数据库操作
创建库
sql
create database hello; create database db2 charset=utf8;//创建一个使用utf8的数据库
create database db3 charset=utf8 collate utf8_general_ci;//校验规则为utf8_general_ci校验规则
utf8_general_ci 不区分大小写
utf8_bin 区分大小写
查看数据库
sql
show databases; show create database db;//查看创建db数据库的语句修改数据库
修改数据库一般修改数据集和校验规则
sql
alter database db2 charset=gbk;删除数据库
注意:数据库不要随意删除
sql
drop database db4;使用数据库
sql
use hello;创建表
sql
mysql> create table student( -> id int, -> name carchar(32), -> gender -> );插入数据
sql
insert into student(id,name,gender) values (2,'张三','男');查询数据
sql
select * from student;备份
备份数据库
sql
mysqldump -uroot -p -B db2 > /home/lmx/test.sql //把数据库db2内容备份到指定文件中
mysqldump -uroot -p -B db2 db3 > /home/lmx/test3.sql//备份多个数据库备份表
不要加上-B
sql
mysqldump -uroot -p db2 test > ./test2.sql还原
sql
source /home/lmx/test.sql;表操作
创建时可以指定字符集 校验规则 存储引擎
sql
create table test1( name varchar(20), id int ) character set utf8 engine MyISAM;查看表结构
sql
desc test1;修改表
sql
alter table test1 add gender varchar(20) after name;//添加一个字段
alter table test1 modify name varchar(60);//将name字段从varchar(20)修改为varchar(60)
alter table test1 drop id;//删除表中字段
alter table test1 rename class;//修改表名
alter table class change name xingming varchar(20);//修改表中字段删除表
sql
drop table test;数据类型
当数据固定大小时使用定长char,变化时使用变长varchar
定长浪费空间,但是效率高
变长节约空间,但是效率低
日期
sql
create table date( t1 date, t2 datetime, t3 timestamp);
insert into date(t1,t2) values('1997-9-1','1997-9-1 12:1:1');
update date set t1='2003-12-30';//更新时间
alter table date modify t3 timestamp default current_timestamp on update current_timestamp;//timestamp当前时间戳默认是为NULL枚举和集合
enum 单选 | set 多选
sql
create table test( id int, gender enum('男','女'),hobby set('basket','gym')); insert into test values(1,'男','basket,gym');在集合中查找find_in_set(sub,set_list),sub在set_list中返回1,没有返回0
sql
select * from test where find_in_set('gym',hobby);//筛选hobby中有gym得所有人表的增删查改
primary key:主键,唯一
unique: 唯一键,两个都是只能有一个
auto_increment:自增长
sql
mysql> create table students( -> id int primary key auto_increment, -> name varchar(20) not null unique comment '姓名' -> ); insert students(name) values('张三'),('李四');//多行插入替换
sql
replace students(id,name) values(3,'王五');//表中没有唯一键或主键冲突,直接插入 replace students(id,name) values(3,'赵一');//冲突时,替换查询
sql
select name,math from students;//查询name和math两列
select name,math+english from students;//查询name和math+english两列
select name,math+english 总分 from students;//查询name和math+english两列,并将math+english重命名为总分
select distinct math from students;//去重查询,如果加上其他字段就不会去重
select name,math from students where math<60;//查询数学成绩小于60
select name,math from students where math>60 and math<90;//查询成绩在60到90之间
select name,math from students where math between 60 and 90;//与上面相同
select name,math from students where math=50 or math=80;//查询成绩为50或者80的同学
select name,math from students where math in (50,80);//与上面相同
select name from students where name like '张%';//查询姓张的同学
select name from students where name like '张_';//严格匹配,后面只有一个字的
select name from students where name not like '张%';//查询不姓张的同学
select * from students where name is NULL;//查询名字为空的
select * from students where name <=> NULL;//与上面相同的
=和<=>区别是什么?
通过如下对比NULL,就可以知道<=>是用来进行判定NULL
select NULL <=> NULL;//结果为1
select NULL = NULL;//为NULL结果排序
asc:升序(默认)
desc:降序
没有使用order by的顺序是不确定的
sql
select name,math from students order by math; select name,math,english from students order by math desc,english;//多字段排序,数学成绩降序排,如果数学成绩相同,再按英语成绩降序排
select name,math+english 总分 from students order by 总分 desc;//按总分排序
select name,math from students where name like '张%' or name like '李%' order by math desc;//把姓张和李的同学按照数学成绩降序的方式进行排序筛选分页结果
当数据太大了,查询全表容易导致数据库卡死,使用limit
sql
select * from students limit 3;//查询前三行
select * from students limit 3 offset 5;//查询从第5行开始的三行数据更新数据
没有*=和+=,修改时使用math=math+10
sql
update students set math=88 where name='jack';//把jack数学成绩改为88
update students set math=math+10 order by math desc limit 3;//前三名数学成绩加3删除数据
数据库删除操作要慎用
如果表中有自增长字段auto_increment,删除表中数据之后这个值还是会是原来的,原来4行数据删除之后下次插入自增长为5
sql
delete from students where name='张三'; delete from class;//删除整张表的数据截断表
truncate不会对数据进行操作,而是直接把数据文件删除,然后重新建一张新表,所以没有形成事务,没有办法进行回滚
插入查询结果
sql
create table duplicate_table( id int, name varchar(20));
insert duplicate_table values('11','aa'),('11','aa'),('22','bb'),('22','bb');//插入元素 create table no_duplicate_table( id int, name varchar(20));//创建一张相同的表
insert no_duplicate_table select distinct * from duplicate_table;//将去重之后的表数据插入聚合函数
count、sum、avg、max、min
select count(distinct math) from students;//去重之后的数学成绩个数
内置函数
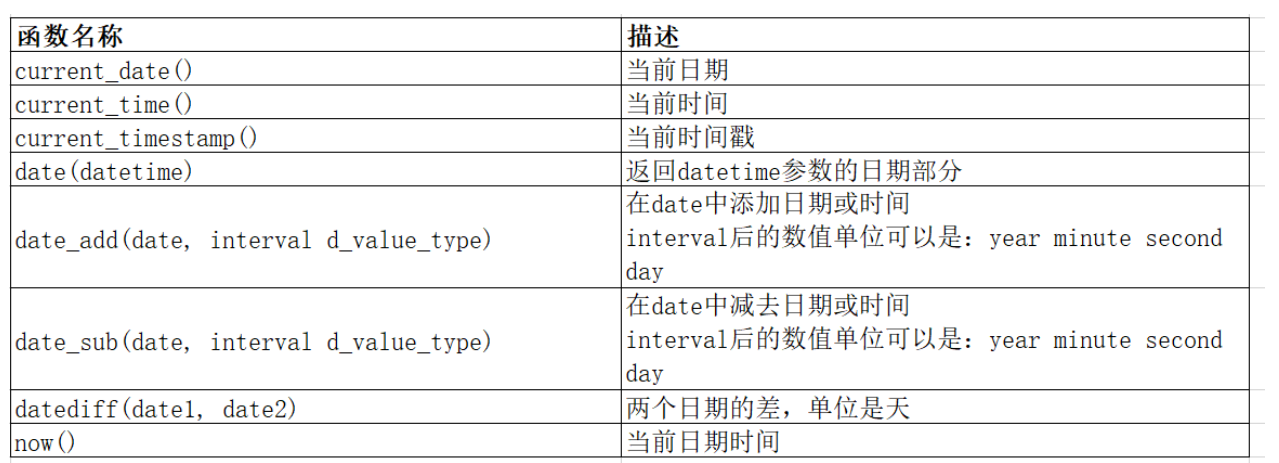
日期
字符串函数
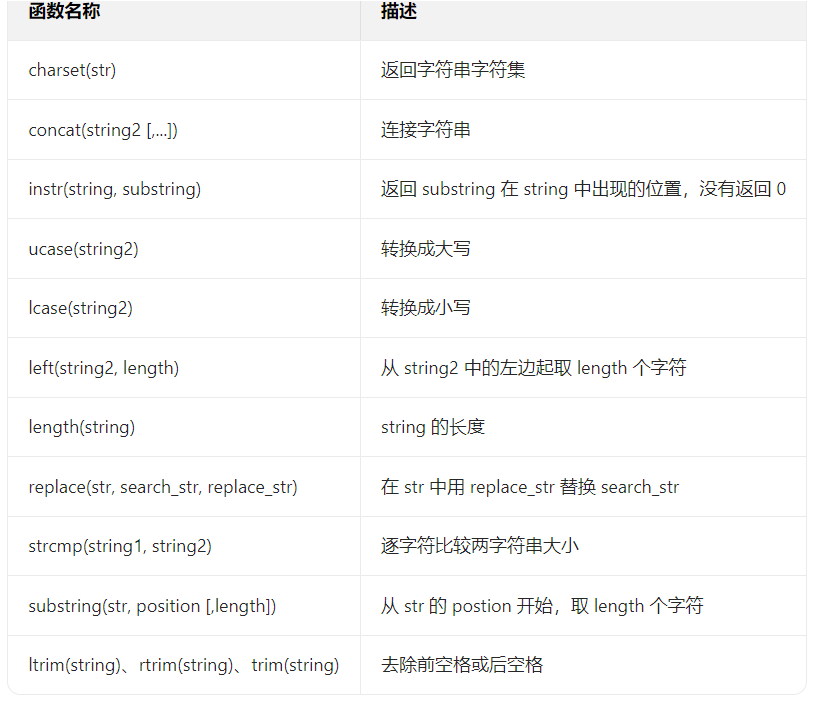
select concat(name,'语文成绩',chinese,' 数学成绩:',math) as '分数' from student;//返回字符串 select length(name),name from student;//查看name占用字节数 select replace(ename,'S','是的') ename from emp;//把ename中的S替换为是的 select substring(ename,2,2) ename from emp;//截取表中ename第二个字符开始后面两个字符 select concat(lcase(substring(ename,1,1)),substring(ename,2)) from emp;//名字首字母小写的方式进行查询
数学函数
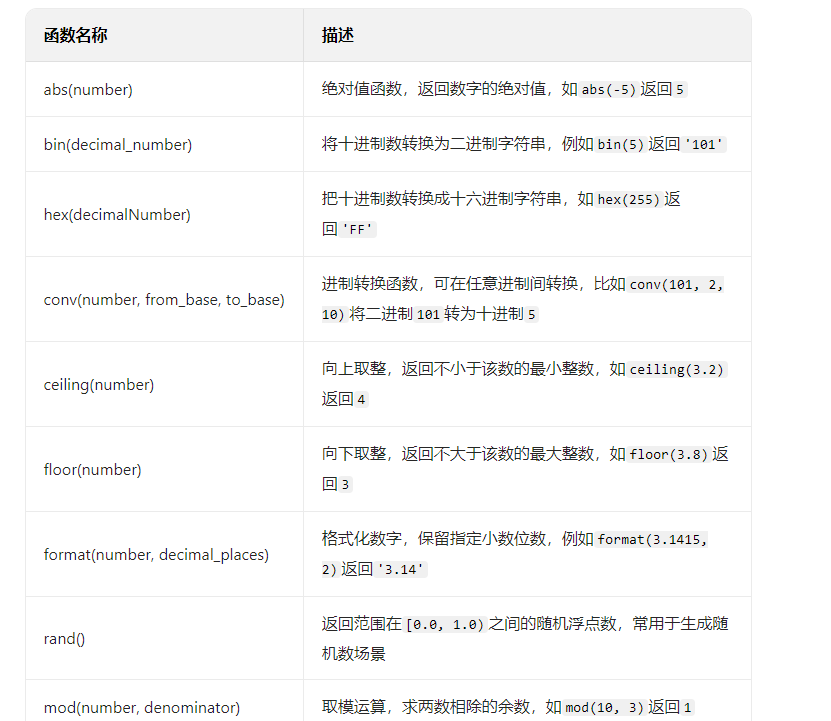
其他函数
select user();//查看当前用户 select md5('hello');//哈希散列 select database();//查询当前数据库
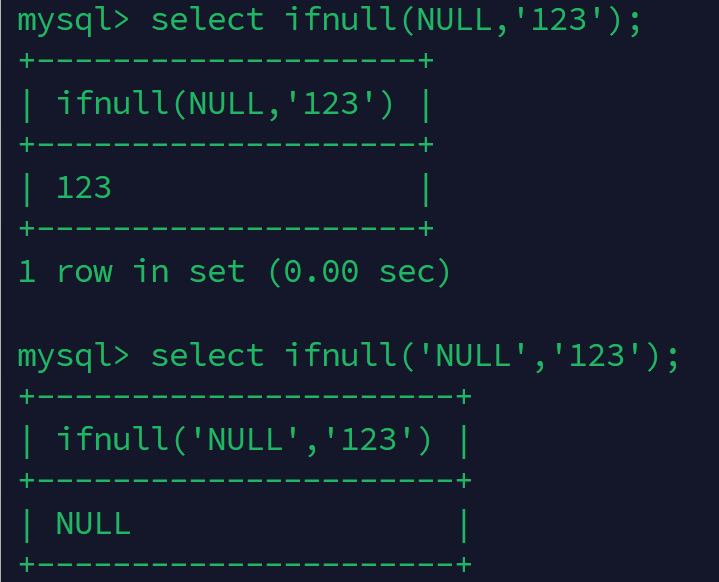
'NULL'不表示空,表示字符串
ifnull第一个参数为空,返回第二个参数
复合查询
自连接:在同一张表连接查询
显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号--empno) //子查询 select empno,ename from emp where emp.empno=(select mgr from emp where ename='ford'); //与上面相同,多表查询,自查询 select leader.empno,leader.ename from emp leader,emp worker where worker.mgr=leader.empno and worker.ename='ford';
子查询指的是sql中嵌入其他sql语句,也叫嵌套查询
多行子查询
sql
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
select ename,job,sal,deptno from emp where job in (select distinct job from emp where deptno=10) and deptno<>10;
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
select ename,sal,deptno from emp where sal > all(select sal from emp where deptno=30); select ename,sal,deptno from emp where sal > all(select sal from emp where deptno=30);
显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
select ename,sal,deptno from emp where sal > any(select sal from emp where deptno=30);多列子查询
sql
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
select ename from emp where (deptno,job)=(select deptno,job from emp where ename='smith') and ename<>'smith';在from中使用子查询
把子查询当作一个临时表来使用
sql
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
select ename,deptno,sal,mysal from emp,(select avg(sal) mysal,deptno dt from emp group by deptno) tmp where emp.sal > tmp.mysal and emp.deptno=tmp.dt;
查找每个部门工资最高的人的姓名、工资、部门、最高工资
select ename,deptno,sal,mysal from emp,(select max(sal) mysal,deptno dt from emp group by deptno) tmp where emp.deptno=tmp.dt and emp.sal=tmp.mysal;
显示每个部门的信息(部门名,编号,地址)和人员数量 多表查询
select dept.dname,dept.loc,dept.deptno,count(*) '人数' from emp,dept where dept.deptno=emp.deptno group by dept.deptno,dept.dname,dept.loc;
子查询
select dept.dname,dept.loc,dept.deptno,cnt from (select count(*) cnt,deptno from emp group by deptno) tmp,dept where dept.deptno=tmp.deptno;合并查询
合并多个select查询的结果
sql
将工资大于2500或职位是MANAGER的人找出来 //union取并集,结果去重
select ename,sal from emp where sal>2500 union select ename,sal from emp where job='manager'; //union all结果不去重
select ename,sal from emp where sal>2500 union all select ename,sal from emp where job='manager';表的内连和外连
内连接
sql
显示SMITH的名字和部门名称
select dname,ename from emp,dept where emp.deptno=dept.deptno and emp.ename='smith';
//标准内连写法,与上面相同
select dname,ename from emp inner join dept on emp.deptno=dept.deptno and emp.ename='smith';外连接
分为左外连接和右外连接
left join把左边表所有都要显示
right join把右边表所有都要显示
sql
查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来
//左外连接,当右边表没有数据时也要把左边表数据显示出来
select * from stu left join exam on stu.id=exam.id;
对stu表和exam表联合查询,把所有的成绩都显示出来,即使这个成绩没有学生与它对应,也要显示出来
//右外连接,左边表没有数据,也要把右边的数据显示出来
select * from stu right join exam on stu.id=exam.id;索引
当海量数据下就需要索引来提高查询效率,但是增删改的效率降低,这些写操作增加了大量io
MySQL通过page来和磁盘进行交互,每个page的大小为16k。
为什么不用多少加载多少呢?
因为如果用的时候进行加载,5次操作进行5次io操作就会导致效率低下,导致io低的原因不是因为io的数据多,而是频繁的和底层进行io操作
MySQL底层使用B+树的数据结构
根节点是目录页,中间节点也是目录页,叶子节点是数据页,页里面的数据也是通过链表连接的
为什么不适用B树而使用B+树呢?
首先目录页不需要存放数据,B+树的中间节点只需要存放对应的键值和page指针来指向数据页就行了。B树叶节点没有相连,而B+树的叶子节点是通过双向链表连接的
非聚簇索引和聚簇索引
存储引擎innoDB把数据和索引存放在一起叫做聚簇索引
存储引擎MyISAM把数据和索引分开存储叫做非聚簇索引
非聚簇索引叶节点存放数据指针,进行回表查询
除了默认建立的主键索引外,还可以建立按照其他列信息建立的索引,这种叫做辅助(普通索引)。
普通索引和主键索引除了可以重复外,没有不同
聚簇索引在一张表中只能有一个,通常是默认的主键索引
索引操作
主键索引
1、主键索引不能为空,且不能重复
2、效率高(不重复)
3、主键索引通常是int
4、一个表中只能有一个主键索引
sql
//创建主键索引的三种方式
create table user(id int primary key,name varchar(20));
create table user2(id int,name varchar(20),primary key(id));
//创建表之后指定
create table user3(id int,name varchar(20));
alter table user3 add primary key(id);唯一键索引
1、一个表中可以有多个唯一键索引
2、唯一键不能重复
3、查询效率高
4、如果唯一键上指定not null,等价于主键索引
sql
//创建唯一键索引的三种方式,和主键索引相同
create table user(id int unique,name varchar(20));
create table user2(id int,name varchar(20),unique(id));
//创建表之后指定
create table user3(id int,name varchar(20));
alter table user3 add unique(id);普通索引
1、一个表中可以有多个普通索引
2、当列中有重复数据时,使用普通索引
sql
//创建普通索引的三种方式
create table user4(id int,name varchar(20),index(name));
create table user5(id int,name varchar(20));
alter table user5 add index(id);
create table user6(id int,name varchar(20));
create index index_name on user6(name);全文索引
需要使用大量文字进行索引时,就需要使用全文索引。
要求引擎必须是MyISAM,全文索引默认使用的是英文
FULLTEXT
sql
SELECT * FROM articles WHERE MATCH (title,body) AGAINST('database')查询索引
sql
//三种方式
show keys from user6;
show index from user6;
desc user6;删除索引
sql
alter table 表名 drop primary key;
//删除其他索引,索引名就是show keys from的key_name
alter table 表名 drop index 索引名
drop index 索引名 on 表名 事务
事务就是一组DML( Data Manipulation Language)语句,这些语句存在逻辑相关性,这一组语句要么成功要么失败
事务不仅仅是SQL集合,还需要满足四个属性
原子性、一致性、隔离性、持久性
引擎支持
InnoDB支持事务,MyISAM不支持
事务提交方式
手动提交和自动提交
sql
show variable like 'autocommit';
set autocommit=1;//来进行开启事务操作
sql
begin;//开启事务也可以使用start transaction
savepoint save;//记录回滚点
insert account ('1','张三',100);
savepoint save2;
insert account values('2','李四',1000);
select * from account;//当前表中有两行数据
rollback to save2;//回滚
select * from account;//只有一行数据了
rollback;//回到最开始注意:
1、只有commit之后才会持久化,跟是否设置了autocommit没有关系
2、事务可以手动回滚,当操作异常会自动回滚
3、InnoDB每条SQL语句都被封装成了事务,自动提交
4、提交了之后就不支持回滚操作
5、没有记录回滚点,就只能回到事务最开始
事务的隔离性
- 脏读:一个事务读取了另一个事务未提交的修改数据,之后那个事务回滚,导致读取的数据是无效的 "脏数据"。
- 不可重复读:一个事务内多次读取同一数据,在读取过程中,其他事务修改并提交了该数据,导致前后读取结果不一致。
- 幻读:一个事务内多次执行同一查询(通常是范围查询),在查询过程中,其他事务插入了符合查询条件的新数据,导致前后查询结果的记录数不一致。
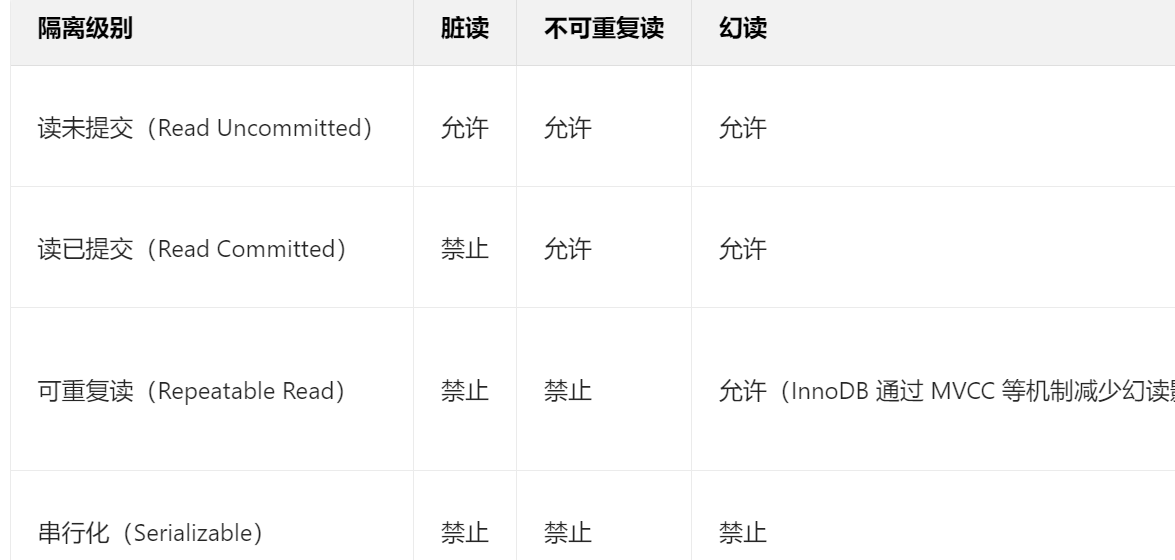
一致性
事务执行之前是合法的,执行之后也是合法的
这里合法指的是数据完整性和业务逻辑的合理性
一致性有原子性、持久性、隔离性共同保障