Apache SeaTunnel 的架构设计以 "批流一体、引擎无关、插件化扩展" 为核心,整体采用分层模块化结构,核心可拆解为 "三段式数据处理流程 + 核心计算引擎 + 辅助支撑组件",既保障了数据集成的高效性,又兼顾了适配性和易用性。
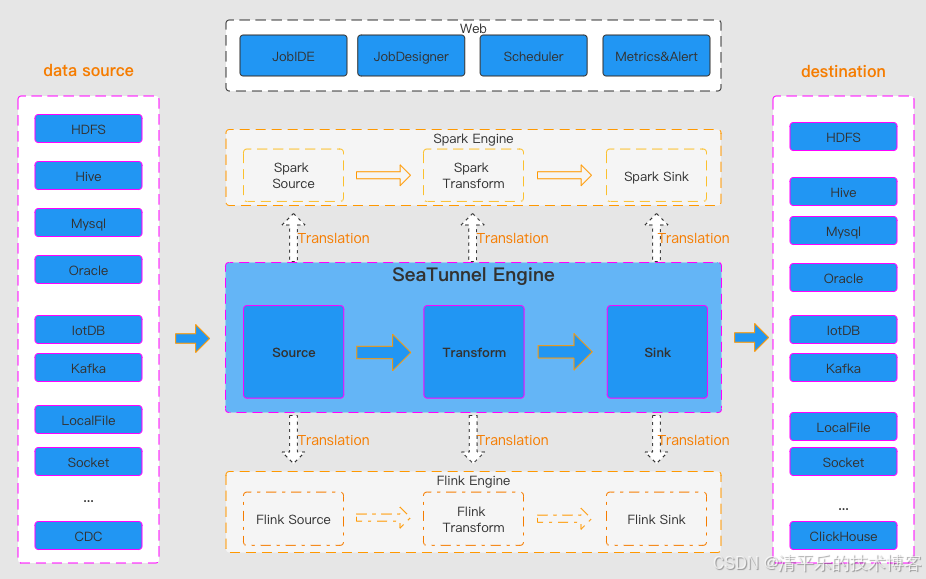
一、核心架构框架:Source→Transform→Sink 三段式流程
这是 SeaTunnel 数据处理的核心流程,所有组件以插件形式实现,通过 Java SPI 机制动态加载,用户可自由组合构建数据集成任务,无需硬编码开发。
Source(数据接入层)
负责从各类数据源读取数据,支持全量、增量、CDC 等多种读取模式。目前已支持超 100 种连接器,覆盖关系型数据库(MySQL、PostgreSQL)、大数据存储(HDFS、Kafka)、时序数据库(InfluxDB)等。例如 JdbcSource 适配主流 JDBC 数据源,KafkaSource 可对接消息队列实现流式数据消费,同时通过并行读取、连接复用技术提升数据抽取效率。
Transform(数据转换层)
对读取的数据执行清洗、过滤、格式转换等操作。提供 FieldMapper(字段映射)、Filter(条件过滤)、TypeConvert(数据类型转换)等常用组件,比如可将 "user_id" 映射为 "id",或过滤出满足 "age>18" 的数据。该层仅聚焦轻量转换,确保数据处理的低延迟,复杂计算则可对接外部引擎完成。
Sink(数据写入层)
将转换后的数据写入目标存储,支持批量写入、流式写入及事务保证。典型实现包括 JdbcSink(写入 MySQL、StarRocks 等)、HiveSink(对接 Hive 数据仓库)等,同时通过幂等性设计和分布式一致性机制,避免数据丢失或重复写入。
二、核心计算引擎:Zeta 引擎及多引擎适配能力
SeaTunnel 默认采用自研的 Zeta 引擎,同时兼容 Flink、Spark 等主流计算引擎,实现引擎无关性,适配企业不同技术栈。其中 Zeta 引擎作为核心,内部由三大核心服务构成,保障分布式场景下的高效调度与运行。
CoordinatorService
集群的 Master 服务,相当于 "调度中枢"。负责将作业从逻辑流程图(LogicalDag)转换为执行流程图(ExecutionDag)和物理流程图(PhysicalDag),并创建 JobMaster 管理单个作业的调度执行,同时通过 CheckpointCoordinator 把控数据一致性,ResourceManager 负责资源的申请与管理。
TaskExecutionService
集群的 Worker 服务,是任务的实际运行载体。采用动态线程共享技术减少 CPU 资源消耗,为每个数据处理任务提供独立的运行环境,保障任务并行执行的稳定性。
SlotService
在集群每个节点上运行,核心负责节点内资源的划分、申请与回收,合理分配 CPU、内存等资源,避免资源浪费或争抢。
三、辅助支撑组件
这类组件为核心流程提供运维、可视化、扩展等能力,降低使用和管理门槛。
1、SeaTunnel Web
独立部署的可视化子项目,提供作业管理、调度、监控等界面。用户可通过画布设计作业流程,直观查看同步任务的读写数据量、QPS 等指标,无需依赖命令行操作。
2、外围工具与监控
包含 MCP Server 等运维工具,同时支持集成 Prometheus 等监控系统。通过分布式快照算法和 Checkpoint 机制,即使节点故障,重启后也可恢复任务,保障数据同步一致性。
3、插件与 API 模块
通过 seatunnel-api 提供连接器 V2 接口,seatunnel-connectors-v2 模块支持插件开发与扩展,用户可通过 SPI 机制自定义连接器,适配自研数据源等特殊场景。此外 translation 模块负责适配 Connector V2 与 Flink、Spark 等外部引擎,实现插件一次开发多引擎复用。