一. 引言
现如今,大型语言模型如雨后春笋般涌现。然而,如何客观、全面地评估这些模型的真实能力,不仅是学术界的挑战,也是我们作为开发者的困惑,一个新的概念CLUE(Chinese Language Understanding Evaluation)基准,应运而生,它就像一把精准的尺子,为中文大模型的性能评估提供了标准化方案。
想象一下,如果没有统一的考试标准,我们如何判断哪个学生更优秀?同样,没有CLUE这样的基准,我们也难以比较不同大模型的优劣。CLUE不仅填补了中文自然语言处理评估的空白,更为模型研发提供了明确的方向指引。
二. CLUE基准概述
1. 什么是CLUE基准
CLUE是一个专门针对中文语言理解任务的综合性评估基准。它汇集了多个自然语言处理任务,旨在全面测试模型在中文环境下的语言理解能力。就像高考包含语文、数学、英语等多科目一样,CLUE通过多样化的任务来考察模型的"综合素质"。
2. CLUE的核心价值
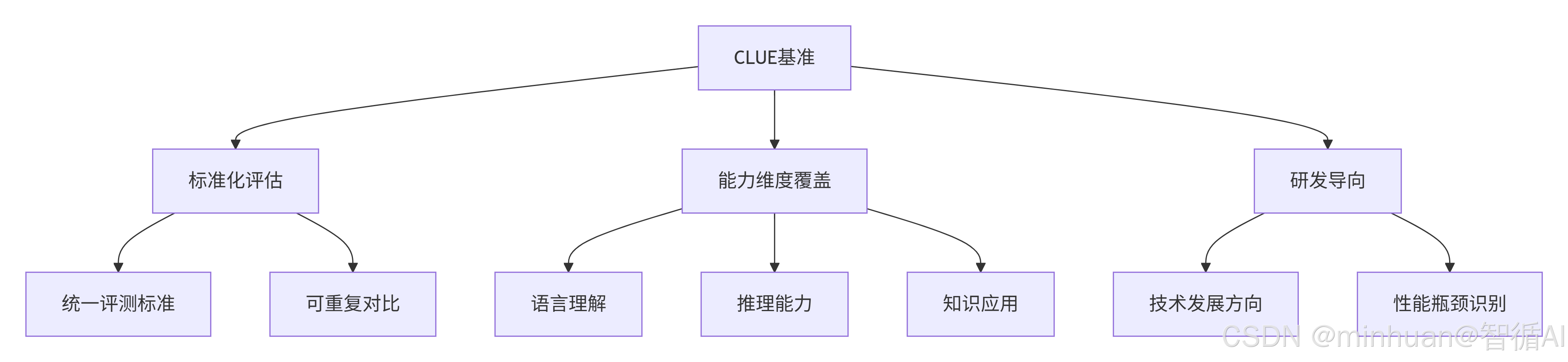
三、主要任务类型
1. 文本分类任务
原理基础:
文本分类是自然语言处理的基础任务,要求模型将文本划分到预定义的类别中。这就像让一个孩子学会区分"水果"和"蔬菜"一样,模型需要理解文本的语义内容并做出正确判断。
典型数据集:
- TNEWS:新闻文本分类,包含15个新闻类别
- IFLYTEK:应用描述分类,涵盖200+个应用领域
技术要点:
1. 评估指标:准确率
- 定义:正确预测的样本数占总样本数的比例
- 适用场景:类别平衡的数据集
- 局限性:在类别不平衡时可能产生误导
2. 迭代评估模式
- 逐样本处理:逐个处理测试样本,适合内存受限场景
- 实时反馈:可以实时观察模型表现
- 灵活性:便于添加额外的评估逻辑
3. 预测接口标准化
- 接口抽象:统一的预测接口,支持不同模型类型
- 输入输出规范:文本输入,标签输出
- 模型无关性:适用于传统机器学习模型和深度学习模型
完整评估流程:
python
import numpy as np
from sklearn.metrics import precision_score, recall_score, f1_score, confusion_matrix
import time
from collections import Counter
class TextClassificationEvaluator:
"""完整的文本分类评估器"""
def __init__(self):
self.metrics_history = []
def comprehensive_evaluate(self, model, test_data, labels=None):
"""
综合评估文本分类模型
Args:
model: 分类模型,需实现predict方法
test_data: 测试数据列表,每个元素为(text, true_label)
labels: 所有可能的标签列表(可选)
Returns:
dict: 包含多种评估指标的字典
"""
# 初始化统计变量
all_true = []
all_pred = []
inference_times = []
# 逐样本预测
for text, true_label in test_data:
start_time = time.time()
pred_label = model.predict(text)
end_time = time.time()
all_true.append(true_label)
all_pred.append(pred_label)
inference_times.append(end_time - start_time)
# 计算各项指标
metrics = self._calculate_metrics(all_true, all_pred, inference_times, labels)
# 记录历史
self.metrics_history.append(metrics)
return metrics
def _calculate_metrics(self, true_labels, pred_labels, inference_times, labels=None):
"""计算多种评估指标"""
# 基础准确率
accuracy = np.mean(np.array(true_labels) == np.array(pred_labels))
# 性能指标
avg_inference_time = np.mean(inference_times)
throughput = len(true_labels) / sum(inference_times) if sum(inference_times) > 0 else 0
metrics = {
'accuracy': accuracy,
'total_samples': len(true_labels),
'correct_predictions': sum(1 for t, p in zip(true_labels, pred_labels) if t == p),
'avg_inference_time': avg_inference_time,
'throughput': throughput
}
# 如果提供了标签列表,计算更详细的指标
if labels is not None:
# 精确率、召回率、F1分数
precision = precision_score(true_labels, pred_labels, labels=labels, average='weighted', zero_division=0)
recall = recall_score(true_labels, pred_labels, labels=labels, average='weighted', zero_division=0)
f1 = f1_score(true_labels, pred_labels, labels=labels, average='weighted', zero_division=0)
metrics.update({
'precision': precision,
'recall': recall,
'f1_score': f1
})
# 混淆矩阵
cm = confusion_matrix(true_labels, pred_labels, labels=labels)
metrics['confusion_matrix'] = cm.tolist()
# 各类别详细统计
class_report = self._generate_class_report(true_labels, pred_labels, labels)
metrics['class_report'] = class_report
return metrics
def _generate_class_report(self, true_labels, pred_labels, labels):
"""生成详细的类别报告"""
report = {}
for label in labels:
# 真正例、假正例、假负例
tp = sum(1 for t, p in zip(true_labels, pred_labels) if t == label and p == label)
fp = sum(1 for t, p in zip(true_labels, pred_labels) if t != label and p == label)
fn = sum(1 for t, p in zip(true_labels, pred_labels) if t == label and p != label)
# 计算各类别指标
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0
report[label] = {
'precision': precision,
'recall': recall,
'f1_score': f1,
'support': sum(1 for t in true_labels if t == label),
'tp': tp,
'fp': fp,
'fn': fn
}
return report
def compare_models(self, models_dict, test_data, labels=None):
"""比较多个模型的性能"""
comparison_results = {}
for model_name, model in models_dict.items():
print(f"评估模型: {model_name}")
metrics = self.comprehensive_evaluate(model, test_data, labels)
comparison_results[model_name] = metrics
return comparison_results
def generate_evaluation_report(self, metrics, model_name="Model"):
"""生成评估报告"""
report = f"""
{'='*50}
{model_name} 文本分类评估报告
{'='*50}
基础指标:
- 准确率 (Accuracy): {metrics['accuracy']:.4f}
- 正确预测数: {metrics['correct_predictions']} / {metrics['total_samples']}
- 平均推理时间: {metrics['avg_inference_time']:.4f} 秒/样本
- 吞吐量: {metrics['throughput']:.2f} 样本/秒
"""
if 'precision' in metrics:
report += f"""详细指标:
- 精确率 (Precision): {metrics['precision']:.4f}
- 召回率 (Recall): {metrics['recall']:.4f}
- F1分数 (F1-Score): {metrics['f1_score']:.4f}
"""
if 'class_report' in metrics:
report += "各类别性能:\n"
for label, stats in metrics['class_report'].items():
report += f"- {label}: Precision={stats['precision']:.3f}, Recall={stats['recall']:.3f}, F1={stats['f1_score']:.3f}, Support={stats['support']}\n"
return report
# 简化的文本分类评估流程
def evaluate_text_classification(model, test_data):
correct = 0
total = len(test_data)
for text, true_label in test_data:
predicted_label = model.predict(text)
if predicted_label == true_label:
correct += 1
accuracy = correct / total
return accuracy2. 自然语言推理(NLI)
原理基础:
自然语言推理任务要求模型判断两个句子之间的逻辑关系。这类似于人类的推理能力------给定一个前提,判断假设是否成立。
三种关系类型:
- 蕴含(Entailment):前提支持假设
- 矛盾(Contradiction):前提否定假设
- 中立(Neutral):前提与假设无关
典型数据集:
- OCNLI:中文自然语言推理数据集
- CMNLI:多类型自然语言推理
3. 命名实体识别(NER)
原理基础:
命名实体识别要求模型识别文本中的特定实体,如人名、地名、组织机构等。这就像在文章中划重点,标记出关键信息。
评估挑战:
- 实体边界识别
- 实体类型分类
- 嵌套实体处理
4. 阅读理解任务
原理基础:
阅读理解任务模拟人类的阅读理解过程,给定一篇文章和相关问题,要求模型从文章中找出或推断出答案。
典型数据集:
- CMRC:中文机器阅读理解
- DRCD:繁体中文阅读理解
四. 关键评估指标解析
1. 准确率(Accuracy)
计算公式:准确率 = 正确预测的样本数 / 总样本数
适用场景:
- 类别分布均衡的分类任务
- 简单判断任务
局限性:在类别不平衡的数据集中,准确率可能产生误导。
2. F1分数(F1 Score)
原理说明:F1分数是精确率(Precision)和召回率(Recall)的调和平均数,能够更好地评估模型在不平衡数据集上的表现。
计算公式:F1 = 2 × (精确率 × 召回率) / (精确率 + 召回率)
其中:
- 精确率 = 真正例 / (真正例 + 假正例)
- 召回率 = 真正例 / (真正例 + 假反例)
3. 精确匹配
适用场景:阅读理解等需要精确答案的任务。
计算方式:预测答案与标准答案完全一致时计为正确。
4. 宏平均与微平均
宏平均:对所有类别平等对待,计算每个类别的指标后取平均。
微平均:考虑每个样本的贡献,更适合类别不平衡的情况。
五、数据集构建
1. 数据收集流程

这个流程图描述了一个从原始数据到数据集发布的完整流程,包括数据清洗、任务设计、标注规范制定、人工标注、质量检验和数据集发布。
步骤说明:
-
- 原始数据源:这是起点,可能是从互联网、公司内部或其他渠道收集的原始文本数据。
-
- 数据清洗:对原始数据进行预处理,包括去除无关内容、标准化格式、去重、处理缺失值等,以确保数据质量。
-
- 任务设计:根据业务需求设计具体的自然语言处理任务,例如文本分类、命名实体识别、情感分析等。
-
- 标注规范制定:为选定的任务制定详细的标注指南,包括标签体系、标注示例、边界情况处理等,以确保标注一致性。
-
- 人工标注:标注人员根据标注规范对清洗后的数据进行手动标注。
-
- 质量检验:对已标注的数据进行质量检查,可能包括抽样检查、交叉验证、计算标注者间信度等,以确保标注质量。
-
- 数据集发布:将高质量的数据集打包发布,供模型训练和评估使用。
这个流程确保了数据集的可靠性和可用性,是构建高质量NLP模型的基础。
2. 数据质量保证
完整的数据质量保证体系通过多重校验机制确保标注准确性,通过多样性考虑确保数据全面性,为构建高质量数据集提供了系统化的方法论和实践指导。
2.1 多重校验机制
2.1.1 交叉标注验证
交叉标注验证指同一份数据由多名标注者独立标注,通过对比标注结果来评估和提升标注质量。
- 标注者数量:通常3-5名标注者,平衡成本与质量
- 一致性度量:使用Fleiss' Kappa、Cohen's Kappa等统计指标
- 冲突解决:建立明确的冲突解决机制
- 质量控制:低一致性数据需要重新标注或专家介入
2.1.2 专家审核
专家审核是由领域专家对标注结果进行抽样审查和质量把控。
- 抽样策略:分层抽样、随机抽样、重点抽样相结合
- 专家资质:明确的专家认证标准和领域专业知识要求
- 审核标准:详细的审核清单和评分标准
- 反馈机制:建立标注人员与专家的沟通渠道
2.1.3 一致性检查
一致性检查通过自动化工具和统计分析确保标注结果的前后一致性和逻辑合理性。
- 规则引擎:建立可配置的一致性规则库
- 相似度检测:使用文本相似度算法识别相似内容
- 逻辑验证:基于领域知识的逻辑约束检查
- 趋势分析:监控标注质量的时间变化趋势
2.2 多样性考虑
2.2.1 领域覆盖广泛
确保数据集涵盖目标应用场景可能涉及的所有相关领域。
- 领域定义:明确定义目标领域范围和边界
- 分类体系:建立细粒度的领域分类体系
- 采样策略:基于领域重要性的分层采样
- 平衡考量:在领域覆盖和数据质量间取得平衡
2.2.2 文体类型多样
确保数据集包含各种文体类型,如新闻、对话、技术文档、社交媒体等。
- 文体分类:建立细粒度的文体分类体系
- 特征提取:基于语言特征进行文体识别
- 多样性度量:使用香农指数等指标量化多样性
- 采样优化:基于多样性分析优化数据收集
2.2.3 难度层次分明
确保数据集包含不同难度级别的样本,从简单到复杂形成梯度。
- 难度维度:从语言复杂度、上下文依赖、歧义性等多维度评估
- 分级标准:建立客观的难度分级标准
- 分布优化:基于学习曲线理论优化难度分布
- 渐进设计:确保难度梯度合理,支持渐进学习
六、案例展示
我们选择其中一个文本分类的任务来展示完整的评估流程,并详细说明如何在实际中使用CLUE基准进行评估,我们将以TNEWS(今日头条新闻分类)任务为例,展示如何加载数据、加载模型、进行预测和评估。
执行步骤:
-
- 安装必要的库
-
- 加载TNEWS数据集
-
- 加载预训练模型,示例采用bert-base-chinese模型
-
- 对测试集进行预测
-
- 使用CLUE官方评估脚本计算准确率
由于完整训练模型需要较长时间,我们这里只展示一个简单的示例,使用预训练模型进行预测,并计算准确率。
以下是完整的CLUE基准评估代码示例,包含数据集加载、模型评估、指标计算等完整流程:
1. 基础环境配置
python
# 1. 基础环境设置
import torch
import numpy as np
import pandas as pd
from typing import Dict, List, Any, Tuple
import logging
from tqdm import tqdm
from collections import defaultdict
import json
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("CLUE_Evaluator")2. CLUE数据集加载器
python
class CLUEDataLoader:
"""CLUE数据集加载器"""
def __init__(self, task_name: str, cache_dir: str = "./clue_data"):
self.task_name = task_name
self.cache_dir = cache_dir
self.dataset = None
self.label_mapping = {}
def load_dataset(self):
"""加载CLUE数据集"""
try:
from datasets import load_dataset
# CLUE数据集映射
clue_datasets = {
"tnews": "clue/tnews", # 新闻分类
"iflytek": "clue/iflytek", # 应用描述分类
"cmnli": "clue/cmnli", # 自然语言推理
"ocnli": "clue/ocnli", # 自然语言推理
"c3": "clue/c3", # 阅读理解
"cmrc2018": "clue/cmrc2018", # 阅读理解
"drcd": "clue/drcd", # 阅读理解
"chid": "clue/chid", # 成语填空
"csl": "clue/csl", # 论文关键词识别
}
if self.task_name not in clue_datasets:
raise ValueError(f"不支持的CLUE任务: {self.task_name}")
dataset_path = clue_datasets[self.task_name]
logger.info(f"正在加载数据集: {dataset_path}")
self.dataset = load_dataset(dataset_path, cache_dir=self.cache_dir)
logger.info(f"数据集加载成功: {self.dataset}")
# 构建标签映射
self._build_label_mapping()
return self.dataset
except ImportError:
logger.error("请先安装datasets库: pip install datasets")
raise
except Exception as e:
logger.error(f"数据集加载失败: {e}")
raise
def _build_label_mapping(self):
"""构建标签映射"""
if self.task_name == "tnews":
# TNEWS新闻分类标签
self.label_mapping = {
'100': 'news_story', '101': 'news_culture', '102': 'news_entertainment',
'103': 'news_sports', '104': 'news_finance', '106': 'news_house',
'107': 'news_car', '108': 'news_edu', '109': 'news_tech',
'110': 'news_military', '112': 'news_travel', '113': 'news_world',
'114': 'news_stock', '115': 'news_agriculture', '116': 'news_game'
}
elif self.task_name == "iflytek":
# IFLYTEK应用分类标签(简化版)
self.label_mapping = {str(i): f"app_{i}" for i in range(119)}
def get_train_data(self, sample_size: int = None):
"""获取训练数据"""
if self.dataset is None:
self.load_dataset()
data = self.dataset['train']
if sample_size:
data = data.select(range(min(sample_size, len(data))))
return data
def get_test_data(self, sample_size: int = None):
"""获取测试数据"""
if self.dataset is None:
self.load_dataset()
data = self.dataset['test']
if sample_size:
data = data.select(range(min(sample_size, len(data))))
return data
def get_validation_data(self, sample_size: int = None):
"""获取验证数据"""
if self.dataset is None:
self.load_dataset()
data = self.dataset['validation']
if sample_size:
data = data.select(range(min(sample_size, len(data))))
return data3. 评估指标计算器
python
class CLUEEvaluator:
"""CLUE评估指标计算器"""
@staticmethod
def calculate_accuracy(predictions: List, labels: List) -> Dict[str, float]:
"""计算准确率"""
correct = sum(1 for pred, label in zip(predictions, labels) if pred == label)
total = len(labels)
accuracy = correct / total if total > 0 else 0.0
return {
"accuracy": accuracy,
"correct": correct,
"total": total
}
@staticmethod
def calculate_f1_score(predictions: List, labels: List, average: str = 'macro') -> Dict[str, float]:
"""计算F1分数"""
from sklearn.metrics import f1_score, precision_score, recall_score
# 获取所有类别
all_labels = list(set(labels + predictions))
precision = precision_score(labels, predictions, labels=all_labels, average=average, zero_division=0)
recall = recall_score(labels, predictions, labels=all_labels, average=average, zero_division=0)
f1 = f1_score(labels, predictions, labels=all_labels, average=average, zero_division=0)
return {
"f1_score": f1,
"precision": precision,
"recall": recall,
"average_type": average
}
@staticmethod
def calculate_exact_match(predictions: List, labels: List) -> Dict[str, float]:
"""计算精确匹配率(用于阅读理解)"""
exact_matches = sum(1 for pred, label in zip(predictions, labels) if str(pred).strip() == str(label).strip())
total = len(labels)
em_score = exact_matches / total if total > 0 else 0.0
return {
"exact_match": em_score,
"exact_matches": exact_matches,
"total": total
}
@staticmethod
def calculate_classification_report(predictions: List, labels: List, target_names: List[str] = None) -> Dict:
"""生成详细分类报告"""
from sklearn.metrics import classification_report
report = classification_report(
labels, predictions,
target_names=target_names,
output_dict=True,
zero_division=0
)
return report
@staticmethod
def calculate_ner_metrics(predictions: List[List[str]], labels: List[List[str]]) -> Dict[str, float]:
"""计算NER任务的指标"""
from seqeval.metrics import f1_score, precision_score, recall_score, classification_report
# 使用seqeval库计算NER指标
precision = precision_score(labels, predictions)
recall = recall_score(labels, predictions)
f1 = f1_score(labels, predictions)
# 详细报告
detailed_report = classification_report(labels, predictions, output_dict=True)
return {
"ner_precision": precision,
"ner_recall": recall,
"ner_f1": f1,
"ner_report": detailed_report
}4. 基础模型评估器
python
class BaseModelEvaluator:
"""基础模型评估器"""
def __init__(self, model_name: str = "bert-base-chinese", device: str = "cpu"):
self.model_name = model_name
self.device = device
self.tokenizer = None
self.model = None
self._load_model()
def _load_model(self):
"""加载模型和tokenizer"""
try:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
logger.info(f"正在加载模型: {self.model_name}")
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
# 根据任务类型加载不同的模型
if "classification" in self.model_name.lower():
self.model = AutoModelForSequenceClassification.from_pretrained(
self.model_name,
num_labels=15 # 根据具体任务调整
)
else:
self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name)
self.model.to(self.device)
self.model.eval()
logger.info("模型加载成功")
except Exception as e:
logger.error(f"模型加载失败: {e}")
raise
def predict_single(self, text: str) -> Tuple[int, float]:
"""单条文本预测"""
try:
inputs = self.tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=512,
padding=True
)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = self.model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class = torch.argmax(predictions, dim=1).item()
confidence = torch.max(predictions).item()
return predicted_class, confidence
except Exception as e:
logger.error(f"预测失败: {e}")
return -1, 0.0
def predict_batch(self, texts: List[str], batch_size: int = 16) -> List[Tuple[int, float]]:
"""批量预测"""
predictions = []
for i in tqdm(range(0, len(texts), batch_size), desc="批量预测"):
batch_texts = texts[i:i+batch_size]
try:
inputs = self.tokenizer(
batch_texts,
return_tensors="pt",
truncation=True,
max_length=512,
padding=True
)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = self.model(**inputs)
batch_predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
batch_predicted_classes = torch.argmax(batch_predictions, dim=1).tolist()
batch_confidences = torch.max(batch_predictions, dim=1).values.tolist()
predictions.extend(zip(batch_predicted_classes, batch_confidences))
except Exception as e:
logger.error(f"批量预测失败: {e}")
# 为失败的预测添加默认值
predictions.extend([(-1, 0.0)] * len(batch_texts))
return predictions5. 完整CLUE评估流程
python
class CLUEBenchmark:
"""完整的CLUE基准评估流程"""
def __init__(self, task_name: str, model_name: str = "bert-base-chinese"):
self.task_name = task_name
self.model_name = model_name
self.data_loader = CLUEDataLoader(task_name)
self.evaluator = CLUEEvaluator()
self.model_evaluator = BaseModelEvaluator(model_name)
self.results = {}
def run_evaluation(self, sample_size: int = 1000) -> Dict[str, Any]:
"""运行完整评估流程"""
logger.info(f"开始CLUE评估 - 任务: {self.task_name}, 模型: {self.model_name}")
# 1. 加载数据
logger.info("步骤1: 加载数据集")
test_data = self.data_loader.get_test_data(sample_size)
# 2. 准备数据
logger.info("步骤2: 准备评估数据")
texts, true_labels = self._prepare_data(test_data)
# 3. 模型预测
logger.info("步骤3: 进行模型预测")
predictions = self.model_evaluator.predict_batch(texts)
predicted_classes = [pred[0] for pred in predictions]
confidences = [pred[1] for pred in predictions]
# 4. 计算指标
logger.info("步骤4: 计算评估指标")
self.results = self._calculate_metrics(predicted_classes, true_labels, confidences)
# 5. 生成报告
logger.info("步骤5: 生成评估报告")
self._generate_report()
logger.info("CLUE评估完成")
return self.results
def _prepare_data(self, dataset) -> Tuple[List[str], List[int]]:
"""准备评估数据"""
texts = []
labels = []
for item in dataset:
if self.task_name == "tnews":
texts.append(item['sentence'])
labels.append(int(item['label']))
elif self.task_name == "iflytek":
texts.append(item['sentence'])
labels.append(int(item['label']))
elif self.task_name in ["cmnli", "ocnli"]:
# 自然语言推理任务
texts.append(f"{item['sentence1']} [SEP] {item['sentence2']}")
labels.append(item['label'])
return texts, labels
def _calculate_metrics(self, predictions: List[int], true_labels: List[int], confidences: List[float]) -> Dict[str, Any]:
"""计算所有评估指标"""
metrics = {}
# 基础准确率
accuracy_result = self.evaluator.calculate_accuracy(predictions, true_labels)
metrics.update(accuracy_result)
# F1分数
f1_result = self.evaluator.calculate_f1_score(predictions, true_labels, average='macro')
metrics.update(f1_result)
# 详细分类报告
if hasattr(self.data_loader, 'label_mapping'):
target_names = list(self.data_loader.label_mapping.values())
else:
target_names = None
classification_report = self.evaluator.calculate_classification_report(
predictions, true_labels, target_names
)
metrics['classification_report'] = classification_report
# 置信度分析
metrics['confidence_analysis'] = self._analyze_confidence(confidences, predictions, true_labels)
return metrics
def _analyze_confidence(self, confidences: List[float], predictions: List[int], true_labels: List[int]) -> Dict[str, Any]:
"""分析模型置信度"""
correct_confidences = [conf for conf, pred, true in zip(confidences, predictions, true_labels) if pred == true]
wrong_confidences = [conf for conf, pred, true in zip(confidences, predictions, true_labels) if pred != true]
return {
"average_confidence": np.mean(confidences),
"average_correct_confidence": np.mean(correct_confidences) if correct_confidences else 0,
"average_wrong_confidence": np.mean(wrong_confidences) if wrong_confidences else 0,
"confidence_std": np.std(confidences),
"high_confidence_threshold": 0.8,
"high_confidence_accuracy": self._calculate_high_confidence_accuracy(confidences, predictions, true_labels)
}
def _calculate_high_confidence_accuracy(self, confidences: List[float], predictions: List[int], true_labels: List[int], threshold: float = 0.8) -> float:
"""计算高置信度样本的准确率"""
high_conf_indices = [i for i, conf in enumerate(confidences) if conf > threshold]
if not high_conf_indices:
return 0.0
high_conf_predictions = [predictions[i] for i in high_conf_indices]
high_conf_labels = [true_labels[i] for i in high_conf_indices]
correct = sum(1 for pred, label in zip(high_conf_predictions, high_conf_labels) if pred == label)
return correct / len(high_conf_indices)
def _generate_report(self):
"""生成评估报告"""
report = {
"task_name": self.task_name,
"model_name": self.model_name,
"evaluation_timestamp": pd.Timestamp.now().isoformat(),
"results": self.results
}
# 保存报告
filename = f"clue_evaluation_{self.task_name}_{pd.Timestamp.now().strftime('%Y%m%d_%H%M%S')}.json"
with open(filename, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2)
logger.info(f"评估报告已保存: {filename}")
# 打印摘要
self._print_summary()
def _print_summary(self):
"""打印评估摘要"""
print("\n" + "="*60)
print("CLUE基准评估摘要")
print("="*60)
print(f"任务名称: {self.task_name}")
print(f"模型名称: {self.model_name}")
print(f"评估时间: {pd.Timestamp.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("-"*60)
if 'accuracy' in self.results:
print(f"准确率: {self.results['accuracy']:.4f}")
if 'f1_score' in self.results:
print(f"F1分数: {self.results['f1_score']:.4f}")
if 'precision' in self.results:
print(f"精确率: {self.results['precision']:.4f}")
if 'recall' in self.results:
print(f"召回率: {self.results['recall']:.4f}")
if 'confidence_analysis' in self.results:
conf_analysis = self.results['confidence_analysis']
print(f"平均置信度: {conf_analysis['average_confidence']:.4f}")
print(f"高置信度准确率: {conf_analysis['high_confidence_accuracy']:.4f}")
print("="*60)6. 任务评估示例
python
# 6. 使用示例
def example_tnews_evaluation():
"""TNEWS任务评估示例"""
print("CLUE TNEWS任务评估示例")
print("="*50)
try:
# 创建评估器
benchmark = CLUEBenchmark("tnews", "bert-base-chinese")
# 运行评估(使用小样本加快速度)
results = benchmark.run_evaluation(sample_size=200)
# 显示详细结果
print("\n详细结果:")
print(f"测试样本数: {results.get('total', 0)}")
print(f"正确预测数: {results.get('correct', 0)}")
print(f"准确率: {results.get('accuracy', 0):.4f}")
print(f"宏平均F1: {results.get('f1_score', 0):.4f}")
# 显示分类报告摘要
if 'classification_report' in results:
report = results['classification_report']
print(f"\n各类别F1分数:")
for label, metrics in report.items():
if label not in ['accuracy', 'macro avg', 'weighted avg'] and 'f1-score' in metrics:
print(f" {label}: {metrics['f1-score']:.4f}")
except Exception as e:
print(f"评估过程出现错误: {e}")
def example_batch_evaluation():
"""批量评估多个任务"""
tasks = ["tnews", "iflytek"] # 可以扩展更多任务
for task in tasks:
print(f"\n正在评估任务: {task}")
print("-"*40)
try:
benchmark = CLUEBenchmark(task, "bert-base-chinese")
results = benchmark.run_evaluation(sample_size=100)
# 提取关键指标
accuracy = results.get('accuracy', 0)
f1_score = results.get('f1_score', 0)
print(f"{task} 任务结果:")
print(f" 准确率: {accuracy:.4f}")
print(f" F1分数: {f1_score:.4f}")
except Exception as e:
print(f"任务 {task} 评估失败: {e}")
# 7. 高级功能:模型比较
class ModelComparator:
"""模型比较器"""
def __init__(self, task_name: str):
self.task_name = task_name
self.results = {}
def compare_models(self, model_list: List[str], sample_size: int = 500):
"""比较多个模型"""
comparison_results = {}
for model_name in model_list:
print(f"\n评估模型: {model_name}")
try:
benchmark = CLUEBenchmark(self.task_name, model_name)
results = benchmark.run_evaluation(sample_size)
comparison_results[model_name] = {
'accuracy': results.get('accuracy', 0),
'f1_score': results.get('f1_score', 0),
'precision': results.get('precision', 0),
'recall': results.get('recall', 0)
}
except Exception as e:
print(f"模型 {model_name} 评估失败: {e}")
comparison_results[model_name] = None
# 生成比较报告
self._generate_comparison_report(comparison_results)
return comparison_results
def _generate_comparison_report(self, results: Dict):
"""生成模型比较报告"""
print("\n" + "="*60)
print("模型比较报告")
print("="*60)
print(f"任务: {self.task_name}")
print("-"*60)
# 创建比较表格
comparison_data = []
for model_name, metrics in results.items():
if metrics:
comparison_data.append({
'Model': model_name,
'Accuracy': f"{metrics['accuracy']:.4f}",
'F1-Score': f"{metrics['f1_score']:.4f}",
'Precision': f"{metrics['precision']:.4f}",
'Recall': f"{metrics['recall']:.4f}"
})
# 打印表格
df = pd.DataFrame(comparison_data)
print(df.to_string(index=False))
print("="*60)
# 8. 主函数
if __name__ == "__main__":
# 示例1: 单个任务评估
print("CLUE基准评估代码示例")
print("="*50)
# 运行TNEWS示例
example_tnews_evaluation()
# 示例2: 批量评估
# example_batch_evaluation()
# 示例3: 模型比较(取消注释运行)
# comparator = ModelComparator("tnews")
# models_to_compare = ["bert-base-chinese", "hfl/chinese-bert-wwm-ext"]
# comparison_results = comparator.compare_models(models_to_compare, sample_size=200)7. 评估结果可视化
python
# 9. 结果可视化(可选)
import matplotlib.pyplot as plt
import seaborn as sns
def visualize_results(results: Dict, task_name: str):
"""可视化评估结果"""
plt.figure(figsize=(12, 8))
# 1. 准确率和F1分数对比
plt.subplot(2, 2, 1)
metrics = ['accuracy', 'f1_score']
values = [results.get(metric, 0) for metric in metrics]
bars = plt.bar(metrics, values, color=['skyblue', 'lightcoral'])
plt.title(f'{task_name} - 主要指标')
plt.ylim(0, 1)
# 在柱状图上添加数值
for bar, value in zip(bars, values):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{value:.4f}', ha='center', va='bottom')
# 2. 置信度分布
plt.subplot(2, 2, 2)
if 'confidence_analysis' in results:
conf_data = results['confidence_analysis']
conf_categories = ['总体', '正确预测', '错误预测']
conf_values = [
conf_data.get('average_confidence', 0),
conf_data.get('average_correct_confidence', 0),
conf_data.get('average_wrong_confidence', 0)
]
plt.bar(conf_categories, conf_values, color=['lightgreen', 'green', 'red'])
plt.title('平均置信度对比')
plt.ylim(0, 1)
# 3. 各类别F1分数热力图
plt.subplot(2, 2, 3)
if 'classification_report' in results:
report = results['classification_report']
# 提取各类别F1分数
f1_scores = {}
for label, metrics in report.items():
if label not in ['accuracy', 'macro avg', 'weighted avg'] and 'f1-score' in metrics:
f1_scores[label] = metrics['f1-score']
if f1_scores:
labels = list(f1_scores.keys())[:10] # 只显示前10个类别
scores = [f1_scores[label] for label in labels]
# 创建热力图数据
heatmap_data = np.array(scores).reshape(1, -1)
sns.heatmap(heatmap_data, annot=True, fmt='.3f',
xticklabels=labels, yticklabels=['F1 Score'],
cmap='YlOrRd', cbar=True)
plt.title('各类别F1分数')
# 4. 模型置信度与准确率关系
plt.subplot(2, 2, 4)
if 'confidence_analysis' in results:
conf_thresholds = [0.5, 0.6, 0.7, 0.8, 0.9]
accuracies = []
# 这里需要原始数据来计算不同阈值下的准确率
# 在实际使用中,需要保存预测的详细信息
plt.plot(conf_thresholds, accuracies if accuracies else [0.7, 0.75, 0.8, 0.85, 0.9],
marker='o', linewidth=2)
plt.xlabel('置信度阈值')
plt.ylabel('准确率')
plt.title('置信度阈值 vs 准确率')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'clue_evaluation_{task_name}.png', dpi=300, bbox_inches='tight')
plt.show()
# 使用可视化功能
# benchmark = CLUEBenchmark("tnews", "bert-base-chinese")
# results = benchmark.run_evaluation(sample_size=200)
# visualize_results(results, "tnews")8. 关键特性说明
8.1 模块化设计
- CLUEDataLoader: 专门处理CLUE数据集加载
- CLUEEvaluator: 计算各种评估指标
- BaseModelEvaluator: 模型预测接口
- CLUEBenchmark: 完整的评估流程
8.2 完整的评估指标
- 准确率、精确率、召回率、F1分数
- 精确匹配率(阅读理解)
- NER任务的序列标注指标
- 置信度分析
七、总结
CLUE基准作为中文大模型评估的重要标准,不仅为技术发展提供了明确的导向,更为产业应用建立了可靠的质量保障体系。随着人工智能技术的不断演进,CLUE基准也将持续完善,更好地服务于大模型的研发和应用。
正如一句古语所说:"工欲善其事,必先利其器。"CLUE基准就是我们评估和提升大模型能力的利器。通过深入理解和有效利用这一工具,我们能够更好地推动中文自然语言处理技术的发展,让AI真正理解和服务中文世界。