之前的文章:《大规模语言模型从理论到实践》--强化学习(RLHF、PPO、DPO)_强化学习bop-CSDN博客
已经学习过强化学习了,但是理解上还是比较抽象,今天工作看到这里就再详细学习一下。
本笔记比较零散,是带着我疑惑的地方重点学习的。
PPO算法
PPO步骤理解

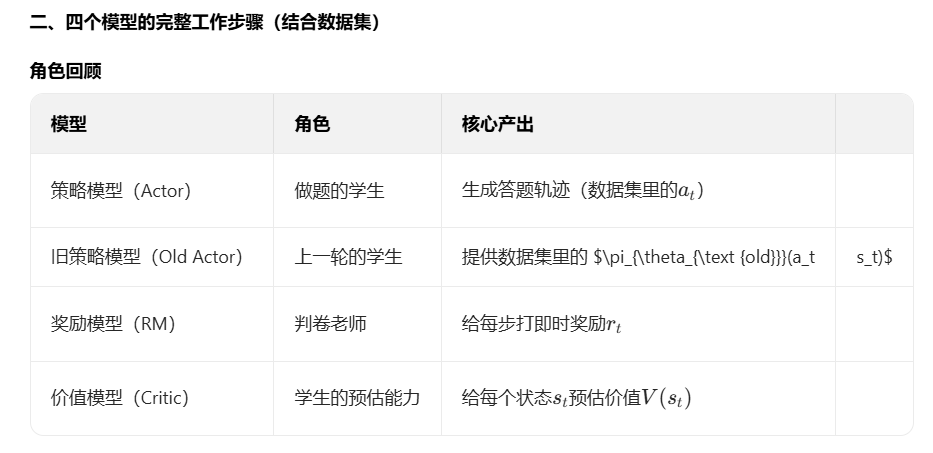




这里的Ut其实是奖励模型计算出来的。
PPO公式理解


PPO的缺点
PPO 的核心痛点是 "依赖绝对奖励模型 + 价值模型",导致标注成本高、适配推理任务难。
不同任务(如数学推理、对话生成)需定制不同奖励模型,PPO 难以实现通用对齐。
PPO 需多次采样生成轨迹数据。

PPO训练策略模型和奖励模型数据集
奖励模型数据集:


价值模型的V(t)是如何得来的


V(t)和参数Theta是需要训练更新的值。开始的 v (t) 确实是随机初始化的 Critic 网络给出的随机预测值,但这只是训练的起点 ------ 随着 Critic 不断用真实轨迹的回报修正自己,v (t) 会从 "随机猜测" 逐渐收敛到能准确反映状态价值的 "有效预测"。
GRPO
GRPO 就解决了这个问题:它不需要奖励模型给 "绝对分数",只需要把 "同一道题的 3 种解法放在一起对比"(比如 "4+2=6" 比 "4+2=7" 好,"步骤详细的解法" 比 "步骤简略的解法" 好),就能让模型学会改进 ------ 相当于学生不用做上万道题,只需要对比几道题的解法优劣,就能学会知识点,效率高得多。


