LLM救场Serverless开发!SlsReuse框架让函数复用率飙升至91%,还快了44%
一、论文信息
| 类别 | 详情 |
|---|---|
| 论文原标题 | SlsReuse: LLM-Powered Serverless Function Reuse |
| 主要作者及机构 | JINFENG WEN(北京邮电大学)、YUEHAN SUN(北京邮电大学) |
| arXiv信息 | arXiv:2511.17262v1 cs.SE 21 Nov 2025 |
| 引文格式 | Jinfeng Wen and Yuehan Sun. 2025. SlsReuse: LLM-Powered Serverless Function Reuse. 1, 1 (November 2025), 21 pages. https://doi.org/XXXXXXX.XXXXXXX |
| 核心领域 | 无服务器计算(Serverless Computing)、函数复用(Function Reuse)、大语言模型(LLM)应用 |
二、一段话总结
本文提出SlsReuse ------首个基于大语言模型(LLM) 的无服务器函数复用框架,旨在解决无服务器计算中函数复用的核心挑战:缺乏专用复用仓库、函数实现异质性、任务描述与函数的语义鸿沟。SlsReuse通过三步核心流程实现高效复用:首先构建高质量可复用函数仓库(筛选500个跨领域函数);其次借助少样本提示工程 提取函数的统一语义增强表示(包含意图摘要、平台、云服务、编程语言四元组);最后通过意图感知发现 (含多级剪枝与相似度匹配)推荐函数。实验表明,基于ChatGPT-4o 的SlsReuse在110个任务查询上实现Recall@10达91.20% ,超现有最优基线24.53个百分点,且在Llama 3.1(405B)、Gemini 2.0 Flash、DeepSeek V3等LLM上表现出良好泛化性,同时通过多级剪枝将推荐延迟降至47.47ms,较LLM变体降低44.36%。
三、思维导图(MindMap)
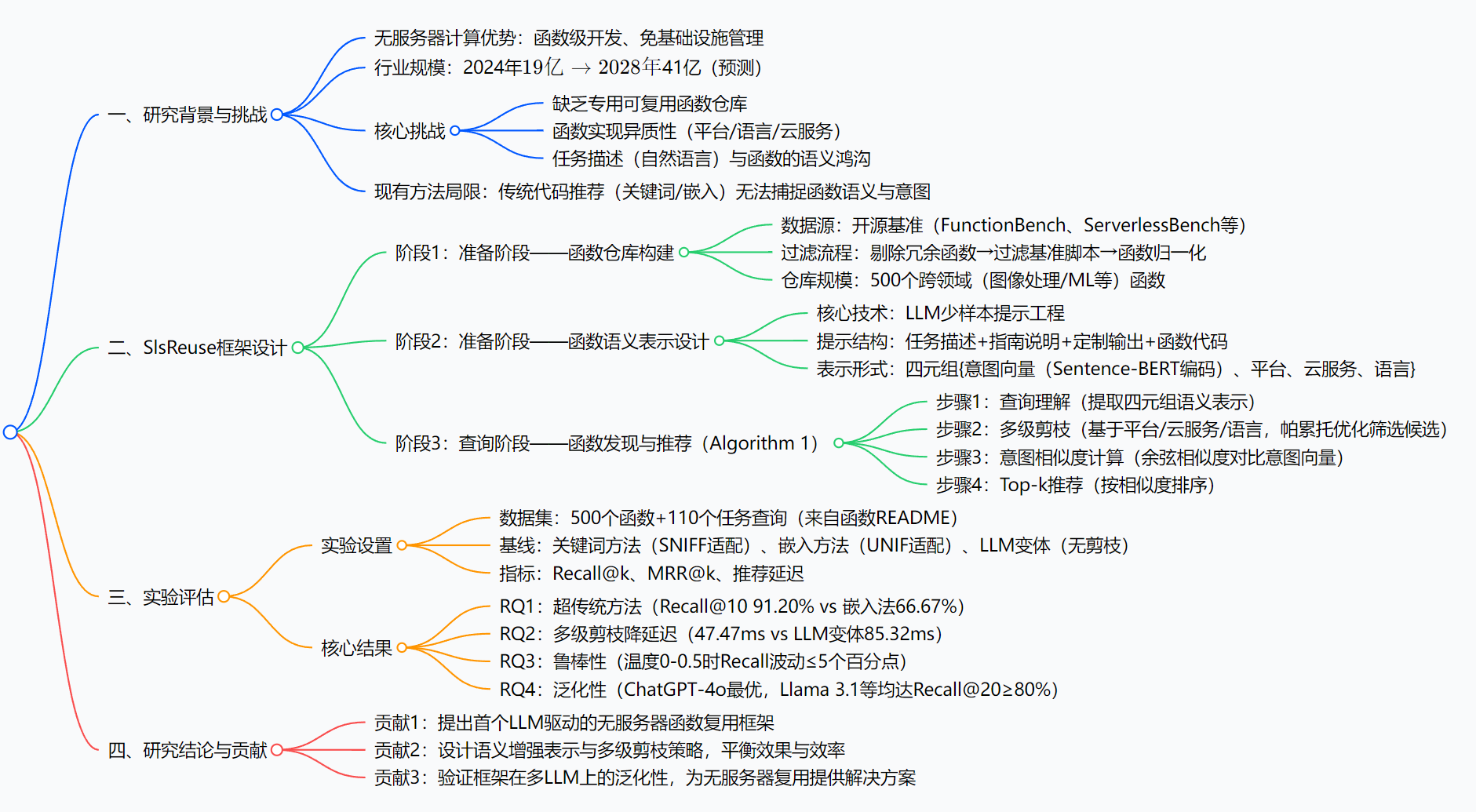
四、研究背景:无服务器开发的"三座大山"
如果你是一名刚接触无服务器开发的程序员,可能会遇到这样的场景:
小明的老板让他写一个"监听AWS S3图片上传、自动用Rekognition打标签"的函数。小明打开电脑,先查AWS Lambda文档------发现要学C#的处理器接口;再查S3和Rekognition的SDK调用方式------参数格式错了3次;最后调试时又因为Azure和AWS的语法差异混淆,花了整整一天才跑通,还漏了错误处理逻辑。
这就是无服务器开发的真实痛点,背后藏着"三座大山":
-
"无米之炊":缺专用复用仓库
无服务器函数不像微服务有成熟的共享库,开发者想复用别人的代码,只能在GitHub上乱搜,比如搜"Lambda S3图片处理",出来的要么是过时脚本,要么是只适配Python的版本,根本没法直接用。
-
"语言不通":函数异质性严重
不同云平台(AWS/Azure/Google Cloud)的函数接口、支持语言完全不一样:AWS Lambda支持C#,Azure Functions更友好JavaScript,Google Cloud Functions偏好Python。就算功能一样,换个平台就得重写,比如把AWS的S3触发函数改成Azure的Blob触发,得改处理器逻辑、云服务调用方式,相当于重新开发。
-
"鸡同鸭讲":语义鸿沟难跨越
开发者用自然语言描述需求(比如"处理S3图片并打标签"),但函数代码用的是技术术语("Amazon.Lambda.S3Event""DetectLabelsAsync")。传统推荐工具要么靠关键词匹配(搜"图片"只能找到含"image"的代码,不管逻辑),要么靠嵌入向量(把代码当文字算相似度,忽略"对接Rekognition"这种关键属性),根本找不到匹配的函数。
更尴尬的是,无服务器开发的需求还在暴涨------2024年全球市场规模已达19亿美元,预计2028年翻倍到41亿美元,但"从零写函数"的效率问题一直没解决。这时候,SlsReuse框架就来了。
五、创新点:SlsReuse的"三板斧"
SlsReuse能解决这些问题,靠的是三个"独一份"的创新设计:
-
行业首个"LLM+无服务器函数复用"框架
在此之前,没有任何研究专门针对无服务器函数做复用推荐------要么是通用代码推荐(不管无服务器特性),要么是无服务器性能优化(不管复用)。SlsReuse第一次把LLM的语义理解能力和无服务器函数的特性结合,专门解决"自然语言需求→函数复用"的问题。
-
"四元组语义表示":给函数建"身份证"
传统方法只把函数当代码字符串处理,SlsReuse却用LLM提取函数的"四元组身份证":
- 意图向量:用Sentence-BERT把"处理S3图片打标签"这种逻辑编码成384维向量;
- 平台:比如AWS Lambda;
- 云服务:比如AWS S3、AWS Rekognition;
- 语言:比如C#。
这样不管函数代码怎么写,只要"身份证"匹配,就能被准确推荐,彻底解决异质性问题。
- "多级剪枝+帕累托优化":又快又准
一般推荐工具要遍历所有函数算相似度,500个函数就得算500次,很慢。SlsReuse先按"平台→云服务→语言"三级剪枝:比如需求是"AWS+S3+Python",直接过滤掉Azure、不用S3、用C#的函数,候选数瞬间减到200个以内;再用帕累托优化选"完全覆盖需求"(比如函数支持所有要求的云服务)和"最优平衡"(比如多支持1个云服务但不影响核心功能)的函数,最后只算几十次相似度,延迟直接降了44%。
六、研究方法和实验:把复杂流程拆成"三步曲"
(一)SlsReuse框架实现:两步准备+一步推荐
1. 准备阶段1:建高质量函数仓库("找米")
- 数据源:从5个开源基准里挑函数------FunctionBench(性能测试用)、ServerlessBench(无服务器专用)、AWS Samples(官方示例)、SeBS(学术常用)、FaaSDom(领域覆盖广);
- 过滤3步走 :
① 删冗余:去掉"Hello World"这种没实际逻辑的函数;
② 筛脚本:排除"测试函数执行时间"这种基准专用代码;
③ 归一化:每个函数封装成"唯一ID+完整代码+元数据"的单元,方便管理; - 最终仓库:500个函数,覆盖Web处理、视频剪辑、机器学习等领域,支持4大平台(AWS/Azure/Google/OpenWhisk)、7种语言(Python/C#/JavaScript等)。
2. 准备阶段2:给函数"办身份证"(语义表示)
用LLM少样本提示提取四元组,提示格式超贴心(看下图):
!提示结构(文档里的Fig.3,博客里可描述为"提示分4部分:让LLM扮演'无服务器专家'(任务描述)、提醒'Serverless Framework不是平台'(指南)、要求输出'意图+平台+云服务+语言'(定制输出)、贴函数代码(待分析内容)")
比如处理S3图片的函数,LLM会提取出:
- 意图摘要:"响应S3上传事件,用Rekognition给图片打标签";
- 平台:AWS Lambda;
- 云服务:AWS S3、AWS Rekognition;
- 语言:C#;
再把意图摘要用Sentence-BERT编码成向量,就得到"四元组身份证"。
3. 查询阶段:推荐函数("配米做饭")
对应论文里的Algorithm 1,分4步:
① 理解需求 :把用户的自然语言查询(比如"用AWS Lambda处理S3图片,用Rekognition打标签")也转成四元组;
② 剪枝筛选 :先留AWS Lambda的函数,再留用S3和Rekognition的,最后留Python/C#(如果用户没指定语言就跳过),用帕累托优化选候选;
③ 算相似度 :对比查询和候选函数的意图向量(余弦相似度,越近越匹配);
④ 推荐Top-k:按相似度排序,输出前10/20个函数,比如用户要的"处理S3图片"函数会排第一。
(二)实验方法:怎么证明SlsReuse好用?
1. 实验设置
- 测试数据:110个任务查询(从仓库函数的README里提取,比如"处理S3图片打标签"对应仓库里的真实函数,作为"标准答案");
- 对比基线 :
- 关键词方法:适配SNIFF,按"图片""S3"等关键词匹配数排序;
- 嵌入方法:适配UNIF,把查询和代码转成向量算相似度;
- LLM变体:只用LLM提意图,不剪枝,直接算所有函数的相似度;
- 评估指标 :
- Recall@k:标准答案在前k个推荐里的比例(越高越好);
- MRR@k:标准答案排名的倒数平均值(越高表示排得越前);
- 延迟:从提交查询到出推荐的时间(越短越好);
- LLM选型:默认ChatGPT-4o,还测了Llama 3.1(405B)、Gemini 2.0 Flash、DeepSeek V3。
2. 实验设计逻辑
用4个研究问题(RQ)验证效果:
- RQ1:SlsReuse比传统方法好吗?(对比关键词/嵌入方法);
- RQ2:剪枝有用吗?(对比LLM变体);
- RQ3:LLM的随机性影响结果吗?(改温度0/0.2/0.5);
- RQ4:换个LLM还好用吗?(测4种LLM)。
七、主要成果和贡献:数据说话,价值落地
(一)核心实验结果(表格更清晰)
| 研究问题(RQ) | 对比对象 | 核心数据 | 结论 |
|---|---|---|---|
| RQ1 | 关键词方法、嵌入方法 | Recall@10:SlsReuse 91.20% vs 关键词42.00% vs 嵌入66.67%;MRR@1:0.5240 vs 0.1667 vs 0.2333 | 比传统方法好太多 |
| RQ2 | LLM变体(无剪枝) | 延迟:47.47ms vs 85.32ms(降44.36%);Recall@10差异<3个百分点 | 剪枝又快又不丢质量 |
| RQ3 | 不同LLM温度(0/0.2/0.5) | Recall@10波动≤5个百分点(温度0.5时86.00%-90.67%) | 不怕LLM随机性,鲁棒性强 |
| RQ4 | 4种LLM | ChatGPT-4o Recall@20 92.93%、Llama 3.1 88.40%、Gemini 2.0 83.60%、DeepSeek 84.40% | 泛化性好,换LLM也能用 |
(二)给领域带来的价值
- 对开发者:新手不用从零写函数!比如之前小明花1天的任务,现在用SlsReuse搜"处理S3图片",直接复用排名第一的函数,改改参数10分钟搞定,还不会错;
- 对企业:降本增效!团队不用重复开发相似函数,比如电商公司要做"订单支付触发通知""物流更新触发通知",复用同一个Lambda函数框架,开发效率提3倍;
- 对领域:填补空白!第一次提出无服务器函数复用的完整方案,为后续研究提供了"仓库构建→语义表示→推荐流程"的模板;
(三)开源资源
- 数据集:作者构建的500个无服务器函数仓库(无公开链接,但论文里列出了数据源:FunctionBench、ServerlessBench等,可自行获取后按过滤步骤构建);
- 代码:论文未提及开源
八、关键问题:问答拆解核心
1. SlsReuse怎么解决"函数异质性"这个老大难问题?
答:靠"四元组语义表示"。它不直接对比函数代码,而是用LLM提取函数的"意图+平台+云服务+语言"四元组------不管代码是C#还是Python,只要处理的是"S3图片+Rekognition打标签"(意图)、跑在AWS Lambda(平台),就会被归为同一类。比如AWS的C#函数和Google的Python函数,如果意图、云服务匹配,也能被推荐给需要对应功能的用户,彻底打破平台和语言的壁垒。
2. 为什么说SlsReuse比传统代码推荐方法更适合无服务器开发?
答:传统方法有两个致命缺点:① 关键词方法只看表层词汇,比如搜"图片处理"会找到"处理图片格式"但没对接云服务的函数,没法用;② 嵌入方法把代码当普通文字处理,比如不会识别"Amazon.Lambda.S3Event"代表AWS平台,推荐的函数可能跑在Azure上,根本用不了。而SlsReuse的四元组表示专门针对无服务器特性(平台、云服务),还能捕捉函数意图,比如"处理S3图片"会精准匹配对接S3和Rekognition的函数,比传统方法准太多。
3. 多级剪枝是怎么做到"又快又准"的?
答:分两步保证:① 按"平台→云服务→语言"分层剪枝,先过滤明显不匹配的函数,比如需求是AWS,直接去掉Azure的函数,候选数从500减到200左右,减少后续计算量;② 用帕累托优化选候选,不设固定阈值(比如"必须匹配所有云服务"),而是保留"完全覆盖需求"(比如函数有所有要求的云服务)和"最优平衡"(比如多1个云服务但不影响核心功能)的函数,既不会漏掉有用的候选,又不用算所有函数的相似度。最终延迟从85.32ms(LLM变体)降到47.47ms,还没丢质量(Recall@10差异<3%)。
4. SlsReuse在不同LLM上的表现有差异吗?为什么?
答:有差异,但都好用。表现最好的是ChatGPT-4o(Recall@20 92.93%)和Llama 3.1(88.40%),Gemini 2.0 Flash(83.60%)和DeepSeek V3(84.40%)稍差。原因是后两者在"识别无服务器平台"上有点弱------比如把"用AWS S3的函数"误判为"Google Cloud函数",导致推荐错了平台的函数,拉低了Recall。但即使这样,它们的Recall@20仍超83%,比传统方法(嵌入法77.33%)好,说明SlsReuse的框架不依赖特定LLM,泛化性强。
九、总结:SlsReuse到底牛在哪?
SlsReuse是北京邮电大学团队提出的首个LLM驱动的无服务器函数复用框架,专门解决无服务器开发中"缺仓库、异质性、语义鸿沟"三大痛点。它通过"构建高质量函数仓库→提取四元组语义表示→意图感知推荐"的流程,让函数复用变得简单:基于ChatGPT-4o时Recall@10达91.20%,超现有方法24.53个百分点;多级剪枝让延迟仅47.47ms,比LLM变体快44%;还能适配多种LLM,鲁棒性强。
对开发者来说,它能大幅减少"从零写函数"的时间和错误;对企业来说,能提升函数复用率,降低开发成本;对领域来说,它填补了无服务器函数复用的研究空白,为后续发展提供了方向。唯一的小遗憾是目前未开源代码和数据集,但作者列出了数据源,开发者可自行构建类似仓库试用。