目录
[1、 通用协议的局限性](#1、 通用协议的局限性)
[1. 性能开销大](#1. 性能开销大)
[2. 功能冗余或缺失](#2. 功能冗余或缺失)
[3. 通信模式不匹配](#3. 通信模式不匹配)
[2、 自定义协议的优势](#2、 自定义协议的优势)
[1. 极致的性能与效率](#1. 极致的性能与效率)
[2. 高度的定制化与业务契合](#2. 高度的定制化与业务契合)
[3. 低成本与低资源消耗](#3. 低成本与低资源消耗)
[4. 增强的安全性与可控性](#4. 增强的安全性与可控性)
[3、 常见的自定义协议应用场景](#3、 常见的自定义协议应用场景)
[4、 自定义协议的代价](#4、 自定义协议的代价)
[二、关于流式数据的处理(基于 jsoncpp 库 + 自定义协议)](#二、关于流式数据的处理(基于 jsoncpp 库 + 自定义协议))
[1. 类定义与成员变量](#1. 类定义与成员变量)
[2. 编码(发送端)](#2. 编码(发送端))
[3. 解码(接收端 - 核心逻辑)](#3. 解码(接收端 - 核心逻辑))
[1. 如何保证每次读取就能读完请求缓冲区的所有内容?](#1. 如何保证每次读取就能读完请求缓冲区的所有内容?)
[2. 如何保证读到的是一个完整的请求?](#2. 如何保证读到的是一个完整的请求?)
[3. 如何保证正确处理TCP缓冲区中的数据?](#3. 如何保证正确处理TCP缓冲区中的数据?)
[1. 快递包裹](#1. 快递包裹)
[2. 书信](#2. 书信)
[3. 火车运输](#3. 火车运输)
四、重点补充探讨:为什么应用层(业务层)、表示层(序列化反序列化)、协议层(自定义协议)、传输层(TCP/UDP方式连接)不能写到操作系统内核?
[总结:内核空间 vs. 用户空间的设计哲学](#总结:内核空间 vs. 用户空间的设计哲学)
一、为什么需要自定义协议?
1、 通用协议的局限性
**首先,我们要明白,像 HTTP、FTP、SMTP 这些通用协议非常成功,它们解决了绝大多数通用网络通信问题。但"通用"也意味着它们可能不是所有场景下的"最优解"。**它们的局限性主要体现在:
1. 性能开销大
-
头部冗余: 像 HTTP/1.x 这样的文本协议,每个请求/响应都带有完整的、可读的头部信息(如 Cookie、User-Agent),这在频繁通信的微服务或游戏场景中会产生大量冗余数据,占用带宽。
-
建立连接慢: HTTPS 的 TLS 握手、TCP 的三次握手,在需要极低延迟的场景(如金融交易、实时游戏)中,这些毫秒级的延迟都是不可接受的。
2. 功能冗余或缺失
-
冗余功能: 一个简单的物联网传感器只需要上报温度和湿度,它不需要 HTTP 协议中复杂的缓存控制、内容协商等机制。这些功能反而增加了实现的复杂度和资源消耗。
-
缺失功能: 通用协议没有为特定业务设计专用的指令。例如,在一个自定义的远程控制协议中,你可以定义一个字节的指令:
0x01代表"开灯",0x02代表"关灯"。而用 HTTP 实现,你需要构造一个完整的 HTTP 请求POST /api/device/light {"action": "on"},这显然臃肿得多。
3. 通信模式不匹配
-
通用协议如 HTTP 是典型的"请求-响应"模式。但在某些场景下,我们需要的是:
-
服务端推送: 如股票行情、实时聊天,服务端需要主动向客户端推送数据。
-
双向通信: 如视频会议、在线游戏,双方都需要随时向对方发送数据。
-
-
虽然 HTTP/2、WebSocket 等技术弥补了这些不足,但它们本身也是建立在通用协议之上的,有时不如在传输层之上直接设计一个原生支持双向通信的协议来得高效和直接。
2、 自定义协议的优势
为了解决上述通用协议的局限性,自定义协议应运而生,它具有以下核心优势:
1. 极致的性能与效率
-
精简的报文结构: 使用二进制格式,而不是文本格式。一个字节可以代表多种含义,极大地减少了数据包大小。
-
通用协议(HTTP):
POST /api/command HTTP/1.1\r\nHost: example.com\r\nContent-Type: application/json\r\n\r\n{"cmd": 1, "data": "hello"} -
自定义协议:
0x01 0x05 0x68 0x65 0x6c 0x6c 0x6f(假设0x01是命令,0x05是数据长度,后面是 "hello" 的 ASCII 码)
-
-
减少网络往返: 设计上尽可能在一个往返中完成更多操作,减少握手和确认次数。
2. 高度的定制化与业务契合
-
协议的设计完全围绕业务逻辑展开。指令、字段、状态码都可以根据业务需求来定义,使得代码逻辑更清晰,数据处理更直接。
-
示例: 一个智能家居协议可以直接定义
0xA1为"查询客厅温度",0xB2为"设置卧室灯光为蓝色",非常直观。
3. 低成本与低资源消耗
- 对于计算能力弱、内存小、电量有限的嵌入式设备或物联网设备,解析复杂的 HTTP 报文是沉重的负担。一个精简的自定义协议可以大大降低对硬件的要求,延长设备续航。
4. 增强的安全性与可控性
-
虽然"安全通过 obscurity( obscurity 隐匿性)"不是好主意,但一个不公开的自定义协议确实能提高攻击门槛。
-
更重要的是,你可以完全控制协议的安全机制,集成自定义的加密、认证和授权流程,而不必受制于通用协议标准可能存在的漏洞或限制。
3、 常见的自定义协议应用场景
-
物联网: MQTT 本身就是一个为物联网设计的轻量级消息协议(它也是一种"自定义"协议,后来成为了开放标准)。很多厂商还会在 MQTT 之上或直接使用更底层的自定义协议与设备通信。
-
网络游戏: 对延迟和实时性要求极高。游戏客户端和服务器之间通常使用自定义的 UDP/TCP 协议来同步玩家位置、状态和动作,以保证流畅体验。
-
分布式系统与微服务: 大型互联网公司内部,成千上万的微服务之间需要高效通信。它们通常会使用像 gRPC(基于 HTTP/2)或自研的二进制 RPC 协议,这些都可以看作是一种"自定义"或"准标准"协议,以实现高效的远程过程调用。
-
即时通讯: QQ、微信等早期都使用自定义协议,以实现登录、消息推送、文件传输等复杂功能,并保证效率和安全性。
-
区块链: 比特币的 P2P 网络协议、以太坊的 DevP2P 等都是典型的自定义协议,用于节点间的数据同步和交易广播。
-
私有网络设备: 路由器、交换机等网络设备的管理协议,很多都是厂商自定义的。
4、 自定义协议的代价
当然,自定义协议并非银弹,它也有显著的代价:
-
开发与维护成本高: 你需要设计、实现、测试、调试整个协议栈,这需要深厚的网络知识。
-
可调试性差: 二进制协议不像 HTTP 那样可以直接用眼睛看,需要借助专门的抓包和解析工具(如 Wireshark 插件)才能调试。
-
兼容性与扩展性挑战: 协议一旦设计完成,后续修改和版本升级需要谨慎处理,否则会导致兼容性问题。而 HTTP 等标准协议则无需担心此类问题。
-
缺乏生态系统支持: 没有现成的浏览器、代理、缓存等中间件支持,所有东西都需要自己实现。
总结
自定义协议是特定领域对效率、功能和成本进行深度优化的产物。
-
当你的应用场景是通用的、对性能不敏感的 Web 服务 时,HTTP/RESTful API 是你的最佳选择,生态成熟,开发快捷。
-
当你的应用场景是内部微服务、物联网、游戏、IM 等对性能、实时性、资源消耗有极致要求 的领域时,考虑自定义协议 或基于自定义协议思想的 gRPC、Thrift 等框架,就变得非常必要。
一言以蔽之:需要自定义协议,是因为在特定的战场上,通用的武器虽然好用,但无法赢得战争。你需要为自己量身打造一把更锋利、更称手的"武器"。
二、关于流式数据的处理(基于 jsoncpp 库 + 自定义协议)
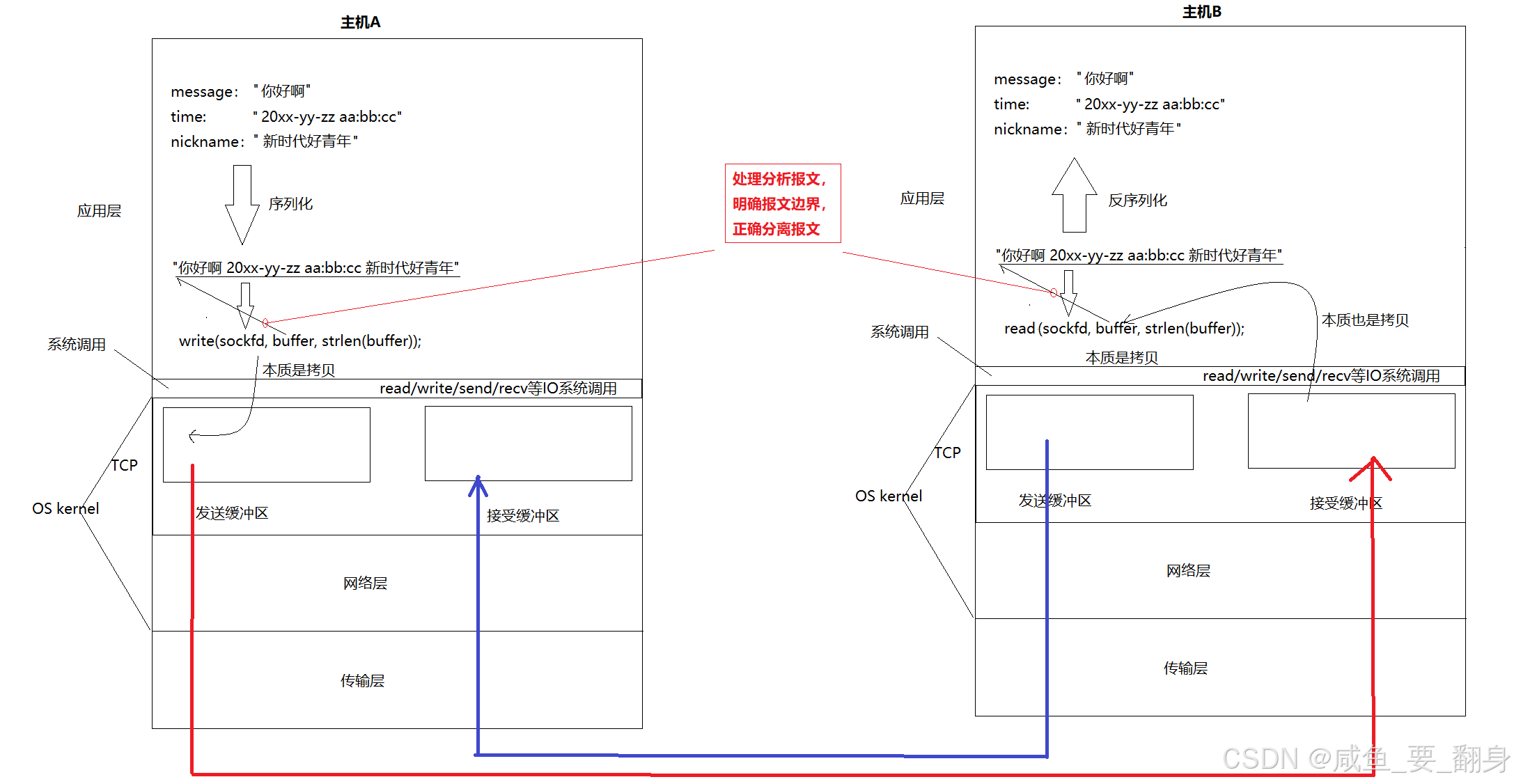
在处理网络通信时,消息边界 是自定义协议设计的核心挑战。
思考下面的三个问题:
-
如何确保每次读取能完整获取请求缓冲区的所有内容?
-
如何判断读取的数据是否构成一个完整的请求?
-
在处理TCP缓冲区数据时,如何确保请求被正确处理?
1、核心问题:TCP是字节流,没有消息边界
TCP协议只保证字节流的可靠传输,但不保证你一次recv调用得到的就是对方一次send发送的数据。对方发送的两个JSON字符串可能在你的一次接收中被粘在一起,也可能一个大的JSON字符串被拆分成多个TCP包到达。
三个问题本质上都是在问:如何从无边界的数据流中,正确地分离出一个个完整的JSON消息?
2、解决方案:设计一个带消息长度头的自定义协议

最通用、最可靠的方法是 "长度头 + 消息体" 的格式。每个数据包由两部分组成:
-
消息头: 一个固定长度的字段(通常是4字节整数),用来表示后面消息体的准确长度。
-
消息体: 实际的JSON字符串数据。
格式: [4字节消息长度][JSON字符串]
例如,JSON字符串 {"action": "ping"} 会被编码为:0x0000000E{"action": "ping"} (0x0E = 14,是后面14个字符的长度)
3、基于jsoncpp的实现详解
我们将构建一个简单的 JsonProtocol 类来处理流式数据。也可以不看这个例子,翻回去看这篇文章的这个简单的例子(基于C++多进程架构的TCP网络计算器服务设计与实现(引入序列化与反序列化、自定义协议)-CSDN博客)
cpp
#pragma once
#include "Socket.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <jsoncpp/json/json.h>
#include <functional>
// 实现一个自定义的网络版本的计算器
using namespace SocketModule;
// 约定好各个字段的含义,本质就是约定好协议!
// client -> server
// 如何要做序列化和反序列化:
// 1. 我们自己写(怎么做) ---> 往往不具备很好的扩展性
// 2. 使用现成的方案(这个是我们要写的) ---> json -> jsoncpp
// content_len jsonstring
// 50\r\n协议号\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n
// 50
// {"x": 10, "y" : 20, "oper" : '+'}
class Request
{
public:
Request()
{
}
Request(int x, int y, char oper) : _x(x), _y(y), _oper(oper)
{
}
std::string Serialize()
{
// _x = 10 _y = 20, _oper = '+'
// "10" "20" '+' : 用空格作为分隔符
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["oper"] = _oper; // _oper是char,也是整数,阿斯克码值
Json::FastWriter writer;
std::string s = writer.write(root);
return s;
}
// {"x": 10, "y" : 20, "oper" : '+'}
bool Deserialize(std::string &in)
{
// "10" "20" '+' -> 以空格作为分隔符 -> 10 20 '+'
Json::Value root;
Json::Reader reader;
bool ok = reader.parse(in, root);
if (ok)
{
_x = root["x"].asInt();
_y = root["y"].asInt();
_oper = root["oper"].asInt(); //?
}
return ok;
}
~Request() {}
int X() { return _x; }
int Y() { return _y; }
char Oper() { return _oper; }
private:
int _x;
int _y;
char _oper; // + - * / % -> _x _oper _y -> 10 + 20
};
// server -> client
class Response
{
public:
Response() {}
Response(int result, int code) : _result(result), _code(code)
{
}
std::string Serialize()
{
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter writer;
return writer.write(root);
}
bool Deserialize(std::string &in)
{
Json::Value root;
Json::Reader reader;
bool ok = reader.parse(in, root);
if (ok)
{
_result = root["result"].asInt();
_code = root["code"].asInt();
}
return ok;
}
~Response() {}
void SetResult(int res)
{
_result = res;
}
void SetCode(int code)
{
_code = code;
}
void ShowResult()
{
std::cout << "计算结果是: " << _result << "[" << _code << "]" << std::endl;
}
private:
int _result; // 运算结果,无法区分清楚应答是计算结果,还是异常值
int _code; // 0:sucess, 1,2,3,4->不同的运算异常的情况, 约定!!!!
};
const std::string sep = "\r\n";
using func_t = std::function<Response(Request &req)>;
// 协议(基于TCP的)需要解决两个问题:
// 1. request和response必须得有序列化和反序列化功能
// 2. 你必须保证,读取的时候,读到完整的请求(TCP, UDP不用考虑)
class Protocol
{
public:
Protocol()
{
}
Protocol(func_t func) : _func(func)
{
}
std::string Encode(const std::string &jsonstr)
{
// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n
std::string len = std::to_string(jsonstr.size());
return len + sep + jsonstr + sep; // 应用层封装报头
}
// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n
// 5
// 50
// 50\r
// 50\r\n
// 50\r\n{"x": 10, "
// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n
// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n50\r\n{"x": 10, "y" : 20, "ope
//.....
// packge故意是&
// 1. 判断报文完整性
// 2. 如果包含至少一个完整请求,提取他, 并从移除它,方便处理下一个
bool Decode(std::string &buffer, std::string *package)
{
ssize_t pos = buffer.find(sep);
if (pos == std::string::npos)
return false; // 让调用方继续从内核中读取数据
std::string package_len_str = buffer.substr(0, pos);
int package_len_int = std::stoi(package_len_str);
// buffer 一定有长度,但是一定有完整的报文吗?
int target_len = package_len_str.size() + package_len_int + 2 * sep.size();
if (buffer.size() < target_len)
return false;
// buffer一定至少有一个完整的报文!
*package = buffer.substr(pos + sep.size(), package_len_int);
buffer.erase(0, target_len);
return true;
}
void GetRequest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
// 读取
std::string buffer_queue;
while (true)
{
int n = sock->Recv(&buffer_queue);
if (n > 0)
{
std::cout << "-----------request_buffer--------------" << std::endl;
std::cout << buffer_queue << std::endl;
std::cout << "------------------------------------" << std::endl;
std::string json_package;
// 1. 解析报文,提取完整的json请求,如果不完整,就让服务器继续读取
while (Decode(buffer_queue, &json_package))
{
// 我敢100%保证,我一定拿到了一个完整的报文
// {"x": 10, "y" : 20, "oper" : '+'} -> 你能处理吗?
// 2. 请求json串,反序列化
// std::cout << "-----------request_json--------------" << std::endl;
// std::cout << json_package << std::endl;
// std::cout << "------------------------------------" << std::endl;
// std::cout << "-----------request_buffer--------------" << std::endl;
// std::cout << buffer_queue << std::endl;
// std::cout << "------------------------------------" << std::endl;
LOG(LogLevel::DEBUG) << client.StringAddr() << " 请求: " << json_package;
Request req;
bool ok = req.Deserialize(json_package);
if (!ok)
continue;
// 3. 我一定得到了一个内部属性已经被设置了的req了.
// 通过req->resp, 不就是要完成计算功能嘛!!业务
Response resp = _func(req);
// 4. 序列化
std::string json_str = resp.Serialize();
// 5. 添加自定义长度
std::string send_str = Encode(json_str); // 携带长度的应答报文了"len\r\n{result:XXX, code:XX}\r\n"
// 6. 直接发送
sock->Send(send_str);
}
}
else if (n == 0)
{
LOG(LogLevel::INFO) << "client:" << client.StringAddr() << "Quit!";
break;
}
else
{
LOG(LogLevel::WARNING) << "client:" << client.StringAddr() << ", recv error";
break;
}
}
}
bool GetResponse(std::shared_ptr<Socket> &client, std::string &resp_buff, Response *resp)
{
// 面向字节流,你怎么保证,你的client读到的 一个网络字符串,就一定是一个完整的请求呢??
while (true)
{
int n = client->Recv(&resp_buff);
if (n > 0)
{
// std::cout << "-----------resp_buffer--------------" << std::endl;
// std::cout << resp_buff << std::endl;
// std::cout << "------------------------------------" << std::endl;
// 成功
std::string json_package;
// 1. 解析报文,提取完整的json请求,如果不完整,就让服务器继续读取
// bool ret = Decode(resp_buff, &json_package);
// if (!ret)
// continue;
while (Decode(resp_buff, &json_package))
{
// std::cout << "----------response json---------------" << std::endl;
// std::cout << json_package << std::endl;
// std::cout << "--------------------------------------" << std::endl;
// std::cout << "-----------resp_buffer--------------" << std::endl;
// std::cout << resp_buff << std::endl;
// std::cout << "------------------------------------" << std::endl;
// 2. 走到这里,我能保证,我一定拿到了一个完整的应答json报文
// 2. 反序列化
resp->Deserialize(json_package);
}
return true;
}
else if (n == 0)
{
std::cout << "server quit " << std::endl;
return false;
}
else
{
std::cout << "recv error" << std::endl;
return false;
}
}
}
std::string BuildRequestString(int x, int y, char oper)
{
// 1. 构建一个完整的请求
Request req(x, y, oper);
// 2. 序列化
std::string json_req = req.Serialize();
// // 2.1 debug
// std::cout << "------------json_req string------------" << std::endl;
// std::cout << json_req << std::endl;
// std::cout << "---------------------------------------" << std::endl;
// 3. 添加长度报头
return Encode(json_req);
}
~Protocol()
{
}
private:
// 因为我们用的是多进程
// Request _req;
// Response _resp;
func_t _func;
};1. 类定义与成员变量
cpp
#include <json/json.h>
#include <string>
#include <vector>
#include <sys/socket.h>
#include <errno.h>
class JsonProtocol {
public:
JsonProtocol();
// 将Json::Value序列化为我们自定义协议的字符串
std::string encode(const Json::Value& value);
// 从接收缓冲区中尝试提取一个完整的JSON消息
// 返回值:成功提取返回true,否则返回false
bool tryDecode(std::vector<char>& receiveBuffer);
// 获取最近成功解析的消息
Json::Value getMessage();
private:
// 缓冲区状态
enum ParseStatus {
READING_HEADER,
READING_BODY
};
ParseStatus m_status;
// 我们期望的消息体长度
uint32_t m_bodyLength;
// 用于累积一个完整消息的缓冲区
std::vector<char> m_messageBuffer;
// 存储解析好的JSON对象
Json::Value m_currentMessage;
// JSON解析器
Json::CharReaderBuilder m_readerBuilder;
std::unique_ptr<Json::CharReader> m_reader;
// 辅助函数:从网络字节序转换到主机字节序
uint32_t networkToHostLong(uint32_t networkLong);
};2. 编码(发送端)
cpp
std::string JsonProtocol::encode(const Json::Value& value) {
// 1. 将Json::Value序列化为字符串
Json::StreamWriterBuilder writerBuilder;
std::string jsonStr = Json::writeString(writerBuilder, value);
// 2. 获取消息体长度,并转换为网络字节序(大端)
uint32_t bodyLen = static_cast<uint32_t>(jsonStr.size());
uint32_t netBodyLen = htonl(bodyLen); // 解决不同机器字节序差异
// 3. 构造最终数据包
std::string packet;
packet.reserve(sizeof(netBodyLen) + bodyLen); // 预分配空间,提高效率
// 先放入4字节的消息头(长度)
packet.append(reinterpret_cast<const char*>(&netBodyLen), sizeof(netBodyLen));
// 再放入消息体(JSON字符串)
packet.append(jsonStr);
return packet;
}3. 解码(接收端 - 核心逻辑)
这是回答问题的关键部分。我们使用一个状态机来处理。
cpp
JsonProtocol::JsonProtocol()
: m_status(READING_HEADER), m_bodyLength(0) {
m_reader = std::unique_ptr<Json::CharReader>(m_readerBuilder.newCharReader());
}
bool JsonProtocol::tryDecode(std::vector<char>& receiveBuffer) {
// 使用一个指针来遍历接收缓冲区,表示已处理到的位置
size_t handledPos = 0;
while (handledPos < receiveBuffer.size()) {
if (m_status == READING_HEADER) {
// 状态1:正在读取消息头(4字节长度)
if (receiveBuffer.size() - handledPos >= sizeof(uint32_t)) {
// 缓冲区有足够的数据读取消息头
// 拷贝出4字节数据
uint32_t netBodyLen;
std::memcpy(&netBodyLen, &receiveBuffer[handledPos], sizeof(uint32_t));
m_bodyLength = networkToHostLong(netBodyLen); // 转换为主机字节序
handledPos += sizeof(uint32_t); // 移动已处理位置
m_status = READING_BODY; // 状态切换为读取消息体
// 预分配消息体缓冲区
m_messageBuffer.clear();
m_messageBuffer.reserve(m_bodyLength);
} else {
// 数据不够一个消息头,等待下次接收
break;
}
}
if (m_status == READING_BODY) {
// 状态2:正在读取消息体
// 计算还需要多少字节
size_t remaining = m_bodyLength - m_messageBuffer.size();
// 计算当前缓冲区中可用的字节数
size_t available = receiveBuffer.size() - handledPos;
// 本次能读取的字节数是两者的最小值
size_t toRead = std::min(remaining, available);
if (toRead > 0) {
// 将数据从接收缓冲区拷贝到消息缓冲区
m_messageBuffer.insert(m_messageBuffer.end(),
receiveBuffer.begin() + handledPos,
receiveBuffer.begin() + handledPos + toRead);
handledPos += toRead;
}
// 检查是否已经读取了完整的消息体
if (m_messageBuffer.size() == m_bodyLength) {
// 解析JSON
std::string jsonStr(m_messageBuffer.begin(), m_messageBuffer.end());
JSONCPP_STRING errs;
bool parsingSuccessful = m_reader->parse(jsonStr.c_str(),
jsonStr.c_str() + jsonStr.size(),
&m_currentMessage,
&errs);
// 重置状态机,准备处理下一条消息
m_status = READING_HEADER;
m_bodyLength = 0;
m_messageBuffer.clear();
if (parsingSuccessful) {
// !!!关键步骤:从接收缓冲区中移除已处理的数据
receiveBuffer.erase(receiveBuffer.begin(),
receiveBuffer.begin() + handledPos);
return true; // 成功解析一条完整消息
} else {
// JSON解析错误,协议错误,可以重置连接或抛出异常
receiveBuffer.clear(); // 清空缓冲区,防止错误扩散
throw std::runtime_error("Invalid JSON format: " + errs);
}
} else {
// 消息体还没读完,跳出循环,等待更多数据
break;
}
}
}
// !!!关键步骤:无论是否解析出完整消息,都要移除已处理的数据
// 因为handledPos之前的头部数据已经被消费了
if (handledPos > 0) {
receiveBuffer.erase(receiveBuffer.begin(),
receiveBuffer.begin() + handledPos);
}
return false; // 本次没有解析出完整的新消息
}
Json::Value JsonProtocol::getMessage() {
return std::move(m_currentMessage); // 使用move转移所有权,清空m_currentMessage
}
uint32_t JsonProtocol::networkToHostLong(uint32_t networkLong) {
// 简单的字节序转换,htonl的逆操作
return ntohl(networkLong);
}4、回答核心问题
1. 如何保证每次读取就能读完请求缓冲区的所有内容?
我们不需要一次读完。 这正是我们设计的关键。
-
receiveBuffer是一个应用层的缓冲区 ,它累积了从TCP socketrecv到的所有数据。 -
tryDecode函数的目标是从这个累积的缓冲区中尝试提取一个完整的消息。 -
它使用
handledPos来跟踪本次调用中已经处理了多少数据。 -
在函数结束时,通过
receiveBuffer.erase(...)移除所有已经被处理过的数据 (无论是已经被消费的头部,还是已经拷贝到m_messageBuffer的部分消息体)。 -
这样,每次调用
tryDecode后,receiveBuffer中只剩下未处理的、不完整的字节流,等待下一次recv的补充。 这保证了缓冲区不会被旧数据撑爆,并且能正确处理后续到达的数据。
2. 如何保证读到的是一个完整的请求?
通过状态机和长度头来保证。
-
状态机: 代码逻辑被分为两个状态
READING_HEADER和READING_BODY。只有在成功读取了完整的4字节头部后,才知道需要读取的消息体长度m_bodyLength。 -
长度校验: 在
READING_BODY状态,我们持续读取数据,直到m_messageBuffer.size() == m_bodyLength。只有达到这个条件,我们才认为得到了一个完整的JSON消息,并尝试解析。 -
如果缓冲区数据不够,
tryDecode会返回false,然后你的网络循环应该继续recv数据,并再次调用tryDecode。这个过程会一直持续,直到拼凑出一个完整的消息。
3. 如何保证正确处理TCP缓冲区中的数据?
通过"应用层缓冲区 + 状态机解析"的模式来保证。
你的主循环应该像这样:
cpp
void eventLoop(int socketFd) {
JsonProtocol protocol;
std::vector<char> recvBuf; // 应用层接收缓冲区
while (true) {
char tempBuf[1024];
ssize_t n = recv(socketFd, tempBuf, sizeof(tempBuf), 0);
if (n > 0) {
// 将新数据追加到应用层缓冲区
recvBuf.insert(recvBuf.end(), tempBuf, tempBuf + n);
// 循环尝试从缓冲区中提取完整消息
// 因为一次recv可能包含多条消息
while (protocol.tryDecode(recvBuf)) {
// 成功提取一条消息
Json::Value message = protocol.getMessage();
// 处理业务逻辑
processMessage(message);
}
// 如果n==0,对端关闭连接
// 如果n<0,处理错误(EAGAIN/EWOULDBLOCK对于非阻塞socket是正常的)
}
}
}总结
这种设计模式的优点:
-
可靠性: 绝对能正确处理粘包和拆包。
-
高效性: 头部固定长度,解析效率高。
-
通用性: 不仅适用于JSON,适用于任何需要定义边界的数据格式。
-
清晰性: 状态机的逻辑清晰,易于理解和维护。
这就是在现代网络编程中处理流式自定义协议的标准做法。jsoncpp 在这里只负责最后一步------将已经分离出来的完整字符串解析成JSON对象,而前面的消息边界界定工作,完全由你的自定义协议逻辑(长度头+状态机)来完成。
三、序列化和反序列化、自定义协议的关系是什么?
简单来说,它们的关系是:序列化和反序列化是实现自定义协议所必需的核心技术手段,而自定义协议则定义了序列化和反序列化的具体规则。
1、序列化与反序列化
序列化: 将数据结构或对象状态转换为一种可以存储或传输的格式(通常是一个字节序列)的过程。
-
目标: 把内存中复杂的、结构化的数据(如对象、结构体、字典等)"拍平",变成一串线性的、无结构的字节流。
-
好比: 把一辆复杂的汽车拆解成零件,然后整齐地打包进一个箱子,以便运输。
反序列化: 是序列化的逆过程。将接收到的字节序列重新构建成内存中的数据结构和对象。
-
目标: 将接收到的字节流,按照既定规则,"组装"回原来的数据结构,以便程序能够理解和操作。
-
好比: 收到装有汽车零件的箱子后,按照说明书把汽车重新组装起来。
常见的序列化格式/技术:
-
语言内置 : Python的
pickle、Java的Serializable。 -
文本格式: JSON、XML、YAML。它们是人类可读的,但通常体积较大。
-
二进制格式: Protocol Buffers(protobuf)、Apache Thrift、MessagePack、Avro。它们高效、紧凑,但人类不可读。
2、自定义协议
自定义协议: 在通信双方(客户端和服务器)之间约定好的一套规则,用于规范数据交换的格式、顺序、含义以及错误处理等。
-
目标: 确保通信双方能够正确、无歧义地理解彼此发送的信息。
-
内容: 协议定义了"如何打包数据"以及"如何解包数据"。
-
好比: 上面汽车零件箱子的"装箱说明书"和"组装说明书"。说明书规定了大零件放下面,小零件放上面,螺丝用哪个袋子装等。
协议的核心要素:
-
消息边界: 如何判断一个完整的消息从哪里开始,到哪里结束?(例如,用特定分隔符、在消息头声明消息体长度)
-
消息头: 通常包含元数据,如版本号、消息类型、消息体长度、错误码等。
-
消息体: 实际要传输的业务数据。
3、三者如何协同工作:一个完整的流程
让我们通过一个例子来理解它们是如何配合的。
场景: 一个简单的客户端向服务器发送"用户登录"请求。
步骤1:定义自定义协议
我们首先定义一个简单的二进制协议:
-
消息头(固定8字节):
-
前4字节:
magic number(例如0x1234abcd),用于标识这是一个合法的协议包开头,也用于解决TCP粘包问题。 -
第5字节:
version(版本号,1字节)。 -
第6字节:
type(消息类型,1表示登录请求,2表示登录响应)。 -
第7-8字节:
body_length(消息体长度,2字节)。
-
-
消息体: 序列化后的业务数据(例如登录用户名和密码)。
步骤2:发送方(客户端)的流程
-
创建业务对象:
cpplogin_request = { "username": "Alice", "password": "secret123" } -
序列化:客户端选择一个序列化方式(比如JSON),将业务对象转换成字节流。
cppimport json body_data = json.dumps(login_request).encode('utf-8') # 序列化为JSON字符串,再编码为字节 -
封装协议:客户端按照自定义协议的规则,将序列化后的数据打包。
-
计算
body_length = len(body_data) -
组装消息头:
magic_number + version + type + body_length -
将消息头和消息体(
body_data)拼接起来,形成一个完整的协议包。
-
-
传输:通过Socket将这个完整的协议包(字节流)发送给服务器。
步骤3:接收方(服务器)的流程
-
接收原始数据:服务器从Socket读取原始字节流。由于TCP是流式协议,可能会发生粘包,所以需要根据协议来解包。
-
解包协议(寻找消息边界):
-
首先读取固定长度的消息头(8字节)。
-
解析消息头,检查
magic number是否正确。 -
从消息头中取出
body_length(假设是50)。 -
接着,服务器知道再精确地读取接下来的50个字节,这就是一个完整的消息体。这解决了粘包问题。
-
-
反序列化:服务器现在拿到了一个完整的消息体字节流。它知道这个字节流是JSON格式的。
cppbody_bytes = ... # 从协议中提取出的50个字节 login_request = json.loads(body_bytes.decode('utf-8')) # 反序列化回字典对象 -
业务处理 :服务器现在得到了一个结构清晰的
login_request字典,可以像操作普通对象一样进行业务逻辑处理(验证用户名和密码)。
4、总结关系
| 概念 | 角色与作用 | 类比 |
|---|---|---|
| 自定义协议 | 通信规则。定义了数据的组织框架,包括如何分界、元信息是什么、业务数据放在哪。 | 物流公司的货运单和装箱规范。规定了箱子尺寸、填写收发人信息的位置、物品清单的格式。 |
| 序列化/反序列化 | 数据转换技术。负责将具体的业务数据(对象)填入协议框架的"数据区",或从其中提取出来。 | 打包和拆包工人的具体操作。他们按照货运单的规范,把实际物品(电视、书本)装箱(序列化)或从箱中取出(反序列化)。 |
核心关系提炼:
-
依赖关系: 实现一个自定义协议,几乎必然要使用到序列化和反序列化技术来处理其消息体。没有序列化,复杂的数据无法放入协议中;没有反序列化,接收方无法理解协议中的数据。
-
层次关系:
-
自定义协议位于更高层,它关注的是通信的整体规范和流程。
-
序列化/反序列化位于更底层,它关注的是单个消息体内数据的格式转换。
-
-
选择与组合: 你可以为同一个自定义协议选择不同的序列化方式。例如,你的协议头定义不变,但消息体可以选择用高效的protobuf,也可以选择人类可读的JSON。序列化方式是协议实现的一个可配置的组成部分。
因此,序列化和反序列化是构建自定义协议的基石,而一个设计良好的自定义协议则确保了序列化后的数据能够被准确、高效地传递和解析。完整流程:业务对象 -> (序列化) -> 序列化格式数据(如JSON字符串) -> (封装自定义协议) -> 完整的网络数据包 -> 发送
5、最终理解
序列化数据是实际传输的信息内容,而自定义协议则是在此基础上进行封装处理。常见的封装方式包括添加数据长度标识或报头信息等,这样既规范了数据传输格式,也便于接收方进行解析处理。
-
序列化后的数据是"货物/内容":这是你真正想要传递的核心信息(比如JSON字符串、protobuf二进制数据等)。
-
自定义协议是"包装/信封":它给货物加上必要的"外包装",让运输过程更可靠。
6、用几个生动的比喻来巩固理解
1. 快递包裹
-
序列化数据 = 你要寄的手机(真正的货物)
-
自定义协议 = 包装盒+填充物+快递单(上面有收件人、重量、条码)
-
如果没有包装盒和快递单,直接把手机扔给快递员,大概率会丢件或损坏
2. 书信
-
序列化数据 = 信纸上写的具体内容
-
自定义协议 = 信封+邮票+收件地址+寄件地址
-
如果没有信封,直接把信纸扔进邮筒,邮局根本不知道这信要寄给谁
3. 火车运输
-
序列化数据 = 火车车厢里装的货物
-
自定义协议 = 火车头+车厢编号+货物清单
-
如果没有火车头和编号,一堆车厢停在铁路上,谁也不知道该怎么拉走
7、为什么这个"包装"如此重要?
提到的"数据长度、报头"正是解决网络通信核心问题的关键:
-
数据长度→ 解决TCP粘包问题,告诉接收方"到底要读多少字节才算一个完整消息" -
消息类型→ 告诉接收方"这是登录请求还是心跳包?",以便分发给不同的处理逻辑 -
版本号→ 保证协议升级后的前后兼容性 -
Magic Number→ 快速验证这是一个合法的数据包,不是乱码或攻击数据
所以,**自定义协议就是给序列化数据加上必要的元信息,让接收方能够正确、高效地解析出你真正想发送的内容。**这种"内容+元数据"的封装思想在计算机科学中无处不在,你能够理解这一点,对于后续学习网络编程、分布式系统等都非常有帮助!
四、重点补充探讨:为什么应用层(业务层)、表示层(序列化反序列化)、协议层(自定义协议)、传输层(TCP/UDP方式连接)不能写到操作系统内核?
这是一个非常好的问题,它触及了网络编程和操作系统设计的核心权衡。
简单直接的回答是:它们可以写到内核里,而且历史上也出现过这样的设计。但是,现代主流的操作系统(如Linux、Windows、macOS)选择不这样做,是因为将网络栈的高层置于"用户空间"在灵活性、稳定性、安全性和开发效率上带来了巨大的优势。
下面我们详细拆解一下,为什么把这四层放到内核是一个"吃力不讨好"的主意。
1、应用层/业务层
这是最不应该放在内核的一层。
-
稳定性风险 :业务逻辑千变万化,充满了Bug、内存泄漏、死循环等。如果把它放在内核,任何一个业务Bug(比如一个空指针解引用)都可能导致整个操作系统内核恐慌 或蓝屏死机,造成单点故障,影响整台机器上运行的所有其他程序。
-
安全风险:内核拥有最高的系统权限。将业务逻辑放在内核,相当于给业务代码赋予了"上帝权限"。一旦业务逻辑有安全漏洞(如缓冲区溢出),攻击者将直接获得内核级控制权,后果是灾难性的。
-
开发与调试困难:内核空间编程和调试非常复杂。你不能使用很多熟悉的标准库(如glibc),需要遵循严格的内核编程规范。每次修改业务逻辑都需要重新编译内核或加载内核模块,开发、测试和部署周期极长。
-
缺乏灵活性:不同的应用需要不同的业务逻辑。如果每个应用都把自己的业务逻辑塞进内核,内核会变得无比臃肿,并且不同应用的逻辑之间会产生难以调和的冲突。
结论:把业务层放在用户空间,相当于给操作系统内核加了一个"安全护城河"。即使某个应用崩溃,也仅仅是该进程退出,不会波及操作系统本身和其他应用。
2、表示层
-
性能开销不显著:序列化/反序列化本质是数据格式转换(如JSON到结构体、Protobuf到二进制)。这些操作是计算密集型的,而非硬件/系统资源管理型的。在用户空间做这些操作,性能损失很小。
-
多变与迭代快:数据格式层出不穷(XML, JSON, Protobuf, Avro, MessagePack...),而且它们的标准和实现更新非常频繁。如果固化在内核中,每当有新格式或现有格式升级,都需要修改和发布新的内核,这是不可接受的。
-
与业务强相关:序列化方式通常由业务需求决定。一个微服务可能用Protobuf,另一个可能用JSON。内核无法预知和内置所有可能的格式。
结论:表示层的逻辑多变且与业务紧密耦合,放在用户空间可以方便地通过库来更新和替换,灵活性远胜于放在内核。
3、协议层
这里的"自定义协议"是关键!!!
-
标准协议已在内核 :像TCP、UDP、IP、ICMP这样的标准、通用、底层的协议确实是在内核中实现的。因为它们需要高效率、低延迟地处理网络数据包,并且是所有网络通信的基石。
-
自定义协议的困境:
-
缺乏通用性:你的自定义协议只对你的应用有用,对其他应用是噪音。将其放入内核是典型的"特权滥用",浪费了内核的宝贵资源和维护精力。
-
安全与审查:任何加入内核的代码都需要经过极其严格的安全审查。一个充满漏洞的自定义协议实现会成为整个系统的后门。
-
版本管理:你的应用协议v1.0和v2.0可能不兼容。如何在内核中同时维护多个版本?这会使内核设计变得异常复杂。
-
结论:通用、底层的协议在内核;非标准、应用层的自定义协议在用户空间。这是一个清晰的职责划分。
4、传输层
-
TCP/IP协议栈已在内核 :操作系统内核已经完整实现了TCP和UDP。你提到的"传输层(TCP/UDP方式连接)"中的连接管理、流量控制、拥塞控制、可靠传输等核心功能,正是由内核负责的。这是为了追求极致的性能。
-
为什么不全放进去? 虽然TCP协议本身在内核,但对TCP连接的使用和管理 (如建立连接、发送/接收数据、关闭连接)是通过系统调用(如
socket,bind,connect,send,recv)与内核交互的。这种"内核提供能力,用户空间发起调用"的模型是最优的:-
控制权分离:内核确保协议的正确性和公平性(所有应用都遵守TCP的拥塞控制),而应用则控制何时、如何以及发送什么数据。
-
避免阻塞 :如果一个应用的
recv调用在内核中阻塞,而该逻辑又完全在内核,可能会影响内核调度其他进程。
-
结论:传输层的核心协议实现在内核,但对它的调用和控制接口暴露在用户空间。这是性能与灵活性的完美折衷。
总结:内核空间 vs. 用户空间的设计哲学
| 特性 | 内核空间 | 用户空间 | 为什么用户空间更合适高层网络逻辑 |
|---|---|---|---|
| 稳定性 | 崩溃导致系统宕机 | 崩溃只影响自身进程 | 业务逻辑不稳定,需要隔离 |
| 安全性 | 最高权限(Ring 0) | 受限权限(Ring 3) | 防止有漏洞的应用代码危害系统 |
| 开发效率 | 困难、调试复杂、重启代价高 | 简单、工具丰富、重启快 | 业务需要快速迭代 |
| 灵活性 | 代码静态、更新缓慢 | 可通过库动态加载、更新容易 | 业务和协议变化快 |
| 性能 | 最高(无上下文切换) | 较高(需系统调用) | 对于高层逻辑,性能损失可接受 |
反例与特例:什么时候会放到内核?
尽管有上述缺点,但在某些极端追求性能的场景下,确实有将高层逻辑移入内核或"旁路内核"的方案:
-
内核旁路:如DPDK、XDP/eBPF。它们允许用户空间的程序直接操作网卡,绕过内核的网络协议栈,用于实现超高性能的负载均衡、防火墙或自定义协议。但这需要专门的硬件和支持,牺牲了通用性和安全性。
-
内核Web服务器:历史上出现过像TUX这样的内核Web服务器,用于提供静态文件,性能极高。但它无法处理复杂的业务逻辑,最终没有成为主流。
最终结论 :将应用层、表示层、自定义协议层和传输层的控制逻辑放在用户空间,是计算机科学经过数十年发展后形成的最佳实践 。它完美地平衡了性能、稳定性、安全性和开发灵活性。操作系统内核的职责是管理硬件资源和提供最通用、最稳定的基础服务,而不是成为所有应用程序的"运行容器"。