目录
-
- 基座大模型的选择
- 企业应用大模型的方法
-
- [大模型 + 插件](#大模型 + 插件)
- [大模型 + 知识库](#大模型 + 知识库)
- [大模型 + Agent](#大模型 + Agent)
- 构建企业专属大模型
基座大模型的选择
选择基座大模型的考量因素
- 大模型的性能
- 首先评估通用大模型在各种自然语言处理任务上的性能
- 选择性能优异的大模型可以提高行业大模型的准确性和效率
- 大模型的预训练数据
- 考虑通用大模型的预训练数据范围和质量
- 涵盖广泛领域和语言的预训练数据集可以为行业大模型提供更丰富的背景知识
- 大模型的规模
- 考虑模型的大小,包括参数数量和计算资源需求
- 较大的模型可能提供更好的性能
- 大模型的开放性
- 选择一个开源、可商用的大模型作为基座,可以更容易地进行定制和商业开发
- 语言支持
- 如果行业大模型需要支持某种特定语言,那么通用大模型本身应该具备该语言能力
典型的通用大模型
| 模型名称 | 核心信息 |
|---|---|
| ERNIE | - 百度自研大语言模型 - 覆盖海量中文数据 - 擅长对话问答、内容创作生成等能力 |
| Llama | - Meta推出的开源大语言模型 - 有不同参数规模版本 - 在多个基准测试中表现出色 |
| ChatGLM | - 清华大学+智谱AI联合开发的对话语言模型 - 具备文案写作、信息抽取、角色扮演、问答和对话等能力 |
| Baichuan | - 百川智能推出的开源大语言模型系列 - 采用高质量多语言语料训练 |
| BLOOM | - BigScience社区开发的开源多语言大模型 - 可进一步微调以适配特定任务 |
企业应用大模型的方法
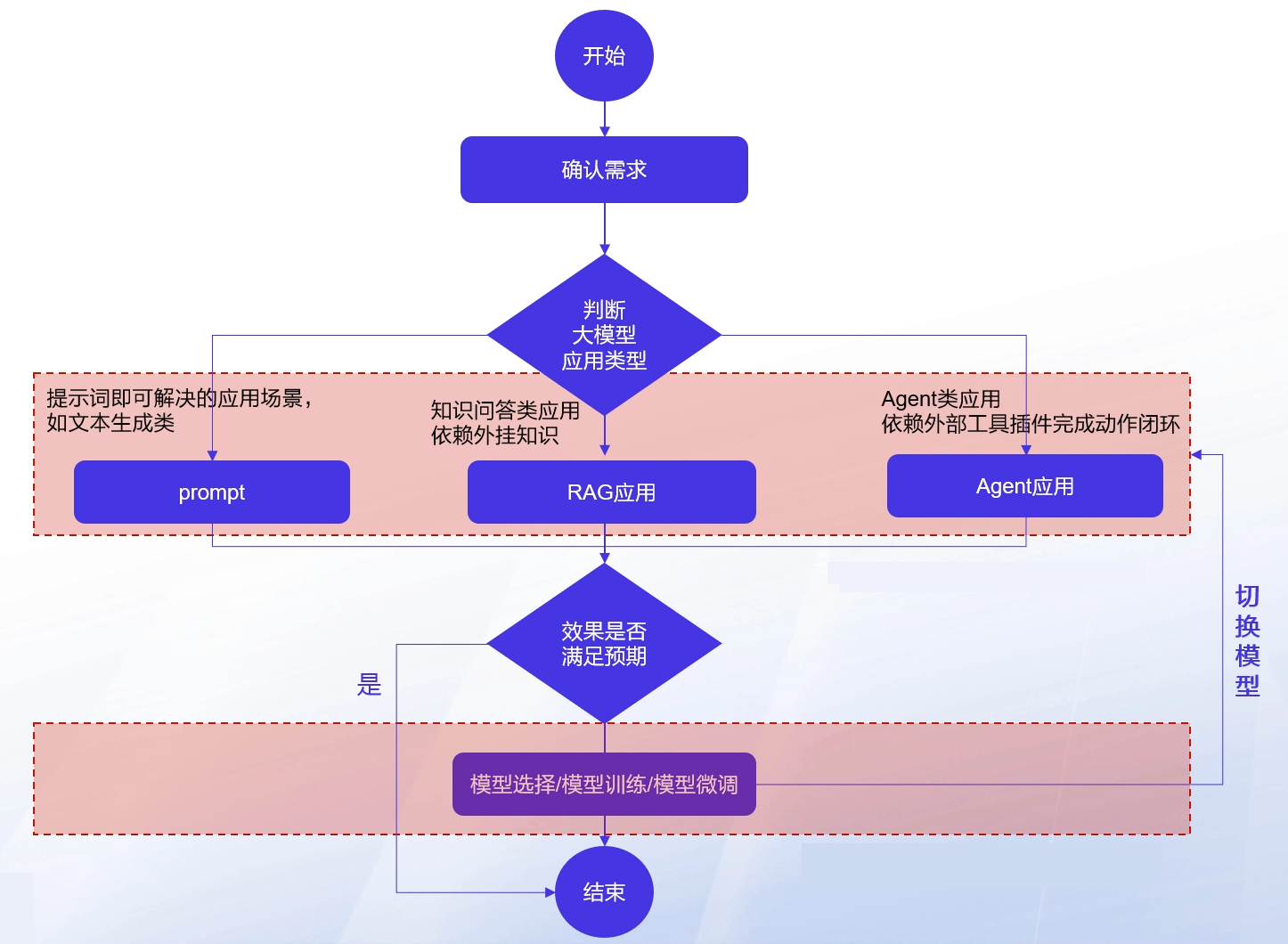
大模型 + 插件
插件是一种将外部能力与大语言模型相结合的机制,可以帮助大模型访问最新信息、运行计算或使用第三方服务,比如访问网络、访问文档、与第三方应用相连接、绘图等。
- 信息增强
- 交互增强
- 服务增强
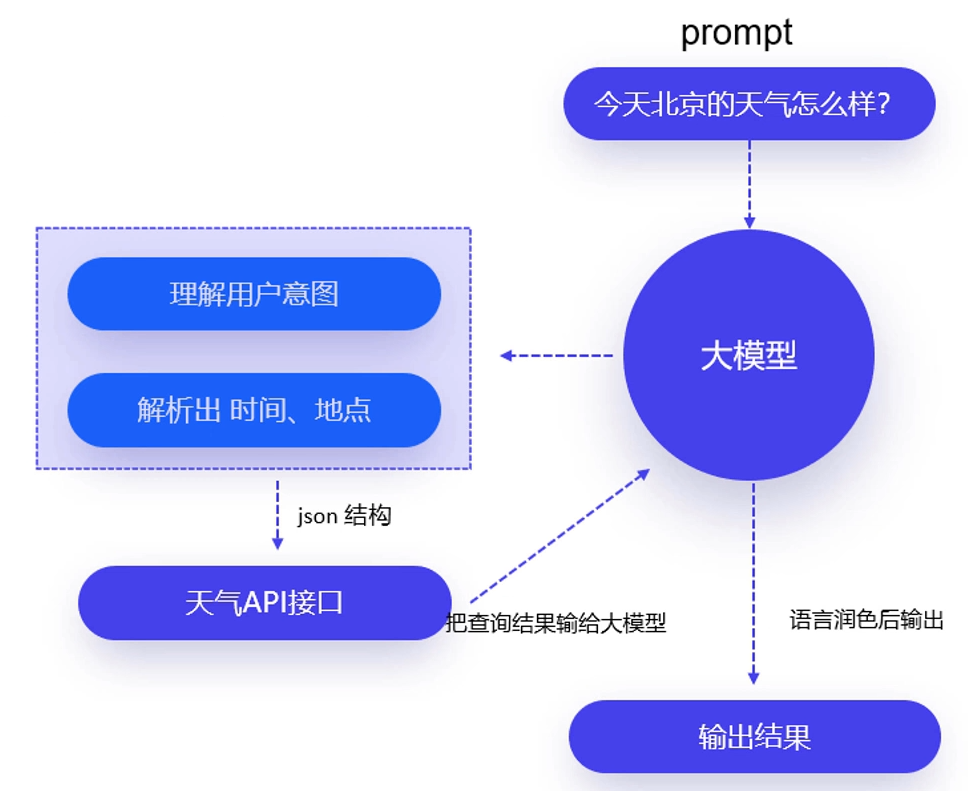
大模型 + 知识库
为了增强大模型处理和回答问题的能力,可以搭建外部知识库,通过外部知识库中的数据来提供额外的知识支持,具有增强知识覆盖、提升准确性和可靠性、获取实时信息、整合特定领域知识、数据更安全等特点。
- 并未修改大模型本身的参数
- 利用检索技术从外部知识库中召回与问题相关的信息
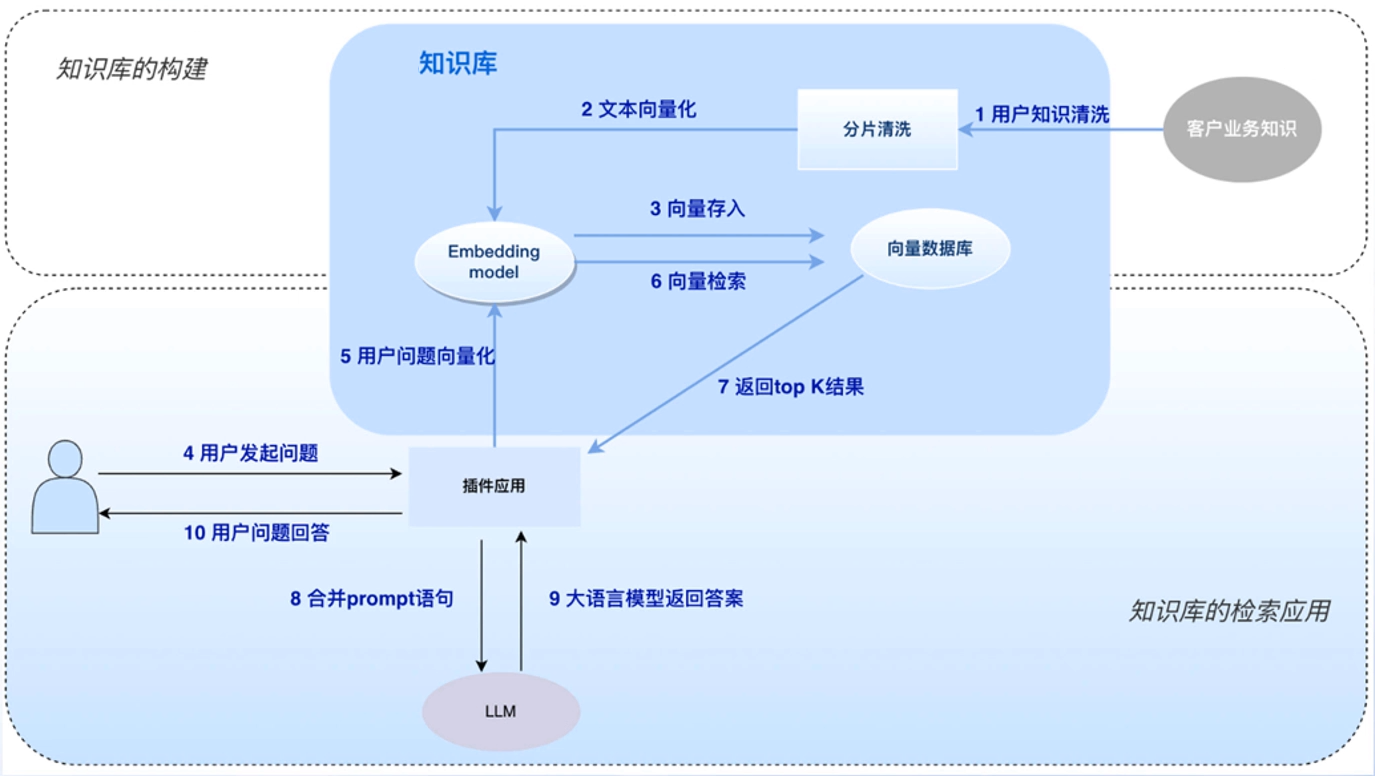
大模型 + Agent
Agent是以大模型为基础,构建的可以进行复杂交互、完成特定任务、或在特定领域内提供专业知识的智能系统或应用程序,结合了大语言模型的强大处理能力和智能代理的自主决策能力,以实现更复杂更高效的任务处理。
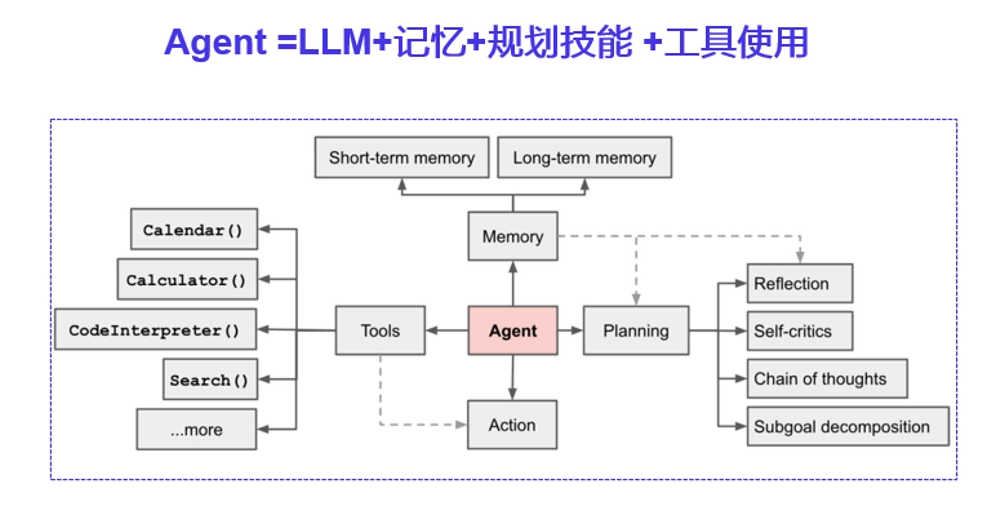
构建企业专属大模型
