JDK 15 新变化之文本块(Text Blocks)
背景
JDK 15 正式支持文本块(Text Blocks),JEP 378: Text Blocks 一文中有详细的描述,本文会对文本块(Text Blocks)中的缩进、转义字符等处理细节进行探讨。
要点
文本块(Text Blocks)对格式有要求
文本块(Text Blocks)的格式有特殊之处,例如在三个双引号开启文本块的那一行,文本块中不能有非 white space 字符 ⬇️
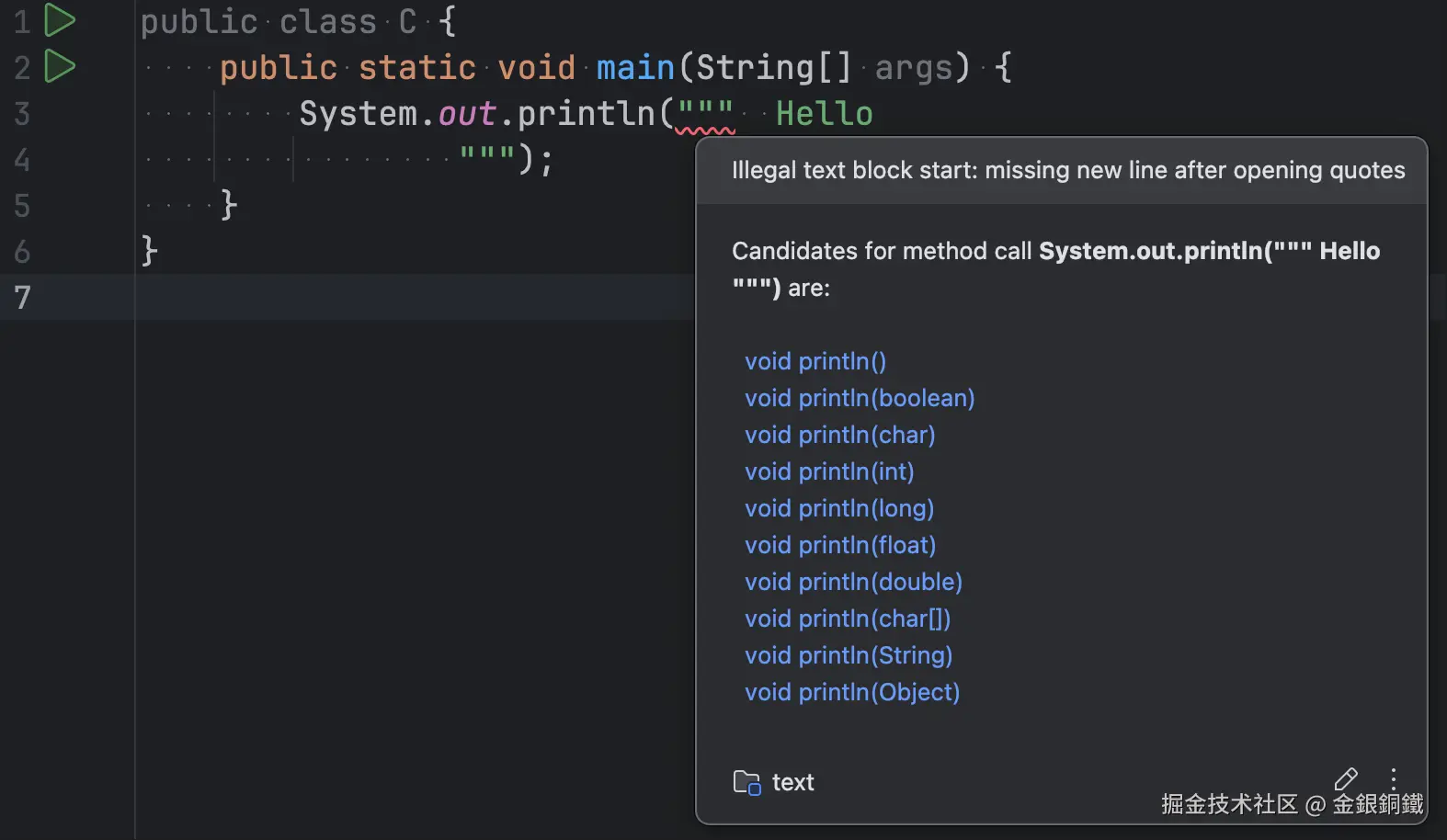
Java 编译器会移除文本块的内容中的次要 white space
Java 编译器会使用 re-indentation 算法对文本块的内容中的次要 white space 进行处理。以下图为例,代码中的第 4 行和第 5 行中都有 white space(图中展示为 .),但是在输出中,这些 white space 都消失了,这是因为 Java 编译器移除了文本块中的次要 white space。
文本块中可以使用转义序列
文本块中除了支持 The Java Language Specification 的 3.10.6 小节 里列举的转义序列外,还新增了对下列 2 个转义序列的支持。
\<line-terminator>\s它会转换成一个空格(U+0020)
我画了张思维导图 ⬇️
正文
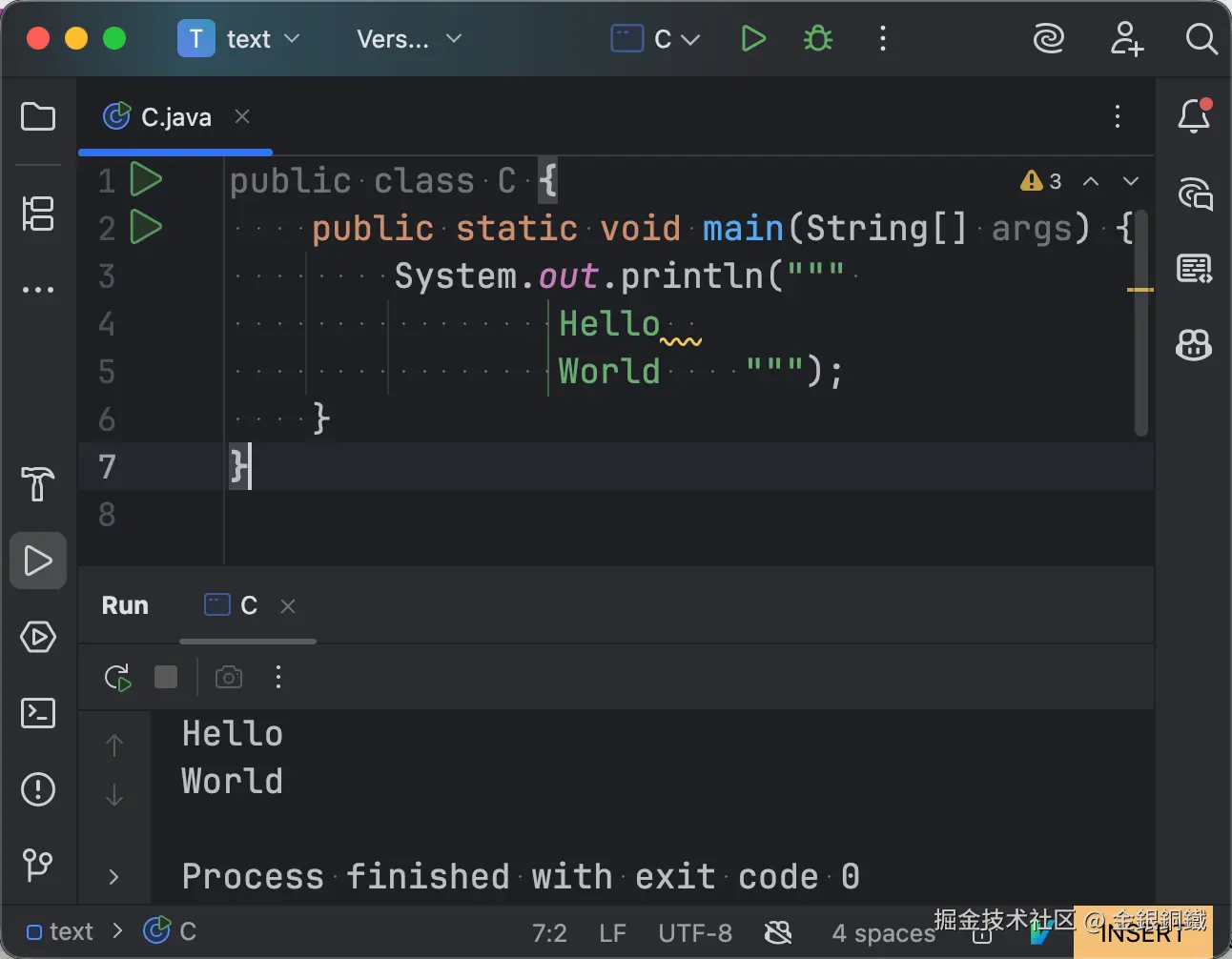
JDK 15 正式支持文本块(Text Blocks),JEP 378: Text Blocks 一文中有详细的描述,有兴趣的读者可以读一读。于是,原先这样的代码 ⬇️
java
String html = "<html>\n" +
" <body>\n" +
" <p>Hello, world</p>\n" +
" </body>\n" +
"</html>\n";如果改用文本块,可以变为这样 ⬇️
java
String html = """
<html>
<body>
<p>Hello, world</p>
</body>
</html>
""";在此基础上,我们可以写出如下的代码 ⬇️
java
public class A {
public static void main(String[] args) {
String html = """
<html>
<body>
<p>Hello, world</p>
</body>
</html>
""";
System.out.println(html);
}
}请将以上代码保存为 A.java。用如下的命令可以编译 A.java 并运行其中的 main 方法。
bash
javac A.java
java A运行结果如下 ⬇️
text
<html>
<body>
<p>Hello, world</p>
</body>
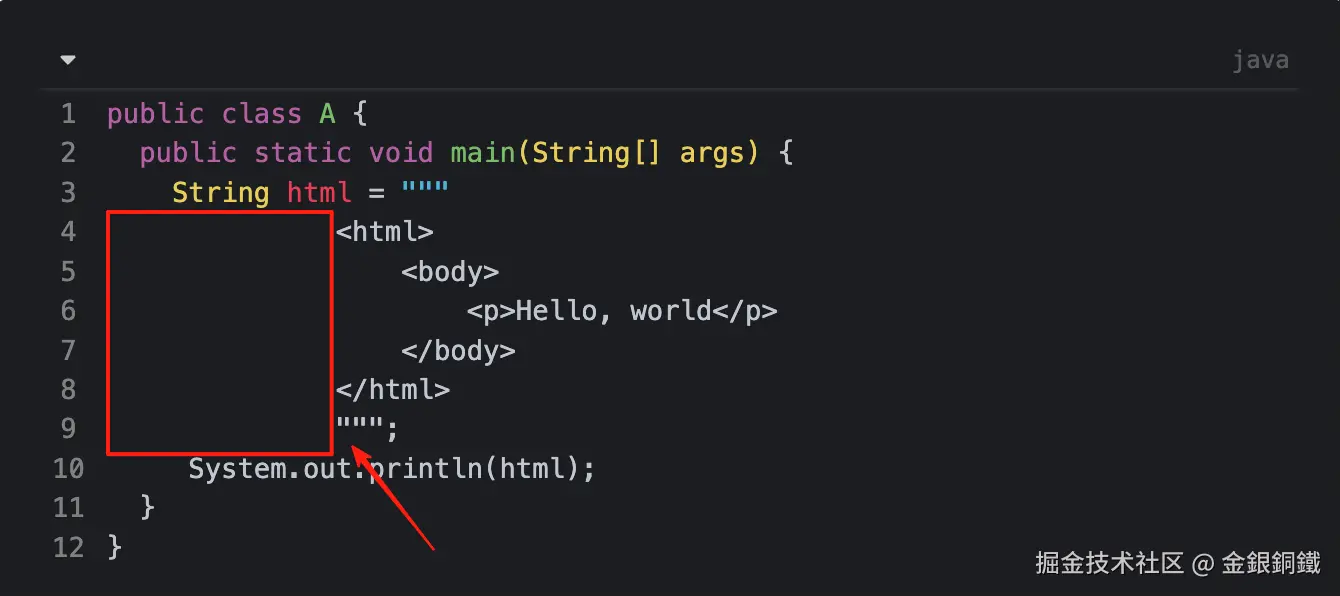
</html>从运行结果来看,源码中的一些空格(U+0020)消失了(这些空格的具体位置如下图红框所示)
这其中的处理细节是怎样的呢?不难联想到以下问题
- 只有空格(
U+0020)会被特殊处理吗,是否还有其他字符也会被特殊处理? - 只有行首的空格(
U+0020)会被特殊处理吗,行尾的空格(U+0020)会被特殊处理吗? - 移除的空格(
U+0020)的数量是如何计算的?
这些问题在 JEP 378: Text Blocks 一文中都可以找到答案。
文本块(Text Blocks)的范围
在讨论其他问题之前,我们先来明确一下文本块(Text Blocks)的范围。在 JEP 378: Text Blocks 一文的 Description 小节里,有如下的描述,我们着重看一下红框里的部分。 
我将红框里的内容翻译如下 ⬇️
一个文本块(
Text Blocks)由 0 个或者更多个字符组成,它被opending delimiter和closing delimiter所包围。
opending delimiter由以下三部分组成
- 3 个连续的双引号字符(即,
""")- 紧随其后的 0 个或者更多个
white space- 紧随其后的
line terminator
文本块的内容开始于opending delimiter里的line terminator之后的第一个字符。closing delimiter是 3 个连续的双引号字符(即,""")。文本块的内容结束于closing delimiter里第一个双引号字符之前的最后一个字符。
这样说有点抽象,我来举个具体的例子 ⬇️
java
public class B {
public static void main(String[] args) {
String html = """
something
""";
System.out.println(html);
}
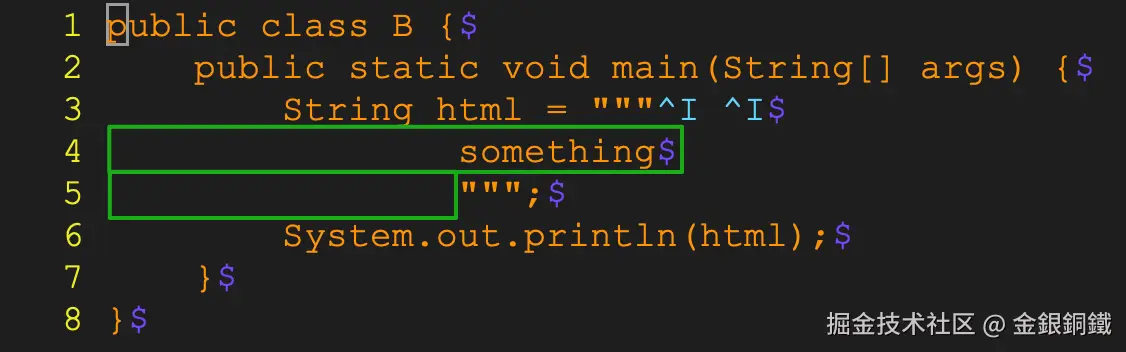
}上面这段代码里有些特殊的字符,我通过 vim 打开这段代码后,截了张图,效果如下 ⬇️ 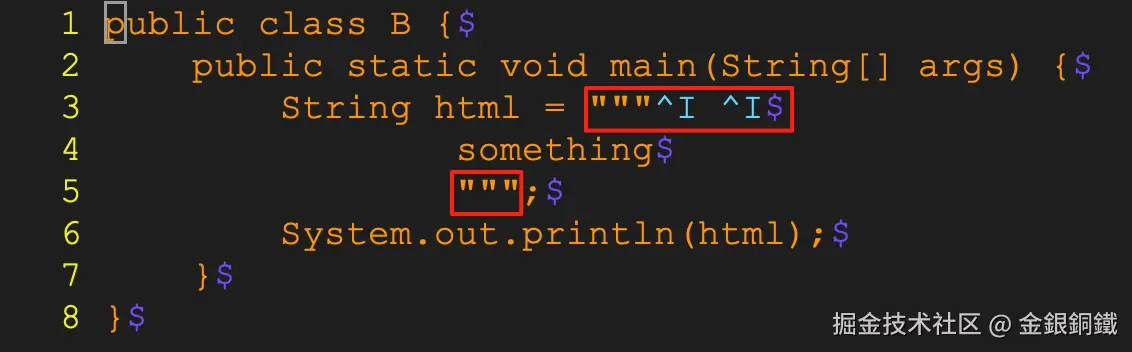 第 3 行的红框里是
第 3 行的红框里是 opening delimiter。请注意,它除了包含 3 个双引号字符外,还包含了
- 1 个
tab字符(U+0009,图中展示成^I) - 1 个 空格字符(
U+0020) - 1 个
tab字符(U+0009,图中展示成^I) - 1 个
line terminator(图中展示为$,在我的电脑上,line terminator是U+000A字符)
第 5 行的红框里是 closing delimiter。它只包含 3 个双引号字符。下图中两个绿色框所展示的就是文本块的内容。
下方是几个格式 有问题 的文本块(它们都来自 JEP 378: Text Blocks 一文)
java
String a = """"""; // no line terminator after opening delimiter
String b = """ """; // no line terminator after opening delimiter
String c = """
"; // no closing delimiter (text block continues to EOF)
String d = """
abc \ def
"""; // unescaped backslash (see below for escape processing)编译时的处理
在 JEP 378: Text Blocks 一文的 Compile-time processing 小节描述了编译时对文本块的处理,其中的部分内容如下 ⬇️
Compile-time processing
A text block is a constant expression of type
String, just like a string literal. However, unlike a string literal, the content of a text block is processed by the Java compiler in three distinct steps:
- Line terminators in the content are translated to LF (
\u000A). The purpose of this translation is to follow the principle of least surprise when moving Java source code across platforms.- Incidental white space surrounding the content, introduced to match the indentation of Java source code, is removed.
- Escape sequences in the content are interpreted. Performing interpretation as the final step means developers can write escape sequences such as
\nwithout them being modified or deleted by earlier steps.
我将其翻译如下 ⬇️
编译时的处理
像字符串字面值一样,文本块是
String类型的 常量表达式。 但与字符串字面值不同的是,Java编译器会用以下 3 步来处理文本块的内容:
- 文本块的内容中的
line terminator会被转化为LF字符 (U+000A)。在不同平台迁移Java源代码时,需要遵循最小惊讶原则(the principle of least surprise),所以才有这样的转化步骤。- 文本块的内容中,为了匹配
Java源代码中的缩进的那些次要的white space会被移除。- 文本块的内容中的转义序列会被解释。解释转移序列这一步被放在最后,这可以保证开发者能正常使用
\n之类的转移序列(而不会被前面两步所影响)。
JEP 378: Text Blocks 中对这 3 步分别做了详细的解释,我结合自己的理解,写了如下的内容
第 1 步:关于 line terminator 的处理
在有的平台上,line terminator 是 CR(U+000D),在有的平台上是 CR(U+000D) 和 LF(U+000A),Java 编译器会将它们转化为 LF(\u000A)。\n(LF),\f(FF),\r(CR) 之类的转义序列 不会 在这一步被解释,转义序列的处理在第 3 步。
第 2 步:次要 white space 字符的处理
如果有用户想从如下的写法(以下简称为"写法一")
java
String html = "<html>\n" +
" <body>\n" +
" <p>Hello, world</p>\n" +
" </body>\n" +
"</html>\n";改成文本块方式的写法(以下简称为"写法二"),
java
String html = """
<html>
<body>
<p>Hello, world</p>
</body>
</html>
""";那么我们可以将其视为一次迁移,迁移过程中自然希望字符串的内容可以保持完全不变。为了让空格(U+0020)变得容易辨认,下面这段代码里用 . 字符来表示空格(U+0020)
java
String html = """
..............<html>
.............. <body>
.............. <p>Hello, world</p>
.............. </body>
..............</html>
..............""";有些时候,文本块的内容可能是从其他地方复制过来的,复制过程中,在某些行的末尾(有意地或无意地)多加一些空格(U+0020)也是常见的情况。甚至被复制的文本本身就有在行尾的多余空格。所以在日常开发的过程中,代码也许会变成这样 ⬇️ (为了让空格变得容易辨认,下面这段代码里用 . 字符来表示空格)
java
String html = """
..............<html>...
.............. <body>
.............. <p>Hello, world</p>....
.............. </body>.
..............</html>...
..............""";一般来说,我们并不需要下图红框所示的这些空格。
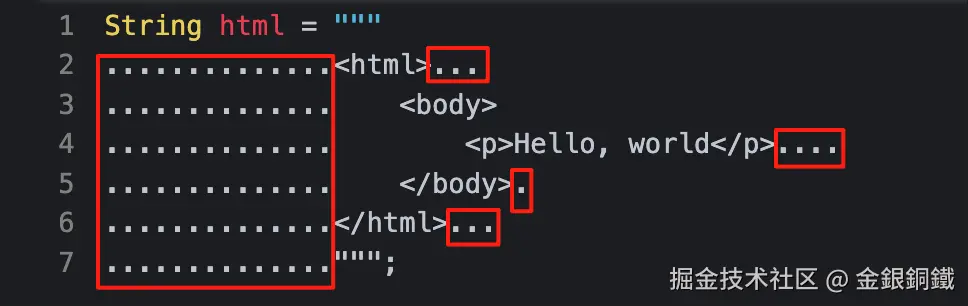
如果保留这些空格的话,那么最终得到的字符串会和"方式一"中得到的字符串有差异(例如长度,hashCode 都会不同)。所以我们希望 java 编译器可以把这些次要的空格(更一般地说,应该是包含了 U+0009, U+000B, U+000C, U+000D 等字符在内的 white space)移除。
Java 编译器会使用 re-indentation 算法来移除次要的 white space 字符。
re-indentation 算法
JEP 378: Text Blocks 一文的 2. Incidental white space 小节,介绍了 re-indentation 算法,原文如下 ⬇️
- Split the content of the text block at every LF, producing a list of individual lines. Note that any line in the content which was just an LF will become an empty line in the list of individual lines.
- Add all non-blank lines from the list of individual lines into a set of determining lines. (Blank lines -- lines that are empty or are composed wholly of white space -- have no visible influence on the indentation. Excluding blank lines from the set of determining lines avoids throwing off step 4 of the algorithm.)
- If the last line in the list of individual lines (i.e., the line with the closing delimiter) is blank , then add it to the set of determining lines. (The indentation of the closing delimiter should influence the indentation of the content as a whole -- a significant trailing line policy.)
- Compute the common white space prefix of the set of determining lines, by counting the number of leading white space characters on each line and taking the minimum count.
- Remove the common white space prefix from each non-blank line in the list of individual lines.
- Remove all trailing white space from all lines in the modified list of individual lines from step 5. This step collapses wholly-white-space lines in the modified list so that they are empty, but does not discard them.
- Construct the result string by joining all the lines in the modified list of individual lines from step 6, using LF as the separator between lines. If the final line in the list from step 6 is empty, then the joining LF from the previous line will be the last character in the result string.
我将其翻译如下 ⬇️
- 将文本块的内容在每一个
LF处进行split操作,从而得到individual line的列表。请注意,在文本块的内容中,如果某一行原本只包含LF,那么在split操作之后,这一行会变为空行(即,长度为 0 的行)。- 将
individual line中的所有non-blank行,加入determining line这个集合中。(如果一行的长度为 0 或者完全由white space组成,那么我们称其为blank line,否则就叫non-blank line。排除掉所有的blank line,是为了防止它们影响本算法的第 4 步。)- 如果
individual line中的最后一行(即,和closing delimiter在一起的那一行)是blank line,那么将它加入determining line中。(closing delimiter所在行的缩进会对文本块的内容的缩进有影响 -- 这被称为 significant trailing line 策略。)- 计算所有
determining line的公共white space前缀,具体的方法是对所有determining line的leading white space的字符数量都进行计数,然后取最小的计数值。- 对
individual line里的所有non-blank行,移除公共white space前缀。- 对所有
individual line(在第 5 步中对其进行修改),移除其trailing white space。这一步会将wholly-white-space(完全由white space组成的行)变为空行,但是并不丢弃它们。- 用
LF作为分隔符,对individual line(在第 6 步中已经被修改)执行join操作。如果第 6 步的最后一行是空行,那么最终结果的最后一个字符会是前一行在join操作时用到的LF。
这个算法涉及 7 个步骤,想象算法的运行过程有些抽象,我们还是结合具体的例子来理解吧。 请将以下代码保存为 ShowTextBlock.java
java
public class ShowTextBlock {
public static void main(String[] args) {
String text = """
远看山有色
近听水无声
春去花还在
人来鸟不惊
""";
System.out.println(text);
}
}用以下命令可以编译 ShowTextBlock.java 并运行其中的 main 方法。
bash
javac ShowTextBlock.java
java ShowTextBlock运行结果如下
text
远看山有色
近听水无声
春去花还在
人来鸟不惊在 ShowTextBlock.java 中有很多空格(U+0020),这些空格的数量不容易看清。在 vim 中,通过调整配置,可以将所有的空格(U+0020)都展示为 .,效果如下图所示 ⬇️ 
基于 ShowTextBlock.java,我们可以将 re-indentation 算法的 7 个步骤列举如下 ⬇️ (表中统一用 . 来表示空格字符)
| 第几步 | individual line |
determining line |
|---|---|---|
| 1 | "......远看山有色..." ".......近听水无声.." "." "........春去花还在.." ".........人来鸟不惊......" "..." |
|
| 2 | "......远看山有色..." ".......近听水无声.." "." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) |
"......远看山有色..." ".......近听水无声.." "........春去花还在.." ".........人来鸟不惊......" |
| 3 | "......远看山有色..." ".......近听水无声.." "." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) |
"......远看山有色..." ".......近听水无声.." "........春去花还在.." ".........人来鸟不惊......" "..." (加了一行) |
| 4 | "......远看山有色..." ".......近听水无声.." "." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) |
"......远看山有色..." ".......近听水无声.." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) (计算出公共 white space 前缀是 3) |
| 5 | "...远看山有色..." "....近听水无声.." "." (注意,只有这一行没有变化) ".....春去花还在.." "......人来鸟不惊......" "" |
"......远看山有色..." ".......近听水无声.." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) |
| 6 | "...远看山有色" "....近听水无声" "" ".....春去花还在" "......人来鸟不惊" "" |
"......远看山有色..." ".......近听水无声.." "........春去花还在.." ".........人来鸟不惊......" "..." (没有变化) |
第 7 步执行完 join 操作,所得到的结果等价于 ⬇️
java
String.join(
"\n", // U+000A, i.e. LF
" 远看山有色", // 有 3 个 leading white space
" 近听水无声", // 有 4 个 leading white space
"",
" 春去花还在", // 有 5 个 leading white space
" 人来鸟不惊" // 有 6 个 leading white space
);第 3 步:转义序列的处理
在第 3 步里,会对转义序列进行解释。文本块中除了支持 \n, \t, ', ", \ 等原有的转义序列(完整的列表可以参考 The Java Language Specification (Java SE 14 Edition) 的 3.10.6 小节)外,还支持两个新增的转义序列。
新增转义序列 1: \<line-terminator>
使用 \<line-terminator> 可以阻止插入换行符。例如在 JDK 15 之前,我们可以这样拼接出一个比较长的字符串(请注意,这个字符串中没有换行符)⬇️
java
String literal = "Lorem ipsum dolor sit amet, consectetur adipiscing " +
"elit, sed do eiusmod tempor incididunt ut labore " +
"et dolore magna aliqua.";在 JDK 15 中,我们可以用文本块来拼出内容相同的字符串 ⬇️ (请注意,其中用到了 <line-terminator> 转义序列)
java
String text = """
Lorem ipsum dolor sit amet, consectetur adipiscing \
elit, sed do eiusmod tempor incididunt ut labore \
et dolore magna aliqua.\
""";新增转义序列 2: \s 它会转换成一个空格(U+0020)
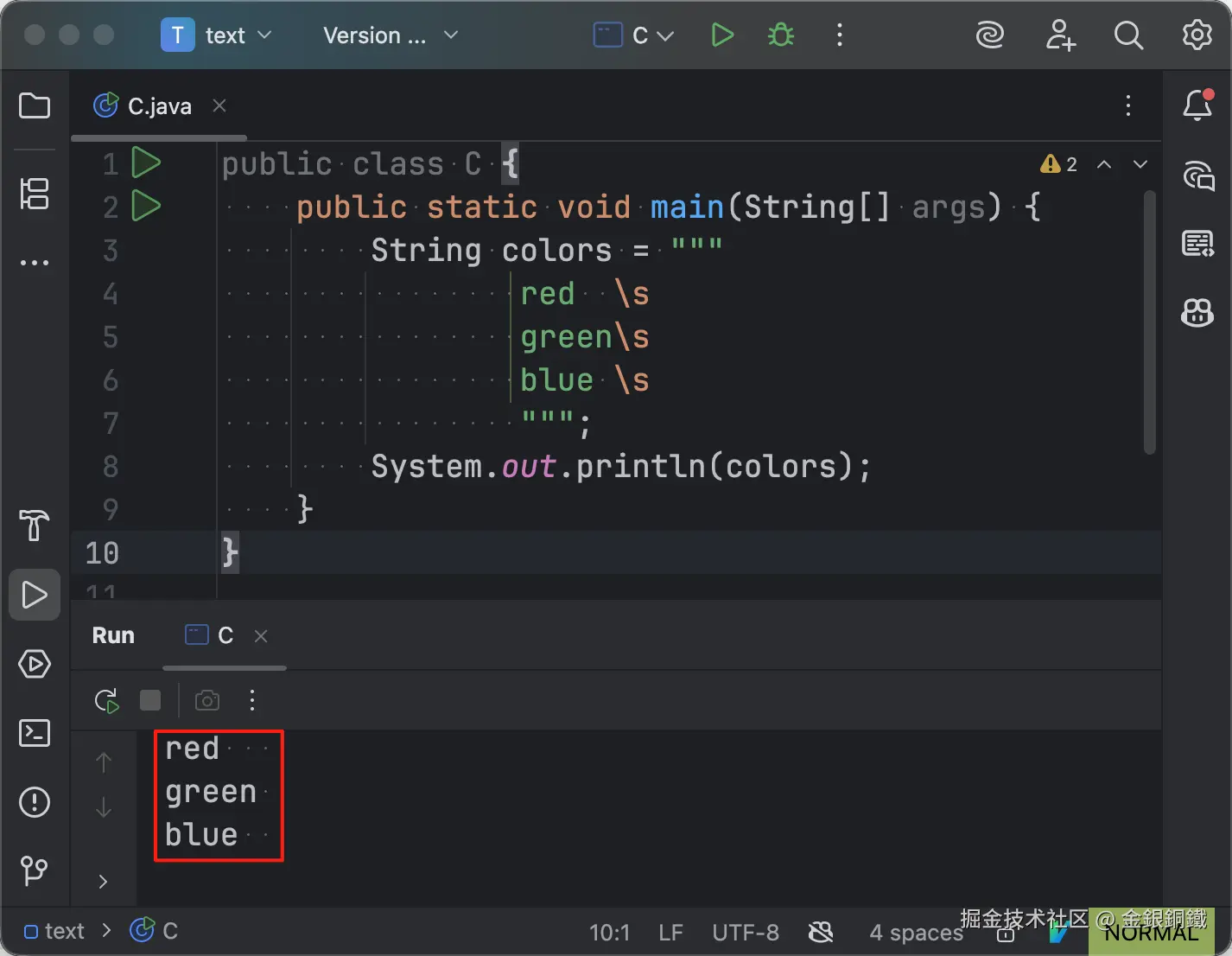
\s 这个转义序列会被转化为空格(U+0020)字符。为什么需要这个转义序列呢?有的时候,我们确实需要在行尾的 white space,但是行尾的 white space 会在第 2 步中被移除。所以我们可以通过使用 \s 转义序列来保留必要的 white space。举个例子,如果我们在 Intellij IDEA 中运行 C 中的 main 方法 ⬇️ 那么会看到标准输出共有 3 行,每一行的结尾都有空格字符(例如 green 后面有一个空格)。
java
public class C {
public static void main(String[] args) {
String colors = """
red \s
green\s
blue \s
""";
System.out.println(colors);
}
}
参考资料
- JEP 378: Text Blocks
The Java® Language Specification(Java SE 14 Edition) 里的3.10.6小节:Escape Sequences for Character and String Literals