前言:在高并发、大数据量的系统中,"分页"看似简单,却常常成为性能瓶颈的源头。
- 为什么查第 1 页只要 10ms,查第 10000 页却要 2s?
- 为什么每次分页都要执行一次
COUNT(*)?这个操作真的必要吗? - 用户到底需要"跳到第 100 页",还是只需要"加载更多"?
本文将从「用户体验 → 数据库原理 → 方案选型 → 框架实践(MyBatis / MyBatis‑Plus / PageHelper / 原生 SQL / Keyset)→ 性能优化」五个层面,系统性地解答这些问题,并给出「可立即落地」的高性能分页实践。
1. 用户体验驱动:先明确你要支持哪种交互
在讨论任何技术方案之前,先问自己:用户到底怎么用?
1.1 跳页
-
用户:
- "我要看第 N 页""直接跳到最后一页看最新一条数据之前的历史"。
- 常见于:运营后台、报表系统、管理控制台。
-
技术要求:
- 精确的总条数 / 总页数。
- 排序稳定,否则用户翻页会看到重复或漏掉记录。
结论:这类场景适合「页号分页」。
1.2 下拉加载 / 无限滚动
-
用户:
- "刷一刷""加载更多""往下滑就行",不关心第几页。
- 常见于:Feed 流、日志流、资讯流。
-
技术要求:
- 性能稳定。
- 顺滑体验,不能频繁"回跳"或出现大量重复记录。
- 排序要稳定不抖动。
结论:这类场景适合「游标 / Keyset 分页」。
1.3 时间窗口 / 区间浏览
-
用户:
- "看最近 7 天的数据""看 ID 在 10000, 20000 的记录"。
- 常见于:报表分析、审计日志、归档浏览。
-
技术要求:
- 强依赖范围(时间/ID)的过滤;分页只是将窗口内数据切块。
- 更关注某个时间段内的数据完整性。
结论:这类场景适合「窗口/区间分页(按时间或 ID 范围)」。
体验决定技术模型:
- 管理后台 → 页号分页
- 大数据流 → Keyset
- 报表/归档 → 时间窗口/区间分页
2. 数据库底层原则:让分页走在"对"的路上
无论选哪种模型,有几个底层原则几乎是"铁律"。
2.1 稳定排序且可索引
-
排序字段必须有索引:
- 否则分页必然伴随 filesort + 回表,越往后越慢。
-
排序要"稳定":
- 仅按非唯一列排序(如
ORDER BY created_at DESC)会导致同一时间多条记录无确定先后,翻页时容易重复/丢失。 - 推荐复合排序键:
ORDER BY created_at DESC, id DESC
对应复合索引:
(created_at, id)。
- 仅按非唯一列排序(如
2.2 避免深分页的大偏移量
-
LIMIT offset, size的执行本质:- 数据库需要"扫描 offset + size 行,然后丢弃前 offset 行",offset 越大,扫描成本越高。
-
深分页查询复杂筛选时,容易触发:
- filesort;
- 大量回表;
- Buffer Pool 热数据被冲刷。
Keyset 的核心价值之一,就是避免这种大偏移扫描。
参考:一些云厂商的深分页优化实践中,常通过改造为 Keyset / Scroll 模式来规避深分页性能问题。
2.3 COUNT(* ) 的成本权衡
COUNT(*) 在分页返回 total、totalPages 上非常常见,但要记住:
-
COUNT 的目的:
- 不是"查数据",而是"告诉前端总共有多少条/多少页"。
-
问题:
- 在大表 + 复杂 WHERE + 多表 JOIN 的场景,精确 COUNT 是一笔不小的开销。
应对策略:
-
分离并简化
countQuery:- 例如只对主表/主键做 count,避免多表 join。
-
使用 "hasNext" 代替精确总页数:
-
查询
size + 1条记录:- 若条数 > size,则
hasNext = true,返回前 size 条; - 前端只展示"加载更多",而不显示"总页数/第几页"。
- 若条数 > size,则
-
2.4 避免函数/表达式排序
-
如
ORDER BY DATE(create_time)、ORDER BY func(column):- 常导致索引失效。
- 正确做法:预先将需要排序的值写入一个字段并建索引,或改变业务需求。
3. 方案选型一览:怎么选、为什么选
3.1 页号分页(Offset)
-
优点:
- 用户容易理解;支持跳页;生态成熟(框架支持丰富)。
-
缺点:
- 深分页(大 offset)性能差;
- 需要更谨慎地处理 COUNT 和排序稳定性。
适合:管理后台、报表、需要跳页的业务。
3.2 Keyset(游标分页)
-
优点:
- 性能稳定:不依赖 offset,翻到"后面几页"也不会明显变慢。
- 抖动更少:以稳定排序键推进,数据新增/删除对已翻页影响小。
-
缺点:
- 不支持任意跳页(你不能直接跳第 100 页,因为协议是"从当前游标继续向后看")。
适合:日志流、Feed 流、时间序列等"只往后看"的场景。
GraphQL Relay、Twitter timeline、很多云存储/列表 API 都采用类似 Keyset 的游标分页。
3.3 窗口/区间分页
-
优点:
- 与业务语义贴近("按时间段查看数据");
- 利用范围索引效率高。
-
缺点:
- UI 层的"第几页"含义不那么强。
适合:报表、审计日志、归档数据分析。
趋势:越来越多系统放弃"精确跳页 + 深分页",转向「Keyset + 加载更多」,以换取性能与一致性。
4. 原生 SQL 的页号分页与 Keyset 实践
4.1 页号分页
以 MyBatis Mapper XML 为例。
Mapper XML(数据 + 简化版 count):
xml
<select id="listItems" resultType="Item">
SELECT id, title, created_at
FROM item
WHERE user_id = #{userId}
ORDER BY created_at DESC, id DESC
LIMIT #{offset}, #{size}
</select>
<select id="countItems" resultType="long">
SELECT COUNT(*)
FROM item
WHERE user_id = #{userId}
</select>Service 计算 offset 并做入参约束:
java
int size = Math.min(reqSize, 100); // 限制最大页大小,防止变相全量
int page = Math.max(reqPage, 1);
int offset = (page - 1) * size;
List<Item> list = mapper.listItems(userId, offset, size);
long total = mapper.countItems(userId);
int totalPages = (int) Math.ceil(total * 1.0 / size);注意事项:
- 排序字段
created_at、id必须有索引; - 尽量使用复合索引
(user_id, created_at, id); - 复杂条件时可拆分
countItems为更简单的统计语句。
4.2 Keyset 分页
仍以 MyBatis XML 为例。
Mapper XML(Keyset 查询):
xml
<select id="listItemsSeek" resultType="Item">
SELECT id, title, created_at
FROM item
WHERE user_id = #{userId}
AND (
created_at < #{lastCreatedAt}
OR (created_at = #{lastCreatedAt} AND id < #{lastId})
)
ORDER BY created_at DESC, id DESC
LIMIT #{size}
</select>Service 组装游标:
java
List<Item> list = mapper.listItemsSeek(userId, lastCreatedAt, lastId, size);
// 返回下一页游标(取最后一条的 created_at 和 id)
Item tail = list.isEmpty() ? null : list.get(list.size() - 1);
NextPageToken next = tail == null
? null
: new NextPageToken(tail.getCreatedAt(), tail.getId());协议设计建议:
- 不直接暴露
lastCreatedAt/lastId,可以将其编码为一个nextPageToken(Base64 + 签名)。 - 客户端只关心
nextPageToken,不需要理解内部细节。
索引建议:
(user_id, created_at, id)复合索引;- 这样 SQL 可以利用索引做顺序扫描,而不是大范围扫表。
5. MyBatis‑Plus:快速实现页号分页
原理: 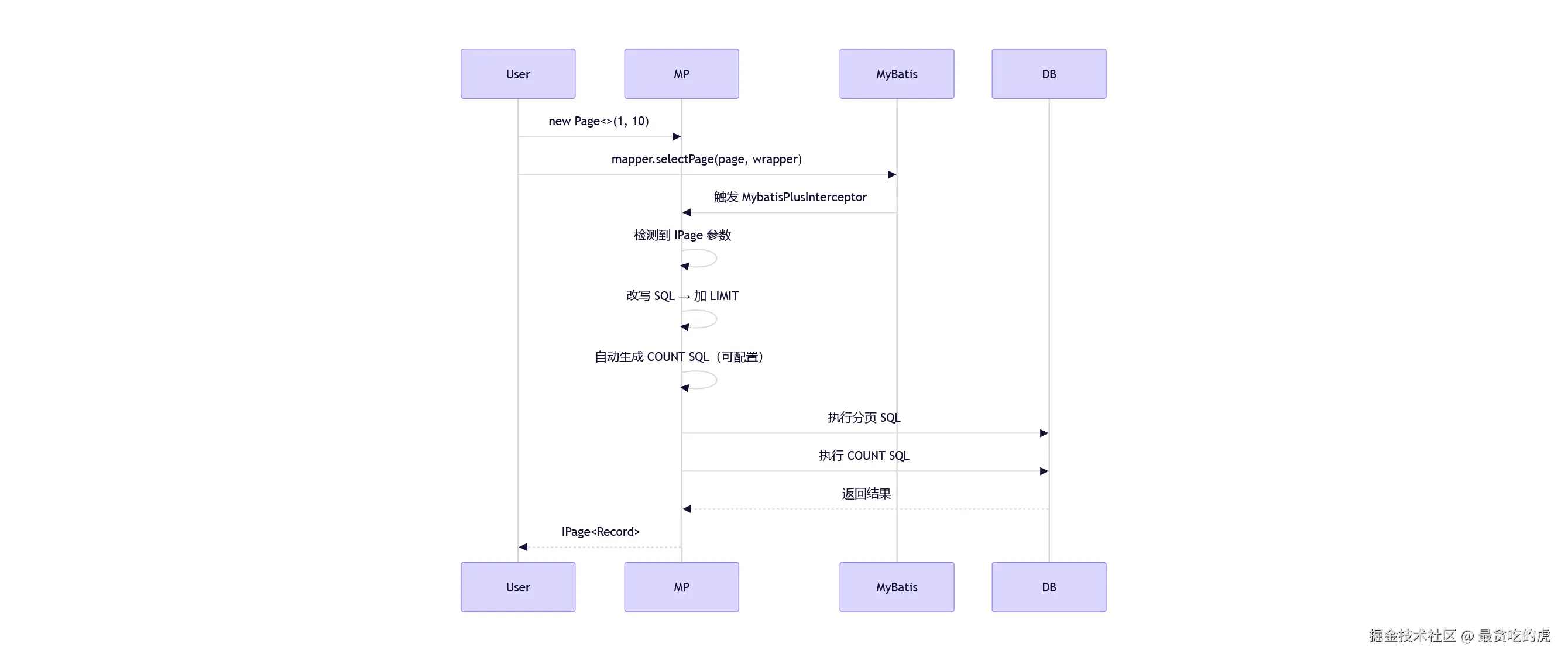
MyBatis‑Plus 的优势是:在"不牺牲 SQL 控制力"的前提下,帮你处理好常规分页工作。
5.1 分页插件配置
参考官方文档配置分页插件:
java
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}5.2 基本分页使用
java
Page<Item> page = new Page<>(pageNum, pageSize, true); // true:统计总数
LambdaQueryWrapper<Item> qw = Wrappers.lambdaQuery(Item.class)
.eq(Item::getUserId, userId)
.orderByDesc(Item::getCreatedAt)
.orderByDesc(Item::getId);
Page<Item> result = itemMapper.selectPage(page, qw);
long total = result.getTotal();
List<Item> records = result.getRecords();注意:
- 一样要保证排序字段有索引;
pageSize要做上限控制;pageNum建议从 1 开始,内部转换为 offset。
5.3 复杂 COUNT 的优化
对于复杂查询:
-
可以关闭自动 count:
new Page<>(pageNum, pageSize, false); -
手工执行更轻量的 count SQL:
- 例如只在主表上 count,再在服务层组装
Page或自定义分页响应;
- 例如只在主表上 count,再在服务层组装
-
或者采用 "size+1 条 + hasNext" 策略,避免 COUNT。
6. PageHelper:拦截器式分页(MyBatis 生态)
原理: 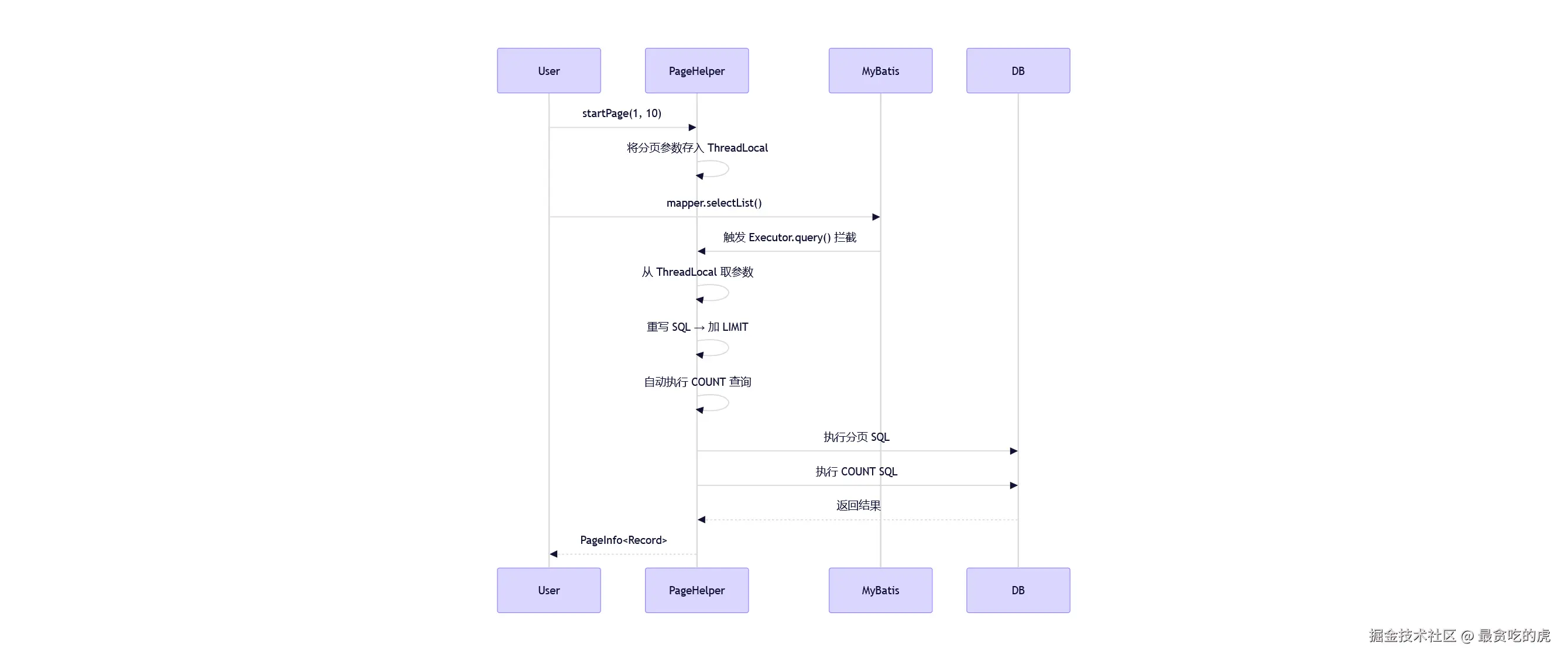
PageHelper 通过拦截 MyBatis 的查询,在 SQL 末尾自动加上 limit/offset 以及 count 语句。
基本用法:
java
PageHelper.startPage(pageNum, pageSize);
List<Item> list = itemMapper.listItems(userId); // 原 SQL 会被拦截并拼接 LIMIT/OFFSET
PageInfo<Item> pageInfo = new PageInfo<>(list);
long total = pageInfo.getTotal();
List<Item> records = pageInfo.getList();建议:
- 搭配稳定排序(建议在 SQL 里显式写
ORDER BY); - 配置合理的参数(
reasonable、pageSizeZero等); - COUNT 昂贵时,可以使用 PageHelper 提供的"关闭 count + 自己统计"组合。
7. 批量查询附加数据:避免 N+1
分页列表常需展示关联数据,如:
- 每条订单的用户昵称;
- 每条短链的"今日点击数";
- 每条帖子下的"点赞数"。
错误做法:循环查询(N+1)
java
for (Order order : orders) {
User user = userMapper.selectById(order.getUserId()); // 每条都查一次
}问题:
- 当前页 N 条就要 N 次查询;
- 延迟和数据库负载线性增长,容易拖垮系统。
正确做法:批量查询 + 内存合并
java
// 1. 提取当前页所有 user_id
List<Long> userIds = orders.stream()
.map(Order::getUserId)
.distinct()
.toList();
// 2. 一次查出所有用户
Map<Long, User> userMap = userMapper.selectBatchIds(userIds).stream()
.collect(Collectors.toMap(User::getId, Function.identity()));
// 3. 内存组装 DTO
List<OrderDTO> dtos = orders.stream()
.map(o -> new OrderDTO(o, userMap.get(o.getUserId())))
.toList();SQL 次数从 N+1 降为 2,性能直接"降了一个数量级"。
通用原则:分页列表需要附加统计或关联信息时,一定要批量查,禁止逐条查,避免 N+1。
8. COUNT 的替代:hasNext 体验
当 COUNT(*) 昂贵时,可以用"是否还有下一页"代替"总条数/总页数"。
简单模式:
java
int size = pageSize;
List<Item> list = mapper.listItemsWithLimit(userId, offset, size + 1);
boolean hasNext = list.size() > size;
List<Item> pageRecords = hasNext ? list.subList(0, size) : list;返回给前端:
records: 当前页数据;hasNext: 是否还有下一页;- 可以不返回
total/totalPages。
体验上类似「加载更多」,对多数"向后浏览"的场景足够好,而且避免了每次 COUNT 的开销。
9. 九个问题、最佳实践
给你一个可以直接对照的 checklist:
- 明确交互:是要"跳页",还是"加载更多",还是"按时间段看"?
- 排序是否稳定?是否包含唯一性字段?是否有对应索引?
- 是否限制了
pageSize的最大值(防止变相全量查询)? - 深分页场景是否考虑使用 Keyset 替代 Offset?
- COUNT 是否会非常昂贵?是否可用简化
countQuery或hasNext方案? - 分页列表是否有"附加统计/关联信息"?是否通过批量查询避免 N+1?
- 是否避免了表达式/函数排序(
ORDER BY func(column))? - 分页 SQL 是否利用到合适的复合索引(如 (user_id, created_at, id))?
- 是否对真实数据分布做过压测和慢查询分析?
10. 结语:
分页是体验与性能的交汇点,当你从用户体验出发,理解数据库的真实运行方式,再结合框架能力做选择时,"分页"就不再是一个隐蔽的性能雷区,而会成为你后端设计中一个可靠、可控的基础设施。
创作不易,希望多多支持!