文章目录
Redis篇
这里都是个人总结的经验,没有什么高深莫测的,只有平常碰到的问题的解决过程。
Redis作为高性能的键值数据库,其性能瓶颈与稳定性问题多集中于内存管理、日志配置及服务启停机制。以下结合实际告警与故障场景,从问题根源到优化落地进行完整拆解。
优化一、解决Redis碎片率过高
根据告警信息和 INFO memory输出,Redis 实例的内存碎片率过高。
bash
# dev
127.0.0.1:12204> INFO memory
# Memory
used_memory:5714768 # 实际使用:5mb
used_memory_rss:12537856 # 操作系统实际分配:12mb
mem_fragmentation_ratio:2.30 # 碎片率虽然不是啥大问题,毕竟我做了最大内存限制是8G,这点占用就是洒洒水啦。可我想做的是如果真的到了某阈值的时候,我的处理办法有哪些,所以才做了一个优化。
问题本质:Redis依赖内存分配器(默认jemalloc)管理内存,当频繁执行键的增删操作时,会产生大量内存空洞------已释放的内存块因大小不连续,无法被新的内存请求复用,导致操作系统分配的物理内存远大于Redis实际使用的内存,形成碎片。
优化过程:手动清理
bash
# dev环境测试
# 尝试清理缓存:(定期在业务低峰执行)
127.0.0.1:12204> INFO memory
# 动态设置为4GB,重启后失效。请务必也修改配置文件使其永久生效。
CONFIG SET maxmemory 4294967296
# 清理页面缓存
127.0.0.1:12204> echo 1 > /proc/sys/vm/drop_caches # 清除页面缓存(对运行中的Redis服务无影响)
# 再次查询:
# 降至1.91注意:
echo 1 > /proc/sys/vm/drop_caches仅清理页缓存,若执行echo 2则清理目录项和inode缓存,可能影响文件系统性能,生产环境需谨慎。
或者开启自动清理功能:
bash
vim /etc/redis/redis.conf
activedefrag yes
# 重启redis即可。如果,我是说如果,你开启了之后出现了以下问题:
bash
root@dev:~# journalctl -xeu redis-server.service
10月 14 17:00:54 dev systemd[1]: redis-server.service: Failed with result 'exit-code'.
░░ Subject: Unit failed
░░ Defined-By: systemd
░░ Support: http://www.ubuntu.com/support
░░
░░ The unit redis-server.service has entered the 'failed' state with result 'exit-code'.
10月 14 17:00:54 dev systemd[1]: Failed to start Advanced key-value store.
░░ Subject: redis-server.service 单元已失败
░░ Defined-By: systemd
░░ Support: http://www.ubuntu.com/support
░░
░░ redis-server.service 单元已失败。
░░
░░ 结果为"failed"。恭喜你,你的redis可能有点小问题:Redis 的自动碎片整理功能依赖于一个特定修改版的 Jemalloc 库。Redis 是通过系统包管理器apt安装的,使用了标准的 libc malloc或不完整功能的 Jemalloc,导致此功能无法启用 。
解决办法:源码安装,补全依赖,重新编译依赖库,重装。
警醒 : 安装核心服务尽量选取官方源码包或二进制包进行安装,以免出现不完整库的情况。
最好通过Prometheus+Grafana监控redis_memory_fragmentation_ratio指标,设置1.8为告警阈值,2.0为紧急阈值。
优化二、提高慢查询日志长度
简单来说,调高 slowlog-max-len就像给 Redis 的性能诊断工具换上一个"更大容量的黑匣子",让它能记录更长时间内的飞行数据,这对于保障生产环境的稳定性和可排查性非常关键。
设置完成后,通过 CONFIG GET slowlog-max-len命令确认修改是否成功,并使用 SLOWLOG LEN随时查看当前慢查询列表中的实际记录数量。
设置过程:
bash
# 原始值128
127.0.0.1:12206> CONFIG GET slowlog-max-len
1) "slowlog-max-len"
2) "128"
# 修改为1000
127.0.0.1:12206> CONFIG SET slowlog-max-len 1000
OK
127.0.0.1:12206> CONFIG GET slowlog-max-len
1) "slowlog-max-len"
2) "1000"
127.0.0.1:12206> CONFIG REWRITE
OK意义:
保留更多历史记录,避免重要慢查询丢失 :Redis 的慢查询日志是一个先进先出 (FIFO) 的队列。当新产生的慢查询数量达到列表最大长度时,最早的一条记录会被移出队列。在并发较高或问题排查周期较长时,较小的队列(如默认的128)可能导致早期的关键慢查询记录被快速挤出,从而无法追溯。设置为 1000 可以显著增加日志的留存时间,为您分析和排查间歇性或历史性的性能问题提供更充足的数据支持。
适合生产环境需求 :对于线上环境,将 slowlog-max-len设置为 1000 或更大 是一个常见的最佳实践 。因为 Redis 在记录慢查询时会对较长的命令进行截断处理,所以适当增加列表长度通常不会占用大量****内存,却可以极大提升问题诊断的便利性。
配合更严格的慢查询阈值 :在高流量、低延迟要求的场景(高OPS场景)下,通常会将慢查询阈值(slowlog-log-slower-than)设置为一个更小的值(例如 1 毫秒,即1000微秒),以捕获更多潜在的性能抖动。降低阈值会导致被记录的慢查询数量增加,此时调高 slowlog-max-len可以确保这些新增的记录有足够的空间被保存下来。
优化三、Redis宕机无法启动
事情经过是这样,某一天凌晨测试在测试服务,但是不知道为什么,redis突然就宕机了,后来给我的说法是上层的某个网络设备出了问题,导致那个设备坏了,但是redis崩了并没有给我解释,就告诉我快点处理,那就处理呗,没招。我一看日志:
bash
10月 17 09:36:22 prod redis-server[1768297]: >>> 'logfile "/data/redis/redis-server.log"'
10月 17 09:36:22 prod redis-server[1768297]: Can't open the log file: Read-only file system
10月 17 09:36:22 prod systemd[1]: redis-server.service: Main process exited, code=exited, status=1/FAILURE
10月 17 09:36:22 prod systemd[1]: redis-server.service: Failed with result 'exit-code'.
10月 17 09:36:22 prod systemd[1]: Failed to start Advanced key-value store.
10月 17 09:36:22 prod systemd[1]: redis-server.service: Scheduled restart job, restart counter is at 2.
10月 17 09:36:22 prod systemd[1]: Stopped Advanced key-value store.
10月 17 09:36:22 prod systemd[1]: Starting Advanced key-value store...
10月 17 09:36:22 prod redis-server[1768304]: *** FATAL CONFIG FILE ERROR (Redis 6.0.16) ***
10月 17 09:36:22 prod redis-server[1768304]: Reading the configuration file, at line 260
10月 17 09:36:22 prod redis-server[1768304]: >>> 'logfile "/data/redis/redis-server.log"'
10月 17 09:36:22 prod redis-server[1768304]: Can't open the log file: Read-only file system
10月 17 09:36:22 prod systemd[1]: redis-server.service: Main process exited, code=exited, status=1/FAILURE
10月 17 09:36:22 prod systemd[1]: redis-server.service: Failed with result 'exit-code'.
10月 17 09:36:22 prod systemd[1]: Failed to start Advanced key-value store.
10月 17 09:36:23 prod systemd[1]: redis-server.service: Scheduled restart job, restart counter is at 3.
10月 17 09:36:23 prod systemd[1]: Stopped Advanced key-value store.
10月 17 09:36:23 prod systemd[1]: Starting Advanced key-value store...
10月 17 09:36:23 prod redis-server[1768517]: *** FATAL CONFIG FILE ERROR (Redis 6.0.16) ***
10月 17 09:36:23 prod redis-server[1768517]: Reading the configuration file, at line 260
10月 17 09:36:23 prod redis-server[1768517]: >>> 'logfile "/data/redis/redis-server.log"'
10月 17 09:36:23 prod redis-server[1768517]: Can't open the log file: Read-only file system
10月 17 09:36:23 prod systemd[1]: redis-server.service: Main process exited, code=exited, status=1/FAILURE
10月 17 09:36:23 prod systemd[1]: redis-server.service: Failed with result 'exit-code'.
10月 17 09:36:23 prod systemd[1]: Failed to start Advanced key-value store.
10月 17 09:36:23 prod systemd[1]: redis-server.service: Scheduled restart job, restart counter is at 4.
10月 17 09:36:23 prod systemd[1]: Stopped Advanced key-value store.
10月 17 09:36:23 prod systemd[1]: Starting Advanced key-value store...
10月 17 09:36:23 prod redis-server[1768739]: *** FATAL CONFIG FILE ERROR (Redis 6.0.16) ***
10月 17 09:36:23 prod redis-server[1768739]: Reading the configuration file, at line 260
10月 17 09:36:23 prod redis-server[1768739]: >>> 'logfile "/data/redis/redis-server.log"'
10月 17 09:36:23 prod redis-server[1768739]: Can't open the log file: Read-only file system
10月 17 09:36:23 prod systemd[1]: redis-server.service: Main process exited, code=exited, status=1/FAILURE
10月 17 09:36:23 prod systemd[1]: redis-server.service: Failed with result 'exit-code'.
10月 17 09:36:23 prod systemd[1]: Failed to start Advanced key-value store.
10月 17 09:36:24 prod systemd[1]: redis-server.service: Scheduled restart job, restart counter is at 5.
10月 17 09:36:24 prod systemd[1]: Stopped Advanced key-value store.
10月 17 09:36:24 prod systemd[1]: redis-server.service: Start request repeated too quickly.
10月 17 09:36:24 prod systemd[1]: redis-server.service: Failed with result 'exit-code'.
10月 17 09:36:24 prod systemd[1]: Failed to start Advanced key-value store.在日志里面找到了核心问题:
bash
10月 17 09:36:22 prod redis-server[1768297]: >>> 'logfile "/data/redis/redis-server.log"'
10月 17 09:36:22 prod redis-server[1768297]: Can't open the log file: Read-only file system
10月 17 09:36:22 prod systemd[1]: redis-server.service: Main process exited, code=exited, status=1/FAILUREaof、rdb、log文件没有写入权限,说实话懵了一下下,之前为什么好用,现在为啥权限干没了???给我干一脸问号,我怀疑是之前的文件目录或许被动过了,也就是说更换了一个新的dir,但是并没有给权限,也没daemon-reload,但是这个宕机之后,再次启动的时候就用到了新修改的目录,所以出现的问题,但是仅限于我的猜测,不管咋样,总之问题就是文件没有权限呗,解决就完了:
- 直接原因:Redis配置的日志目录
/data/redis所在文件系统为只读模式,无写入权限; - 潜在原因:磁盘挂载参数错误(如/etc/fstab中配置了ro权限)、磁盘损坏触发保护模式、systemd服务配置限制了目录访问权限。
bash
root@dev:~# vim /etc/systemd/system/redis.service
[Service]
# 现有配置...
ReadWritePaths=-/var/lib/redis
ReadWritePaths=-/var/log/redis
ReadWritePaths=-/var/run/redis
ReadWritePaths=-/etc/redis
# 添加以下行,允许写入 /data/redis 目录
ReadWritePaths=-/data/redis
root@dev:~# systemctl daemon-reload
root@dev:~# systemctl restart redis 这就解决了,属于是给我干笑了哈哈哈哈哈。
MySQL篇
优化一、MySQL的InnoDB缓冲池命中率低
Prometheus监控告警:MySQL 实例 prod-mysql InnoDB 缓冲池命中率 94.70%,低于 95% 阈值,建议增加innodb_buffer_pool_size。
**虽说这个告警是我设置的,但是一看到但是MySQL的问题还是心头一惊。**其实看到之后感觉也不是啥大问题,不过是缓冲池大小没被修改过,还是MySQL的默认值,上调一下就好了,对了,解释一下上调的意义:
上调MySQL的innodb_buffer_pool_size最核心的意义在于,通过分配更多内存来缓存InnoDB存储引擎的表数据和索引,显著减少数据库对磁盘的直接I/O访问,从而大幅提升数据的读取速度和处理性能,这是优化MySQL数据库性能最有效的手段之一。
调整原则:
- 独立MySQL服务器:建议设置为物理内存的50%70%(如16GB内存服务器设为812GB);
- 混合部署服务器:预留至少4GB内存给操作系统及其他服务,剩余内存的50%分配给缓冲池;
- 多实例部署:按实例数据量比例分配内存,避免单实例占用过高导致系统OOM。
那还说啥了,改呗兄弟:
SQL
# 查看原始值:
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.00 sec)
# 上调至8G:
# 热加载模式,无需重启redis
mysql> SET GLOBAL innodb_buffer_pool_size = 8589934592;
Query OK, 0 rows affected (0.00 sec)
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
+-------------------------+------------+
| Variable_name | Value |
+-------------------------+------------+
| innodb_buffer_pool_size | 8589934592 |
+-------------------------+------------+
1 row in set (0.01 sec)
mysql>
# 写入配置文件
vim /etc/mysql/mysql.conf.d/mysqld.cnf
# innodb上调-2025.10.16
innodb_buffer_pool_size = 8G优化二、因apt自动更新导致的数据库重启
在平常不过的一天,自己刚部署了夜莺的监控,即将完善的时候,查看了一下MySQL的运行日志,突然发现生产数据库在早上竟然迷之重启了:
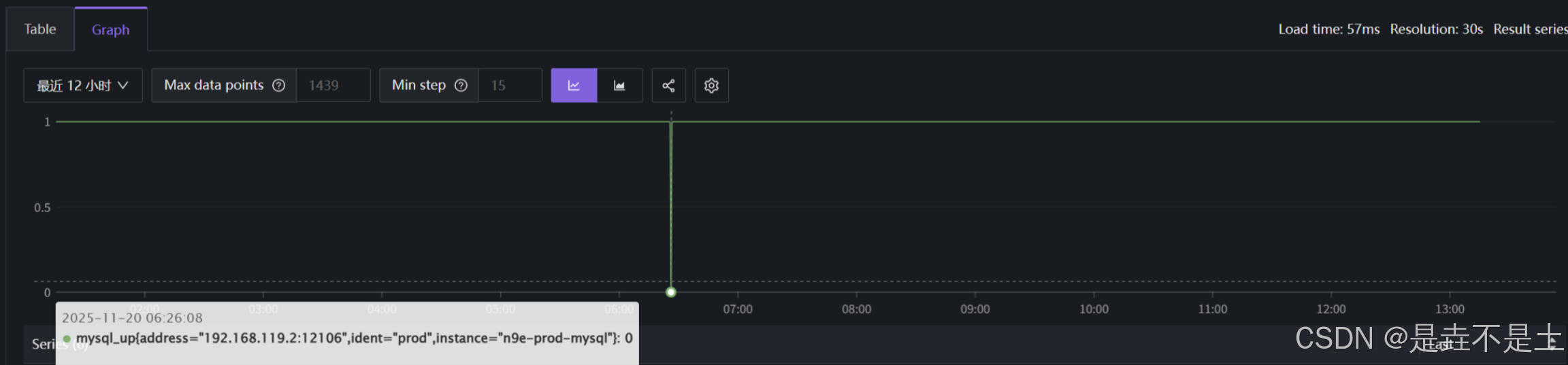
我一下子就懵了,赶紧查服务运行日志:
bash
root@prod:/app/n9e/categraf# sudo journalctl -u mysql.service -n 10
11月 20 06:25:47 prod systemd[1]: Stopping MySQL Community Server...
11月 20 06:26:00 prod systemd[1]: mysql.service: Deactivated successfully.
11月 20 06:26:00 prod systemd[1]: Stopped MySQL Community Server.
11月 20 06:26:00 prod systemd[1]: mysql.service: Consumed 18h 6min 50.746s CPU time.
11月 20 06:26:16 prod systemd[1]: Starting MySQL Community Server...
11月 20 06:26:19 prod systemd[1]: Started MySQL Community Server.
root@prod:/app/n9e/categraf# journalctl -u mysql.service --since "06:25:00" --until "06:27:00"
11月 20 06:25:47 prod systemd[1]: Stopping MySQL Community Server...
11月 20 06:26:00 prod systemd[1]: mysql.service: Deactivated successfully.
11月 20 06:26:00 prod systemd[1]: Stopped MySQL Community Server.
11月 20 06:26:00 prod systemd[1]: mysql.service: Consumed 18h 6min 50.746s CPU time.
11月 20 06:26:16 prod systemd[1]: Starting MySQL Community Server...
11月 20 06:26:19 prod systemd[1]: Started MySQL Community Server.只看到了数据库停止和数据库启动的操作,并且时间极短,那这该怎么去排查问题呢?
**首先,这个动作还是比较像人为的,发现问题后第一时间问了所有的后端,是不是他们动的(怀疑有人加班然后导入新的数据库了等等原因),**然后我就屁颠屁颠的去问了,问了一圈都没回应,我想应该不是了,那个时间还加班可真的太阴间了哈哈哈哈哈。
既然不是人为的,那就有可能是系统自动执行的程序导致的,我直接查看了数据库从停止到再次启动之间的系统日志。
bash
root@prod:/app/n9e/categraf# sudo journalctl --since "06:25:00" --until "06:27:00"
# 开始apt自动更新
11月 20 06:25:01 prod CRON[3454664]: (root) CMD (test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ))
11月 20 06:25:35 prod systemd[1]: Starting Daily apt upgrade and clean activities...
......
# 数据库被停止
11月 20 06:26:00 prod systemd[1]: mysql.service: Deactivated successfully.
11月 20 06:26:00 prod systemd[1]: Stopped MySQL Community Server.
11月 20 06:26:00 prod systemd[1]: mysql.service: Consumed 18h 6min 50.746s CPU time.
# 告警引擎发现了数据库宕机
11月 20 06:26:06 prod categraf[3797908]: 2025/11/20 06:26:06 mysql.go:219: E! failed to ping mysql: dial tcp 192.168.119.2:12106: connect: connectio>
......
# 数据库被启动
11月 20 06:26:16 prod systemd[1]: Starting MySQL Community Server...
11月 20 06:26:19 prod systemd[1]: Started MySQL Community Server.
......
# apt定时自动更新完成
11月 20 06:26:39 prod systemd[1]: apt-daily-upgrade.service: Deactivated successfully.
11月 20 06:26:39 prod systemd[1]: Finished Daily apt upgrade and clean activities.当我把日志整理之后粘贴出来,其实就显而易见了:
- 日常执行:apt 每日升级完整流程
- 启动时间:06:25:35(systemd 发起「Daily apt upgrade and clean activities」)
- 重启关联:apt 启动后 12 秒触发 MySQL 停止
- 停止流程:06:25:47 系统发起停止指令 → 06:26:00 成功停止(「Deactivated successfully」)
- 启动流程:06:26:16 系统发起启动指令 → 06:26:19 成功启动(「Started MySQL Community Server」)
- 关键状态:重启全程无报错,仅监控工具(categraf、mysqld_exporter)因服务临时停止报连接失败
- 完成时间:06:26:39(成功停止,状态为「Deactivated successfully」)
到此,已经基本可以确定是apt自动升级导致mysql版本升级导致的服务自动启停。
原数据库版本:8.0.43,现在数据库版本:8.0.44
为了确保问题排查的准确性,查询apt的更新日志:
bash
cat /var/log/apt/history.log
# 数据库更新了
Start-Date: 2025-11-20 06:25:46
Commandline: /usr/bin/unattended-upgrade
Upgrade: mysql-server-8.0:amd64 (8.0.43-0ubuntu0.22.04.1, 8.0.44-0ubuntu0.22.04.1), mysql-client-8.0:amd64 (8.0.43-0ubuntu0.22.04.1, 8.0.44-0ubuntu0.22.04.1), mysql-server-core-8.0:amd64 (8.0.43-0ubuntu0.22.04.1, 8.0.44-0ubuntu0.22.04.1)
End-Date: 2025-11-20 06:26:19
Start-Date: 2025-11-20 06:26:29
Commandline: /usr/bin/unattended-upgrade
Upgrade: mysql-client-core-8.0:amd64 (8.0.43-0ubuntu0.22.04.1, 8.0.44-0ubuntu0.22.04.1)
End-Date: 2025-11-20 06:26:29到此,排查结束。为了避免此类问题出现,导致服务宕机,使用apt-mark阻止服务被更新、重装或卸载,同时保持服务正常运行。
bash
# 集群同步执行
root@prod:/# apt-mark hold mysql-server mysql-client
mysql-server 设置为保留。
mysql-client 设置为保留。
root@dev:~# apt-mark hold redis-server
redis-server 设置为保留。
# 解除锁定(需要更新时)
sudo apt-mark unhold mysql-server总结
Redis与MySQL的运维优化核心在于"精准定位问题本质+构建长效保障机制"。无论是Redis的内存碎片、慢查询配置,还是MySQL的缓冲池优化、服务管控,都需结合技术原理与业务场景,既要解决当前问题,更要通过监控、配置加固与流程规范避免问题复发。本文档的优化方案均经过生产环境验证,可根据服务器配置与业务需求灵活调整。
(本文章会持续更新,作为本人实习阶段的收获。)