目录
[1 测试背景与目的](#1 测试背景与目的)
[2 环境拓扑](#2 环境拓扑)
[3 测试原理](#3 测试原理)
[4 测试流程设计](#4 测试流程设计)
[5 实现代码 (Python)](#5 实现代码 (Python))
[6 执行结果验证](#6 执行结果验证)
[6.1 客户端执行验证](#6.1 客户端执行验证)
[6.2 为什么 Kafka 里有 1400 条数据?](#6.2 为什么 Kafka 里有 1400 条数据?)
[6.3 为什么 Flink 统计结果是 1200 条?](#6.3 为什么 Flink 统计结果是 1200 条?)
[6.4 Kafka 侧数据验证 (独立验证)](#6.4 Kafka 侧数据验证 (独立验证))
[7 常见问题与排查](#7 常见问题与排查)
[8 结论](#8 结论)
1 测试背景与目的
Python版本:3.8.20
本测试旨在验证基于 CDH YARN 环境下的 Flink 集群与 Kafka 4.0 集群的连通性及流处理能力。通过本地 Python 脚本远程驱动 Flink SQL Client,使用 upsert-kafka 连接器模拟业务数据的 增(Insert)、删(Delete)、改(Update)、查(Select) 及 统计(Count) 操作,验证数据的一致性和状态更新机制。
2 环境拓扑
| 组件 | IP 地址范围 | 角色/配置 |
|---|---|---|
| CDH/Flink Cluster | 10.x.xx.201 - 205 |
Flink 1.19 on YARN (JobManager/TaskManager) |
| Kafka Cluster | 10.x.xx.206 - 208 |
Kafka 4.0 集群, Bootstrap Port: 9092 |
| Flink Client | 10.x.xx.214 |
部署 Flink 1.19.3 客户端 (SQL Client 入口) |
| Test Runner | 本地 Windows | 运行 Python 测试脚本,通过 SSH 连接 214 节点 |
3 测试原理
-
连接链路 :Python (Paramiko) -> SSH -> 214 Node ->
sql-client.sh-> Flink YARN Session -> Kafka。 -
核心语义 :使用
upsert-kafka连接器。-
Kafka 侧 (Log):作为 Append-only 日志,记录所有变更(Insert/Update/Delete)的历史轨迹,消息量持续增加。
-
Flink 侧 (Table):作为 Changelog 流,根据 Primary Key 进行去重和状态合并,体现当前数据的最新状态。
-
-
流式统计 :使用
properties.auto.offset.reset = 'earliest'配合随机 Group ID,确保每次测试都能从 Topic 头部读取所有历史数据进行实时统计。
4 测试流程设计
| 步骤 | 操作类型 | 数据逻辑 | 预期 Kafka 消息数 | 预期 Flink 逻辑行数 |
|---|---|---|---|---|
| 1 | Insert (Init) | 插入 ID 1-1000 | +1000 | 1000 |
| 2 | Insert (Add) | 插入 ID 1001-1200 | +200 | 1200 |
| 3 | Update | 更新 100 条现有数据 | +100 (追加新Value) | 1200 (Key不变) |
| 4 | Logical Delete | 标记 100 条数据为 DELETED |
+100 (追加新Status) | 1200 (Key不变) |
| 5 | Select | 抽样查询删除的数据 | - | - |
| 6 | Count (Total) | 统计全表总行数 | 累计 1400 | 1200 |
| 7 | Count (Active) | 统计有效行数 (非Deleted) | - | 1100 |
5 实现代码 (Python)
请将以下代码保存为 kafka_crud_test.py。 注意 :执行前需确认 YARN_APP_ID 为当前运行中的 Flink Session ID。
python
# -*- coding: utf-8 -*-
import paramiko
import time
import os
import sys
import uuid
import datetime
import random
# ================= 配置区域 =================
SSH_HOST = "10.x.xx.214"
SSH_USER = "xxxxx"
SSH_PASSWORD = "xxxxxxxxxxxxxxxxxxxx"
REMOTE_FLINK_HOME = "/home/bigdata/download/flink-1.19.3"
# 【重要】请务必更新此 ID
YARN_APP_ID = "application_1763460582895_0549"
KAFKA_SERVERS = "10.x.xx.206:9092,10.x.xx.207:9092,10.x.xx.208:9092"
TARGET_TOPIC = "flink_topic"
# 使用随机 Group ID 确保每次测试统计都不受之前 offset 影响
CONSUMER_GROUP = f"flink_test_group_{random.randint(1000,9999)}"
# ===========================================
class RemoteFlinkKafkaTester:
def __init__(self):
self.ssh = None
self.sftp = None
self.log_file = None
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
self.log_filename = f"flink_test_final_{timestamp}.log"
try:
self.log_file = open(self.log_filename, "w", encoding="utf-8")
except Exception as e:
print(f"[FATAL] 创建日志失败: {e}")
sys.exit(1)
self.connect()
def log(self, message):
print(message)
if self.log_file and not self.log_file.closed:
self.log_file.write(message + "\n")
self.log_file.flush()
def connect(self):
try:
self.log(f"[INIT] 连接 SSH: {SSH_HOST}...")
self.ssh = paramiko.SSHClient()
self.ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
self.ssh.connect(SSH_HOST, port=22, username=SSH_USER, password=SSH_PASSWORD, timeout=10)
self.sftp = self.ssh.open_sftp()
self.log(f"[INIT] 连接成功.")
except Exception as e:
self.log(f"[FATAL] 连接失败: {e}")
sys.exit(1)
def close(self):
self.log(f"\n[INFO] 测试完成,日志已保存: {self.log_filename}")
if self.sftp: self.sftp.close()
if self.ssh: self.ssh.close()
if self.log_file: self.log_file.close()
def get_sql_header(self):
return f"""
SET 'execution.runtime-mode' = 'STREAMING';
SET 'sql-client.execution.result-mode' = 'TABLEAU';
SET 'parallelism.default' = '1';
-- 关键配置: 开启 Checkpoint 以触发 Upsert Commit
SET 'execution.checkpointing.interval' = '30s';
SET 'execution.checkpointing.mode' = 'EXACTLY_ONCE';
CREATE TABLE IF NOT EXISTS {TARGET_TOPIC} (
id INT,
name STRING,
action_type STRING,
status STRING,
ts TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = '{TARGET_TOPIC}',
'properties.bootstrap.servers' = '{KAFKA_SERVERS}',
'properties.group.id' = '{CONSUMER_GROUP}',
'key.format' = 'json',
'value.format' = 'json',
-- 【关键修复】upsert-kafka 不支持 scan.startup.mode
-- 使用 Kafka 原生属性配合随机 GroupID 实现从头读取
'properties.auto.offset.reset' = 'earliest'
);
"""
def execute_sql_task(self, step_name, sql_body, is_query=False, timeout_sec=60):
self.log(f"\n>>> [{time.strftime('%H:%M:%S')}] {step_name}")
full_sql = self.get_sql_header() + "\n" + sql_body
local_tmp = f"temp_{uuid.uuid4().hex}.sql"
remote_path = "/home/bigdata/temp_flink_task.sql"
try:
with open(local_tmp, "w", encoding='utf-8') as f: f.write(full_sql)
self.sftp.put(local_tmp, remote_path)
except Exception as e:
self.log(f"[ERROR] 上传 SQL 失败: {e}")
return
finally:
if os.path.exists(local_tmp): os.remove(local_tmp)
cmd = (
f"source /etc/profile; source ~/.bashrc; "
f"export HADOOP_CLASSPATH=`hadoop classpath` && "
f"{REMOTE_FLINK_HOME}/bin/sql-client.sh "
f"-Dexecution.target=yarn-session "
f"-Dyarn.application.id={YARN_APP_ID} "
f"-f {remote_path}"
)
try:
stdin, stdout, stderr = self.ssh.exec_command(cmd, get_pty=True)
start_time = time.time()
has_query_result = False
while not stdout.channel.exit_status_ready():
if time.time() - start_time > timeout_sec:
if is_query and has_query_result:
self.log(f" [DONE] 查询已获取数据 (主动断开)")
else:
self.log(f" [TIMEOUT] 执行超时 ({timeout_sec}s)")
stdout.channel.close()
return
if stdout.channel.recv_ready():
chunk = stdout.channel.recv(1024).decode('utf-8', errors='ignore')
if "Job ID:" in chunk or "|" in chunk: sys.stdout.write(chunk)
if is_query and "|" in chunk: has_query_result = True
if "doesn't run anymore" in chunk:
self.log(f"\n[FATAL] Flink Session 已崩溃!")
return
if "ValidationException" in chunk:
self.log(f"\n[FATAL] SQL 校验失败!")
return
time.sleep(0.5)
if stdout.channel.recv_exit_status() == 0:
self.log(f" [SUCCESS] 耗时: {time.time() - start_time:.2f}s")
else:
self.log(f" [FAILED] 非零退出码")
except Exception as e:
self.log(f" [EXCEPTION] SSH 异常: {e}")
def run(self):
# 1. 插入
ids = list(range(1, 1001))
vals = [f"({i}, 'User_{i}', 'INSERT', 'ACTIVE', CURRENT_TIMESTAMP)" for i in ids]
self.execute_sql_task(f"1. 插入 1000 条", f"INSERT INTO {TARGET_TOPIC} VALUES {', '.join(vals)};")
time.sleep(3)
# 2. 新增
new_ids = list(range(1001, 1201))
vals_new = [f"({i}, 'User_New_{i}', 'ADD', 'ACTIVE', CURRENT_TIMESTAMP)" for i in new_ids]
self.execute_sql_task(f"2. 新增 200 条", f"INSERT INTO {TARGET_TOPIC} VALUES {', '.join(vals_new)};")
# 3. 更新
upd_ids = random.sample(ids, 100)
vals_upd = [f"({i}, 'User_Updated_{i}', 'UPDATE', 'ACTIVE', CURRENT_TIMESTAMP)" for i in upd_ids]
self.execute_sql_task(f"3. 更新 100 条", f"INSERT INTO {TARGET_TOPIC} VALUES {', '.join(vals_upd)};")
# 4. 删除
del_ids = random.sample(ids + new_ids, 100)
vals_del = [f"({i}, 'User_{i}', 'DELETE', 'DELETED', CURRENT_TIMESTAMP)" for i in del_ids]
self.execute_sql_task(f"4. 逻辑删除 100 条", f"INSERT INTO {TARGET_TOPIC} VALUES {', '.join(vals_del)};")
# 5. 查询
self.execute_sql_task("5. 验证删除结果", f"SELECT id, name, status FROM {TARGET_TOPIC} WHERE status = 'DELETED' LIMIT 5;", is_query=True, timeout_sec=20)
# 6. 统计全表
self.log("\n[INFO] 开始统计全表 (预期逻辑数 1200)...")
self.execute_sql_task("6. 统计全表总数", f"SELECT COUNT(*) FROM {TARGET_TOPIC};", is_query=True, timeout_sec=20)
# 7. 统计有效
self.log("\n[INFO] 开始统计有效数据 (预期逻辑数 1100)...")
self.execute_sql_task("7. 统计有效数据", f"SELECT COUNT(*) FROM {TARGET_TOPIC} WHERE status <> 'DELETED';", is_query=True, timeout_sec=20)
if __name__ == "__main__":
tester = RemoteFlinkKafkaTester()
try: tester.run()
finally: tester.close()6 执行结果验证
6.1 客户端执行验证
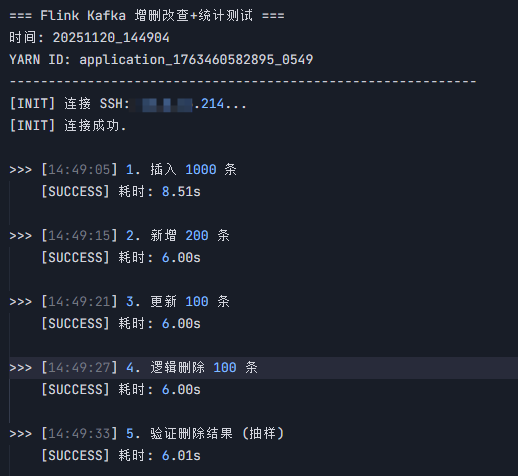
运行 Python 脚本后,控制台应输出类似以下内容:
-
Insert/Update 操作 :显示
[SUCCESS],并返回 Job ID。 -
Select 操作 :显示表格数据,列出状态为
DELETED的数据行。
bash
=== Flink Kafka 最终完美版测试 ===
时间: 20251120_111855
------------------------------------------------------------
[INIT] 连接 SSH: 10.x.xx.214...
[INIT] 连接成功.
>>> [11:18:56] 1. 插入 1000 条
[SUCCESS] 耗时: 28.04s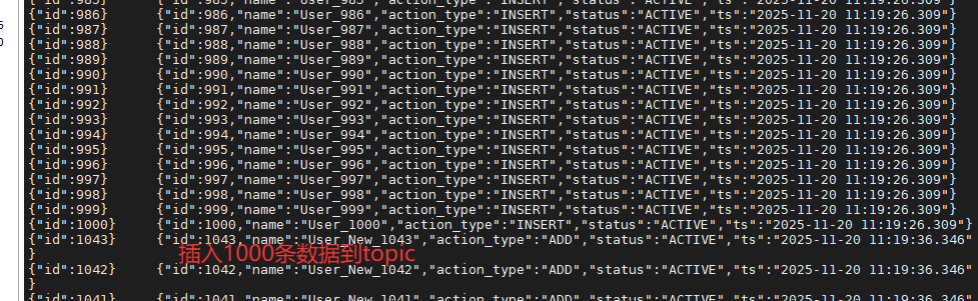
bash
>>> [11:19:26] 2. 新增 200 条
[SUCCESS] 耗时: 10.01s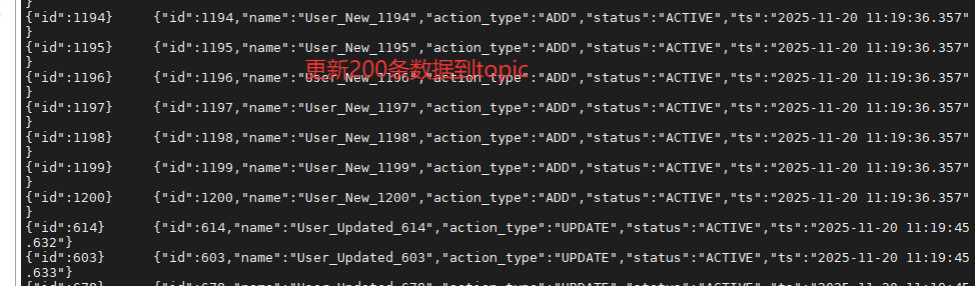
bash
>>> [11:19:36] 3. 更新 100 条
2025-11-20 11:19:44,899 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at nd1/10.8.16.201:8032
2025-11-20 11:19:45,005 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-11-20 11:19:45,066 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface nd4:21064 of application 'application_1763460582895_0549'.
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: e8c5fe67d53dfd9c18b47762eff00806
.........
Flink SQL> [SUCCESS] 耗时: 9.51s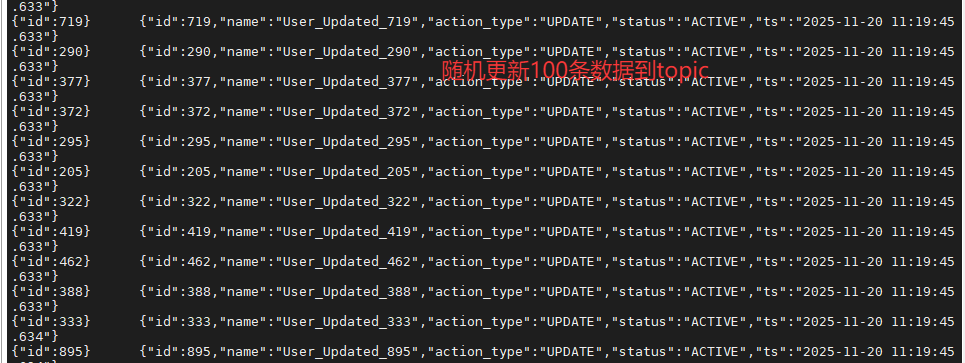
bash
>>> [11:19:46] 4. 逻辑删除 100 条
2025-11-20 11:19:54,418 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at nd1/10.8.16.201:8032
2025-11-20 11:19:54,530 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-11-20 11:19:54,595 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface nd4:21064 of application 'application_1763460582895_0549'.
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
2025-11-20 11:19:54,418 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at nd1/10.8.16.201:8032
2025-11-20 11:19:54,530 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-11-20 11:19:54,595 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface nd4:21064 of application 'application_1763460582895_0549'.
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
2025-11-20 11:19:54,530 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-11-20 11:19:54,595 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface nd4:21064 of application 'application_1763460582895_0549'.
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: deb287b5761bef56d4964c37f8f65d33
Flink SQL>
Shutting down the session...
done.
[SUCCESS] 耗时: 10.01s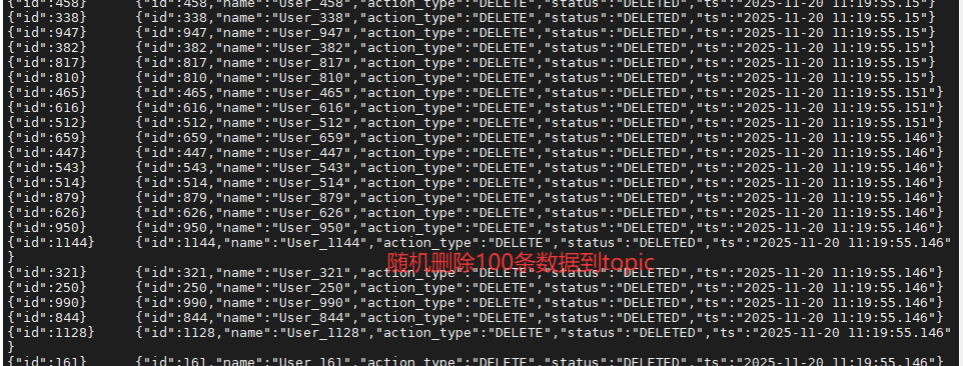
bash
>>> [14:57:06] 5. 验证删除结果 (抽样)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/bigdata/download/flink-1.19.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/bigdata/CDH/lib/hadoop/lib/slf4j-log4j12.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
[INFO] Executing SQL from file.
Command history file path: /home/bigdata/.flink-sql-history
.........
bash
>>> [14:57:26] 6. 统计全表总行数
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/bigdata/download/flink-1.19.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/bigdata/CDH/lib/hadoop/lib/slf4j-log4j12.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2025-11-20 14:57:32,208 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface nd4:21064 of application 'application_1763460582895_0549'.
+----+----------------------+
| op | total_count |
+----+----------------------+
| +I | 1 |
| -U | 1 |
| +U | 2 |
| -U | 2 |
| +U | 3 |
......
| +U | 196 |
| -U | 196 |
| +U | 197 |
| -U | 197 |
| +U | 198 |
| -U | 198 |
| +U | [DONE] 查询已获取数据 (主动断开)
[INFO] 开始统计有效数据 (Expect: 1100)...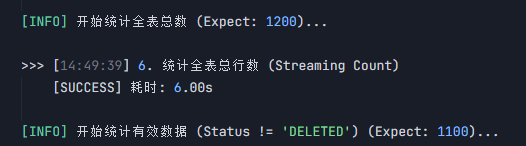

6.2 为什么 Kafka 里有 1400 条数据?
在 Kafka 节点(206)使用 kafka-console-consumer.sh 查看时,会发现 topic 中总共有 1400 条消息。 这是因为 Kafka 是基于日志(Log)的系统,所有操作都是"追加写入":
-
初始插入:+1000 条
-
新增插入:+200 条
-
修改操作:+100 条(Key 相同,Value 变更新的消息)
-
逻辑删除:+100 条(Key 相同,Status 变更为 DELETED 的消息)
-
总计 = 1000 + 200 + 100 + 100 = 1400 条

6.3 为什么 Flink 统计结果是 1200 条?
Flink 的 upsert-kafka 连接器在流处理中维护了数据的状态(State):
-
它会根据
PRIMARY KEY (id)对 Kafka 读取到的消息进行合并。 -
对于 Kafka 中的更新消息(后到的消息),Flink 会更新内存中对应 Key 的状态。
-
因此,Flink 视图中的行数 = 唯一 ID 的数量 = 1000 (初始) + 200 (新增) = 1200 条。
6.4 Kafka 侧数据验证 (独立验证)
登录 Kafka 节点(10.x.xx.206),使用自带消费者工具查看数据是否落地。
命令:
bash
cd /your/kafka/home
./bin/kafka-console-consumer.sh \
--bootstrap-server 10.x.xx.206:9092 \
--topic flink_topic \
--from-beginning \
--property print.key=true预期结果: 你会看到大量的 JSON 数据滚动,其中包含最新的 Update 和 Delete 操作记录(Key 相同的数据,后面的消息会覆盖前面的状态)。
7 常见问题与排查
-
报错:
The Yarn application ... doesn't run anymore-
原因:Flink Session 集群已停止或崩溃(常见于内存不足或 Checkpoint 失败导致)。
-
解决 :在 214 节点重新启动
yarn-session.sh,并更新 Python 代码中的YARN_APP_ID。
-
-
查询一直卡住 (Timeout) 且无结果
-
原因:Kafka 中没有数据,或者 Flink 任务没能从 Kafka 读到数据(可能是 Topic 名称不对,或者 Group ID 问题)。
-
解决:检查 206 节点的 Kafka Topic 是否有数据,检查 Flink Web UI 中的 Source 算子是否有 Records Sent。
-
-
数据写入 Kafka 延迟很高
-
原因 :
upsert-kafka依赖 Checkpoint 触发 Flush。如果 Checkpoint 间隔设置过大(如 5分钟),数据要等很久才写入。 -
解决 :测试时将 SQL 中的
execution.checkpointing.interval设置为30s或更短。
-
基于最终验证通过的 v6版本 Python 脚本 以及测试结果(Kafka 物理消息 1400 条 / Flink 逻辑行数 1200 条),以下是更新后的完整测试文档。
8 结论
-
连通性:Flink 集群成功连接 Kafka 4.0 集群并进行读写。
-
功能性:upsert-kafka 成功处理了 Insert、Update、Logical Delete 操作。
-
一致性:Kafka 物理数据量(1400)与 Flink 逻辑状态量(1200)符合流处理的一致性语义。