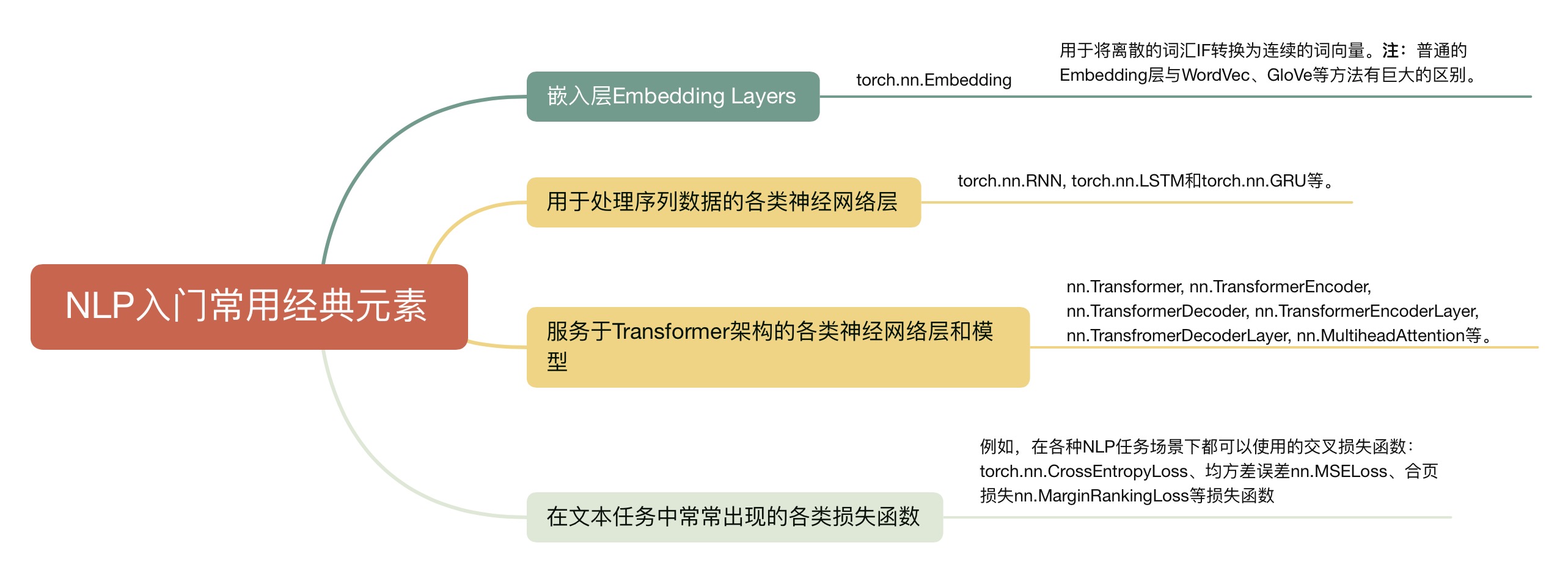
文章目录
- 前言
- 一、NLP概述
-
- [1.1 是智能的象征,也是通往智能之路](#1.1 是智能的象征,也是通往智能之路)
- [1.2 大模型引发行业剧变](#1.2 大模型引发行业剧变)
- [1.3 NLP领域的危险与机遇](#1.3 NLP领域的危险与机遇)
- 二、自然语言领域中的数据
-
- [2.1 深度学习中的时间序列数据](#2.1 深度学习中的时间序列数据)
- [2.2 深度学习中的文字序列数据](#2.2 深度学习中的文字序列数据)
-
- 2.2.1分词操作
- [2.2.2 词、字与Token](#2.2.2 词、字与Token)
- [2.2.3 编码](#2.2.3 编码)
- 三、循环神经网络
-
- [3.1 RNN的基本架构与数据流](#3.1 RNN的基本架构与数据流)
- [3.2 RNN的效率问题与权重共享](#3.2 RNN的效率问题与权重共享)
- [3.3 RNN的输入与输出结构](#3.3 RNN的输入与输出结构)
- [3.4 在PyTorch中实现循环神经网络](#3.4 在PyTorch中实现循环神经网络)
-
- [3.4.1 单层循环神经网络](#3.4.1 单层循环神经网络)
- [3.4.2 深度循环神经网络](#3.4.2 深度循环神经网络)
- [3.5 RNN的反向传播与缺陷](#3.5 RNN的反向传播与缺陷)
-
- [3.5.1 反向传播的数学过程](#3.5.1 反向传播的数学过程)
- [3.5.2 RNN的反向传播所带来的问题](#3.5.2 RNN的反向传播所带来的问题)
- 总结
前言
提示:菜菜和九天老师的深度学习实战课程学习笔记,非抄袭。
一、NLP概述
1.1 是智能的象征,也是通往智能之路
图灵测试是计算机科学家阿兰·图灵在1950年提出的概念,这一测试可以衡量机器是否能够表现出与人类相当的智能。具体来说,图灵测试让一个人类与另一个不可视房间中存在的机器进行对话,如果该人类无法判断出与他/她对话的对象是机器还是真人,那该机器就被认为"通过图灵测试",即被认可"拥有人工智能"。
自图灵测试被提出70多年以来,它一直是深度学习研究者们津津乐道的主题之一,众多模型都被投入进行不严格的"图灵测试",而人们也以"模型是否与真人足够相似"、"模型生成的文字能否与假乱真"来衡量模型的优异程度。不公平的是,当人工智能在非语言领域表现卓越、甚至远远超出人类平均水平时,人们往往习以为常------例如,广泛应用的人脸识别技术其实并不出圈,大部分普通人心中所想的"人工智能"与人脸识别机器大相径庭。然而,当人工智能的交流能力接近人类水平、甚至还不能超越人类水平时(例如:ChatGPT的爆火),社会人就已经感觉到了巨大的威胁,国家紧急出台人工智能应用标准、学者与企业家发起"暂停研发"的呼吁、全球开启AI军备竞赛等技术大事件接踵而至,一时之间热闹非凡。
事实上,在研究者们追求人工智能实现的路径上,我们有三种不同的智能层次:
- 运算智能:让计算拥有快速计算和记忆存储能力。
typescript
硬件加速器:例如 GPU(图形处理单元)、TPU(张量处理单元)、ASICs(应用特定集成电路)等。
并行计算:多核处理器、分布式系统、超线程技术等。
高效算法:如 FFT(快速傅里叶变换)、Strassen算法(快速矩阵乘法)等。
内存和存储技术:如 SSD、RAM、以及新型存储技术如 3D XPoint。- 感知智能:让计算机系统具备感知外部环境的能力。
typescript
计算机视觉:包括以卷积神经网络(CNN)和图像处理在内的一系列内容,应用于图像识别、目标检测、图像分割等。
语音识别:技术包括递归神经网络(RNN)、长短时记忆网络(LSTM)、声谱图等。
触觉技术:例如电容触摸屏、压力感应器等。
其它传感器技术:如雷达、激光雷达(LiDAR)、红外线传感器、摄像头、麦克风、气味检测传感器等。- 认知智能:让那个计算机系统具备类似于人类认知和思维能力的能力。
typescript
自然语言处理:如 RNN、transformer、BERT、GPT架构、语义分析、情感分析等。
增强学习:技术包括 Q-learning、Deep Q Networks (DQN)、蒙特卡洛树搜索(MCTS)等。
知识图谱:结合大量数据,构建对象之间的关系,支持更复杂的查询和推理。
逻辑推理和符号计算:如专家系统、规则引擎、SAT solvers 等。
模拟人类思维的框架和算法:例如认知架构(如 SOAR 和 ACT-R)。无论是图灵测试的设计方式,还是GPT爆火引发的AI浪潮都说明------在人工智能发展的过程当中,深度学习学者们、甚至整个人类社会都无意识地达成了一种高度的共识:认知智能是智能的终极体现,人机同频的交流是智能被实现的象征,无论一个人工智能算法有多强大的能力。只要它不能普适性地理解人类、不能让人类理解、不能与人类顺畅交流,它终归是无法融入人类和商业社会的(残酷的是,一个真人也是一样)。人工智能的终极评判标准,就是人机同频交流。
在"人机同频交流"的大目标下,自然语言处理这一领域的关键性不言而喻。人类90%的信息获取与交流都依赖于语言,人类所有的逻辑、情感、知识、智慧、甚至社会的构建、文明的传承依赖于对语言的理解和表达。因此,计算机想要具备"看人类所看,想人类所想,与人类同频"的能力,就必须理解人类所使用的自然语言,而自然语言处理(Natural Langurage Process)正是研究如何让计算机认知人类语言、理解人类语言、生成人类语言、甚至依赖这些语言与人进行交流、完成特定语言任务的关键学科。豪不夸张的说,人工智能能否真正"智能",很大程度上都依赖于自然语言处理领域的发展。也正因如此,在当今的机器学习世界,自然语言处理有着极其重要的学术和工业地位。
- 持续繁荣的学术界
在过去10年中,计算机视觉技术逐渐成熟、对抗式技术停滞不前,深度学习领域的重大发展和成就都离不开自然语言技术的推动------从Word2Vec、LSTM到Transformer结构,再到BERT、GPT-3和GPT-4等模型,人工智能的每次出圈都离不开NLP,图灵奖得主、深度学习之父Geoffrey Hinton甚至直言"深度学习的下一个大的进展应该是让神经网络真正理解文字的含义",人人都在关注NLP领域的发展。
在过去5年中,NLP经典会议ACL和NAACL中被接受论文数量和比率都逐年增高,得益于语言与其他信息承载形式可以很好的结合,计算机视觉领域、强化学习、对抗式学习、自动驾驶等领域也都受到NLP的影响、纷纷出现借鉴NLP架构的精彩论文------能够在图像领域大杀四方的非卷积架构ViT(Vision Transformer)就是最典型的代表,而23年3月,谷歌大脑发表论文《LEAST-TO-MOST PROMPTING》,验证了大模型+恰当的提示工程可在自动驾驶领域的高难导航数据集SCAN上达到99%的预测精度,而在这之前SCAN数据集上的平均预测精度大约只有50%左右;同时,在2023年3月发布的"机器学习/深度学习领域年度百佳论文"列表中,专注NLP或需要NLP技术支持的论文占据了榜单的2/3,涉及生成式语言模型技术、预训练技术、大语言模型技术、语音技术、图文模型技术等各个方向,NLP无愧于人工智能研究的王者领域。
- 工业界方兴未艾,招聘市场再度火热
在工业界,NLP技术已被投入到各类实用技术当中------搜索引擎、推荐系统、语音助手、聊天机器人、自动摘要、情感分析等都离不开NLP技术,在我们的PC或移动设备上,几乎每一个涉及到文本或语音的产品或服务都在使用NLP。大模型诞生后,这种现象更为明显,在2023年世界人工智能大会上,整个软件展区几乎全被大语言模型相关的软件和APP覆盖,几乎所有前沿科技企业、互联网企业都在尝试研究探索自己的大模型产品。
受到大模型影响,NLP方向招聘市场也开始逐渐回暖,23年春招、23年夏季NLP岗位数量明显多于去年,且逐渐增加了各式各样大模型相关岗位。
1.2 大模型引发行业剧变
随着对NLP的研究不断深入,我们见证了NLP在过去几十年中的巨大进展和突破。从早期的规则驱动方法到统计模型的兴起,再到如今神经网络和深度学习的崛起,NLP领域一直在不断演变和创新。这些发展为我们理解、分析和处理人类语言提供了强大的工具和框架,也为我们未来指出一条明路,让我们一起来看看NLP现在处于什么样的发展阶段,我们应该如何把握住时代的红利、规避时代风险。
从2011年第三次人工智能革命开启,自然语言处理领域已经经历了三大发展阶段:
- 探索阶段:2011~2015(前Transformer时代)
在AlphaGo和卷积网络掀起第三次人工智能革命之前,NLP领域主要依赖人工规则和知识库构建非常精细的"规则类语言模型",当人工智能浪潮来临后,NLP转向使用统计学模型、深度学习模型和大规模语料库。在这个阶段,NLP领域的重要目标是"研发语言模型、找出能够处理语言数据的算法"。因此在这个阶段,NLP领域学者们一直在尝试一些重要的技术和算法,如隐马尔可夫模型(HMM)、条件随机场(CRF)和支持向量机(SVM)。同时,这个阶段也见证了循环神经网络RNN和长短期记忆网络LSTM等神经网络模型的出现和发展。
- 提升阶段:2015~2020(Transformer时代)
RNN和LSTM是非常有效的语言模型,但是和在视觉领域大放光彩的卷积网络比起来,RNN对语言的处理能力只能达到"小规模数据上勉强够用"的程度。2015年谷歌将自注意力机制发扬光大、提出了Transformer架构,在未来的几年中,基于transformer的BERT、GPT等语言模型相继诞生,因此这个阶段NLP领域的重要目标是"大幅提升语言模型在自然语言理解和生成方面的能力"。这是自然语言处理理论发展最辉煌的时代之一。此外,这个阶段中语言模型已经能够很好地完成NLP领域方面的各个任务,因此工业界也实现了不少语言模型的应用,比如搜索引擎、推荐系统、自动翻译、智能助手等。
- 应用阶段:2020-至今(大模型时代)
2020年秋天、GPT3.0所写的小软文在社交媒体上爆火,这个总参数量超出1750w、每运行1s就要消耗100w美元的大语言模型(Large Language Models,LLMs)为NLP领域开启了一个全新的阶段。在这一阶段,大规模预训练模型的出现改变了NLP的研究和应用方式,它充分利用了大规模未标注数据的信息,使得模型具备了更强的语言理解能力和泛化能力。基于预训练+微调模式诞生的大模型在许多NLP任务上取得了前所未有好成绩,在模型精度、模型泛化能力、复杂任务处理能力方面都展示出了难以超越的高水准,这吸引了大量资本的注意、同时也催生了NLP领域全新的发展方向与研究方向。现阶段NLP领域的核心目标主要集中在模型研发&成本降低&模型技术变现三大方向上:
1) 如何研发、训练自己的大模型?
虽然GPT系列大模型的原理并未开源,但GPT的成功无疑为"如何提升语言模型表现"指出了一条明路。在GPT的启发下,海内外各大科技企业正在研发基于BERT、基于GPT或基于Transformer其他组合方式的大模型,国内一线大模型ChatGLM系列就是基于BERT和GPT的融合理念开发的中文大模型。同时,大模型研发和训练技术、如生物反馈式强化学习(RLFH)、近端策略优化(PPO)、奖励权重策略(Reward-based Weighting)、DeepSpeed训练引擎等发展迅速,势不可挡。虽然现在已不是NLP理论发展的高峰,但毫无疑问,大模型算法研发与训练依然是NLP最前沿的研究方向之一。
2) 如何降低大模型应用门槛与应用成本?
大模型吞吃大量语料、训练成本极高,要将大模型应用到具体商业场景、还需进一步研究和训练。因此降低大模型应用成本的预训练、微调、大规模语料库构建等技术正蓬勃发展!自2020年以来已诞生十余种可行的微调方法和自动语料生成方法,如有监督微调(SFT)、低阶自适应微调方法LoRA、提示词前缀微调方法Prefix Tuning、轻量级Prefix微调Prompt Tuning、百倍效率提升的微调方法P-Tuning V2、以及自适应预算分配微调方法AdaLoRA等。这些方法催生了GPT4.0和大量语言方面落地应用,已经大大改变了NLP的研究和应用格局。
3) 如何化技术为产品,实现大语言模型的商业应用?
大语言模型在变现方面有两大优势:首先,大语言模型的性能十分强大、足以很好地支持各类NLP方面服务;其次,大语言模型使用自然语言与消费者交互,可以大幅降低新产品的使用门槛,还可以与图像、语音等领域强势联动、形成多模态的产品。基于这两点变现优势,自动翻译、智能助手、文本分析、情感分析等经典NLP任务都有了实用且价格低廉的APP产品,人们在日常生活工作中更是有无限的机会接触到各类基于大模型技术的NLP应用,家庭物联网、语音指令等技术更是已经走入千家万户,一些谐星的领域,如AI算命、AI佛祖、AI心理咨询师等也相继诞生......
同时,随着大模型应用门槛和使用门槛都逐步降低,大量的大模型产品不断涌现------ChatGPT、跨语言代码编译工具Cursor、Github官方代码编写工具CopilotX、一键生成PPT内容的Gamma AI,office全家桶中配置的Copilot、Photoshop中配置的fill features,广泛生成图像的MidJourney和Stable Diffusion......这些应用不仅改变了商业的运营方式,也极大地影响了人们的生活和工作。同时,大模型APP研发范式LangChain也受到了大规模追捧,LangChain正在逐步构建基于大模型研发变现产品的行业规范,很快整个人工智能领域都将迎来大规模变现的时代。
1.3 NLP领域的危险与机遇
微软联合创始人比尔·盖茨说"像ChatGPT这样的AI聊天机器人将变得与个人电脑或互联网同样重要",英伟达总裁黄仁勋说"ChatGPT是AI领域iPhone,是更伟大事物的开始"。GPT的诞生在社会上引起巨大的轰动,这是因为它代表了大模型技术和预训练模型在自然语言处理领域的重要突破。它不仅提升了人机交互的能力,还为智能助手、虚拟智能人物和其他领域的创新应用打开了新的可能性。随着大模型的进一步发展和应用,我们有理由期待GPT以及类似的技术在未来带来更多令人惊叹的创新和进步。
如果不跟进技术变革,个人也面临被淘汰的危机。现代社会的快速发展和技术创新意味着技能和知识的更新换代速度越来越快。如果个人停留在过时的技能和知识上,将很难适应变化的需求和就业市场的竞争。技术变革带来了新的工作方式、工具和需求。例如,随着人工智能、自动化和数字化的发展,许多传统的工作岗位可能会被自动化或被新的技术取代。如果个人没有及时学习和掌握新的技能,他们可能会发现自己在就业市场上面临竞争的不利位置。另外,技术变革也创造了新的机遇和职业领域。例如,大数据分析、人工智能开发、虚拟现实等新兴领域正迅速发展,对具备相关技能和知识的人才需求量大。如果个人能够抓住这些机遇,不断学习和更新自己的技能,就能在新兴领域找到有竞争力的职业发展机会。因此,紧跟技术变革并不断提升自己的技能和知识是非常重要的。持续学习、适应新技术、关注行业趋势以及不断发展自己的专业能力,可以帮助个人在快速变化的社会中保持竞争力,并更好地应对技术变革可能带来的淘汰危机。
因此,作为立志投身NLP领域的人们,我们应该抓住这个机会,勇往直前。NLP领域不仅具有广阔的前景,而且对于个人成长和职业发展也带来了巨大的机遇。我们可以参与到大模型的研发和优化中,探索更高效的模型结构和训练方法;我们可以开发创新的NLP应用,为人们提供更智能、高效的语言交互体验;我们可以参与到多模态、具身和人类行为模拟等前沿研究中,推动NLP技术的进一步发展。
二、自然语言领域中的数据
自然语言领域的核心数据是序列数据,这是一种在样本与样本之间存在特定顺序、且这种特定顺序不能被轻易修改的数据。这是什么意思呢?在机器学习和普通深度神经网络的领域中我们所使用的数据是二维表。如下所示,在普通的二维表中,样本与样本之间是相互独立的,一个样本及其特征对应了唯一的标签,因此无论我们先训练1号样本、还是先训练7号样本、还是只训练数据集中的一部分样本,都不会从本质上改变数据的含义、许多时候也不会改变算法对数据的理解和学习结果。
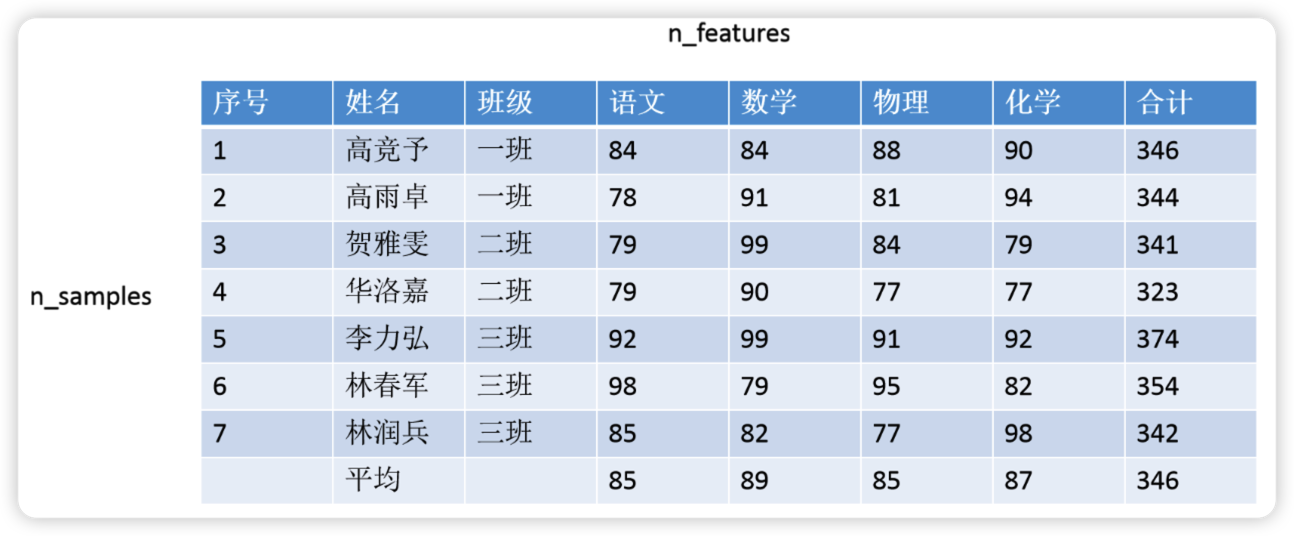
但序列数据则不然,对序列数据来说,一旦调换样本顺序或样本发生缺失,数据的含义就会发生巨大变化。最典型的序列数据有以下几种类型:
- 文本数据(Text Data): 文本数据中的样本以"特定顺序"排列,这充分代表了语义的顺序,在语义环境中,词语顺序的变化与词语的缺失会彻底改变语义,例如:
typescript
改变顺序:事半功倍和事倍功半;曾国藩战太平天国时非常著名的典故:他将"屡战屡败"修改为"屡败屡战",前者给人绝望,后者给人希望。
样本缺失(对文本来说特指上下文缺失):小猫睡在毛毯上,因为它很_。当我们在横线上填上不同的词时,句子的含义也会发生变化。- 时间序列数据(Time Series Data): 时间序列数据中的"特定顺序"是时间顺序,时许数据中的每个样本就是每个时间点,在不同时间点上存在着不同的标签取值,且这些标签取值常常用于描述某个变量随时间变化的趋势,因此样本之间的顺序不能随意改变。例如:股票价格、气温纪录和心电图等数据,一旦改变样本顺序,就会破坏当前趋势,影响对未来时间下的标签的预测。
- 音频数据(Audio Data): 音频数据大部分时候是文本数据的声音信号,此时音频数据中的"特定顺序"也是语义的顺序;当然,音频数据中的顺序也可能是音符的顺序,试想你将一首歌的旋律全部打乱再重新播放,那整首歌的顺序和听感就会完全丧失。
- 视频数据(Video Data): 视频数据本质就是由一帧一帧图像构成,因此视频数据是图像按照顺序排列后构成的数据。和音频数据类似,如果将动画或电影中的画面顺序打乱重新播放,那没有任何人能够理解视频的内容。
类似的数据还有很多,例如DNA序列数据,从医学角度来说DNA测序的顺序不能被打乱,否则就会违背医学常识。除此之外,符号序列数据也是常见的序列数据,密码学、自动编码学、甚至自动编程的算法都对数据本身的逻辑有严格的要求。很明显,在处理序列数据时,我们不仅要让算法理解每一个样本,还需要让算法学习到样本与样本之间的联系。今天,这些能够学习到样本之间联系的算法们构成了自然语言处理架构群。
2.1 深度学习中的时间序列数据
序列数据的概念很容易理解,但奇妙的是,现实中的序列数据可以是二、三、四、五任意维度,只要给原始的数据加上"时间顺序"或"位置顺序",任意数据都可以化身为序列数据。在这里,我们展现几种常见的序列数据:
-
二维时间序列
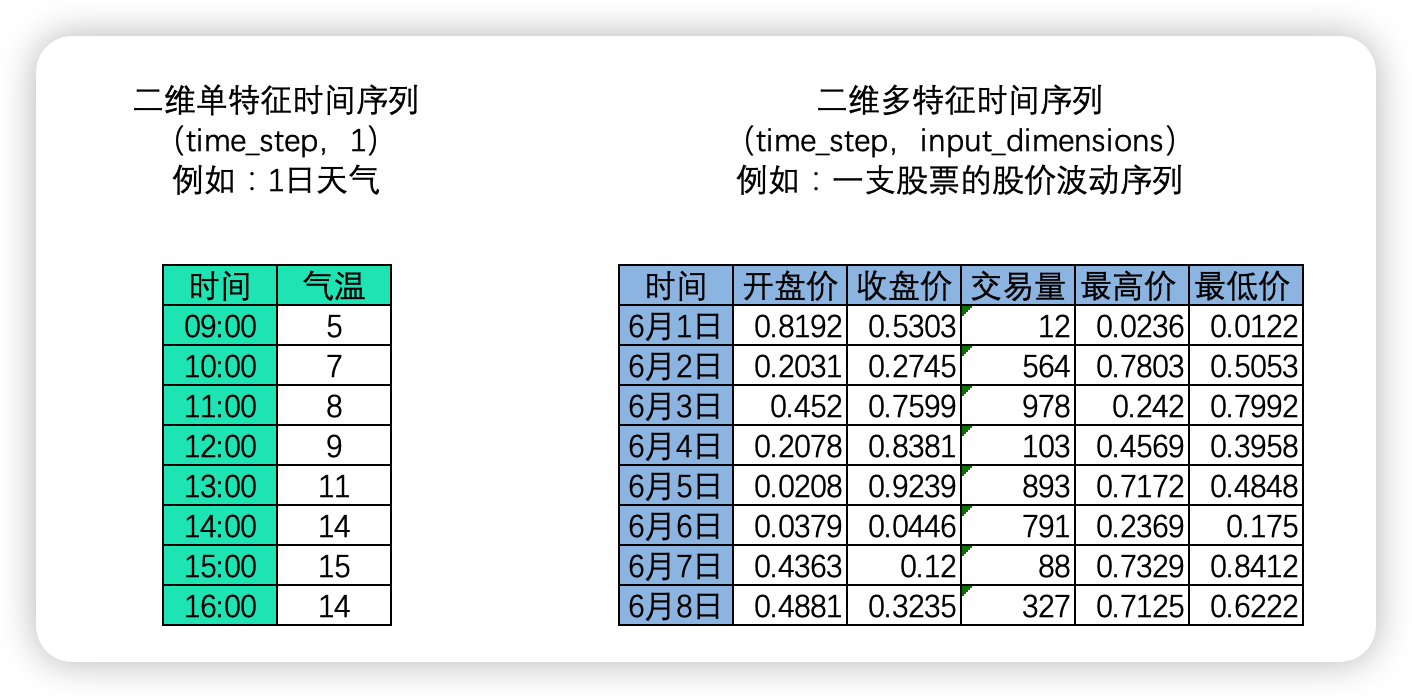
时间序列中,样本与样本之间的顺序是时间顺序,因此每个样本有一个时间戳,时间顺序也就是time_step这一维度上的顺序。这种顺序在自然语言处理领域叫"时间步",它代表了当前时间序列的长度,因此也被称为序列长度(sequence_length)。对时间序列而言,时间步的顺序正是我们要求算法必须去学习的顺序。在NLP领域中,我们常常一次性处理多个时间序列,如下图所示,我们可以一次性处理多支股票的股价波动序列,及三维时间序列。
-
三维时间序列
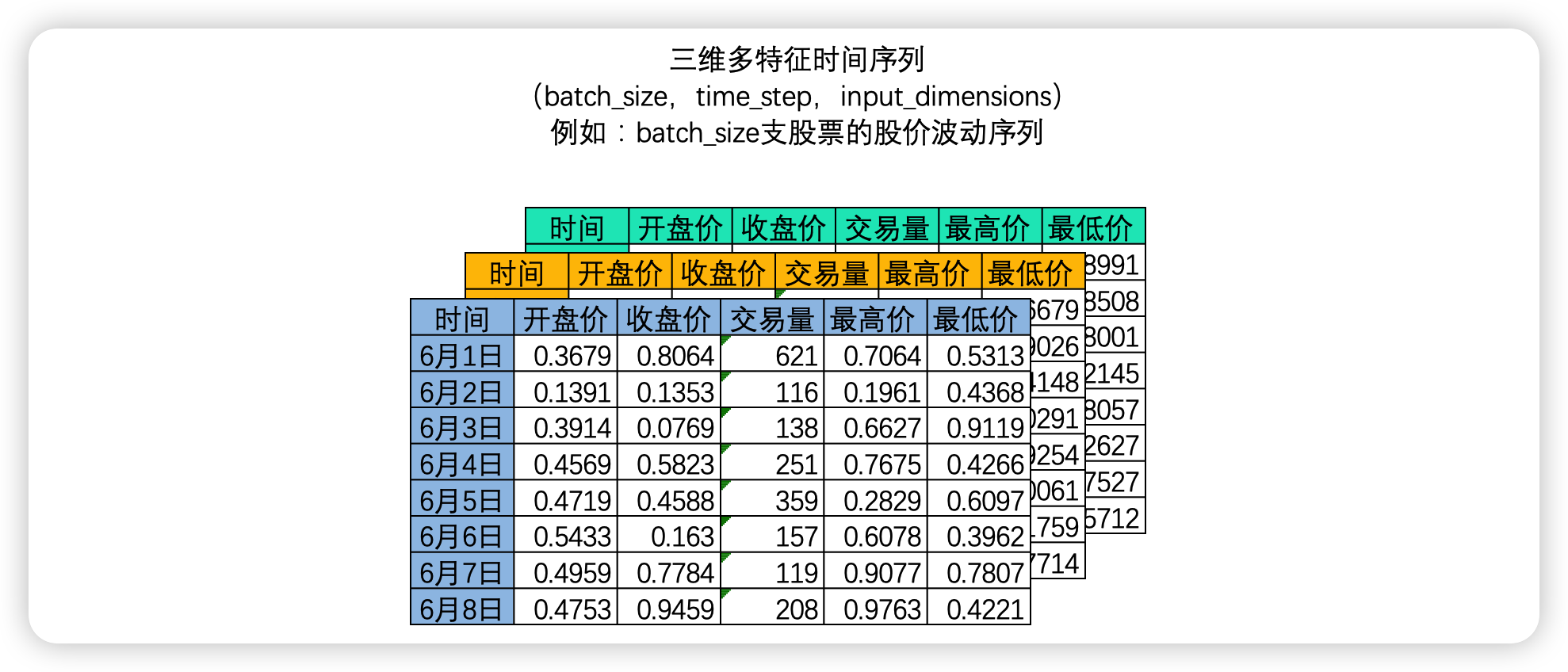
此时我们拥有的是一个三维矩阵,其中batch_size是样本量,也就是一共有多少个二维时间序列表单。你或许已经发现了,其实三维时间序列数据就是机器学习中定义的"多变量时间序列数据"。在多变量时间序列数据当中,时间和另一个因素共同决定唯一的特征值。在上面的例子中,每张时序二维表代表一支股票,因此在这个多变量时间序列数据中"时间"和"股票编号"共同决定了一个时间点上的值,如果在机器学习中,我们会看到这样的数据结构:
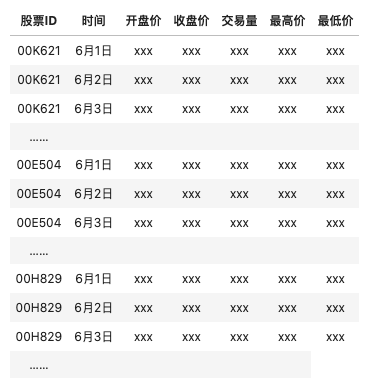
当把这张表单拆成独立的三张表单,每张表单上只显示一支股票时,就是深度学习中常见的三维时间序列数据。相似的例子还可能是------不同用户在不同时间点上的行为,不同植物在不同季节时分泌的激素值、不同商家在不同时间点上的销售额等等。
需要注意的是,虽然上述两种形式的时序数据是深度学习中最常见的时序数据,但时序数据被用于不同的算法时可能有不同的形态,有时候我们甚至不会拘泥于"时序"和"连续性"这些时间序列的常规属性,而是从时间数据的局部性和全局性来考虑,将时序数据变形为特定网络所需要的输入数据形态(例如,时间序列数据用于CNN,或时间序列数据用于GAN时,它的形态会不同于上述我们描述的形态)。
2.2 深度学习中的文字序列数据
- 二维文字序列
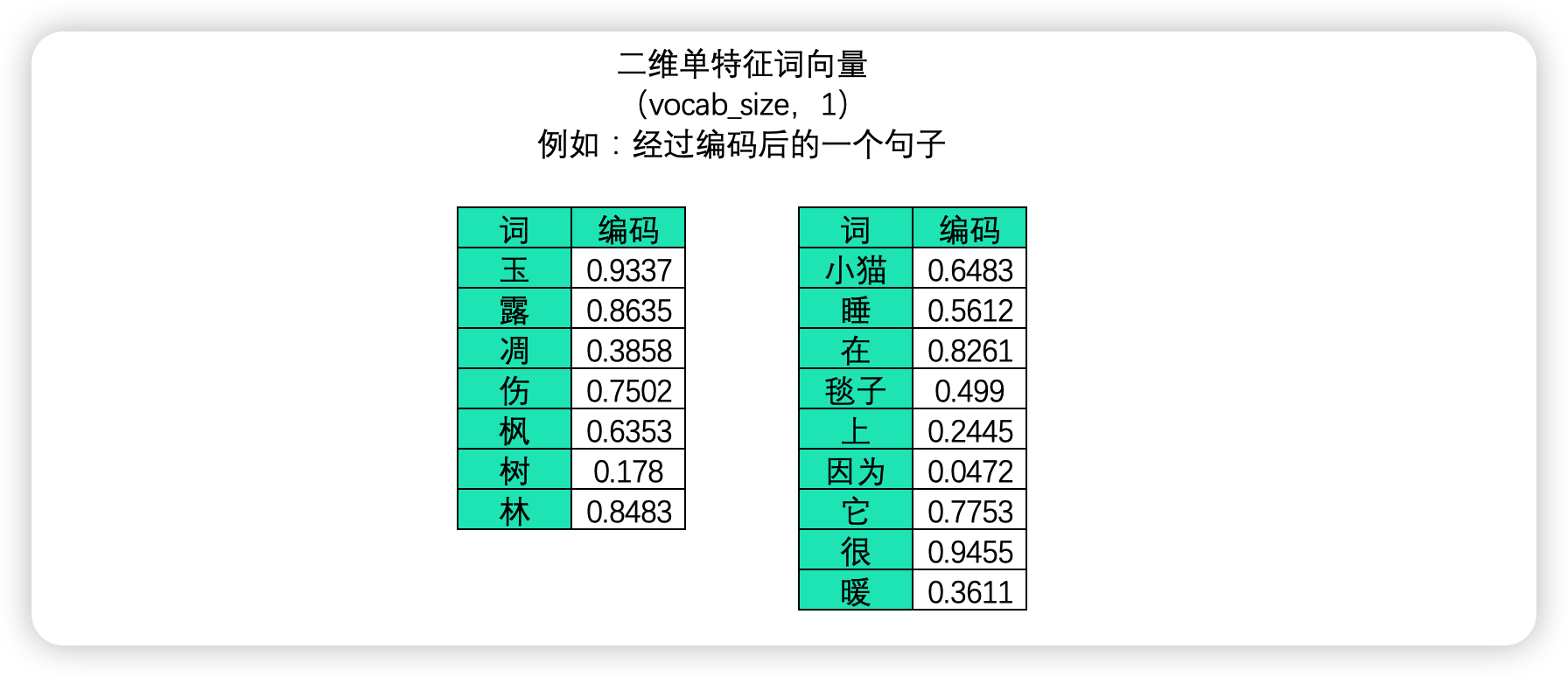
在文字数据中,样本与样本之间的联系是语义的联系,语义的联系即是词与词之间、字与字之间的联系,因此在文字序列中每个样本是一个单词或一个字(对英文来说大部分时候是一个单词,偶尔也可以是更小的语言单位,如字母或半词),故而在中文文字数据中,一张二维表往往是一个句子或一段话,而单个样本则表示单词或字。
此时,不能够打乱顺序的维度是vocab_size,它代表了一个句子/一段话中的字词总数量。一个句子或一段话越长,vocab_size也就会越大,因此这一维度的作用与时间序列中的time_step一致,vocab_size在许多时候也被称之为是序列长度(sequence_length)。同样,vocab_size这一维度上的顺序就是算法需要学习的语义顺序。
算法是不能认知文字数据的,因此我们必须将文字数据转化为"数字"来进行表示,这个过程叫做"编码"。编码是一个复杂的过程,但是现在我们不必对其进行深究,我们只需要知道,我们可以像上面的图像中一样将一个单词编码成一个数字,也可以将单词编码成一个序列。大部分时候,我们需要学习的肯定不止一个句子,当每个句子被编码成矩阵后,就会构成高维的多特征词向量。由于在实际训练时,所有句子或段落长度都一致的可能性太小(即所有句子的vocab_size都一致的可能性太小),因此我们往往为短句子进行填充、或将长句子进行裁剪,让所有的特征词向量保持在同样的维度。
- 三维文字序列
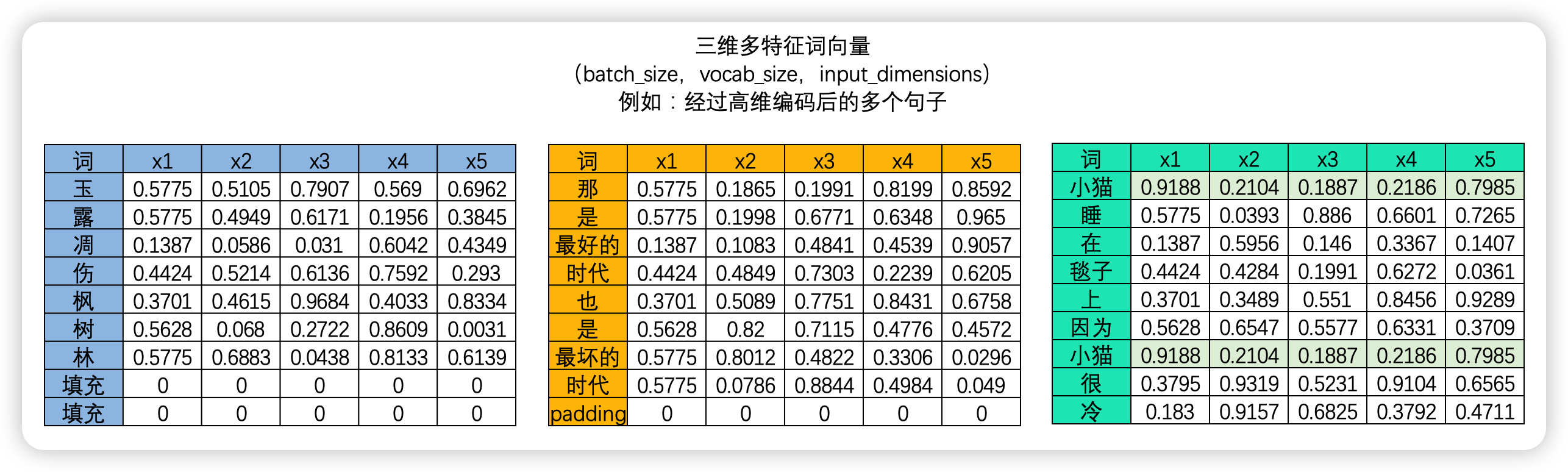
2.2.1分词操作
原始文本数据大多是段落,但是输入到深度学习中的文字数据的样本却是词或字,因此文字数据大部分时候需要进行"分词"。分词是将连续的文本切分成一个个具有独立意义的词或词组的过程,良好的分词可以降低算法理解文本的难度,可以很好地提升模型的性能。例如,将诗句"玉露凋伤枫树林"分为"玉露","调伤","枫树林"三个词,可能会比将其分为"玉","露","凋","伤","枫","树","林"7个字更容易理解,要求每个字都自带完整的语义其实会有些困难。
由于不同的语言有不同的特色,因此每种语言所使用的分词方式也大不相同。例如,英文等拉丁语系的语言天然就有空格来分割不同的单词,只要按照空格进行分词就能够自然得到很好的结果,而中文日文韩文等语言却没有空格来进行辅助,有时分词的结果可能会造成巨大的误解。例如,经典的"吃烧烤不给你带"这一句子,分割成"吃","烧烤","不给","你","带"和"吃","烧烤","不","给你","带"就会令语义有所不同,因此中文还面临着"断句"的挑战。
现在对于不同语言的分词,我们都有丰富的手段可以操作:
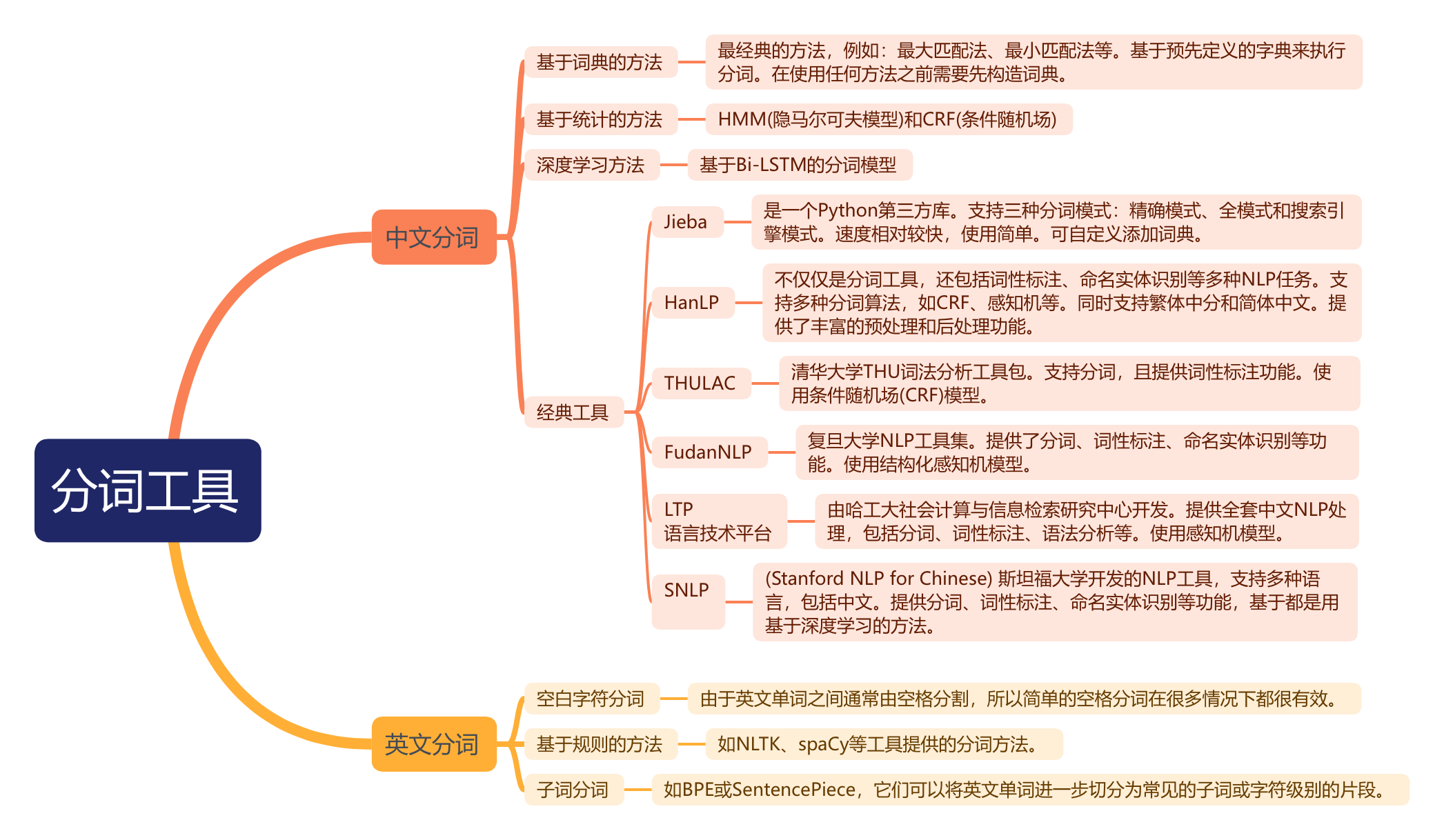
python
import thulac
def thulac_demo():
#初始化THULAC,默认模式(进行分词和词性标注)
thu = thulac.thulac(seg_only=False) # seg_only=True 表示只分词不标注
#示例文本
text = "清华大学位于北京海淀区,是一所世界著名的综合性大学。"
print("原始文本:")
print(text)
print("\n" + "="*50 + "\n")
#进行分词和标注
result = thu.cut(text, text=True)
print("分词和词性标注结果:")
print(result)
print("\n" + "="*50 + "\n")
#以列表形式返回结果
print("详细分析(列表形式):")
word_list = thu.cut(text)
for word, pos in word_list:
print(f"词语:{word:<8} | 词性:{pos}")
if __name__ == "__main__":
#基本功能演示
thulac_demo()
2.2.2 词、字与Token
Token 是自然语言处理中的重要概念,这个概念没有官方中文译名,但我们可以根据该词语在众多论文中的语境对其进行如下定义:Token是当前分词模式下的最小语义单元,根据分词的不同,它可能是一个单词、一个半词或一个字母,也可能是一个短语(攀登高峰)、一个词语(攀登、高峰)或一个字(攀、登、高、峰)。之前我们提到,分词是连续的文本切成一个具有独立意义的词或词组的过程,本质上就是分词或者分割Token的过程,因此,文字数据表单的一行行样本就是一个个Token。
Token在自然语言处理世界中有什么意义?首先,它是语义的最小组成部分,同时也是大部分深度学习算法输入数据时的"单一样本"。Token的数量代表了样本的数量,也就代表了当前文本的长度和当前算法需要处理的数据量,直接对当前算法运行需要多少资源(算力、时间、电力)产生影响,也就会影响模型开发、模型训练、模型调用的成本。在NLP和大语言模型的世界里,OpenAI等模型开发厂商以Token使用程度来计价和使用限制,我们以大模型训练和微雕时所必须使用的token数量来衡量大模型的性能。随着大模型的发展,Token已成为NLP世界中广受认可的数据量/模型吞吐量计量单位。
2.2.3 编码
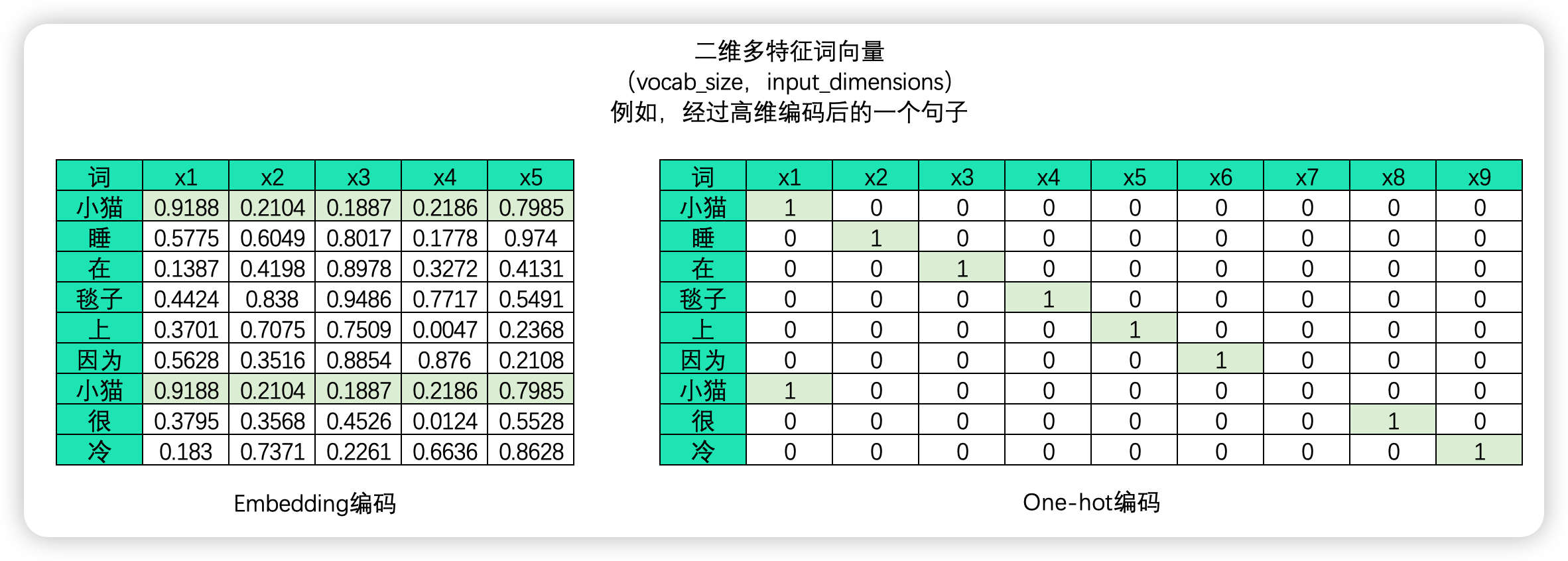
文本序列必须经过编码才能被计算机所识别。编码的方式由很多种,但无一例外,编码的本质是用单一数字或一串数字的组合代表某个字/词,在同一套规则下,同一个字被编码成同样的序列或同样的数字,而使用一个数字还是一串数字则可以由算法工程师自行决定。目前常见的编码方式有:
-
one-hot编码:将每个词表示为一个长向量,这个向量的维度等于词汇表的大小,其中只有一个维度的值为1,其余为0。这个1的位置对应于该词在词汇表中的位置。
-
词嵌入(Word Embeddings) :词嵌入是一种将词或短语映射到高维空间的表示方法,使得语义上相似的词在这个高维空间中彼此接近。例如,通过训练得到的词嵌入模型,我们可能发现"king"和"queen"、"man"和"woman"在向量空间中是相似的。词嵌入通常通过大量的文本数据训练得到,目的是捕捉单词之间的语义关系。
经典的词嵌入方法有:
-
word2vec:通过神经网络模型学习单词的词向量表示,常见的有CBOW和Skip-Gram两种模型。
-
Glove(Global Vectors for Word Representation): 基于单词共现统计信息来学习单词的词向量表示。
-
FastText:与Word2Vec类似,但考虑了单词内部的子词信息。
-
固定编码:例如使用BERT、GPT等预训练的深度学习模型来编码文本。这些模型通常使用大量数据进行预训练,并可以为新任务进行微调。
-
基于大语言模型:在OpenAI研发的大模型生态矩阵当中,存在专用于构建语义空间的embeddings大模型。
除了最为经典的one-hot和embedding之外,还有以下方法可以进行编码:
TF-IDF:基于单词在文档中的频率和整个数据集中的反向文档频率来为单词分配权重。
Byte Pair Encoding(BPE)/SentencePiece:这是子词级别的编码,能够处理词汇外的单词和多种语言的文本。
ElMo:深度上下文化词嵌入,考虑了单词的上下文信息来生成词向量。
Seq2Seq等序列变化模型:如果将"编码"的概念拓展到"如何将非结构化数据(如文本)转换为结构化的数字表示",那seq2seq等序列转化模型也可以作为编码的手段之一。seq2seq,即sequence-to-sequence,是一个在多种NLP任务中广泛应用的神经网络结构,常常被用在机器翻译、文本摘要、问答系统等需要从一个序列生成另一个序列的任务中,因此seq2seq本质与encoder-decoder非常相似,是输入序列、输出序列的模型。seq2seq模型的编码器涉及到了与文本编码很类似的过程,它将输入序列(如一个句子)转换为一个固定大小的向量。但这个向量通常是为了特定的seq2seq任务(如翻译)而生成的,并不是用于一般的文本表示。因此,虽然seq2seq的编码器确实进行了"编码",但它和我们之前讨论的文本编码方法(如Word2Vec或TF-IDF)有些不同。
三、循环神经网络
循环神经网络(Recurrent Neural Network)是自然语言处理领域的入门级深度学习算法,也是序列数据处理方法的经典代表作,它开创了"记忆"方式、让神经网络可以学习样本之间的关联、它可以处理时间、文字、音频数据,也可以执行NLP领域最为经典的情感分析、机器翻译等工作。在NLP领域,循环神经网络是GRU、LSTM以及许多经典算法的基础、更对我们理解transformer结构有巨大的帮助,因此即便在Transformer和大语言模型统治前沿算法战场的今天,我们依然需要学习RNN算法。RNN就仿佛机器学习中的逻辑回归算法一般,是打开NLP领域大门的钥匙。
3.1 RNN的基本架构与数据流
RNN循环神经网络由输入层、隐藏层和输出层构成,并且这三类层都是线性层。和深度神经网络中的线性层一样,输入层的神经元个数由数据的特征数量决定,隐藏层和隐藏层上神经元的个数都可以自己设置,而输出层的神经元数量则需要根据输出的任务目标进行设置。以下面的数据为例,现在我们将每个单词都编码成了5个特征构成的词向量,因此输入层就会需要5个神经元,我们将该文字数据输入循环神经网络执行三分类的"情感分类"任务(三分类分别是积极,消极,中性),那输出层就会需要三个神经元。假设有一个隐藏层,而隐藏层上有2个神经元,一个最为简单的循环网络的网络结构如下:
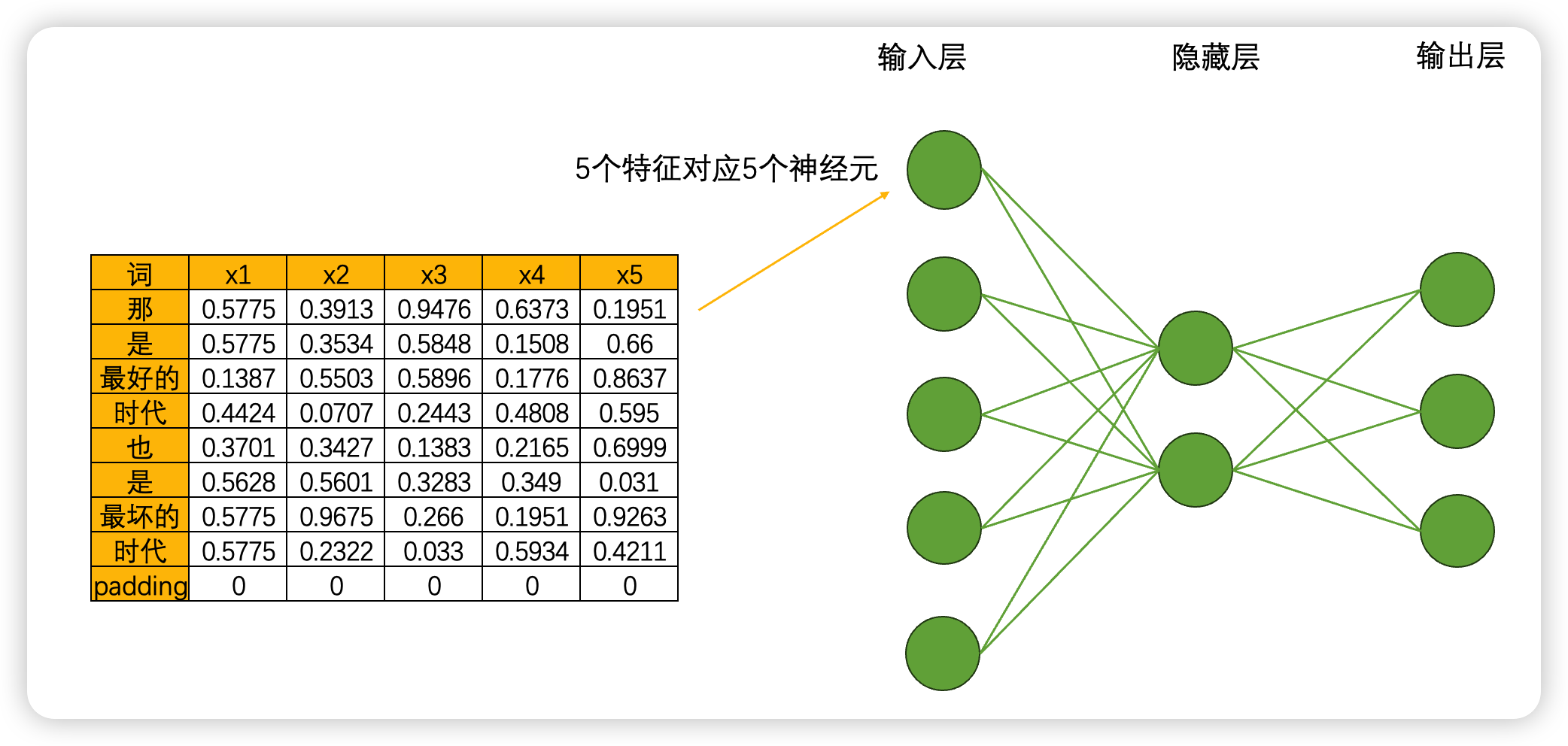
当我们将数据输入深度神经网络DNN时,一个神经元会一次性处理一列数据,5个神经元会涵盖整张表的数据,在一次正向传播中深度神经网络就会接触到完整的一张数据表。这种方式计算效率很高,同时矩阵计算也很简单:输入结构为(9,5),中间层输出为(9,2),最终输出结果为(9,3),整个计算过程完全只考虑每个单词的特征之间的转换(5➡️2➡️3),而完全忽略"单词与单词之间的联系",毕竟输入9个单词,输出9个单词,并没有对单词之间的关系进行任何学习。
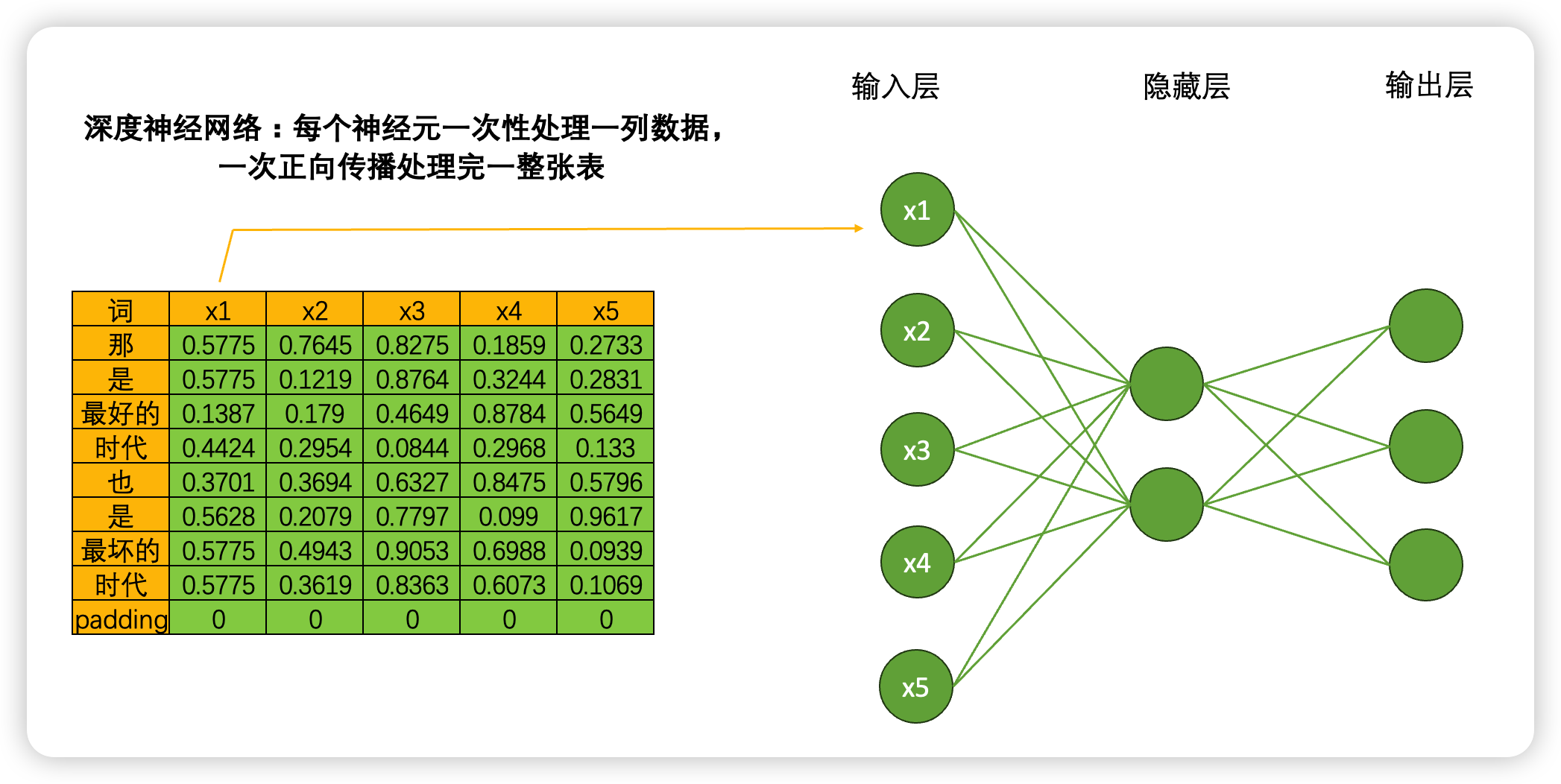
但是,在循环神经网络当中就不一样了。虽然是一模一样的网络结构,但当我们将数据输入到循环神经网络时,一个神经元一次性只会处理一行(也就是一个单词)的数据,5个神经元会覆盖当前单词的5个特征,在一次正向传播中,循环神经网络只会接触到一个单词的全部信息,而不会接触到整张表。
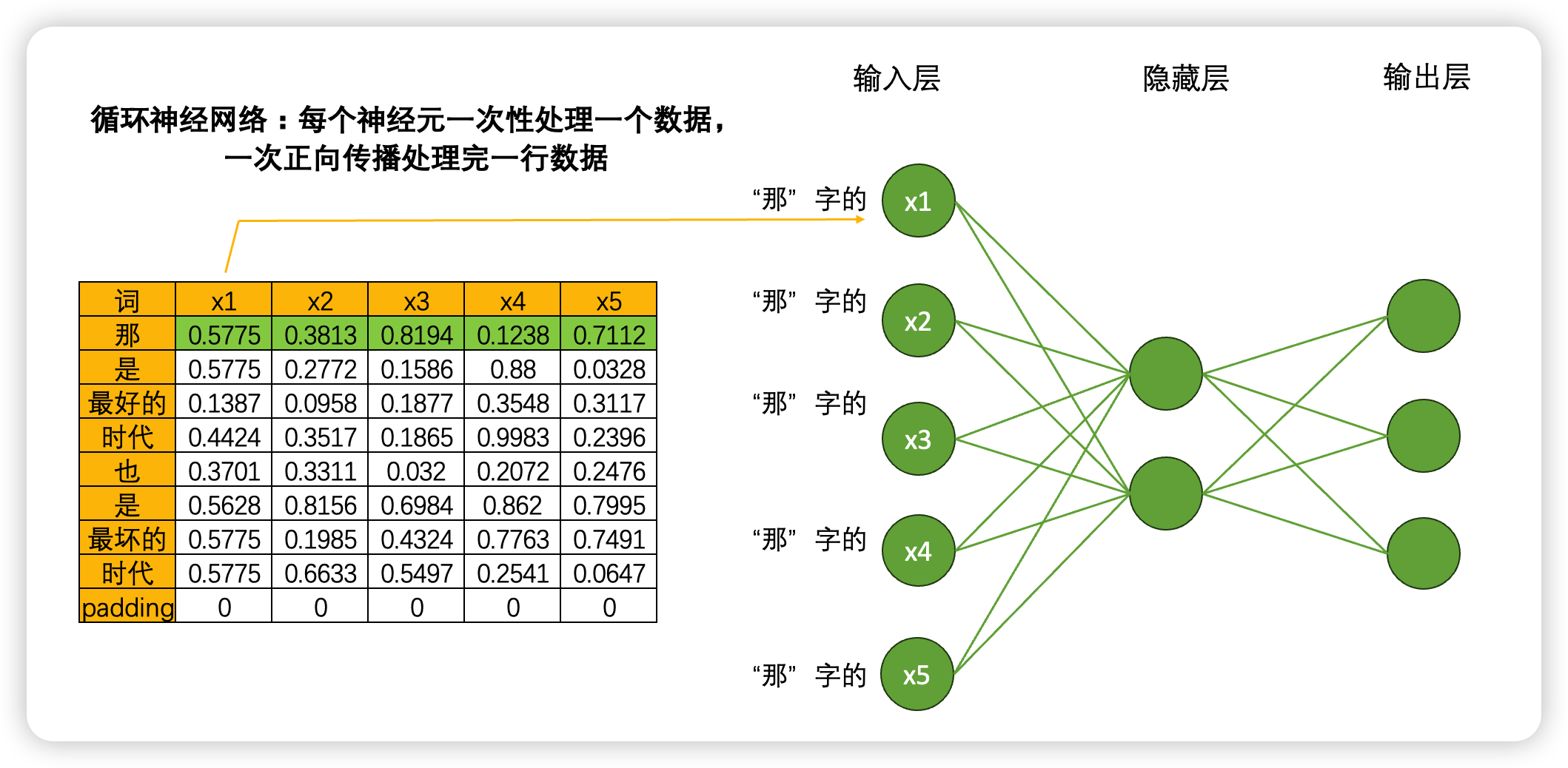
如果这样的话,岂不是要一行一行处理数据了?没错!虽然非常颠覆神经网络当中对效率的根本追求,但循环神经网络是一个单词、一个单词地处理文本数据,一个时间点、一个时间点处理时序数据的。具体过程如下:

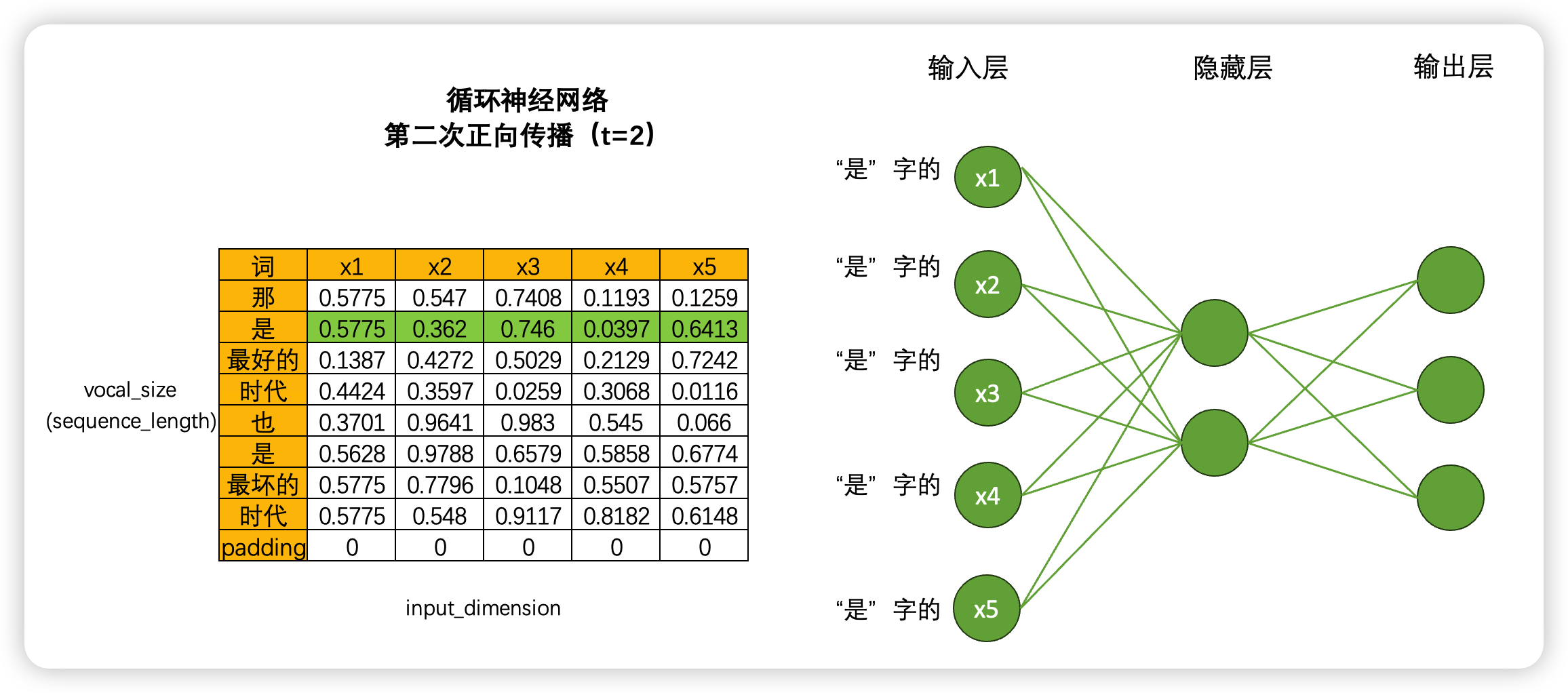

如果一次正向传播只处理一行数据,那对于结构为(vocab_size,input_dimension)的文字数据来说,就需要在同一个网络上进行vocab_size次正向传播。同样的,对于结构为(time_step,input_dimension)的时间序列数据来说,就需要在同一个网络上进行time_step次正向传播。所以为了便利,vocab_size和time_step这个维度可以统称为时间步,对任意数据来说,循环神经网络都需要进行时间步次正向传播,而每个时间步上是一个单词或一个时间点的数据。
基于这样的数据流设置,循环神经网络构建了自己的灵魂结构:循环数据流。在多次进行正向传播的过程中,循环神经网络会将每个单词的信息向下传递给下一个单词,从而让网络在处理下一个单词时还能够"记得"上一个单词的信息。
如下图所示,在Tt−1时间步上时,循环网络处理了一个单词,此时隐藏层上输出的中间变量Ht−1会走向两条数据流,一条数据流是继续向输出层的方向正向传播,另一条则流向了下一个时间步的隐藏层。在Tt时间步时,隐藏层会结合当前正向传播的输入层传入的Xt和上个时间不的隐藏层传来的中间变量Ht−1共同计算当前隐藏层的输出Ht。如此,Ht当中就包含了上一个单词的信息。
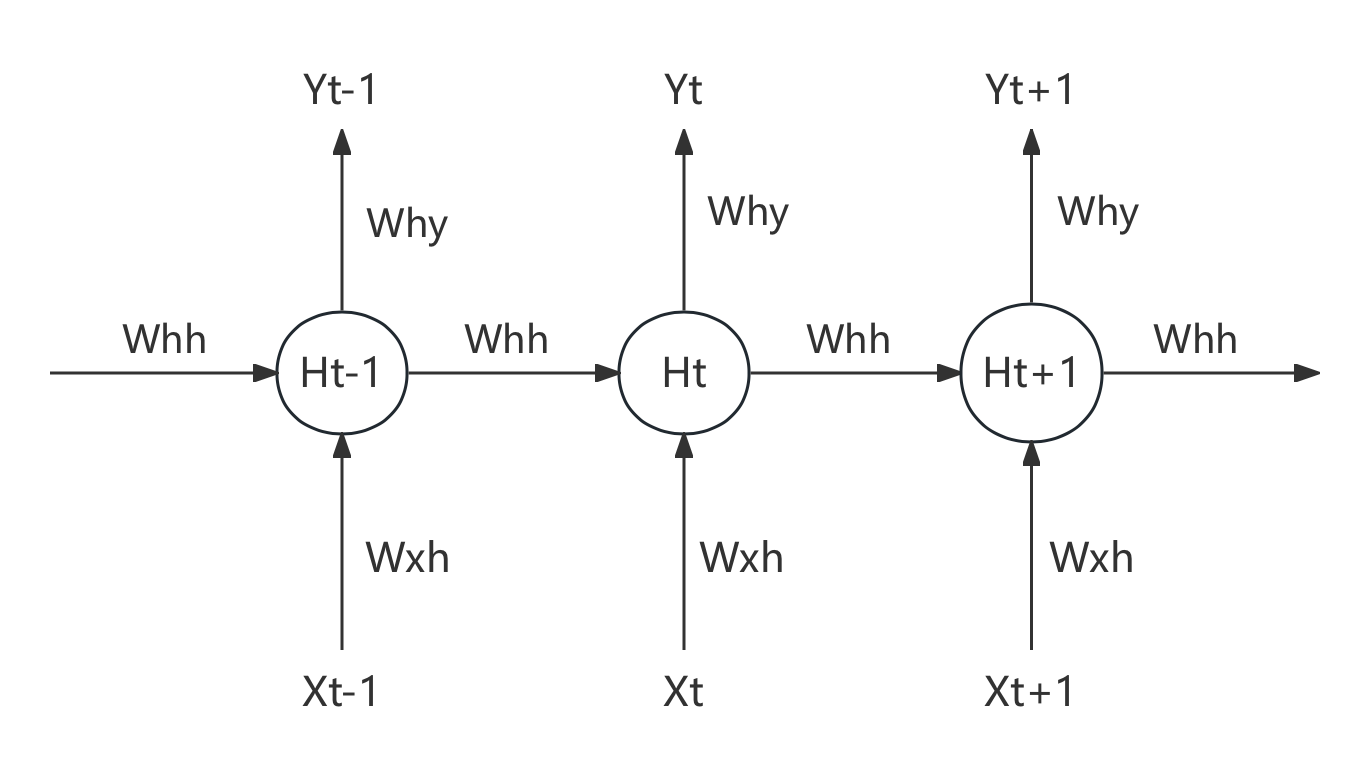
利用这种方式,只要进行vocal_size次向前传播,并且每次都将上一个时间步中隐藏层上诞生的中间变量传递给下一个时间步的隐藏层,整个网络就能在全部的正向传播完成后获得整个句子上的全部信息。在这个过程中,我们在同一个网络上不断运行正向传播,此过程在神经网络结构上是循环的,在数据逻辑上是递归,这也正是循环神经网络名称的由来。
在这个过程中,H被称之为是"隐藏状态"(Hidden Representation 或 Hidden State),它特指在循环神经网络的隐藏层上诞生的中间变量,一般在代码中也表示为小写的字母h。当然,在循环神经网络中我们也是可以有多个隐藏层的,虽然我们的图像上只显示了最为简单的情况(一个输入层、一个隐藏层、一个输出层)。
3.2 RNN的效率问题与权重共享
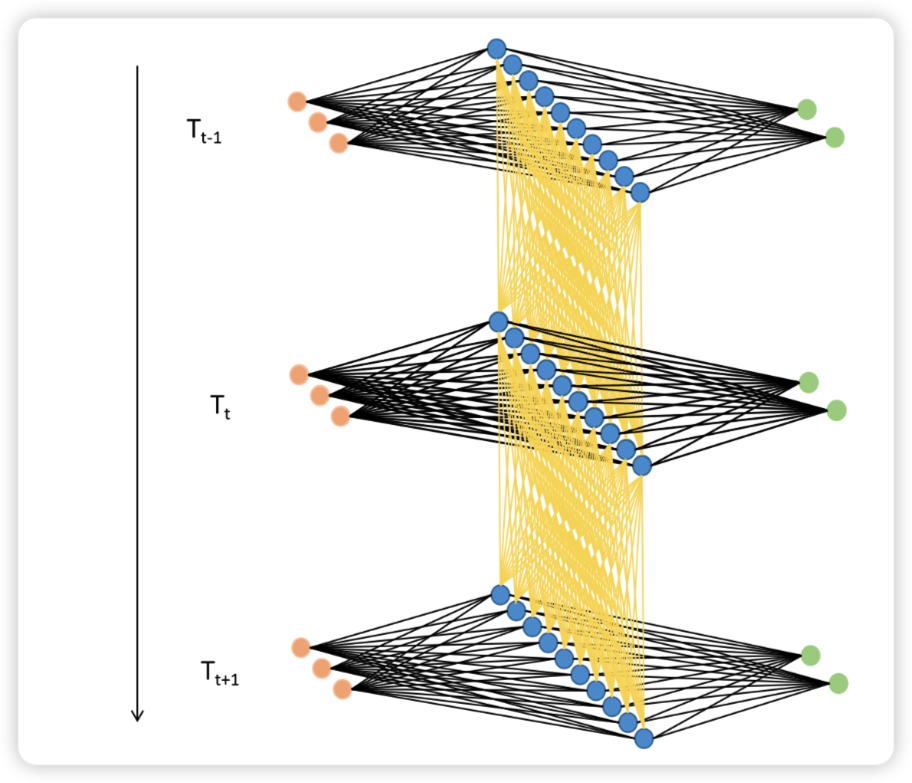
RNN作为递归神经网络,在保证预测准确率的基础上牺牲了一部分效率。刚才我们以一张表为例讲解了循环神经网络的迭代过程,但循环网络在实际应用时可能面临batch_size张表单,如果每张表单都需要一行一行进行向前传播的话,那循环神经网络运行一次需要(batch_size * time_step)次向前传播,这样整个网络的运行效率必然是非常非常低的。
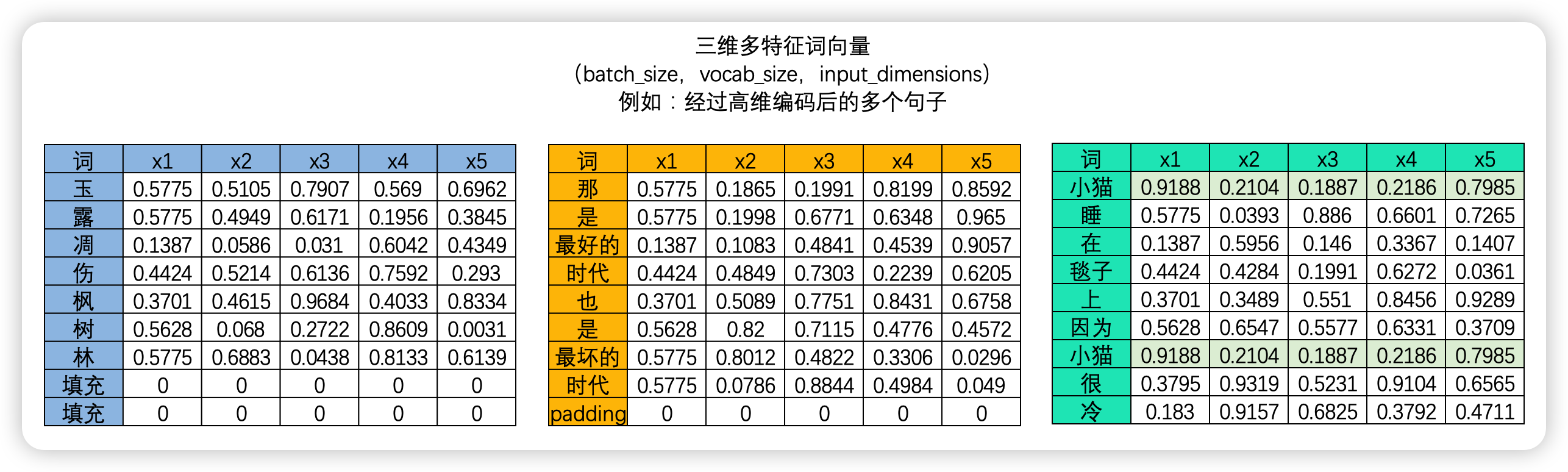
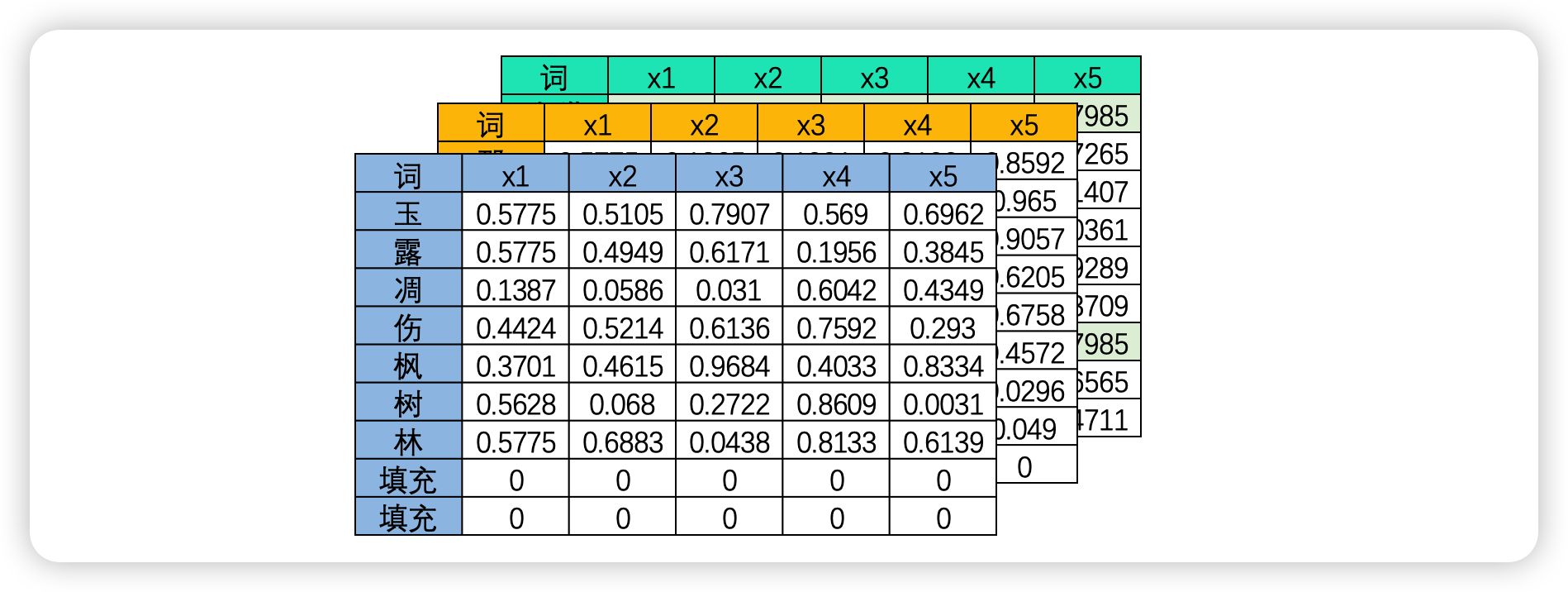
幸运的是,事实上这个问题并不存在。在现实中使用循环神经网络的时候,我们所使用的输入数据结构往往是三维时间或三维文字数据,也就是说数据中大概率会包括不止一张时序二维表、会包括不止一个句子或一个段落。之前我们提到过,循环神经网络要顺利运行的前提是所有的句子/时间序列被处理成同等的长度,因此编码后每张二维表需要循环的时间步数量是相等的,因此在实际训练的时候循环神经网络是会一次性将所有的batch_size张二维表的第一行数据都放入神经元进行处理,故而RNN并不需要对每张表单一一处理,而是对全部表单的每一行进行一一处理,所以最终循环神经网络只会进行time_step次向前传播,所有的batch是共享权重的。
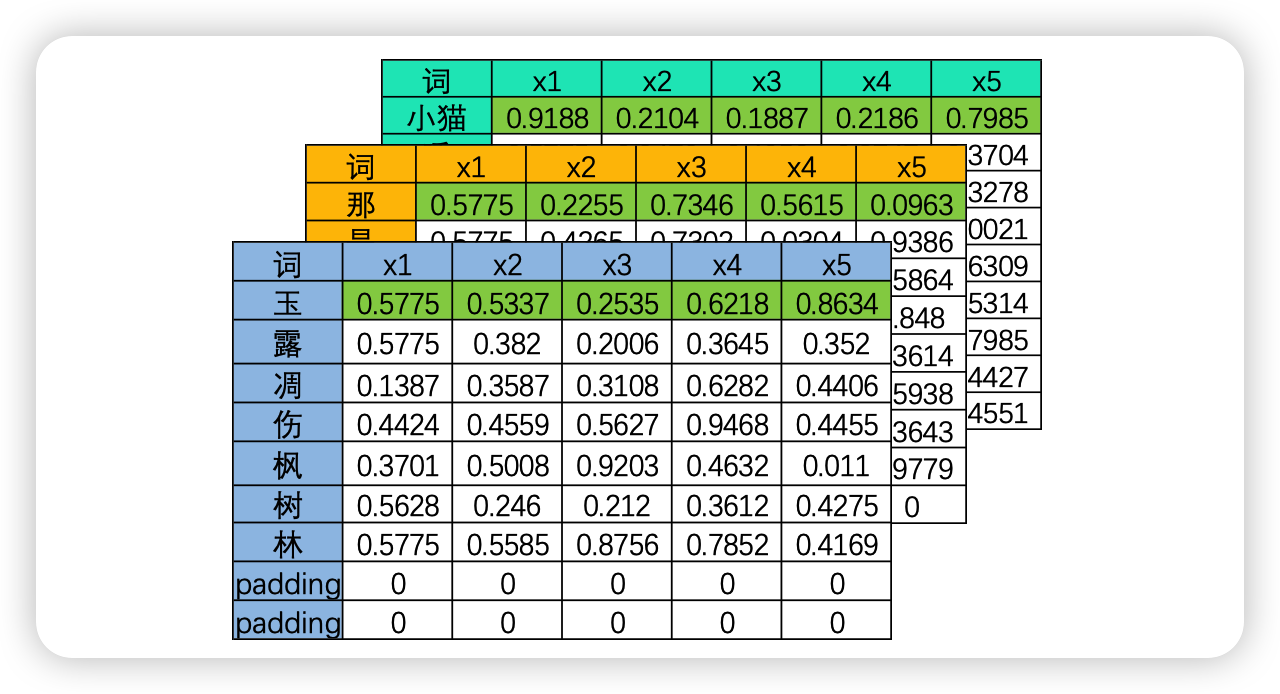
如果将三维数据看作是一个立方体,那循环神经网络就是一次性处理位于最上层的一整个平面的数据,因此循环神经网络一次性处理的数据结构与深度神经网络一样都是二维的,只不过这个二维数据不是(vocal_size,input_dimension)结构,而是(batch_size,input_dimension)结构罢了。
3.3 RNN的输入与输出结构
- 输入结构
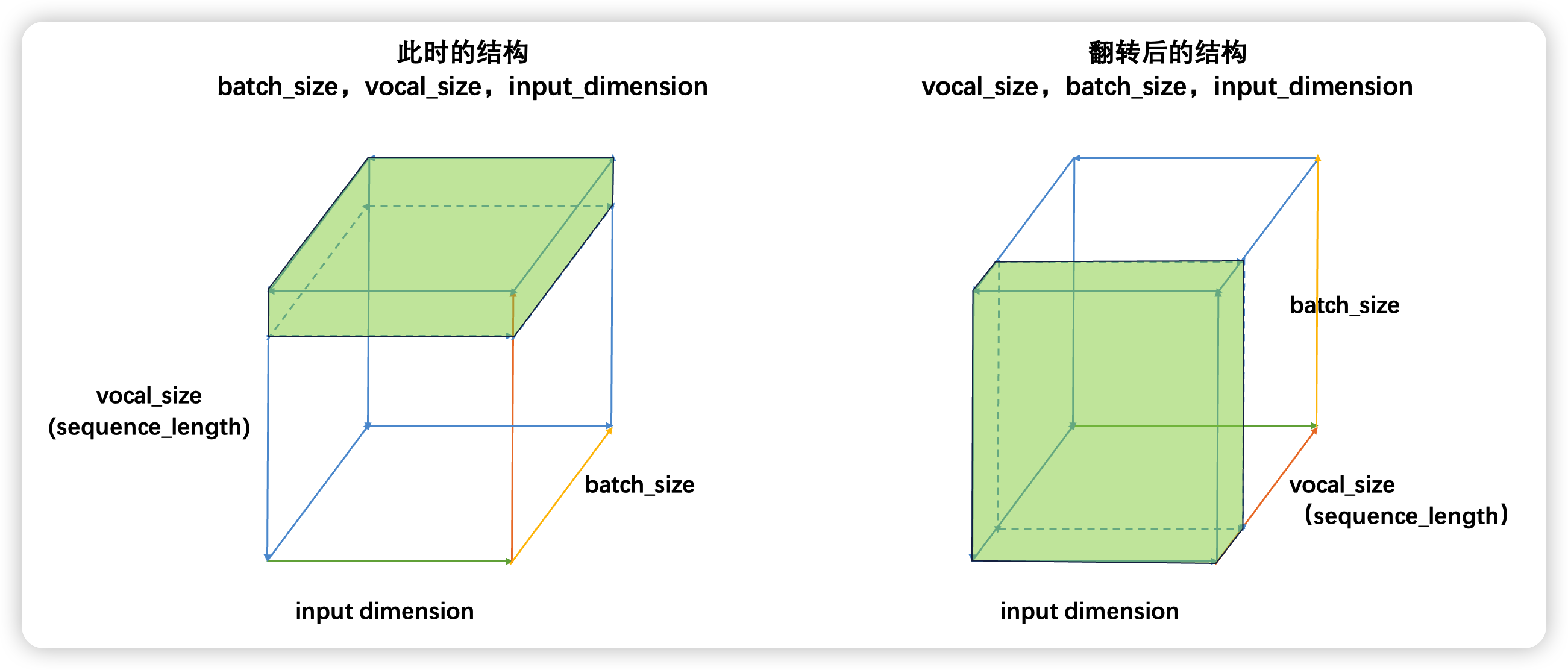
PyTorch或Tensorflow深度学习框架下,循环神经网络的输入结果一律为三维数据。最常见的结构就是(batch_size, vocal_size, input_dimension),且循环是在vocal_size维度上进行的。但是有一些才俩中,循环神经网络的输入也被描述为(vocal_size, batch_size, input_dimension)结构。事实上,这两种结构是同一种结构,具体如下:
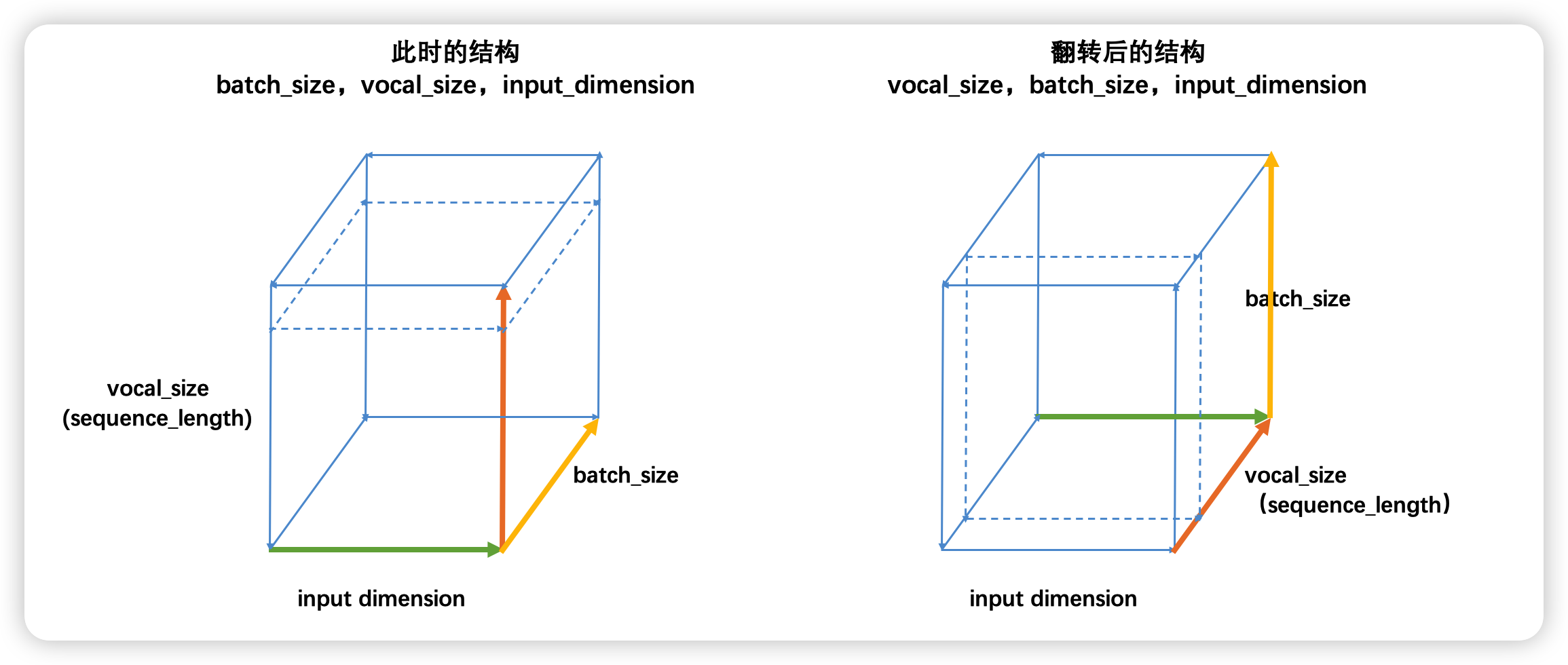
普通的结构(batch_size,vocal_size,input_dimension)如左图,此时循环神经网络会在vocal_size这一维度上循环,执行vocal_size个时间步的正向传播、即从上至下不断处理面向上方的二维表单(虚线标注处)。但立方体是可以被旋转的,当我们将立方体旋转一个角度,即需要处理的二维表单由正上方专向正前方时,我们就得到了(vocal_size,batch_size,input_dimension)的数据结构,此时循环神经网络依然是在vocal_size方向进行循环,只不过我们需要处理的表单方向由从上到下变成了从前往后。
因此不难发现,本质上这两种结构是一模一样的,但无论是哪种结构,循环神经网络都必须在时间步的方向进行循环。对于时序数据来说,这个方向是time_step的方向,对于文字数据来说,这个方向是vocab_size的方向。
- 输出结构
循环神经网络的输出层结构由具体的输出任务来决定。但丰富的NLP任务让RNN输出变得丰富多彩。我们将NLP任务大致分为以下三类:
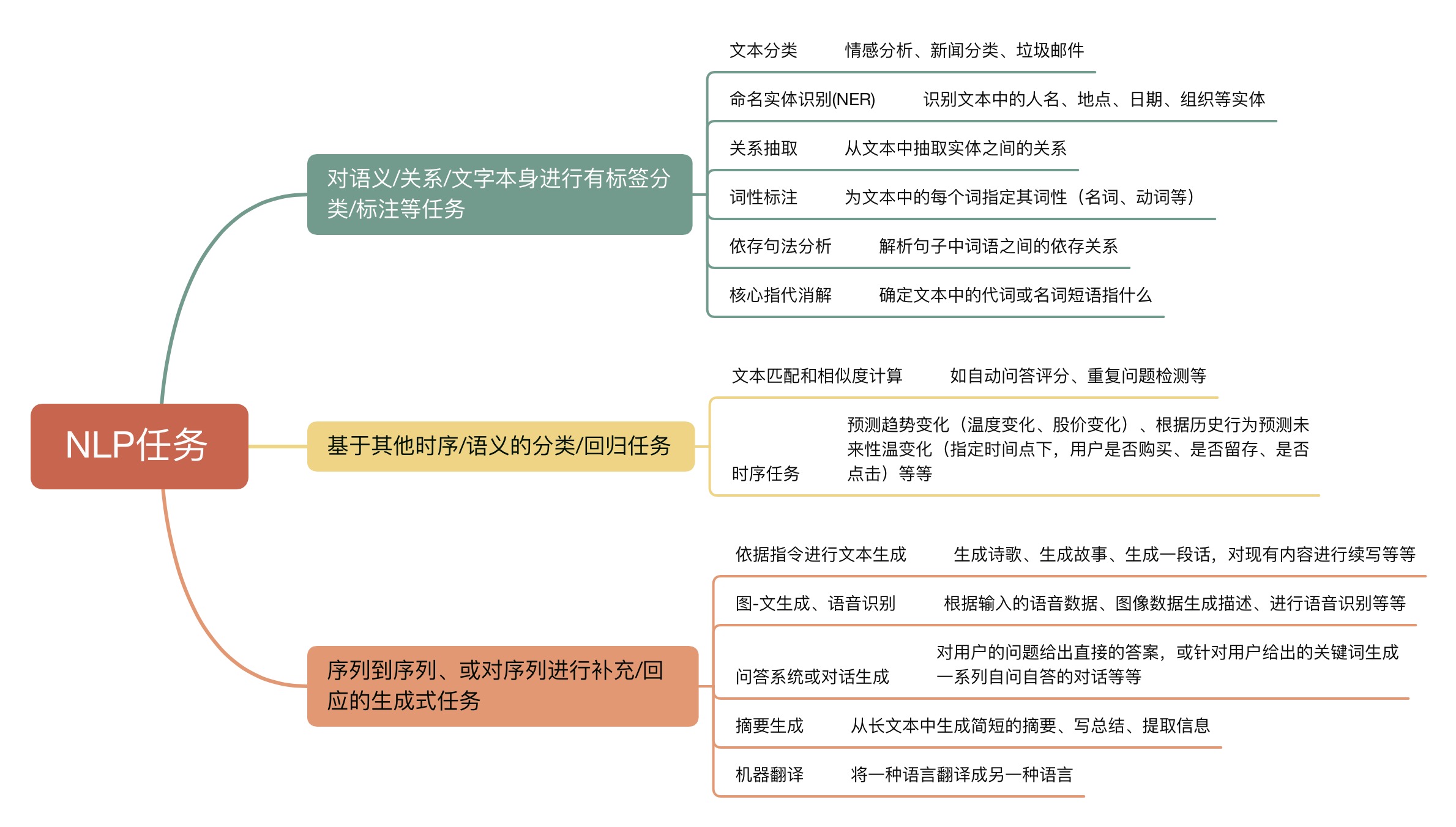
尽管NLP世界的预测任务都有非常专业的流程,但总体来说生成式任务的流程比分类/回归任务要复杂得多。在生成式任务中,RNN需要一个字、一个字、或一个词一个词地进行生成,在多次生成中逐渐构建出一个完整的句子或段落(所以你可能会观察到,ChatGPT这样的产品在说话的时候是一个词一个词往外蹦),所以生成式RNN的输出层和分类任务中的输出层有很大的区别。
首先,NLP算法的生成并不能"无中生有",模型只能从它曾经见过的字/词/短语中挑选它认为当下最能在语义上自洽的字/词/短语来进行输出,所以生成的本质是"在模型曾见过的字/词/短语中,挑选出最有可能使句子语义自洽的那个字/词/短语"。在进行实际生成时,模型会对它所见过的每个字/词/短语都输出一个概率,预测这个字/词/短语是当前最佳输出的可能性,再从中挑选出可能性最高或较高的词进行输出。因此本质上来说,生成模型是多分类概率模型。
所以不难发现,一个生成式模型想要进行灵活、丰富的文字生成,就必须先见过巨量文字数据。同时,分词越细致,生成式模型在生成时的创造力就会越强。如果模型是基于字符级别的,那么输出层的神经元数量就是所有可能字符的数量,模型就可能基于字符构建新的词语。如果模型是基于词级别的,那么输出层的神经元数量就是词汇表中所有词的数量,模型就可能基于词语构建新的短语。但这样,模型自然对数据量、算力就会有更高的要求。
当然,在实际进行生成式任务时,我们会有很多手段来结局生成式模型中的问题------例如,每次预测下一个字时都必须对全部的数十万个字/单词生成概率,那计算效率实在是会过低;同时,如果模型只能生成"曾经见过"的词/短语的话,那远远达不到具备"认知智能"的水准,因此业内也有相当多的手段用于增强语言模型的创造力和泛化能力。在后续我们讲解Transformer的生成式案例时,我们将会详细展开来聊聊这些技术。
3.4 在PyTorch中实现循环神经网络
在了解循环神经网络的基本原理之后,我们可以借助PyTorch来实现循环神经网络了。在之前的课程当中,我们已经认识了PyTorch框架的基本结构,整个PyTorch框架可以大致被分Torch和成熟AI领域两大板块,其中Torch包含各类神经网络组成元素、用于构建各类神经网络,各类AI领域中则包括Torchvision、Torchtext、Torchaudio等辅助完成图像、文字、语音方面各类任务的领域模块。
本小节重点介绍的就是nn.RNN类:class torch.nn.RNN(input_size, hidden_size, num_layers, nonlinearity, bias, batch_first, dropout, bidirectional, *args, **kwargs)
不难发现,这是一个参数很少、相当简单的类。虽然该类的名字叫做循环神经网络,但实际上nn.RNN是循环层,它是在线性层的基础上改进后的层,除了线性层的基本功能(匹配权重、神经元结果加和、激活函数、向前向后传播等)外,循环层还负责执行我们在讲解RNN的原理时提到的"将上个时间步的中间变量传递给下个时间步"的功能。我们来看看这些nn.RNN的几个重要参数:
- input_size:输出特征的数量,也是输入层的神经元数量。
- hidden_size:隐藏层的神经元数量,也是隐藏状态h的特征数量。
- nonlinearity:激活函数,可选择"tanh"或"relu",这是RNN论文中默认的两个选项。
- batch_first:如果为True,输入和输出Tensor形状为batch_size, seq_len,input_dimension,否则为seq_len, batch_size,input_dimension。当数据是时间序列数据时,seq_len是time_step,当数据是文字序列时,seq_len是vocab_size。注:默认值是False,所以pytorch官方使用的结构式seq_len,batch_size, input_dimension。
同时,RNN的输出有两个:output和h_
- output:所有时间步在最后一个隐藏层上输出的隐藏状态的集合。很显然,对于单层神经网络来说,output代表了唯一一个隐藏层上的隐藏状态。output的shape为:seq_len,batch_size, hidden_size。
- h_:最后一个时间步在所有隐藏层上输出的隐藏状态,它的shape为:num_layers, batch_size, hidden_size。
不难发现,虽然每个时间步、每个隐藏层都会输出隐藏状态,但是RNN类却只会"选择性"地帮助我们输出部分隐藏状态,例如output在深层神经网络中只会保留最后一个隐藏层的隐藏状态,而hn则是只显示最后一个时间步的隐藏状态。通常来说当我们在实现rnn时,所有隐藏状态都是需要向下一个时间步、以及下一个隐藏层传递的,因此output和hn都不能代表nn.RNN层在循环中所传输的信息。
当然,在很多情况下,我们确实也只会关心最后一个时间步的隐藏状态,或者最后一个隐藏层的隐藏状态。output关注全部时间步,hn关注全部隐藏层,在NLP经典任务当中------
- 如果我们需要执行对每一个时间步进行预测的任务(比如,预测每一分钟的股价,预测明天是否会下雨,预测每个单词的情感倾向,预测每个单词的词性),此时我们就会关注每个时间步在最后一个隐藏层上的输出。此时我们要关注的是整个output。
- 如果我们需要执行的是对每张表单、每个句子进行预测的任务时(比如对句子进行情感分类,预测某个时间段内用户的行为),我们就只会关注最后一个时间步的输出。此时我们更可能使用hn。
但需要注意的是,无论是output还是hn,都只是循环层的输出,不是循环神经网络真正的输出,因为nn.RNN层缺乏关键性结构 :输出层。一般来说,我们不会把循环层的输出直接当作RNN的输出,但这个操作也不是完全不符合规定,毕竟很多时候,我们可能会结合RNN和其他更高级的神经网络,此时循环层的输出需要作为其他神经网络的输入来使用,那循环层本身也可以被认为是构建了一个"网络"本身,但这种定义是不严谨的,通常来说我们还是需要给循环神经网络加上一个输出层。
3.4.1 单层循环神经网络
python
import torch
from torch import nn
import time
#假设一个文字数据,序列长度为3(时间步为3)
input = torch.randn((3, 50, 10)) #seq_len(vocal_size),batch_size,input_dimension
rnn1 = nn.RNN(input_size=10, hidden_size=20)
output1, h1 = rnn1(input)
print(output1.shape) #torch.Size([3, 50, 20])
#output1是所有步长在最后一个隐藏层上的状态,所以shape为torch.Size([3, 50, 20])
print(h1.shape)#torch.Size([1, 50, 20])
#h1表示最后一个步长在所有隐藏层上的状态,由于只有一个隐藏层,所以shape为torch.Size([1, 50, 20])
#针对output,我们索引初最后一个时间片上、第一个batch---size的隐藏层状态
print(output1[-1, 0, :])
'''
tensor([ 0.6173, 0.0858, -0.5784, 0.3460, -0.4437, 0.3020, 0.1443, -0.2846,
-0.5002, 0.3178, 0.3004, 0.0424, -0.7142, 0.6787, -0.7725, 0.2024,
0.2961, 0.2179, 0.5354, -0.1324], grad_fn=<SliceBackward0>)
'''
#此时,我们与h1第一个batch-size的隐藏层状态进行对比
print(h1[:, 0, :])
'''
tensor([ 0.6173, 0.0858, -0.5784, 0.3460, -0.4437, 0.3020, 0.1443, -0.2846,
-0.5002, 0.3178, 0.3004, 0.0424, -0.7142, 0.6787, -0.7725, 0.2024,
0.2961, 0.2179, 0.5354, -0.1324], grad_fn=<SliceBackward0>)
'''3.4.2 深度循环神经网络
和普通的循环神经网络比起来,深度循环神经网络是指不只有一个隐藏层的神经网络。在这里,我们需要来查看nn.RNN两个关键的参数:
- num_layers: 隐藏层的层数,不过这里的隐藏层除了向下一个隐藏层输送数据外,还需要向下一个时间步上的同层的隐藏层输送数据。
- hidden_size: 隐藏层的神经元数量,也是隐藏状态h的特征数量。注意,无论有多少隐藏层,当前参数都只能填写一个数字,这说明在PyTorch中,循环神经网络的每一层隐藏层的尺寸都是相同的,在实践情况下这种设计可以满足大部分的需求。从实践的角度看,当我们有多个堆叠的RNN层时,为每一层都设定一个不同的隐藏层大小可能会让模型的设计和维护变得复杂(也很没必要)。因此,一般的做法是为所有的RNN层使用相同的隐藏单元数。这简化了模型的设计和超参数调整。当然,从RNN的原理角度来说,我们可以自由设置每一个隐藏层的神经元数量。
python
import torch
from torch import nn
import time
#假设一个文字数据,序列长度为3(时间步为3)
input = torch.randn((3, 50, 10)) #seq_len(vocal_size),batch_size,input_dimension
drnn1 = nn.RNN(input_size=10, num_layers=4, hidden_size=20)
output2, h2 = drnn1(input)
print(output2.shape) #[seq_len(vacal_size), batch_size, input_dimension]
#torch.Size([3, 50, 20])
#输出的是所有步长在最后一个隐藏层上的隐藏状态
print(h2.shape) #输出的是最后一个时间步的所有隐藏层的隐藏状态
#torch.Size([4, 50, 20])
print(output2[-1, 0, :]) #提取最后一个时间步上第一个batch_size在最后一个隐藏层上的隐藏状态
'''
tensor([ 0.3607, 0.3325, 0.0405, 0.4199, 0.3999, -0.0055, 0.0713, -0.0035,
0.3690, 0.2328, -0.1301, -0.3315, 0.4026, 0.6789, 0.1924, 0.1916,
0.5495, 0.1747, -0.6020, 0.0021], grad_fn=<SliceBackward0>)
'''
print(h2[-1, 0, :]) #提取最后一个时间步上第一个batch_size在最后一隐藏层上的隐藏状态,其中-1表示最后一个最后一个隐藏层
'''
tensor([ 0.3607, 0.3325, 0.0405, 0.4199, 0.3999, -0.0055, 0.0713, -0.0035,
0.3690, 0.2328, -0.1301, -0.3315, 0.4026, 0.6789, 0.1924, 0.1916,
0.5495, 0.1747, -0.6020, 0.0021], grad_fn=<SliceBackward0>)
'''接下来就让我们使用nn.RNN来实现一个简单的深度循环神经网络,我们设置输入层为100个神经元,输出层为3个神经元(假设这是一个最为单纯的三分类任务,需要对每个句子进行情感分类),其中每个隐藏层都有256个神经元。
对句子层面进行预测(关注最后一个时间步上的输出):
注:RNN多层神经网络无法给不同RNN层设置不同的隐藏层神经元个数,只能保证4层RNN层的神经元个数保持一致。
python
import torch
from torch import nn
import time
#假设一个文字数据,序列长度为3(时间步为3)
input = torch.randn((3, 50, 10)) #seq_len(vocal_size),batch_size,input_dimension
class myRNN(nn.Module):
def __init__(self,input_size=10, num_layers=4, hidden_size=256, output_size=3):
super(myRNN, self).__init__()
#创建一个RNN模块,里买包含了4个隐藏层
self.rnn = nn.RNN(input_size=input_size, num_layers=num_layers, hidden_size=hidden_size)
#输出层是需要单独建立的
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
#x的形状为(seq_len, batch_size, input_size)
#传入x
output, hn = self.rnn(x)
#我们关心的是最后一个时间步的输出,可以从output中索引
predict = self.fc(output[-1, :, :]) #output[-1, :, :]的shape为(1,batch_size, hidden_size)
#也可以从hn中索引
#predict = self.fc(hn[-1, :, :])#hn[-1, :, :]的shape为(1,batch_size, hidden_size)
return predict
model = myRNN()
print(model)
'''
myRNN(
(rnn): RNN(10, 256, num_layers=4)
(fc): Linear(in_features=256, out_features=3, bias=True)
)
'''
print(model.forward(input).shape)
#torch.Size([50, 3])初始化hn:
python
import torch
from torch import nn
import time
#假设一个文字数据,序列长度为3(时间步为3)
input = torch.randn((3, 50, 10)) #seq_len(vocal_size),batch_size,input_dimension
class myRNN(nn.Module):
def __init__(self,input_size=10, num_layers=4, hidden_size=256, output_size=3):
super(myRNN, self).__init__()
#创建一个RNN模块,里买包含了4个隐藏层
self.num_layers = num_layers
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size=input_size, num_layers=num_layers, hidden_size=hidden_size)
#输出层是需要单独建立的
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
#x的形状为(seq_len, batch_size, input_size)
#初始化h0
h0 = torch.zeros(self.num_layers, x.size(1), self.hidden_size)
#同时输入x和hn
output, _ = self.rnn(x, h0)
#我们关心的是最后一个时间步的输出,可以从output中索引
predict = self.fc(output[-1, :, :]) #output[-1, :, :]的shape为(1,batch_size, hidden_size)
#也可以从hn中索引
#predict = self.fc(hn[-1, :, :])#hn[-1, :, :]的shape为(1,batch_size, hidden_size)
return predict
model = myRNN()
print(model)
'''
myRNN(
(rnn): RNN(10, 256, num_layers=4)
(fc): Linear(in_features=256, out_features=3, bias=True)
)
'''
print(model.forward(input).shape)
#torch.Size([50, 3])实现每个隐藏层上神经元数量不一致的DRNN
虽说大部分时候,循环神经网络内部的隐藏层上神经元数量都是一致的,但如果我们要求神经元数量不一致呢?例如,在全部的隐藏层中,前2个隐藏层为256个神经元,后两个隐藏层为512个神经元:
python
import torch
from torch import nn
import time
class myRNN4(nn.Module):
def __init__(self, input_size=100,
hidden_size=[256, 256, 512, 512],
output_size=3):
super(myRNN4, self).__init__()
#定义4个不同的rnn层
self.hidden_size = hidden_size
self.rnn1 = nn.RNN(input_size, hidden_size[0])
self.rnn2 = nn.RNN(hidden_size[0], hidden_size[1])
self.rnn3 = nn.RNN(hidden_size[1], hidden_size[2])
self.rnn4 = nn.RNN(hidden_size[2], hidden_size[3])
self.fc = nn.Linear(hidden_size[3], output_size)
def forward(self, x):
#初始化h0,需要对4个隐藏层都进行初始化,但由于4个隐藏层是分开的,且神经元个数不同,所以需要分别进行初始化
h0 = [torch.zeros(1, x.size(1), self.hidden_size[0]),
torch.zeros(1, x.size(1), self.hidden_size[1]),
torch.zeros(1, x.size(1), self.hidden_size[2]),
torch.zeros(1, x.size(1), self.hidden_size[3])
]
output1, _ = self.rnn1(x, h0[0])
output2, _ = self.rnn2(output1, h0[1])
output3, _ = self.rnn3(output2, h0[2])
output4, _ = self.rnn4(output3, h0[3])
#最终取出最后一个步长在最后一个隐藏层上的输出
output = self.fc(output4[-1, :, :])
return output
input2 = torch.randn((3, 50, 100))
model = myRNN4()
print(model)
print(model.forward(input2).shape)
#torch.Size([50, 3])3.5 RNN的反向传播与缺陷
自诞生以来,循环神经网络(RNN)一直在许多序列任务中都表现出色,它的独特结构使其能够捕捉时间序列数据中样本与样本之间的依赖关系,但它也存在一些固有的、不可克服的缺陷,例如容易发生梯度消失、梯度爆炸、不擅长长期记忆等等。这些问题不仅限于理论层面,而且在实际应用中也反复出现,严重影响了模型的实际效果和训练的稳定性。对于深度学习的从业者来说,理解这些缺陷非常重要,因为它决定了RNN是否适合特定的任务,同时也影响我们对于后续改进方案(如LSTM、transformer等算法)的理解。在本部分,我们将深入探讨RNN的这些局限性,以及它们如何影响模型的性能。
要讨论RNN的局限性,就必然要讨论RNN的反向传播过程,因为RNN在实际应用中的问题基本都和它异常复杂的反向传播过程有关。反向传播是神经网络优化迭代过程中的关键过程,它基于链式法则来计算损失函数L相对于网络权重W的梯度,并用这些梯度优化、迭代网络中的权重,以辅助梯度下降、Adam等优化算法的完成。
3.5.1 反向传播的数学过程
首先,由于循环层的存在,RNN数据流存在两个方向:第一个方向是与普通神经网络一致的【输入层-隐藏层-输出层】方向,第二个维度则是沿着时间步进行传播的【输入-t时刻隐藏层-t+1时刻隐藏层】方向。由于反向传播是正向传播的逆过程,因此循环神经网络在反向传播上也同样有两个方向:一个是从与普通神经网络一致的【输出层-隐藏层-输入层】方向,另一个则是循环网络独特的【输出-t时刻隐藏层-t+1时刻隐藏层】的方向。这种同时在两个方向上进行反向传播的方式被称之为"通过时间的反向传播"(Backpropagation Through Time,BPTT),是循环神经网络的特色之一。
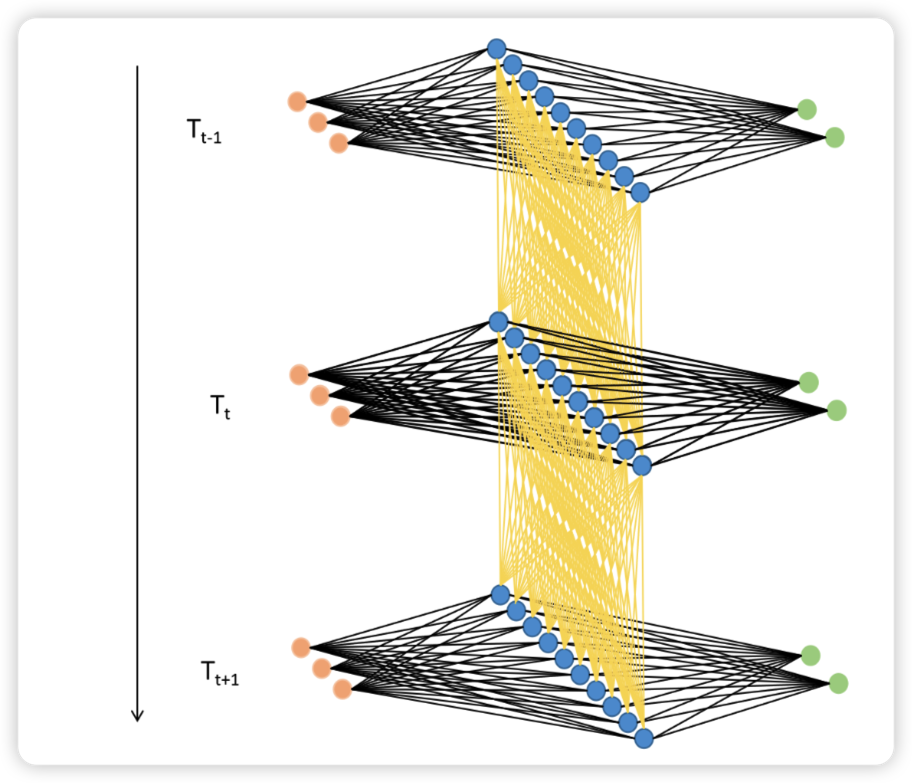
通过时间的反向传播(BPTT)比一般的反向传播要更为复杂,不过它也是从损失函数开始不断向各级的权重W求导、并利用导数来迭代权重的过程。我们来仔细看一下它的具体流程:
- 明确NLP任务,明确标签输出的方式
在不同类型NLP任务会有不同的输出层结构、会有不同的标签输出方式。例如,在对词语/样本进行预测的任务中(情感分类、词性标注、时间序列等任务),RNN会在每个时间步都输出词语对应的相应预测标签;但是,在对句子进行预测的任务中(例如,生成式任务、seq2seq的任务、或以句子为单位进行标注、分类的任务),RNN很可能只会在最后一个时间步输出句子相对应的预测标签。输出标签的方式不同,反向传播的流程自然会有所区别。考虑到生成式任务的多样性和复杂性,在这里我们使用最简单的词语分类任务作为例子来为大家讲解RNN反向传播中的各种特点与问题。

- 正向/反向传播的数据过程
假设现在我们有一个最为简单的RNN,需要完成针对每个词语的情感分类任务。该RNN由输入层、一个隐藏层和一个输出层构成,全部层都没有截距项,总共循环t个时间步。该网络的输入数据为X,输出的预测标签为yhat,真实标签为y,激活函数为σ,输入层与隐藏层之间的权重矩阵为Wxh,隐藏层与输出层之间的权重矩阵为Why,隐藏层与隐藏层之间的权重为Whh,损失函数为L(yhat,y),t时刻的损失函数我们简写为Lt。此时,这个RNN的正向传播过程可以展示如下:
注:所有的公式均存在错误,RNN原文中是ht = tanh(Xt \dot Wxh + ht-1 \dot Whh),是矩阵点积!且,参数矩阵在后,所有的公式都将参数矩阵放置在前面,是错误的写法!
(1)时间步1,初始化h0,并且初始化需要迭代的参数Whh、Wxh、Why:
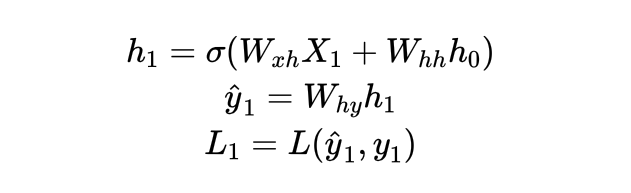
(2) 时间步2,计算过程如下:
公式有误,是L2,不是L1
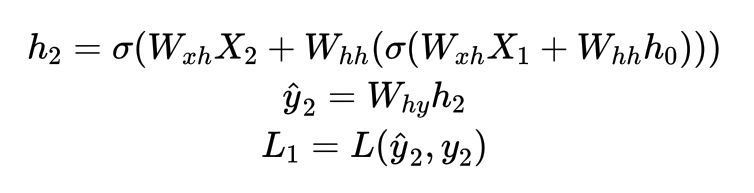
(3)时间步3,计算过程如下:
公式有误,是L3,不是L1
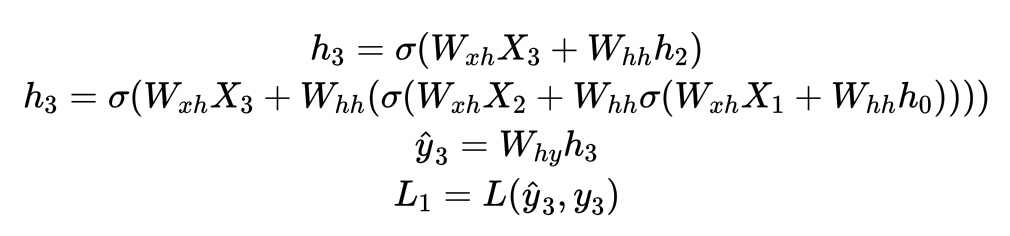
...
(n-1) 时间步t-1的计算过程:
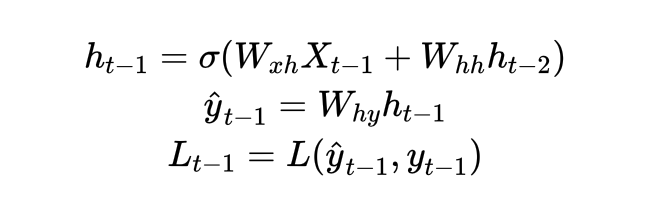
(n) 时间步t的计算过程:
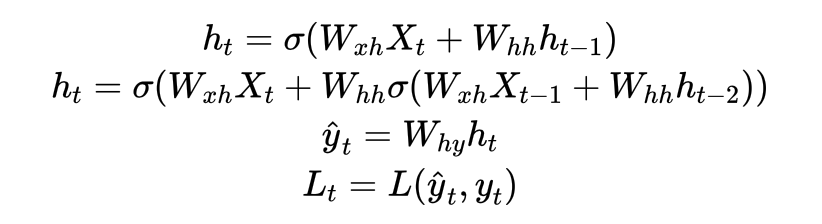
不难发现,RNN中存在至少三个权重矩阵需要迭代:输出层与隐藏层之间的权重矩阵Wxh,隐藏层与输出层之间的权重矩阵Why,隐藏层与隐藏层之间的权重Whh。在循环神经网络中,我们首先要完成全部时间步上的正向传播,才可以开始进行反向传播和参数迭代,因此用于计算h1的Wxh和Whh与用于计算ht的Wxh和Whh是完全相同的权重矩阵。这是循环神经网络权值共享的关键,表面上看是所有表单共享一套参数,本质是所有时间步上的所有循环共享一套参数,无论走过多少时间步,我们使用的是始终都是同一套Whh、Wxh和Why。
首先先来回忆一下梯度下降法的思想:
而梯度下降,作为最优化算法,核心目标也是找到或者逼近最小值点,而其基本过程则:在目标函数上随机找到一个初始点;通过迭代运算,一步步逼近最小值点;
在这里插入图片描述数学意义上的迭代运算,指的是上一次计算的结果作为下一次运算的初始条件带入运算。
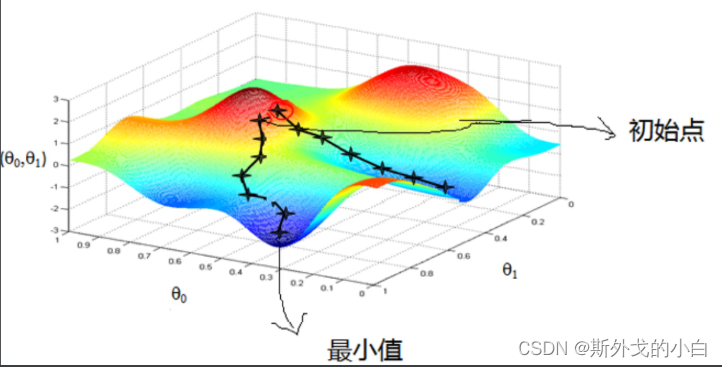
梯度:梯度本身是一个代表方向的矢量,代表某一函数在该点处沿着梯度方向变化时,变化率最大。当然,梯度的正方向代表函数值增长最快的方向,梯度的负方向表示函数减少最快的方向。
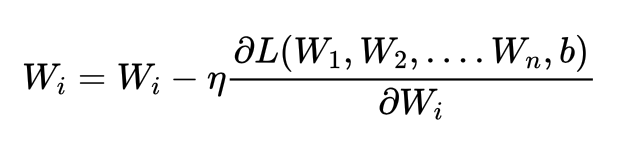
再次回到RNN神经网络的反向传播
当完成正向传播后,RNN需要在反向传播过程中对以上三个权重求解梯度、并迭代权重。反向传播是从最后的时间步开始,因此以最后的时间步t为例子,反向传播中需要计算的梯度有:
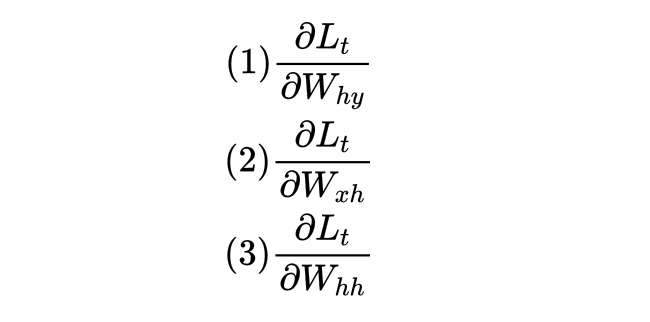
根据链式法则可得:
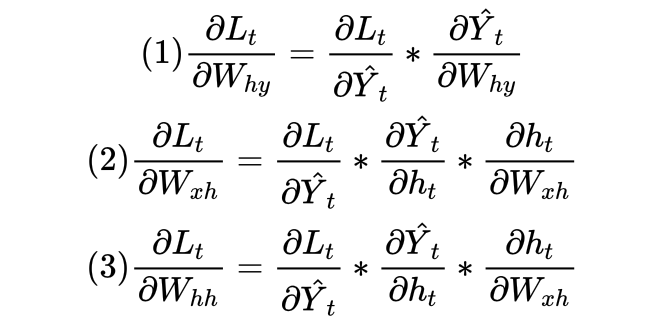
由于循环神经网络有权值共享机制,因此用于计算ht的Wxh和Whh与计算ht-1的Wxh和Whh是完全相同的权重矩阵。如下面的公式所示,蓝色的部分是完全相同的矩阵,红色的部分也是完全相同的矩阵:
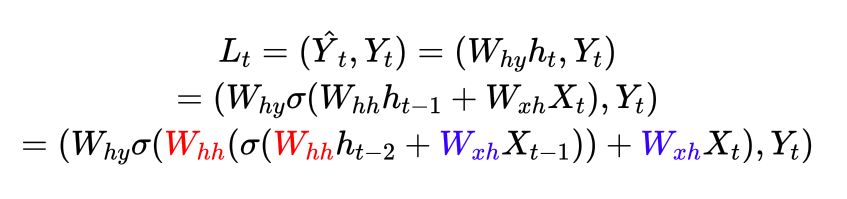
因此,在求解Lt对Whh和Wxh的导数时,不止要求解(1)、(2)、(3),还需要求解式(2.1)和(3.1)。
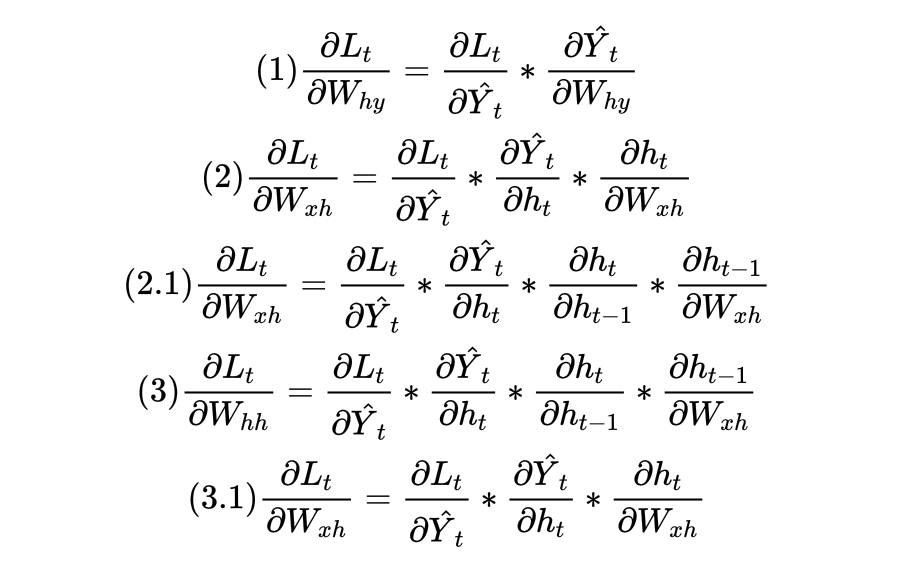
甚至于,我们还可以将Lt继续拆分到x-1和ht-2的函数、x-2和ht-3的函数,直至X1和h0的函数,在这个过程中,只要拆解最够多,我们就可以从Lt求解出t个针对Wxh和Whh的导数。因此,惊人的事实是,在时间步t上,我们可以计算t个用于迭代Wxh和Whh的梯度!
在整个RNN的反向传播过程中,每个时间步上都可以计算用于迭代Wxh和Whh的梯度等于时间步的数值本身。在时间步t上,我们可以计算t个用于迭代的Wxh和Whh的梯度,在时间步t-1上,我们可以计算t-1个用于迭代Wxh和Whh的梯度,因此有t个时间步时,我们可以计算的用于迭代Wxh和Whh梯度的梯度总数量为:
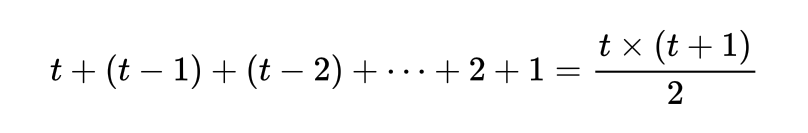
这是一个算数级数之和。那我们现在该如何使用那么多梯度对Whh进行迭代?通常来说,我们可以对这些梯度进行求和、求均值等聚合计算,并将聚合后的值用于迭代。以下是一个聚合的例子:
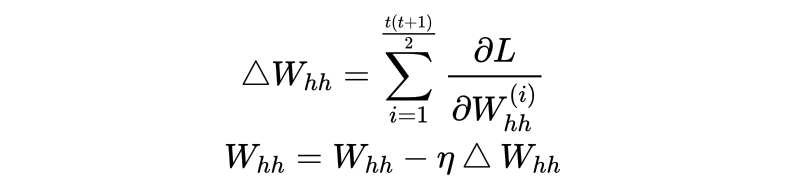
以上迭代流程在每个batch中会发生一次,假设现在分批之后每个batch中有100张表单,即数据格式(batch_size, seq_len, input_dimensions)中的第一个维度为100,那RNN看完全部的100张表单后就会进行一次迭代。而总共有多少次迭代?就看全部数据集中有多少个batch,以及在训练过程中循环了多少个epochs了。
3.5.2 RNN的反向传播所带来的问题
作为NLP入门经典算法,RNN处理序列数据的思路非常精彩,但是同时它会有众多不可忽视的缺陷,这些缺陷与它复杂的反向传播过程有关。
*极其容易发生梯度消失和梯度爆炸
梯度消失和梯度爆炸是神经网络在训练过程中很常见的问题之一,其中梯度消失是指随着迭代进行、权重的梯度变得越来越小,从而导致迭代失效的现象;梯度爆炸是随着迭代进行、权重的梯度变得越来越大、从而导致迭代失效的现象。这种现象一般是由反向传播中的偏导数连乘引起的,但相比起一般的深度学习算法。RNN算法更容易发生梯度消失和梯度爆炸现象,因为RNN反向传播中的连乘过程会比DNN反向传播中的连乘过程更加极端。来看RNN反向传播过程中损失函数的表达式,在时间步t上我们有:
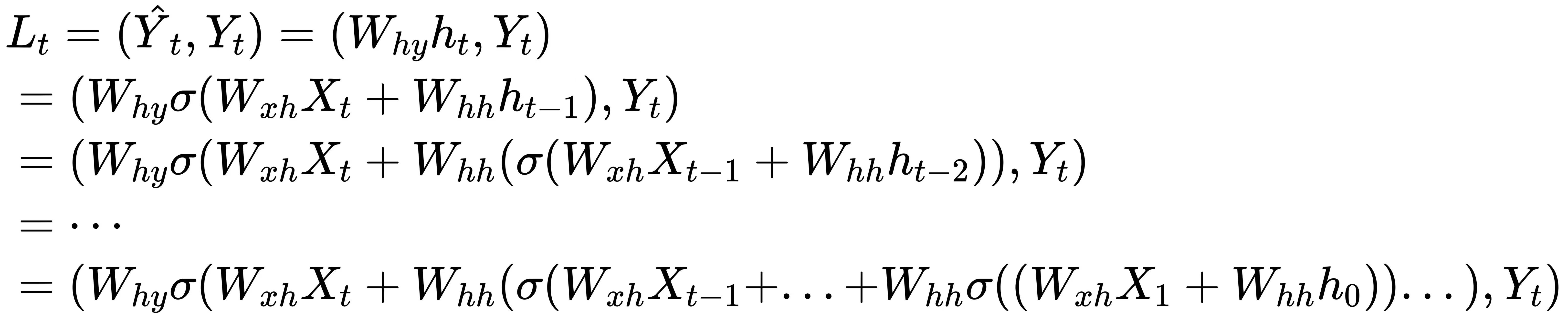
这个公式嵌套了t层公式,共有ht到h0的t个自变量,且每个自变量h都与权重Whh相乘。假设此时我们令激活函数sigmoid为常量1,则损失函数的公式可以改写为:
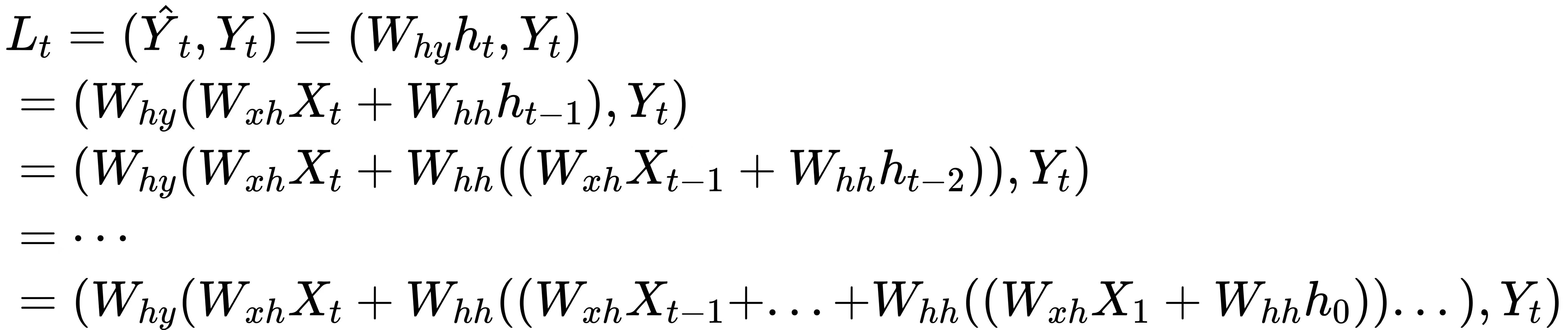
在这个彻底拆解后的公式上,我们可以求解出嵌套了t层的Whh的梯度(如公式3.t):
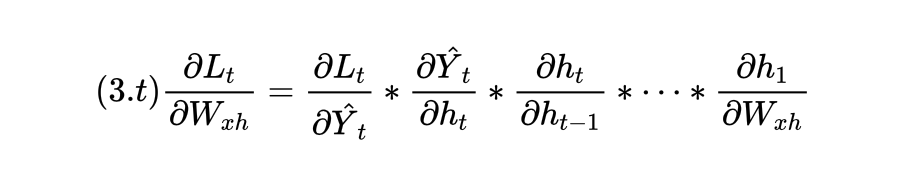
此时在这个公式中,许多偏导数的求解就变得非常简单,例如:
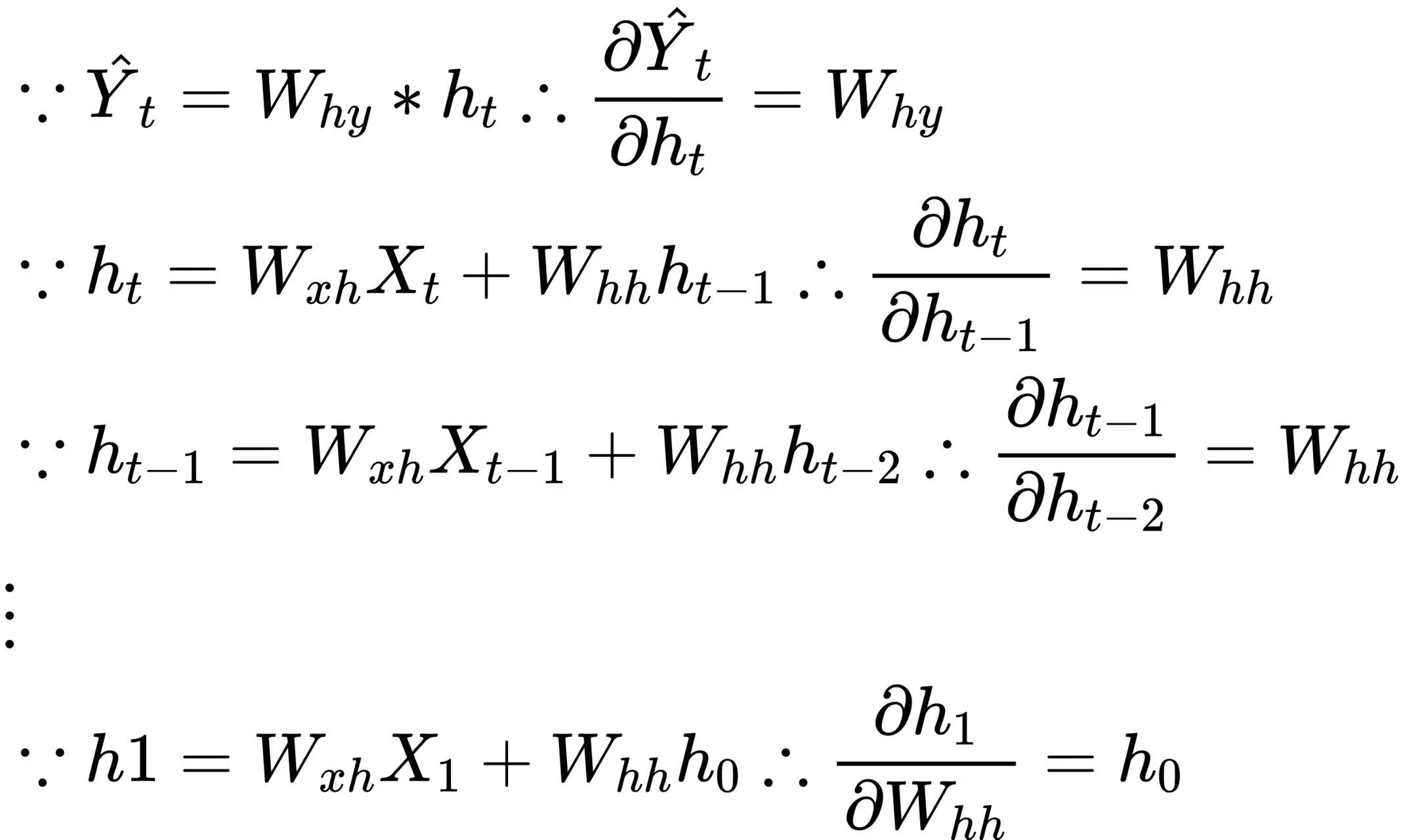
所以最终的梯度表达式为:
不难发现,在这个梯度表达式中出现了Whh的t-1次方这样的高次项,这就是循坏神经网络非常容易梯度爆炸和梯度消失的根源所在:假设Whh是一个小于1的值,那么Whh的t-1次方会非常接近0,从而导致梯度消失;假设Whh是大于1,那么Whh的t-1次方将会接近无限大,从而引发梯度爆炸,其中地图消失的可能性有远远高于梯度爆炸。在深度神经网络中,在应用链式法则后,我们会面临复合函数连乘的问题,由于普通神经网络中并不存在权值共享的现象,因此每个偏导数的表达求解出的值大多数是不一致的,在连乘的时候有的偏导数数值较大、有的偏导数数值较小,相比之下就不那么容易发生梯度爆炸或梯度消失的问题。当然,现在的公式是建立在"激活函数等于1"这个假设上,当激活函数不为1,而是sigmoid或tanh时,梯度消失会更容易发生(毕竟激活函数会将连乘的值不断压缩到0-1之间)。为了克服这一问题,有如下解决方案:
- (1)权值初始化:使用适当的权重初始化策略可以帮助缓解梯度消失/爆炸的问题。例如,使用Xavier初始化。当然,不恰当的初始化更可能引发梯度爆炸,因为初始化的权重矩阵一般都是小于1的值,因此在使用该手段时要特别小心。
- (2)梯度截断:通过设定一个阈值,当梯度超过这个阈值时,将其缩小到阈值,从而避免梯度爆炸。同样的,设定一个阈值,当梯度小于这个阈值时,将其放大到阈值,从而避免梯度消失。
- (3)在RNN中适当加入残差连接、Batch Normalization等技术,对深层循环神经网络可能有用。
- (4)使用更高级的、改进后的RNN结构,例如:LSTM(Long Short-Term Memory): LSTM是RNN的一个变种,设计上加入了三个门结构(输入门、遗忘门和输出门)来控制信息的流动,从而有效地缓解了梯度消失的问题。GRU (Gated Recurrent Unit):GRU是LSTM的简化版本,它只有两个门结构(更新门和重置门)。虽然结构更简单,但在某些任务上与LSTM有着类似的表现。
*容易遗忘,难以捕获长期依赖关系
尽管我们说循坏网络在最后一个时间步时依然能够保留第一个时间步的信息,但在循环神经网络复杂的嵌套过程中,较早的时间步中的信息重要性会被大幅削弱,从而导致网络会"遗忘掉"最初的信息,而只记得最近的时间步的信息。

经过高次项连乘后再乘以X,大部分时候会极大程度削弱X本身的信息传递,即便不发生梯度消失,权重连乘后的值一般也是比较小的数字。因此在RNN中,越早时间步的输入越容易被遗忘,RNN也因此不擅长处理很长的序列,而这一点也非常难以改善。
除了前面提到的梯度消失/梯度爆炸问题、难以记忆长期记忆的问题,RNN还有许多其他难以克服的问题,包括但不限于:
*运算过程过于复杂,计算效率极其低下
*保存大量中国南京爱你变量,运存利用率低
*使用全链接层,再限制参数量也会很大
*容易过拟合,抗过拟合结构严重不足
总结
随着我们深入探索RNN的奥秘,可以明显地看到这一算法如何为序列数据建模提供了强大的工具。从RNN的基本架构,到其独特的循环原理,再到复杂的反向传播过程,我们已经对这一核心技术有了全面的了解。在实际操作中,通过PyTorch这一先进的深度学习框架,我们进一步巩固了对RNN的认识,也体会到了其在NLP领域的实际应用价值。
RNN,尽管在处理序列数据上有其天然的优势,但正如我们所探讨的,它并不是没有挑战的。它的计算效率、容易过拟合等问题都需要我们在实际应用中注意和解决。幸运的是,深度学习的研究者和工程师们从未停止对其进行优化和改进。为了让大家更加直观地理解和应用RNN,接下来的两个手动实现RNN的例子会为大家提供一个实战的机会,希望大家可以通过这些例子进一步巩固所学,并体验到RNN的魅力。从下一章开始,我们即将探索LSTM算法,这是RNN家族中的另一位重要成员,它为我们提供了处理长序列数据中的挑战的有效策略,我们将会看到LSTM是如何解决RNN的各种问题的,请期待后续的课程!