1.项目
pdf-craft 可以将 PDF 文件转化为各种其他格式。该项目将专注于扫描书籍的 PDF 文件的处理。
2.PDF 转 MD
2.1.环境准备
VSCode 创建项目文件夹,文件夹下创建 pdf_soufce_files 和 md_output_files 和 model 三个子文件夹,分别放 pdf 扫描文件和转换后的 md 文件以及大模型。
点击 VSCode 的终端功能,新建虚拟环境并安装 pdf-craft 包。
python
python -m venv .venv
.\.venv\Scripts\activate
pip install pdf-craft[cpu]2.2.代码
注意:执行过程中,如果没有大模型会下载,看自己的网络,如果不行,可能需要其他办法。
python
from pdf_craft import create_pdf_page_extractor, PDFPageExtractor, MarkDownWriter
extractor: PDFPageExtractor = create_pdf_page_extractor(
device="cpu", # 如果希望使用 CUDA,请改为 device="cuda" 这样的格式。
model_dir_path="model", # AI 模型下载和安装的文件夹地址
)
with MarkDownWriter("md_output_files/test.md", "images", "utf-8") as md:
for block in extractor.extract(pdf="pdf_soufce_files/test.pdf"):
md.write(block)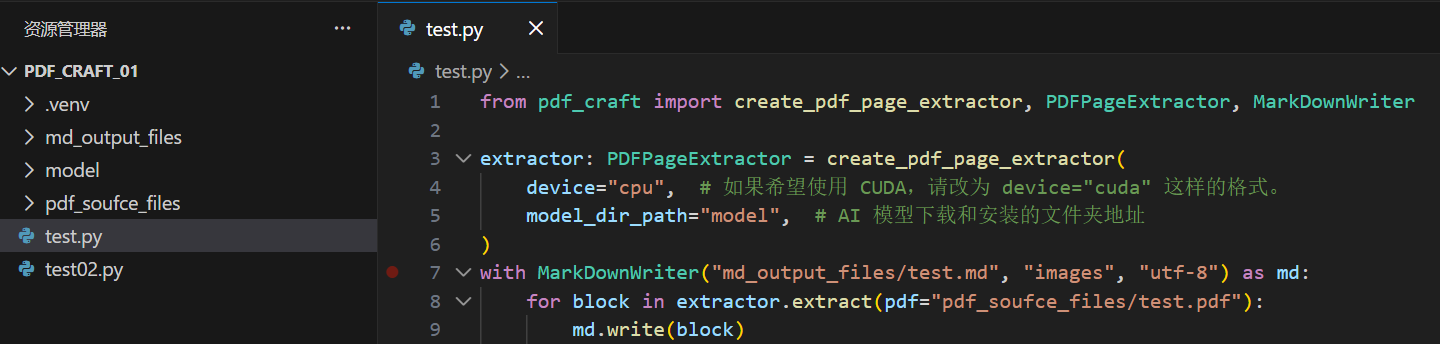
2.3.执行过程

3.PDF 转 EPUB
3.1.环境准备
VSCode 创建项目文件夹,文件夹下创建 pdf_soufce_files 并把戴转换的电子书放入其中。
analysing ,model,output/files,output/epub 文件夹会自动创建,分别放 pdf 扫描文件中间文件以及大模型和 EPUB 输出文件。
点击 VSCode 的终端功能,新建虚拟环境并安装 pdf-craft 包。
python
python -m venv .venv
.\.venv\Scripts\activate
pip install pdf-craft[cpu]3.2.申请 deepsessk key
进入 DeepSeek 开放平台,实名后充值即可,一本书一般不到五块钱。
3.3.代码
让 deepseek 写了一个,只需要把 pdf 文件放到 pdf_soufce_files 文件夹下即可,如果有中文,会自动翻译成英文。
使用前,需要配置一个叫 OPENAI_API_KEY 的环境变量。变量的值是上一步申请到的 key 。
python
import os
import re
import requests
from pdf_craft import (
create_pdf_page_extractor,
PDFPageExtractor,
LLM,
analyse,
generate_epub_file,
)
# -----------------------------
# 统一定义脚本目录(绝对路径)
# -----------------------------
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
SOURCE_DIR = os.path.join(BASE_DIR, "pdf_source_files")
# -----------------------------
# 文件名翻译(DeepSeek 简化版)
# -----------------------------
def translate_filename(text, api_key=None):
"""仅用于翻译 PDF 文件名,非常轻量"""
if api_key is None:
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("未找到 API Key,请设置 OPENAI_API_KEY 环境变量。")
url = "https://api.deepseek.com/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
data = {
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "Translate the following filename from Chinese to English. Only output the translated filename.",
},
{"role": "user", "content": text},
],
"temperature": 0.1,
}
try:
response = requests.post(url, headers=headers, json=data, timeout=10)
response.raise_for_status()
result = response.json()
name = result["choices"][0]["message"]["content"].strip()
name = re.sub(r'[\\/:*?"<>|]', "", name)
return name
except Exception as e:
print(f"翻译失败,使用中文文件名:{text}, 错误:{e}")
return text
# -----------------------------
# 主流程:扫描 PDF → 重命名 → 转换 → EPUB
# -----------------------------
def auto_convert():
print("开始扫描 pdf_source_files 目录...")
if not os.path.exists(SOURCE_DIR):
print(f"目录 {SOURCE_DIR} 不存在,已创建。")
os.makedirs(SOURCE_DIR)
return
pdf_files = [f for f in os.listdir(SOURCE_DIR) if f.lower().endswith(".pdf")]
if not pdf_files:
print("未发现 PDF 文件,请放入 pdf_source_files 后重新运行。")
return
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("未设置 OPENAI_API_KEY 环境变量!")
pdf_page_extractor: PDFPageExtractor = create_pdf_page_extractor(
device="cpu",
model_dir_path=os.path.join(BASE_DIR, "model"), # 绝对路径
)
llm = LLM(
key=api_key,
url="https://api.deepseek.com",
model="deepseek-chat",
token_encoding="o200k_base",
)
for pdf in pdf_files:
full_path = os.path.join(SOURCE_DIR, pdf)
base_name = os.path.splitext(pdf)[0]
print(f"\n=== 处理文件:{pdf} ===")
if re.search(r"[\u4e00-\u9fa5]", base_name):
print("检测到中文文件名,正在翻译...")
new_name = translate_filename(base_name, api_key=api_key)
new_pdf = new_name + ".pdf"
new_path = os.path.join(SOURCE_DIR, new_pdf)
os.rename(full_path, new_path)
print(f"文件已重命名为:{new_pdf}")
full_path = new_path
base_name = new_name
# -----------------------------
# 所有路径改成绝对路径
# -----------------------------
analysing_dir = os.path.join(BASE_DIR, "analysing", base_name)
output_dir = os.path.join(BASE_DIR, "output", "files", base_name)
epub_output = os.path.join(BASE_DIR, "output", "epub", base_name + ".epub")
os.makedirs(analysing_dir, exist_ok=True)
os.makedirs(output_dir, exist_ok=True)
os.makedirs(os.path.dirname(epub_output), exist_ok=True)
print("开始分析 PDF...")
analyse(
llm=llm,
pdf_page_extractor=pdf_page_extractor,
pdf_path=full_path,
analysing_dir_path=analysing_dir,
output_dir_path=output_dir,
)
print("生成 EPUB 文件...")
generate_epub_file(
from_dir_path=output_dir,
epub_file_path=epub_output,
)
print(f"EPUB 生成完成:{epub_output}")
print("\n 所有文件已处理完毕!")
if __name__ == "__main__":
auto_convert()