本文将介绍有关 redis 的 string 底层实现的内容
结构源码
redis 的的 String 类型底层主要是依靠 redis 的SDS 结构,同时通过 int, embstr, raw 等不同编码方式进行存储。
首先我们来看 redis 中进行数据存储的 redisObject 源码
c
struct redisObject {
unsigned type:4; // 数据类型(字符串、哈希等)
unsigned encoding:4; // 编码类型(int、embstr、raw等)
int64_t ptr; // 实际的数据指针,这里直接存储整数值
};可以看到其中有三个字段,分别是
- type,表明数据类型(字符串、哈希等)
- encoding,表明编码类型,如 int、embstr、raw 等
- ptr,实际的数据指针
针对于 redis 的 String 类型数据,redis 的 type 为字符串,encoding 将为 int、embstr、raw。而 ptr 又会根据 encoding 有不同的分配指向。
接着我们又来看看 String 依赖的底层结构 SDS,如下图(图片来自于小林 coding)

可以看到 SDS 的数据结构主要有以下及部分组成
- len,记录了字符串长度
- alloc,分配给字符数组的空间长度
- flags,用来表示不同类型的 SDS。redis 一共设计了 5 中类型,分别是 sdshdr 5、sdshdr 8、sdshdr 16、sdshdr 32 和 sdshdr 64。这几种不同类型主要差别在于对数据结构中的 len 和 alloc 变量的数据类型不同,比如 sdshdr 16 的 len 和 alloc 是uint16_t,而 sdshdr 64 的 len 和 alloc 是 uint 64_t,类型不同,变量能够表示的数据范围也不同
- buf\[\],字节数组,用来保存实际数据
这里我们以 sdshdr 32 的源码定义为例,其中的 __attribute__ ((packed)) redis 使用的准们的编译优化来节省空间,告诉编译器取消编译过程中的优化对齐,按照实际占用字节数进行对齐
c
struct __attribute__ ((packed)) sdshdr32 {
uint32_t len; // 当前字符串长度
uint32_t alloc; // 已分配的内存大小
unsigned char flags; // 编码类型
char buf[]; // 实际字符串数据
};通过源码,redis 相比于 C 语言的 char 数组实现字符串,有以下好处
- SDS可以通过 O(1 )的方式获取字符串长度,而不是像 C 语言那样通过遍历获得
- SDS可以存储二进制数据文件,因为 SDS 以 len 来判断是否为字符串末尾,不再像 C 语言那样利用'\0'来判断
- SDS 的 API 更为安全,拼接字符串不会造成缓冲区溢出的问题。这是因为 SDS 可以通过 alloc-len 来检查剩余空间是否满足要求
现在 redis 对于 String 实现的结构定义源码已经看了,我们现在可以来关注当 encoding 使用不同的编码方式时,redis 有关 String 的存储形式是什么样子的。
不同编码实现
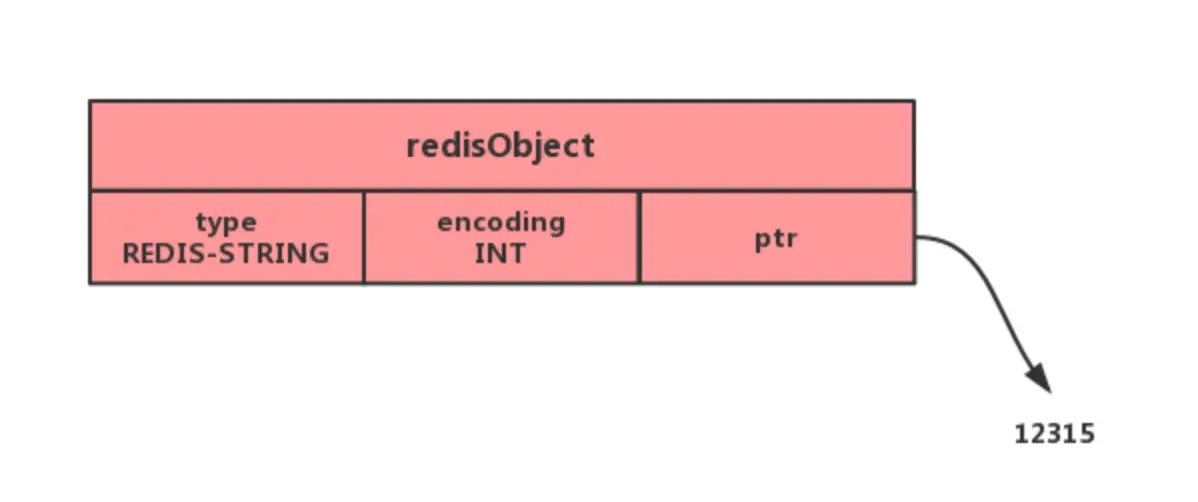
encoding=int
当 redis 的 String 存储的是整数值,并且这个整数值可以用 long 来表示,那么字符串对象会将整个数值保存在 redisObject 的 ptr 属性之中(将 void* 转换成 long),并将字符串对象的编码设置为 int,如下图(图片来源于小林 coding)
encoding=embstr
当 redis 的 string 保存的是一个字符串,且这个字符串长度小于等于 32 字节(这个与 redis 的版本有关),那么字符串对象的 encoding 将为 embstr,如下图(图片来源于小林 coding)

当使用这中编码方式时,字符串相关的结构体和数据将存放在连续的内存中,分配的时候,只需要分配一次,减少内存分配和管理开销
encoding=raw
当 redis 的 string 保存的是一个字符串,且这个字符串长度大于 32 字节(这个与 redis 的版本有关),那么字符串对象的 encoding 将为 raw,如下图(图片来源于小林 coding)
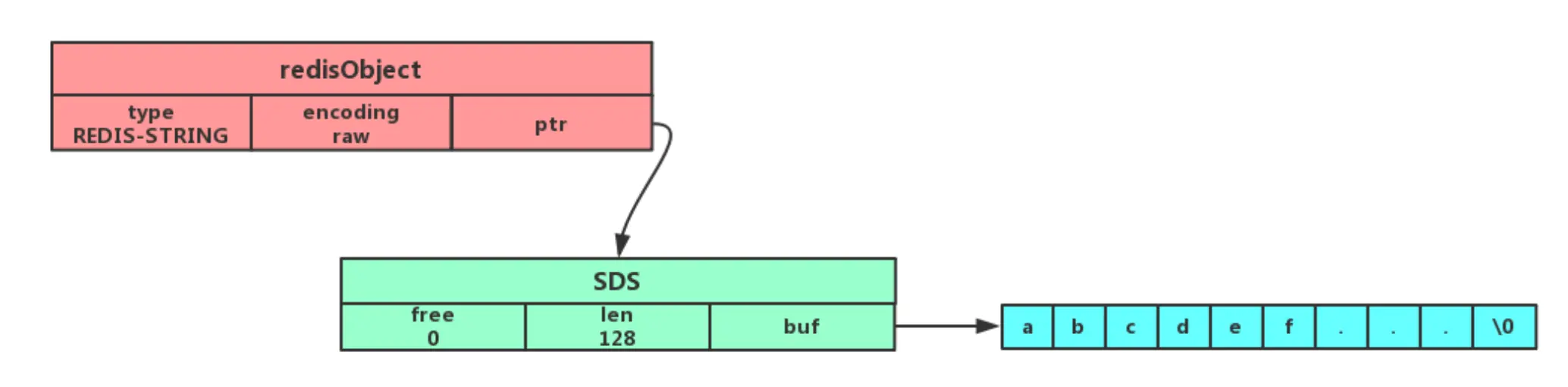
其中可以看到这种编码方式将通过调用两次内存分配函数来分别分配两块空间来保存 redisObject 和 SDS,将 redis 对象结构体和数据分开存储,以便处理更长的数据。
最后总结一下
- int 编码:用于存储可以解析为整数的字符串,内存消耗最小,适合数值
- embstr 编码:用于存储较短的字符串,将结构和数据存储在同一块内存中,一次性分配内存
- raw 编码:用于存储较长的字符串,调用两次内存分配函数来分别分配两块空间来保存,结构和数据分开存储,适合频繁操作的大字符串