muti-Agent+RAG+KnowledgeGraph这套架构是目前 AI 领域最前沿的 GraphRAG (Graph-based Retrieval Augmented Generation) 的进化版。
-
Agent (大脑与手): 现有的框架(LangGraph, AutoGen, CrewAI)已经能够很好地支持多 Agent 协作。你可以定义"分诊台 Agent"、"内科医生 Agent(查日志)"、"外科医生 Agent(查代码)"。
- 可行性状态: 成熟,只需关注 Token 消耗和上下文超长问题。
-
RAG (记忆): 向量检索技术(Milvus, Chroma, ES)非常成熟。对于非结构化的《运维手册》、《历史故障复盘》,RAG 是最佳方案。
- 可行性状态: 非常成熟。
-
Knowledge Graph (逻辑地图): 图数据库(Neo4j, NebulaGraph)是成熟产品。
- 挑战点: 如何将非结构化数据自动转化为图谱(Text-to-Graph)是当前难点,但利用 LLM 进行实体抽取(NER)和关系抽取(RE)的准确率已达到可用级别。
|-----------------|------------|----------------|-------------------------------------------|
| 组件 | 优势 | 劣势 | 组合后的化学反应 |
| LLM (Agent) | 通用推理,能听懂人话 | 容易产生幻觉,不懂私有架构 | Agent + KG: 不会瞎猜,沿着图谱的边(依赖关系)去推理。 |
| RAG | 记忆力好,能找文档 | 缺乏逻辑,看不懂"蝴蝶效应" | RAG + KG: 不仅搜到"报错含义",还能搜到"导致报错的上游服务"。 |
| KG | 逻辑严密,关系清晰 | 构建成本高,泛化能力弱 | KG + LLM: 让 LLM 帮你自动构建图谱,降低成本。 |
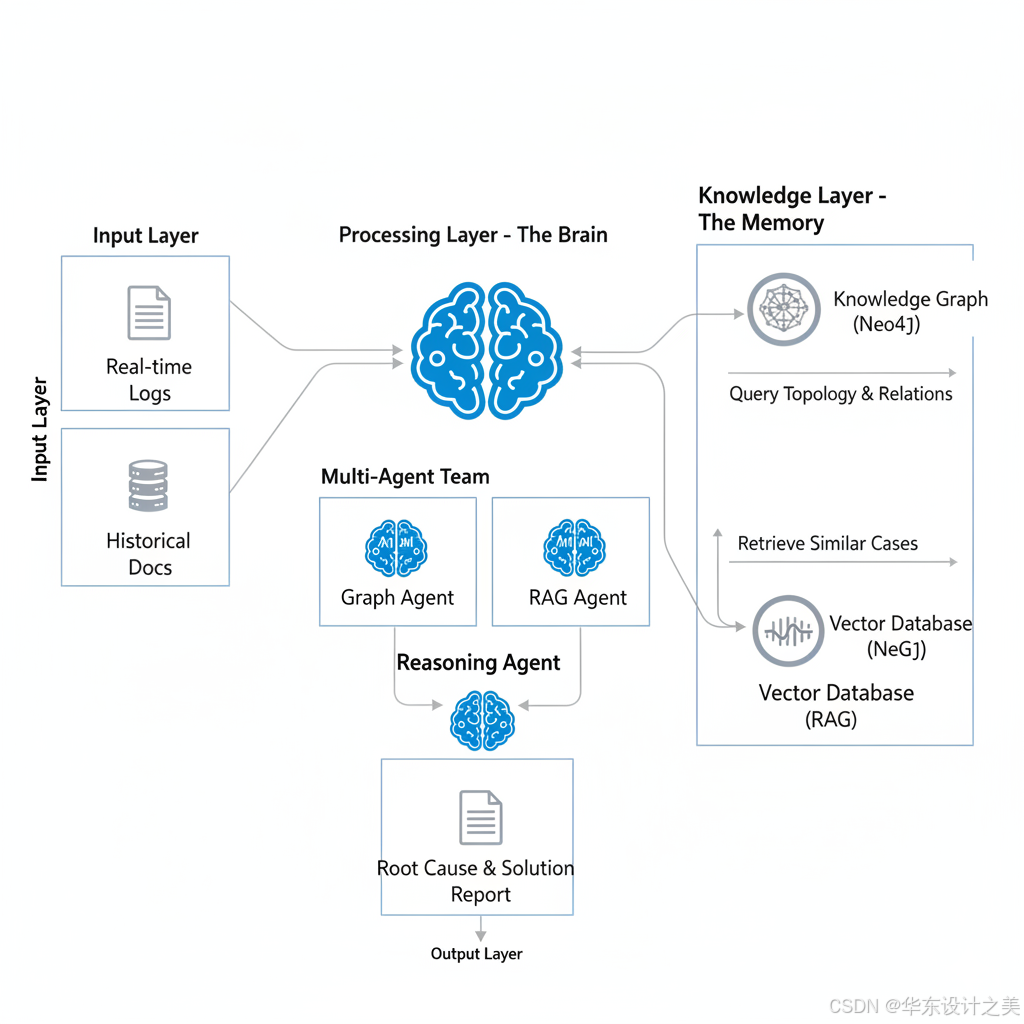
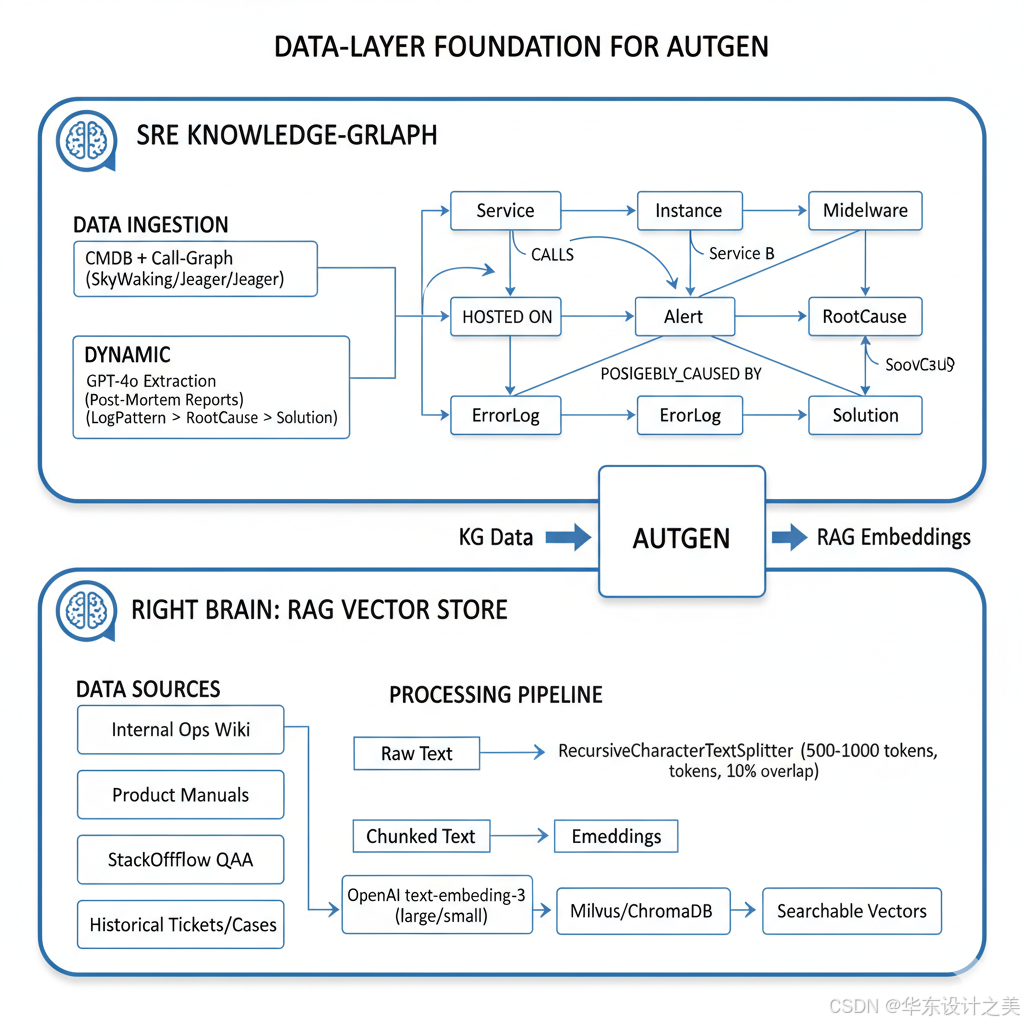
一、 数据层构建 (The Foundation)
在 AutoGen 运行之前,必须先准备好"左脑(图谱)"和"右脑(向量库)"。
1. 知识图谱 (KG) 构建:聚焦"故障根因"
这里不建议构建大而全的通用图谱,应构建 "运维排障专用图谱"。
-
Schema 定义 (本体设计):
-
实体 (Nodes):
-
Service (微服务), Instance (实例IP), Middleware (Redis/MySQL).
-
Alert (告警规则), ErrorLog (错误日志模式).
-
RootCause (根因类型, 如: OOM, Network Congestion, Config Error).
-
Solution (解决方案).
-
-
关系 (Edges):
-
拓扑: (Service A)-CALLS->(Service B), (Service)-HOSTED_ON->(Host).
-
因果: (ErrorLog)-POSSIBLY_CAUSED_BY->(RootCause).
-
修复: (RootCause)-SOLVED_BY->(Solution).
-
-
-
数据灌入:
-
静态数据: 同步 CMDB 和调用链(SkyWalking/Jaeger)数据,生成拓扑关系。
-
动态经验: 使用 GPT-4o 分析历史 Post-mortem(复盘报告),提取 (Log Pattern) -> (Root Cause) -> (Solution) 三元组存入 Neo4j。
-
2. RAG 向量库构建:text-embedding-3
-
数据源: 运维 Wiki、产品手册、StackOverflow 爬取的特定组件问答、历史工单记录。
-
分词与 Embedding:
-
Chunking: 建议使用 RecursiveCharacterTextSplitter,Chunk size 设为 500-1000 tokens,保留 10% overlap。
-
Model: 调用 OpenAI text-embedding-3-large (性能更优) 或 small (成本更低)。
-
Storage: 存入 Milvus 或 ChromaDB。
-
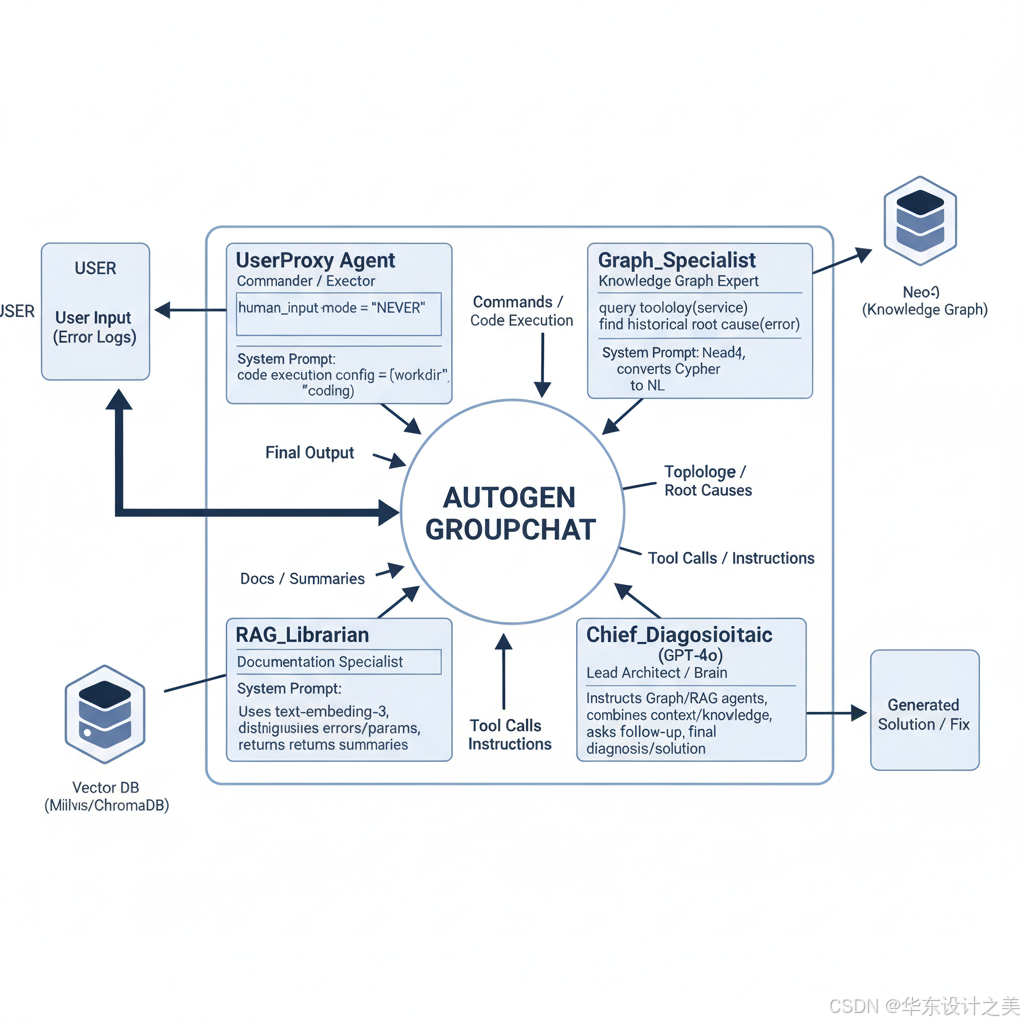
二、 AutoGen Agent 角色定义 (The Team)
我们需要在 AutoGen 中定义一个 GroupChat,包含以下核心角色。
1. UserProxy Agent (指挥官/执行者)
-
职责: 接收用户输入的报错日志;执行代码(如查询数据库、执行 Python 脚本);终止对话。
-
配置: human_input_mode="NEVER", code_execution_config={"work_dir": "coding"}.
2. Graph_Specialist (图谱专家)
-
职责: 负责与 Neo4j 交互,查询拓扑结构和关联故障。
-
核心能力 (Function Calling):
-
query_topology(service_name): 查询上下游依赖。
-
find_historical_root_cause(error_message): 在图谱中匹配相似错误的根因节点。
-
-
System Prompt: "你是一名运维图谱专家。当需要了解服务依赖关系或查找历史上的结构化因果关系时,请调用工具查询 Neo4j。请将 Cypher 查询结果转化为自然语言解释。"
3. RAG_Librarian (文档专员)
-
职责: 负责向量检索,查找非结构化文档。
-
核心能力 (Function Calling):
- search_knowledge_base(query_string): 对输入文本进行 Embedding 并检索 Top-K 文档。
-
System Prompt: "你是一名知识库管理员。利用 text-embedding-3 检索相关运维手册。请区分'日志报错'和'配置参数',提供准确的参考文档摘要。"
4. Chief_Diagnostician (主治医师 - GPT-4o)
-
职责: 它是 GroupChat 的核心大脑。它不直接操作数据库,而是分析其他 Agent 的返回结果,进行推理,给出最终方案。
-
System Prompt: "你是首席架构师。收到报错后,先指挥 Graph Agent 查拓扑,再指挥 RAG Agent 查文档。结合 拓扑上下文 和 文档知识,进行逻辑推理。如果信息不足,继续追问;如果确认根因,输出最终解决方案。"
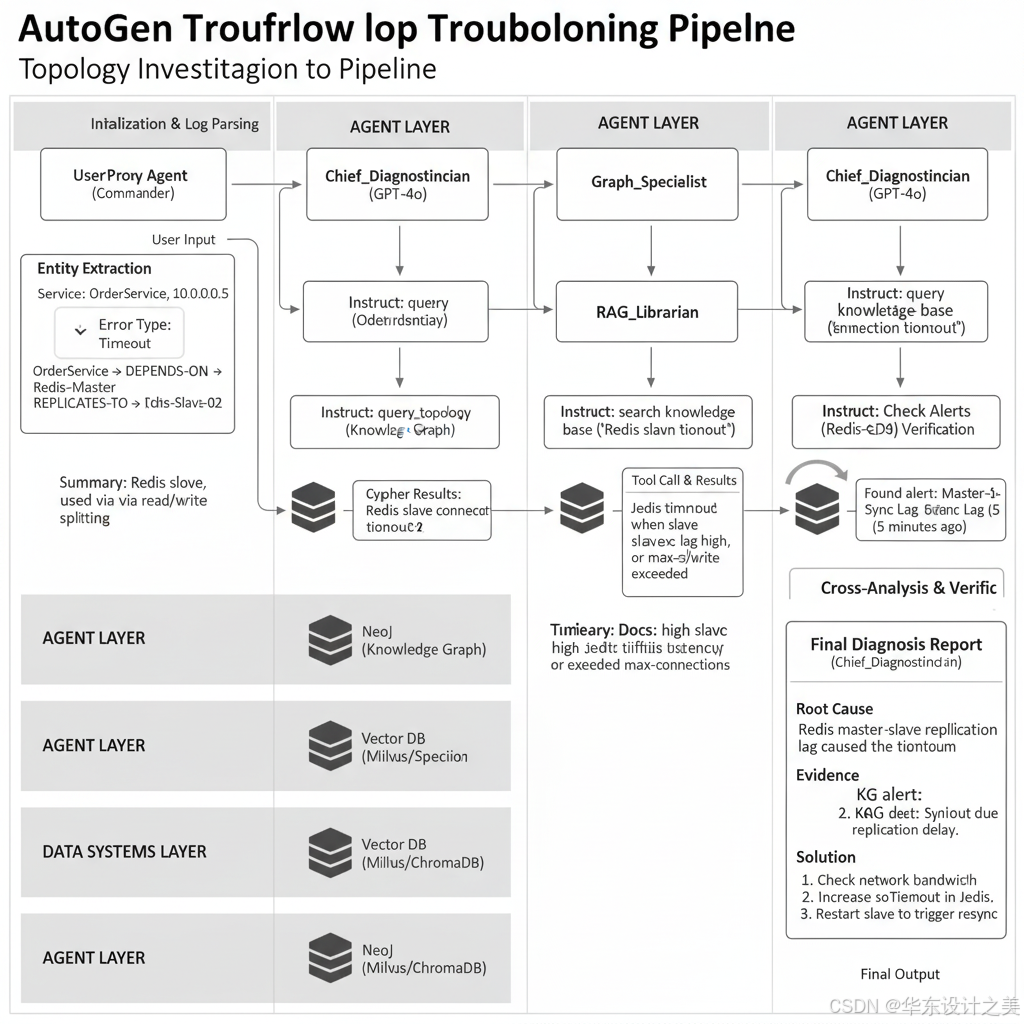
三、 完整纠错诊错工作流 (The Workflow)
假设输入报错:Error OrderService connection timeout to 10.0.0.5
Step 1: 初始化与初步解析
-
UserProxy 发起对话,传入日志。
-
Diagnostician (GPT-4o) 分析日志,识别出实体 OrderService 和 10.0.0.5,以及错误类型 Timeout。
Step 2: 图谱拓扑侦查 (Knowledge Graph)
-
Diagnostician 指示: "Graph_Specialist, find out what 10.0.0.5 is and its relation to OrderService."
-
Graph_Specialist 调用 query_topology (Text-to-Cypher)。
- Neo4j 返回: 10.0.0.5 is Redis-Slave-02. Relationship: OrderService -> DEPENDS_ON -> Redis-Master -> REPLICATES_TO -> Redis-Slave-02.
-
Graph_Specialist 回复: "目标 IP 是 Redis 从节点。OrderService 并不直接连接它,可能是读写分离配置。"
Step 3: 知识检索与经验匹配 (RAG)
-
Diagnostician 思考: "Redis 从节点连接超时?可能是网络问题,也可能是配置问题。RAG_Librarian, search for 'Redis slave connection timeout' issues."
-
RAG_Librarian 调用 search_knowledge_base。
- VectorDB 返回: 检索到一篇《Redis 读写分离常见坑》,文中提到 "Jedis 客户端在从节点同步延迟过高时会报连接超时"。
-
RAG_Librarian 回复: "根据文档,Jedis 客户端在从库同步延迟高或 max-connection 满时会报超时。"
Step 4: 综合推理与验证 (Reasoning)
-
Diagnostician 综合信息:
-
事实1 (KG): 这是一个 Redis 从库。
-
事实2 (RAG): 同步延迟可能导致此错误。
-
-
Diagnostician 再次指示 Graph_Specialist: "查询图谱中该 Redis 节点最近是否有 'High Latency' 或 'Sync Error' 的告警节点。"
-
Graph_Specialist 查询并返回: "发现 5 分钟前该节点关联了 'Master-Slave Sync Lag' 告警。"
Step 5: 生成解决方案 (Solution)
-
Diagnostician 输出最终报告:
-
根因: Redis 主从同步延迟过高,导致读写分离客户端连接超时。
-
证据: 图谱显示存在同步延迟告警,RAG 文档支持该理论。
-
解决方案: 1. 检查主从网络带宽;2. 临时调大 Jedis 的 soTimeout;3. 重启从节点触发全量同步。
-
伪代码:
python
import autogen
from autogen import UserProxyAgent, AssistantAgent, GroupChat, GroupChatManager
from openai import OpenAI
# 1. 配置 GPT-4o
config_list = [{"model": "gpt-4o", "api_key": "sk-..."}]
llm_config = {"config_list": config_list, "temperature": 0}
# 2. 定义工具函数 (Tools)
def query_neo4j(cypher: str):
# 连接 Neo4j 执行 Cypher
# 返回 JSON 结果
pass
def rag_search(query: str):
# 1. 使用 text-embedding-3 将 query 向量化
# 2. 在 ChromaDB/Milvus 中搜索 Top-k
# 3. 返回 Context String
pass
# 3. 定义 Agents
# A. 用户代理 (触发器)
user_proxy = UserProxyAgent(
name="User_Proxy",
human_input_mode="NEVER",
code_execution_config={"work_dir": "coding", "use_docker": False}
)
# B. 图谱专家 (挂载 Neo4j 工具)
graph_agent = AssistantAgent(
name="Graph_Specialist",
llm_config=llm_config,
system_message="你是图谱专家。将用户问题转化为 Cypher 语句查询 Neo4j。关注服务依赖关系和历史根因链。"
)
autogen.agent_utils.register_function(
query_neo4j, caller=graph_agent, executor=user_proxy, description="Execute Cypher query"
)
# C. RAG 专员 (挂载向量检索工具)
rag_agent = AssistantAgent(
name="RAG_Librarian",
llm_config=llm_config,
system_message="你是文档检索专家。使用 search_tool 查找相关运维文档和案例。"
)
autogen.agent_utils.register_function(
rag_search, caller=rag_agent, executor=user_proxy, description="Vector search for docs"
)
# D. 主诊医生 (大脑)
doctor_agent = AssistantAgent(
name="Chief_Diagnostician",
llm_config=llm_config,
system_message="""
你是首席运维诊断专家。你需要协调 Graph_Specialist 和 RAG_Librarian。
1. 首先让 Graph_Specialist 确认报错实体的拓扑位置。
2. 然后让 RAG_Librarian 查找相关错误文档。
3. 结合两者信息,进行逻辑推理。
4. 输出最终根因分析和解决方案。
"""
)
# 4. 创建 GroupChat
groupchat = GroupChat(
agents=[user_proxy, graph_agent, rag_agent, doctor_agent],
messages=[],
max_round=10
)
manager = GroupChatManager(groupchat=groupchat, llm_config=llm_config)
# 5. 启动流程
error_log = "Error: Database connection pool exhaustion on Service-Payment, target: 192.168.1.20"
user_proxy.initiate_chat(manager, message=error_log)四、 关键技术难点与优化点
-
Text-to-Cypher 的准确率:
-
难点: LLM 直接生成的 Cypher 语法可能错误,或者字段名对不上。
-
优化: 在 Graph_Specialist 的 Prompt 中放入 Schema 示例(Few-Shot Learning)。或者在 Python 函数中增加一层校验逻辑,如果 Cypher 报错,把错误信息返给 LLM 让它重写。
-
-
RAG 的噪声过滤:
-
难点: text-embedding-3 可能检索到虽然语义相似但版本不同(如 Java 8 vs Java 17)的无效文档。
-
优化: 利用 KG 中的实体属性(如 version: 1.8)作为 Metadata Filter 传给向量数据库,进行混合检索 (Hybrid Search)。
-
-
Agent 陷入死循环:
-
难点: 两个 Agent 互相推诿,或者查不到数据时反复重试。
-
优化: 在 GroupChatManager 的 Prompt 中明确"如果两轮查询无果,直接根据现有信息给出推测性建议,并停止对话"。
-