文章目录
- Pre
- [0. 引言:从数据湖到数据洞察](#0. 引言:从数据湖到数据洞察)
- [1. Spark SQL的历史演进:从Shark到统一查询引擎](#1. Spark SQL的历史演进:从Shark到统一查询引擎)
-
- [1.1 前身:Hive与Shark的时代](#1.1 前身:Hive与Shark的时代)
- [1.2 蜕变:Spark SQL的诞生](#1.2 蜕变:Spark SQL的诞生)
- [1.3 为什么Spark SQL如此重要?](#1.3 为什么Spark SQL如此重要?)
- [2. Spark SQL架构:查询优化的艺术](#2. Spark SQL架构:查询优化的艺术)
-
- [2.1 整体架构设计](#2.1 整体架构设计)
- [2.2 Catalyst优化器:查询优化的核心](#2.2 Catalyst优化器:查询优化的核心)
- [2.3 Tungsten执行引擎:性能的保障](#2.3 Tungsten执行引擎:性能的保障)
- [3. 核心API详解:DataFrame vs Dataset vs RDD](#3. 核心API详解:DataFrame vs Dataset vs RDD)
-
- [3.1 RDD:分布式计算的基石](#3.1 RDD:分布式计算的基石)
- [3.2 DataFrame:结构化数据的革命](#3.2 DataFrame:结构化数据的革命)
- [3.3 Dataset:类型安全的升华](#3.3 Dataset:类型安全的升华)
- [3.4 三者对比与选择指南](#3.4 三者对比与选择指南)
- [4. 实战案例:从数据湖到洞察](#4. 实战案例:从数据湖到洞察)
-
- [4.1 场景:电商平台用户行为分析](#4.1 场景:电商平台用户行为分析)
- [4.2 数据加载与预处理](#4.2 数据加载与预处理)
- [4.3 复杂查询与分析](#4.3 复杂查询与分析)
- [4.4 高级分析:用户行为序列挖掘](#4.4 高级分析:用户行为序列挖掘)
- [5. 性能优化:从分钟级到秒级](#5. 性能优化:从分钟级到秒级)
-
- [5.1 数据存储优化](#5.1 数据存储优化)
- [5.2 查询优化技巧](#5.2 查询优化技巧)
- [5.3 资源调优参数](#5.3 资源调优参数)
- [6. 未来展望:Spark SQL 4.0与AI融合](#6. 未来展望:Spark SQL 4.0与AI融合)
- [7. 小结](#7. 小结)
- 参考资源

Pre
大规模数据处理:04_大规模数据处理实战_从电商热销榜到分布式架构设计
大规模数据处理:05_分布式系统服务等级协议(SLA)实战评估与优化
大规模数据处理:06_分布式系统架构师必知的三大指标_扩展性、一致性与持久性
大规模数据处理:07_大规模数据处理模式深度剖析_批处理vs流处理
大规模数据处理:08_Workflow设计模式_大规模数据处理的架构利器
大规模数据处理:09_发布/订阅模式:流处理架构中的瑞士军刀
大规模数据处理:10_CAP定理深度解读与大规模数据处理系统架构设计
大规模数据处理:11_深入解析 Lambda 架构:亿级实时数据分析架构的技术原理与实战应用
大规模数据处理:12_Kappa架构剖析与Kafka在大规模流式数据处理中的应用实践
大规模数据处理:14_弹性分布式数据集(RDD)_Spark大厦的地基与现代数据处理核心(上)
大规模数据处理:15_弹性分布式数据集(RDD)_Spark大厦的地基与现代数据处理核心(下)
0. 引言:从数据湖到数据洞察
在当今数据驱动的时代,企业面临着前所未有的数据规模与复杂性挑战。根据IDC最新报告,全球数据总量预计到2025年将达到175ZB,其中80%以上是非结构化或半结构化数据。面对如此庞大的数据量,传统的关系型数据库已难以胜任,而分布式计算框架Spark凭借其卓越的性能和丰富的生态系统成为大数据处理的首选平台。
在Spark生态中,Spark SQL作为核心组件,为开发者提供了结构化数据处理的统一接口,实现了批处理、流处理、机器学习和图计算的数据无缝流转。它不仅继承了Spark的分布式计算能力,还融合了关系型数据库的查询优化技术,使得数据分析师和工程师能够以熟悉的SQL语法高效地处理PB级数据。
本文将深入探讨Spark SQL的核心架构、关键组件及其与传统RDD的区别,通过实际案例解析DataFrame与DataSet API的使用场景,并分享性能优化的最佳实践。
1. Spark SQL的历史演进:从Shark到统一查询引擎
1.1 前身:Hive与Shark的时代
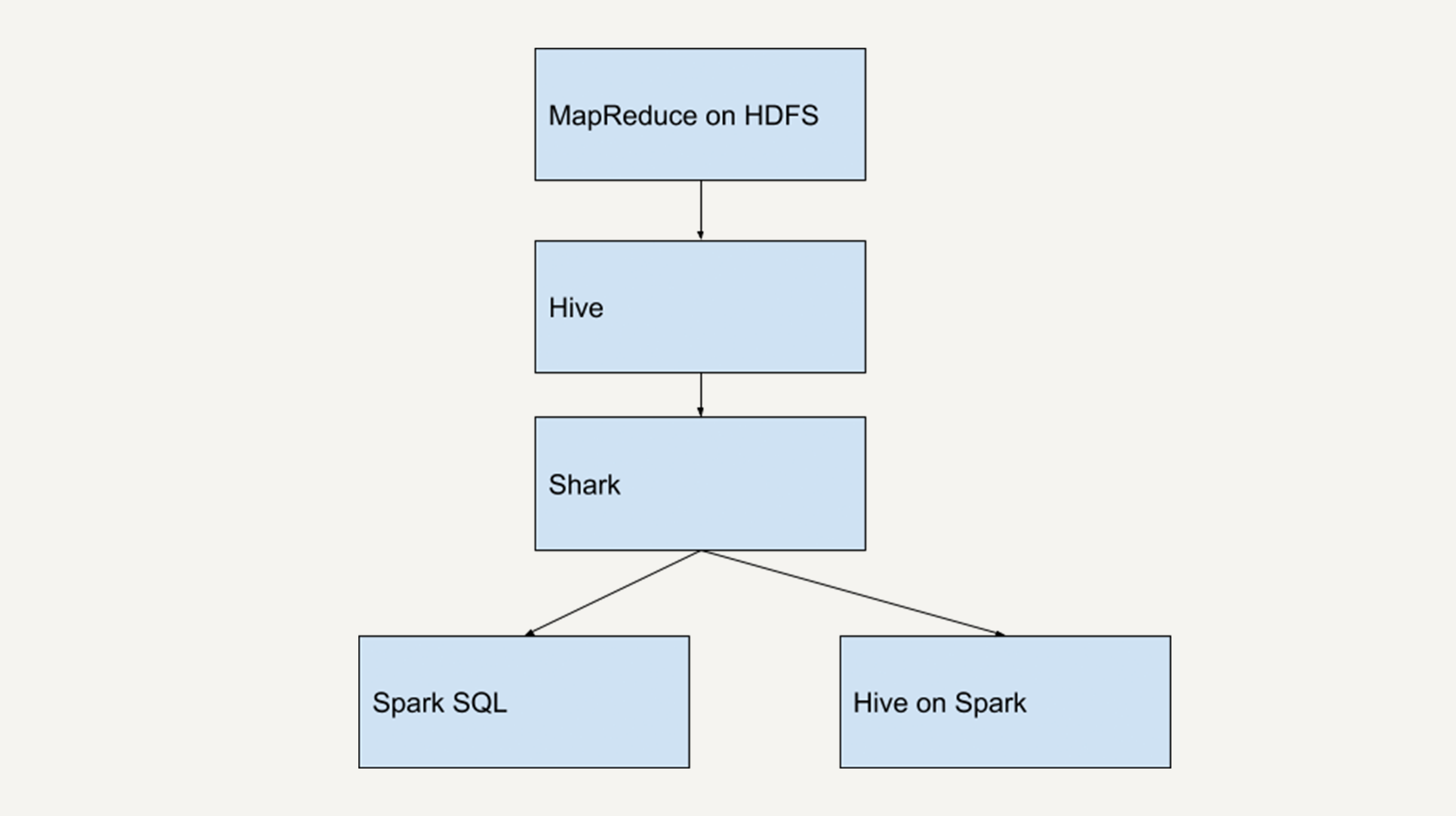
在大数据处理的早期阶段,Hadoop/MapReduce是主流技术栈,但其编程模型复杂且性能有限。为了降低使用门槛,Facebook于2010年推出了Hive,它提供了类似SQL的查询语言(HQL),将查询转化为MapReduce任务执行,使熟悉关系型数据库的开发人员能够轻松上手大数据分析。
当Spark于2010年问世后,其内存计算特性带来了显著的性能优势。2013年,Spark团队开发了Shark(Hive on Spark),它保留了Hive的语法和元数据管理,但将执行引擎替换为Spark,性能提升了10-100倍。然而,Shark的设计存在根本性缺陷:它重度依赖Hive的代码库,这严重制约了Spark的独立发展。
1.2 蜕变:Spark SQL的诞生
2014年7月,Spark团队做出了关键决策:放弃Shark,重新设计Spark SQL。这一转变的核心原因在于:
- 架构解耦:摆脱对Hive的依赖,建立独立的查询优化器和执行引擎
- 统一API:提供DataFrame/Dataset API,打通批处理、流处理和机器学习
- 深度优化:利用Spark的内存计算和DAG调度,实现更高效的查询执行
Spark SQL 1.0于2014年底发布,引入了Catalyst优化器;2016年的Spark 2.0实现了DataFrame和Dataset API的统一;而2018年发布的Spark 2.3引入了持续处理模式,将批处理和流处理的API进一步融合。如今,最新的Spark 3.x版本在性能、兼容性和功能上都有显著提升,成为企业级数据处理的事实标准。
1.3 为什么Spark SQL如此重要?
- 降低使用门槛:让熟悉SQL的数据分析师无需深入学习分布式系统原理
- 性能优势:相比Hive on MapReduce,查询速度提升10-100倍
- 统一数据访问:同时支持结构化、半结构化和非结构化数据
- 生态系统整合:与Spark Streaming、MLlib和GraphX无缝协作
- 兼容性:完全兼容Hive metastore,可无缝迁移现有Hive工作负载
2. Spark SQL架构:查询优化的艺术
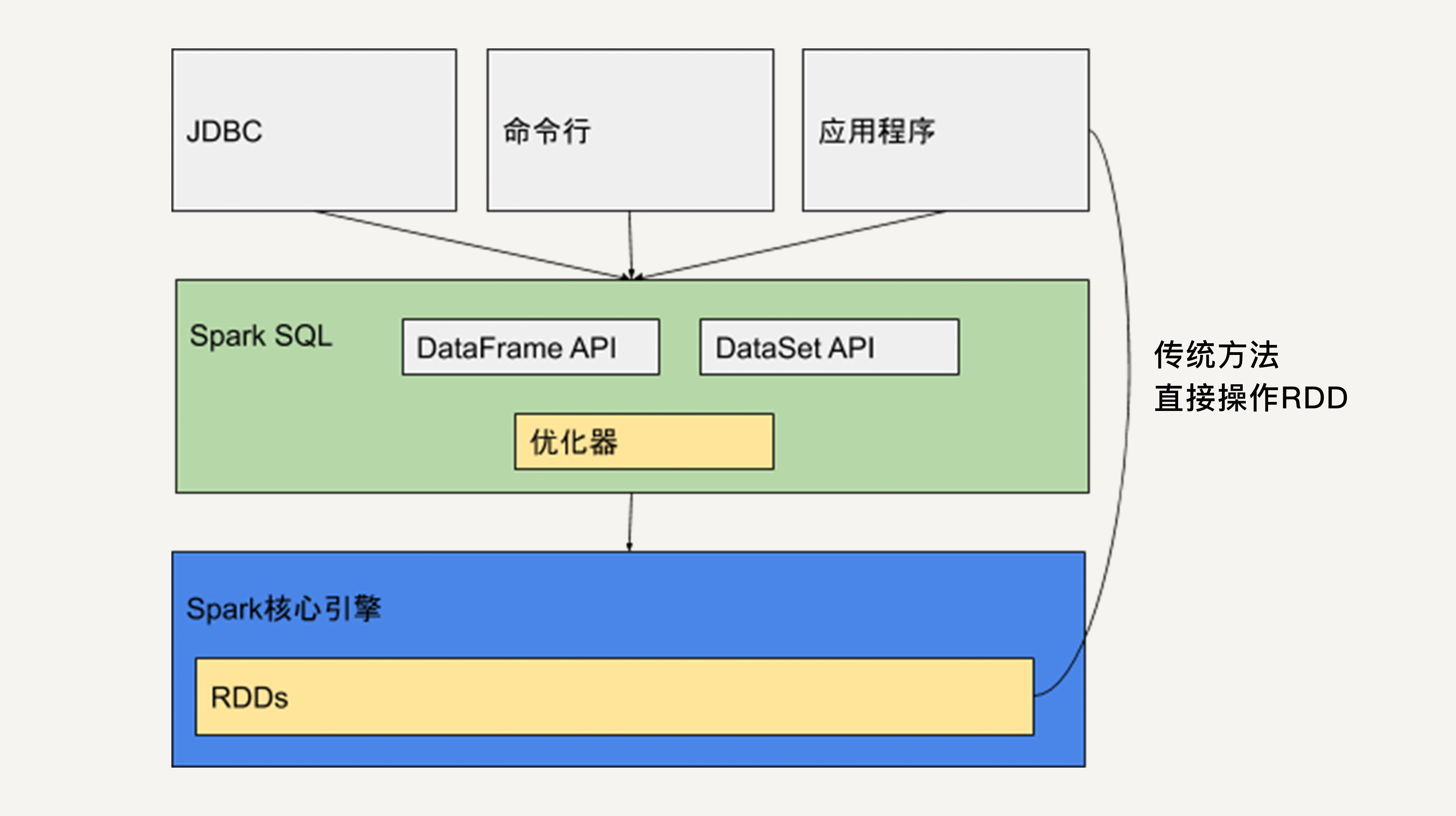
2.1 整体架构设计
Spark SQL的架构可分为四层:
- 语言层:支持SQL、DataFrame API、Dataset API等多种接口
- 优化层:Catalyst优化器负责逻辑计划的生成和优化
- 执行层:Tungsten引擎负责物理计划的执行和代码生成
- 存储层:兼容多种数据源,如Hive、Parquet、JSON、JDBC等
这种分层设计使得Spark SQL能够在保持接口灵活性的同时,实现深度的查询优化。
2.2 Catalyst优化器:查询优化的核心
Catalyst是Spark SQL的查询优化引擎,它采用函数式编程范式,将SQL查询转化为可执行的物理计划。其优化过程包含四个主要阶段:
- 解析(Analysis):将SQL字符串或DataFrame操作转换为未解析的逻辑计划
- 优化(Optimization):应用规则将逻辑计划转换为优化后的逻辑计划
- 物理计划(Physical Planning):生成多个可行的物理执行计划,并选择成本最低的
- 代码生成(Code Generation):将物理计划编译为可执行的Java字节码
Catalyst的规则包括谓词下推、列裁剪、常量折叠、连接重排序等。例如,一个先filter后join的查询,优化器可能将filter下推到join之前,大幅减少需要连接的数据量。
2.3 Tungsten执行引擎:性能的保障
Tungsten是Spark SQL的执行引擎,专注于内存管理和CPU效率:
- 二进制处理:数据以紧凑的二进制格式存储,减少GC开销
- 代码生成:将查询编译为Java字节码,避免解释执行的开销
- 缓存感知:优化内存访问模式,提高CPU缓存命中率
- 向量化执行:在支持的格式(如Parquet)上,批量处理数据而非逐行处理
这些技术使得Spark SQL能够高效处理大规模数据集,尤其在复杂查询和迭代计算场景下表现突出。
3. 核心API详解:DataFrame vs Dataset vs RDD
3.1 RDD:分布式计算的基石
RDD(Resilient Distributed Dataset)是Spark的核心抽象,是一个不可变的、分区的元素集合,支持分布式计算。它提供了低级别的API,允许开发者精确控制数据处理流程:
scala
// RDD示例
val lines = sc.textFile("hdfs://path/to/data.txt")
val words = lines.flatMap(line => line.split(" "))
val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _)RDD的优势在于灵活性,但缺乏结构化信息,难以进行高级优化,且类型安全依赖于开发者。
3.2 DataFrame:结构化数据的革命
DataFrame是Spark 1.3引入的API,它将数据组织为命名列的形式,类似于关系型数据库中的表。每个DataFrame都有schema信息,但不包含列的类型信息(在运行时解析):
scala
// DataFrame示例
val df = spark.read.json("data.json")
df.select("name", "age").filter($"age" > 21).show()DataFrame的主要优势:
- 自动优化:Catalyst优化器可利用schema信息进行查询优化
- 内存效率:Tungsten引擎使用二进制格式存储,减少内存占用
- 多语言支持:在Scala、Java、Python和R中API一致
- 数据源集成:统一访问Hive、Parquet、JSON、CSV等多种格式
3.3 Dataset:类型安全的升华
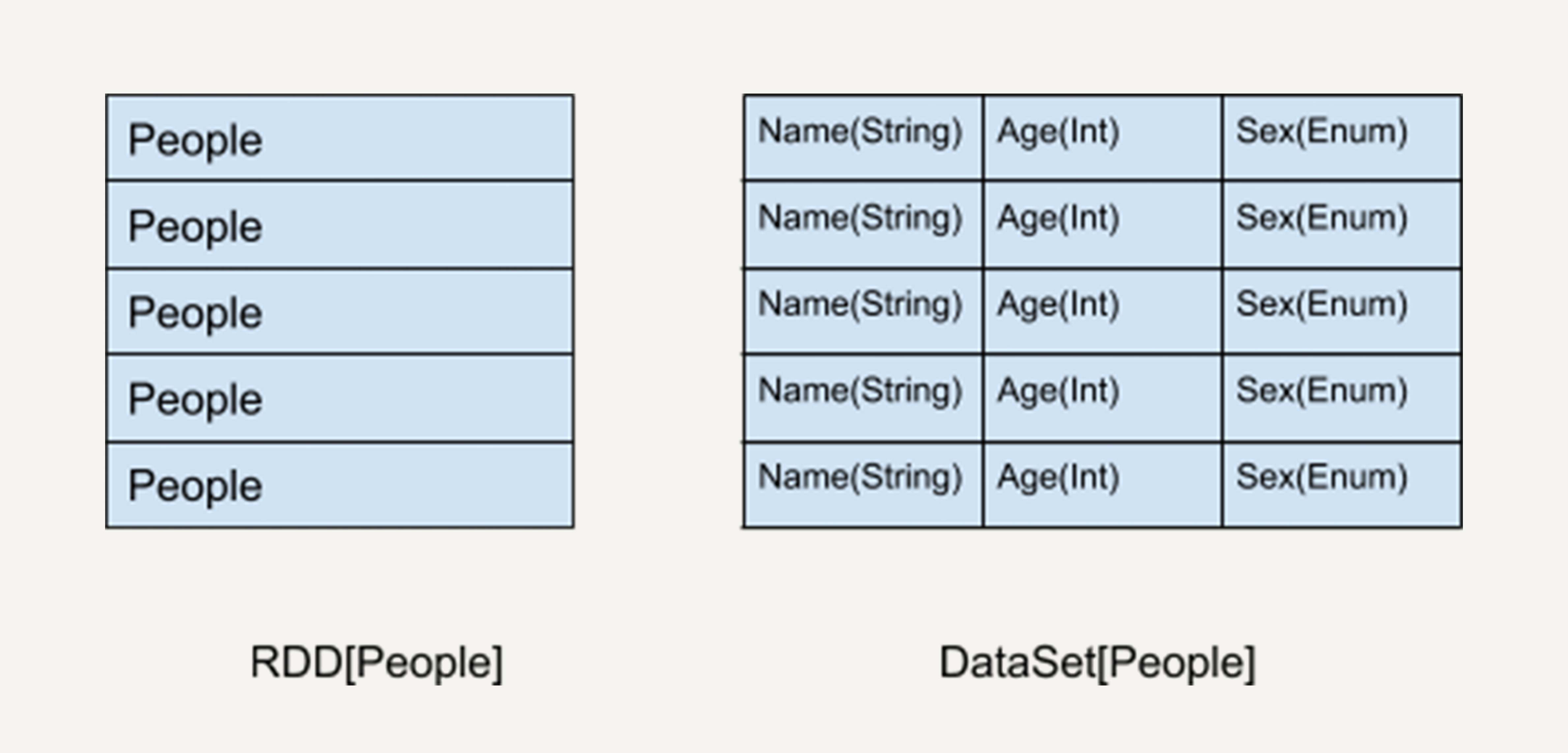
Dataset是Spark 1.6引入的API,在Spark 2.0中与DataFrame统一。它结合了RDD的类型安全和DataFrame的查询优化:
scala
case class Person(name: String, age: Int)
// Dataset示例
val ds: Dataset[Person] = spark.read.json("data.json").as[Person]
val adults = ds.filter(_.age > 21)Dataset的核心特性:
- 编译时类型安全:Scala/Java编译器可检查类型错误
- 序列化优化:使用Encoder高效序列化JVM对象
- 兼容DataFrame:在Spark 2.0+中,DataFrame是DatasetRow的别名
- JVM对象操作:可直接操作领域对象,无需手动解析Row
3.4 三者对比与选择指南
| 特性 | RDD | DataFrame | Dataset |
|---|---|---|---|
| 类型安全 | 编译时检查 | 运行时检查 | 编译时检查 |
| 优化级别 | 有限 | Catalyst优化 | Catalyst优化 |
| 序列化 | Java序列化 | 二进制格式(Tungsten) | 二进制格式+Encoder |
| 内存效率 | 低 | 高 | 高 |
| 适用语言 | Scala/Java | Scala/Java/Python/R | Scala/Java |
| 适用场景 | 非结构化数据/定制转换 | 交互式分析/ETL | 类型敏感的应用/复杂领域模型 |

选择建议:
- 优先使用DataFrame/Dataset API,除非有特殊需求
- 在Scala/Java中,若需要编译时类型检查,选择Dataset
- 在Python/R中,DataFrame是唯一选择
- 处理非结构化数据(如文本处理)或需要细粒度控制时,考虑RDD
4. 实战案例:从数据湖到洞察
4.1 场景:电商平台用户行为分析
假设我们有以下数据源:
- 用户基本信息(Hive表):users(id, name, age, gender, location)
- 订单数据(Parquet):orders(order_id, user_id, amount, timestamp, items)
- 点击流数据(JSON):clicks(user_id, page, timestamp, device)
我们的目标是分析不同年龄段用户的购买行为和页面偏好。
4.2 数据加载与预处理
scala
// 初始化SparkSession
val spark = SparkSession.builder()
.appName("E-commerce Analysis")
.config("spark.sql.warehouse.dir", "/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
// 加载数据
val usersDF = spark.table("users") // 从Hive读取
val ordersDF = spark.read.parquet("hdfs://path/to/orders") // 从Parquet读取
val clicksDF = spark.read.json("hdfs://path/to/clicks") // 从JSON读取
// 数据清洗
val validOrders = ordersDF.filter($"amount" > 0)
val recentClicks = clicksDF.filter($"timestamp" > "2023-01-01")4.3 复杂查询与分析
scala
// 创建临时视图
validOrders.createOrReplaceTempView("orders")
usersDF.createOrReplaceTempView("users")
// SQL方式分析
val sqlResult = spark.sql("""
SELECT
CASE
WHEN age < 25 THEN '18-24'
WHEN age < 35 THEN '25-34'
WHEN age < 45 THEN '35-44'
ELSE '45+'
END as age_group,
COUNT(DISTINCT user_id) as active_users,
SUM(amount) as total_revenue,
AVG(amount) as avg_order_value
FROM orders
JOIN users ON orders.user_id = users.id
GROUP BY age_group
ORDER BY total_revenue DESC
""")
// DataFrame API方式
val dfResult = validOrders.join(usersDF, "user_id")
.withColumn("age_group",
when($"age" < 25, "18-24")
.when($"age" < 35, "25-34")
.when($"age" < 45, "35-44")
.otherwise("45+"))
.groupBy("age_group")
.agg(
countDistinct("user_id").alias("active_users"),
sum("amount").alias("total_revenue"),
avg("amount").alias("avg_order_value")
)
.orderBy(desc("total_revenue"))4.4 高级分析:用户行为序列挖掘
scala
// 定义Dataset模式
case class ClickEvent(user_id: String, page: String, timestamp: Timestamp, device: String)
case class UserBehavior(user_id: String, age_group: String, pages: Seq[String])
// 转换为Dataset进行类型安全操作
val clicksDS = clicksDF.as[ClickEvent]
val usersDS = usersDF.as[User]
val userBehaviors = clicksDS
.groupBy("user_id")
.agg(collect_list(struct("timestamp", "page")).alias("events"))
.join(usersDS, "user_id")
.withColumn("age_group",
when($"age" < 25, "18-24")
.when($"age" < 35, "25-34")
.otherwise("35+"))
.withColumn("sorted_pages", expr("transform(sort_array(events), x -> x.page)"))
.select($"user_id", $"age_group", $"sorted_pages".alias("pages"))
.as[UserBehavior]
// 分析每个年龄段的常见页面路径
val commonPaths = userBehaviors
.groupBy("age_group")
.agg(
count("*").alias("total_users"),
array_distinct(flatten(collect_set("pages"))).alias("common_pages")
)5. 性能优化:从分钟级到秒级
5.1 数据存储优化
- 文件格式选择:使用列式存储(Parquet/ORC)而非行式存储(CSV/JSON)
scala
// 读取Parquet比JSON快3-5倍,且占用空间小75%
val df = spark.read.parquet("hdfs://path/to/data.parquet")- 分区设计:按查询过滤条件分区
scala
// 按日期和地域分区
df.write.partitionBy("date", "region").parquet("hdfs://path/to/output")- 分桶优化:对频繁连接的键进行分桶
scala
// 按user_id分桶
df.write.bucketBy(16, "user_id").saveAsTable("bucketed_table")5.2 查询优化技巧
- 谓词下推:将过滤条件尽可能下推
scala
// 优化前
val result = df.filter($"date" === "2023-01-01").select("user_id", "amount")
// 优化后(自动优化)
// Spark SQL会自动将filter下推,先过滤再投影- 广播连接:小表广播到各节点
scala
// 当users表较小时(默认<10MB),自动广播
val joined = orders.join(broadcast(users), "user_id")- 缓存中间结果:避免重复计算
scala
val filteredOrders = orders.filter($"amount" > 100).cache()
val result1 = filteredOrders.groupBy("user_id").count()
val result2 = filteredOrders.groupBy("product").sum("amount")5.3 资源调优参数
scala
// 常用优化参数
spark.conf.set("spark.sql.shuffle.partitions", "200") // 根据集群核心数调整
spark.conf.set("spark.sql.adaptive.enabled", "true") // 启用自适应查询执行
spark.conf.set("spark.sql.files.maxPartitionBytes", "128mb") // 控制分区大小
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "50mb") // 调整广播阈值6. 未来展望:Spark SQL 4.0与AI融合
随着大数据与AI的深度融合,Spark SQL也在向智能化和实时化演进:
-
增强的AI集成:
- MLlib与SQL的无缝集成,通过SQL直接调用ML模型
- 使用DataFrame API构建端到端的机器学习流水线
-
流批统一:
- 通过Structured Streaming API,使用相同代码处理批数据和流数据
- 持续查询模式(Continuous Processing)降低延迟至毫秒级
-
自适应查询执行:
- Spark 3.0+的自适应查询执行(AQE)自动优化join策略和分区
- 基于运行时统计信息动态调整执行计划
-
云原生支持:
- 与Delta Lake、Apache Iceberg等开放表格式深度集成
- 无服务器架构支持,如Databricks Serverless SQL
7. 小结
Spark SQL作为现代数据处理的核心工具,成功地将关系型数据库的易用性与分布式系统的扩展性相结合。它不仅仅是一个查询引擎,更是连接数据工程、数据分析和机器学习的桥梁。
在实际应用中,我们应该:
- 优先选择DataFrame/Dataset API而非RDD
- 根据语言环境和需求选择合适的API
- 重视数据存储格式和分区设计
- 利用Catalyst优化器自动优化查询
- 持续关注Spark SQL的新特性,如自适应查询执行和流批统一
正如大数据先驱Doug Cutting所言:"工具应该适应人类,而不是相反。"Spark SQL通过其优雅的API设计和强大的优化能力,让数据工作者能够专注于业务问题而非分布式系统复杂性,释放数据的真正价值。
参考资源
- Apache Spark官方文档
- "Spark: The Definitive Guide" by Bill Chambers and Matei Zaharia
- Databricks博客:
- Spark SQL优化实践白皮书,Cloudera
- Structured Streaming: A Declarative API for Processing Streams in Apache Spark, 2018
