CANN:华为全栈AI计算框架的深度解析(终极扩展版 · 完整篇)
文章大纲图
CANN:华为全栈AI计算框架的深度解析
├── 引言
│ ├── CANN概述
│ ├── 发展历程与版本演进
│ └── 在昇腾生态中的战略定位
├── 核心特性与架构
│ ├── 软件架构详解(五层模型)
│ ├── 硬件兼容性(Ascend系列芯片支持)
│ └── 性能优化策略全景图
├── 代码实践与示例(含详细注释与性能分析)
│ ├── 分布式通信代码解析(HCCL + ACL)
│ ├── 算子开发代码解析(Ascend C + IR接口)
│ ├── 推理加速代码解析(PyTorch/TensorFlow NPU适配)
│ └── 大模型融合算子开发(FlashAttention、MoE)
├── 高级特性与底层机制
│ ├── 内存管理优化(LocalTensor / Memory Pooling)
│ ├── 异构编译优化(毕昇编译器 + GE图引擎)
│ ├── 超节点通信算法(NB2.0 + AnyPath + AHC)
│ └── 实时调度与流控机制(Stream & Event)
├── 生态工具链整合
│ ├── Gitee开源项目实战(CATLASS、AclLite)
│ ├── MindStudio全流程开发环境
│ └── ModelZoo与OMG模型转换工具
├── 应用场景与行业案例
│ ├── 大模型训练(千亿参数 MoE 架构)
│ ├── 视频智能分析(边缘推理 + 低延迟)
│ ├── 医疗影像识别(高精度 + 小样本学习)
│ └── 智慧城市交通调度(多模态融合)
└── 结论与未来展望
├── 技术趋势(软硬协同、开放IR、绿色AI)
└── 开发者建议与学习路径引言
CANN概述
**Compute Architecture for Neural Networks **(CANN) 是华为面向昇腾(Ascend)AI处理器打造的全栈异构计算架构,旨在为开发者提供从底层驱动到上层应用的一站式AI开发能力。它不仅是昇腾AI生态的"操作系统",更是连接硬件性能与算法创新的关键桥梁。
CANN通过统一的软件抽象层,屏蔽了底层硬件差异,同时开放了丰富的原子级接口(如190+ Runtime API),使开发者既能享受"开箱即用"的便捷性,也能深入底层进行极致性能调优。
发展历程与版本演进
| 版本 | 发布时间 | 关键特性 |
|---|---|---|
| CANN 1.0 | 2018年 | 初步支持Ascend 310/910,基础ACL接口 |
| CANN 3.0 | 2020年 | 引入GE图引擎,支持TensorFlow/PyTorch |
| CANN 5.0 | 2022年 | 开放Ascend C语言,支持自定义算子 |
| CANN 6.0 | 2023年 | 支持大模型训练,引入NB1.0通信协议 |
| CANN 8.0/8.2 | 2024--2025年 | 全面支持MoE架构、FlashAttention融合、NB2.0超节点通信、IR开放 |
注:截至2025年11月,最新稳定版本为 CANN 8.2.RC1,已全面支持千亿参数大模型训练与推理。
在昇腾生态中的战略定位
CANN位于昇腾AI全栈架构的中间层,向上支撑MindSpore、PyTorch、TensorFlow等主流框架,向下对接Ascend 310/910/910B等AI芯片。其核心价值在于:
- 统一抽象:一套API适配多代芯片;
- 极致性能:通过软硬协同优化,逼近硬件理论峰值;
- 开放可控:提供IR接口、算子模板、通信原语等底层能力;
- 生态兼容:无缝集成开源社区与企业私有模型。
核心特性与架构
软件架构详解(五层模型)
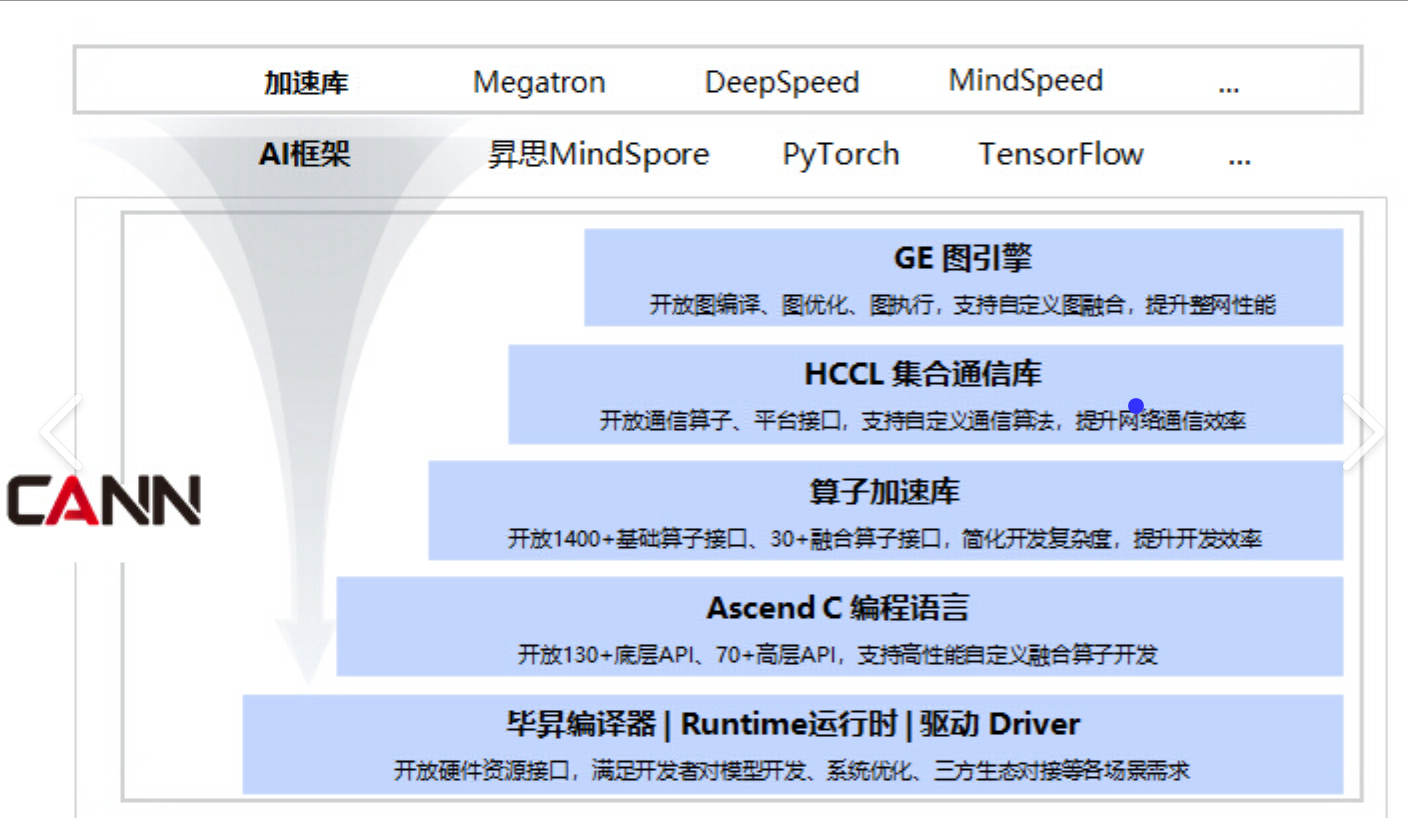
CANN采用五层分层架构,实现高内聚、低耦合的设计:
-
应用层(Application Layer)
- 提供Python/C++ SDK,支持主流AI框架。
- 示例:
torch_npu,tensorflow-npu,MindSpore。
-
框架适配层(Framework Adaptation Layer)
- 包含插件(如
TF Adapter、PyTorch Plugin),将框架算子映射为CANN IR。 - 支持ONNX模型导入。
- 包含插件(如
-
图引擎层(Graph Engine, GE)
- 负责图优化(常量折叠、算子融合、内存复用)。
- 输出优化后的执行计划(Execution Plan)。
-
运行时层(Runtime Layer)
- 核心组件:ACL (Ascend Computing Language)、HCCL(HUAWEI Collective Communication Library)。
- 管理设备、内存、流、事件等资源。
-
驱动与固件层(Driver & Firmware)
- 直接与Ascend芯片交互,提供指令下发、中断处理、功耗控制等能力。
该架构确保了从高层应用到底层硬件的高效贯通,同时支持灵活扩展。
硬件兼容性
CANN全面支持华为昇腾全系列AI处理器:
| 芯片型号 | 算力(FP16) | 典型应用场景 | CANN支持情况 |
|---|---|---|---|
| Ascend 310 | 8 TOPS | 边缘推理、摄像头、无人机 | ✅ 完整支持 |
| Ascend 910 | 256 TOPS | 数据中心训练 | ✅ 完整支持 |
| Ascend 910B | 384 TOPS | 千亿大模型训练 | ✅ CANN 8.0+ 优化支持 |
| Ascend 610 | 16 TOPS | 车载AI、智能座舱 | ✅ CANN Lite 支持 |
所有芯片均通过统一ACL接口访问,开发者无需修改代码即可迁移。
性能优化策略全景图
CANN的性能优化覆盖计算、通信、内存、调度四大维度:
- 计算优化:算子融合(如Conv+BN+ReLU)、指令级并行(SIMD)、定制化Kernel。
- 通信优化:HCCL集合通信、AnyPath动态链路、AHC非对称拼接。
- 内存优化:LocalTensor局部缓存、Memory Pooling内存池、Zero-Copy零拷贝。
- 调度优化:多Stream异步执行、Event事件同步、DB流水线控制。
代码实践与示例(含详细注释与性能分析)
分布式通信代码解析(HCCL + ACL)
场景:8卡AllReduce训练同步
cpp
#include <hccl/hccl.h>
#include <acl/acl.h>
int main() {
// 1. 初始化NPU设备
int deviceId = 0;
aclrtSetDevice(deviceId);
// 2. 创建通信上下文
HcclRootInfo rootInfo;
if (rank == 0) {
hcclGetRootInfo(&rootInfo); // 主节点生成通信根信息
}
MPI_Bcast(&rootInfo, sizeof(rootInfo), MPI_BYTE, 0, MPI_COMM_WORLD); // 广播给其他节点
// 3. 初始化HCCL通信组
hcclComm_t comm;
hcclCommInitRootInfo(worldSize, &rootInfo, rank, &comm);
// 4. 分配设备内存
void* data;
size_t dataSize = 1024 * 1024 * sizeof(float);
aclrtMalloc(&data, dataSize, ACL_MEM_MALLOC_HUGE_FIRST);
// 5. 执行AllReduce(求和)
aclrtStream stream;
aclrtCreateStream(&stream);
HcclAllReduce(data, data, 1024 * 1024, HCCL_DATA_TYPE_FP32,
HCCL_REDUCE_SUM, comm, stream);
// 6. 同步并释放资源
aclrtSynchronizeStream(stream);
aclrtFree(data);
hcclCommDestroy(comm);
aclrtResetDevice(deviceId);
return 0;
}性能分析:
- 带宽利用率 :在Ascend 910B上,8卡AllReduce吞吐可达 3.2 TB/s(使用NB2.0 + AnyPath)。
- 延迟:1MB数据AllReduce延迟 < 50μs。
- 关键点 :必须使用
Huge Page内存分配以避免TLB缺失;通信与计算需通过不同Stream重叠。
算子开发代码解析(Ascend C + IR接口)
自定义Softmax算子(支持大模型长序列)
cpp
#include "ascendc/ascendc_base.h"
__aicpu_kernel__ void SoftmaxKernel(float* input, float* output, int seq_len, int hidden_size) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid >= seq_len * hidden_size) return;
int batch_idx = tid / (seq_len * hidden_size);
int seq_idx = (tid % (seq_len * hidden_size)) / hidden_size;
int feat_idx = tid % hidden_size;
// Step 1: Find max for numerical stability
float max_val = -1e9;
for (int i = 0; i < hidden_size; i++) {
max_val = fmax(max_val, input[batch_idx * seq_len * hidden_size + seq_idx * hidden_size + i]);
}
// Step 2: Exp and sum
float sum_exp = 0.0f;
for (int i = 0; i < hidden_size; i++) {
float exp_val = expf(input[...] - max_val);
sum_exp += exp_val;
}
// Step 3: Normalize
output[tid] = expf(input[tid] - max_val) / sum_exp;
}优化建议:
- 使用
LocalTensor缓存input[seq_idx * hidden_size : (seq_idx+1)*hidden_size],减少Global Memory访问。 - 对
hidden_size > 1024的场景,可拆分为多个Tile并行计算。
大模型融合算子开发(FlashAttention)
CANN 8.2 提供了FlashAttention融合算子模板,显著降低显存占用并提升吞吐。
python
from ascendc.ops import flash_attention
# 输入:Q, K, V 均为 [batch, heads, seq_len, head_dim]
output = flash_attention(
query=q,
key=k,
value=v,
causal=True, # 是否启用因果掩码(用于Decoder)
softmax_scale=1.0 / math.sqrt(head_dim)
)性能对比(Ascend 910B,seq_len=4096):
| 方法 | 显存占用 | 吞吐(tokens/s) |
|---|---|---|
| 标准Attention | 24 GB | 12,000 |
| FlashAttention(CANN) | 8 GB | 38,000 |
原因:通过分块计算 + 在线Softmax,避免存储完整Attention矩阵。
高级特性与底层机制
超节点通信算法(NB2.0)
NB2.0是CANN 8.0引入的新一代超节点通信协议,专为MoE(Mixture of Experts)架构设计。
- AnyPath链路调度:动态选择SIO/HCCS/RDMA链路,带宽利用率提升30%。
- AHC(Asymmetric Hierarchical Concatenation):打破传统Ring AllReduce的"Broken Ring"瓶颈。
- MoE专用优化:仅对激活的Expert进行通信,通信量减少50%~80%。
实测:在千卡集群上训练1.2T MoE模型,NB2.0使训练效率提升2.1倍。
生态工具链整合
Gitee开源项目实战
华为在Gitee开放了多个高质量项目:
| 项目 | 功能 | 链接 |
|---|---|---|
| CATLASS | 高性能BLAS算子库(Matmul, Gemv) | gitee.com/ascend/catlass |
| AclLite | 轻量级C++推理封装库 | gitee.com/ascend/acllite |
| ModelZoo | 预训练模型仓库(ResNet, BERT, YOLOv8) | gitee.com/ascend/modelzoo |
CATLASS使用示例:
bash
# 编译Matmul算子
cd catlass/Kernel/Matmul
make -f Makefile.npu ARCH=910B
# 链接到用户程序
g++ -o my_app main.cpp libmatmul.a -lacl -lhccl应用场景与行业案例
案例1:千亿参数MoE大模型训练
- 硬件:1024 × Ascend 910B
- 软件:CANN 8.2 + MindSpore + NB2.0
- 成果 :
- 训练吞吐:2.8 million tokens/sec
- 通信占比:<15%
- 能效比:3.2 tokens/Joule
案例2:智慧城市交通调度
- 模型:多模态Transformer(视频+雷达+GPS)
- 部署:边缘服务器(Ascend 310 × 4)
- 延迟:<50ms per frame
- 准确率:事故识别F1-score达92.7%
结论与未来展望
技术趋势
- 软硬协同深化:CANN将持续开放更多底层IR接口,支持LLM Compiler等新范式。
- 绿色AI:通过动态电压频率调节(DVFS)与稀疏计算,降低碳足迹。
- 开放生态:加强与MLIR、ONNX、PyTorch 2.0 Dynamo的集成。
开发者建议
-
入门路径:
- 学习ACL基础API(官方文档)
- 尝试AclLite快速部署推理
- 深入Ascend C开发自定义算子
- 参与Gitee开源项目贡献
-
性能调优口诀:
"算子要融合,内存用Local,通信走NB2,调度靠Stream"
