文章目录
- 前言
- 时序数据管理的技术挑战
- 时序数据库选型的核心维度
- [Apache IoTDB 技术架构深度解析](#Apache IoTDB 技术架构深度解析)
- [IoTDB 实战代码示例](#IoTDB 实战代码示例)
-
- 快速部署(Docker)
- [Java 原生 API 开发](#Java 原生 API 开发)
-
- [添加 Maven 依赖](#添加 Maven 依赖)
- [创建 Session 连接](#创建 Session 连接)
- [创建时间序列(Schema 定义)](#创建时间序列(Schema 定义))
- 批量写入对齐时间序列
- 高级写入:多设备批量插入
- [SQL 查询示例](#SQL 查询示例)
- [5.4 查询数据](#5.4 查询数据)
- 性能优化最佳实践
- 工业场景实战案例
-
- 智能制造:设备健康监测
- 智慧能源:电力负荷预测
- [车联网:OBD 实时诊断](#车联网:OBD 实时诊断)
- 选型建议与最佳实践
- 总结
前言
在数字化转型浪潮下,工业物联网(IIoT)产生的时序数据呈爆发式增长。从智能制造的设备监控到智慧能源的负荷分析,从车联网的实时诊断到智慧城市的环境感知,海量时序数据的高效存储、查询与分析成为企业面临的核心挑战。本文将从技术架构视角深度解析时序数据库选型要点,并重点剖析 Apache IoTDB 在工业场景中的技术优势。

时序数据管理的技术挑战
时序数据的核心特征
时序数据与传统业务数据有着本质区别:
写入特征:
- 高频写入:工业设备通常以毫秒级甚至微秒级频率上报数据,单个项目日增数据可达 TB 级
- 批量插入:物联网场景下设备批量上报,要求数据库支持高效批量写入
- 乱序处理:网络波动、设备离线导致数据延迟到达,需要处理乱序数据写入
查询特征:
- 时间范围查询:按时间窗口查询是最常见的访问模式
- 聚合计算:平均值、最大值、统计分析是核心需求
- 多维下钻:从企业→工厂→车间→产线→设备的层级查询
存储特征:
- 数据量巨大:年度数据可达 PB 级,传统数据库难以承载
- 访问模式固定:极少更新和删除,主要是追加写入
- 生命周期管理:历史数据价值递减,需要分层存储和 TTL 机制
传统数据库的局限性
| 数据库类型 | 核心问题 | 具体表现 |
|---|---|---|
| 关系型数据库 | 写入性能瓶颈 | MySQL/PostgreSQL 在百万级点位/秒写入时性能急剧下降 |
| NoSQL 数据库 | 时序优化不足 | MongoDB/Cassandra 缺乏时间索引优化,查询效率低 |
| 通用时序数据库 | 工业场景适配弱 | 缺乏层级模型、边云协同等工业特性 |
时序数据库选型的核心维度
性能维度
| 性能指标 | 评估标准 | 工业场景要求 |
|---|---|---|
| 写入吞吐量 | Points/Second | 单机 ≥ 100 万点/秒,集群线性扩展 |
| 查询延迟 | 毫秒级响应 | TB 级数据聚合查询 < 100ms |
| 乱序处理 | 延迟容忍度 | 支持小时级乱序数据高效写入 |
| 并发能力 | 同时在线用户 | 支持千级并发查询不降级 |
成本维度
| 成本因素 | 关键指标 | 优秀标准 |
|---|---|---|
| 存储压缩比 | 压缩前后数据量 | 工业数值类型 ≥ 10:1 |
| 硬件需求 | 单位数据算力 | 低配服务器可处理亿级测点 |
| 运维复杂度 | 人力成本 | 支持自动化运维和故障自愈 |
生态维度
| 生态能力 | 评估要点 | 说明 |
|---|---|---|
| 数据接入 | 协议支持 | MQTT、OPC UA、Modbus 等工业协议 |
| 可视化对接 | 工具集成 | Grafana、DataEase 等主流工具 |
| 大数据集成 | 生态连接器 | Spark、Flink、Kafka 原生对接 |
| 边缘计算 | 端侧能力 | 轻量化部署和边云协同 |
Apache IoTDB 技术架构深度解析
Apache IoTDB 是清华大学主导研发的开源时序数据库,已成为 Apache 顶级项目。其专为工业物联网设计的技术架构解决了传统时序数据库的多个痛点。
整体架构设计
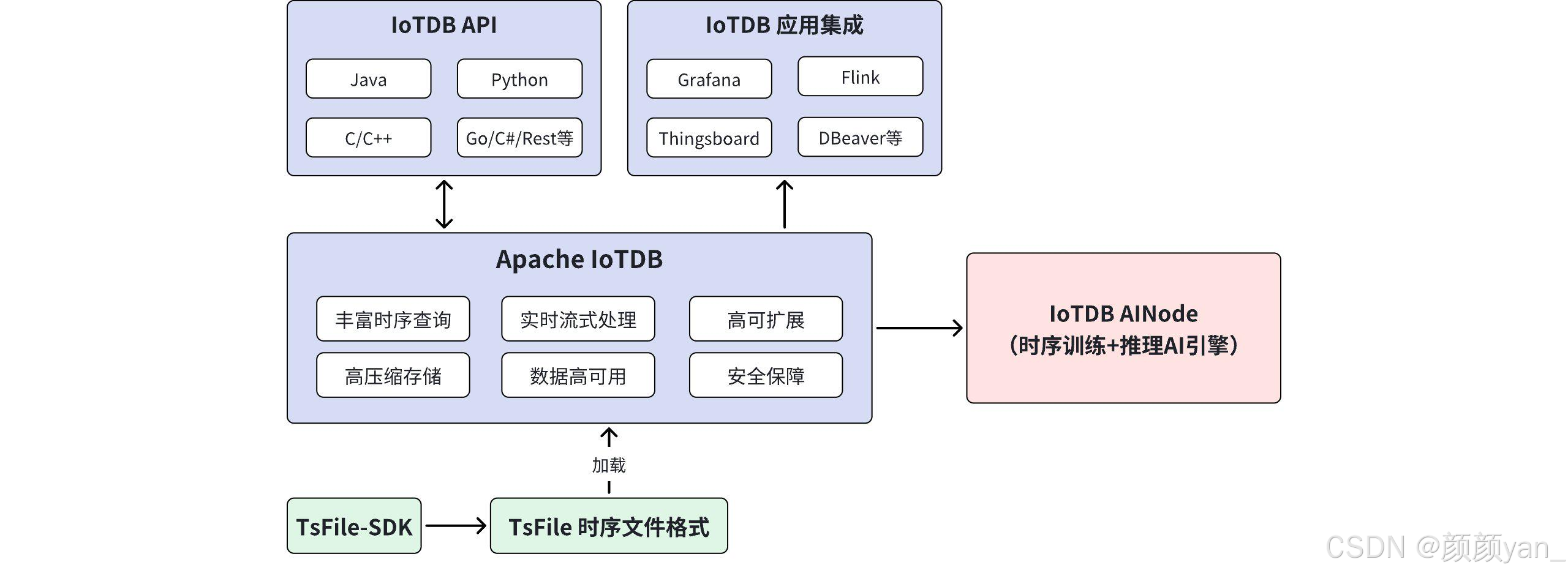
IoTDB 采用模块化分层架构:
┌─────────────────────────────────────────┐
│ 应用层:多语言 API + 可视化工具 │
├─────────────────────────────────────────┤
│ 服务层:ConfigNode + DataNode 集群 │
│ - ConfigNode: 元数据管理、集群协调 │
│ - DataNode: 数据存储、查询计算 │
├─────────────────────────────────────────┤
│ 存储层:TsFile 列式存储引擎 │
│ - LSM Tree 架构 │
│ - 多层索引(时间、元数据、多维) │
│ - 专用压缩算法(RLE、Gorilla、GZIP) │
└─────────────────────────────────────────┘核心组件说明:
-
ConfigNode(配置节点)
- 管理集群元数据(Schema、分区信息)
- 提供分布式协调服务
- 支持 3 节点部署实现高可用
-
DataNode(数据节点)
- 负责数据的实际存储和查询
- 支持水平扩展,动态增删节点
- 自动负载均衡和数据分片
-
TsFile 存储引擎
- 专为时序数据设计的列式存储格式
- 支持多种压缩算法组合优化
- 独立文件格式,可直接用于大数据分析
核心技术特性
TsFile 存储引擎
TsFile 是 IoTDB 自研的时序数据文件格式,采用三层索引结构:
TsFile 文件结构:
┌────────────────────┐
│ Magic String │ 文件头标识
├────────────────────┤
│ Chunk Group 1 │ 设备数据组
│ ├─ Chunk 1 │ 测点数据块
│ │ ├─ Page 1 │ 数据页(压缩)
│ │ └─ Page 2 │
│ └─ Chunk 2 │
├────────────────────┤
│ Chunk Group 2 │
├────────────────────┤
│ Index 索引区 │ 三层索引
│ ├─ Device Index │ 设备索引
│ ├─ Measurement │ 测点索引
│ └─ Time Index │ 时间索引
├────────────────────┤
│ Metadata 元数据 │ 统计信息
└────────────────────┘压缩算法组合:
- 数值类型:RLE(游程编码)+ Gorilla(浮点压缩)
- 布尔类型:位图压缩
- 文本类型:字典编码 + Snappy
- 二次压缩:可选 LZ4/GZIP 再压缩
实测数据显示,工业场景下压缩比可达 10:1 至 20:1 。

对齐时间序列
针对"设备级批量上报"场景,IoTDB 创新性地提出对齐时间序列(Aligned Timeseries):
传统存储:
设备 A:
timestamp | temperature | pressure | vibration
---------------------------------------------
1000 | 25.6 | 1.2 | 0.03
2000 | 25.8 | 1.1 | 0.04每行重复存储时间戳,浪费空间。
对齐存储:
设备 A(对齐):
timestamp | temperature | pressure | vibration
---------------------------------------------
[1000, 2000] | [25.6, 25.8] | [1.2, 1.1] | [0.03, 0.04]时间戳只存储一次,多个测点按列对齐,写入性能提升 30%-50%。
树形数据模型
IoTDB 采用层次化路径模型,完美映射工业组织结构:
root # 根节点
└─ factory01 # 工厂
├─ workshop01 # 车间
│ ├─ line01 # 产线
│ │ └─ device001 # 设备
│ │ ├─ temperature # 测点
│ │ ├─ pressure
│ │ └─ vibration
│ └─ line02
└─ workshop02分级聚合能力:
sql
-- 按车间统计平均温度
SELECT AVG(temperature)
FROM root.factory01.**
GROUP BY LEVEL = 2;
-- 按产线统计设备数量
SELECT COUNT(DISTINCT device)
FROM root.factory01.workshop01.**
GROUP BY LEVEL = 3;边云协同架构
IoTDB 支持从端到云的全栈部署:
┌─────────────┐
│ 边缘端 │ IoTDB Lite (200KB)
│ - 嵌入式 │ - 本地缓存
│ - 实时处理 │ - 边缘计算
└──────┬──────┘
│ 数据同步
┌──────▼──────┐
│ 边缘服务器 │ IoTDB 单机版
│ - 小规模 │ - 数据预处理
│ - 协议转换 │ - 历史缓存
└──────┬──────┘
│ 数据上传
┌──────▼──────┐
│ 云端集群 │ IoTDB 分布式集群
│ - 海量存储 │ - 大数据分析
│ - 全局分析 │ - AI 建模
└─────────────┘
IoTDB 实战代码示例
快速部署(Docker)
bash
# 1. 拉取最新镜像
docker pull apache/iotdb:latest
# 2. 启动容器
docker run -d \
--name iotdb-server \
-p 6667:6667 \
-p 8181:8181 \
-v iotdb-data:/iotdb/data \
apache/iotdb:latest
# 3. 进入 CLI 客户端
docker exec -it iotdb-server /iotdb/sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw rootJava 原生 API 开发
添加 Maven 依赖
xml
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>iotdb-session</artifactId>
<version>1.3.2</version>
</dependency>创建 Session 连接
java
import org.apache.iotdb.session.Session;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
public class IoTDBQuickStart {
private static Session session;
public static void main(String[] args) {
try {
// 创建 Session 连接
session = new Session.Builder()
.host("127.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
// 打开连接
session.open(false);
System.out.println("IoTDB 连接成功!");
// 执行业务逻辑
createTimeseries();
insertData();
queryData();
} catch (IoTDBConnectionException e) {
System.err.println("连接失败:" + e.getMessage());
} catch (StatementExecutionException e) {
System.err.println("执行失败:" + e.getMessage());
} finally {
closeSession();
}
}
private static void closeSession() {
try {
if (session != null) {
session.close();
System.out.println("连接已关闭");
}
} catch (IoTDBConnectionException e) {
System.err.println("关闭连接失败:" + e.getMessage());
}
}
}创建时间序列(Schema 定义)
java
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.file.metadata.enums.TSEncoding;
import org.apache.iotdb.tsfile.file.metadata.enums.CompressionType;
public static void createTimeseries() throws StatementExecutionException, IoTDBConnectionException {
// 创建数据库
session.createDatabase("root.factory01");
// 创建单个时间序列
session.createTimeseries(
"root.factory01.workshop01.device001.temperature", // 路径
TSDataType.FLOAT, // 数据类型
TSEncoding.RLE, // 编码方式
CompressionType.SNAPPY // 压缩算法
);
session.createTimeseries(
"root.factory01.workshop01.device001.pressure",
TSDataType.FLOAT,
TSEncoding.RLE,
CompressionType.SNAPPY
);
session.createTimeseries(
"root.factory01.workshop01.device001.vibration",
TSDataType.FLOAT,
TSEncoding.GORILLA,
CompressionType.SNAPPY
);
session.createTimeseries(
"root.factory01.workshop01.device001.status",
TSDataType.BOOLEAN,
TSEncoding.RLE,
CompressionType.SNAPPY
);
System.out.println("时间序列创建成功!");
}批量写入对齐时间序列
java
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public static void insertData() throws IoTDBConnectionException, StatementExecutionException {
// 1. 定义 Schema
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("temperature", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("pressure", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("vibration", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("status", TSDataType.BOOLEAN));
// 2. 创建 Tablet(批量数据容器)
String deviceId = "root.factory01.workshop01.device001";
Tablet tablet = new Tablet(deviceId, schemaList, 1000); // 最多 1000 行
// 3. 批量添加数据
long startTime = System.currentTimeMillis();
for (int row = 0; row < 1000; row++) {
int rowIndex = tablet.rowSize++;
tablet.addTimestamp(rowIndex, startTime + row * 1000); // 每秒一条
tablet.addValue("temperature", rowIndex, 25.0f + (float)(Math.random() * 5));
tablet.addValue("pressure", rowIndex, 1.0f + (float)(Math.random() * 0.5));
tablet.addValue("vibration", rowIndex, 0.01f + (float)(Math.random() * 0.05));
tablet.addValue("status", rowIndex, Math.random() > 0.1); // 90% 正常
}
// 4. 插入数据(对齐写入)
session.insertAlignedTablet(tablet);
System.out.println("成功写入 " + tablet.rowSize + " 条数据!");
// 5. 重置 Tablet 供下次使用
tablet.reset();
}高级写入:多设备批量插入
java
import org.apache.iotdb.session.SessionDataSet;
import org.apache.iotdb.session.SessionDataSet.DataIterator;
import java.util.HashMap;
import java.util.Map;
public static void insertMultiDevices() throws IoTDBConnectionException, StatementExecutionException {
// 定义多个设备的 Tablet
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("temperature", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("pressure", TSDataType.FLOAT));
Map<String, Tablet> tabletMap = new HashMap<>();
// 为多个设备创建 Tablet
for (int deviceNum = 1; deviceNum <= 10; deviceNum++) {
String deviceId = "root.factory01.workshop01.device" + String.format("%03d", deviceNum);
Tablet tablet = new Tablet(deviceId, schemaList, 100);
// 填充数据
long timestamp = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
int rowIndex = tablet.rowSize++;
tablet.addTimestamp(rowIndex, timestamp + i * 1000);
tablet.addValue("temperature", rowIndex, 20.0f + (float)(Math.random() * 10));
tablet.addValue("pressure", rowIndex, 1.0f + (float)(Math.random()));
}
tabletMap.put(deviceId, tablet);
}
// 批量插入多个设备的数据
session.insertAlignedTablets(tabletMap);
System.out.println("成功写入 " + tabletMap.size() + " 个设备的数据!");
}SQL 查询示例
基础查询
sql
-- 查询最新数据
SELECT * FROM root.factory01.workshop01.device001
ORDER BY time DESC
LIMIT 10;
-- 时间范围查询
SELECT temperature, pressure, vibration
FROM root.factory01.workshop01.device001
WHERE time >= 2024-01-01T00:00:00 AND time < 2024-01-02T00:00:00;
-- 条件过滤
SELECT * FROM root.factory01.workshop01.device001
WHERE temperature > 30 AND status = true;聚合查询
sql
-- 时间窗口聚合(每小时平均值)
SELECT AVG(temperature), MAX(pressure), MIN(vibration)
FROM root.factory01.workshop01.device001
GROUP BY ([2024-01-01T00:00:00, 2024-01-02T00:00:00), 1h);
-- 降采样查询(每 10 分钟一个点)
SELECT AVG(temperature) AS temp_avg
FROM root.factory01.workshop01.device001
GROUP BY ([now() - 24h, now()), 10m);层级聚合
sql
-- 按车间统计平均温度
SELECT AVG(temperature)
FROM root.factory01.**
GROUP BY LEVEL = 2;
-- 按产线统计设备数量
SELECT COUNT(device)
FROM root.factory01.workshop01.**
GROUP BY LEVEL = 3;
-- 多层级联合统计
SELECT LEVEL = 2 AS workshop,
LEVEL = 4 AS device,
AVG(temperature) AS avg_temp
FROM root.factory01.**
GROUP BY LEVEL = 2, LEVEL = 4;高级分析函数
sql
-- 滑动窗口平均
SELECT temperature,
AVG(temperature) OVER (ORDER BY time ROWS BETWEEN 9 PRECEDING AND CURRENT ROW) AS moving_avg
FROM root.factory01.workshop01.device001;
-- 时间插值(填充缺失值)
SELECT temperature,
LINEAR_FILL(temperature) AS temp_filled
FROM root.factory01.workshop01.device001
WHERE time >= 2024-01-01T00:00:00 AND time < 2024-01-01T01:00:00;
-- 异常检测(标准差法)
SELECT time, temperature
FROM root.factory01.workshop01.device001
WHERE ABS(temperature - AVG(temperature)) > 3 * STDDEV(temperature);5.4 查询数据
java
import org.apache.iotdb.session.SessionDataSet;
import org.apache.iotdb.tsfile.read.common.Field;
import org.apache.iotdb.tsfile.read.common.RowRecord;
public static void queryData() throws StatementExecutionException, IoTDBConnectionException {
// 1. 执行查询
String sql = "SELECT temperature, pressure, vibration, status " +
"FROM root.factory01.workshop01.device001 " +
"WHERE time >= now() - 1h " +
"ORDER BY time DESC " +
"LIMIT 100";
SessionDataSet dataSet = session.executeQueryStatement(sql);
// 2. 打印列名
System.out.println("查询结果:");
System.out.println("Time\t\t\tTemperature\tPressure\tVibration\tStatus");
System.out.println("=".repeat(80));
// 3. 遍历结果集
int rowCount = 0;
while (dataSet.hasNext()) {
RowRecord record = dataSet.next();
// 获取时间戳
long timestamp = record.getTimestamp();
// 获取字段值
List<Field> fields = record.getFields();
float temperature = fields.get(0).getFloatV();
float pressure = fields.get(1).getFloatV();
float vibration = fields.get(2).getFloatV();
boolean status = fields.get(3).getBoolV();
// 打印数据
System.out.printf("%d\t%.2f\t\t%.2f\t\t%.4f\t\t%b%n",
timestamp, temperature, pressure, vibration, status);
rowCount++;
}
System.out.println("=".repeat(80));
System.out.println("共查询到 " + rowCount + " 条记录");
// 4. 关闭结果集
dataSet.closeOperationHandle();
}性能优化最佳实践
java
public class IoTDBPerformanceOptimization {
/**
* 优化 1:使用对齐时间序列
*/
public static void useAlignedTimeseries() throws Exception {
// 创建对齐时间序列
List<String> measurements = Arrays.asList("temperature", "pressure", "vibration");
List<TSDataType> dataTypes = Arrays.asList(
TSDataType.FLOAT, TSDataType.FLOAT, TSDataType.FLOAT
);
List<TSEncoding> encodings = Arrays.asList(
TSEncoding.RLE, TSEncoding.RLE, TSEncoding.GORILLA
);
List<CompressionType> compressors = Arrays.asList(
CompressionType.SNAPPY, CompressionType.SNAPPY, CompressionType.SNAPPY
);
session.createAlignedTimeseries(
"root.factory01.workshop01.device001",
measurements,
dataTypes,
encodings,
compressors
);
}
/**
* 优化 2:批量写入配置
*/
public static Session createOptimizedSession() {
return new Session.Builder()
.host("127.0.0.1")
.port(6667)
.username("root")
.password("root")
.fetchSize(10000) // 增大查询批次大小
.enableRedirection(true) // 启用重定向(集群)
.build();
}
/**
* 优化 3:使用 Schema 模板
*/
public static void useSchemaTemplate() throws Exception {
// 创建模板
Template template = new Template("device_template");
template.addAlignedMeasurement("temperature", TSDataType.FLOAT, TSEncoding.RLE, CompressionType.SNAPPY);
template.addAlignedMeasurement("pressure", TSDataType.FLOAT, TSEncoding.RLE, CompressionType.SNAPPY);
template.addAlignedMeasurement("vibration", TSDataType.FLOAT, TSEncoding.GORILLA, CompressionType.SNAPPY);
// 创建并挂载模板
session.createSchemaTemplate(template);
session.setSchemaTemplate("device_template", "root.factory01");
// 自动应用模板(写入时自动创建时间序列)
}
/**
* 优化 4:异步写入
*/
public static void asyncInsert() throws Exception {
// 开启异步写入模式
session.setEnableQueryRedirection(false);
// 批量异步写入
for (int i = 0; i < 10; i++) {
Tablet tablet = createTablet(i);
session.insertTablet(tablet, false); // 不等待响应
}
// 等待所有异步操作完成
Thread.sleep(1000);
}
}工业场景实战案例
智能制造:设备健康监测
场景描述:
某汽车制造厂拥有 500 条产线,每条产线 20 台关键设备,每台设备 50 个监测点,采样频率 1Hz,需要实时监控设备健康状态。
技术方案:
java
// 1. 数据模型设计
root.automobile_factory
├─ line001
│ ├─ robot001 (焊接机器人)
│ │ ├─ temperature # 温度
│ │ ├─ current # 电流
│ │ ├─ vibration_x # X 轴振动
│ │ ├─ vibration_y # Y 轴振动
│ │ └─ error_code # 故障码
│ └─ robot002
└─ line002
// 2. 实时健康度计算
SELECT
LEVEL = 2 AS production_line,
COUNT(CASE WHEN temperature > 80 THEN 1 END) AS overheat_count,
AVG(vibration_x) AS avg_vibration,
SUM(CASE WHEN error_code != 0 THEN 1 END) AS error_count
FROM root.automobile_factory.**
WHERE time >= now() - 5m
GROUP BY LEVEL = 2, ([now() - 5m, now()), 1m);性能数据:
- 总测点数:500 × 20 × 50 = 50 万
- 写入速率:50 万点/秒
- 存储空间:10TB/年(压缩后)
- 查询延迟:< 50ms
智慧能源:电力负荷预测
场景描述:
省级电网需要管理 10 万个变电站的实时负荷数据,每个站点 100 个监测点,要求秒级响应聚合查询。
技术方案:
sql
-- 1. 分区域负荷统计
SELECT
LEVEL = 2 AS region,
SUM(active_power) AS total_load,
AVG(voltage) AS avg_voltage
FROM root.power_grid.**
WHERE time >= now() - 15m
GROUP BY LEVEL = 2, ([now() - 15m, now()), 5m);
-- 2. 负荷曲线预测(结合 AI)
SELECT
time,
active_power,
FORECAST(active_power, 'ARIMA', 24) AS predicted_load
FROM root.power_grid.region_east.station001.transformer001
WHERE time >= now() - 7d;性能数据:
- 总测点数:1000 万
- 日增数据量:864 亿条
- 压缩比:15:1
- 聚合查询:< 100ms
车联网:OBD 实时诊断
场景描述:
车联网平台管理 100 万辆在线车辆,每辆车 200 个 OBD 参数,需要支持实时故障诊断和历史轨迹回放。
技术方案:
java
// 1. 车辆数据模型
root.vehicle_platform
├─ vehicle_0001 (车辆 VIN)
│ ├─ gps_latitude # GPS 纬度
│ ├─ gps_longitude # GPS 经度
│ ├─ speed # 车速
│ ├─ engine_rpm # 发动机转速
│ ├─ fuel_consumption # 油耗
│ └─ dtc_codes # 故障码
// 2. 实时异常检测
SELECT time, vehicle_id, engine_rpm, coolant_temp
FROM root.vehicle_platform.**
WHERE engine_rpm > 6000
OR coolant_temp > 120
OR dtc_codes IS NOT NULL
AND time >= now() - 1m;性能数据:
- 总测点数:2 亿
- 峰值写入:5000 万点/秒
- 存储成本:100TB 数据占用 5TB
- 并发查询:支持 1000+ 用户同时在线
选型建议与最佳实践
选型决策树
开始选型
│
├─ 是否为工业物联网场景?
│ ├─ 是 → 需要设备层级管理?
│ │ ├─ 是 → 需要边缘计算?
│ │ │ ├─ 是 → **推荐 IoTDB**(端边云协同)
│ │ │ └─ 否 → **推荐 IoTDB**(树形模型 + 分级聚合)
│ │ └─ 否 → 考虑 InfluxDB 或 QuestDB
│ └─ 否 → IT 监控?
│ ├─ 是 → **推荐 InfluxDB**(生态成熟)
│ └─ 否 → 金融场景?
│ └─ 是 → **推荐 TimescaleDB**(SQL 兼容)部署架构建议
小规模场景(< 1000 设备):
- 单机部署 IoTDB
- 配置:4 核 8GB + 500GB SSD
- 成本:约 5000 元/年(云服务器)
中等规模(1000 - 10 万设备):
- 3 ConfigNode + 3 DataNode 集群
- 配置:每节点 8 核 16GB + 2TB SSD
- 成本:约 5 万元/年
大规模场景(> 10 万设备):
- 边缘 + 云端混合架构
- 边缘侧:IoTDB Lite(200KB)
- 云端:分布式集群(按需扩展)
性能调优检查清单
✅ 存储优化
- 使用对齐时间序列(aligned timeseries)
- 选择合适的压缩算法(数值用 RLE/Gorilla)
- 配置 TTL 策略(自动清理历史数据)
- 启用数据分层存储(冷热分离)
✅ 写入优化
- 使用批量写入(Tablet 接口)
- 每批次数据 > 1000 行
- 启用异步写入模式
- 使用 Schema 模板减少元数据开销
✅ 查询优化
- 创建合适的时间分区
- 使用时间范围过滤(避免全表扫描)
- 利用分级聚合(GROUP BY LEVEL)
- 增大 fetchSize 参数
✅ 集群优化
- 配置节点亲和性(减少网络开销)
- 启用负载均衡
- 监控数据分片均衡度
- 定期执行 Compaction
总结
随着工业互联网、新能源、智慧城市等领域的快速发展,时序数据的规模和价值将持续增长。选择一个技术先进、生态完善的时序数据库平台,将为企业数字化转型提供坚实的数据基础。IoTDB凭借其在工业场景的深度优化和持续创新,正成为国产时序数据库的标杆,值得技术团队深入评估和实践。
📥 下载地址 :https://iotdb.apache.org/zh/Download/
🏢 官网 :https://timecho.com
