内容为AI生成,主要是辅助论文阅读,细节还需自己看论文。
2012 年:AlexNet论文标题:《ImageNet Classification with Deep Convolutional Neural Networks》
下载链接:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
1. 一段话总结
Alex Krizhevsky、Ilya Sutskever和Geoffrey E. Hinton(多伦多大学)提出的AlexNet ,是一种深度卷积神经网络(CNN),旨在对ImageNet LSVRC数据集的120万张高分辨率图像 进行1000类分类;其网络包含5个卷积层(部分后接最大池化层)和3个全连接层 ,共6000万参数、65万个神经元,核心创新包括采用ReLU非线性激活函数 (加速训练)、双GPU并行训练 (突破内存限制)、局部响应归一化 (提升泛化)、重叠池化 (降低过拟合),并通过数据增强 (扩大训练集)和Dropout (抑制神经元共适应)缓解过拟合;在ILSVRC-2010测试集上实现top-1 37.5%、top-5 17.0%的误差率 ,ILSVRC-2012竞赛中以top-5 15.3%的误差率远超第二名(26.2%),显著突破当时的技术水平。
2. 思维导图(mindmap)
mindmap
## AlexNet(NIPS 2012)
- 研究目标
- 解决ImageNet LSVRC数据集1000类图像分类问题
- 突破传统方法性能瓶颈,实现更高分类精度
- 数据集
- 基础数据集:ImageNet(1500万张图,22000类)
- 实验子集:ILSVRC(1000类)
- 训练集:120万张
- 验证集:5万张
- 测试集:15万张
- 预处理:图像缩放到256×256,减训练集像素均值
- 网络架构(共8个学习层)
- 核心组件
- ReLU:非饱和激活,训练速度比tanh快数倍
- 双GPU并行:拆分 kernels,仅特定层通信,降错1.7%/1.2%
- 局部响应归一化:k=2、n=5、α=1e-4、β=0.75,降错1.4%/1.2%
- 重叠池化:s=2、z=3,降错0.4%/0.3%
- 层结构细节
- 卷积层(5层):96×11×11×3 → 256×5×5×48 → 384×3×3×256 → 384×3×3×192 → 256×3×3×192
- 全连接层(3层):4096 → 4096 → 1000-way softmax
- 防过拟合策略
- 数据增强
- 随机裁剪+水平翻转:训练集扩2048倍,测试用10个patch平均
- RGB强度调整:PCA降维后加随机扰动,减top-1误差1%
- Dropout:前两个全连接层,神经元失活概率0.5,收敛迭代加倍
- 训练细节
- 优化器: stochastic gradient descent(SGD)
- 关键参数:批大小128,动量0.9,权重衰减0.0005
- 初始化:权重高斯分布(均值0,标准差0.01),部分偏置=1/0
- 学习率:初始0.01,共调整3次(每次÷10)
- 硬件/时间:双GTX 580(3GB),训练5-6天(90轮)
- 实验结果
- ILSVRC-2010:top-1 37.5%、top-5 17.0%(远超Sparse coding的47.1%/28.2%)
- ILSVRC-2012:7个CNN平均top-5 15.3%(远超第二名26.2%)
- Fall 2009 ImageNet:top-1 67.4%、top-5 40.9%(远超此前78.1%/60.9%)
- 核心贡献与展望
- 贡献:GPU优化CNN实现、架构创新、防过拟合方法、性能突破
- 展望:深度对性能关键,未来可探索更大网络、视频序列数据3. 详细总结
1. 研究背景与目标
- 核心目标:针对ImageNet LSVRC竞赛数据集(1000类、120万张训练图),构建深度卷积神经网络(CNN),解决高分辨率图像分类问题,突破传统方法的性能瓶颈。
- 背景挑战 :
- 传统图像数据集规模小(如NORB、Caltech-101),难以应对真实场景中物体的 variability;
- 高分辨率图像的CNN训练计算成本极高,此前难以大规模应用;
- 大型网络易过拟合,需有效正则化方法。
2. 数据集详情
| 数据集类型 | 规模/参数 | 预处理方式 |
|---|---|---|
| ImageNet(整体) | 1500万张图,22000个类别 | - |
| ILSVRC(子集) | 1000个类别 | - |
| - 训练集 | 120万张 | 1. 缩放到256×256(短边先缩至256); 2. 裁剪中心256×256 patch; 3. 减去训练集像素均值 |
| - 验证集 | 5万张 | 同训练集预处理 |
| - 测试集 | 15万张(ILSVRC-2010标签可获取) | 同训练集预处理 |
- 评价指标 :采用ImageNet传统指标------top-1误差率 (预测第一类别错误占比)和top-5误差率(预测前5类别无正确标签占比)。
3. 网络架构设计(共8个学习层:5卷积+3全连接)
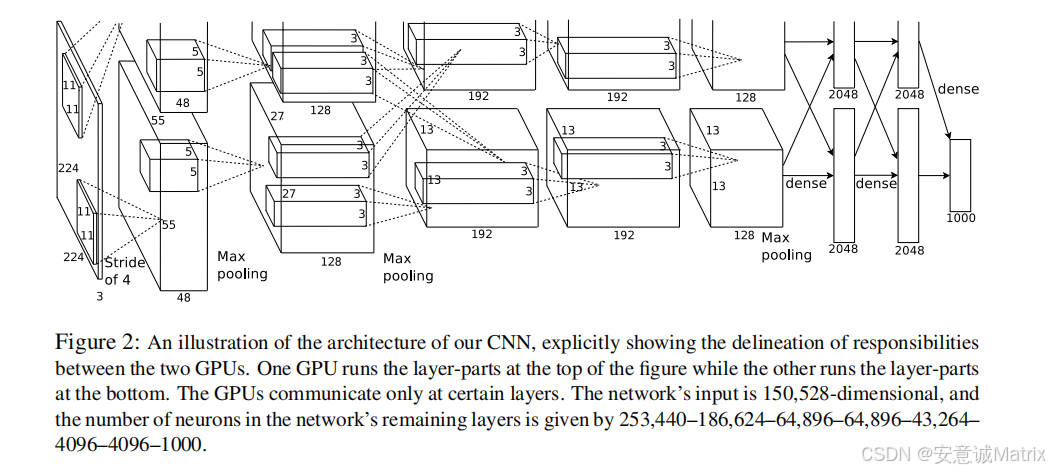
3.1 核心创新组件(按重要性排序)
-
ReLU非线性激活函数
- 传统激活函数(tanh、sigmoid)为饱和型,训练速度慢;AlexNet采用f(x)=max(0,x) 的ReLU,使训练速度提升数倍(如CIFAR-10数据集上,达25%训练误差的迭代次数仅为tanh网络的1/6)。
-
双GPU并行训练
- 单GTX 580(3GB内存)无法容纳大型网络,故将网络拆分为两部分,每GPU负责一半kernels;
- 仅特定层(如第3卷积层)跨GPU通信,平衡计算与通信成本;
- 效果:相比单GPU(同参数规模),top-1/top-5误差率分别降低1.7%、1.2%,训练时间略短。
-
局部响应归一化(LRN)
- 目的:模拟神经元侧向抑制,增强泛化能力;
- 公式:(b_{x, y}^{i}=a_{x, y}^{i} /\left(k+\alpha \sum_{j=max (0, i-n / 2)}^{min (N-1, i+n / 2)}\left(a_{x, y}{j}\right){2}\right)^{\beta})
- 参数:(k=2)、(n=5)、(\alpha=10^{-4})、(\beta=0.75);
- 效果:top-1/top-5误差率分别降低1.4%、1.2%,CIFAR-10测试误差从13%降至11%。
-
重叠池化
- 传统池化(s=z,无重叠)易丢失细节;AlexNet采用s=2、z=3(步长2,池化窗口3×3),实现重叠池化;
- 效果:相比s=2、z=2(同输出维度),top-1/top-5误差率分别降低0.4%、0.3%,且更难过拟合。
3.2 整体层结构细节
| 层类型 | 层序号 | 核心参数 | 后续操作 |
|---|---|---|---|
| 卷积层 | 1 | 96个11×11×3核,步长4 | ReLU → LRN → 重叠池化 |
| 卷积层 | 2 | 256个5×5×48核(单GPU仅处理24个) | ReLU → LRN → 重叠池化 |
| 卷积层 | 3 | 384个3×3×256核(跨GPU通信,接收所有前层输出) | ReLU |
| 卷积层 | 4 | 384个3×3×192核(单GPU仅处理192个) | ReLU |
| 卷积层 | 5 | 256个3×3×192核(单GPU仅处理128个) | ReLU → 重叠池化 |
| 全连接层 | 6 | 4096个神经元 | ReLU → Dropout(概率0.5) |
| 全连接层 | 7 | 4096个神经元 | ReLU → Dropout(概率0.5) |
| 全连接层 | 8 | 1000个神经元(对应1000类) | 1000-way softmax |
- 注:所有卷积层和全连接层输出均接ReLU;softmax层用于输出类别概率分布,目标函数为多分类逻辑回归(最大化正确标签的对数概率)。
4. 过拟合缓解策略
4.1 数据增强(无额外计算成本,CPU生成变换图像时GPU训练)
-
空间变换增强
- 操作:从256×256图像中随机裁剪224×224 patch,并生成水平翻转版本;
- 效果:训练集规模扩大2048倍(缓解过拟合);测试时取5个patch(4角+中心)及翻转版(共10个),平均预测结果提升精度。
-
RGB强度增强
- 操作:对ImageNet训练集RGB像素做PCA,向每个图像的RGB通道添加"主成分×特征值×高斯随机变量(均值0,标准差0.1)";
- 效果:模拟光照/颜色变化,top-1误差率降低超过1%。
4.2 Dropout正则化
- 操作:在第6、7全连接层,每次训练时随机将50%神经元输出置0(不参与前向/反向传播);测试时所有神经元激活,输出乘以0.5(近似几何平均);
- 作用:抑制神经元共适应,迫使学习更鲁棒的特征;
- 代价:训练收敛迭代次数加倍,但有效缓解过拟合。
5. 训练细节
- 优化器: stochastic gradient descent(SGD);
- 关键超参数 :
- 批大小(batch size):128;
- 动量(momentum):0.9;
- 权重衰减(weight decay):0.0005(不仅正则化,还降低训练误差);
- 参数初始化 :
- 权重:零均值高斯分布(标准差0.01);
- 偏置:第2、4、5卷积层及全连接层偏置=1(加速ReLU正向激活),其余层偏置=0;
- 学习率调度:初始0.01,当验证误差停止下降时÷10,共调整3次;
- 硬件与时间 :双NVIDIA GTX 580(3GB内存),训练90轮(遍历120万训练图90次),耗时5-6天。
6. 实验结果(对比当时SOTA)
6.1 ILSVRC-2010测试集结果
| 模型 | top-1误差率 | top-5误差率 |
|---|---|---|
| Sparse coding(2010竞赛最佳) | 47.1% | 28.2% |
| SIFT + FVs(2012前最佳) | 45.7% | 25.7% |
| AlexNet(本文) | 37.5% | 17.0% |
6.2 ILSVRC-2012竞赛结果(测试集标签未公开,用验证集误差近似)
| 模型 | top-1验证误差率 | top-5验证误差率 | top-5测试误差率 |
|---|---|---|---|
| SIFT + FVs(第二名) | - | - | 26.2% |
| 1个AlexNet | 40.7% | 18.2% | - |
| 5个AlexNet平均 | 38.1% | 16.4% | 16.4% |
| 1个预训练AlexNet(ImageNet 2011) | 39.0% | 16.6% | - |
| 7个AlexNet平均(含2个预训练) | 36.7% | 15.4% | 15.3% |
6.3 Fall 2009 ImageNet结果(10184类、890万张图)
| 模型 | top-1误差率 | top-5误差率 |
|---|---|---|
| 此前最佳方法 | 78.1% | 60.9% |
| AlexNet(加第6卷积层) | 67.4% | 40.9% |
7. 讨论与展望
- 深度的重要性 :移除任一卷积层(即使仅占1%参数),top-1性能降低约2%,证明深度对高精度至关重要;
- 未用无监督预训练:作者认为无监督预训练可进一步提升性能(尤其当标签数据有限时);
- 未来方向:随着GPU算力提升和数据集扩大,可构建更大网络;探索视频序列数据(利用时序信息补充静态图像)。
4. 关键问题
问题1:AlexNet在网络架构上的核心创新点有哪些?这些创新分别解决了传统CNN的哪些痛点?
答案:AlexNet的核心架构创新及解决的痛点如下:
- ReLU激活函数:解决传统饱和激活函数(tanh、sigmoid)训练速度慢的问题,使CNN训练效率提升数倍(如CIFAR-10上达25%训练误差的迭代次数仅为tanh网络的1/6);
- 双GPU并行训练:解决单GPU内存有限(如GTX 580仅3GB)无法容纳大型网络的问题,通过拆分kernels并控制跨层通信,平衡计算与通信成本,同时降低误差率(top-1/top-5分别降1.7%/1.2%);
- 局部响应归一化(LRN):解决传统CNN泛化能力不足的问题,模拟神经元侧向抑制,增强特征区分度,使top-1/top-5误差率分别降1.4%/1.2%;
- 重叠池化:解决传统无重叠池化(s=z)丢失细节、易过拟合的问题,采用s=2、z=3的重叠窗口,既保留更多空间信息,又降低0.4%/0.3%的top-1/top-5误差率。
问题2:AlexNet采用了两种核心的数据增强策略,其具体实现方式和效果有何差异?
答案:AlexNet的两种数据增强策略在实现和效果上差异显著,具体如下:
| 策略类型 | 实现方式 | 核心效果 |
|---|---|---|
| 空间变换增强 | 从256×256图像随机裁剪224×224 patch,生成水平翻转版本;测试时取10个patch(5个核心+翻转)平均预测 | 训练集规模扩大2048倍,显著缓解过拟合,提升测试集稳定性 |
| RGB强度增强 | 对ImageNet训练集RGB像素做PCA,向每个图像添加"主成分×特征值×高斯随机变量(均值0,标准差0.1)" | 模拟光照/颜色变化,仅降低top-1误差率超过1%,侧重鲁棒性提升 |
| 两者均无额外计算成本(CPU生成变换图像时GPU同步训练),但空间变换增强侧重扩大数据多样性,RGB强度增强侧重模拟真实场景的光照变异。 |
问题3:在ILSVRC竞赛中,AlexNet相比此前的最佳方法(如Sparse coding、SIFT+FVs),性能提升幅度如何?请结合具体数据说明其突破性。
答案:AlexNet在ILSVRC竞赛中实现了颠覆性性能突破,具体提升幅度如下:
- ILSVRC-2010测试集 :相比2010竞赛最佳的Sparse coding方法,AlexNet的top-1误差率从47.1%降至37.5%(降低9.6个百分点 ),top-5误差率从28.2%降至17.0%(降低11.2个百分点);相比2012前最佳的SIFT+FVs方法,top-1误差率从45.7%降至37.5%(降8.2个百分点),top-5从25.7%降至17.0%(降8.7个百分点);
- ILSVRC-2012竞赛 :相比第二名的SIFT+FVs方法(top-5测试误差26.2%),AlexNet(7个模型平均)的top-5测试误差仅15.3%,降低10.9个百分点 ,成为首个在ImageNet上误差率低于20%的模型;
这种幅度的性能提升远超此前方法的迭代改进(通常每次提升1-2个百分点),标志着深度学习正式开启计算机视觉的新时代。