

**前引:**在 Linux 系统中,并发是常态,但并发带来的竞争条件、数据不一致问题,全靠 "锁" 来兜底。从内核态的进程调度到用户态的多线程编程,锁是保障系统稳定的核心同步原语。本文将跳出 "只会用" 的层面,深入内核源码逻辑,拆解自旋锁、互斥锁等常见锁的实现机制,剖析不同锁的设计取舍,帮你从底层理解 Linux 锁的工作原理与性能关键!
目录
【一】共享数据不一致问题
(1)不一致现象
我们先来看一段代码,如果现在有一个全局整数,由3个线程并发减减,减到0结束,看看结果:

理想效果:变量不管如何变化,减到0应该会结束所有线程访问,但是下面是测试结果:

原因解释:
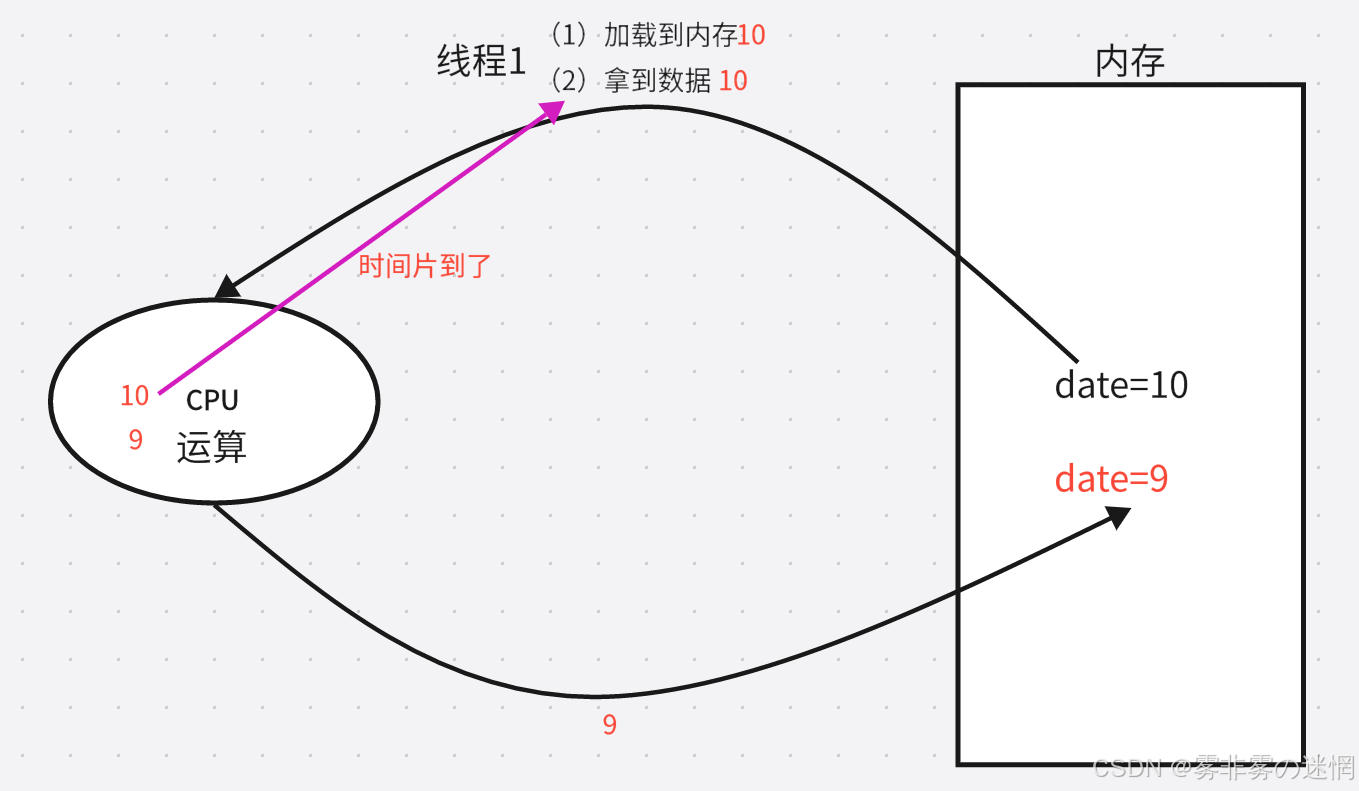
数据需要从内存拿到CPU运算得到处理结果:但是如果一个线程的时间片到了,它只完成了第一步(加载到内存)此时从CPU拿回数据结果为10,但是CPU已经完成了运算10->9,CPU返回给内存。此时线程1再次调用运算,给CPU的数据就是10,虽然看上去是这个时间片的问题,但是数据每次执行运算都是根据(date>0)判断,所以只要同步这个数据结果,就不会出现这个不一致问题
(2)加锁理解
上面出现的问题无非是:共享资源被并发线程访问出现的数据不一致问题,而"锁"恰好可以解决:
**"锁"的理解:**进程或线程操作同一个资源(比如文件、内存数据、设备)时,锁会强制它们 "排队访问",确保同一时间只有一个执行者能操作资源,从而避免冲突(类似队列式访问)
"锁"的特点:互斥性:同一时间,锁只能被一个进程 / 线程持有,其他请求者会被阻塞或直接返回失败
原子性:锁的 "获取" 和 "释放" 操作是不可分割的,不会出现 "一半获取成功" 的中间状态
锁的使用:对"获取锁"和"释放锁"范围的代码形成加锁,即中间代码每次只允许一个线程访问
【二】互斥"锁"
什么是互斥"锁"?单单的满足你访问我就不能访问的条件,每次只有一个执行流访问
(1)定义锁变量
在使用锁之前我们需要先定义一个锁变量:
cpp
pthread_mutex_t 变量名; // 定义锁变量例如:

或者直接全局初始化一把锁,就可以直接使用:直接开始(3)和(4)
cpp
#include <pthread.h>
pthread_mutex_t 锁变量名 = PTHREAD_MUTEX_INITIALIZER;(2)初始化锁
原型:
cpp
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);参数:
**第一个参数:**定义的锁变量地址
**第二个参数:**设置锁的属性,一般传NULL
例如:

(3)获取锁
原型:
cpp
int pthread_mutex_lock(pthread_mutex_t *mutex);参数:锁变量的地址
例如:

(4)主动释放锁+获取返回值
原型:
cpp
int pthread_mutex_unlock(pthread_mutex_t *mutex);参数:锁变量的地址
例如:

锁的使用举例:
对我们刚才的代码进行加锁,看是否还能出现数据不一致的问题:需要注意释放锁的位置
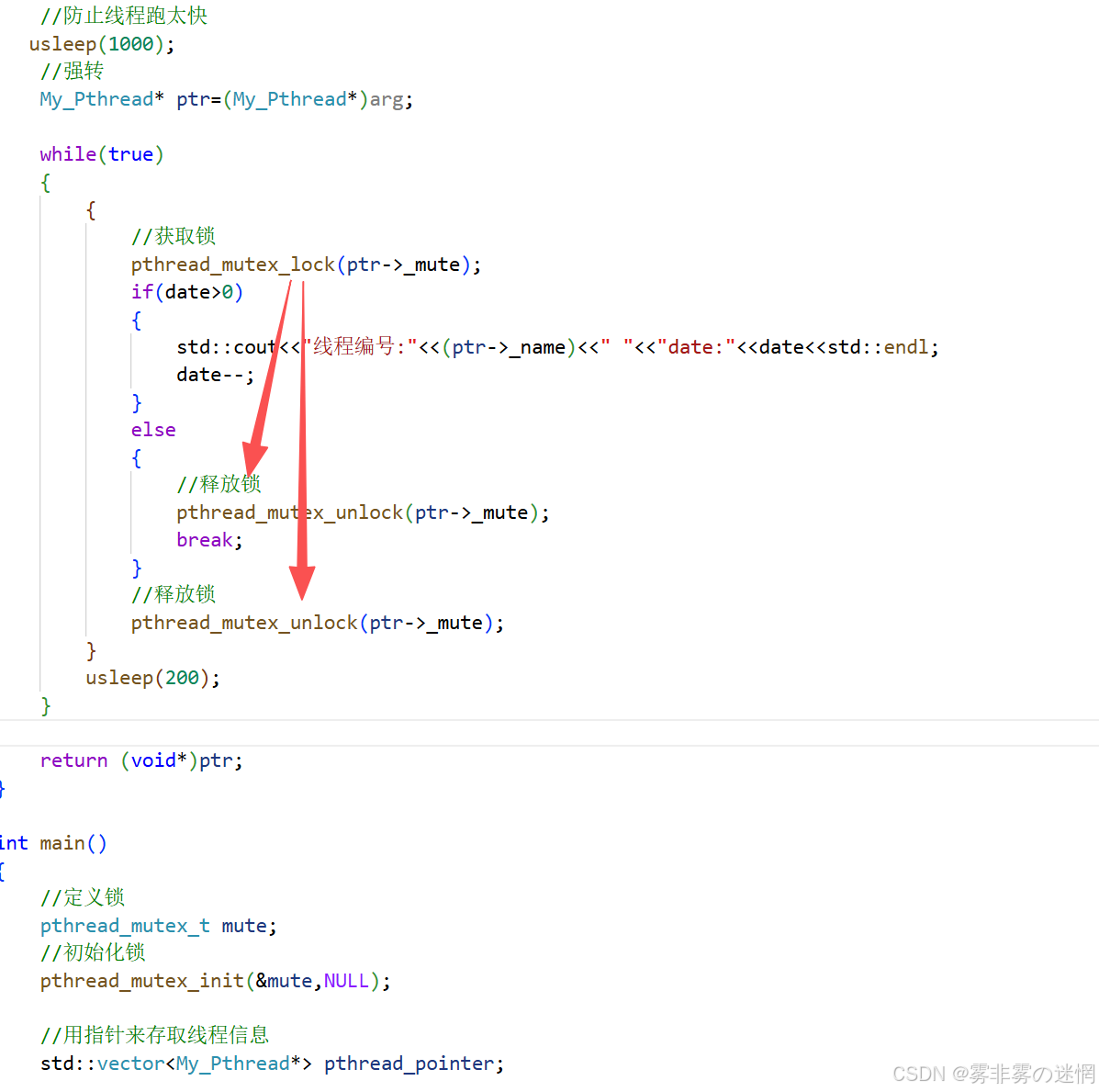
运行结果:

(5)自动释放进程资源(无需获取返回值)
原型:
cpp
#include <pthread.h>
int pthread_detach(pthread_t thread);参数:要自动释放资源的线程 ID
作用:让线程结束后自动回收资源
(6)释放互斥锁
原型:
cpp
pthread_mutex_destroy(互斥锁地址);【三】"死锁"
"死锁"我们简单了解即可,需要同时满足下面四个条件才是"死锁":
(1)互斥条件:一个资源每次只能被一个执行流使用
(2)请求与保持条件:一个执行流因请求资源而阻塞时,对已获取的资源保持不放
(3)不剥夺条件:一个执行流已获取的资源,在未使用之前,不能强行剥夺
(4)循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
【四】条件"锁"+互斥"锁"
什么是条件"锁"?尝尝用于需要"等待"条件的情况,需要以互斥"锁"为底层锁基础
(1)定义锁变量
原型:
cpp
pthread_cond_t cond 条件锁变量名参数:条件锁变量名
或者直接全局初始化一把锁,就可以直接使用:直接开始(3)和(4)
cpp
pthread_cond_t 条件锁变量名 = PTHREAD_COND_INITIALIZER例如:使用互斥"锁"+条件"锁"的初始化

(2)初始化锁
单独初始化:
cpp
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);参数:
**第一个参数:**条件锁变量的地址
**第二个参数:**属性选择,一般为NULL
(3)阻塞等待队列
原型:
cpp
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);参数:
**第一个参数:**条件变量指针
**第二个参数:**关联的互斥锁指针,调用前必须持有该锁
作用:使当前线程阻塞,等待条件变量被唤醒;
自动释放传入的互斥锁(因此前提需要该线程先持有锁),唤醒后自动重新获取互斥锁
例如:

(4)唤醒等待队列线程
原型:
cpp
int pthread_cond_signal(pthread_cond_t *cond);参数:条件锁的地址
作用:唤醒一个等待该条件变量的线程(通常是等待队列的第一个线程)
例如:

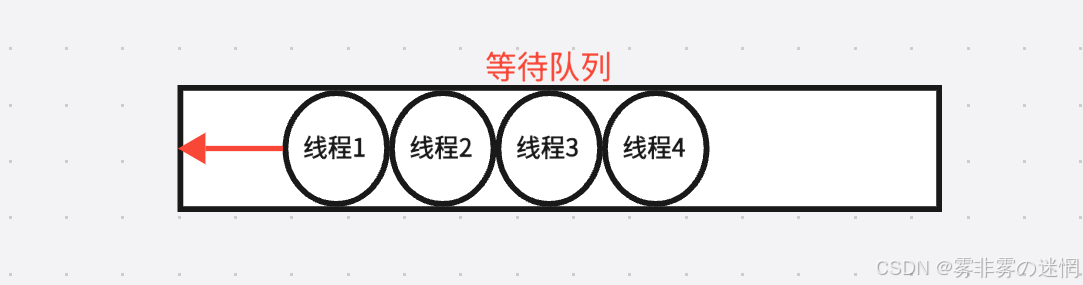
阻塞等待理解:
每个线程会按照顺序进入类似队列的结构中,待被唤醒,达到先进先出的效果,例如:
1<---2<---3依次进入等待队列,每次调用被唤醒一个线程,随即自动给改进程加互斥锁
(5)释放条件锁
原型:
cpp
pthread_cond_destroy(条件锁地址);【五】"生产消费"模型
(1)理论认识
假设当前存在:消费者、供应商(供货商)、超市三种关系组成
超市作为中介解决了"消费者"直接面向"供应商"完全不协调的问题:
消费者不定时的消费商品,供应商每次单个生产货物,超市作为存货地,来调节二者生产消费关系
超市:有一定大小的存储空间,商品数量不能超过临界值
消费者:随时取走"超市"的商品,保证每次有商品可被取走,不能出现并发"消费"
供应商:可根据"超市"的存储空间来不断供货,保证货物不超出存储空间,不能出现并发"供货"
(注意:也不能出现并发的"消费"和"供应",因为可能因为执行时差导致失败)

从线程角度来说:
"生成消费"模型是通过建立中间数据缓存区(阻塞队列)来实现对数据生成与处理的解耦
(解耦:降低对象之间的依赖关系,不至于一方崩了和它有关联的都崩了........)
(2)理论框架
"消费者"与"生产者"都是通过"锁"的控制来控制多线程并发操作的问题,这里以队列为中间存储区
既然不能并发"消费",不能并发"供应",不能并发"消费"和"供应",因此------>只有一个互斥"锁"
而"消费"和"供应"又是解耦的,所以------>存在两个条件"锁"
那么类的设计就出来了:
cpp
template<class T>
class Pthread_P_C
{
public:
Pthread_P_C()
{
//初始化互斥锁
pthread_mutex_init(&mute,NULL);
//初始化条件锁
pthread_cond_init(&cond_p,NULL);
pthread_cond_init(&cond_c,NULL);
}
~Pthread_P_C()
{
//释放互斥锁
pthread_mutex_destroy(&mute);
//释放条件锁
pthread_cond_destroy(&cond_p);
pthread_cond_destroy(&cond_c);
}
//生产
void push_back(const T& date)
{
}
//消费
void pop()
{
}
private:
//缓存
std::queue<T> _buffer;
//互斥锁
pthread_mutex_t mute;
//条件锁*2
pthread_cond_t cond_p;
pthread_cond_t cond_c;
};(3)生产实现
理论:每次生产会调用一次push_back(),因此存在两种情况:当然都是在互斥条件下执行
(1)如果缓冲区满了,那就阻塞等待无法生产,可以尝试给"消费"发信号:你赶紧来消费
(2)如果缓冲区没满,那就生产,然后告诉"消费":你可以继续"消费"了
cpp
//生产
void push_back(const T& date)
{
//互斥
pthread_mutex_lock(&mute);
//如果缓冲区满了
while(_buffer.size()>=MAX)
{
std::cout<<"你赶紧给我过来消费!"<<std::endl;
//给消费发信号
pthread_cond_signal(&cond_c);
////以防万一继续阻塞
pthread_cond_wait(&cond_p,&mute);
}
//说明可以生产
std::cout<<"生产成功:"<<date<<std::endl;
_buffer.push(date);
//继续消费
pthread_cond_signal(&cond_c);
//解互斥锁
pthread_mutex_unlock(&mute);
}(4)消费实现
理论:每次生产会调用一次pop(),因此存在两种情况:当然都是在互斥条件下执行
(1)如果缓冲区为空,说明无法消费,可以尝试告诉"消费":催促生产!
(2)如果缓冲区有数据,说明可以消费,然后告诉"生产":你可以继续"生产"了
cpp
//消费
void pop()
{
//互斥
pthread_mutex_lock(&mute);
//如果为空
while(_buffer.size()==0)
{
std::cout<<"你给我赶紧生产!"<<std::endl;
//给生产发信号
pthread_cond_signal(&cond_p);
//以防万一继续阻塞
pthread_cond_wait(&cond_c,&mute);
}
//说明可以消费
std::cout<<"我消费了:"<<_buffer.front()<<"...."<<std::endl;
_buffer.pop();
//继续生产
pthread_cond_signal(&cond_p);
//解互斥锁
pthread_mutex_unlock(&mute);
}(5)效果展示:
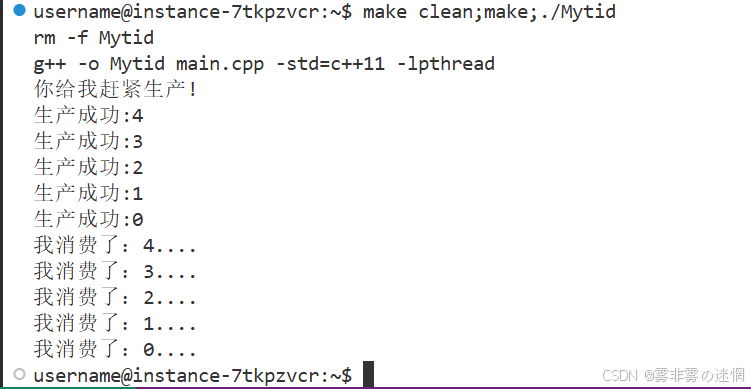
我们创建两个线程,传实例类的指针来调用生产消费模型,只需无脑调用即可:
cpp
#include"pthread_c_p.cpp"
//负责生产
void* Product(void* arg)
{
//线程结束自动释放资源
pthread_detach(pthread_self());
Pthread_P_C<int>* ptr=(Pthread_P_C<int>*)arg;
int count=P_C;
while(count--)
{
ptr->push_back(count);
}
return NULL;
}
//负责消费
void* Consume(void* arg)
{
//线程结束自动释放资源
pthread_detach(pthread_self());
Pthread_P_C<int>* ptr=(Pthread_P_C<int>*)arg;
int count=P_C;
while(count--)
{
ptr->pop();
}
return NULL;
}
int main()
{
Pthread_P_C<int> V;
Pthread_P_C<int>* ptr=&V;
//生产
pthread_t pd;
pthread_create(&pd,NULL,Product,ptr);
//消费
pthread_t cd;
pthread_create(&cd,NULL,Consume,ptr);
sleep(2);
return 0;
}效果展示:
两大隐藏点讲解:
第一点:效率问题
我们仔细看上面的"生产消费"的实现,不难发现如下图所示的现象:不管多少线程("消费、供应"),每次都只能有一方执行,那么另一方就只能闲着,何谈效率?
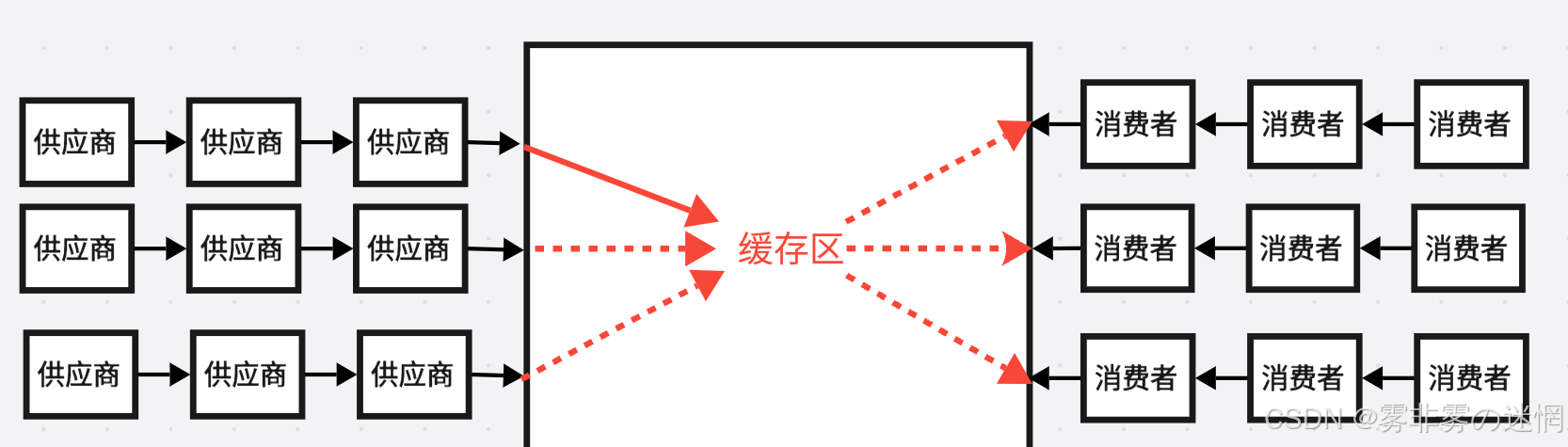
"生产消费"模型其实效率的体现不在这里,而在于左右两边对数据的处理工作,只要当前执行流正在"生产"或者"消费"数据,那么其它的所有执行流就可以去随便处理数据,如下图:

第二点:伪进程唤醒问题

明明每个线程每次进入 push 或者 pop 都是该线程单个执行,那么为什么这里用 while 而不是 if ?
用 if 只要它满足阻塞条件就进入阻塞队列,满足条件再被同一个锁唤醒即可,似乎没有BUG!
但是如果多个线程同时进入阻塞队列,此时pthread_cond_signal可能一次性唤醒多个线程,用 if 就会出现问题,而pthread_cond_signal并不保证每次只唤醒一个线程,这和内部有关!
