目录
[GAN是什么("Generative Adversarial Networks")](#GAN是什么(“Generative Adversarial Networks”))
软标签vs硬标签vs伪标签(软伪标签,硬伪标签,但是核心一致))
[CPL 的做法(不是手工):(手工设计的区域划分)](#CPL 的做法(不是手工):(手工设计的区域划分))
[全局 - 局部投票(Global-Local Voting, GLV)->作用阶段特征学习环节,特征质量问题"](#全局 - 局部投票(Global-Local Voting, GLV)->作用阶段特征学习环节,特征质量问题”)
["Intersection selector(交集选择器)" 的作用](#“Intersection selector(交集选择器)” 的作用)
[第一步 Pooling(池化)](#第一步 Pooling(池化))
[第二步 计算全局相似性](#第二步 计算全局相似性)
[基于置信度的软伪标签模块(Confidence-based Soft Pseudo-label Module)](#基于置信度的软伪标签模块(Confidence-based Soft Pseudo-label Module))
[1. CE Loss(Cross-Entropy Loss,交叉熵损失)](#1. CE Loss(Cross-Entropy Loss,交叉熵损失))
[2. Entropy Loss(熵损失-全部数据)](#2. Entropy Loss(熵损失-全部数据))
[3. GLV Loss(Global-Local Voting Loss,全局 - 局部投票损失 -全部数据)](#3. GLV Loss(Global-Local Voting Loss,全局 - 局部投票损失 -全部数据))
[4. CSP Loss(Confidence-based Soft Pseudo-label Loss,基于置信度的软伪标签损失)](#4. CSP Loss(Confidence-based Soft Pseudo-label Loss,基于置信度的软伪标签损失))
[L(CSP)损失的计算-软伪标签损失,用未标注样本的软伪标签(含 Top1/2/3 信息)训练,利用无标签数据。](#L(CSP)损失的计算-软伪标签损失,用未标注样本的软伪标签(含 Top1/2/3 信息)训练,利用无标签数据。)
Lce的用途-监督训练核心,用真实标签约束模型,让模型学会基础分类。
[论文实验中的 "未知攻击" 是 "可控的未知",而非 "极端的未知"](#论文实验中的 “未知攻击” 是 “可控的未知”,而非 “极端的未知”)
研究动机
**攻击类型覆盖不足:**早期方法侧重 GAN 生成图像,忽略了 "身份替换 / 表情迁移" 这类更逼真、威胁性更强的伪造攻击;
场景局限性:大多基于封闭场景设计 ------ 训练集与测试集的类别分布一致(训练时见过的类型,测试时判断一下,无新类型),无法适配 "开放世界"(测试时会出现训练未见过的伪造类型);
数据利用效率低(这个没提,但是应该是也有):真实场景中标注的伪造人脸数据少,但未标注数据多,传统监督学习难以利用海量未标注数据。
现有方法的局部性:
现有方法主要关注样本的全局相似性,忽略了可能表明篡改的伪造人脸图像的局部一致性,解决方法 - 全局和局部特征
OW- DFA的核心挑战:如何在开放世界场景中利用无标签数据,以提高对已知未知伪造人脸的归因性
补充知识
GAN是什么("Generative Adversarial Networks")
生成对抗网络,常用的人工智能生成技术,用来目前生成看似很真实的图像
一个是生成器:相当于 "造假者",目标是生成尽可能逼真的内容(比如假人脸),越像真实的越好,好到能骗过另一个网络。
一个是判别器:相当于 "鉴定师",目标是分辨输入的内容是 "生成器造的假内容" 还是 "真实存在的内容",越准越好。
一开始生成器造的内容很假,判别器很容易就能识破;但生成器会根据判别器的 "反馈" 不断调整,慢慢把假内容做得更逼真;同时判别器也会在和生成器的较量中,不断提升自己的 "鉴定能力"。直到最后,生成器能造出判别器几乎分辨不出来的、和真实内容高度相似的东西,整个学习过程就完成了
软标签vs硬标签vs伪标签(软伪标签,硬伪标签,但是核心一致)
硬标签:非0即1的离散标签,仅仅标记样本属于哪个类别,比如样本属于C1,则标签为0,1,0,....0 ( 推理阶段(模型部署 / 预测):需要明确的分类结果
比如用模型做图片分类时,用户要的是 "这张图是猫",而不是 "这张图是猫的概率 93.6%、狗 4.7%、鸟 1.7%"------ 硬标签能给出明确、可解释的最终结果,符合实际使用的需求。
软标签:类别概率分布(例如样本的标签为0.1, 0.8, 0.05,..., 0.05,既标记 "最可能的类别",也保留 "模型对其他类别的置信度";
伪标签:针对未标注数据生成的模型预测标签,核心是利用模型自身的预测结果为无标签数据赋予 "临时标签",从而实现半监督学习,具体解读如下:
一些类似于注释
DFA:识别来源模型 -人话:检测人脸怎么伪造的
OW- DFA:DFA(Pro Max版本):开发世界,属于可以识别已知类型,并且发现出未知的类型
引入了CPL框架-全局-投票模块
CPL 的做法(不是手工):(手工设计的区域划分)
它 自动 把特征图切成 3×3 或 5×5 的小块,
然后 让网络自己算 每块的重要性(用 L2 响应),
重要的地方权重高 ,不重要的地方权重低 ,但 不会完全扔掉,
最终 加权融合 所有局部信息。
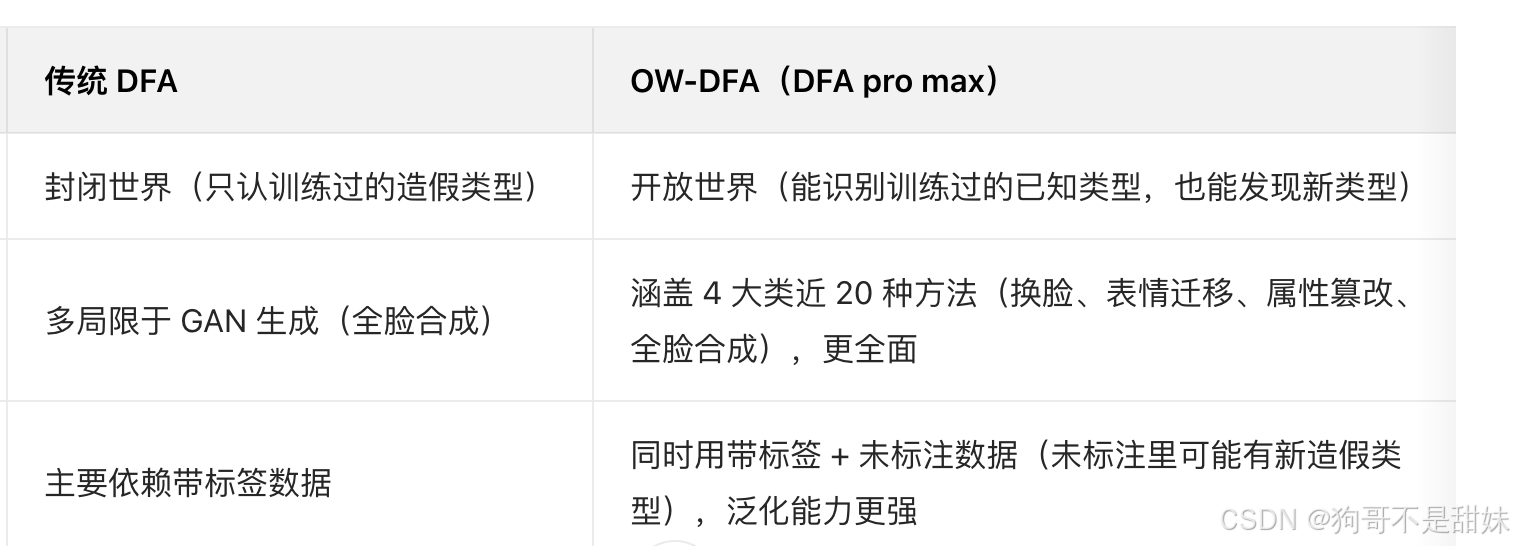
详细解读
- Face Type:人脸数据的 "类型"(是真实人脸,还是哪种篡改 / 生成的人脸);
- Labeled Sets :训练阶段用的 "已标注数据集"(即模型训练时见过的、带 "篡改 / 真实" 标签的数据);
- Unlabeled Sets :测试阶段用的 "未标注数据集"(即模型测试时要判断的、不带标签的数据);
- Source Dataset:这些数据 "来自哪个公开基准数据集"(相当于数据的 "出处");
- Method:具体的 "人脸篡改 / 生成技术"(比如 Deepfakes 是一种身份替换的方法);
- Tag :测试数据的 "类型标识":
Known:模型训练时见过的方法(相当于 "同分布测试");Novel:模型训练时没见过的方法(相当于 "跨分布 / 泛化测试");- Labeled #/Unlabeled # :对应数据集的样本数量(# 代表 "数量")。
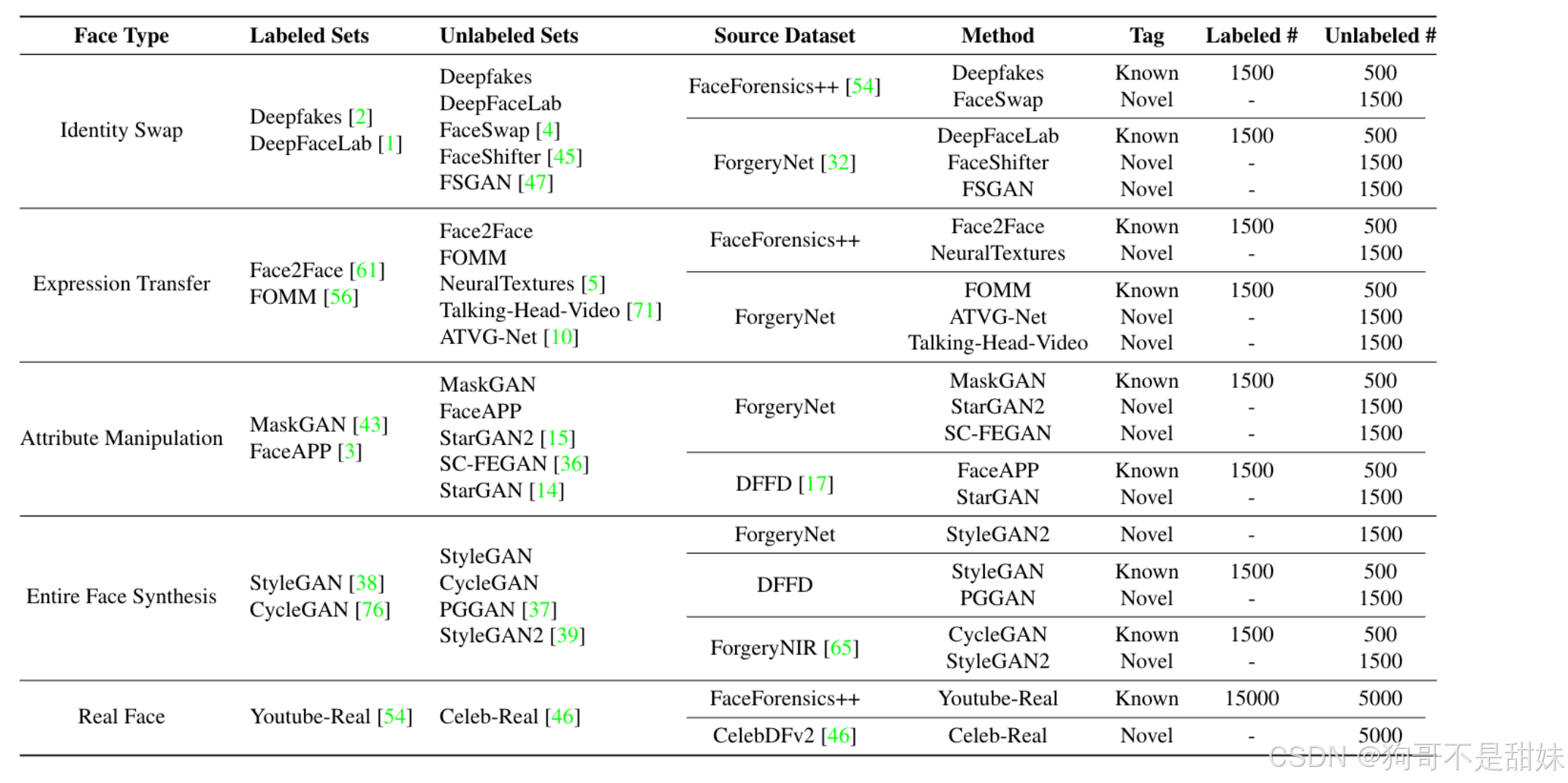
数据集划分

标签的未知性,因此Du也无需去管yi
这块下面说的很清楚
标注集中的已知类别 CL
未标注集中的所有类 CU
交集为Ck,即未知的数据集里面,包含的已知数据集
CN=Cu\Cl(差集,可以理解为减法)
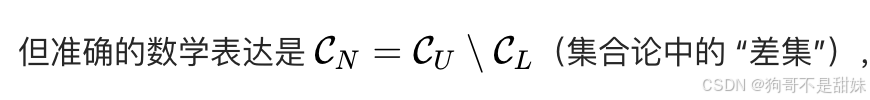

大部分操作都是根据这个图
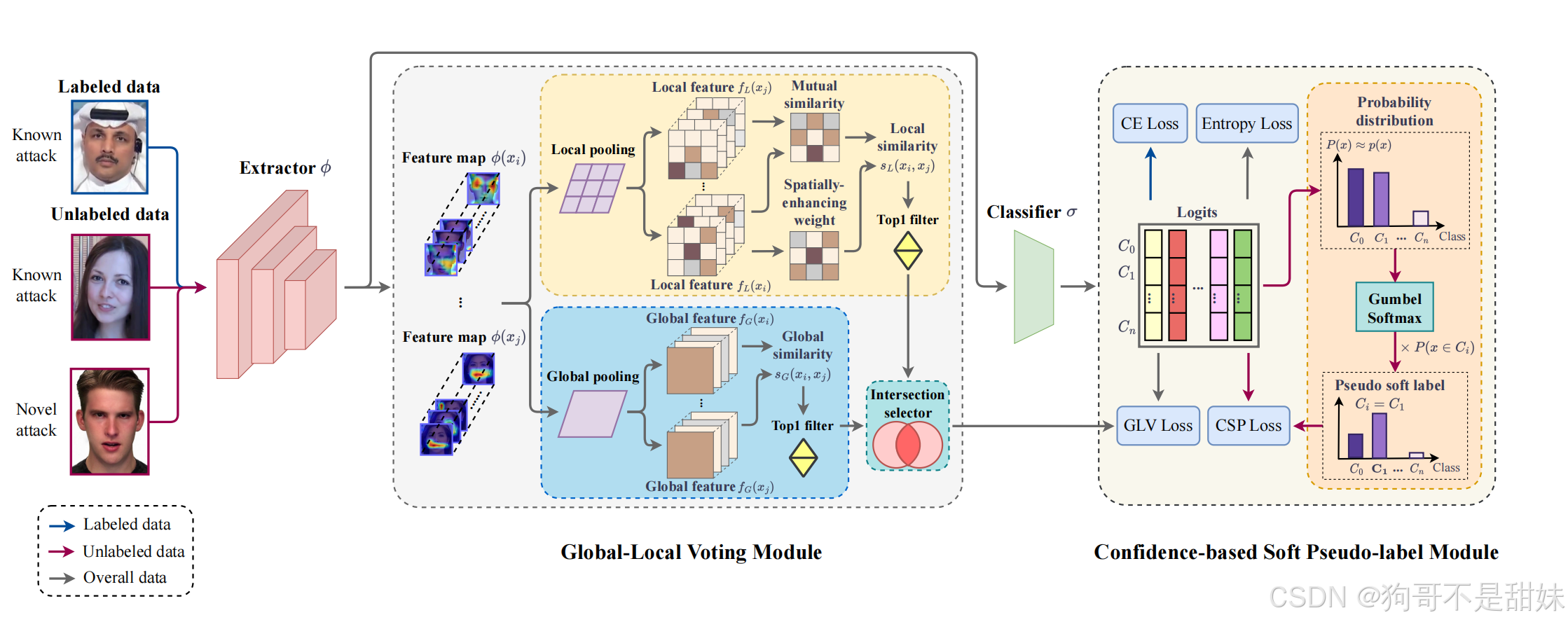
**全局 - 局部投票(Global-Local Voting, GLV)->作用阶段特征学习环节,**特征质量问题"
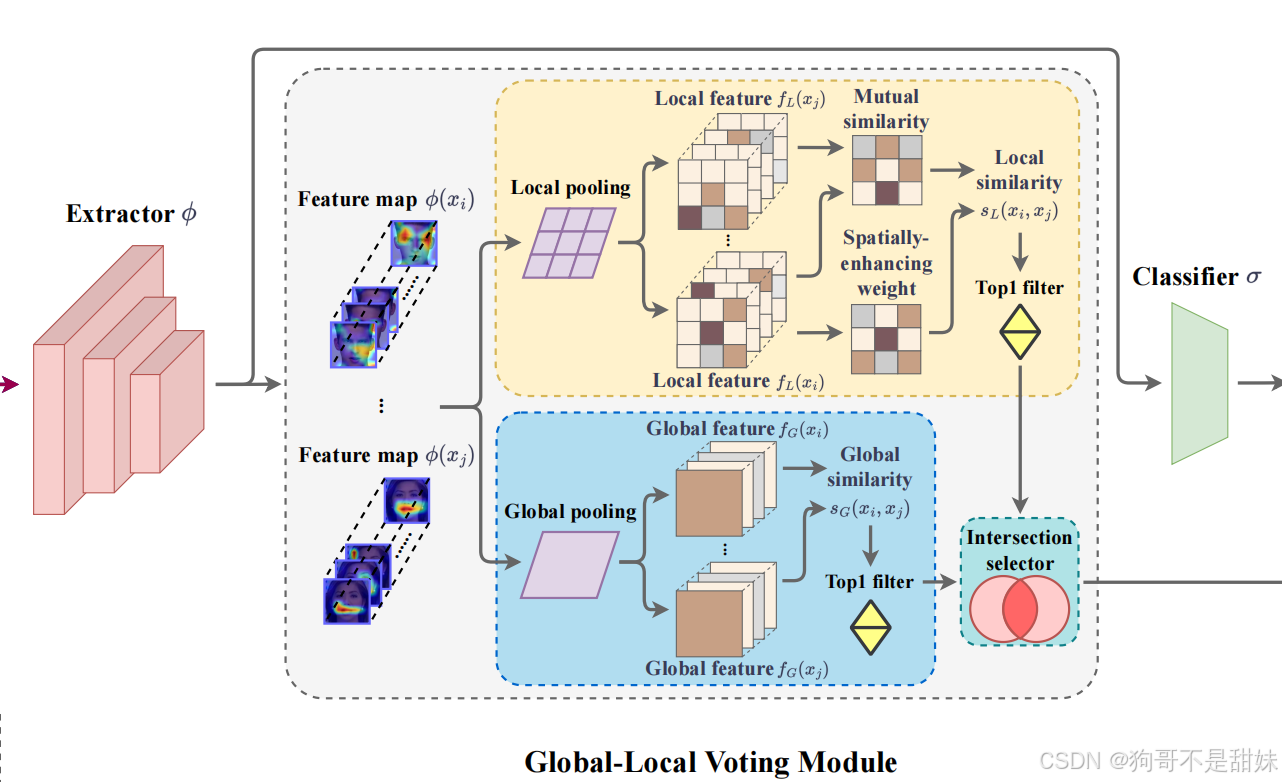
还有一个有意思的,最上面的那条线,并非是绕过中间的全局-局部投票模块,而是表示特征图传递路径
中间的Global-Local Voting Module -全局投票
两条分支的流程
局部特征分支:对特征图做局部池化得到多个局部特征,计算这些局部特征之间的相似度,结合空间增强权重后,通过 Top1 filter 筛选出 "相似度最高的局部特征对"。
全局特征分支:对特征图做全局池化得到全局特征,计算全局特征之间的相似度,同样通过 Top1 filter 筛选出 "相似度最高的全局特征对"。
"Intersection selector(交集选择器)" 的作用
不是 "取 Top1 的交集",而是融合两条分支的 Top1 结果:
- 局部分支的 Top1 反映 "人脸局部区域(如五官)的伪造特征相似度";
- 全局分支的 Top1 反映 "整个人脸的伪造特征相似度";
- 交集选择器会保留同时在 "局部 Top1" 和 "全局 Top1" 中出现的特征对(或融合两者的信息),从而过滤掉单一分支中可能存在的噪声,得到更鲁棒的特征表示。
全局特征分支
第一步 Pooling(池化)
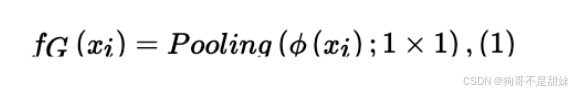




第二步 计算全局相似性

通过余弦相似度可以判断 "两个样本的全局特征是否相似"------ 若两个样本是同一类伪造方法,它们的全局特征相似度会更高;反之则更低。这为后续的 "Top1 筛选" 和 "特征融合" 提供了依据。
简言之,这两步是先把特征图转成全局特征向量,再用余弦相似度衡量不同样本的全局特征相似性,是全局分支实现 "特征区分" 的核心逻辑。


该损失的作用是约束样本的全局特征关系:让 "语义相似的样本(比如同一类伪造方法)" 的全局特征更聚集,从而提升特征的区分性 ------ 无论样本是标注数据D(L) 还是未标注数据Du,都会被该损失约束。

局部特征分支
q*q是一个正方形,对称


L2范数

局部也有优先级,脸,嘴啥的
- 伪造人脸的篡改区域会有更高的特征响应(比如像素变化更明显);
- L2 范数可以有效衡量特征的 "响应强度",因此用 L2 范数来定义局部区域的优先级。
全局加局部
这个是全局-局部损失函数
我的理解,到目前还是优化训练的数据,这里面,
模型的目标是让 "同类样本的特征更聚集",而可靠的样本对(一致的情况)是 "同类样本" 的概率更高 ------ 因此需要通过损失函数约束它们的特征 "更接近",以此优化模型的特征学习能力。
如果全局和局部的 Top-1 样本不一致,说明这个相似性判断 "不可靠"(比如全局认为 A 相似,但局部伪造痕迹显示 B 更相似),此时若强行约束,反而会误导模型学习错误的特征关系 ------ 所以不纳入损失计算。




最终通过GLV损失将上述约束转化为模型可优化的目标,让匹配可靠的样本对特征更接近,提升类内特征紧凑性 ------ 该损失直接作用于特征提取器
的参数更新,而非修改数据集。
基于置信度的软伪标签模块(Confidence-based Soft Pseudo-label Module)
上述的对比学习,相同伪造类型人脸可以被分组,处理具有相似篡改区域的样本可能在缺乏监督的情况下,混入其他类别
使用伪标签,将概率最高的预测类别用作分类监督
但是我们发现,不仅是最高的预测很好,第二第三也有很大概率正确
引入噪声样本" 是指 "伪标签与真实类别不一致"。如果模型对 Top1、Top2、Top3 的预测都接近真实类别,那么同时保留这几个类别的信息(而非仅选 Top1,这里的Top是模型对样本类别的预测结果(即类别标签))
1. CE Loss(Cross-Entropy Loss,交叉熵损失)
- 含义:是分类任务中最常用的监督损失函数,用于衡量 "模型预测的类别概率分布" 与 "真实标签的概率分布" 之间的差异;
- 作用 :在该框架中,针对标注数据(仅针对已知攻击),通过 CE Loss 让模型学习 "特征→已知类别" 的正确映射,保证对已知伪造方法的分类准确性。
2. Entropy Loss(熵损失-全部数据)
- 含义:熵是衡量 "概率分布不确定性" 的指标,熵越大表示预测结果越不确定;熵损失通常是 "最小化预测分布的熵";
- 作用:让模型对样本的预测结果更 "明确"(即某一类别的概率显著高于其他类别),避免输出模糊的概率分布,提升预测的置信度(同时覆盖标注 / 未标注数据)。
3. GLV Loss(Global-Local Voting Loss,全局 - 局部投票损失 -全部数据)
- 含义:是该框架自定义的损失函数,针对 "全局 - 局部投票模块" 的输出设计;
- 作用:约束 "局部特征相似度" 和 "全局特征相似度" 的一致性,确保两者筛选出的 Top1 特征对是匹配的,从而提升特征的区分性与可靠性(覆盖所有数据)。
4. CSP Loss(Confidence-based Soft Pseudo-label Loss,基于置信度的软伪标签损失)
- 含义:是针对未标注数据设计的半监督损失函数;
- 作用 :基于 "软伪标签"(模型对未标注数据的高置信度预测结果,仅针对未知数据),让模型从无标签数据中学习特征规律,尤其是对 "新攻击类型" 的特征学习,提升开放世界下的泛化能力。
这些损失函数组合使用,实现了 "监督学习(标注数据)+ 半监督学习(未标注数据)+ 特征优化" 的协同训练,是该框架实现开放世界溯源的核心保障。
受于前面的启发,引入基于置信度的软伪标签模块,模块根据所有类别输出概率为每个未标记样本,分配伪标签对于未标注的样本xi^(u),先通过特征提取器,得到全局特征fg(xi^(u) ),再去输入分类
Gumbel - 生成软标签

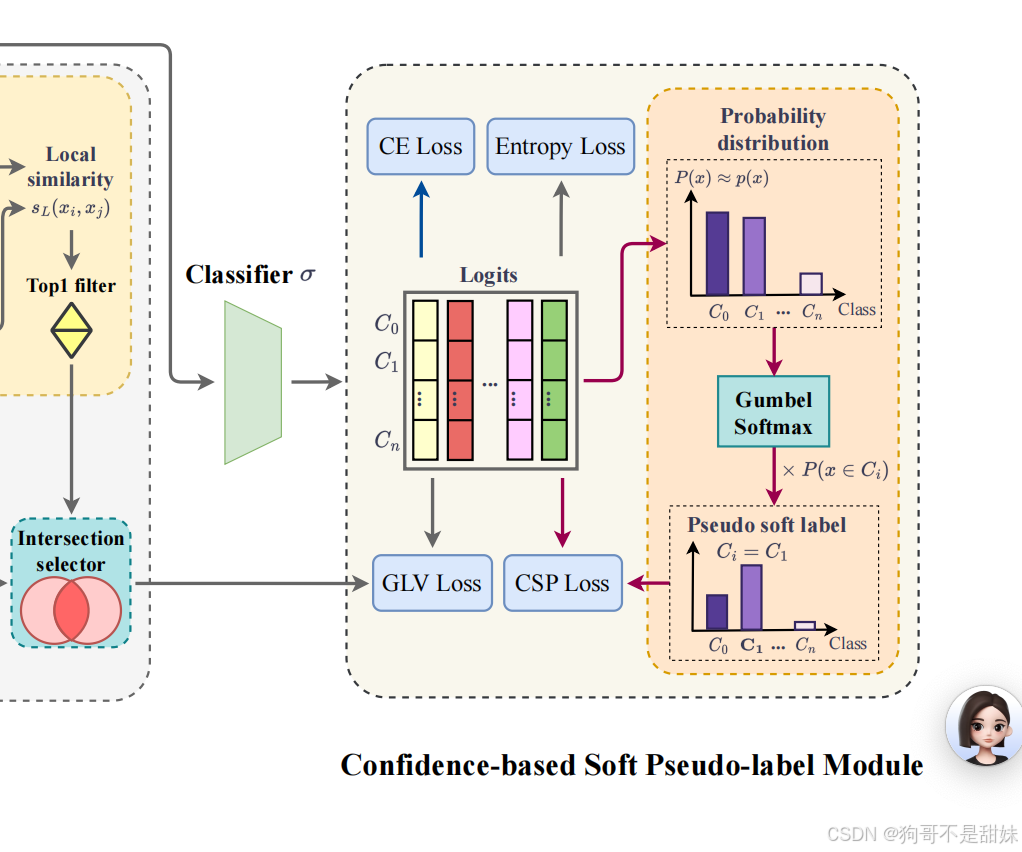




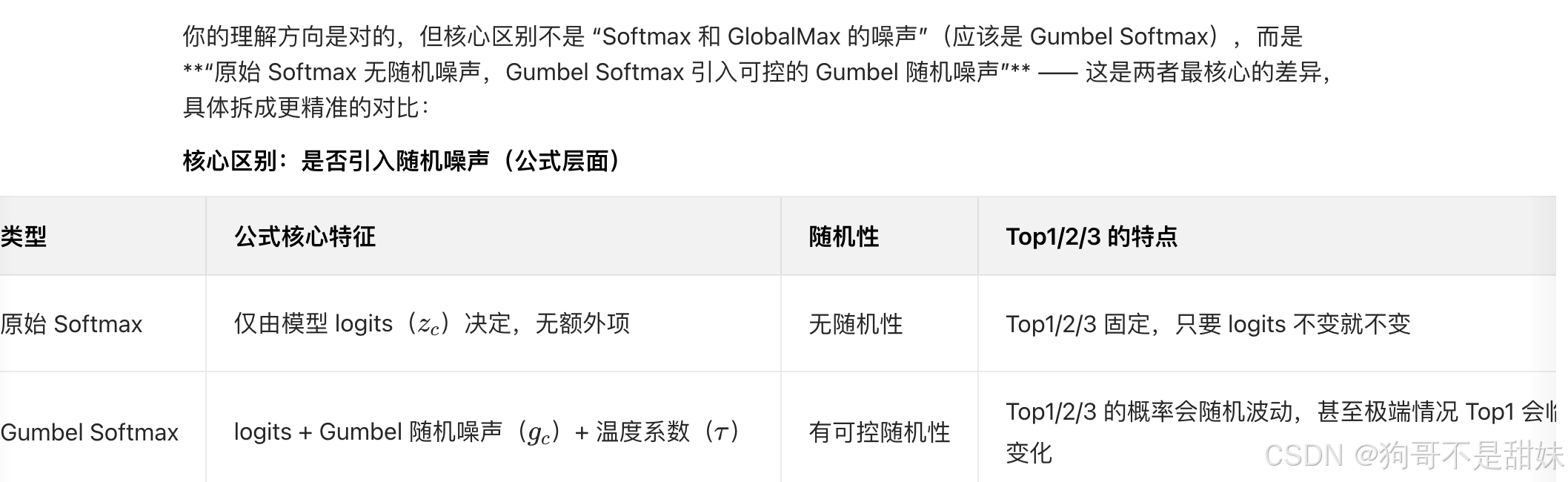
为什么说是使用Gumbel Softmax 是因为他可传播吗,为什么Softmax不可传播,是因为他不可导吗 -
如果用普通 Softmax 的输出取 "硬标签"(比如选 Top-1 类别,将其设为 1,其他设为 0),这个 "取 Top-1" 的操作是不可导的------ 因为它是一个离散的 "跳跃式" 选择(比如从 0.6→1,其他从 0.3→0),梯度无法通过这个离散操作传递,导致伪标签无法反向优化模型

动态权重
生成软伪标签后,会基于模型输出的类别概率分布,计算置信度权重(比如用 Top-1 预测的置信度作为权重)。
- 若某样本的 Top-1 置信度很高(如 0.9),则该软伪标签的权重较大,在损失中占比更高;
- 若置信度很低(如 0.5),则权重较小,减少低质量伪标签对训练的干扰。

L(CSP)损失的计算-软伪标签损失,用未标注样本的软伪标签(含 Top1/2/3 信息)训练,利用无标签数据。
损失函数里的c:是所有类别(比如 "GAN 伪造、表情迁移、换脸"),求和是对每个类别计算损失后再累加。 (下面公式的C)
双重求和:对所有未标注样本、所有类别计算损失,再取平均。
- 对未标注样本,把它与 "软伪标签类别相同" 的样本特征拉近;
- 与 "软伪标签类别不同" 的样本特征推远;
- 损失会同时约束 "特征的类内紧凑性" 和 "类间区分性",让模型从软伪标签中学习更可靠的类别规律。

Lce的用途-监督训练核心,用真实标签约束模型,让模型学会基础分类。


R的用途



总损失函数


代码解读



阶段2



为什么代码里面stage1,使用L(ce),stage2使用总损失,stage3使用l(ce),为啥不是全部直接总损失



不足
论文实验中的 "未知攻击" 是 "可控的未知",而非 "极端的未知"
论文(如 CDAL)中所谓的 "未知攻击",本质是 **"训练时没见过,但测试前已预设标签的未知"**,属于 "可控场景"
"真实世界中独一份、无任何对应标签的未知攻击",属于 **"极端未知"**,其核心是 "无类别体系、无批量样本、无统计规律",这正是现有实验(包括 CDAL)未完全解决的问题