五、锁机制(MySQL Locking)
(一)概述
1. 锁是什么?
锁用于协调多线程并发访问共享数据,保证数据一致性和事务隔离性。数据库中的竞争不仅来自 CPU/I/O,还来自数据抢占,因此锁机制在事务、并发控制中占核心位置。
2. 锁存在的根本目标:
保证 ACID 中的 I(隔离性)与 C(一致性)
降低并发冲突,提高整体吞吐
3. 锁按粒度划分
| 锁类型 | 粒度 | 冲突概率 | 应用场景示例 |
|---|---|---|---|
| 全局锁 | 数据库级 | 最高 | 全库备份,保证一致性快照 |
| 表级锁 | 表级 | 较高 | DDL执行、MDL锁、MyISAM读写 |
| 行级锁 | 行级 | 最低 | InnoDB事务更新或查询加锁 |
并发能力:行级 > 表级 > 全局
(二)全局锁
1. 机制说明
全局锁会将整个 MySQL 实例设置为只读,阻塞所有写入,常用于逻辑备份确保一致性快照。
sql
FLUSH TABLES WITH READ LOCK; -- 加全局锁
UNLOCK TABLES; -- 释放备份命令示例(Windows示例):
sql
mysqldump -uroot -p1234 db01 > D:/db01.sql但此方式会阻塞写,业务几乎停摆。
2. InnoDB无锁一致性备份
sql
mysqldump --single-transaction -uroot -p123456 itcast > itcast.sql原理 :MVCC + 快照读生成一致性视图,无需阻塞写操作
但仅适用于 InnoDB(MyISAM 仍必须 FTWRL)
对比总结
| 方式 | 是否阻塞写 | 原理 |
|---|---|---|
| 全局锁 FTWRL | ✔ | 整库只读 |
| --single-transaction | ✘ | 基于 MVCC 快照读 |
生产环境做全库备份如何避免阻塞业务?
使用 mysqldump --single-transaction 基于 MVCC 生成一致性视图,无需加全局锁。仅适用于 InnoDB,MyISAM 仍需 FTWRL。
(三)表级锁
1. 介绍
表锁粒度大,开销低但并发差,多用于 MyISAM 或 InnoDB 的元数据管理。
2. 手动表锁
sql
LOCK TABLES t READ; -- 共享锁,仅可读
LOCK TABLES t WRITE; -- 排他锁,阻塞其他会话读写
UNLOCK TABLES;3. 元数据锁(MDL, Meta Data Lock)
MDL自动控制,无需手动加锁。
| 操作 | 加锁类型 |
|---|---|
| SELECT / INSERT / UPDATE | MDL Shared 共享锁 |
| ALTER / DROP TABLE | MDL Exclusive 排他锁(阻塞所有读写) |
DDL阻塞线上业务 80% 原因是 MDL 未释放
DDL(如 ALTER)必须拿到 排他锁,
而排他锁必须等所有 MDL-S(SELECT/DML)释放才能执行。
→ 长事务未提交 = DDL永远无法执行 = 业务阻塞雪崩
查看元数据锁:
sql
SELECT * FROM performance_schema.metadata_locks;4. 意向锁(IS/IX,Intention Lock)
用于快速判断是否可加表锁,不会阻塞行锁本身,是兼容协调用的锁。
| 锁类型 | 含义 | 作用 |
|---|---|---|
| IS | 打算加共享行锁 | 允许共存,阻塞表X锁 |
| IX | 打算加排他行锁 | 并发事务可共存,用于RC、RR |
查看锁状态:
sql
SELECT object_schema, object_name, index_name, lock_mode, lock_data
FROM performance_schema.data_locks;为什么 DDL 常阻塞业务?
因为DML会加MDL共享锁,而DDL需要MDL排他锁
排他锁需要所有共享锁释放才可执行
只要有长事务未提交,就会导致DDL一直等待 → 生产大量阻塞
(四)行级锁(InnoDB核心)
InnoDB 加锁是基于索引的,不走索引会退化为表锁。
| 锁类型 | 区别 |
|---|---|
| Record Lock(记录锁) | 锁定当前行记录 |
| Gap Lock(间隙锁) | 锁定区间,阻止插入 |
| Next-Key Lock(临键锁) | Record + Gap,RR默认的范围锁 |
1. Row Lock 行锁
仅锁定目标记录,等值查询走唯一索引时不锁范围。
sql
SELECT * FROM user WHERE id = 10 FOR UPDATE;2. Gap Lock 间隙锁(防止幻读)
作用:锁区间,不含记录本身,用于阻止插入:
sql
SELECT * FROM user WHERE age > 20 AND age < 30 FOR UPDATE;3. Next-Key Lock 临键锁
RR默认模式下范围查询使用临键锁:
范围锁 = 当前记录行锁 + 左侧间隙锁
行锁加锁规则
| 场景 | 锁类型 | 说明 |
|---|---|---|
| 唯一索引等值命中 | 行锁 | 不锁间隙 |
| 唯一索引等值未命中 | 间隙锁 | 防止新插入造成幻读 |
| 普通索引范围扫描 | Next-Key Lock | 锁范围+记录 |
| 不走索引查询 | 表锁 | 极高风险 |
查看锁:
sql
SELECT object_schema,object_name,lock_type,lock_mode,lock_data
FROM performance_schema.data_locks;为什么普通索引范围查询会产生 Next-Key Lock?
RR隔离级别下为防止幻读
InnoDB必须锁住范围内所有可能插入的位置
因此使用 Next-Key(记录锁 + 间隙锁)
唯一索引等值查询一定只加行锁吗?
不是,存在记录才是行锁,不存在是间隙锁。
| SQL | 记录存在? | 加锁类型 |
|---|---|---|
SELECT * FROM t WHERE id = 5 FOR UPDATE |
✔ | 行锁 |
SELECT * FROM t WHERE id = 999 FOR UPDATE |
✘ | 间隙锁 |
不走索引更新为什么可能将锁升级为表锁?
InnoDB基于索引加锁
无索引会进行全表扫描
必须锁住所有行以保证一致性
→ 行锁退化为表锁
六、InnoDB存储引擎
(一)逻辑存储结构
| 层级 | 说明 | 底层原理/细化(扩写深度版) |
|---|---|---|
| Tablespace | ibd 或 system tablespace | 物理数据容器,包含数据页、索引页、Undo段、数据字典等元信息 |
| Segment | 数据段 / 索引段 / 回滚段 | InnoDB以段为管理粒度;数据段存行数据,索引段存B+ Tree结构,回滚段存Undo版本链 |
| Extent | 1MB(= 64 pages) | 分配空间以区为单位,连续64页减少碎片,支持顺序IO |
| Page | 16KB(最小IO单位) | Buffer Pool 与磁盘交互单元,页内 Slot Directory 进行记录快速定位 |
| Row | 记录(含隐藏列) | 行存储真实数据 + MVCC三大隐藏字段,决定可见性和版本链构建 |
为什么层级要这样设计?(底层思想)
MySQL不是按行读取而是按页读
一次IO最少16KB → 一次查询可能顺带读到同页其它行 → 局部性提升读性能
Extent(区)保证写入尽量连续
减少随机IO,提高写入吞吐
隐藏列
| 列 | 作用 |
|---|---|
| trx_id | 最近一次修改该行的事务ID |
| roll_pointer | 指向 Undo Log 旧版本链 |
| row_id | 无主键自动生成主键(影响聚簇索引顺序) |
没有主键的危害:
隐藏 row_id 是无序递增,但二级索引指向row_id导致插入位置随机 →B+树频繁分裂 → 页分裂、页分配压力↑ → 性能显著下降
最佳实践:永远显式使用业务主键或自增主键!
举例:一条数据被 UPDATE 三次发生了什么?
| 版本 | trx_id | roll_pointer | 可见? |
|---|---|---|---|
| v4(最新) | 25 | → v3 | 当前读能访问 |
| v3 | 21 | → v2 | 快照读可能访问 |
| v2 | 19 | → v1 | 当ReadView活跃时间早于trx19时可见 |
| v1(最早版本) | 15 | NULL | 所有旧事务都能读到 |
原理:Undo Log 构成链表,ReadView 决定事务看到哪个版本 → 读无需加锁。
为什么 InnoDB 要设计 Undo + 隐藏列才能实现 MVCC?
更新不是覆盖,而是写新版本,同时旧版本保存在Undo,通过 roll_pointer 串成版本链。
ReadView 决定当前事务能看到哪个版本,因此读无需加锁,不阻塞写。
为什么必须要有主键?
无主键自动生成 row_id,插入无序,导致B+树分裂更频繁,查询回表次数变多。明确主键 = 顺序写入 + 更快定位。
(二)InnoDB 内存结构
| 组件 | 作用 | 深度理解 |
|---|---|---|
| Buffer Pool | 缓存数据页/索引页 | 内存命中=0.1ms 远快于磁盘5~10ms,核心性能来源 |
| Change Buffer | 缓存二级非唯一索引写 | 更新无需立刻落盘 → 后台合并批量刷盘,写放大变低 |
| Adaptive Hash Index | 针对热点页生成哈希索引 | 高频B+Tree路径自动变成O(1),无需手动创建 |
| Log Buffer | Redo缓冲写入区 | 使用 WAL(write-ahead log)保证崩溃可恢复 |
为什么 Buffer Pool 这么重要?
因为数据库瓶颈不是CPU,而是磁盘随机IO。
16KB为单位批量读取、缓存高命中率直接降低读盘成本,
缓存命中与不命中性能差距可达 100~500倍级。
SELECT 查询完整流程图
sql
↓ 查Buffer Pool?
是 → 直接返回(亚毫秒级)
否 → 读磁盘 → 放到Buffer Pool → 返回(>5ms)Change Buffer 什么场景反而变慢?
二级索引频繁写并且查询立刻发生
数据未 merge,导致查询仍需回磁盘 → 甚至比不缓存更慢。
(三) 磁盘结构
| 组件 | 用途 | 底层原理(强化版) |
|---|---|---|
| System Tablespace | 早期共享存储 | 现代推荐file-per-table隔离空间 |
| File-per-table (.ibd) | 每表独立存储 | 可单独回收空间 TRUNCATE有效 |
| Undo Tablespace | 储存历史版本 | MVCC核心,版本链由 roll_pointer 串联 |
| Redo Log | 保障持久性 | 先写日志再刷盘(WAL),崩溃恢复靠它 |
| ★Doublewrite Buffer | 防止页半写 | 先写双写区再写表文件,PowerOff也不会页损坏 |
| Temporary Tablespace | order by / group by 需要 | 内存不足时溢写磁盘TMP表 |
Redo Log vs Undo Log
| 区别 | Redo | Undo |
|---|---|---|
| 内容 | 物理修改日志 | 保存修改前旧版本 |
| 用途 | 崩溃恢复 | MVCC + 回滚 |
| 写入 | WAL 顺序写,速度快 | 版本链越长,查询越慢 |
(四)后台线程
| 线程 | 工作内容 |
|---|---|
| Master Thread | 刷脏页、合并写入、回收空间 |
| IO Thread | 批量异步IO |
| Log Thread | 刷Redo Log至磁盘 |
| Purge Thread | 回收过期Undo链(清理MVCC垃圾) |
| Page Cleaner Thread | 降低批量刷盘造成的抖动 |
脏页什么时候刷盘?
① Buffer Pool满
② Checkpoint达到阈值
③ 事务提交时可能触发
④ 后台周期刷新
⑤ 关闭数据库前强制刷新
为什么Redo Log写够了也会刷脏页?
Checkpoint推进意味着Redo旧记录可覆盖;
不刷盘 = Redo永远不能清空 = 写满数据库直接停机。
(五)事务 & MVCC 底层原理
1. ACID
| 特性 | 落地组件 | 底层实现与说明 |
|---|---|---|
| A 原子性 | Undo Log | 修改前写 Undo,事务回滚时读取 Undo 反向应用,保证原子性。Undo 写在 Buffer Pool 内,可快速回滚。 |
| C 一致性 | 约束 + Redo + Undo + MVCC | 逻辑约束检查保证一致性,异常回滚通过 Undo 恢复,MVCC 保证快照读下并发一致性。 |
| I 隔离性 | 锁(行锁/间隙锁)+ MVCC | 写写冲突靠行锁/间隙锁隔离,读写冲突靠快照(ReadView)隔离,读不阻塞写。 |
| D 持久性 | Redo Log + WAL + 刷盘机制 | 提交事务先写 Redo(顺序写,WAL),后台异步刷盘,保证崩溃恢复。 |
Undo → 回滚(原子性 A)
Redo → 崩溃恢复(持久性 D)
Undo + ReadView → 决定事务能看到的版本(隔离性 I & 一致性 C)
2. MVCC 原理
MVCC(Multi-Version Concurrency Control,多版本并发控制)核心思想是:通过保存数据的多个版本,实现事务间读写隔离,而不必读操作阻塞写操作。
实现依赖三大核心组件
| 组件 | 作用 |
|---|---|
| Undo Log | 保存数据修改前的旧版本(Update/Delete),Insert 失败可回滚。通过 roll_pointer 串成版本链,支撑快照读。 |
| 隐藏列 | 每行额外存储元信息:- trx_id:最近修改该行的事务 ID- roll_pointer:指向 Undo Log 链表- row_id:无主键时生成的唯一 ID这些信息用于判断事务能否看到该版本。 |
| ReadView | 每个事务快照,用于判断当前事务可见的数据版本(利用 trx_id + 活跃事务列表 m_ids)。 |
InnoDB 行结构
sql
[主键/列数据]
[trx_id] ← 最近修改该行的事务 ID
[roll_pointer] ← 指向上一版本 Undo Log
[row_id] ← 无主键自动生成Update 流程
写新行版本
旧版本写入 Undo
通过 roll_pointer 串成版本链
示意链结构:
sql
最新版本 → V7(trx_id=27)
↓ roll_pointer
V6(trx_id=25)
↓ roll_pointer
V5(trx_id=19)
...快照读:遍历版本链,找到第一个对当前事务可见的版本
当前读 (FOR UPDATE):直接读取最新版本并加锁
Undo Log 类型
| 类型 | 用途 | 示例 |
|---|---|---|
| Insert Undo | 新增失败可回滚 | insert后rollback → 删除记录 |
| Update Undo | 保存旧版本用于MVCC | update salary=5000→6000需保留5000版本 |
| Delete Undo | 删除可回滚成可见 | delete后可撤销恢复行 |
Insert Undo 在事务结束可立即清除
Update/Delete Undo 要等 没有事务需要旧版本 才能 purge
这就是长事务为什么会拖垮数据库!
因为旧版本永远不能清除 → Undo无限增长 → 查询版本链越长越慢。
3. ReadView 可见性判断
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃事务列表 |
| min_trx_id | m_ids中最小ID |
| max_trx_id | 下一个未分配trx_id(可理解成最大活跃ID+1) |
| creator_trx_id | 当前事务ID |
一条数据对某事务是否可见
trx_id == creator_trx_id → 自己修改的可见
trx_id < min_trx_id → 已提交
trx_id > max_trx_id → 未来事务写的,不可见
min_trx_id ≤ trx_id ≤ max_trx_id 且 trx_id ∈ m_ids → 活跃事务,可能回滚,不可见
min_trx_id ≤ trx_id ≤ max_trx_id 且不在 m_ids → 已提交,可见
4. 多事务并发修改示例
| 时间 | 事务 | 操作 |
|---|---|---|
| T1 开启 | trx10 | UPDATE a SET age=18 |
| T2 开启 | trx12 | UPDATE a SET age=21 |
| T3 SELECT | 快照读(RR) | 可见 age=21(已提交版本) |
原理:
快照读 → 遍历版本链,找到可见版本
当前读 FOR UPDATE → 会等待 T1 释放行锁,再读最新值
5. MVCC & 四个隔离级别
| 隔离级别 | 读取来源 | 是否脏读 | 是否不可重复读 | 是否幻读 | ReadView策略 | 锁行为 |
|---|---|---|---|---|---|---|
| Read Uncommitted | 最新值(不看Undo) | ✔ | ✔ | ✔ | 不生成快照 | 几乎无锁,并发高错误多 |
| Read Committed | 每次select生成新ReadView | ✘ | ✔ | ⚠部分存在 | 快照随每次查询刷新 | update最新,select读新版本 |
| Repeatable Read(默认) | 事务期间使用同一ReadView | ✘ | ✘ | ⚠依旧可能 | 快照固定不变 | 幻读需Gap Lock解决 |
| Serializable | 加锁串行执行 | ✘ | ✘ | ✘ | 不依赖快照版本 | 读也加锁,性能最差 |
注意:
RR 默认隔离级别 非天然无幻读,必须通过间隙锁(Gap Lock)+ Next-Key Lock 防止幻读
MVCC 主要解决读写冲突,提高并发性能,而不是完全避免幻读
七、MySQL管理
(一)系统数据库
MySQL 安装完成后自带的四个系统数据库及作用:
| 数据库 | 作用 |
|---|---|
| mysql | 存储 MySQL 服务器正常运行所需信息,包括用户、权限、时区设置、主从配置等 |
| information_schema | 数据库元数据访问接口,提供数据库、表、字段类型、索引、权限等信息 |
| performance_schema | MySQL 运行时性能监控底层数据库,收集服务器状态和性能参数 |
| sys | 对 performance_schema 进行封装,提供易用视图,方便 DBA 和开发人员进行性能分析和调优 |
information_schema 和 performance_schema 是只读的视图,不存储业务数据。
(二)常用命令行工具
1. mysql 客户端
用于连接 MySQL 服务器执行 SQL 命令,不是服务端程序。
语法:
sql
mysql [options] [database]常用选项:
| 选项 | 说明 |
|---|---|
-u, --user=name |
指定用户名 |
-p, --password[=name] |
指定密码(可不直接跟密码,回车后输入) |
-h, --host=name |
指定服务器 IP 或域名 |
-P, --port=# |
指定端口 |
-e "SQL" |
直接执行 SQL 并退出,适合脚本批处理 |
示例:
sql
# 执行查询并退出
mysql -uroot -p123456 db01 -e "SELECT * FROM stu;"2. mysqladmin
MySQL 管理工具,用于检查服务器状态、创建/删除数据库等。
示例:
sql
# 删除数据库
mysqladmin -uroot -p123456 drop test01
# 查看服务器版本
mysqladmin -uroot -p123456 version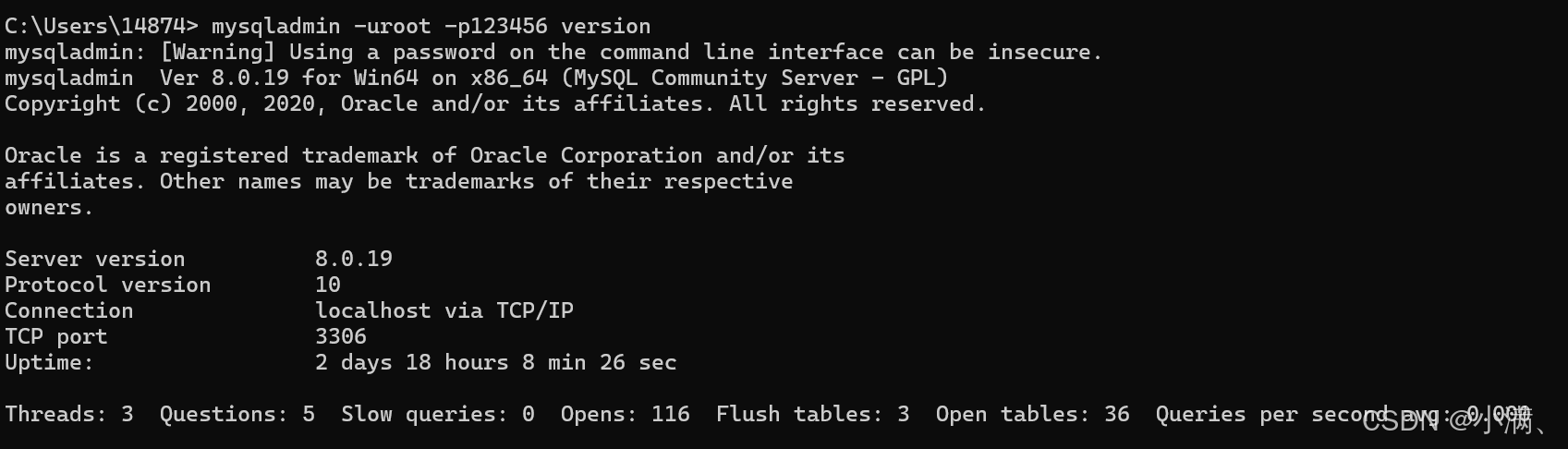
3. mysqlbinlog
用于解析 MySQL 二进制日志文件(Binary Log)。
常用选项:
| 选项 | 说明 |
|---|---|
-d, --database=name |
仅输出指定数据库相关操作 |
-o, --offset=# |
忽略前 n 行日志 |
-r, --result-file=name |
将输出写入文件 |
-s, --short-form |
简化输出,省略详细信息 |
--start-datetime=... --stop-datetime=... |
指定时间范围 |
--start-position=... --stop-position=... |
指定日志位置范围 |
4. mysqlshow
快速查看数据库、表、字段、索引等信息。
语法:
sql
mysqlshow [options] [db_name [table_name [col_name]]]常用选项:
| 选项 | 说明 |
|---|---|
--count |
显示统计信息(表行数、字段数等) |
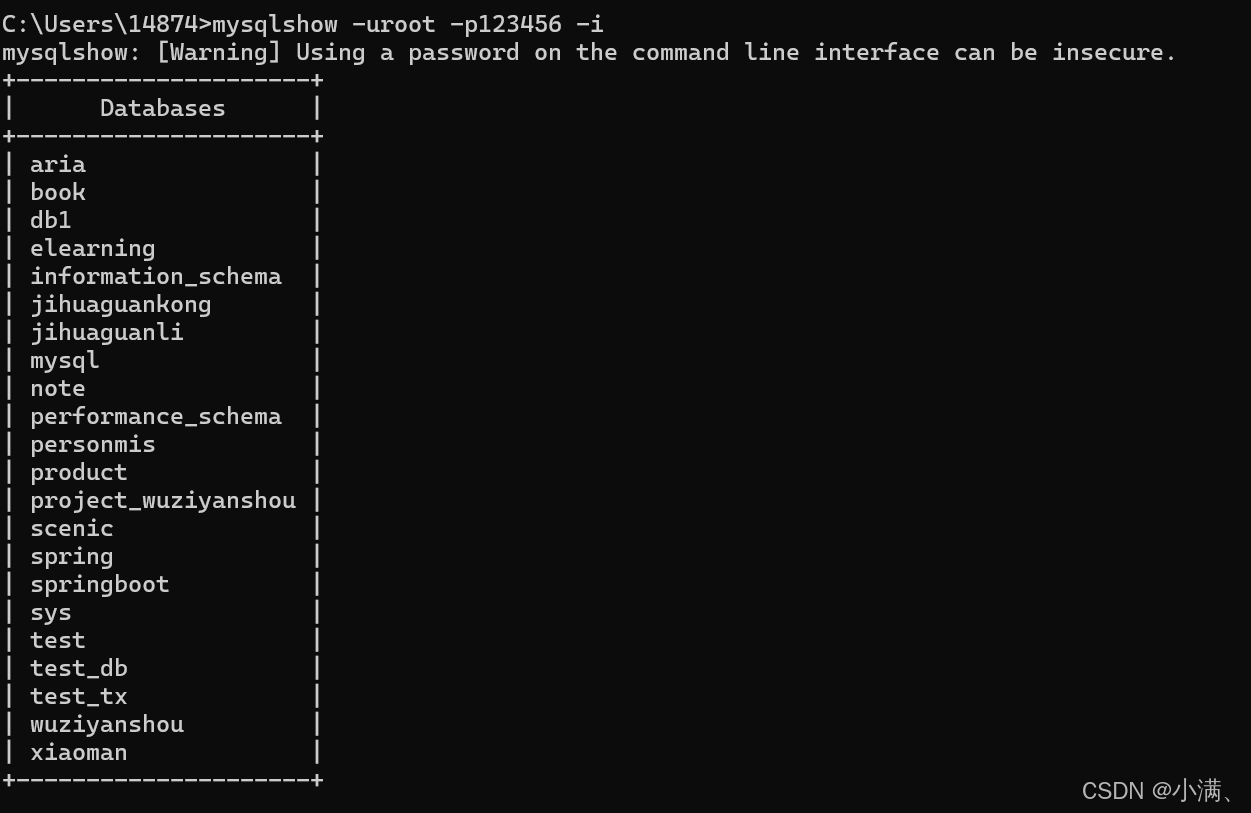
-i |
显示数据库或表的状态信息 |
示例:
sql
# 查询所有数据库及表数量
mysqlshow -uroot -p1234 --count
# 查询 test 库中表和字段信息
mysqlshow -uroot -p1234 test --count
# 查询 test.book 表详细信息
mysqlshow -uroot -p1234 test book --count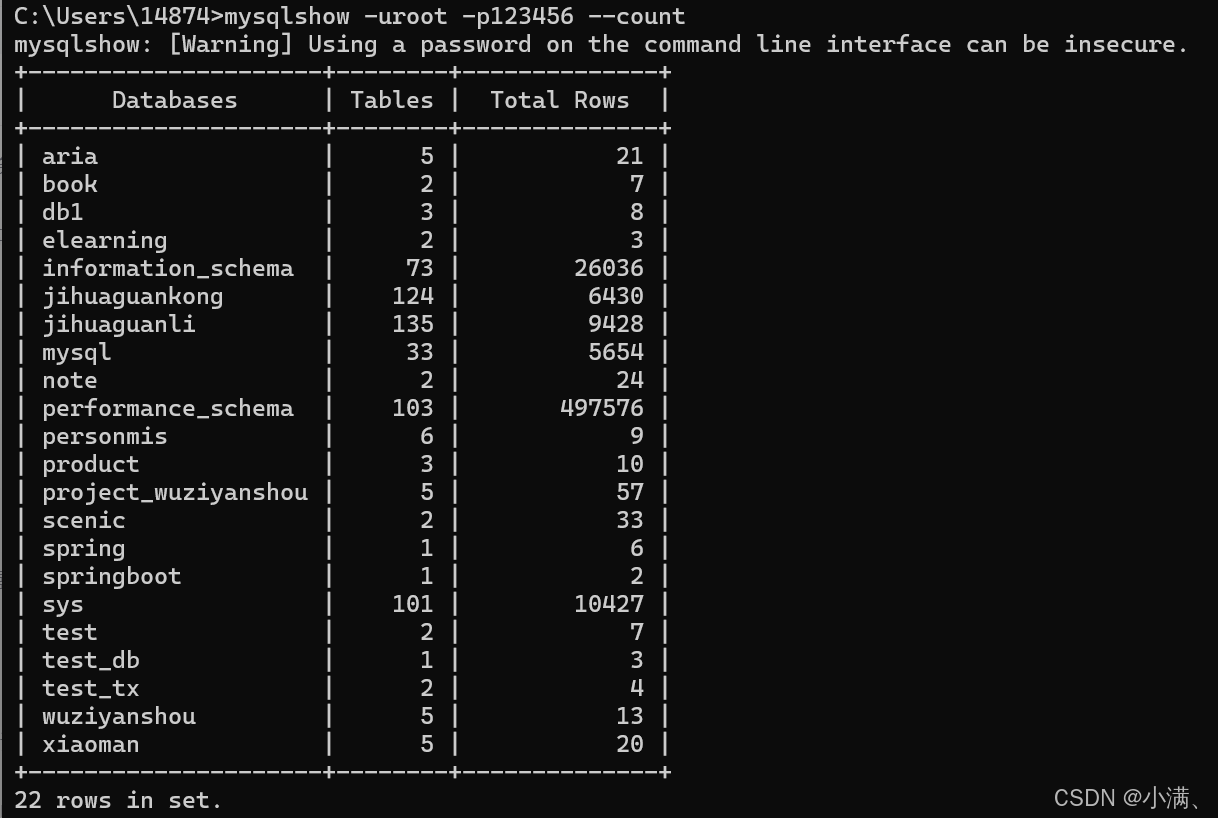
5. mysqldump
数据库备份与迁移工具,可导出 SQL 文件或数据。
语法:
sql
mysqldump [options] db_name [tables]
mysqldump [options] --databases db1 [db2 ...]
mysqldump [options] --all-databases / -A常用选项:
| 选项 | 说明 |
|---|---|
-u, --user |
指定用户名 |
-p, --password |
指定密码 |
--add-drop-database |
备份文件中包含 DROP DATABASE |
--add-drop-table |
备份文件中包含 DROP TABLE(默认开启) |
-n, --no-create-db |
不生成数据库创建语句 |
-t, --no-create-info |
不生成表结构语句,只导出数据 |
-d, --no-data |
只生成表结构,不导出数据 |
-T, --tab=name |
生成 .sql(结构)和 .txt(数据)两个文件 |
示例:
sql
# 备份单个数据库
mysqldump -uroot -p1234 db01 > db01.sql
# 备份所有数据库
mysqldump -uroot -p1234 -A > all_databases.sql6. mysqlimport 与 source
mysqlimport:导入 mysqldump -T 生成的文本数据。
sql
mysqlimport -uroot -p1234 test /tmp/data.txtsource:导入 SQL 文件到当前数据库。
sql
source /root/backup.sql;Excel、JSON、XML 文件可先转换为 .csv 或 .txt 再使用 LOAD DATA INFILE 或 mysqlimport 导入。