
🎁个人主页:User_芊芊君子
🎉欢迎大家点赞👍评论📝收藏⭐文章
🔍系列专栏:AI


【前言】
在人工智能技术从"工具化"向"自主化"演进的浪潮中,Agent AI(智能体已成为连接技术研究与产业落地的核心桥梁。不同于传统AI需要人工明确指令才能完成任务,Agent AI具备自主感知环境、设定目标、规划路径并执行闭环的能力,正在重构智能系统的交互逻辑与应用边界。本文将从技术原理、核心架构、工程实现到行业落地,全方位拆解Agent AI的关键技术点,结合实战代码与案例,为开发者提供可落地的实践参考。
文章目录:
- 一、Agent AI的核心定义与技术边界
-
- 1.1 什么是Agent AI?
- 1.2 Agent AI与传统AI的核心差异
-
- 对比表格:==传统AI系统与Agent AI系统的特性==
- 二、Agent AI的核心技术架构拆解
-
- 2.1 架构整体示意图
- 2.2 各模块核心功能与技术选型
-
- 2.2.1 感知层:环境数据的"传感器"
- 2.2.2 决策层:智能体的"大脑"
- 2.2.3 执行层:动作落地的"手脚"
- 2.2.4 记忆层:智能体的"知识库"
- 三、Agent AI的工程实现:实战代码示例
-
- 3.1 技术栈选型
- 3.2 核心模块代码实现
-
- 3.2.1 感知层:数据采集与预处理
- 3.2.2 决策层:目标拆解与路径规划
- 3.2.3 执行层与记忆层:闭环实现
- 3.3 完整Agent AI工作流示意图
- 四、Agent AI的性能优化与落地挑战
-
- 4.1 性能优化关键指标
- 4.2 落地过程中的核心挑战
- 五、Agent AI的典型应用场景
-
- 5.1 企业级应用
- 5.2 开发者工具
- 5.3 消费级应用
- 六、总结与展望
一、Agent AI的核心定义与技术边界
1.1 什么是Agent AI?
Agent AI(智能体)是具备自主决策能力的智能系统,通过"感知-决策-执行-反馈"的闭环机制,在动态环境中自主完成复杂目标。其核心特征可概括为:
- 自主性:无需人工干预,能根据目标自主规划行动路径;
- 交互性:通过传感器(数据输入)与执行器(动作输出)与环境动态交互;
- 适应性:面对环境变化或任务调整,能实时优化决策策略;
- 协同性:单智能体可拆分任务,多智能体可协作完成复杂目标。
1.2 Agent AI与传统AI的核心差异
对比表格:传统AI系统与Agent AI系统的特性
| 特性 | 传统AI系统 | Agent AI系统 |
|---|---|---|
| 核心逻辑 | 输入→模型→输出(静态映射) | 感知→决策→执行→反馈(动态闭环) |
| 任务处理方式 | 单任务专项优化 | 多任务协同与目标拆解 |
| 环境依赖 | 固定输入格式,对噪声敏感 | 自适应动态环境,容错性强 |
| 人工干预程度 | 需明确指令引导 | 仅需设定目标,自主执行 |
| 学习模式 | 离线预训练为主 | 在线持续学习+预训练知识融合 |
二、Agent AI的核心技术架构拆解
Agent AI的架构设计围绕"自主决策"核心展开,从下到上可分为感知层、决策层、执行层、记忆层四大模块,各模块通过数据总线实现高效协同。
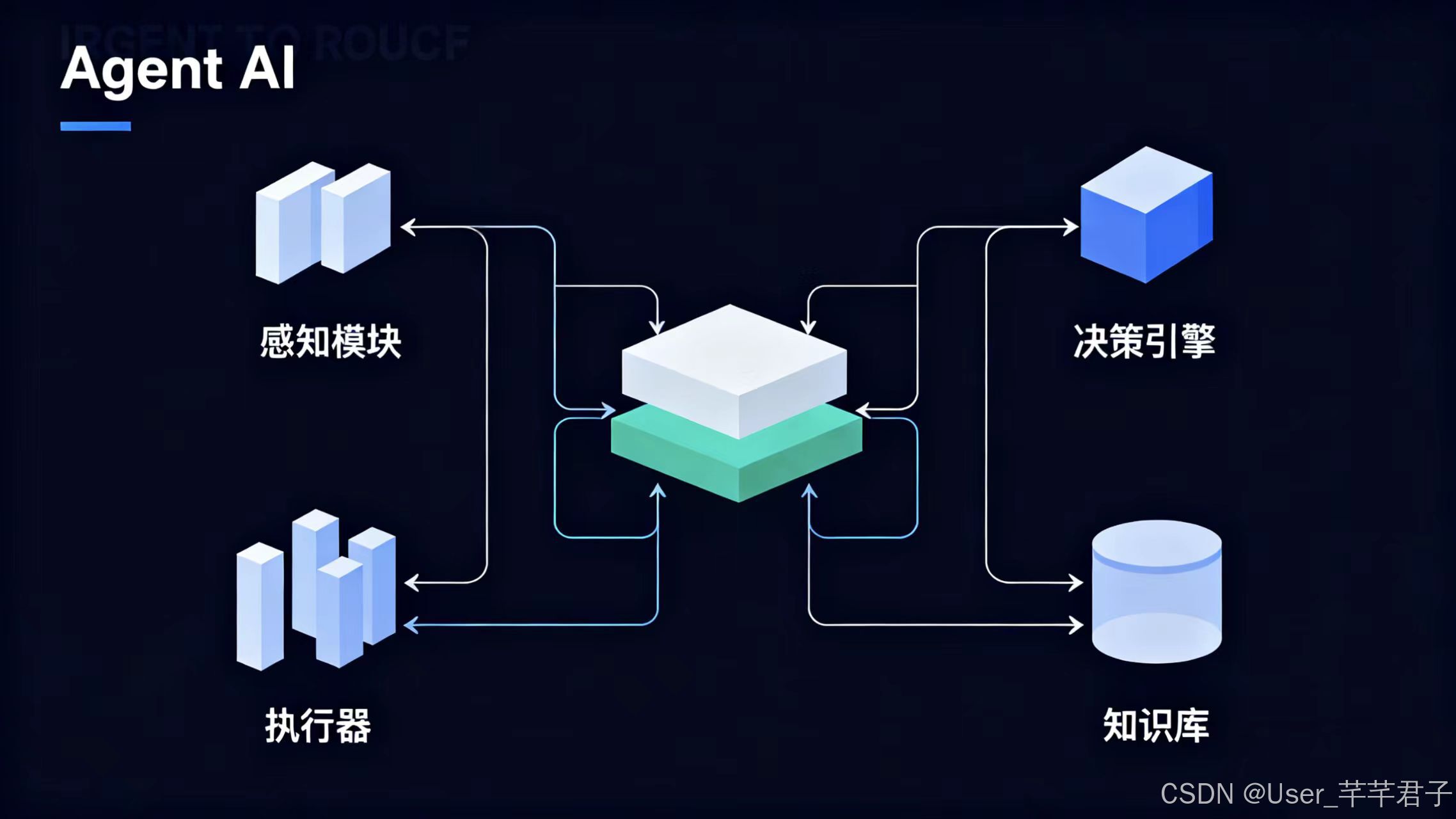
2.1 架构整体示意图
Agent AI核心架构图 
示意图说明:
感知层:负责数据采集与预处理;
决策层:是核心大脑;
执行层:对接外部系统;
记忆层:提供短期缓存与长期知识存储
2.2 各模块核心功能与技术选型
2.2.1 感知层:环境数据的"传感器"
感知层的核心是将异构环境数据转化为智能体可理解的结构化信息,常用技术包括:
数据采集:API调用、数据库查询、网页爬虫、传感器数据接入;数据预处理:实体识别(NER)、关键信息抽取(IE)、数据标准化;环境建模:状态表示(如用向量表示当前环境状态)。
技术选型建议:
- 结构化数据(数据库、API):使用SQLAlchemy、Requests库直接解析;
- 非结构化数据(文本、图片):轻量场景用spaCy做NER,复杂场景用LLaMA 2微调模型做信息抽取。
2.2.2 决策层:智能体的"大脑"
决策层是Agent AI的核心,负责目标拆解、路径规划与动作选择,核心技术包括:
- 目标拆解:将复杂目标拆分为可执行的子任务(如"完成季度报表"拆分为"数据采集→数据清洗→计算分析→生成报告");
- 规划算法:基于规则的规划(如有限状态机FSM)、基于强化学习(RL)的规划、基于大模型的推理规划;
- 冲突解决:当多目标冲突时(如"快速完成"与"高质量完成"),通过优先级权重动态调整。
2.2.3 执行层:动作落地的"手脚"
执行层负责将决策层输出的动作指令转化为实际操作,常用形式包括:
- 代码执行:调用Python/Java代码完成计算、文件处理等;
- 接口调用:通过RESTful API、RPC与外部系统交互;
- 自然语言生成:生成报告、邮件、指令等自然语言内容。
2.2.4 记忆层:智能体的"知识库"
记忆层负责存储智能体的历史经验与外部知识,支撑长期决策,分为:
- 短期记忆:存储当前任务的上下文信息(如已完成的子任务、环境状态变化);
- 长期记忆:存储领域知识、历史经验、用户偏好等(如用向量数据库存储结构化知识)。
三、Agent AI的工程实现:实战代码示例
3.1 技术栈选型
- 核心框架:Python 3.10+、LangChain(智能体流程编排)、LLaMA 2(推理引擎)
- 记忆存储:Redis(短期记忆)、Milvus(向量数据库,长期记忆)
- 执行工具:Python-SDK、Requests(API调用)、Pandas(数据处理)
- 环境依赖: pip install langchain llama-cpp-python redis milvus pandas
3.2 核心模块代码实现
3.2.1 感知层:数据采集与预处理
python
python
import requests
import pandas as pd
from spacy import load
# 初始化NLP工具(信息抽取)
nlp = load("en_core_web_sm")
class PerceptionLayer:
def __init__(self, api_url: str):
self.api_url = api_url # 外部数据API地址
# 采集结构化数据(API调用)
def fetch_structured_data(self, params: dict) -> pd.DataFrame:
response = requests.get(self.api_url, params=params, timeout=10)
response.raise_for_status() # 异常捕获
return pd.DataFrame(response.json()["data"])
# 预处理非结构化文本(关键信息抽取)
def extract_key_info(self, text: str) -> dict:
doc = nlp(text)
# 抽取实体(组织、日期、数值)
entities = {
"organizations": [ent.text for ent in doc.ents if ent.label_ == "ORG"],
"dates": [ent.text for ent in doc.ents if ent.label_ == "DATE"],
"numbers": [ent.text for ent in doc.ents if ent.label_ == "NUM"]
}
return entities
# 测试代码
if __name__ == "__main__":
perception = PerceptionLayer("https://api.example.com/financial-data")
# 采集结构化数据
data = perception.fetch_structured_data({"start_date": "2024-01-01", "end_date": "2024-12-31"})
print("结构化数据采样:")
print(data.head())
# 抽取非结构化文本信息
text = "ABC公司2024年Q3营收120亿元,同比增长15%"
key_info = perception.extract_key_info(text)
print("\n关键信息抽取结果:")
print(key_info)3.2.2 决策层:目标拆解与路径规划
python
python
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from llama_cpp import Llama
# 初始化LLM(推理引擎)
llm = Llama(
model_path="./llama-2-7b-chat.ggmlv3.q4_0.bin",
n_ctx=2048, # 上下文窗口大小
n_threads=8 # 线程数
)
class DecisionLayer:
def __init__(self, llm):
self.llm = llm
# 目标拆解提示词(去AI化,贴近人类决策逻辑)
self.decomposition_prompt = PromptTemplate(
input_variables=["goal"],
template="""请将以下复杂目标拆分为3-5个可执行的子任务,要求每个子任务明确、具体、可落地:
目标:{goal}
子任务列表(按执行顺序排列):
1.
2.
3.
4.
5."""
)
self.decomposition_chain = LLMChain(llm=llm, prompt=self.decomposition_prompt)
# 目标拆解
def decompose_goal(self, goal: str) -> list:
result = self.decomposition_chain.run(goal)
# 解析结果为列表
subtasks = [line.strip().lstrip("0123456789.- ") for line in result.split("\n") if line.strip() and line.strip()[0].isdigit()]
return subtasks
# 动态调整子任务优先级
def adjust_priority(self, subtasks: list, urgency: float, importance: float) -> list:
"""
urgency: 紧急程度(0-1),importance: 重要程度(0-1)
优先级得分 = urgency * 0.4 + importance * 0.6
"""
# 假设每个子任务的紧急度和重要度可通过规则或模型预测(此处简化为随机值)
import random
task_scores = [(task, random.uniform(0,1)*0.4 + random.uniform(0,1)*0.6) for task in subtasks]
# 按得分降序排序
sorted_tasks = [task for task, score in sorted(task_scores, key=lambda x: x[1], reverse=True)]
return sorted_tasks
# 测试代码
if __name__ == "__main__":
decision = DecisionLayer(llm)
goal = "完成2024年Q3财务报表分析,生成可视化报告并提出3条优化建议"
subtasks = decision.decompose_goal(goal)
print("目标拆解结果:")
for i, task in enumerate(subtasks, 1):
print(f"{i}. {task}")
# 调整优先级(紧急度0.7,重要度0.9)
sorted_tasks = decision.adjust_priority(subtasks, 0.7, 0.9)
print("\n优先级调整后:")
for i, task in enumerate(sorted_tasks, 1):
print(f"{i}. {task}")3.2.3 执行层与记忆层:闭环实现
python
python
import redis
from pymilvus import connections, Collection
import pandas as pd
import matplotlib.pyplot as plt
# 初始化记忆存储
class MemoryLayer:
def __init__(self):
# 短期记忆(Redis)
self.short_term_memory = redis.Redis(host="localhost", port=6379, db=0)
# 长期记忆(Milvus)
connections.connect("default", host="localhost", port="19530")
self.long_term_memory = Collection("agent_knowledge") # 提前创建的向量库
# 存储短期记忆(任务上下文)
def store_short_term(self, task_id: str, data: dict):
self.short_term_memory.hset(task_id, mapping=data)
# 读取短期记忆
def get_short_term(self, task_id: str) -> dict:
return self.short_term_memory.hgetall(task_id)
# 存储长期记忆(领域知识)
def store_long_term(self, knowledge: str, embedding: list):
self.long_term_memory.insert([[knowledge], [embedding]])
# 执行层实现
class ExecutionLayer:
def __init__(self, memory: MemoryLayer):
self.memory = memory
# 执行数据处理任务
def process_data(self, data: pd.DataFrame, task_id: str) -> pd.DataFrame:
# 示例:计算营收增长率
data["revenue_growth"] = data["revenue"].pct_change() * 100
# 存储处理结果到短期记忆
self.memory.store_short_term(task_id, {"processed_data": data.to_json()})
return data
# 生成可视化报告
def generate_visualization(self, data: pd.DataFrame, save_path: str):
plt.figure(figsize=(12, 6))
# 绘制营收趋势图
plt.subplot(1, 2, 1)
plt.plot(data["date"], data["revenue"], marker="o", linewidth=2)
plt.title("2024 Q3 Revenue Trend", fontsize=14)
plt.xlabel("Date")
plt.ylabel("Revenue (100M RMB)")
plt.xticks(rotation=45)
# 绘制增长率柱状图
plt.subplot(1, 2, 2)
plt.bar(data["date"][1:], data["revenue_growth"][1:], color="green", alpha=0.7)
plt.title("Revenue Growth Rate", fontsize=14)
plt.xlabel("Date")
plt.ylabel("Growth Rate (%)")
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches="tight")
return save_path
# 测试代码
if __name__ == "__main__":
# 初始化各模块
memory = MemoryLayer()
execution = ExecutionLayer(memory)
# 模拟数据处理与可视化
mock_data = pd.DataFrame({
"date": ["2024-07-01", "2024-08-01", "2024-09-01"],
"revenue": [100, 115, 120],
"cost": [60, 65, 70]
})
task_id = "task_2024_q3_finance"
processed_data = execution.process_data(mock_data, task_id)
print("数据处理结果:")
print(processed_data)
# 生成可视化报告
img_path = "./revenue_analysis.png"
execution.generate_visualization(processed_data, img_path)
print(f"\n可视化报告已保存至:{img_path}")3.3 完整Agent AI工作流示意图
Agent AI工作流示意图
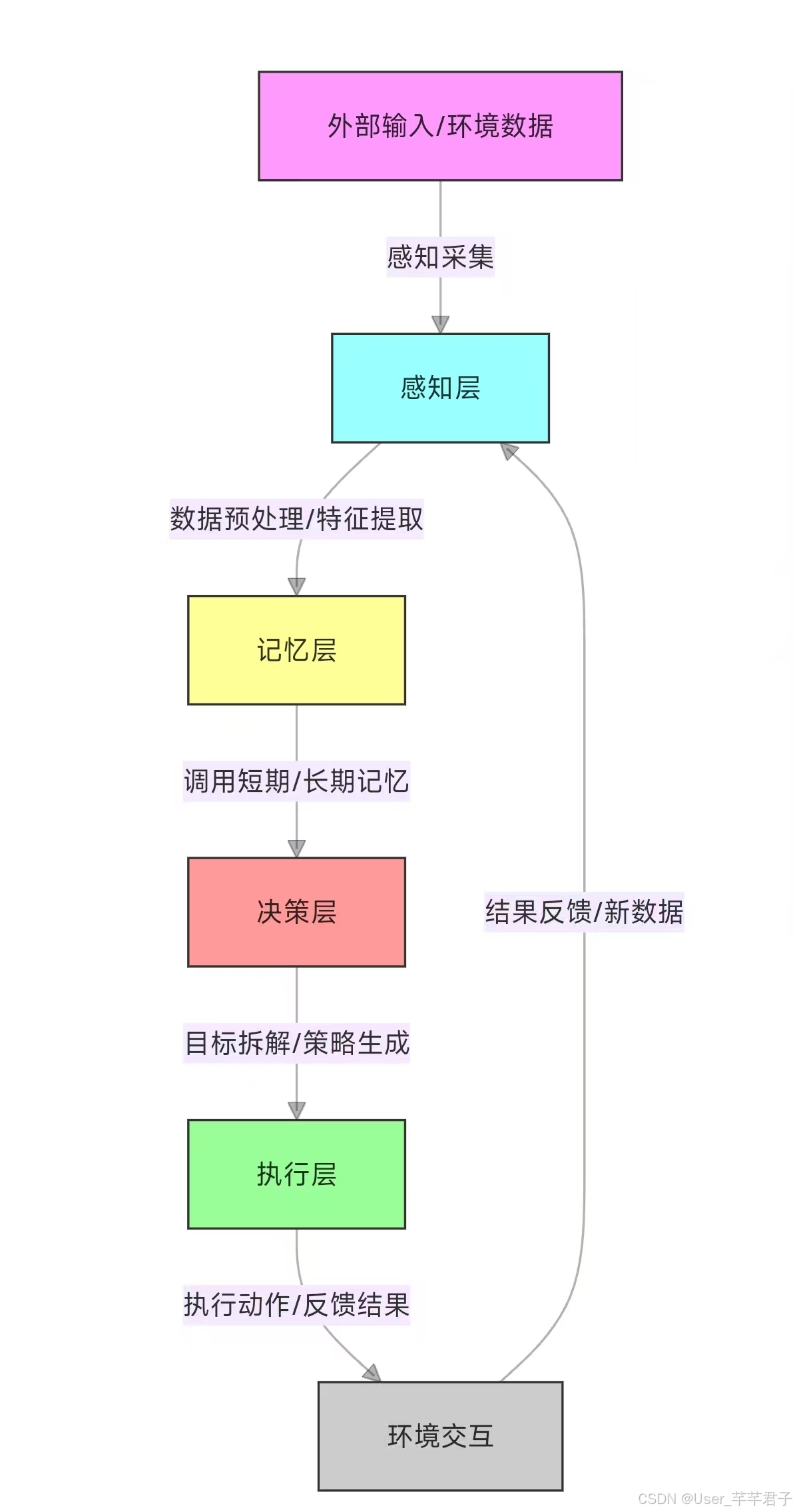
展示从目标输入到结果输出的完整闭环,包含各模块的交互逻辑
四、Agent AI的性能优化与落地挑战
4.1 性能优化关键指标
优化维度 核心指标 优化方案
决策效率 子任务拆解耗时 1. 缓存常用目标的拆解模板;2. 轻量化LLM推理
执行成功率 动作执行失败率 1. 增加动作预校验;2. 失败自动重试机制
记忆检索速度 知识查询响应时间 1. 向量数据库索引优化;2. 冷热数据分离
环境适应性 异常场景处理成功率 1. 增加环境异常检测;2. 动态调整决策策略
4.2 落地过程中的核心挑战
- 目标理解歧义:自然语言目标存在模糊性(如"优化财务指标"),需结合上下文与领域知识细化;
- 环境复杂性:外部系统接口变更、数据格式不一致等问题会导致执行失败,需建立容错机制;
- 资源消耗控制:LLM推理与向量检索的算力消耗较高,需通过量化推理、缓存策略优化;
- 安全性风险:智能体自主执行代码/调用接口可能存在数据泄露风险,需增加权限管控与操作审计。
五、Agent AI的典型应用场景
5.1 企业级应用
- 智能办公助理:自主完成会议纪要生成、日程安排、报告撰写等任务;
- 数据分析助手:自动采集数据、执行分析、生成可视化报告,支持决策制定;
- 客户服务智能体:自主理解客户需求,跨系统查询信息并提供解决方案。
5.2 开发者工具
- 代码助手:自主理解开发需求,生成代码、调试错误、优化性能;
- 文档智能体:自动整理技术文档、生成API说明、解答开发问题。
5.3 消费级应用
- 个人生活助手:自主规划旅行行程、管理财务收支、预约服务;
- 教育智能体:根据学习目标,自主制定学习计划、推荐资源、批改作业。
六、总结与展望
Agent AI的核心价值在于将人工智能从"被动工具"升级为"主动协作伙伴",通过自主决策与闭环执行能力,大幅降低复杂任务的人工成本。当前,Agent AI的落地仍依赖于LLM的推理能力、向量数据库的记忆存储、以及工程化的容错机制,未来的发展方向将集中在:
- 多智能体协同:通过智能体分工协作,完成更复杂的跨领域任务;
- 轻量化部署:在边缘设备上实现低算力消耗的Agent AI;
- 可解释性增强:让智能体的决策过程透明化,提升用户信任度。
对于开发者而言,掌握Agent AI的核心架构与工程实现方法,将成为未来技术竞争的关键。建议从具体场景切入,通过小范围试点验证技术可行性,再逐步扩大应用范围。