结果展示
陈平安在山巅,望着远方,怔怔出神,喃喃道:"人心汇聚,怎么会如此,不能不在乎,何必一味退避?我只说自己的问心无愧,是死了。"陈平安转过头,"我没有告诉你,会去找你,自己找机会去。"茅小冬起身离去,犹豫了一下,还是没能起身,起身。陈平安闭上眼睛,也跟着起身。书院君子王宰,立即站起身,对陈平安作揖行礼,朗声道:"好。"王宰......
源代码
惜哉剑气疏/programs_0![]() https://gitee.com/zirui-shu/programs_0
https://gitee.com/zirui-shu/programs_0
循环神经网络
循环神经网络(Recurrent Neural Network, RNN),正如其名,特点在于**【循环】** 二字,是一种处理**【序列化数据】**的神经网络模型。分为三层,分别是数据预处理层、隐藏层和全连接层。
数据预处理层
对于上述内容之后分析,首先我们从结果出发:什么叫做**【序列化数据】**?就是前后之间数据有相关联系的的数据。最为常见的就是文本数据了,比如说小说、诗歌等这种上下文有关系的数据。本文做的是文本生成的项目,以下就以文本数据为准。
我们都知道,计算机处理的都是数字,不会处理其他类型的数据。那么,要处理这种文本数据,我们就需要一个数据预处理的步骤,把文本变成一个个的数字,这样计算机就可以处理了。
那么,如何把文本变成一个个的数字呢?分为两步:其一是把整个文本数据划分为一个个最小单元,其二是把这些最小单元转换为对应的数据。对于第一步,其实有两种方法:一个是按照词语划分 ,一个是按照单个的字划分。一般都是前者效果较好,毕竟我们写文章时都是按照一个个词语写的,这样划分有利于理解文本的风格构成。对于第二步,我们就可以将这一个个词语转换为一个多维的向量(也就是1*N维的矩阵),便于计算机计算,这个过程有时候也叫做词嵌入层。
当然到此还没有为止。为了便于之后的参数调整及生成操作,我们需要构建一个【词表】 ,将这些词语改造成一个个索引,按照这个索引搜索这些词。
def build_vocabulary():
unique_words_set = set()
all_words = []
with open('剑来(后).txt', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
words = list(jieba.cut(line))
all_words.append(words)
unique_words_set.update(words)
unique_words = list(unique_words_set)
word2index = {word: i for i, word in enumerate(unique_words)}
if ' ' not in word2index:
word2index[' '] = len(word2index)
unique_words.append(' ')
corpus_idx = []
for words in all_words:
for word in words:
corpus_idx.append(word2index[word])
corpus_idx.append(word2index[' '])
return unique_words, word2index, len(unique_words), corpus_idx隐藏层
隐藏层就体现出**【循环】**二字的特点了。
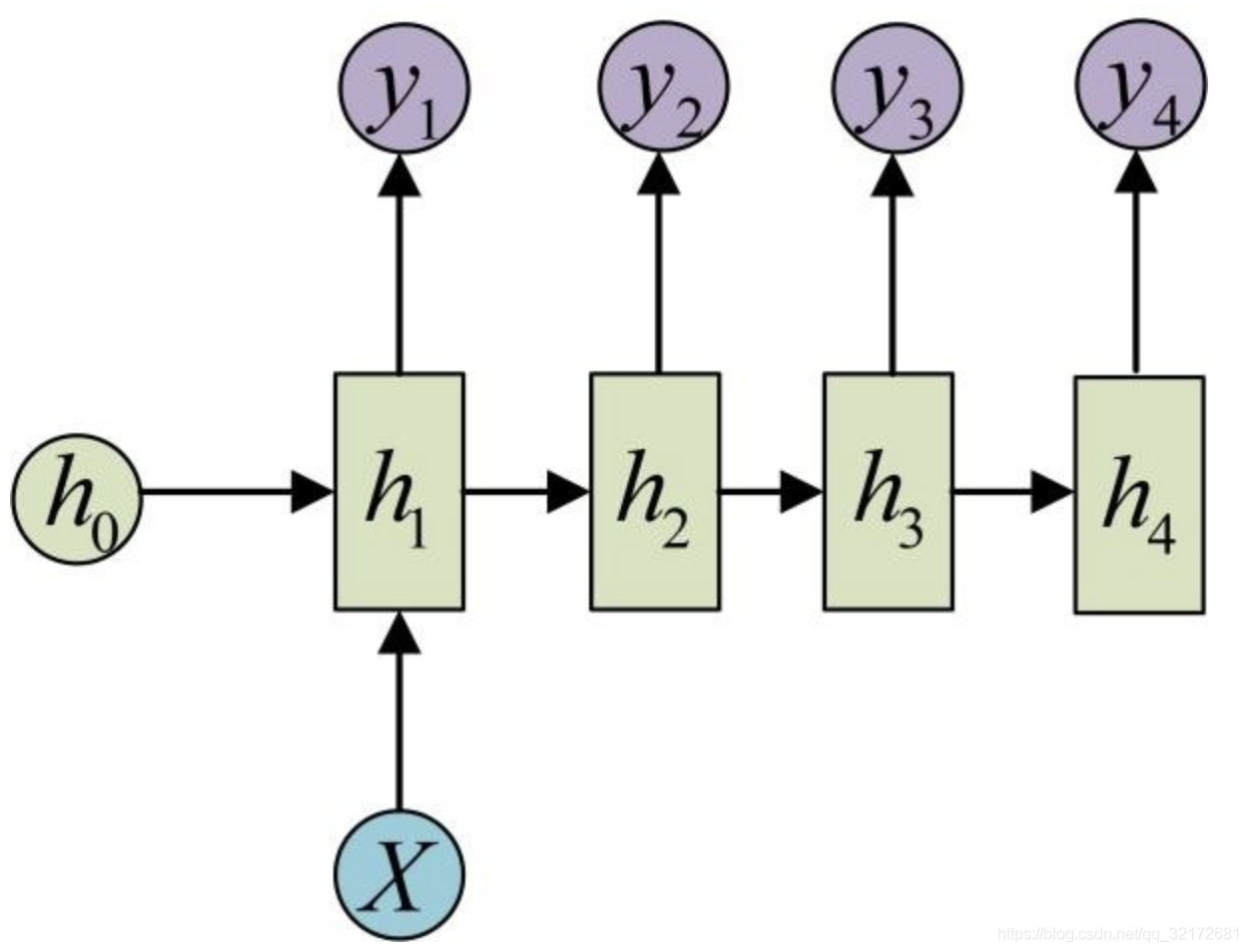
每个字母含义如下:
:状态参数,一定程度上代表了在当前上下文的语境影响。
:输入数据,与词语数据同维。
:输出数据。
正因为有了这个状态参数,循环神经网络有了**【记忆】**功能,也就可以处理序列化数据了。
对于每一次迭代,有状态转移方程:
,
同时,每一次的输出会作为下一次的输入,不负**【循环】** 之名。初始的一般设为0,毕竟初始状态没有文本,而
就是对应的词语向量了。
举个例子,对于文本:
裴钱眼神死寂,却咧嘴笑了笑。
使用分词之后有:
裴钱 眼神 死寂 , 却 咧嘴 笑了笑 。
设计词向量为四维,裴钱 对应的可能是1,2,3,4,那么就是1,2,3,4;眼神 对应的可能是2,3,4,5,那么
就是2,3,4,5,以及对应的
是0,以此根据公式调整其他参数。再以
为输入,如果得到的
是1,以及死寂对应的词向量也就是
是3,4,5,6,那么继续根据公式调整其他参数,依次循环类推......
全连接层
这个就是普通的基础神经网络,包括激活函数之类的,得到最终的输出。
class TextDataset(torch.utils.data.Dataset):
def __init__(self, corpus_idx, seq_len):
self.corpus_idx = corpus_idx
self.seq_len = seq_len
self.num_samples = len(corpus_idx) - seq_len
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
x = self.corpus_idx[idx:idx + self.seq_len]
y = self.corpus_idx[idx + 1:idx + self.seq_len + 1]
return torch.tensor(x, dtype=torch.long), torch.tensor(y, dtype=torch.long)
class TextGenerator(nn.Module):
def __init__(self, vocab_size, embed_dim=256, hidden_dim=512, num_layers=2):
super().__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers, batch_first=True, dropout=0.3)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden):
x = self.embed(x) # [B, L, E]
out, hidden = self.lstm(x, hidden) # out: [B, L, H]
logits = self.fc(out.reshape(-1, out.size(-1))) # [B*L, V]
return logits, hidden
def init_hidden(self, batch_size, device):
h = torch.zeros(2, batch_size, 512, device=device)
c = torch.zeros(2, batch_size, 512, device=device)
return (h, c)
def train(resume_from=None):
# 超参数(调整以加速训练)
SEQ_LEN = 64 # 从 128 → 64,大幅提速
BATCH_SIZE = 16 # 保持 16(可适当调小如 8 若显存紧张)
EPOCHS = 100 # 设大些,靠时间/loss 控制退出
LR = 0.002
GRAD_CLIP = 1.0
MAX_TRAIN_TIME = 39600 # 最多训练 11 小时(秒)
unique_words, word2index, vocab_size, corpus_idx = build_vocabulary()
print(f"词表大小: {vocab_size}")
dataset = TextDataset(corpus_idx, SEQ_LEN) # 使用新的 SEQ_LEN
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, pin_memory=True)
model = TextGenerator(vocab_size).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=LR, weight_decay=1e-5)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.8)
start_epoch = 0
total_train_time = 0.0
# === 断点续训逻辑 ===
if resume_from and os.path.exists(resume_from):
print(f"🔁 从 {resume_from} 加载模型继续训练...")
ckpt = torch.load(resume_from, map_location=device)
model.load_state_dict(ckpt['model_state_dict'])
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
scheduler.load_state_dict(ckpt['scheduler_state_dict'])
start_epoch = ckpt.get('epoch', 0)
total_train_time = ckpt.get('total_train_time', 0.0)
print(f"▶ 从 Epoch {start_epoch} 开始,已训练 {total_train_time / 3600:.2f} 小时")
start_global = time.time()
for epoch in range(start_epoch, EPOCHS):
model.train()
total_loss = 0.0
epoch_start = time.time()
for x, y in dataloader:
actual_bsz = x.size(0)
hidden = model.init_hidden(actual_bsz, device)
# 分离隐藏状态(避免反向传播到上一个 batch)
hidden = tuple(h.detach() for h in hidden)
x, y = x.to(device, non_blocking=True), y.to(device, non_blocking=True)
optimizer.zero_grad()
logits, hidden = model(x, hidden)
loss = criterion(logits, y.view(-1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), GRAD_CLIP)
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
epoch_time = time.time() - epoch_start
total_train_time += epoch_time
ppl = torch.exp(torch.tensor(avg_loss)).item()
print(f'Epoch {epoch + 1}/{EPOCHS} | Loss: {avg_loss:.4f} | PPL: {ppl:.2f} | Time: {epoch_time:.2f}s')
scheduler.step()
# === 关键:每训练约 1 小时就保存并退出 ===
if total_train_time >= MAX_TRAIN_TIME:
print(f"⏰ 已训练 {total_train_time / 3600:.2f} 小时,保存模型并退出。")
break
# === 提前停止防过拟合 ===
if avg_loss < 1.5: # jieba 分词:Loss < 1.5 时可能已过拟合
print("💡 Loss 已足够低,提前停止以防过拟合")
break
# 每个 epoch 都保存(方便随时中断)
save_path = './model/text_model_3.pth'
os.makedirs('./model', exist_ok=True)
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'vocab': (unique_words, word2index),
'epoch': epoch + 1,
'total_train_time': total_train_time,
'last_loss': avg_loss
}, save_path)
print(f"💾 模型已保存至 {save_path}")
final_time = time.time() - start_global
print(f"✅ 总训练时间: {final_time / 3600:.2f} 小时")变型
细心的人可能发现了,我在项目中及上述代码没有使用RNN,因为效果实在是太差了。RNN也进化出了不同的类型,一个是LSTM一个是Transformer。
LSTM(长短期记忆网络)
在隐藏层中,LSTM引入了新的机制:门控制机制。大致流程如下:
输入 → [输入门] → [细胞状态更新] ← [遗忘门] ← 历史细胞状态
↓
[输出门] → 隐藏状态 → 输出细胞大致可以理解为之前循环网络的一个循环基本单位(也就是每次公式计算的单元)。
第一步:遗忘门
- 目的:决定从细胞状态中丢弃什么信息
- 输入 :上一时刻隐藏状态
和当前输入
- 输出 :遗忘门值
- 含义:接近0表示完全丢弃,接近1表示完全保留
第二步:输入门
- 目的:决定什么新信息被存储在细胞状态中
- 输出 :输入门值
3.3 第三步:候选值
- 目的:创建新的候选值向量
- 激活函数:tanh,输出范围-1,1
3.4 第四步:更新细胞状态
- 目的:更新细胞状态
- 操作:遗忘旧信息 + 添加新信息
3.5 第五步:输出门
- 目的:决定从细胞状态输出什么
- 输出 :输出门值
3.6 第六步:更新隐藏状态
- 目的:计算当前时间步的隐藏状态
- 输出 :
Transformer
这个就不多说了,有点多。我在仓库中上传了相关代码,感兴趣的可以试一试(这个是实现了并发的神经网络,训练起来会快很多)。
【补】超参数说明
一些常规的超参数就不介绍了,介绍一点罕见的。
***SEQ_LEN:***序列长度,我们训练时是以该长度数据作为训练数据,便于理解上下文。也就是说,长度越大模型能力越强,不过消耗资源变大。
WARMUP_STEPS:预热步数。预热是从0或很小的学习率开始逐渐增加到预设的学习率,让模型参数平稳过渡。
***temperature:***将原本的概率矩阵乘以该系数,可以增大/缩小概率差距。
***top_p:***概率阈值。概率矩阵从大到小的概率和大于该阈值就不考虑低概率事件。