MyISAM :适合读多写少的场景(如报表、日志系统、数据仓库)。
批量查询速度可能更快(无事务开销,表锁简单)。
总结
| 维度 | MyISAM | InnoDB |
|---|---|---|
| 事务 | 不支持 | 支持(ACID、提交/回滚) |
| 锁粒度 | 表级锁 | 行级锁(含间隙锁) |
| 外键 | 不支持 | 支持 |
| 崩溃恢复 | 仅依赖检查/修复表(REPAIR TABLE) | redo/undo 日志自动崩溃恢复 |
| 索引类型 | 非聚簇索引(数据与索引分离) | 聚簇索引(主键即数据) |
| 存储文件 | .MYD(数据)+.MYI(索引) |
.ibd(单表空间)或共享表空间 |
| COUNT(*) | 内置计数器,瞬间返回(无WHERE条件下) | InnoDB 执行 COUNT() 需要扫描可用索引或聚簇索引,数据量越大耗时越长 |
| 全文索引 | 5.6 之前仅 MyISAM 支持原生全文索引 | 5.6+ 支持,性能更优 |
| 压缩表 | myisampack 只读压缩 | 支持行格式压缩(ROW_FORMAT=COMPRESSED) |
| 适用场景 | 读多写少、无事务、静态报表 | 高并发读写、需要事务/外键/恢复保障 |
如何选择
优先InnoDB:现代MySQL的默认引擎,适合99%的场景,尤其是需要事务、并发或数据安全的应用。
例外用MyISAM:仅当系统以读为主、无需事务且追求极简优化时(如静态报表),但已逐渐被InnoDB+缓存或Aria(MariaDB)替代。
MySQL 8.0已标记MyISAM为废弃引擎,仅保留InnoDB作为核心引擎。
MySQL的一条SQL语句的执行过程是怎么样的?
先来看一张总览图
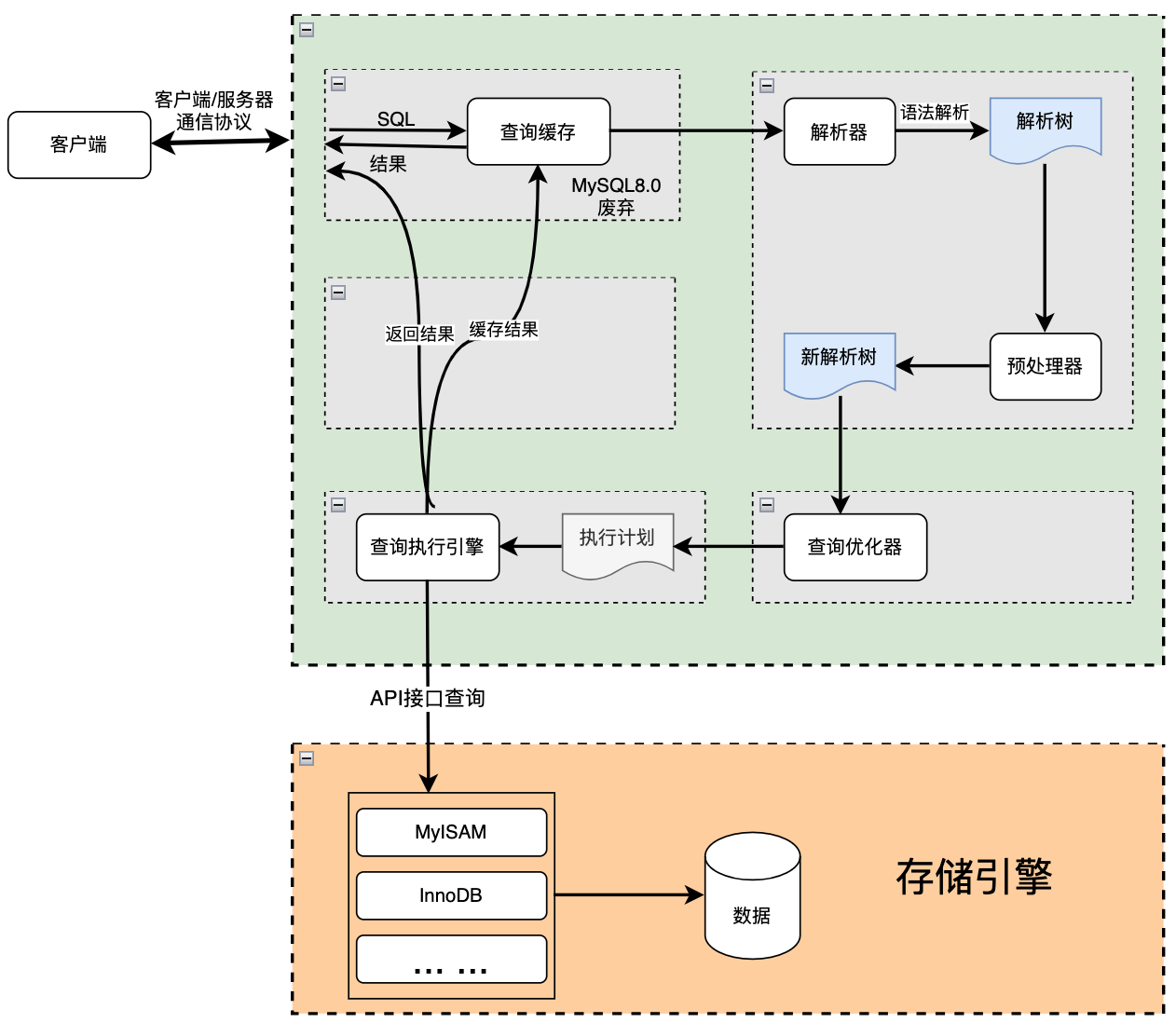
主要步骤:客户端发送 SQL → 连接器 → 查询缓存(8.0 已移除)→ 解析器 → 预处理器 → 优化器 → 执行器 → 存储引擎 → 返回结果
使用连接器
通过客户端/服务器通信协议,客户端与 MySQL 建立 TCP 连接。验证用户名、密码、权限。每个连接对应一个线程(MySQL 是线程模型)。
查询缓存(Query Cache)(MySQL 8.0 已移除)
如果开启,会检查是否执行过完全相同的 SQL。
命中则直接返回结果,跳过后续步骤。
但由于命中率低、锁竞争严重,8.0 被废弃(实际在 5.7 起已默认关闭)。
解析器(Parser)
词法分析 :将 SQL 字符串拆成 token。
语法分析 :构建语法树(AST),检查语法是否正确。比如:select * form user (form写错了应该是from)→ 会报错 syntax error。
预处理器(Preprocessor)
语义分析 :检查表、列是否存在。别名是否合法。展开视图、子查询等。
权限验证:检查用户是否有访问表的权限。
优化器(Optimizer)
这里是核心阶段:决定怎么执行这条 SQL。
主要工作包括:
- 选择索引(哪个索引最优)。
- 决定 join 顺序(先查 A 表还是 B 表)。
- 是否使用覆盖索引、ICP、MRR 等优化。
- 生成执行计划(Execution Plan)。
你可以用 EXPLAIN 或 EXPLAIN FORMAT=JSON 查看优化器的选择。
执行器(Executor)
- 根据执行计划,调用存储引擎的接口。
- 逐行读取数据(或通过索引加速)。
- 执行
WHERE过滤、排序、聚合、LIMIT等操作。 - 对于
UPDATE/DELETE,还会加锁(行锁、间隙锁等)。
存储引擎(如 InnoDB)
这里真正负责数据在磁盘与内存间的读写。
关键操作步骤:
- 通过 B+ 树索引定位记录。
- 加载数据页到内存(
Buffer Pool)。 - 加锁(行锁、间隙锁、
Next-Key Lock)。 - 写
undo log(用于事务回滚)。 - 写
redo log(保证崩溃恢复)。
如果是写操作,还会:
- 修改内存页 → 标记为脏页。
- 写入
redo log(WAL 机制)。 - 后续由后台线程刷盘。
返回结果
- 对于
SELECT:将结果集封装成协议包返回客户端。 - 对于
DML:返回影响的行数、自增 ID 等(如INSERT ... VALUES ...)。
举个例子:
sql
SELECT * FROM user WHERE id = 10上面这段SQL的执行步骤如下:
- 连接器:验证连接和权限。
- 解析器:识别出是 SELECT,表是 user,条件是 id = 10。
- 预处理器:确认 user 表存在,id 列存在,用户有权限。
- 优化器:发现 id 是主键,决定用主键索引,生成执行计划。
- 执行器:调用 InnoDB 接口,通过主键索引定位 id=10 的行。
- InnoDB:从 Buffer Pool 或磁盘加载数据页,返回行数据。
- 执行器:封装结果,返回客户端。
数据库事务机制
数据库的事务机制是数据库管理系统(DBMS)执行过程中的一个逻辑单位,核心目标是通过特定的控制逻辑,确保一组操作要么全部成功执行,要么在发生异常时全部回滚至初始状态,从而维护数据的完整性与业务逻辑的正确性。
事务机制通常遵循ACID原则,这是四个基本特性的缩写:
原子性(Atomicity)
事务中的所有操作要么全部完成,要么全部不完成,不会结束在中间某个点。如果事务中的某个操作失败,整个事务将回滚到执行前的状态,就像这个事务从未执行过一样。
一致性(Consistency)
事务必须保证数据库从一个一致的状态转移到另一个一致的状态。这意味着事务执行的结果必须是数据库完整性约束没有被破坏,所有的规则都必须应用于事务的修改。
隔离性(Isolation)
并发执行的事务之间不会互相影响。一个事务的中间状态对其他事务是不可见的。事务的隔离性防止了多个事务并发执行时由于交叉执行导致数据的不一致。
持久性(Durability)
一旦事务提交,它对数据库的改变就是永久性的,即使系统发生故障,提交的事务结果也不会丢失。