1 定义
正则表达式(Regular Expression,简称regex或regexp)是一种用于描述、匹配、查找和替换字符串中特定模式的工具。它由普通字符(如a-z)和元字符(如 .、*、+、?、\[\]、()、^、$、等)组成,形成一套紧凑而强大的规则语言。
1.1 应用范围
正则表达式广泛应用于各类编程语言,文本编辑器、命令行工具(如grep、sed)及数据库系统,典型用于包括:
| 场景 | 示例 |
|---|---|
| 数据验证 | 验证邮箱格式、手机号、身份证号等是否符合规范 |
| 文本搜索于提取 | 从日志文件中提取IP、从HTML中抓取<title>\mathrm{<title>}<title>内容 |
| 字符串替换 | 将文档中所有http替换成https |
1.2 使用时注意事项
- 可读性差
复杂正则容易编程"一次性代码" - 性能陷阱
- 回溯爆炸(Catastrophic Backtracking):当使用(a+)+b(a+)+b(a+)+b匹配aaaaaaaaaaacaaaaaaaaaaacaaaaaaaaaaac时可能导致指数级回溯
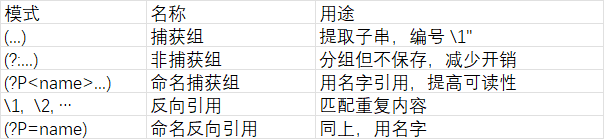
- 避免嵌套量词:优先使用非捕获组 (?:...);必要时改用原子组 (?>...) 或占有量词(如 a++)
- 上下文依赖性强
- 同一正则在不同语言/引擎中行为可能不同
- 过度使用风险
- 尽量不使用正则解析HTML/XML/JSON(使用专用解析器)
- 对结构化数据(如CSV),优先使用 csv 模块而不是正则拆分
- 安全问题
- 用户输入的正则若直接拼接到系统中(如re.compile(user_input)),可能被用于ReDos攻击
2 python中re库示例
2.1 基础元字符与字面量

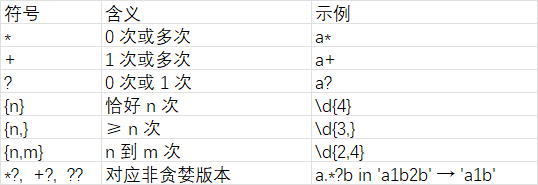
2.2 量词
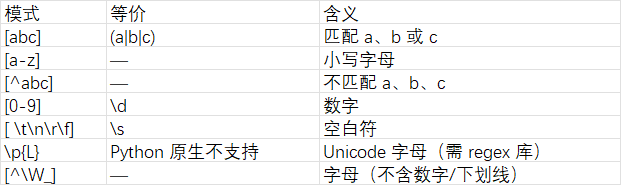
2.3 字符组与预定义类
2.4 分组与捕获
2.5 边界与锚点

2.6 工程场景可能使用
- 提取 ply文件的点数(头部element vertex N)
- 匹配隧道区段编号
- 提取混凝土用量
- 清理日志时间戳前缀
- 文件名标准化