1、源码编译
1.1、下载源码包
shell
#git clone源码,并切换到指定的版本分支或者tag
git clone https://github.com/redis/redis.git
#或者直接下载指定的tag
wget -O redis-<version>.tar.gz https://github.com/redis/redis/archive/refs/tags/<version>.tar.gz本文演示采用的是
8.2.3版本,用8.2.3替换脚本中的尖括号和version,后续脚本直接用具体版本,注意区分
1.2、编译
shell
#解压
tar -zxf redis-8.2.3.tar.gz
cd redis-8.2.3
#安装编译所需要的依赖
sudo apt-get install build-essential
# 编译
make执行成功之后,就可以运行了
1.3、运行
通过上面的编译,没有明确的报错就能够正常运行了
shell
./src/redis-server redis.conf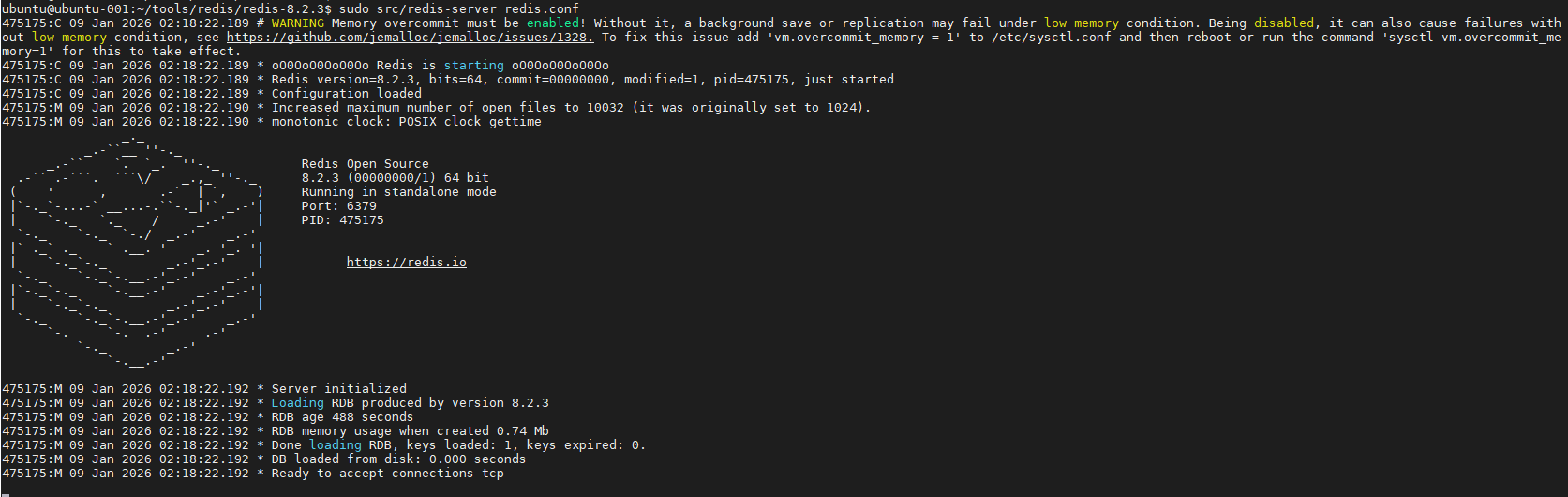
用redis客户端工具或者直接用客户端去连接,就能正常操作了
shell
ubuntu@ubuntu-001:~/tools/redis/redis-8.2.3$ ./src/redis-cli
127.0.0.1:6379> set name Navy
OK
127.0.0.1:6379> get name
"Navy"
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379>2、docker方式运行
2.1、首先需要安装docker环境
安装docker环境这里不讲述,没有基础的可以直接百度
2.2、编写docker-compose.yaml文件
yaml
version: '3'
services:
shao_redis:
container_name: redis
restart: always
image: redis:latest
ports:
- "6379:6379"
command:
- redis-server
- --appendonly yes
- --requirepass 密码 # 设置你的密码
volumes:
- ./data:/data # 挂载数据目录,以便密码设置可以持久化
- ./logs:/logs # 挂载日志目录
deploy:
resources:
limits:
memory: 512M
cpus: '0.5'
reservations:
memory: 128M这里使用的镜像是redis:latest,可以换成具体的版本,比如我自己保存的8.2.3版本的镜像registry.cn-hangzhou.aliyuncs.com/xhsx/redis:8.2.3
ports指定了端口映射,将容器的6379端口映射到主机的6379上,这样通过主机的6379端口就可以访问到redis
command命令中--requirepass参数指定了redis的密码,防止redis裸奔提高安全性
volumes挂载了两个目录,一个data是数据目录,另外一个是日志目录,待容器启动成功之后会自动创建这两个目录
resources配置了最小内存、最大内存和最大cpu资源
2.3、运行docker-compose
shell
sudo docker-compose up -d
sudo docker ps | grep redis待容器启动完成后同样可以用客户端工具或者客户端直接连接并操作
3、k8s集群部署【集群模式为例】
前面通过源码方式可docker方式运行了单机版的,接下来体验一下用k8s部署一个redis集群版。当然首先你得有一个k8s集群,这里不讲述k8s集群的搭建
3.1、准备配置文件
3.1.1、configMap.yaml
yaml
apiVersion: v1
data:
redis.conf: |
bind 0.0.0.0
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize no
supervised no
pidfile /data/redis.pid
loglevel notice
logfile /data/redis_log
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /data
masterauth 密码
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100
requirepass 密码
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 15000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
kind: ConfigMap
metadata:
name: redis-conf
namespace: middleware注意两处配置密码的地方:
- requirepass
- masterauth
3.1.2、命名空间
这里可以看到配置文件的最后面指定了命名空间为middleware,所以要么把所有的命名空间去掉,要么改成自己的命名空间。再要么就自己建一个
shell
kubectl create ns middleware3.2、创建statefulSet文件
redis-cluster-sts.yaml
yaml
apiVersion: apps/v1
kind: StatefulSet #创建StatefulSet资源
metadata:
labels: #StatefulSet本身的标签
app: redis-sts
name: redis-sts #资源名称
namespace: middleware #资源所属命名空间
spec:
selector: #标签选择器,要与下面pod模板定义的pod标签保持一致
matchLabels:
app: redis-sts
replicas: 6 #副本数为6个,redis集群模式最少要为6个节点,构成3主3从
serviceName: redis-svc #指定使用service为上面我们创建的无头service的名称
template:
metadata:
labels: #pod的标签,上面的无头service的标签选择器和sts标签选择器都要与这个相同
app: redis-sts
spec:
# affinity:
# podAntiAffinity: #定义pod反亲和性,目的让6个pod不在同一个主机上,实现均衡分布,这里我的node节点不够,所以不定义反亲和性
# preferredDuringSchedulingIgnoredDuringExecution:
# - weight: 100
# podAffinityTerm:
# labelSelector:
# matchExpressions:
# - key: app
# operator: In
# values:
# - redis-sts
# topologyKey: kubernetes.io/hostname
containers:
- name: redis #容器名称
# image: redis:latest #redis镜像
image: registry.cn-hangzhou.aliyuncs.com/xhsx/redis:latest
imagePullPolicy: IfNotPresent #镜像拉取策略
command: #定义容器的启动命令和参数
- "redis-server"
args:
- "/etc/redis/redis.conf"
- "--cluster-announce-ip" #这个参数和下面的这个参数
- "$(POD_IP)" #这个参数是为了解决pod重启ip变了之后,redis集群状态无法自动同步问题
env:
- name: POD_IP #POD_IP值引用自status.podIP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports: #定义容器端口
- name: redis-6379 #为端口取个名称为http
containerPort: 6379 #容器端口
volumeMounts: #挂载点
- name: "redis-conf" #引用下面定义的redis-conf卷
mountPath: "/etc/redis" #redis配置文件的挂载点
- name: "redis-data" #指定使用的卷名称,这里使用的是下面定义的pvc模板的名称
mountPath: "/data" #redis数据的挂载点
- name: localtime #挂载本地时间
mountPath: /etc/localtime
readOnly: true
restartPolicy: Always
volumes:
- name: "redis-conf" #挂载一个名为redis-conf的configMap卷,这个cm卷已经定义好了
configMap:
name: "redis-conf"
items:
- key: "redis.conf"
path: "redis.conf"
- name: localtime #挂载本地时间
hostPath:
path: /etc/localtime
# type: File
volumeClaimTemplates: #定义创建pvc的模板
- metadata:
name: "redis-data" #模板名称
spec:
resources: #资源请求
requests:
storage: 500M #需要100M的存储空间
accessModes:
- ReadWriteOnce #访问模式为RWO
storageClassName: "sx-managed-nfs-storage" #指定使用的存储类,实现动态分配pv需要注意的是这里采用NFS数据卷挂载的方式进行数据持久化,NFS服务器搭建这里不讲述。
3.3、storage-class.yaml
上面sts定义文件这里指定了动态数据存储的storageClassName,会通过它动态分配磁盘,这个sx-managed-nfs-storage的定义如下:
yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
namespace: middleware
name: sx-managed-nfs-storage
provisioner: sx-nfs-client-provisioner # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false"
---
kind: Deployment
apiVersion: apps/v1
metadata:
namespace: middleware
name: sx-nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
namespace: middleware
labels:
app: nfs-client-provisioner
spec:
serviceAccount: nfs-client-provisioner
containers:
- name: sx-nfs-client-provisioner
imagePullPolicy: IfNotPresent
#image: registry.cn-hangzhou.aliyuncs.com/xhsx/nfs-client-provisioner:latest
image: registry.cn-hangzhou.aliyuncs.com/xhsx/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: sx-nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: sx-nfs-client-provisioner
- name: NFS_SERVER
value: 192.168.0.1
- name: NFS_PATH
value: /nfs_win/k8s
volumes:
- name: sx-nfs-client-root
nfs:
server: 192.168.0.1
path: /nfs_win/k8s这里指定的是在192.168.0.1这台机器上安装的nfs-server,并指定对应的export路径为/nfs_win/k8s
3.4、service-account.yaml
上面sc的定义文件这里指定的serviceAccount的定义如下:
yaml
---
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: middleware
name: nfs-client-provisioner3.5、rbac
不仅如此,还要给这个serviceAccount进行授权,也就是rbac的权限绑定
rbac.yaml
yaml
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: middleware
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: middleware
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: middleware
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: middleware
name: leader-locking-nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: middleware
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: middleware
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io3.6、redis服务
svc.yaml
yaml
apiVersion: v1
kind: Service #先创建一个无头service
metadata:
labels: #service本身的标签
app: redis-svc
name: redis-svc #service的名称,下面创建的StatefulSet就要引用这个service名称
namespace: middleware
spec:
ports:
- port: 6379 #service本身的端口
protocol: TCP
targetPort: 6379 #目标端口6360,redis默认端口是6379,这里为了安全改成了6360
selector:
app: redis-sts #标签选择器要与下面创建的pod的标签一样
type: ClusterIP
clusterIP: None至此,运行上面的所有yaml就可以得到6个redis的pod
shell
sudo kubectl apply -f rbac.yaml
sudo kubectl apply -f service-account.yaml
sudo kubectl apply -f storage-class.yaml
sudo kubectl apply -f configMap.yaml
sudo kubectl apply -f svc.yaml
sudo kubectl apply -f redis-cluster-sts.yaml
#查看启动情况
sudo kubectl -n middleware get po | grep redis
redis-sts-0 1/1 Running 0 28s
redis-sts-1 1/1 Running 0 25s
redis-sts-2 1/1 Running 0 22s
redis-sts-3 1/1 Running 0 19s
redis-sts-4 1/1 Running 0 16s
redis-sts-5 1/1 Running 0 13s3.7、创建集群
但是,创建集群还需要最终执行一个创建集群的命令,将这6个pod组成一个真正的redis集群
shell
# 先进入某个pod
sudo kubectl -n middleware exec -it redis-sts-0 bash
# 执行创建集群命令
redis-cli -a 密码 --cluster create --cluster-replicas 1 \
redis-sts-0.redis-svc.middleware.svc.cluster.local:6379 \
redis-sts-1.redis-svc.middleware.svc.cluster.local:6379 \
redis-sts-2.redis-svc.middleware.svc.cluster.local:6379 \
redis-sts-3.redis-svc.middleware.svc.cluster.local:6379 \
redis-sts-4.redis-svc.middleware.svc.cluster.local:6379 \
redis-sts-5.redis-svc.middleware.svc.cluster.local:6379注意这里
-a参数是前面configMap里边指定的密码,
middleware为前面的命名空间,
redis-sts-x是前面sts定义的时候name的前缀
redis-svc是redis服务的名称
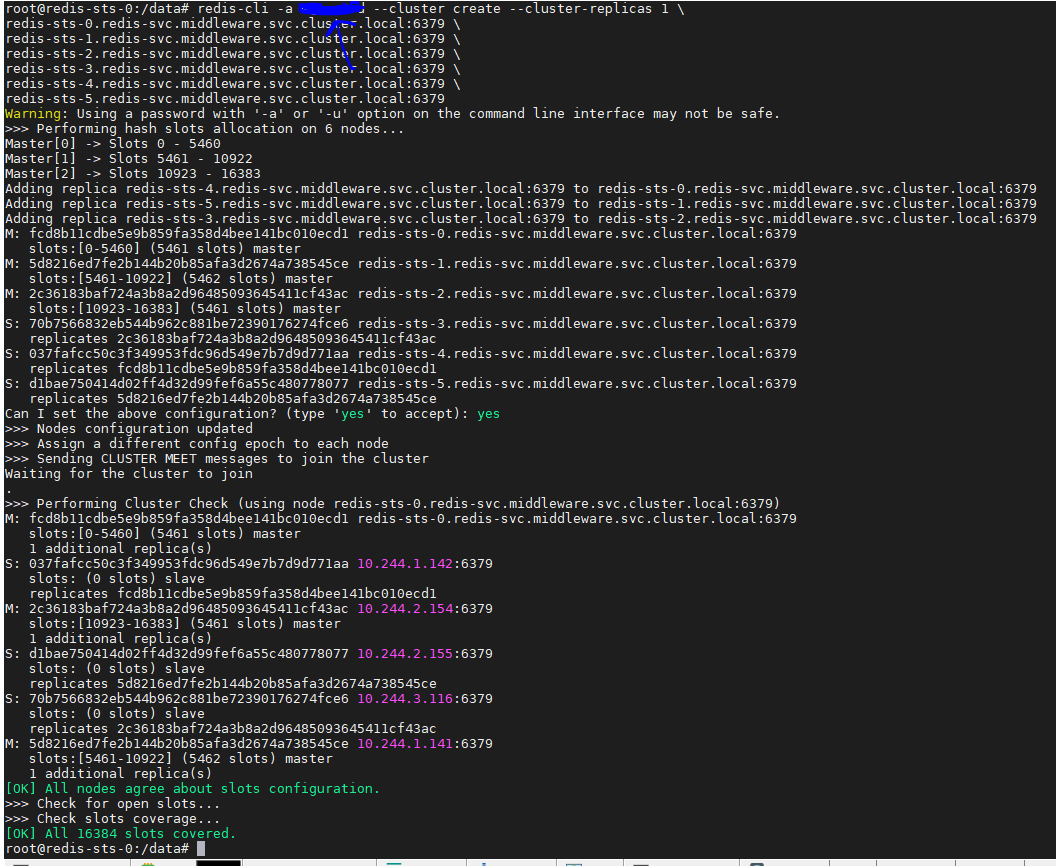
看到这个结果就说明集群创建成功了,接下来看一下集群的信息
shell
#连接到集群
root@redis-sts-0:/data# redis-cli -a 密码 -c
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379>
127.0.0.1:6379>
# 查看集群信息
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:114
cluster_stats_messages_pong_sent:125
cluster_stats_messages_sent:239
cluster_stats_messages_ping_received:120
cluster_stats_messages_pong_received:114
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:239
total_cluster_links_buffer_limit_exceeded:0
127.0.0.1:6379>
127.0.0.1:6379>
# 查看集群节点信息
127.0.0.1:6379> cluster nodes
037fafcc50c3f349953fdc96d549e7b7d9d771aa 10.244.1.142:6379@16379 slave fcd8b11cdbe5e9b859fa358d4bee141bc010ecd1 0 1767927960059 1 connected
2c36183baf724a3b8a2d96485093645411cf43ac 10.244.2.154:6379@16379 master - 0 1767927961066 3 connected 10923-16383
d1bae750414d02ff4d32d99fef6a55c480778077 10.244.2.155:6379@16379 slave 5d8216ed7fe2b144b20b85afa3d2674a738545ce 0 1767927958047 2 connected
70b7566832eb544b962c881be72390176274fce6 10.244.3.116:6379@16379 slave 2c36183baf724a3b8a2d96485093645411cf43ac 0 1767927958000 3 connected
fcd8b11cdbe5e9b859fa358d4bee141bc010ecd1 10.244.3.115:6379@16379 myself,master - 0 0 1 connected 0-5460
5d8216ed7fe2b144b20b85afa3d2674a738545ce 10.244.1.141:6379@16379 master - 0 1767927959000 2 connected 5461-10922
127.0.0.1:6379>
127.0.0.1:6379>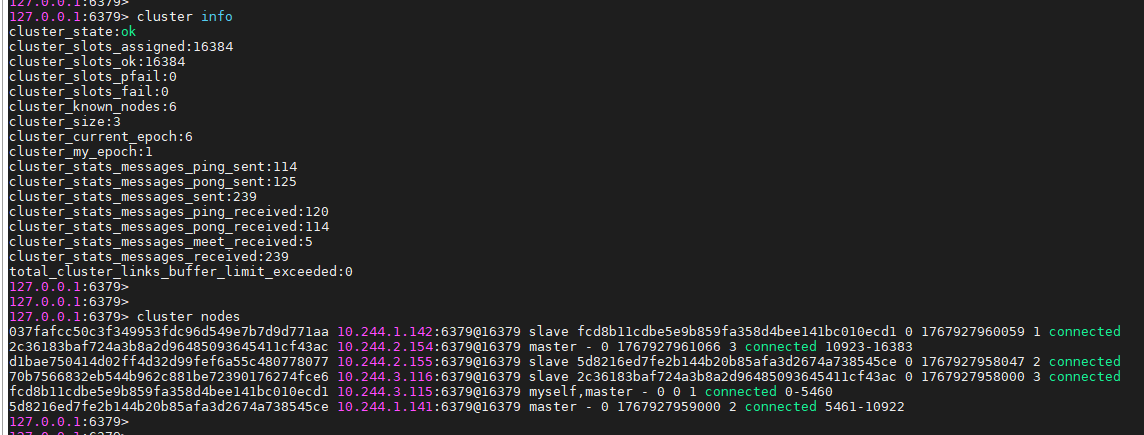
4、redis的几种使用方式
4.1、单机模式
维护简单,成本低,一般简单的项目基本上够用
4.2、主从模式
在主从模式下,主节点负责处理所有的写操作,并将写操作记录在内存中的缓冲区。从节点从主节点获取这些写操作记录,并在自己的数据库上执行这些操作,从而保持与主节点的数据一致。此外,读请求可以在主节点和从节点上进行,从而实现读写分离,提高系统的读取性能。主从同步的流程大致如下图所示:
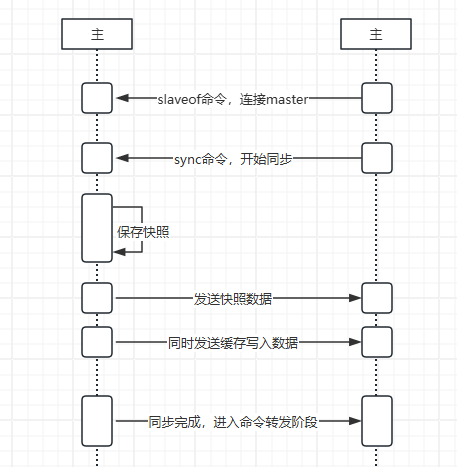
步骤:
- 1、slave发送SLAVEOF命令,连接到master
- 2、slave向master发送一条SYNC命令,触发master开始复制
- 3、收到SYNC命令后,主服务器会开始在后台保存其数据快照。同时,主服务器还会记录从接收到SYNC命令开始执行的所有写命令,这些命令将在数据快照完成后发送给从服务器
- 4、数据快照完成后,主服务器会将其发送给从服务器。从服务器在接收到数据快照后,会删除所有旧数据,然后使用接收到的数据快照来加载新数据。
- 5、数据快照发送完成后,主服务器会将在数据快照过程中记录的所有写命令发送给从服务器。从服务器在接收到这些命令后,会按照接收的顺序执行这些命令,以确保其数据与主服务器的数据保持一致。
- 6、完成上述步骤后,主从服务器的数据就同步了。之后,主服务器每执行一次写命令,就会将这个命令发送给所有的从服务器。从服务器在接收到写命令后,会执行这个命令,以确保其数据始终与主服务器的数据保持一致。
优点:
1、可以实现数据的备份,提高数据的安全性;
2、读写分离,提高系统的读取性能
局限性:
1、不能自动切换,如果主节点发生故障,从节点不能自动切换为主节点,需要人工干预;
2、所有的写操作都在主节点上进行,如果写请求量大,主节点可能会成为性能瓶颈。
4.3、哨兵模式
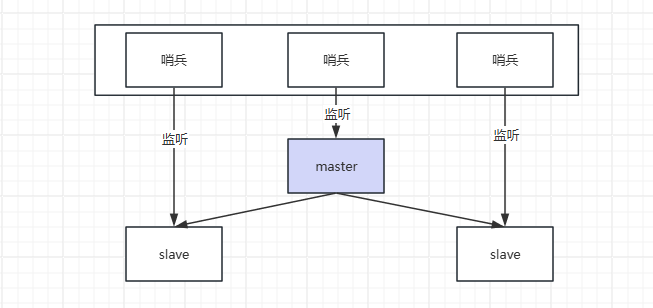
上面说到主从模式无法完成故障时候的主从切换,如何解决这个问题呢?在redis中可以设置哨兵节点,通过哨兵来监听各个节点的状态,一旦发现master不可用了,自动从slave中选择一个成为master。如正常情况下的结构如下图所示:
一旦master挂了失联了,可以选择一个slave顶上去
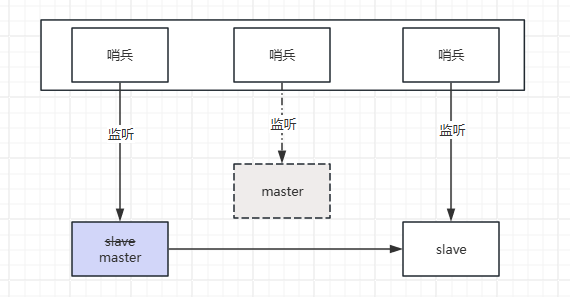
1、哨兵Sentinel主要负责三个方面的任务:
- 监听:通过发送命令,不间断的监控Redis服务器运行状态,包括主服务器和从服务器。
- 提醒:当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(核心任务) :当哨兵监测到主服务器宕机,会自动在已下线主服务器属下的所有从服务器里面,挑选出一个从服务器将其转换为主服务器(自动切换)。然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
2、哨兵模式的配置和使用
配置哨兵模式需要在哨兵节点的配置文件中设置主节点的信息和故障转移的策略,然后启动哨兵节点即可。
在使用上,用户可以直接向主节点发送写请求,而读请求可以发送到主节点或从节点。
如果主节点发生故障,用户可以从哨兵节点获取新的主节点信息,然后向新的主节点发送请求。
3、哨兵模式的优点和局限性
- 优点:
- 哨兵模式可以实现故障转移,提高系统的可用性
- 哨兵模式可以实现客户端的透明切换,提高系统的可维护性。
- 局限性:
- 哨兵节点需要额外的资源和维护,增加了系统的复杂性;
- 主节点发生故障后,新的主节点可能会有一段时间的数据不一致,影响数据的准确性。
4.4、集群模式(使用较多)
redis的集群模式是一种分布式的解决方案,它允许多个Redis节点(服务器)协同工作,提供更高的性能和可用性。在这种模式下,数据被分片存储在多个节点上,每个节点负责一部分数据的读写。
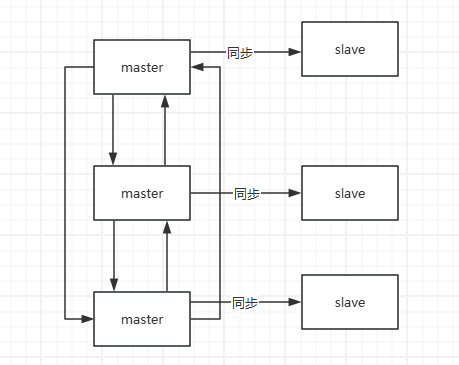
集群模式主要解决水平拓展问题和整体的高可用(局部节点故障不影响其他节点的数据,因为数据是散列在一个hash环上的,每个节点负责一个hash区间,即使节点不可用影响的也只是hash到这个区间的数据)。如果要保证所有数据的高可用还需要配合主从模式
在Redis集群模式下,任意一个Master节点都可以接受客户端的请求。当客户端向某个Master节点发送请求时,如果这个请求的键所对应的哈希槽不在这个Master节点负责的范围内,那么这个Master节点会返回一个重定向信息,告诉客户端应该向哪个节点发送请求。这个过程对客户端来说是透明的,客户端只需要按照重定向信息重新发送请求即可。这种方式确保了Redis集群可以有效地处理并分发客户端的请求,提高了系统的性能和可用性。
- 优点
- 集群模式可以实现数据的水平扩展,提高了系统的性能和存储容量;
- 集群模式实现高可用性,即使某个节点发生故障,系统仍然可以继续提供服务。
- 局限性:
- 配置和维护相对复杂,需要管理多个节点;
- 某些操作,如多键操作和事务,可能会受到限制。
4.5、主从、哨兵、集群模式如何选择
如果你的应用场景主要是读取数据,数据量不大,对数据的一致性要求不高,那么主从模式可能是一个不错的选择。
如果你的应用场景需要高可用性,即使在主节点发生故障的情况下也需要保证服务的正常运行,那么哨兵模式可能更适合你。
如果你的应用场景数据量大,需要高性能和高可用性,那么集群模式可能是最好的选择。集群模式可以提供更高的性能,更大的存储容量,以及更好的故障容忍能力。